

**个人简介: **
📦个人主页:赵四司机
🏆学习方向:JAVA后端开发
📣种一棵树最好的时间是十年前,其次是现在!
⏰往期文章:SpringBoot项目整合微信支付
🧡喜欢的话麻烦点点关注喔,你们的支持是我的最大动力。
前言:
1.前面基于Springboot的单体项目介绍已经完结了,至于项目中的其他功能实现我这里就不打算介绍了,因为涉及的知识点不难,而且都是简单的CRUD操作,假如有兴趣的话可以私信我我再看看要不要写几篇文章做个介绍。
2.完成上一阶段的学习,我就投入到了微服务的学习当中,所用教程为B站上面黑马的微服务教程。由于我的记性不是很好,所以对于新事物的学习我比较喜欢做笔记以加强理解,在这里我会将笔记的重点内容做个总结发布到“微服务学习”笔记栏目中。我是赵四,一名有追求的程序员,希望大家能多多支持,能给我点个关注就更好了。
一: 流式计算
1.概述
一般流式计算会与批量计算相比较。在流式计算模型中,输入是持续的,可以认为在时间上是无界的,也就意味着,永远拿不到全量数据去做计算。同时,计算结果是持续输出的,也即计算结果在时间上也是无界的。流式计算一般对实时性要求较高,同时一般是先定义目标计算,然后数据到来之后将计算逻辑应用于数据。同时为了提高计算效率,往往尽可能采用增量计算代替全量计算。
可能上面的话看起来不好理解,我举个简单的栗子,批量计算就相当于我们平时搭乘的升降式电梯,运送人是一批一批的,中间会等待人流的积累;而流式计算则相当于我们商场里面搭乘的扶梯,人是源源不断进行运送的,它会不断接收人流,你把人理解成数据就可以理解什么是数据的流式计算了。
2.应用场景
流式计算其实在我们生活中十分常见,下面我举几个例子:
- 日志分析网站的用户访问日志进行实时的分析,计算访问量,用户画像,留存率等等,实时的进行数据分析,帮助企业进行决策
- 大屏看板统计可以实时的查看网站注册数量,订单数量,购买数量,金额等。
- 公交实时数据可以随时更新公交车方位,计算多久到达站牌等
- 实时文章分值计算头条类文章的分值计算,通过用户的行为实时文章的分值,分值越高就越被推荐。
3.技术方案选型
常用的流式计算技术方案选型有如下几种:
Hadoop
Apche Storm
Flink
Kafka Stream
前面三种都是大数据领域常用的技术方案,因此学习成本会比较高,其相关功能大家可以自行查阅官方文档或者相关教程,这里就不多做介绍了。我的项目是基于Java开发的,需求是实现文章分值实时计算,而Kafka Stream可以轻松地将其嵌入任何Java应用程序中,并与用户为其流应用程序所拥有的任何现有打包,部署和操作工具集成。 所以我这里选用的技术方案的Kafka Stream来实现流式计算。
二:Kafka Stream
1.概述
Kafka Stream是Apache Kafka从0.10版本引入的一个新Feature。它是提供了对存储于Kafka内的数据进行流式处理和分析的功能。
Kafka Stream的特点如下:
- Kafka Stream提供了一个非常简单而轻量的Library,它可以非常方便地嵌入任意Java应用中,也可以任意方式打包和部署
- 除了Kafka外,无任何外部依赖
- 充分利用Kafka分区机制实现水平扩展和顺序性保证
- 通过可容错的state store实现高效的状态操作(如windowed join和aggregation)
- 支持正好一次处理语义
- 提供记录级的处理能力,从而实现毫秒级的低延迟
- 支持基于事件时间的窗口操作,并且可处理晚到的数据(late arrival of records)
- 同时提供底层的处理原语Processor(类似于Storm的spout和bolt),以及高层抽象的DSL(类似于Spark的map/group/reduce)
2.Kafka Streams的关键概念
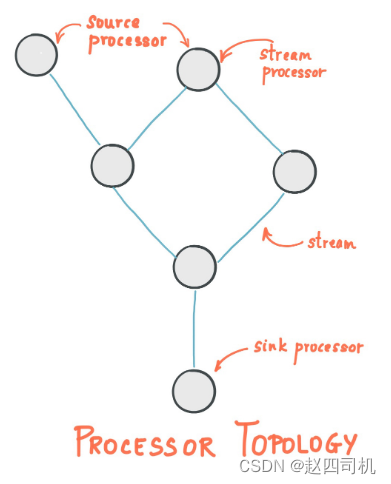
- 源处理器(Source Processor):源处理器是一个没有任何上游处理器的特殊类型的流处理器。它从一个或多个kafka主题生成输入流。通过消费这些主题的消息并将它们转发到下游处理器。
- Sink处理器:sink处理器是一个没有下游流处理器的特殊类型的流处理器。它接收上游流处理器的消息发送到一个指定的Kafka主题。
下面提供一幅官方的图供大家参考帮助理解:
3.KStream
3.1:KStream数据结构
KStream数据结构有点像Map结构,都是Key-Value键值对,见下图:

3.2:KStream数据流
KStream数据流(data stream),即是一段顺序的,可以无限长,不断更新的数据集。 数据流中比较常记录的是事件,这些事件可以是一次鼠标点击(click),一次交易,或是传感器记录的位置数据。
KStream负责抽象的,就是数据流。与Kafka自身topic中的数据一样,类似日志,每一次操作都是向其中插入(insert)新数据。
可能上面的话不太好理解,可以看下图:
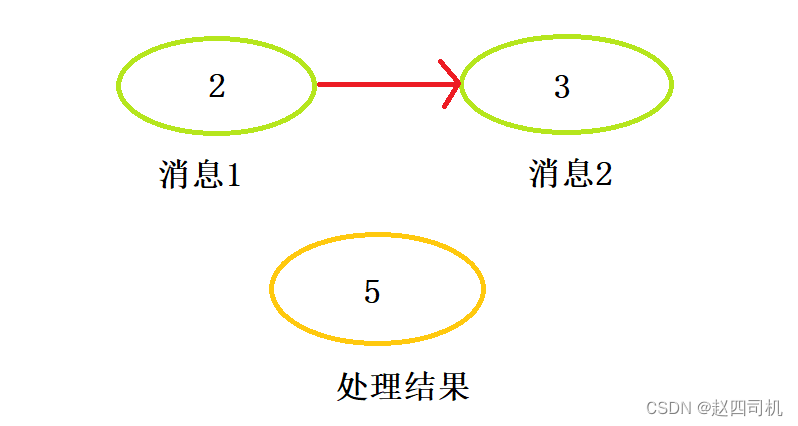
你可能会问,消息是按序发送,为什么处理结果不是3而是5呢?这就是上面提到的第二条数据记录不被视为先前记录的更新,而是新增。
三:入门案例编写
1.需求分析
我们需要利用Kafka Stream实现对单词数量的统计,假如多个生产者发送多条数据,数据是一段英文,那么消费者将统计这些生产者发送的消息中不同单词的个数进行输出。
2.引入依赖
<!-- kafkfa -->
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
<exclusions>
<exclusion>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
</dependency>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-streams</artifactId>
<exclusions>
<exclusion>
<groupId>org.apache.kafka</groupId>
<artifactId>connect-json</artifactId>
</exclusion>
<exclusion>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
</exclusion>
</exclusions>
</dependency>
3.创建原生的kafka staream入门案例
3.1:开启流式计算
package com.my.kafka.demo;
import org.apache.kafka.common.serialization.Serdes;
import org.apache.kafka.streams.KafkaStreams;
import org.apache.kafka.streams.KeyValue;
import org.apache.kafka.streams.StreamsBuilder;
import org.apache.kafka.streams.StreamsConfig;
import org.apache.kafka.streams.kstream.KStream;
import org.apache.kafka.streams.kstream.TimeWindows;
import org.apache.kafka.streams.kstream.ValueMapper;
import java.time.Duration;
import java.util.Arrays;
import java.util.Properties;
/**
* 流式处理
*/
public class KafkaStreamQuickStart {
public static void main(String[] args) {
//kafka的配置信息
Properties prop = new Properties();
prop.put(StreamsConfig.BOOTSTRAP_SERVERS_CONFIG,"49.234.48.192:9092");
prop.put(StreamsConfig.DEFAULT_KEY_SERDE_CLASS_CONFIG, Serdes.String().getClass());
prop.put(StreamsConfig.DEFAULT_VALUE_SERDE_CLASS_CONFIG, Serdes.String().getClass());
prop.put(StreamsConfig.APPLICATION_ID_CONFIG,"streams-quickstart");
//stream 构建器
StreamsBuilder streamsBuilder = new StreamsBuilder();
//流式计算
streamProcessor(streamsBuilder);
//创建kafkaStream对象
KafkaStreams kafkaStreams = new KafkaStreams(streamsBuilder.build(),prop);
//开启流式计算
kafkaStreams.start();
}
/**
* 流式计算
* 消息的内容:hello kafka hello tbug
* @param streamsBuilder
*/
private static void streamProcessor(StreamsBuilder streamsBuilder) {
//创建kstream对象,同时指定从哪个topic中接收消息
KStream<String, String> stream = streamsBuilder.stream("tbug-topic-input");
/**
* 处理消息的value
*/
stream.flatMapValues(new ValueMapper<String, Iterable<String>>() {
@Override
public Iterable<String> apply(String value) {
return Arrays.asList(value.split(" "));
}
})
//按照value进行聚合处理
.groupBy((key,value)->value)
//时间窗口
.windowedBy(TimeWindows.of(Duration.ofSeconds(10)))
//统计单词的个数
.count()
//转换为kStream
.toStream()
.map((key,value)->{
System.out.println("key:"+key+",value:"+value);
return new KeyValue<>(key.key().toString(),value.toString());
})
//发送消息
.to("tbug-topic-out");
}
}
3.2:生产者
package com.my.kafka.demo;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.util.Properties;
/**
* 生产者
*/
public class ProducerDemo {
public static void main(String[] args) {
//1.kafka的配置信息
Properties pro = new Properties();
//Kafka的连接地址
pro.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"49.234.48.192:9092");
//发送失败,失败重连次数
pro.put(ProducerConfig.RETRIES_CONFIG,5);
//消息key的序列化器
pro.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
//消息value的序列化器
pro.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringSerializer");
//数据压缩
pro.put(ProducerConfig.COMPRESSION_TYPE_CONFIG,"lz4");
//2.生产者对象
KafkaProducer<String,String> producer = new KafkaProducer<String, String>(pro);
for (int i = 0; i < 5; i++) {
//3.封装发送消息
ProducerRecord<String, String> message = new ProducerRecord<>("tbug-topic-input", "ni gan ma ai yuo");
//4.发送消息
producer.send(message);
}
//5.关闭消息通道(必选)
producer.close();
}
}
3.3:消费者
package com.my.kafka.demo;
import org.apache.kafka.clients.consumer.ConsumerConfig;
import org.apache.kafka.clients.consumer.ConsumerRecord;
import org.apache.kafka.clients.consumer.ConsumerRecords;
import org.apache.kafka.clients.consumer.KafkaConsumer;
import java.time.Duration;
import java.util.Collections;
import java.util.Properties;
/**
* 消费者
*/
public class ConsumerDemo {
public static void main(String[] args) {
//1.添加Kafka配置信息
Properties pro = new Properties();
//Kafka的连接地址
pro.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG,"49.234.48.192:9092");
//消费者组
pro.put(ConsumerConfig.GROUP_ID_CONFIG,"group2");
//消息key的反序列化器
pro.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer");
//消息value的反序列化器
pro.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG,"org.apache.kafka.common.serialization.StringDeserializer");
//手动提交偏移量
pro.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, false);
//2.消费者对象
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(pro);
//3.订阅主题
consumer.subscribe(Collections.singletonList("tbug-topic-out"));
//4.设置线程一种处于监听状态
//同步提交和异步提交偏移量
try {
while(true) {
//5.获取消息
ConsumerRecords<String, String> messages = consumer.poll(Duration.ofMillis(1000)); //设置每秒钟拉取一次
for (ConsumerRecord<String, String> message : messages) {
System.out.print(message.key() + ":");
System.out.println(message.value());
}
}
} catch (Exception e) {
e.printStackTrace();
System.out.println("记录错误的信息:"+e);
} finally {
//同步
consumer.commitSync();
}
}
}
4.测试结果
先启动消费者和KafkaStream,然后启动消费者发送消息:
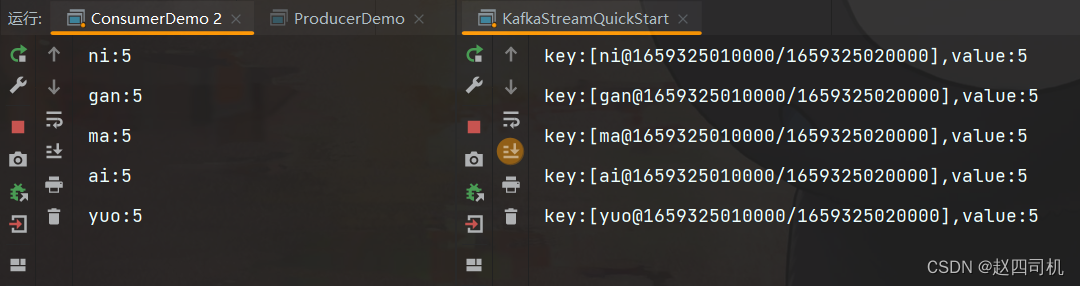
可以看到成功利用流式计算实现了单词数量的统计,当然你也可以设置多个生产者发送消息。
要注意的是,假如你是第一次启动程序,那么你先启动KafkaStream是会报错的,这时候你需要先启动生产者创建一个topic,然后再启动KafkaStream,等待一会就能接收到消息。
版权归原作者 赵四司机 所有, 如有侵权,请联系我们删除。