
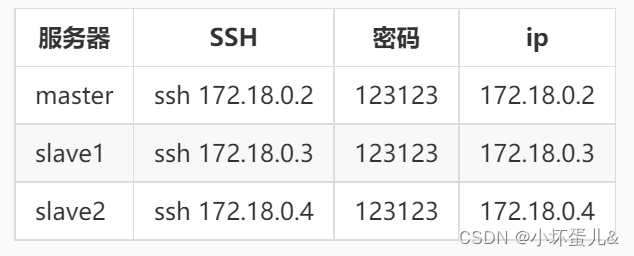
示例集群信息
以下表格为本教程所用示例集群节点信息:
我们准备了三台虚拟服务器,连接方式如下:
第一步我们需要在 evassh 服务器初始化虚拟服务器:
cd /opt
wrapdocker
ulimit -f unlimited
docker load -i ubuntu16-ssh.tar
docker-compose up -d
注意:请不要在各个虚拟服务器之间进行 ssh 登录,这种操作会导致无法保存配置数据。正确方法是:在虚拟服务器里执行 exit 后回到 evassh 服务器,再按上述方法登录各虚拟服务器。
一、文件传输
通过 scp 命令将 evassh 上面的 Java 安装包与 Hadoop 安装包放入 master 服务器上的/opt 目录下。
scp /opt/jdk-8u141-linux-x64.tar.gz [email protected]:/opt
scp /opt/hadoop-3.1.0.tar.gz [email protected]:/opt
第一次连接,会询问是否继续连接。键盘输入 yes 并输入密码 123123 即可进行传输。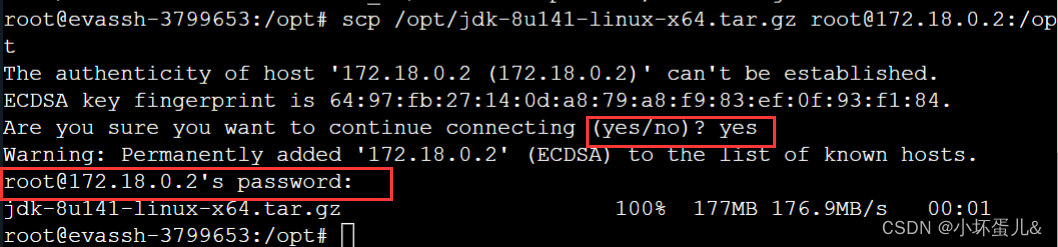

二、配置免密登录
在集群搭建过程中,我们会频繁的在各个服务器之间跳转,此过程是通过 SSH 去连接的,为了避免启动过程输入密码,我们可以配置免密登录。
1、分别在 master、slave1、slave2 生成密钥,命令如下:
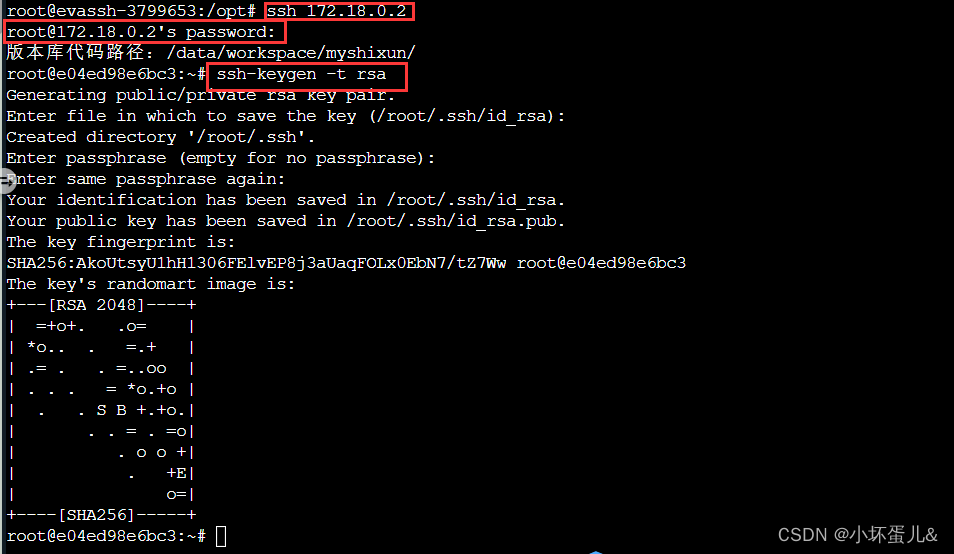
在 master 服务器生成秘钥:
# 进入 master 服务器,键盘输入 yes 与 密码 123123
ssh 172.18.0.2
ssh-keygen -t rsa
# 执行命令之后,连着按三个回车键即可生成秘钥。
这里我们可以开启多个命令行窗口,可以大大减少各个服务器之间的跳转次数。
点击 + 号开启多个窗口,最多可以开启共 3 个命令行窗口。
在 salve1 服务器生成秘钥:
#进入 salve1 服务器,键盘输入 yes 与 密码 123123
ssh 172.18.0.3
ssh-keygen -t rsa
在 salve2 服务器生成秘钥:
# 进入 salve2 服务器,键盘输入 yes 与 密码 123123
ssh 172.18.0.4
ssh-keygen -t rsa
master、slave1和slave2直接已经做了映射,所以这里不需要再做映射。
2、 在 master 复制 master、slave1、slave2 的公钥。
cat ~/.ssh/id_rsa.pub>> ~/.ssh/authorized_keys
ssh slave1 cat ~/.ssh/id_rsa.pub>> ~/.ssh/authorized_keys
ssh slave2 cat ~/.ssh/id_rsa.pub>> ~/.ssh/authorized_keys
密码为:123123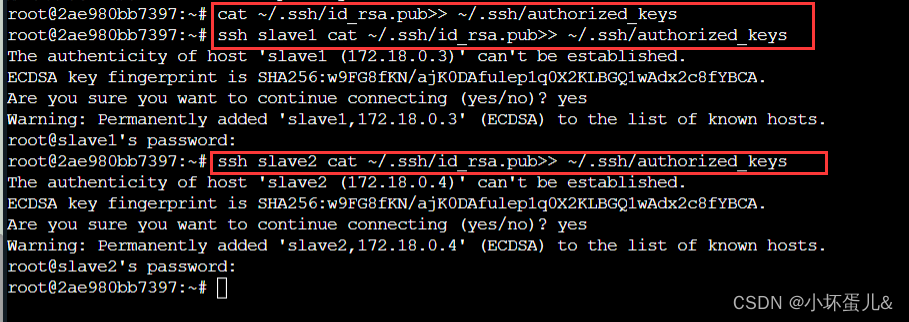
3、 在 slave1 复制 master 的 authorized_keys 文件。
ssh master cat ~/.ssh/authorized_keys>> ~/.ssh/authorized_keys

4、 在 slave2 复制 master 的 authorized_keys 文件。
ssh master cat ~/.ssh/authorized_keys>> ~/.ssh/authorized_keys

集群之间免密至此设置成功
三、集群安装 JavaJDK
在 master 服务器的 /opt 目录下有 evassh 服务器传过来的 Java 安装包与 Hadoop 安装包。解压 Java 安装包至/usr/local目录下。
tar -zxvf /opt/jdk-8u141-linux-x64.tar.gz -C /usr/local/
解压好JDK之后还需要在环境变量中配置JDK,才可以使用,接下来就来配置JDK。
输入命令:vim /etc/profile 编辑配置文件;
在文件末尾输入如下代码(不可以有空格):
export JAVA_HOME=/usr/local/jdk1.8.0_141
export PATH=$PATH:$JAVA_HOME/bin
然后,保存并退出。
最后:source /etc/profile使刚刚的配置生效。
输入:java -version 出现如下界面代表配置成功。
将解压好的JDK与配置文件通过 scp 命令发送至 slave1、slave2 中。
#发送JDK
scp -r /usr/local/jdk1.8.0_141/ root@slave1:/usr/local/
scp -r /usr/local/jdk1.8.0_141/ root@slave2:/usr/local/
#发送配置文件
scp /etc/profile root@slave1:/etc/
scp /etc/profile root@slave2:/etc/
slave1 和 slave2 服务器上分别执行source /etc/profile使发送来的配置生效。
四、Hadoop 分布式集群搭建
解压并改名
解压Hadoop的压缩包到/usr/local目录下,并将解压好的文件夹改名为 hadoop 。
tar -zxvf /opt/hadoop-3.1.0.tar.gz -C /usr/local/
cd /usr/local
mv hadoop-3.1.0/ hadoop

将Hadoop添加到环境变量中
vi /etc/profile
在文件末尾插入如下代码:
export HADOOP_HOME=/usr/local/hadoop
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
最后使修改生效:source /etc/profile
创建文件夹
mkdir /var/hadoop
mkdir /var/hadoop/disk
mkdir /var/hadoop/logs
mkdir /var/hadoop/tmp
mkdir /var/hadoop/namenode
修改配置文件
进入 hadoop 配置文件夹中:
cd /usr/local/hadoop/etc/hadoop/
修改 core-site.xml文件
vim core-site.xml
core-site.xml 是核心配置文件我们需要在该文件中加入HDFS的URI和NameNode的临时文件夹位置,这个临时文件夹在下文中会创建。
在文件末尾的configuration标签中添加代码如下:
<configuration><property><name>fs.defaultFS</name><value>hdfs://master:9000</value></property><property><name>hadoop.tmp.dir</name><value>/var/hadoop/tmp</value></property></configuration>
修改 hdfs-site.xml文件
vim hdfs-site.xml
replication指的是副本数量,我们现在是3个节点,所以是3。属性名dfs.datanode.data.dir代表 datanode 上数据块的物理存储位置,属性名dfs.namenode.name.dir代表 namenode 上存储 hdfs 名字空间元数据
<configuration><property><name>dfs.datanode.data.dir</name><value>/var/hadoop/disk</value></property><property><name>dfs.namenode.name.dir</name><value>/var/hadoop/namenode</value></property><property><name>dfs.replication</name><value>3</value></property></configuration>
修改 yarn-site.xml文件
vim yarn-site.xml
<configuration><property><name>yarn.resourcemanager.hostname</name><value>master</value></property><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property></configuration>
修改 mapred-site.xml文件
vim mapred-site.xml
<configuration><property><name>mapreduce.framework.name</name><value>yarn</value></property></configuration>
修改 hadoop-env.sh文件
文件主要是配置JDK的位置,在文件中添加语句:
export JAVA_HOME=/usr/local/jdk1.8.0_141
修改 workers文件
vim workers
打开文件后应该只有一个localhost,将其删除改为master、slave1、slave2即可。
hadoop-2.6 这个文件名为 slaves ,现在3.0版本为 workers。
master
slave1
slave2

因为root用户现在还不能启动hadoop,我们来设置一下就可以了。
在/hadoop/sbin路径下: cd /usr/local/hadoop/sbin。
将start-dfs.sh,stop-dfs.sh两个文件顶部添加以下参数
#!/usr/bin/env bash
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root
还有,start-yarn.sh,stop-yarn.sh顶部也需添加以下:
#!/usr/bin/env bash
YARN_RESOURCEMANAGER_USER=root
HADOOP_SECURE_DN_USER=yarn
YARN_NODEMANAGER_USER=root
格式
在使用Hadoop之前我们需要格式化一些hadoop的基本信息。
使用如下命令:
hadoop namenode -format
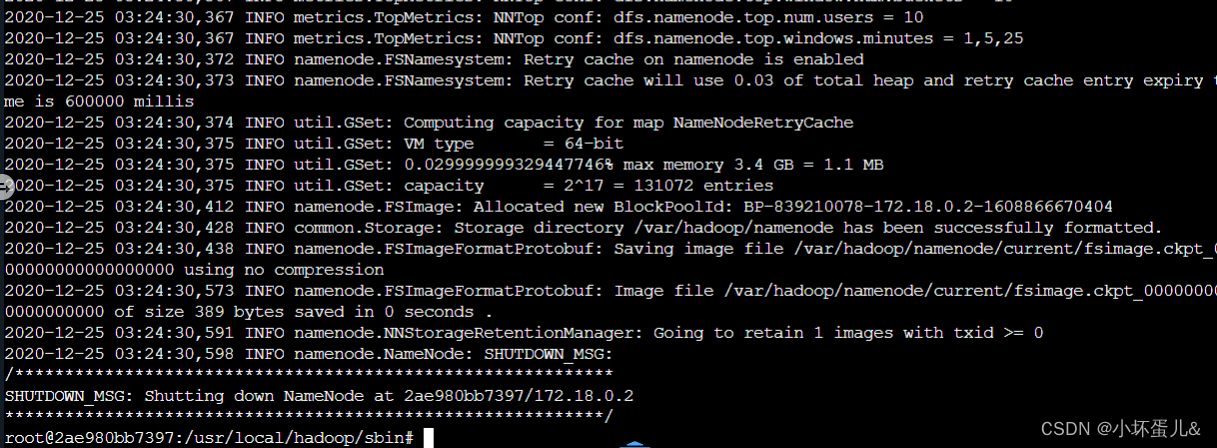
发送至另外两台服务器
scp -r /usr/local/hadoop/ root@slave1:/usr/local/
scp -r /usr/local/hadoop/ root@slave2:/usr/local/
启动Hadoop
接下来我们启动Hadoop:
start-all.sh
输入命令应该会出现如下图界面:
出现如下界面代表成功:
使用 jps 查看 hadoop 进程是否启动成功。
master上: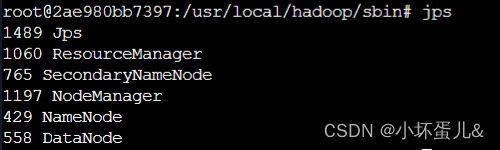
slave1上: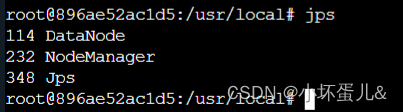
slave2上: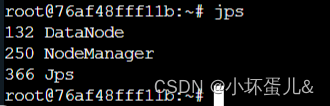
版权归原作者 小坏蛋儿& 所有, 如有侵权,请联系我们删除。