
🚩首先在介绍本章之前,我们有必要清楚学习技术的真正意义:我认为学习技术的真正意义是能够运用所学去处理实际问题,而不是用知识去包装自己让自己成为技术界的“纸老虎”。
老铁们,让技术有用武之地。我们要以项目为线索,逐步深入开发的各个环节,掌握常用的优化思路。提升工程编码能力和思维能力。
数据分析流程

一、项目背景及目的
1、项目背景
我们要处理的是一份电子游戏行业综合销售数据,希望通过分析电子游戏行业在全球的发展概况,产生一份综合的游戏行业报告。
2、分析目的
从市场角度: 各个地区销售额变化(折线图)的数据可视化和分析。
从平台角度: 开发游戏数量前二十(条形图)的数据可视化和分析,近些年的趋势有什么变化?
从类型角度: 探究用户最喜欢的游戏类型top10是什么,近些年的趋势有什么变化?
二、数据收集与整理
1、数据来源
所用到的vgsale.csv数据均从Kaggle平台下载:
Kaggle平台https://www.kaggle.com/datasets/gregorut/videogamesales
2、数据说明
数据集包含了从1980年到2020年来,发行的电子游戏销售数据。
文件名称说明包含特征特征对应中文名vgsale.csv
电子游戏销售数据
Rank、Name、Platform、Year、Genre、Publisher、
NA_Sales、EU_Sales、JP_Sales、Other_Sales、
Global_Sales
排名、游戏名、平台、发行年份、类型、发行商、NA销售额、EU销售额、JP销售额、其他地区销售额、总销售额
3、理解数据
数据集的每一行表示一条用户行为,由排名、游戏名、平台、发行年份、类型、发行商、NA销售额、EU销售额、JP销售额、其他地区销售额、总销售额组成,并以逗号分隔。关于数据集中每一列的详细描述如下:👇
列名称说明排名整数类型,序列化后的排名游戏名字符串,游戏名称平台字符串,该游戏发行平台名称发行年份浮点型,该游戏的发行日期类型字符串,该游戏的类型发行商字符串,该游戏的发行商名称NA销售额浮点型,小数点后有效数字为2位,该游戏北美销售额(百万)EU销售额浮点型,小数点后有效数字为2位,该游戏欧洲销售额(百万)JP销售额浮点型,小数点后有效数字为2位,该游戏日本销售额(百万)其他地区销售额浮点型,小数点后有效数字为2位,该游戏世界其他地区销售额(百万)总销售额浮点型,小数点后有效数字为2位,该游戏全球销售额(百万)
三、数据处理
1、导入数据
(1)导入模块
#1、导入模块
import pandas as pd
import numpy as np
(2)解决中文显示问题
import matplotlib as mpl
mpl.rcParams['font.sans-serif'] = ['KaiTi', 'SimHei', 'FangSong'] # 汉字字体,优先使用楷体,如果找不到楷体,则使用黑体
mpl.rcParams['font.size'] = 12 # 字体大小
mpl.rcParams['axes.unicode_minus'] = False # 正常显示负号
(3)读取源文件
#3、读取源文件
df=pd.read_csv(r"C:\Users\lis\Desktop\vgsales.csv")
//这里我使用的是本地文件夹下的csv文件
2、检查数据
(4)检查前五组数据
#4、检查前五组数据
print(df.head())
运行结果:
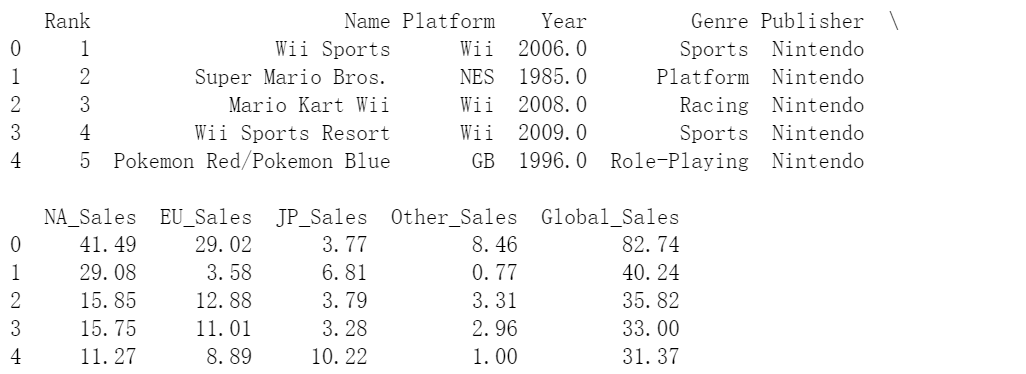
(5)一下每列的数据类型
#5、查一下每列的数据类型
print(df.dtypes)
运行结果:

(6)检测数据集的几行几列(形状)
#6、检测数据集的几行几列(形状)
print(df.shape)
运行结果:

(7)获取数据集的长度
#7、获取数据集的长度
print(len(df))
运行结果:

(8)获取数据集的基本信息
#8、获取数据集的基本信息
print(df.info())
运行结果: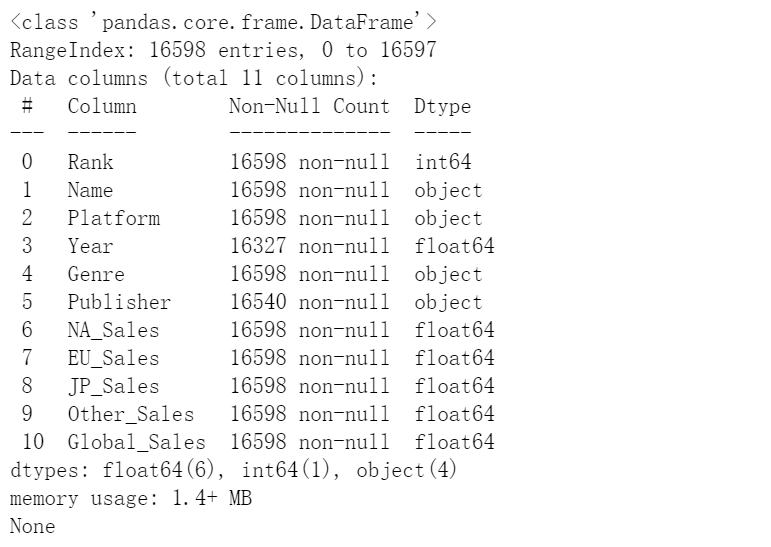
3、数据清洗
(1)去重(很明显没有重复数据,不需要去重)drop_duplicates()
(2)检测是否有缺失值
#2.1、检测是否有缺失值
df.isnull().any()
运行结果:

(3)缺失值的图形显示(安装模块——missingno)
#2.2、缺失值的图形显示(安装模块——missingno)
import missingno as mano
import matplotlib.pyplot as plt
mano.matrix(df,figsize=(16,5),labels=True)
plt.show()
运行结果:
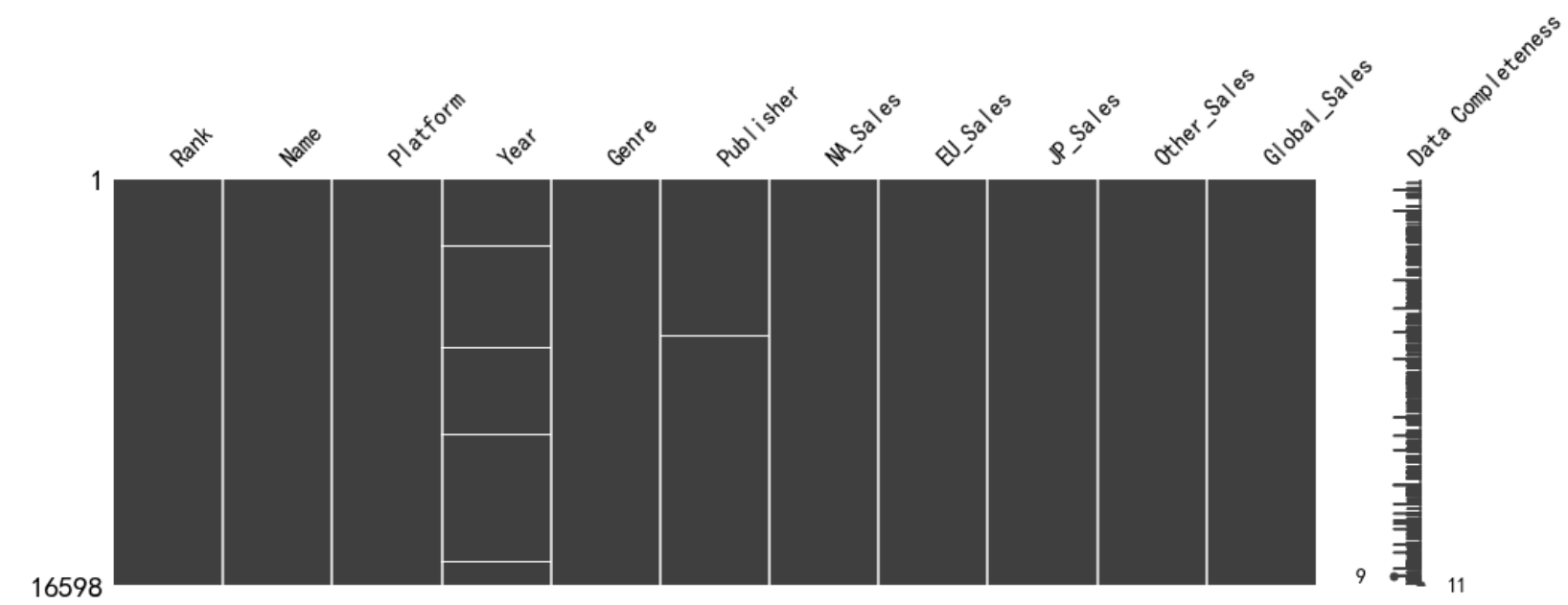
(4)缺失率的计算
#2.3、缺失率的计算
def mis_val_table(df):#自定义一个函数
#缺失值的个数
mis_val=df.isnull().sum()#sum求出缺失值个数
mis_val_per=100*mis_val/len(df)#比上数据长度得到缺失率
mis_val_table=mis_val_per.to_frame()#转换为DataFrame数据
mis_val_table.columns=['缺失率']#让列名等于‘缺失率’
mis_val_table=mis_val_table.sort_values(by='缺失率',ascending=False)#通过sort_values函数将值从大到小排序
print(mis_val_table)#最后按倒序打印出缺失率
mis_val_table(df)
#通过结果可以看出缺失率非常小,删除不影响处理结果
运行结果:

(5)删除缺失值
#2.4、删除缺失值
df.dropna(inplace=True)
df.info()
#删除之后数据由16598变为16291,删去了307行缺失数据
#到这里第2步‘缺失值的处理’,就完成了
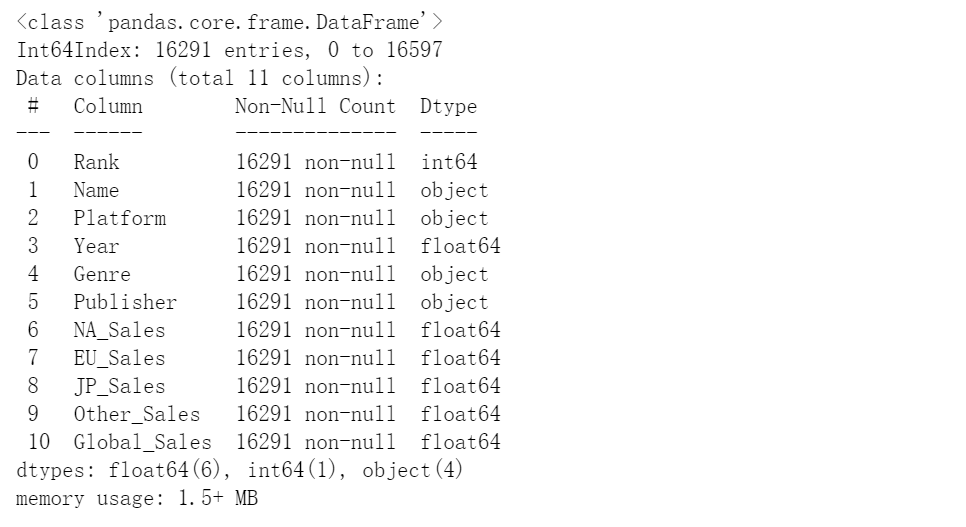
(6)转化
#3、转化
df['Year']=df['Year'].astype(int)#将年份转换为整形
df.info()
运行结果:
(7)异常数据处理
#4、异常数据处理
print(df[df['Year']>2022])#通过数据过滤
#输出结果为空,没有异常数据
运行结果:
4、保存新数据
#5、保存清洗完的数据
df.to_csv('games.csv',index=0)#index=0删去第一行unname数据,避免对后面操作造成麻烦
#到这里,‘数据清洗’操作全部完成
四、数据分析
1、求出每个平台总的销售业绩,并绘制出线性图,并做简单的数据分析
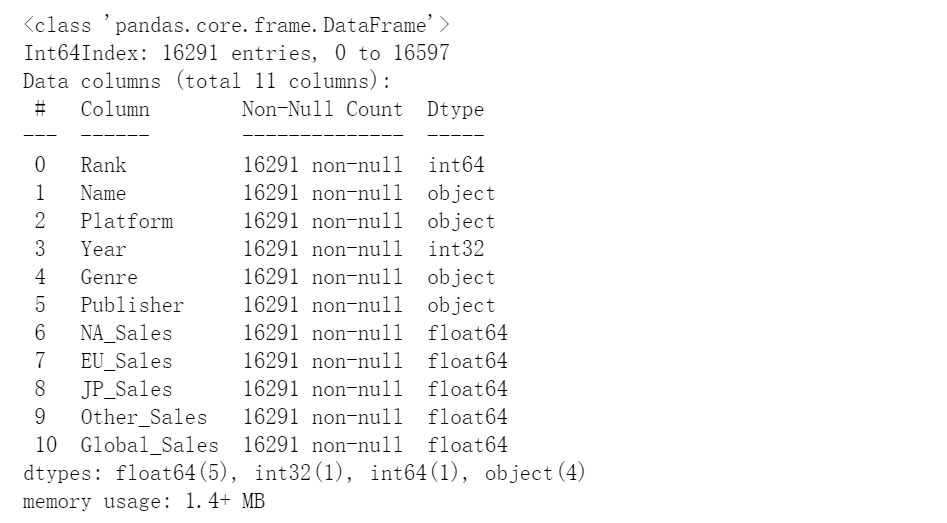
#1、求出每个平台总的销售业绩,并绘制出线性图,并做简单的数据分析
df1=df.groupby('Platform')['Global_Sales'].sum()#对Platform分组,找到全球销售额,求和
print(df1)
df1.plot(xlabel='开发平台',ylabel='销售总额')#画图
# 分析:最高PS2达到1233.46
#分析 最低PCFX 为0.03
运行结果:
2、 求出每个平台总的销售业绩,排出前5名,画柱形图
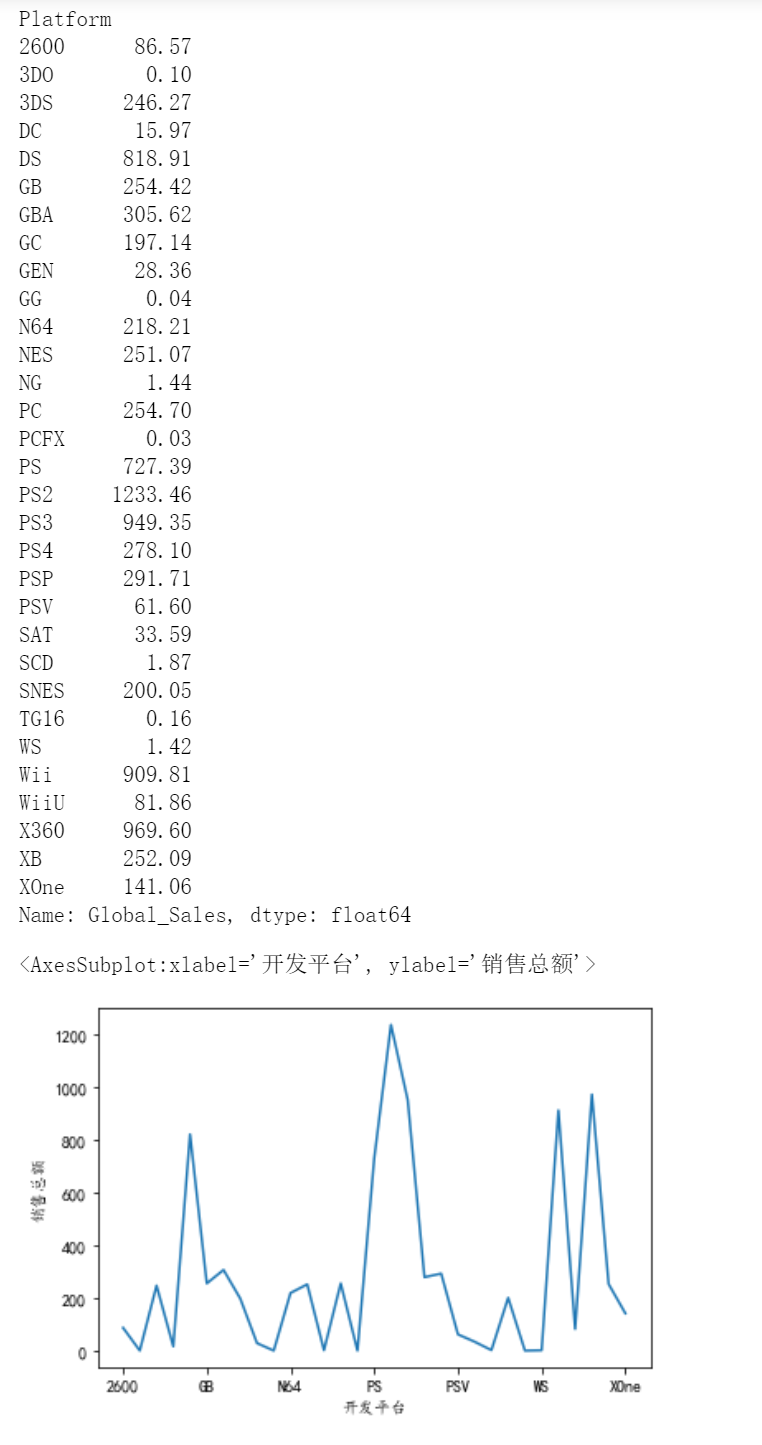
#2、 求出每个平台总的销售业绩,排出前5名,画柱形图
df2=df.groupby('Platform')['Global_Sales'].sum().sort_values(ascending=False).head(5)#对Platform分组,找到全球销售额,求和,排序,拿到前五
print(df2)
df2.plot.bar(xlabel='开发平台', ylabel='销售总额')#画图
运行结果:
3、求出每个平台在北美的平均销售业绩,线形图
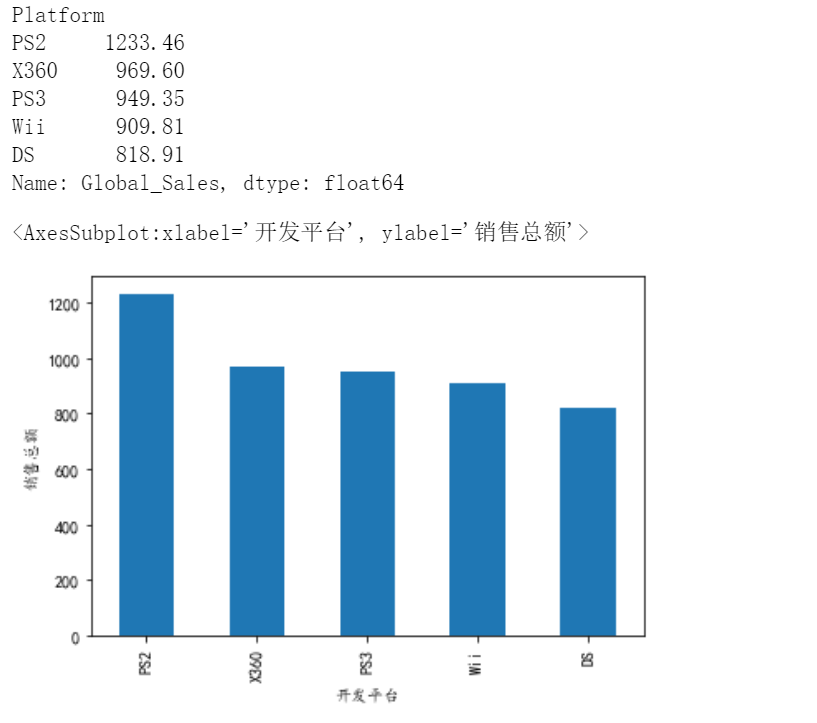
# 3、求出每个平台在北美的平均销售业绩,线形图
df3=df.groupby('Platform')['NA_Sales'].mean()#对Platform分组,找到北美销售额,求平均
print(df3)
df3.plot(xlabel='开发平台',ylabel='平均销售业绩')#画图
#最高为GB 1.171546
#最低为3DO GG NG PCFX TG16 WS 为0
运行结果:
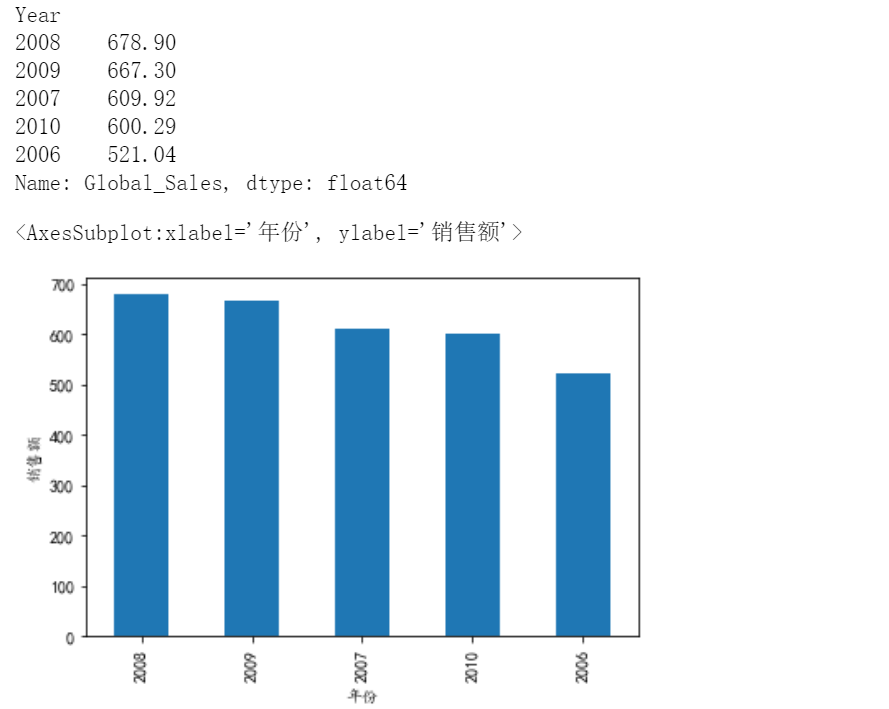
4、求出年销售额前5的年份和销售额,并画出柱状图
# 4、求出年销售额前5的年份和销售额,并画出柱状图
df4=df.groupby('Year')['Global_Sales'].sum().sort_values(ascending=False).head(5)#对Year分组,找到全球销售额,求和,排序,拿到前五
print(df4)
df4.plot.bar(xlabel='年份', ylabel='销售额')
运行结果:
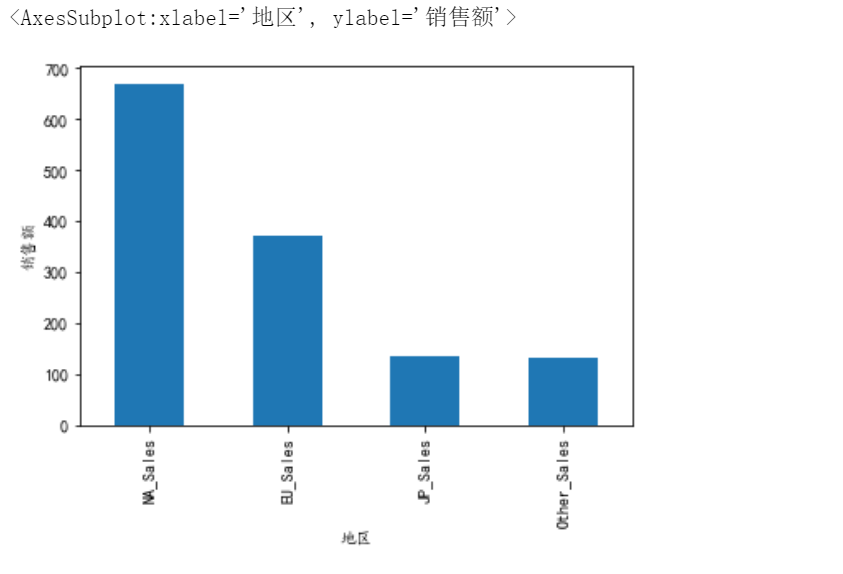
5、求出类别为Sports的游戏在北美、欧洲、日本和其他地区的销售总额
# 5、求出类别为Sports的游戏在北美、欧洲、日本和其他地区的销售总额
df5=df[df['Genre']=='Sports'][['NA_Sales','EU_Sales','JP_Sales','Other_Sales']].sum()#过滤出Sports类型数据,分别找出北美、欧洲、日本、其他
#地区求和
df5.plot.bar(xlabel='地区',ylabel='销售额')#画图
运行结果:
6、统计每个平台开发不同游戏类型的个数
# 6、统计每个平台开发不同游戏类型的个数
df6=df.groupby(["Platform",'Genre']).count()['Year']#对Platform,Genre进行分组,用count统计游戏类型个数,通过['Year']找到对应的值
df6.plot()#画图
运行结果:
7、求出年份在1998和2008年之间的每个发行商的销售业绩。
# 7、求出年份在1998和2008年之间的每个发行商的销售业绩。
df7=df[(df['Year']<=2008)&(df['Year']>=1998)].groupby('Publisher')['Global_Sales'].sum()#过滤出年份在1998-2008的数据,对Publisher分组,找到
#全球销售额,求和
df7.plot(xlabel='发行商', ylabel='销售业绩')#画图
运行结果:
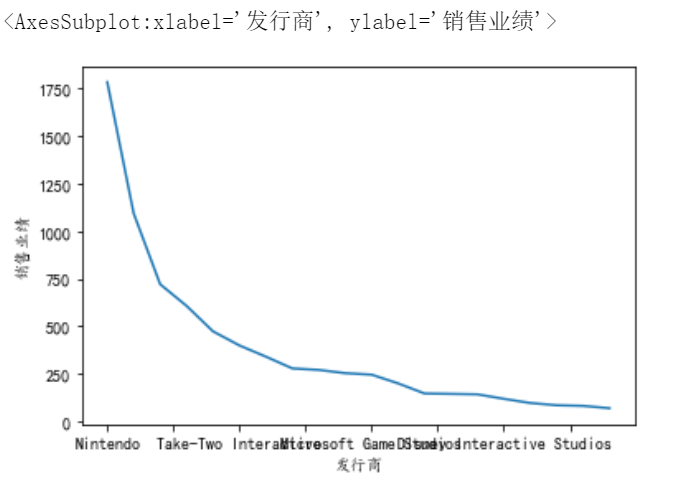
8、发行商的销售业绩排行榜(前20名),画线性图
# 8、发行商的销售业绩排行榜(前20名),画线性图
df8=df.groupby('Publisher')['Global_Sales'].sum().sort_values(ascending=False).head(20)#对Publisher分组,找到全球销售额,求和,排序,拿出前20
df8.plot(xlabel='发行商', ylabel='销售业绩')#画图
运行结果:
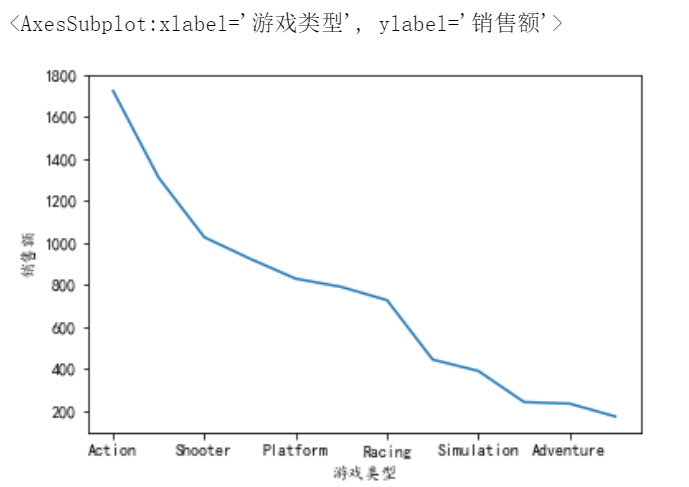
9、哪种类型的游戏最受欢迎?
# 9、哪种类型的游戏最受欢迎?
df9=df.groupby('Genre')['Global_Sales'].sum().sort_values(ascending=False).head(20)#对Genre分组,找到全球销售额,求和,排序,拿出前20
df9.plot(xlabel='游戏类型', ylabel='销售额')
#分析:通过销售额可以看出Action类型游戏最受欢迎
运行结果:
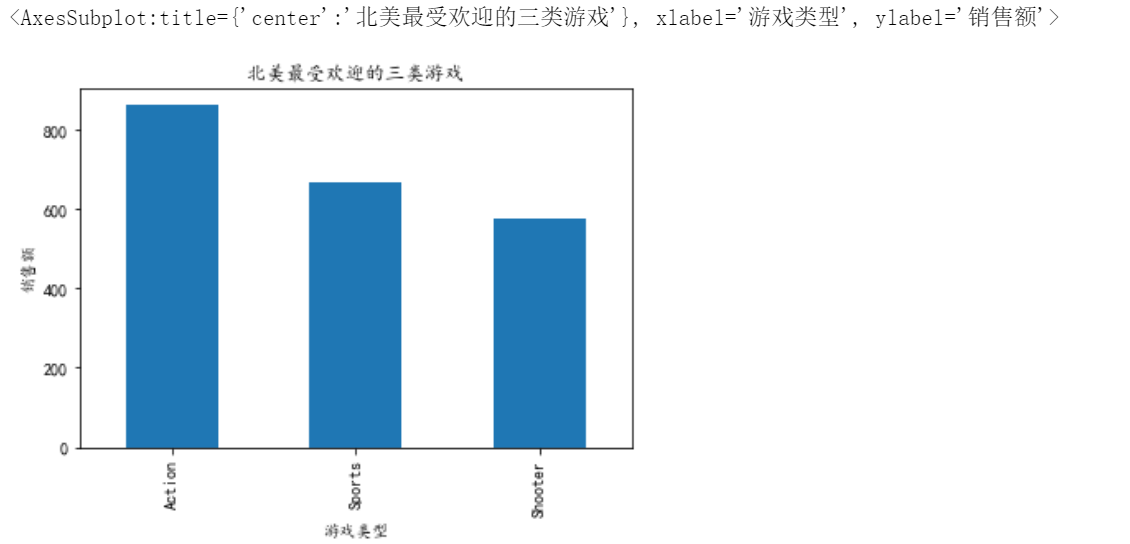
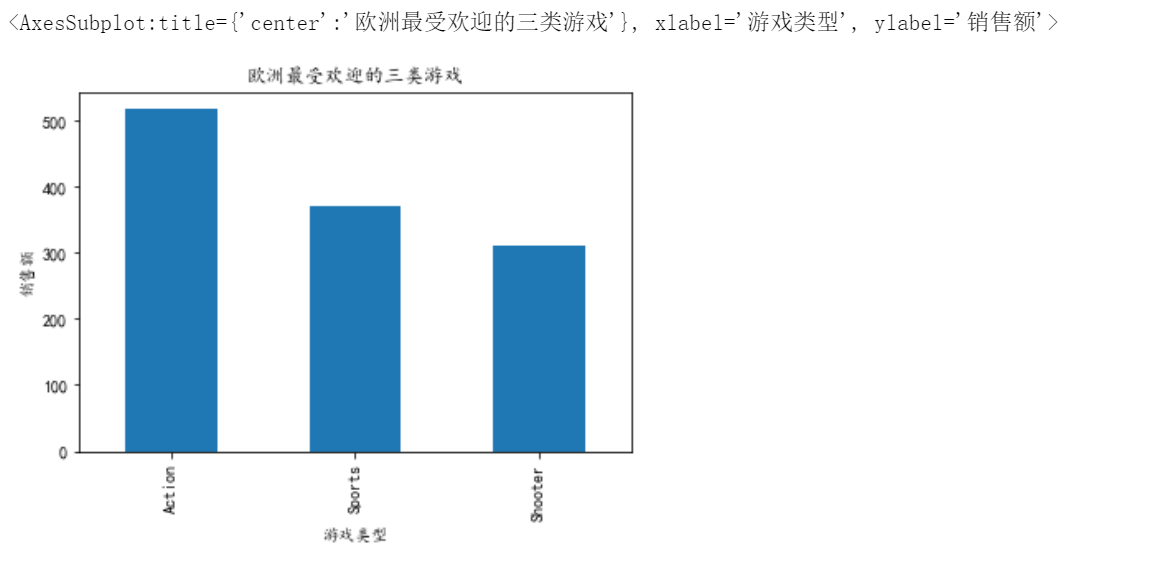
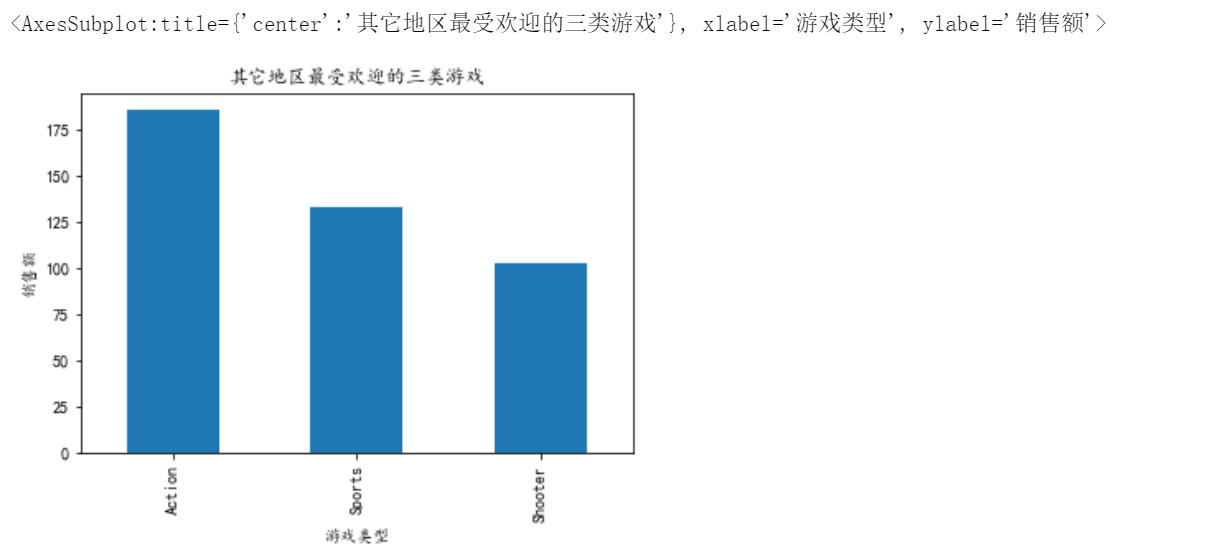
10、每个地区最受欢迎的三类游戏
# 10、每个地区最受欢迎的三类游戏
# 对Genre进行分组,分别找到北美、欧洲、日本、其他地区销售额,求和,排序,拿出前3,分别画图
df10_1=df.groupby('Genre')['NA_Sales'].sum().sort_values(ascending=False).head(3)
df10_2=df.groupby('Genre')['EU_Sales'].sum().sort_values(ascending=False).head(3)
df10_3=df.groupby('Genre')['JP_Sales'].sum().sort_values(ascending=False).head(3)
df10_4=df.groupby('Genre')['Other_Sales'].sum().sort_values(ascending=False).head(3)
df10_1.plot.bar(xlabel='游戏类型',ylabel='销售额',title='北美最受欢迎的三类游戏')
df10_2.plot.bar(xlabel='游戏类型',ylabel='销售额',title='欧洲最受欢迎的三类游戏')
df10_3.plot.bar(xlabel='游戏类型',ylabel='销售额',title='日本最受欢迎的三类游戏')
df10_4.plot.bar(xlabel='游戏类型',ylabel='销售额',title='其它地区最受欢迎的三类游戏')
运行结果:

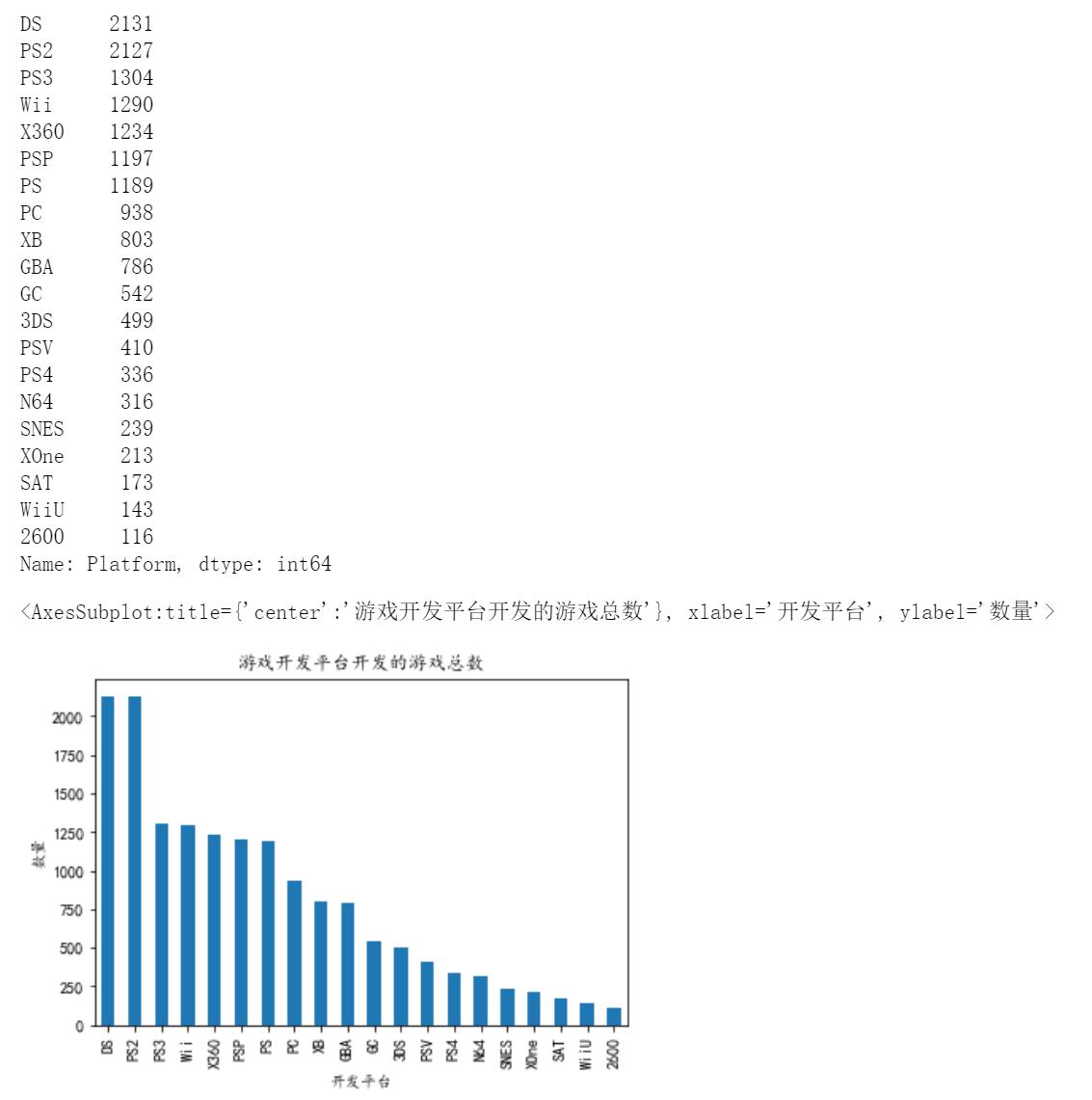
11、每个游戏开发平台开发的游戏总数(前20名)
# 11、每个游戏开发平台开发的游戏总数(前20名)
print(df['Platform'].value_counts().head(20))
df11=df['Platform'].value_counts().sort_values(ascending=False).head(20)#找到Platform数据,用value_counts()统计每个平台开发游戏的总数,排序
#拿出前20
df11.plot.bar(xlabel='开发平台',ylabel='数量',title='游戏开发平台开发的游戏总数')#画图
#分析最多:DS 达到2131
# 最低:2600仅为116
运行结果:
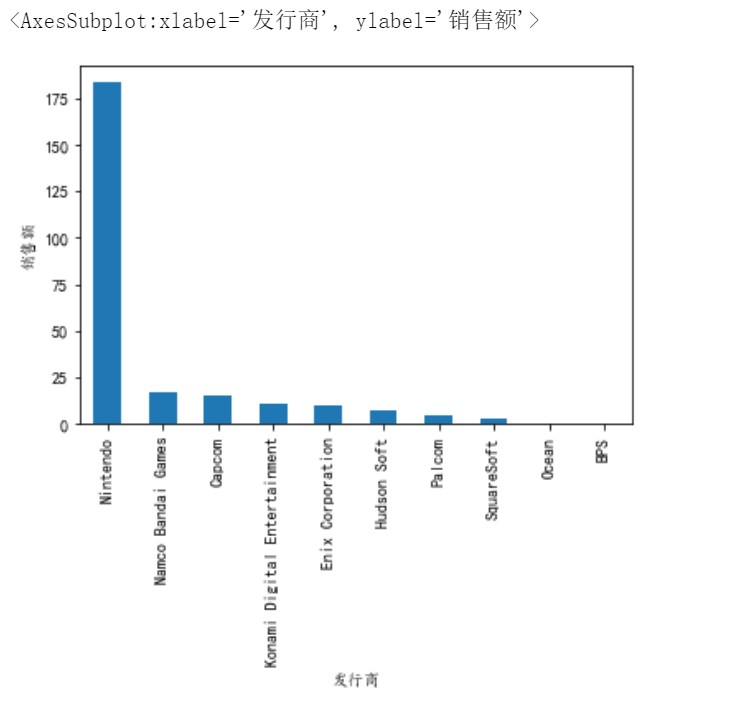
12、平台名为NES的下一步应该寻求哪十个发行商合作
#12、平台名为NES的下一步应该寻求哪十个发行商合作
dfx=df[df['Platform']=='NES'].groupby('Publisher')['Global_Sales'].sum().sort_values(ascending=False).head(10)#过滤出平台名为NES的数据,对
#Publisher分组,找到全球销售额
dfx.plot.bar(xlabel='发行商',ylabel='销售额')#画图 #求和,排序,拿出前10
运行结果:
版权归原作者 小牛要翻身 所有, 如有侵权,请联系我们删除。