
Task1:了解Deepfake & 初探baseline
Part1 Deepfake是什么?
Deepfake 是一种利用人工智能(AI)和机器学习技术(特别是生成对抗网络,即 GANs)创建的合成媒体,其中一个人的面部特征或声音被替换为另一个人的。这种技术可以生成高度逼真的视频、图像和音频,使其看起来像是某个人在说话或做某些事情,尽管这些实际上从未发生过。
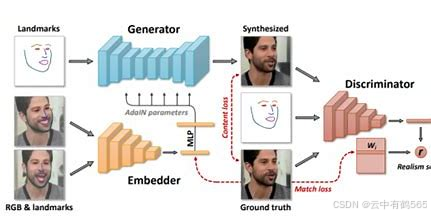
这项技术有广泛的应用,如在娱乐行业中用于电影和电视制作,复活已故演员或减少昂贵的特效成本;在教育领域中用于创建逼真的虚拟角色或历史人物;在艺术创作中,为艺术家和内容创作者提供新的表达方式。
然而,Deepfake 技术也带来了负面影响。它可能被用于传播假新闻和误导信息,对个人和社会造成严重影响;可能侵害隐私与安全,被用于制造假冒身份进行欺诈或其他非法活动;还可能引发伦理问题,未经同意使用他人的图像或声音进行合成操作。
为了应对 Deepfake 的负面影响,研究人员和科技公司正在开发检测技术,通过分析视频和音频的异常特征来识别合成内容。同时,许多国家正在制定法律法规,以规范 Deepfake 技术的使用,防止其被用于非法或不道德的目的。提高公众对 Deepfake 技术的认识和警惕性,也有助于更好地识别和应对潜在的威胁。
Part2 如何识别Deepfake?
识别 Deepfake 是一项技术挑战,但有几种方法可以帮助检测和区分合成内容与真实内容:
视频和图像分析:- 面部细节:注意面部表情不自然、不协调的部分,尤其是眼睛、嘴唇和皮肤的细微变化。- 光照和阴影:检查光照和阴影是否一致,Deepfake 通常在处理光照变化时表现不佳。- 眼睛眨动:早期的 Deepfake 通常会忽略眼睛眨动的自然频率,可以观察眨眼是否自然。
音频分析:- 语音合成错误:注意语音的断续、不连贯,或者背景噪音的突然变化。- 嘴唇同步:检查嘴唇动作是否与语音完全同步,Deepfake 在这一点上往往有漏洞。
Part3 Baseline的关键步骤
使用深度学习模型(如 ResNet-18 )进行训练和验证时,需要按照以下步骤进行:
- 数据加载与增强:- 加载训练集和验证集数据,并使用预定义的数据增强方法(transforms),例如旋转、缩放或归一化图像数据。
- 模型定义:- 使用
timm库中的预训练 ResNet-18 模型作为基础模型。- 调整模型的最后一层全连接层,以适应具体的任务要求,比如分类问题中的类别数量。 - 损失函数与优化器:- 选择适当的损失函数,如交叉熵损失,用于衡量模型输出与真实标签之间的差异。- 选择优化器(如 Adam),用于根据损失函数的梯度调整模型的权重。
- 训练过程:- 编写训练函数,用于执行每个 epoch 的训练过程。- 在训练函数中,将模型设置为训练模式,遍历训练数据集,计算损失、更新参数,并计算训练集的准确率。
- 验证过程:- 编写验证函数,用于评估模型在验证集上的性能。- 在验证函数中,将模型设置为评估模式,遍历验证集数据,计算损失并评估预测准确率。
- 性能评估与输出:- 使用准确率(Accuracy)作为主要性能评估指标,监控模型在每个 epoch 后在验证集上的表现。- 最后,将模型用于生成预测结果,并将结果保存到 CSV 文件中,以便进一步分析或提交到竞赛平台。
通过以上步骤,可以有效地使用 ResNet-18 模型进行训练、验证和预测任务,确保模型在实际应用中取得良好的性能。
项目链接:https://www.kaggle.com/code/finlay/deepfake-ffdi-baseline/
通过修改原始项目来尝试改进模型效果是一个逐步优化的过程。
首先,可以尝试调整数据预处理方法,如更详细的数据增强(如随机裁剪、颜色扭曲等),以增加数据的多样性和模型的泛化能力。在这次项目中,我对训练集数据进行了简单的数据增强。具体来说,使用了一系列的图像转换技术来丰富数据集的多样性:
train_loader = torch.utils.data.DataLoader(
# FFDIDataset(train_label['path'].head(1000), train_label['target'].head(1000),
FFDIDataset(train_label['path'], train_label['target'],
transforms.Compose([
transforms.Resize((312, 312)),
transforms.RandomHorizontalFlip(),
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomVerticalFlip(p=0.5),
transforms.RandomRotation(degrees=30),
transforms.RandomGrayscale(p=0.1),
transforms.RandomVerticalFlip(),
transforms.CenterCrop((256, 256)),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
), batch_size=40, shuffle=True, num_workers=4, pin_memory=True
)
在此次项目中,不仅进行了数据增强,还对模型结构进行了优化。具体来说,将原本的 ResNet-18 模型添加了 SE 模块(Squeeze-and-Excitation),利用自注意力机制增强模型的特征提取能力。SE 模块通过对每个通道的特征进行加权,使得模型能够更好地捕捉到重要的特征,从而提升模型的拟合能力和整体性能。这种改进使得模型在处理复杂图像时具有更高的识别准确率和更强的泛化能力。通过结合复杂的数据增强方法和增强的模型结构,最终实现了模型性能的显著提升。
import timm
import torch
import torch.nn as nn
import torch.nn.functional as F
# 定义SE模块
class SEModule(nn.Module):
def __init__(self, channels, reduction=32):
super(SEModule, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc1 = nn.Conv2d(channels, channels // reduction, kernel_size=1, padding=0)
self.fc2 = nn.Conv2d(channels // reduction, channels, kernel_size=1, padding=0)
def forward(self, x):
module_input = x
x = self.avg_pool(x)
x = F.relu(self.fc1(x))
x = torch.sigmoid(self.fc2(x))
return module_input * x
# 定义SE Basic Block
from timm.models.resnet import BasicBlock
class SEBasicBlock(BasicBlock):
def __init__(self, inplanes, planes, stride=1, downsample=None, reduction=32):
super(SEBasicBlock, self).__init__(inplanes, planes, stride, downsample)
self.se = SEModule(planes * self.expansion, reduction)
self.relu = nn.ReLU()
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.se(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out
# 创建带有SE模块的ResNet18模型
def se_resnet18(num_classes=2):
model = timm.create_model('resnet18', pretrained=True, num_classes=num_classes)
# 替换模型中的基本块为 SEBasicBlock
model.layer1 = nn.Sequential(
SEBasicBlock(64, 64),
SEBasicBlock(64, 64)
)
model.layer2 = nn.Sequential(
SEBasicBlock(64, 128, stride=2, downsample=model.layer2[0].downsample),
SEBasicBlock(128, 128)
)
model.layer3 = nn.Sequential(
SEBasicBlock(128, 256, stride=2, downsample=model.layer3[0].downsample),
SEBasicBlock(256, 256)
)
model.layer4 = nn.Sequential(
SEBasicBlock(256, 512, stride=2, downsample=model.layer4[0].downsample),
SEBasicBlock(512, 512)
)
return model
通过对模型进行改造,包括添加 SE 模块和改进数据预处理方法,经过两个 epoch 的训练后,模型在训练集上的准确率已经达到了 92.5%。这表明,通过引入自注意力机制和复杂的数据增强技术,模型的特征提取能力和泛化能力得到了显著提升,能够更有效地捕捉并利用重要特征,从而提升了整体性能。这些改进措施不仅增强了模型的拟合能力,还提高了其在处理复杂图像时的准确性,展示了对深度学习模型进行细致优化的重要性和有效性。
版权归原作者 云中有鹤565 所有, 如有侵权,请联系我们删除。