
** spark官方提供了两种方法实现从RDD转换到DataFrame。第一种方法是利用反射机制来推断包含特定类型对象的Schema,这种方式适用于对已知的数据结构的RDD转换;第二种方法通过编程接口构造一个 Schema ,并将其应用在已知的RDD数据中。**
(一)反射机制推断Schema
在Windows系统下开发Scala 代码,可以使用本地环境测试,因此首先需要在本地磁
盘准备文本数据文件,这里将HD FS中的/spark/person.txt文件下载到本地D:/spark person.txt路径下。从文件4-1可!以看出,当前数据文件共3列,可以非常容易地分析出这3列分别是编号、姓名、年龄。但是计算机无法像人一样直观地感受字段的实际含义,因此需要通过反射机制来推断包含特定类型对象的Schema信息。
接下来打开IDEA开发工具,创建名为 spark01 的Maven工程,讲解实现反射机制推断Schema的开发工具。
1、添加 Spark SQL 依赖,代码如下:
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.11</artifactId>
<version>2.3.2</version>
</dependency>
2、编写代码:
文件名:CaseClassSchema.scala
package cn.itcast
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Row,SparkSession}
//定义样例类
case class Person(id:Int,name:String,age:Int)
object CaseClassSchema {
def main(args: Array[String]): Unit = {
//构建SparkSession
val spark : SparkSession = SparkSession.builder()
.appName("CaseClassSchema")
.master("local[2]")
.getOrCreate()
//获取SparkContext
val sc : SparkContext = spark.sparkContext
//设置日志打印级别
sc.setLogLevel("WARN")
//读取文件
val data:RDD[Array[String]]=
sc.textFile("D://spark//person.txt").map(x=>x.split(" "))
//将RDD与样例类关联
val personRdd : RDD[Person] = data.map(x=>Person(x(0).toInt,x(1),x(2).toInt))
//获取DataFrame
//手动导入隐式转换
import spark.implicits._
val personDF : DataFrame = personRdd.toDF
//------------DSL风格操作开始----------
// 显示DataFrame的数据,默认显示20行
personDF.show()
//显示DataFrame的schema信息
personDF.printSchema()
//统计DataFrame中年龄大于30岁的人
println(personDF.filter($"age">30).count())
//-----------------DSL风格操作结束------------
//----------------SQL风格操作开始-------------
//将DataFrame注册成表
personDF.createOrReplaceTempView("t_person")
spark.sql("select * from t_person").show()
spark.sql("select * from t_person where name='kuli'").show()
//---------------------SQL风格操作结束--------------------
//关闭资源操作
sc.stop()
spark.stop()
}
}
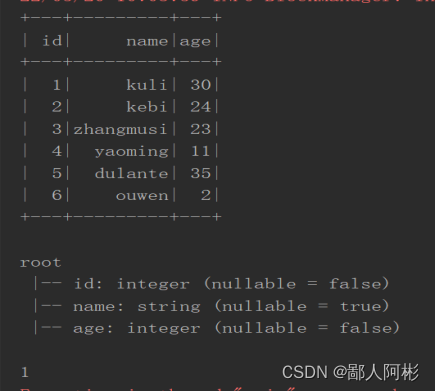
运行结果:

(二)编程方式定义Schema
当case类不能提前定义的时候,就需要采用编程方式定义Schema信息,定义DataFrame主要包含3个步骤,具体如下:
(1)创建一个Row对象结构的RDD;(2)基于StructType类型创建Schema;
(3)通过SparkSession提供的createDataFrame(()方法来拼接Schema。
根据上述步骤,创建 SparkSqlSchema.scala文件,使用编程方式定义Schema信息的具体代码如文件所示。
文件名:SparkSqlSchema.scala
package cn.itcast
import org.apache.spark.SparkContext
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Row, SparkSession}
import org.apache.spark.sql.types.{StructType, StructField, StringType,IntegerType}
object SparkSqlSchema {
def main(args: Array[String]): Unit = {
// 创建SparkSeeion
val spark : SparkSession = SparkSession.builder()
.appName("SparkSqlSchema")
.master("local[2]")
.getOrCreate()
// 获取sparkContext对象
val sc : SparkContext = spark.sparkContext
//设置日志打印级别
sc.setLogLevel("WARN")
//加载数据
val dataRDD : RDD[String] = sc.textFile("D://spark//person.txt")
// 切分每一行
val dataArrayRDD : RDD[Array[String]] = dataRDD.map(_.split(" "))
//加载数据到Row对象中
val personRDD : RDD[Row] = dataArrayRDD.map(x=>Row(x(0).toInt,x(1),x(2).toInt))
//创建Schema
val schema : StructType = StructType(Seq(
StructField("id",IntegerType,false),
StructField("name",StringType,false),
StructField("age",IntegerType,false)
))
//利用personRDD与Schema创建DataFrame
val personDF : DataFrame = spark.createDataFrame(personRDD,schema)
//DSL操作显示DataFrame的数据结果
personDF.show()
//将DataFrame注册成表
personDF.createOrReplaceTempView("t_person")
//sql语句操作
spark.sql("select * from t_person").show()
//关闭资源
sc.stop()
spark.stop()
}
}
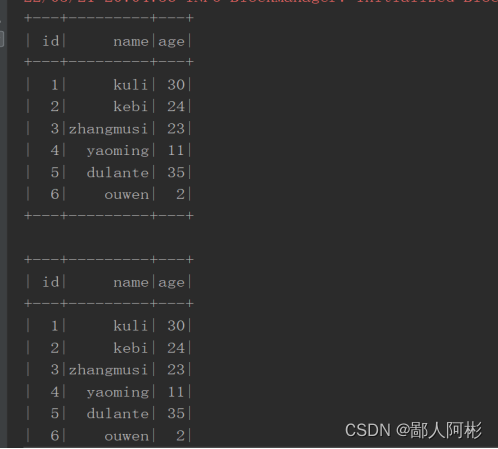
运行结果:
本文转载自: https://blog.csdn.net/m0_59839948/article/details/124902790
版权归原作者 鄙人阿彬 所有, 如有侵权,请联系我们删除。
版权归原作者 鄙人阿彬 所有, 如有侵权,请联系我们删除。