
selenium是一个Web的自动化测试工具,最初是为网站自动化测试而开发的。Selenium可以直接调用浏览器,它支持所有主流的浏览器。其本质是通过驱动浏览器,完成模拟浏览器操作,比如挑战,输入,点击等。
下载与打开
下载链接:CNPM Binaries Mirror
找到与自己的谷歌浏览器版本最接近的。
然后点击下载里面win32.zip即可
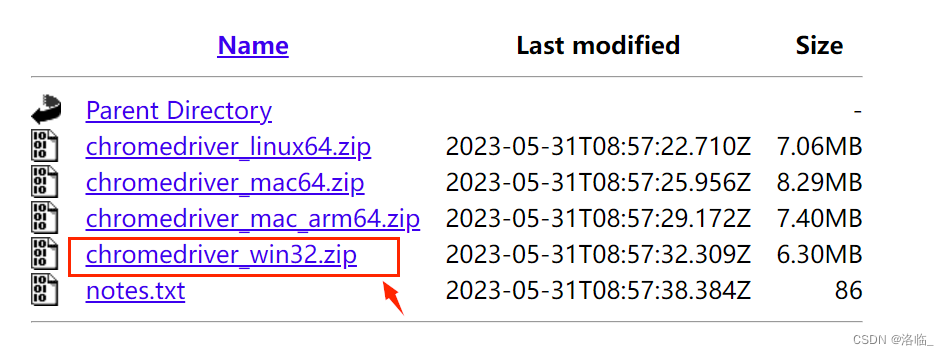 下载的压缩包解压完成后的内容放到python的安装路径。
下载的压缩包解压完成后的内容放到python的安装路径。
python安装路径:可以运行一个空的py文件,第一行的第一个路径就是你的python解释器安装路径
cmd命令提示符中:pip install selenium==3.141.0
卸载:pip uninstall 模块名
from selenium import webdriver
# 导入其中的webdriver来驱动浏览器
url = "https://www.baidu.com/"
# 启动谷歌浏览器
driver = webdriver.Chrome()
# 在地址栏输入网址
driver.get(url)
可以打开网页了。
不过可能会报错。根据报错内容查看是哪里出现了问题:
- 问题一:下载的selenium与urllib3不兼容- 解决方式:cmd中输入pip install selenium==3.141.0和pip install urllib3==1.26.2
- 问题二:谷歌浏览器与下载的chromedriver驱动版本不一致- 解决方式:右上角三个点--帮助--关于--找到自己浏览器的版本,再对应下载驱动
浏览器对象
get(url=url):地址栏--输入url地址并确认
page_source:HTML结构源码
maxmize_window:浏览器窗口最大化
quit():关闭浏览器窗口
from selenium import webdriver # 导入其中的webdriver来驱动浏览器 url = "https://www.baidu.com/" # 启动谷歌浏览器 driver = webdriver.Chrome() # 在地址栏输入网址 driver.get(url) driver.maximize_window() # 将浏览器窗口最大化 print(driver.page_source) # 打印请求头 driver.quit() # 关掉浏览器
Selenium定位元素
from selenium.webdriver.common.by import By
- find_element(By.ID, '根据标签id属性进行定位')
- find_element(By.NAME, '根据标签name属性进行定位')
- find_element(By.CLASS_NAME, '根据标签class属性进行定位')
- find_element(By.XPATH, '根据xpath语法进行定位')
- find_element(By.CSS_SELECTOR, '根据css语法进行定位')
- find_element(By.LINK_TEXT, '根据标签文本内容进行定位')
from selenium import webdriver from selenium.webdriver.common.by import By url = "https://www.baidu.com/" driver = webdriver.Chrome() driver.get(url) driver.maximize_window() driver.find_element(By.ID, "kw").send_keys("CSDN") # 在搜索框上输入CSDN driver.find_element(By.ID, 'su').click() # 点击搜索
无界面模式
from selenium import webdriver
options = webdriver.ChromeOptions()
添加无界面参数
options.add_argument('--headless')
browser = webdriver.Chrome(options=options)
import time from selenium import webdriver from selenium.webdriver.common.by import By url = "https://www.jd.com/?cu=true&utm_source=baidu-pinzhuan&utm_medium=cpc&utm_campaign=t_288551095_baidupinzhuan&utm_term=0f3d30c8dba7459bb52f2eb5eba8ac7d_0_4f2b917133dd438ab114acdc46cd0f2c" options = webdriver.ChromeOptions() # 添加无界面参数 options.add_argument('--headless') driver = webdriver.Chrome(options=options) driver.get(url) driver.execute_script( "window.scrollTo(500, document.body.scrollHeight)" ) time.sleep(2) li_list = driver.find_elements(By.XPATH, '//div[@id="J_feeds"]/ul/li') i = 0 for li in li_list: print(li.text) print('*'*30) i += 1 print(i) # *
打开新窗口和切换页面
通过excute_script()来执行js脚本的形式来打开新窗口。
window.excute_script("window.open('https://www.douban.com')")
打开新窗口后driver当前的页面依然是之前的。
如果想获取新窗口的源代码,就必须先切换过去 :
window.switch_to.window(driver.window_handles[1])
from selenium import webdriver url = 'https://www.baidu.com/' driver = webdriver.Chrome() driver.get(url) driver.maximize_window() js = 'open("https://www.douban.com/")' driver.execute_script(js) print(driver.page_source) # 获取到的是百度页面的信息 driver.quit()切换:
from selenium import webdriver url = 'https://www.baidu.com/' driver = webdriver.Chrome() driver.get(url) driver.maximize_window() js = 'open("https://www.douban.com/")' driver.execute_script(js) driver.switch_to_window(js) # print(driver.window_handles) print(driver.page_source) driver.quit()
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
class JdSpider():
def __init__(self):
self.url = 'https://search.jd.com/Search?keyword=%E6%95%B0%E7%A0%81&enc=utf-8&wq=%E6%95%B0%E7%A0%81&pvid=34b0fcf7ed434840a74c057bc97be346'
self.driver = webdriver.Chrome()
def get_url(self):
self.driver.get(self.url)
self.driver.execute_script(
"window.scrollTo(0, document.body.scrollHeight)"
)
time.sleep(2)
li_list = self.driver.find_elements(By.XPATH, '//div[@id="J_goodsList"]/ul/li')
detail_urls = []
for li in li_list:
a = li.find_element(By.XPATH, './/a')
detail_urls.append(a.get_attribute('href'))
for detail_url in detail_urls:
js = f'open("{detail_url}")'
self.driver.execute_script(js)
self.driver.switch_to_window(self.driver.window_handles[1])
time.sleep(2)
self.get_detail()
self.driver.close()
self.driver.switch_to_window(self.driver.window_handles[0])
def get_detail(self):
print('获取详情')
name = self.driver.find_element(By.CSS_SELECTOR, 'body > div:nth-child(10) > div > div.itemInfo-wrap > div.sku-name').text
print(name)
if __name__ == '__main__':
spider = JdSpider()
spider.get_url() # *
selenium-iframe
网页中嵌套了网页,先切换到iframe,再执行其他操作
切换到要处理的iframe
browaer.switch_to.frame(frame节点对象)
from selenium import webdriver from selenium.webdriver.common.by import By import infos url = 'https://douban.com/' driver = webdriver.Chrome() driver.get(url) iframe = driver.find_element(By.XPATH, '//div[@class="login"]/iframe') # print(iframe) driver.switch_to.frame(iframe) # 切进来 # 点击密码登录 driver.find_element(By.XPATH, '/html/body/div[1]/div[1]/ul[1]/li[2]').click() # 输入账号密码 driver.find_element(By.XPATH, '//*[@id="username"]').send_keys(infos.username) driver.find_element(By.XPATH, '//*[@id="password"]').send_keys(infos.username) # 点击登录 driver.find_element(By.XPATH, '/html/body/div[1]/div[2]/div[1]/div[5]/a').click()
验证码处理
数字验证码:
img = driver.find_element(By.XPATH, '复制验证码所在代码段的XPATH(右击--copy)')
img.screenshot("1.png") # 将图片截取下来
【网站:www.ttshitu.com---登录--开发文档--python--可以找到相应代码】
def base64_api(uname, pwd, img, typeid): with open(img, 'rb') as f: base64_data = base64.b64encode(f.read()) b64 = base64_data.decode() data = {"username": uname, "password": pwd, "typeid": typeid, "image": b64} result = json.loads(requests.post("http://api.ttshitu.com/predict", json=data).text) if result['success']: return result["data"]["result"] else: return result["message"] img_path = "1.jpg" result = base64_api(uname='你的账号', pwd='你的密码', img=img_path, typeid=3) print(result) # 记得导包**滑动验证码: **
button = driver.find_element(By.CSS_SELECTOR, '复制验证码所在代码的CSS路径') action = ActionChains(driver) action.click_and_hold(button).perform() # 点击且不松开 action.move_by_offset(int(result) - 30, 0) # 滑块与左边框距离30 action.release().perform()
selenium翻页操作
取到第一页数据:
from selenium import webdriver from selenium.webdriver.common.by import By url = 'https://www.maoyan.com/board/4?offset=0' driver = webdriver.Chrome() driver.get(url) driver.maximize_window() dds = driver.find_elements(By.XPATH, '//*[@id="app"]/div/div/div[1]/dl/dd') for dd in dds: print(dd.text.split('\n')) print('-'*30)翻页爬取:
from selenium import webdriver from selenium.webdriver.common.by import By url = 'https://www.maoyan.com/board/4?offset=0' option = webdriver.ChromeOptions() option.add_argument('--headless') # 加上这两句就不会弹出页面了(无头模式),,当然也可以不添加 driver = webdriver.Chrome() driver.get(url) driver.maximize_window() dds = driver.find_elements(By.XPATH, '//*[@id="app"]/div/div/div[1]/dl/dd') def get_data(): """一页的数据""" dds = driver.find_elements(By.XPATH, '//*[@id="app"]/div/div/div[1]/dl/dd') for dd in dds: print(dd.text.split('\n')) print('-' * 30) while True: get_data() try: driver.find_element(By.LINK_TEXT, '下一页').click() # 点击下一页的文本 except Exception as e: # 做异常处理,数据爬取100个后就没有下一页,会报错的 print(e) print('数据爬取完成') # 没有下一页代表完成 driver.quit() break
操作cookie
获取cookie:driver.get_cookies()
根据cookie的key获取value:value=driver.get_cookie(key)
删除所有的cookie:driver.delete_all_cookies()
删除某个cookie:driver.delete_cookie(key)
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
import infos
url = 'https://douban.com/'
driver = webdriver.Chrome()
driver.get(url)
iframe = driver.find_element(By.XPATH, '//div[@class="login"]/iframe')
# print(iframe)
driver.switch_to.frame(iframe) # 切进来
# 点击密码登录
driver.find_element(By.XPATH, '/html/body/div[1]/div[1]/ul[1]/li[2]').click()
# 输入账号密码
driver.find_element(By.XPATH, '//*[@id="username"]').send_keys(infos.username)
driver.find_element(By.XPATH, '//*[@id="password"]').send_keys(infos.password)
# 点击登录
driver.find_element(By.XPATH, '/html/body/div[1]/div[2]/div[1]/div[5]/a').click()
time.sleep(20)
cookies = driver.get_cookies()
cookies_dict = {}
for cookie in cookies:
name = cookie['name']
value = cookie['value']
cookies_dict[name] = value
url = 'https://douban.com/'
import requests
headers = {
'User-Agent': '# 将User-Agent复制过来'
}
print(requests.get(url, cookies=cookies_dict, headers=headers).text) # 获取到登陆后的数据
隐式等待和显式等待
隐式等待:指定一个时间,在这个时间内会一直处于等待状态。使用:driver.implicitly_wait
显式等待:指定在某个时间内,如果某个条件满足了,就不会在等待。使用:from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
# 隐式等待:后续的标签定位都会建立在5秒之内
# 后续的某个标签在5秒内加载出来就进行爬取,否则继续下一页
driver.implicitly_wait(5)
# 显式等待:针对某一个标签定位
WebDriverWait(driver, 10).until(
EC.presence_of_all_elements_located((By.LINK_TEXT, "地图"))
).click()
版权归原作者 洛临_ 所有, 如有侵权,请联系我们删除。