
本文用来记录windows系统上深度学习的环境搭建,目录如下
一、安装显卡驱动
首先为装有NVIDIA gpu的电脑安装显卡驱动,如果安装过了,或者想使用cpu的,可以跳过这一步。(其实这一步可以跳过,因为显卡驱动好想和深度学习环境没什么关系,保险起见还是安装上吧)
去官网下载对应的显卡驱动:官方驱动 | NVIDIA

完成下载,选择文件开始安装,直接解压在默认地址
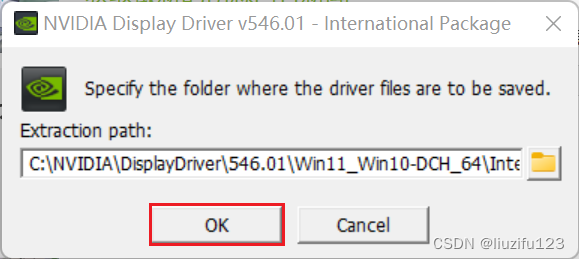
- 选择自定义安装选项,执行清洁安装(按情况选择)
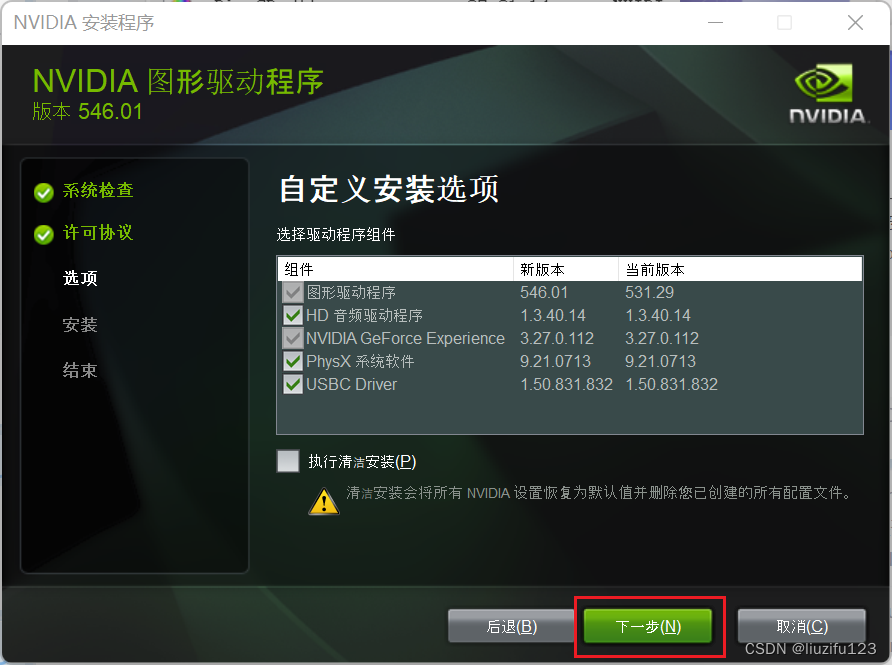
- 一直点下一步即可。
二、安装Visual Studio
可以跳过,但是很多深度学习环境需要用到,建议安装
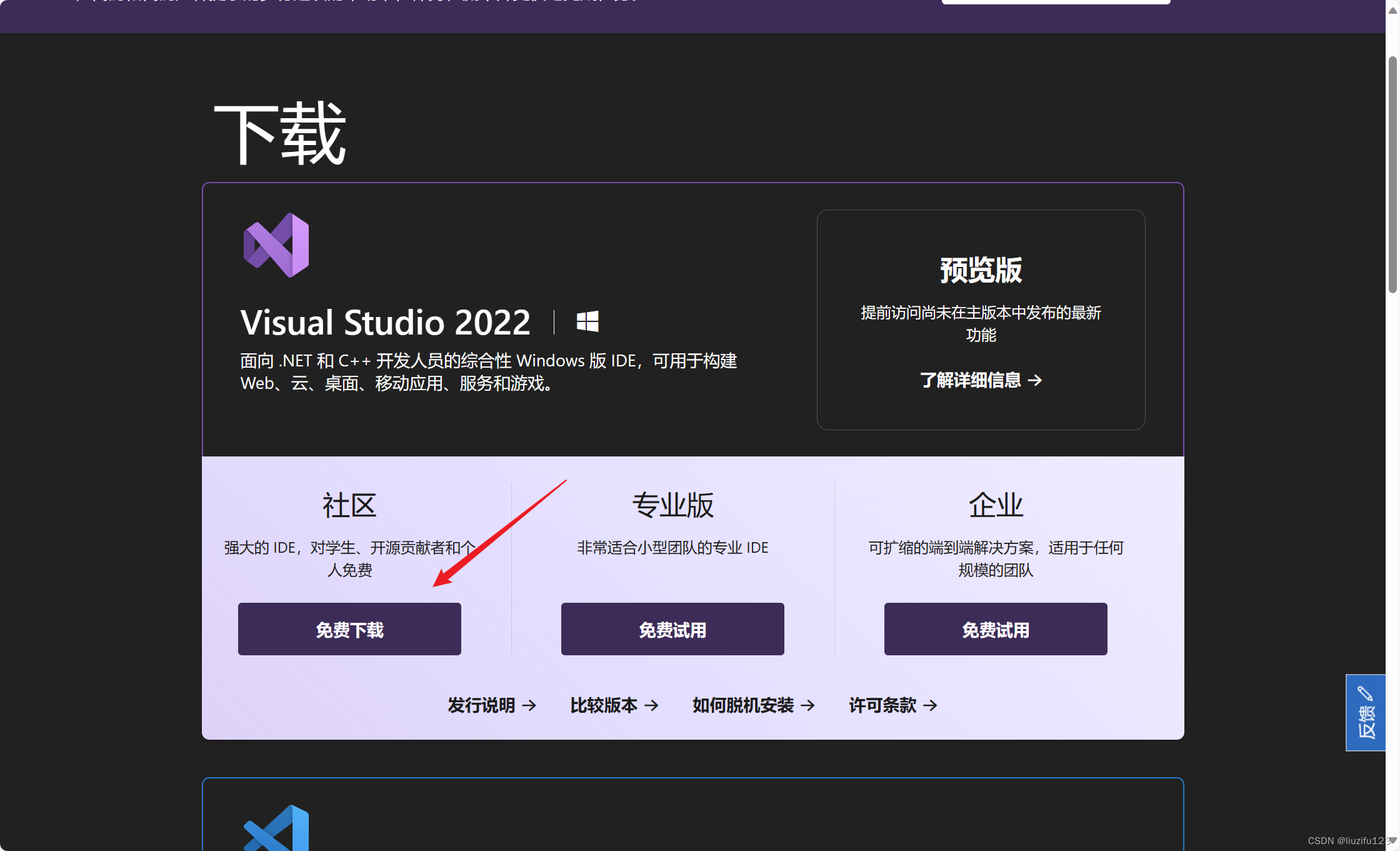
- 官网下载 Visual Studio Tools - 免费安装 Windows、Mac、Linux (microsoft.com)
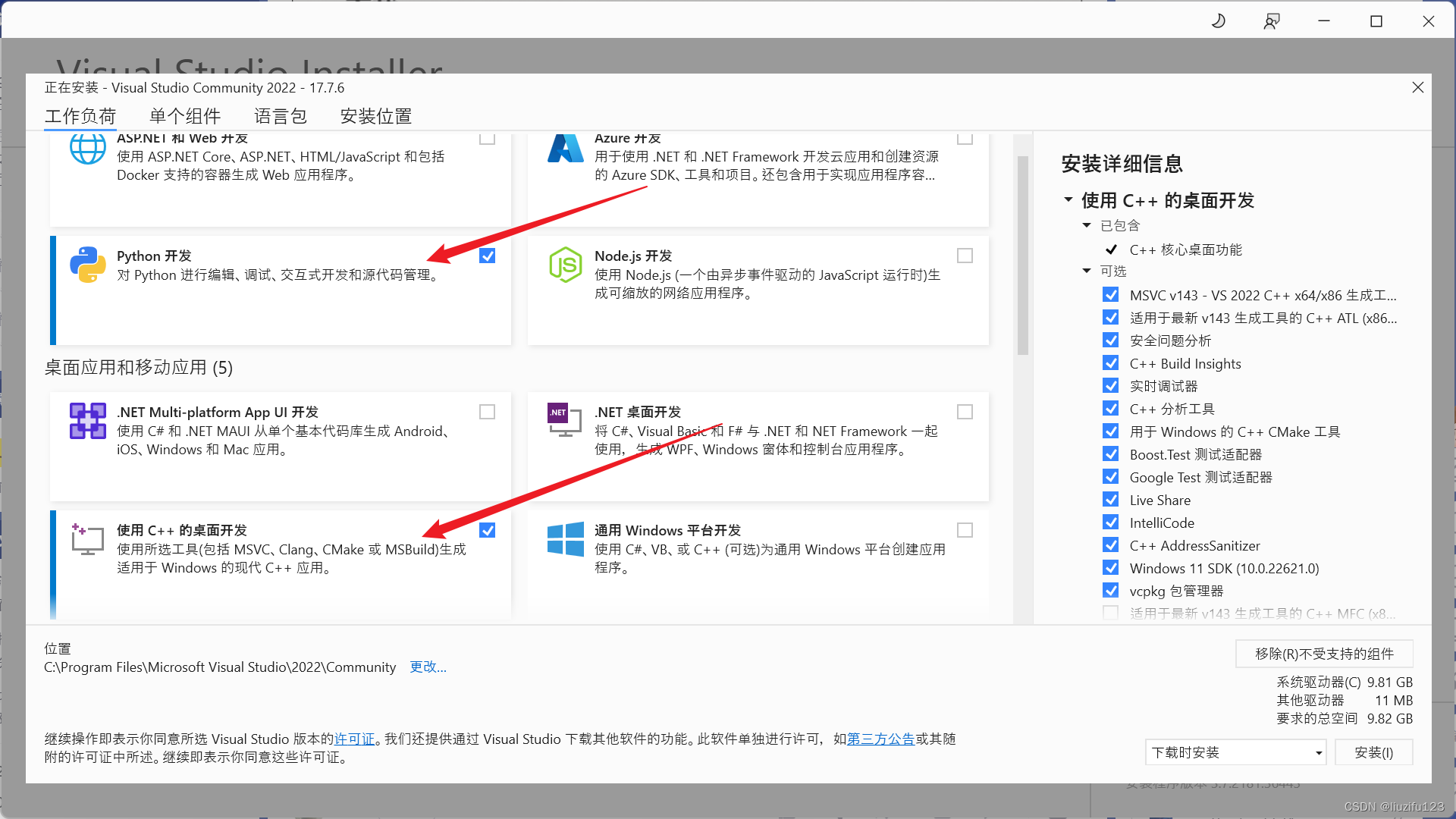
- 选择python开发和c++桌面开发,开始安装
三、cuda+cudnn安装
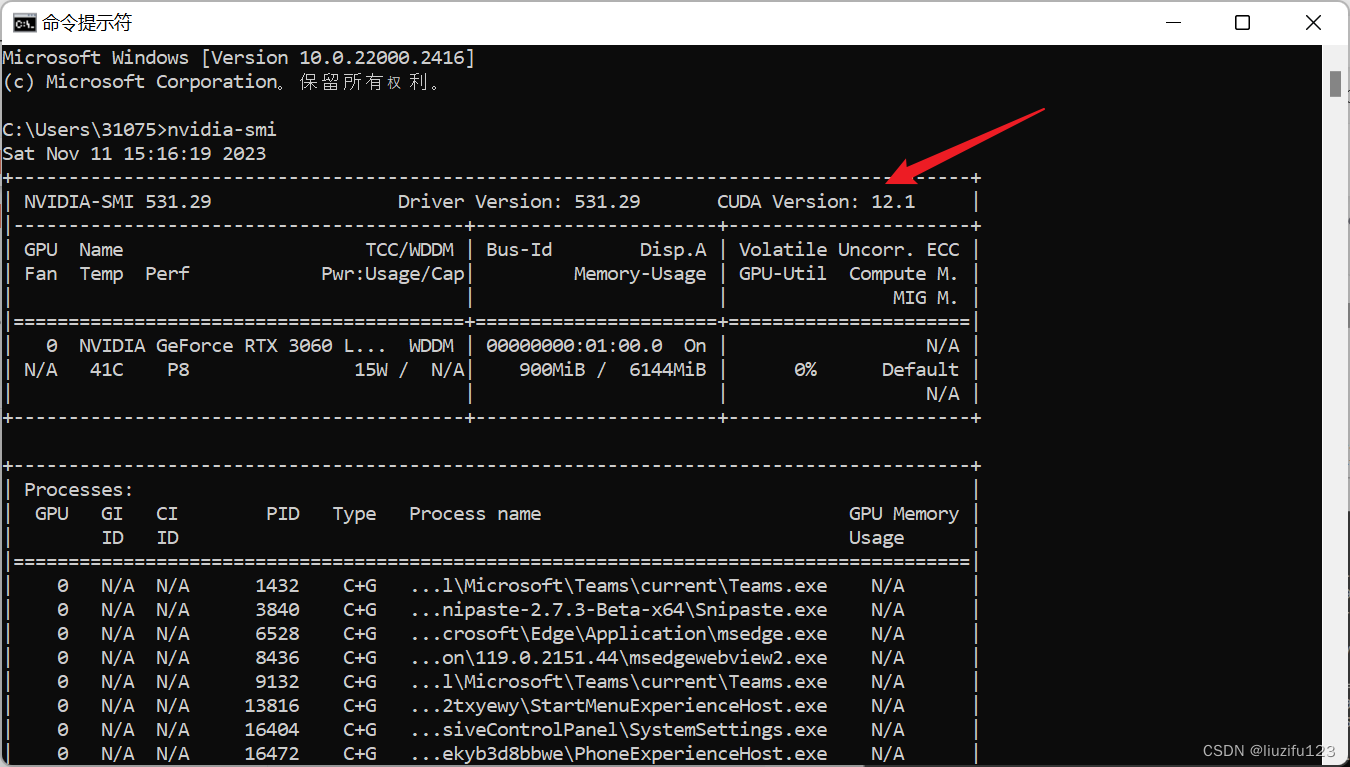
- 打开cmd,输入nvidia-smi查看GPU的CUDA版本,可以看到CUDA版本12.1,意味着只能安装小于12.1的CUDA版本。
CUDA Toolkit Archive | NVIDIA Developer2. 去网站下载适合的CUDA版本:CUDA Toolkit Archive | NVIDIA Developer
要根据两个条件选择:
- CUDA版本要小于上面的版本信息
- 先去pytorch官网Start Locally | PyTorch,看一眼自己需要的pytorch版本对应的CUDA版本
例如:pytorch1.12.0只支持CUDA10.2,11.3,11.6

- 然后去官网下载:CUDA Toolkit Archive | NVIDIA Developer,以11.6版本举例,选好系统参数,点击下载,
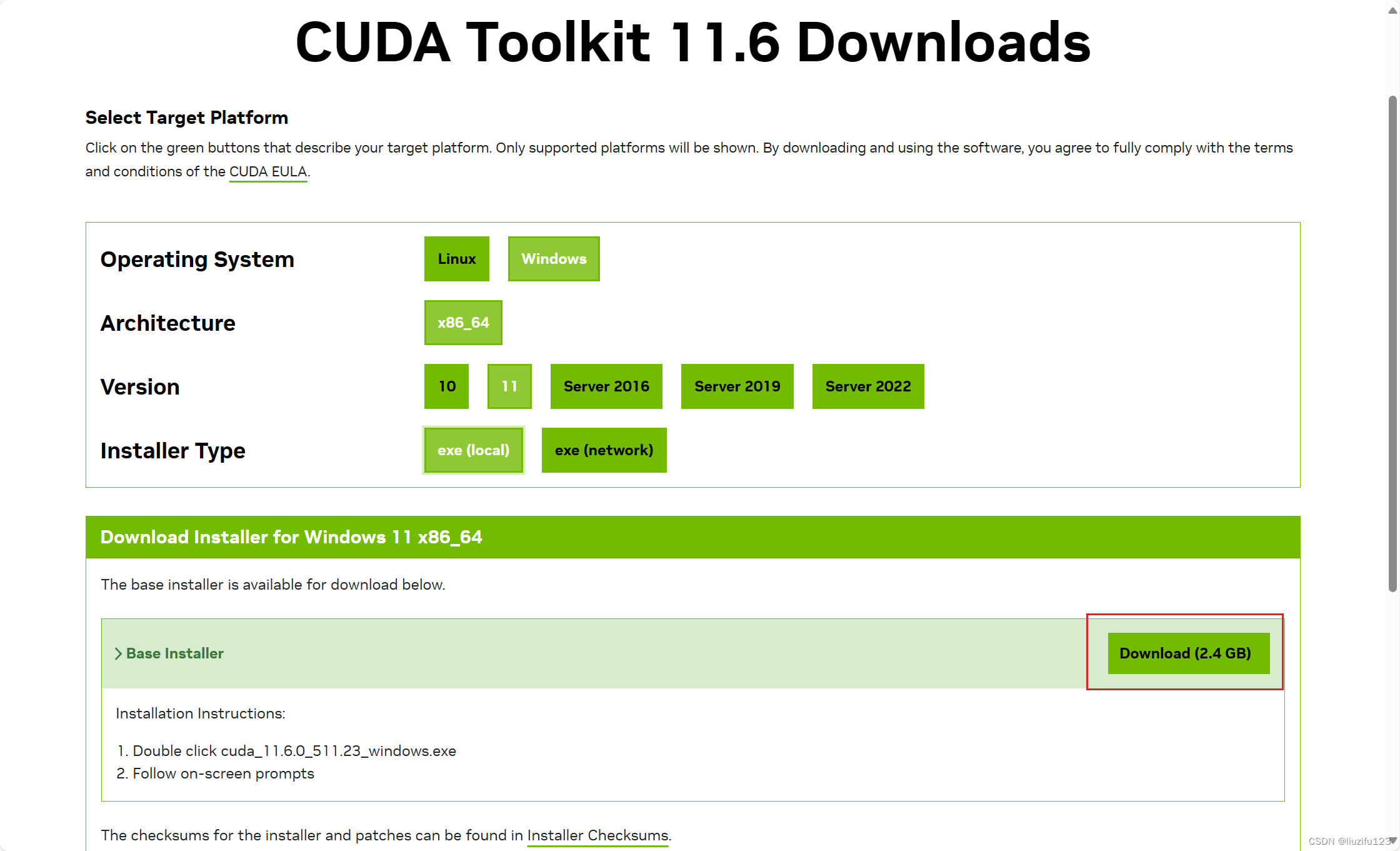
- 下载完成,直接默认解压位置

- 默认勾选即可,点下一步

- 安装cudnn
去官网下载CUDA Deep Neural Network (cuDNN) | NVIDIA Developer,需要注册一个NVIDIA账号,然后选择CUDA对应版本的cudnn即可。
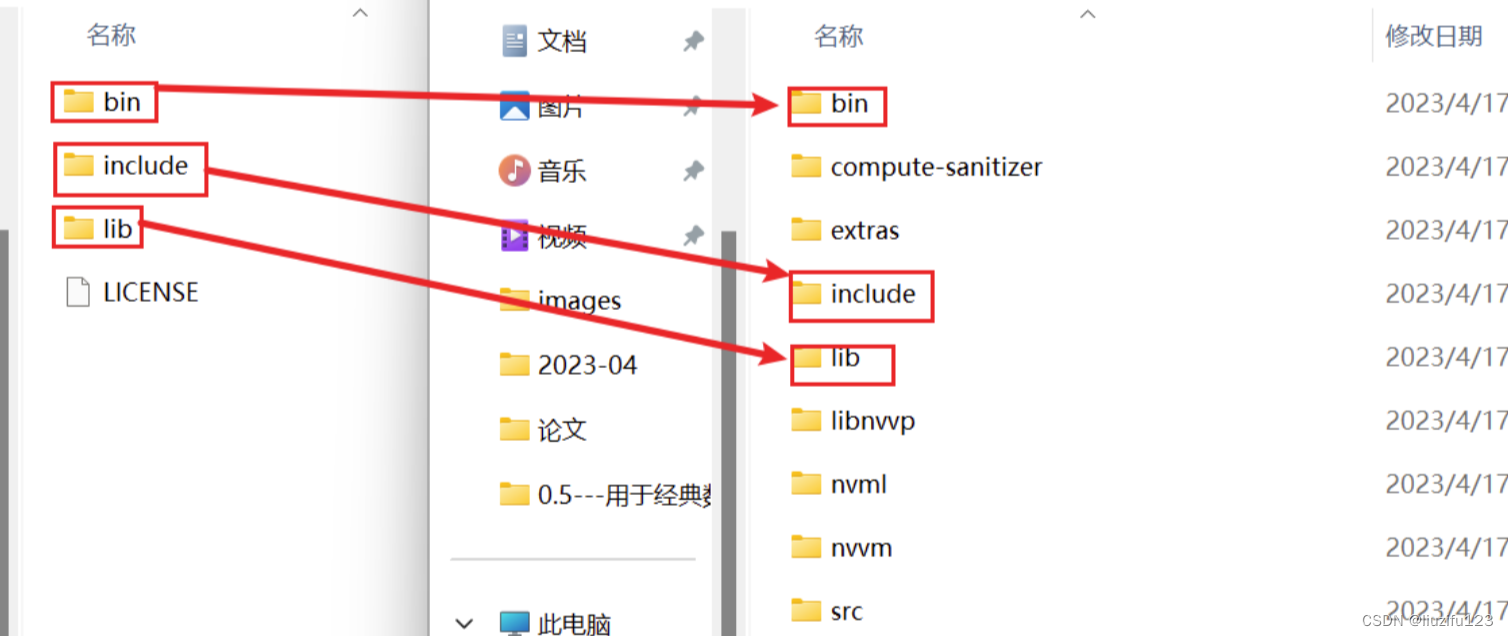
- 下载cudnn后直接将其解开压缩包,然后需要将解压后的bin,include,lib文件夹复制粘贴到cuda安装时的默认路径文件夹下
- 检查环境变量


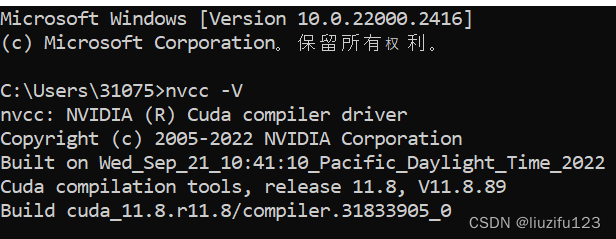
- 在cmd输入nvcc -V,显示CUDA版本即安装成功
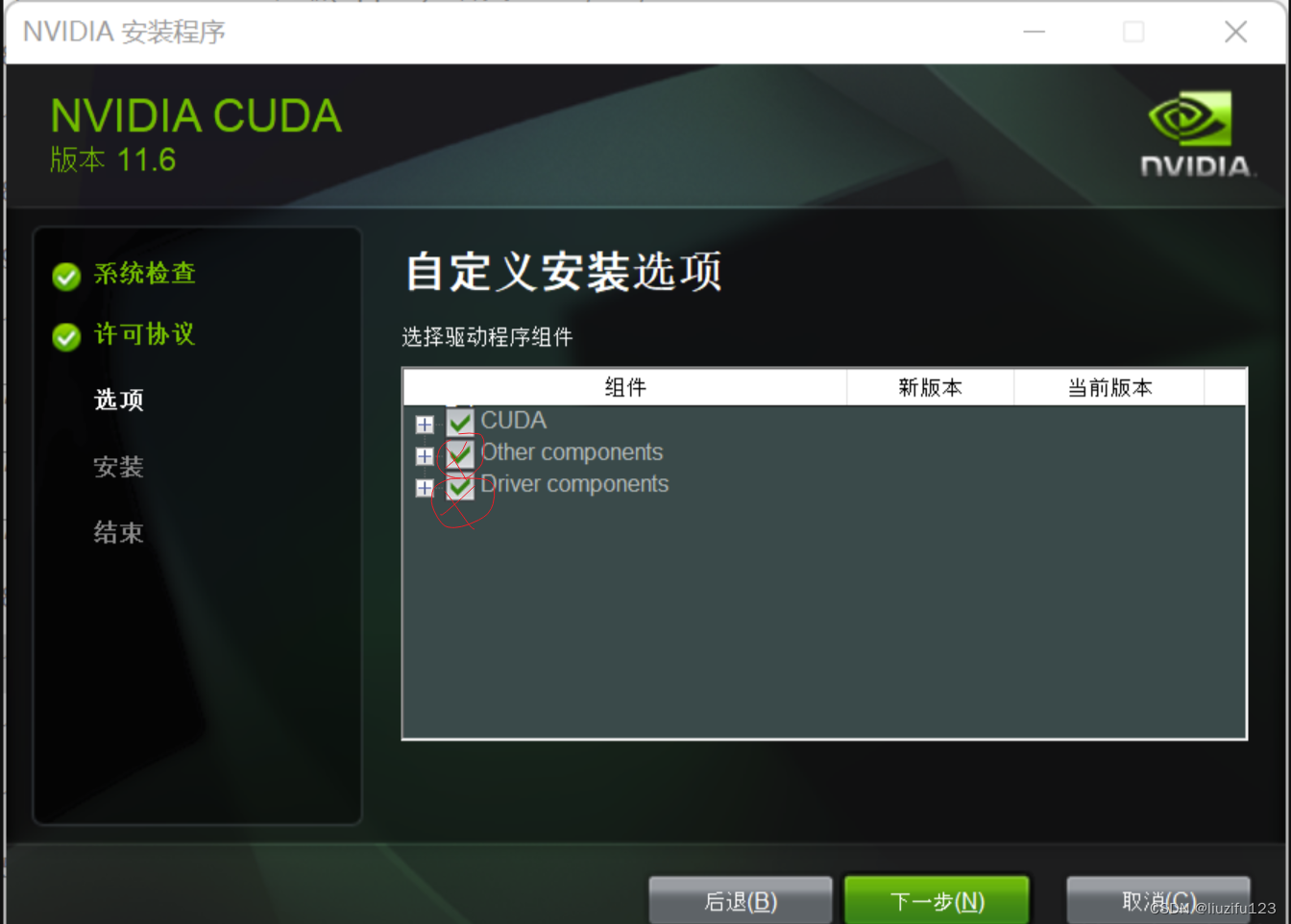
安装多个CUDA环境:
如果要安装多个CUDA环境的话,和上述步骤基本相同,其中在安装时只需要选中cuda即可
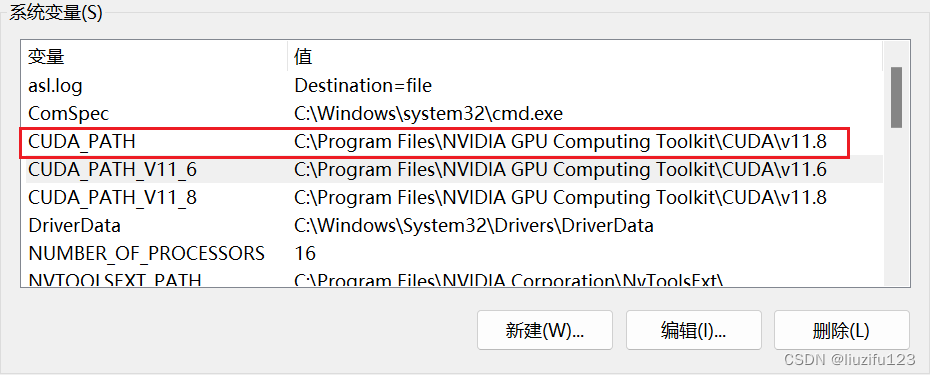
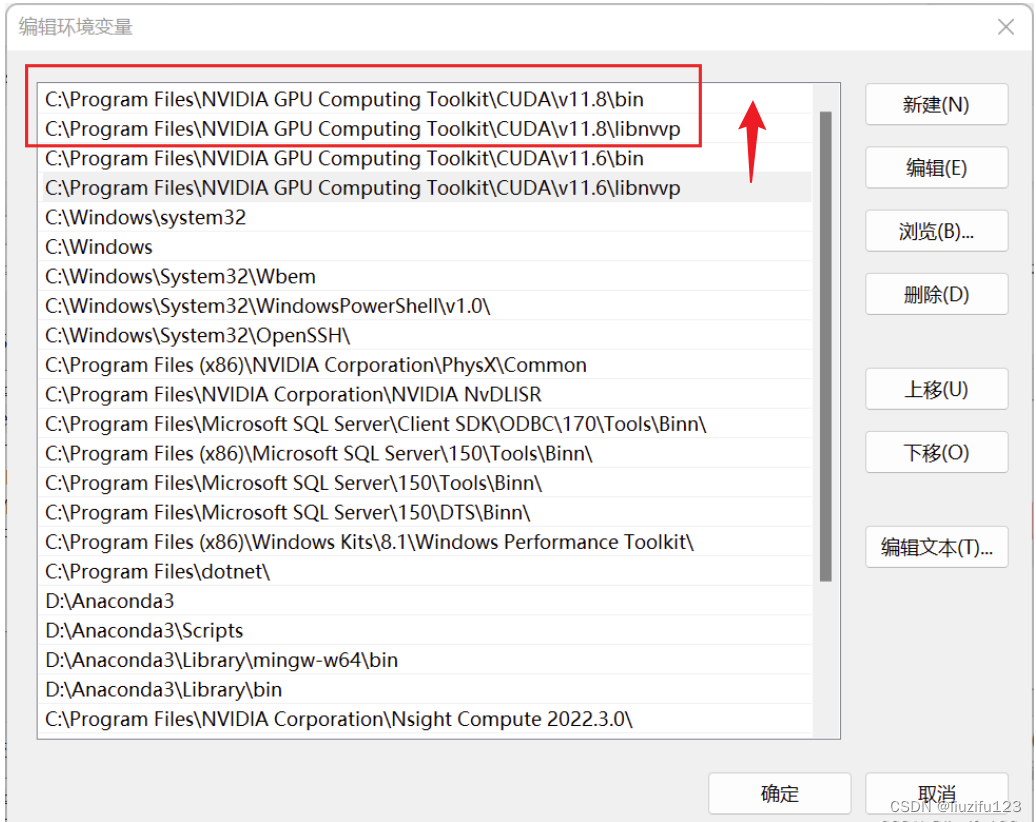
如果要在各个CUDA间进行转换,只需要修改环境变量即可。
例如:把CUDA11.6改为CUDA11.8,只需要把CUDA_PATH改为v11.8,并把Path中v11.6的路径上移到v11.8之前,然后重启电脑即可
四、anaconda安装
去官网下载安装包:Free Download | Anaconda
下载完成,进行安装,建议安装在非系统盘,以后会创建比较多的环境的话,剩下的默认安装即可

五、pycharm安装
官网下载安装包:PyCharm: the Python IDE for Professional Developers by JetBrains,可申请教育账号免费下载专业版,如果没有,下载社区版即可
自行安装即可
六、pytorch安装,及在pycharm中选择conda环境
1.首先创建一个conda环境,打开Anaconda prompt,输入:conda create --name yourname python=3.10 -y
删除环境输入: conda remove -n env_name --all
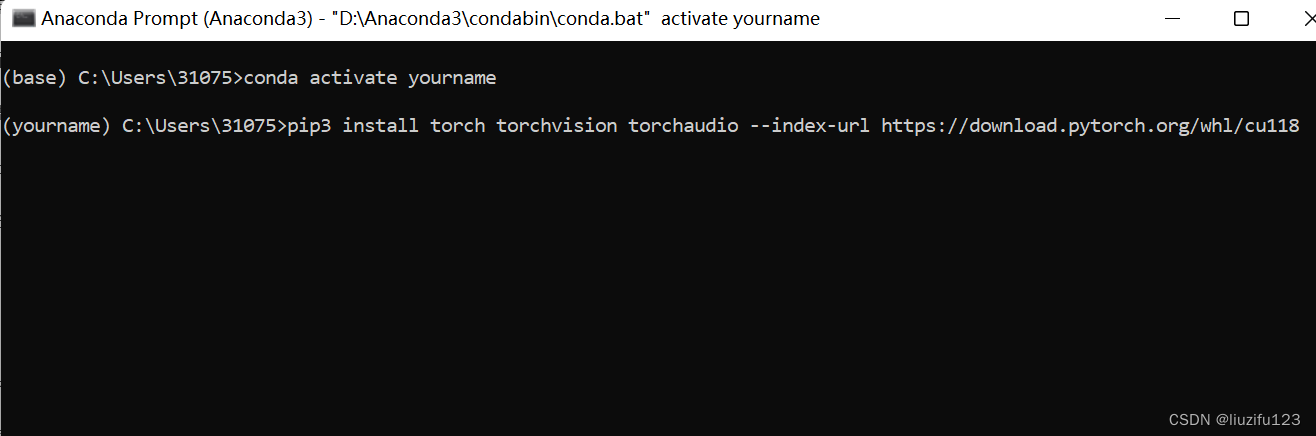
- 输入conda activate yourname 激活环境

- 去官网找自己需要的pytorch版本:Start Locally | PyTorch 。选择电脑参数,并复制pip install命令,也可以去找之前的版本。

- 将复制的pip install命令,粘贴在Anaconda prompt中,等待安装即可
4.打开anaconda prompt命令行测试代码
python
import torch
print(torch.__version__)
print(torch.cuda.is_available())
5.打开pycharm,选择添加新的解释器→添加本地解释器→conda环境→/yourname/python.exe (这里不同版本的pycharm可能有点不一样,只要能识别就行)
x

至此,环境搭建结束。。。。
安装了yolov8的,可以试着训练一下yolov8
from ultralytics import YOLO
if __name__ == '__main__':
# Load a model
model = YOLO(r'\ultralytics\detection\yolov8n\yolov8n.yaml') # 不使用预训练权重训练
# model = YOLO(r'yolov8p.yaml').load("yolov8n.pt") # 使用预训练权重训练
# Trainparameters ----------------------------------------------------------------------------------------------
model.train(
data=r'\ultralytics\detection\dataset\appledata.yaml',
epochs= 30 , # (int) number of epochs to train for
patience= 50 , # (int) epochs to wait for no observable improvement for early stopping of training
batch= 8 , # (int) number of images per batch (-1 for AutoBatch)
imgsz= 320 , # (int) size of input images as integer or w,h
save= True , # (bool) save train checkpoints and predict results
save_period= -1, # (int) Save checkpoint every x epochs (disabled if < 1)
cache= False , # (bool) True/ram, disk or False. Use cache for data loading
device= 0 , # (int | str | list, optional) device to run on, i.e. cuda device=0 or device=0,1,2,3 or device=cpu
workers= 16 , # (int) number of worker threads for data loading (per RANK if DDP)
project= 'result', # (str, optional) project name
name= 'yolov8n' ,# (str, optional) experiment name, results saved to 'project/name' directory
exist_ok= False , # (bool) whether to overwrite existing experiment
pretrained= False , # (bool | str) whether to use a pretrained model (bool) or a model to load weights from (str)
optimizer= 'SGD', # (str) optimizer to use, choices=[SGD, Adam, Adamax, AdamW, NAdam, RAdam, RMSProp, auto]
verbose= True ,# (bool) whether to print verbose output
seed= 0 , # (int) random seed for reproducibility
deterministic= True , # (bool) whether to enable deterministic mode
single_cls= True , # (bool) train multi-class data as single-class
rect= False ,# (bool) rectangular training if mode='train' or rectangular validation if mode='val'
cos_lr= False , # (bool) use cosine learning rate scheduler
close_mosaic= 0, # (int) disable mosaic augmentation for final epochs
resume= False , # (bool) resume training from last checkpoint
amp= False, # (bool) Automatic Mixed Precision (AMP) training, choices=[True, False], True runs AMP check
fraction= 1.0 , # (float) dataset fraction to train on (default is 1.0, all images in train set)
profile= False, # (bool) profile ONNX and TensorRT speeds during training for loggers
# Segmentation
overlap_mask= True , # (bool) masks should overlap during training (segment train only)
mask_ratio= 4, # (int) mask downsample ratio (segment train only)
# Classification
dropout= 0.0, # (float) use dropout regularization (classify train only)
# Hyperparameters ----------------------------------------------------------------------------------------------
lr0=0.01, # (float) initial learning rate (i.e. SGD=1E-2, Adam=1E-3)
lrf=0.01, # (float) final learning rate (lr0 * lrf)
momentum=0.937, # (float) SGD momentum/Adam beta1
weight_decay=0.0005, # (float) optimizer weight decay 5e-4
warmup_epochs=3.0, # (float) warmup epochs (fractions ok)
warmup_momentum=0.8, # (float) warmup initial momentum
warmup_bias_lr=0.1, # (float) warmup initial bias lr
box=7.5, # (float) box loss gain
cls=0.5, # (float) cls loss gain (scale with pixels)
dfl=1.5, # (float) dfl loss gain
pose=12.0, # (float) pose loss gain
kobj=1.0, # (float) keypoint obj loss gain
label_smoothing=0.0, # (float) label smoothing (fraction)
nbs=64, # (int) nominal batch size
hsv_h=0.015, # (float) image HSV-Hue augmentation (fraction)
hsv_s=0.7, # (float) image HSV-Saturation augmentation (fraction)
hsv_v=0.4, # (float) image HSV-Value augmentation (fraction)
degrees=0.0, # (float) image rotation (+/- deg)
translate=0.1, # (float) image translation (+/- fraction)
scale=0.5, # (float) image scale (+/- gain)
shear=0.0, # (float) image shear (+/- deg)
perspective=0.0, # (float) image perspective (+/- fraction), range 0-0.001
flipud=0.0, # (float) image flip up-down (probability)
fliplr=0.5, # (float) image flip left-right (probability)
mosaic=1.0, # (float) image mosaic (probability)
mixup=0.0, # (float) image mixup (probability)
copy_paste=0.0, # (float) segment copy-paste (probability)
)
版权归原作者 liuzifu123 所有, 如有侵权,请联系我们删除。