
文章目录
写在前面
k8s集群,每一台机器需要2核CPU+2G的内存。
我们此次搭建的集群环境,各个版本如下:
- Docker 18.09.0
- kubeadm-1.14.0-0
- kubelet-1.14.0-0
- kubectl-1.14.0-0 - k8s.gcr.io/kube-apiserver:v1.14.0- k8s.gcr.io/kube-controller-manager:v1.14.0- k8s.gcr.io/kube-scheduler:v1.14.0- k8s.gcr.io/kube-proxy:v1.14.0- k8s.gcr.io/pause:3.1- k8s.gcr.io/etcd:3.3.10- k8s.gcr.io/coredns:1.3.1
- calico:v3.9
此次我们会搭建一个master节点,两个worker节点。
官网GitHub
一、准备三个centos7虚拟机
注:我们使用virtualbox+vagrant进行快速搭建centos7,首先要下载安装virtualbox+vagrant,然后按照我们的步骤快速搭建3个centos7。
更多详细请移步:
快速搭建centos7虚拟机——使用virtualbox+vagrant
1、创建Vagrantfile
在D:\linux\k8s目录(可以自定义),创建Vagrantfile:
boxes =[{
:name =>"master-kubeadm-k8s",
:eth1 =>"192.168.56.100",
:mem =>"2048",
:cpu =>"2"},
{
:name =>"worker01-kubeadm-k8s",
:eth1 =>"192.168.56.101",
:mem =>"2048",
:cpu =>"2"},
{
:name =>"worker02-kubeadm-k8s",
:eth1 =>"192.168.56.102",
:mem =>"2048",
:cpu =>"2"}]
Vagrant.configure(2)do|config|
config.vm.box ="centos/7"
boxes.each do|opts|
config.vm.define opts[:name]do|config|
config.vm.hostname = opts[:name]
config.vm.provider "vmware_fusion"do|v|
v.vmx["memsize"]= opts[:mem]
v.vmx["numvcpus"]= opts[:cpu]
end
config.vm.provider "virtualbox"do|v|
v.customize ["modifyvm", :id, "--memory", opts[:mem]]
v.customize ["modifyvm", :id, "--cpus", opts[:cpu]]
v.customize ["modifyvm", :id, "--name", opts[:name]]
end
config.vm.network :private_network, ip: opts[:eth1]
end
end
end
2、启动三台虚拟机
# 在Vagrantfile同级目录下启动虚拟机,首次启动会耗时很久,耐心等待
vagrant up
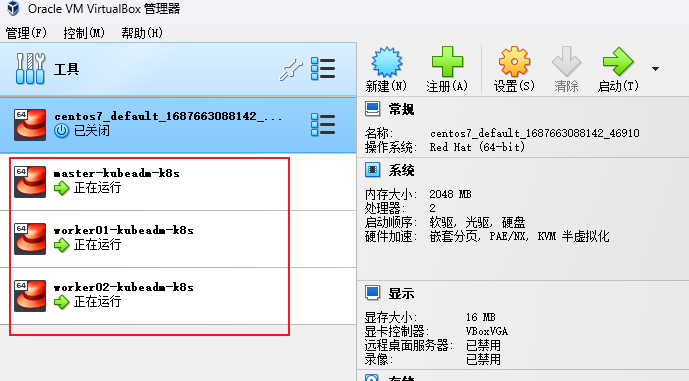
3、配置centos7支持ssh登录(所有机器)
#分别进入三台虚拟机,root用户,密码是vagrant# [进入manager-node]
vagrant ssh master-kubeadm-k8s
# [进入worker01-node]
vagrant ssh worker01-kubeadm-k8s
# [进入worker02-node]
vagrant ssh worker02-kubeadm-k8s
# 切换为rootsu root
vi /etc/ssh/sshd_config
修改PasswordAuthentication yes
重启服务 service sshd restart
以后可以使用提供的 ssh 连接工具直接连接

4、修改 linux 的 yum 源(所有机器)
1)、备份原 yum 源
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup
2)、使用新 yum 源
curl -o /etc/yum.repos.d/CentOS-Base.repo http://mirrors.163.com/.help/CentOS7-Base-163.repo
3)、生成缓存
yum makecache
注:三台机器都执行。
5、更新并安装依赖(所有机器)
# 三台机器都需要执行
yum -y update
yum install -y conntrack ipvsadm ipset jq sysstat curl iptables libseccomp
6、安装docker(所有机器)
# 1、卸载系统之前的 docker(如果装过的话)sudo yum remove docker\
docker-client \
docker-client-latest \
docker-common \
docker-latest \
docker-latest-logrotate \
docker-logrotate \
docker-engine
# 2、安装必要依赖sudo yum install -y yum-utils device-mapper-persistent-data lvm2
# 3、设置 docker repo 的 yum 位置sudo yum-config-manager \
--add-repo \
http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
# 4、更新yum软件包索引
yum makecache fast
# 5、安装docker(指定版本)sudo yum install -y docker-ce-18.09.0 docker-ce-cli-18.09.0 containerd.io
# 6、启动docker并设置开机启动sudo systemctl start docker&&sudo systemctl enabledocker# 7、设置阿里云的docker镜像加速sudomkdir -p /etc/docker
sudotee /etc/docker/daemon.json <<-'EOF'
{
"registry-mirrors": ["https://t3irn0eu.mirror.aliyuncs.com"]
}
EOF# 重启服务器sudo systemctl daemon-reload
sudo systemctl restart docker# 8、测试docker安装是否成功sudodocker -v
7、修改host文件(所有机器)
设置master的hostname,并且修改hosts文件
sudo hostnamectl set-hostname m 02
两个worker设置worker01/02的hostname,并且修改hosts文件
sudo hostnamectl set-hostname w1
sudo hostnamectl set-hostname w2
三台机器修改host文件:
vi /etc/hosts
192.168.56.100 m
192.168.56.101 w1
192.168.56.102 w2
ping一下,看是否能通过主机名ping通。
8、系统基础前提配置(所有机器)
# 关闭防火墙
systemctl stop firewalld && systemctl disable firewalld
# 关闭selinux
setenforce 0sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/config
# 关闭swap
swapoff -a
sed -i '/swap/s/^\(.*\)$/#\1/g' /etc/fstab
# 配置iptables的ACCEPT规则
iptables -F && iptables -X && iptables \
-F -t nat && iptables -X -t nat && iptables -P FORWARD ACCEPT
# 设置系统参数cat<<EOF> /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sysctl --system
二、使用kubeadm&kubelet&kubectl安装k8s集群
1、配置yum源(所有机器)
cat<<EOF> /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
2、安装kubeadm&kubelet&kubectl(所有机器)
yum install -y kubelet-1.14.0-0 kubeadm-1.14.0-0 kubectl-1.14.0-0
# 如果报错的话,或许需要先安装这个
yum install -y kubernetes-cni-0.7.5-0
3、docker和k8s设置同一个cgroup(所有机器)
注!这一步骤算是踩坑,新机器或许不需要做这一步。
# 打开daemon.jsonvi /etc/docker/daemon.json
# 追加"exec-opts":["native.cgroupdriver=systemd"],

# 重启docker
systemctl restart docker
# kubelet,这边如果发现输出directory not exist,也说明是没问题的,大家继续往下进行即可 # 检验kubelet的cgroup的方式是否为systemd,如果不是就修改,如果是就找不到文件sed -i "s/cgroup-driver=systemd/cgroup-driver=cgroupfs/g" /etc/systemd/system/kubelet.service.d/10-kubeadm.conf
4、启动kubelet (所有机器)
#启动
systemctl enable kubelet && systemctl start kubelet
5、拉取所需镜像(所有机器)
[root@master-kubeadm-k8s ~]# kubeadm config images list
I0703 07:09:28.230209 14181 version.go:96] could not fetch a Kubernetes version from the internet: unable to get URL "https://dl.k8s.io/release/stable-1.txt": Get https://dl.k8s.io/release/stable-1.txt: net/http: request canceled while waiting for connection (Client.Timeout exceeded while awaiting headers)
I0703 07:09:28.230609 14181 version.go:97] falling back to the local client version: v1.14.0
k8s.gcr.io/kube-apiserver:v1.14.0
k8s.gcr.io/kube-controller-manager:v1.14.0
k8s.gcr.io/kube-scheduler:v1.14.0
k8s.gcr.io/kube-proxy:v1.14.0
k8s.gcr.io/pause:3.1
k8s.gcr.io/etcd:3.3.10
k8s.gcr.io/coredns:1.3.1
我们发现,镜像地址是国外的,我们可以使用阿里云进行镜像拉取,并修改为原名:
(1)创建kubeadm.sh脚本,用于拉取镜像/打tag/删除原有镜像
#!/bin/bashset -e
KUBE_VERSION=v1.14.0
KUBE_PAUSE_VERSION=3.1ETCD_VERSION=3.3.10
CORE_DNS_VERSION=1.3.1
GCR_URL=k8s.gcr.io
ALIYUN_URL=registry.cn-hangzhou.aliyuncs.com/google_containers
images=(kube-proxy:${KUBE_VERSION}
kube-scheduler:${KUBE_VERSION}
kube-controller-manager:${KUBE_VERSION}
kube-apiserver:${KUBE_VERSION}
pause:${KUBE_PAUSE_VERSION}
etcd:${ETCD_VERSION}
coredns:${CORE_DNS_VERSION})forimageNamein${images[@]};dodocker pull $ALIYUN_URL/$imageNamedocker tag $ALIYUN_URL/$imageName$GCR_URL/$imageNamedocker rmi $ALIYUN_URL/$imageNamedone
# 执行脚本chmod +x kubeadm.sh
./kubeadm.sh
# 查看镜像docker images
(2)将这些镜像推送到自己的阿里云仓库【可选,根据自己实际的情况】
# 登录自己的阿里云仓库docker login --username=xxx registry.cn-hangzhou.aliyuncs.com
我们也编写一个脚本,并运行脚本 sh ./kubeadm-push-aliyun.sh
#!/bin/bashset -e
KUBE_VERSION=v1.14.0
KUBE_PAUSE_VERSION=3.1ETCD_VERSION=3.3.10
CORE_DNS_VERSION=1.3.1
GCR_URL=k8s.gcr.io
ALIYUN_URL=xxx
images=(kube-proxy:${KUBE_VERSION}
kube-scheduler:${KUBE_VERSION}
kube-controller-manager:${KUBE_VERSION}
kube-apiserver:${KUBE_VERSION}
pause:${KUBE_PAUSE_VERSION}
etcd:${ETCD_VERSION}
coredns:${CORE_DNS_VERSION})forimageNamein${images[@]};dodocker tag $GCR_URL/$imageName$ALIYUN_URL/$imageNamedocker push $ALIYUN_URL/$imageNamedocker rmi $ALIYUN_URL/$imageNamedone
6、kube init初始化master(主节点)
(1)kube init流程(了解)
01-进行一系列检查,以确定这台机器可以部署kubernetes
02-生成kubernetes对外提供服务所需要的各种证书可对应目录
/etc/kubernetes/pki/*
03-为其他组件生成访问kube-ApiServer所需的配置文件
ls /etc/kubernetes/
admin.conf controller-manager.conf kubelet.conf scheduler.conf
04-为 Master组件生成Pod配置文件。
ls /etc/kubernetes/manifests/*.yaml
kube-apiserver.yaml
kube-controller-manager.yaml
kube-scheduler.yaml
05-生成etcd的Pod YAML文件。
ls /etc/kubernetes/manifests/*.yaml
kube-apiserver.yaml
kube-controller-manager.yaml
kube-scheduler.yaml
etcd.yaml
06-一旦这些 YAML 文件出现在被 kubelet 监视的/etc/kubernetes/manifests/目录下,kubelet就会自动创建这些yaml文件定义的pod,即master组件的容器。master容器启动后,kubeadm会通过检查localhost:6443/healthz这个master组件的健康状态检查URL,等待master组件完全运行起来
07-为集群生成一个bootstrap token
08-将ca.crt等 Master节点的重要信息,通过ConfigMap的方式保存在etcd中,工后续部署node节点使用
09-最后一步是安装默认插件,kubernetes默认kube-proxy和DNS两个插件是必须安装的
(2)初始化master节点
官网:https://kubernetes.io/docs/reference/setup-tools/kubeadm/kubeadm/
# kubernetes-version:版本# apiserver-advertise-address:主节点ip;# pod-network-cidr:pod的ip,可以不指定,没什么影响
kubeadm init --kubernetes-version=1.14.0 --apiserver-advertise-address=192.168.56.100 --pod-network-cidr=10.244.0.0/16
# 注意【若要重新初始化集群状态:kubeadm reset,然后再进行上述操作】
执行完成后,下面的日志我们要保存下来: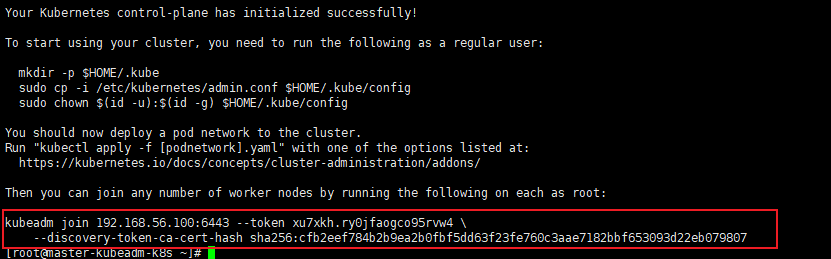
# 日志中的这三条命令需要在主节点执行一下mkdir -p $HOME/.kube
sudocp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudochown$(id -u):$(id -g)$HOME/.kube/config
(3)查看集群信息、pod运行情况
# 查看集群信息[root@master-kubeadm-k8s ~]# kubectl cluster-info
Kubernetes master is running at https://192.168.56.100:6443
KubeDNS is running at https://192.168.56.100:6443/api/v1/namespaces/kube-system/services/kube-dns:dns/proxy
To further debug and diagnose cluster problems, use 'kubectl cluster-info dump'.# 运行在主节点的组件情况,我们看到有的在Running,有的正在准备[root@master-kubeadm-k8s ~]# kubectl get pods -n kube-system
NAME READY STATUS RESTARTS AGE
coredns-fb8b8dccf-jm4fj 0/1 Pending 0 6m18s
coredns-fb8b8dccf-qwlnj 0/1 Pending 0 6m18s
etcd-m 1/1 Running 0 5m36s
kube-apiserver-m 1/1 Running 0 5m23s
kube-controller-manager-m 1/1 Running 0 5m28s
kube-proxy-mjmp9 1/1 Running 0 6m18s
kube-scheduler-m 1/1 Running 0 5m20s
我们发现coredns没有启动,需要安装网络插件。
# 健康检查[root@master-kubeadm-k8s ~]# curl -k https://localhost:6443/healthz
ok
一定确保全部Running状态,再安装网络插件!(除了前两个)
(4)部署calico网络插件
选择网络插件:https://kubernetes.io/docs/concepts/cluster-administration/addons/
calico网络插件:https://docs.projectcalico.org/v3.9/getting-started/kubernetes/
# 在k8s中安装calico
kubectl apply -f https://docs.projectcalico.org/v3.9/manifests/calico.yaml
# 确认一下calico是否安装成功
kubectl get pods --all-namespaces -w
多等一会,我们发现,所有的pod都是Running状态了。
注意:calico中包含很多images,此处我们可以先下载下来,避免以后部署pod很慢:
docker pull calico/cni:v3.9.3
docker pull calico/pod2daemon-flexvol:v3.9.3
docker pull calico/node:v3.9.3
docker pull calico/kube-controllers:v3.9.3
7、worker节点加入到主节点(worker节点)
(1)在woker01和worker02上执行上述命令
记得保存初始化master节点的最后打印信息【注意这边大家要自己的,下面我的只是一个参考】
# 在worker1和worker2都执行
kubeadm join192.168.56.100:6443 --token xu7xkh.ry0jfaogco95rvw4 \
--discovery-token-ca-cert-hash sha256:cfb2eef784b2b9ea2b0fbf5dd63f23fe760c3aae7182bbf653093d22eb079807
需要等一段时间,等worker节点加入到主节点。
(2)在master节点上检查集群信息
[root@m ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
m Ready master 15h v1.14.0
w1 Ready <none> 7m5s v1.14.0
w2 Ready <none> 6m55s v1.14.0
(3)踩坑kubeadm join 卡住
k8s从节点加入主节点[preflight] Running pre-flight checks卡住(已解决)
三、体验Pod
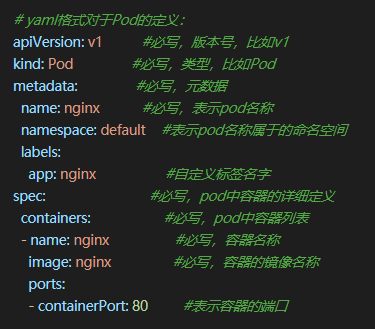
1、定义pod_nginx_rs.yaml
apiVersion: apps/v1
kind: ReplicaSet
metadata:
name: nginx
labels:
tier: frontend
spec:
replicas: 3
selector:
matchLabels:
tier: frontend
template:
metadata:
name: nginx
labels:
tier: frontend
spec:
containers:
- name: nginx
image: nginx
ports:
- containerPort: 80
2、创建pod
# 根据pod_nginx_rs.yml文件创建pod
kubectl apply -f pod_nginx_rs.yaml
# 查看pod[root@m ~]# kubectl get pods
NAME READY STATUS RESTARTS AGE
nginx-5hcwk 1/1 Running 0 98s
nginx-c5zd9 1/1 Running 0 98s
nginx-w8kg6 1/1 Running 0 98s
[root@m ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-5hcwk 1/1 Running 0 85s 192.168.190.65 w1 <none><none>
nginx-c5zd9 1/1 Running 0 85s 192.168.80.193 w2 <none><none>
nginx-w8kg6 1/1 Running 0 85s 192.168.80.194 w2 <none><none>
kubectl describe pod nginx
生成三个虚拟IP,访问这三个IP就可以访问nginx了。
# 感受通过rs将pod扩容# 扩容5个
kubectl scale rs nginx --replicas=5[root@m ~]# kubectl get pods -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
nginx-5hcwk 1/1 Running 0 6m15s 192.168.190.65 w1 <none><none>
nginx-c5zd9 1/1 Running 0 6m15s 192.168.80.193 w2 <none><none>
nginx-vnkq8 1/1 Running 0 17s 192.168.80.195 w2 <none><none>
nginx-w8kg6 1/1 Running 0 6m15s 192.168.80.194 w2 <none><none>
nginx-wcmrp 1/1 Running 0 17s 192.168.190.66 w1 <none><none># 删除pod
kubectl delete -f pod_nginx_rs.yaml
版权归原作者 秃了也弱了。 所有, 如有侵权,请联系我们删除。