
这次练习获取的网站使用了许多反爬技术:
1.html页面使用了css字体偏移

2.xhr加载有webdriver反爬检测
3.请求接口使用了多项加密参数以及cookie验证
4.部分js代码用了ob混淆
一开始只是想学习练手一下css偏移学习后是解决了,但想获取页面源代码时候遇到了重重问题。
爬取测试思路:
request请求无数据内容,说明数据是异步请求得来,查看xhr找到了请求的api,查看试图逆向参数发现稍有难度,参数比较多,接着试图换一个思路,用selenium访问获取页面源代码,接着驱动访问发现显示不出内容,并要求登录,然后解决cookies:解决登录获取cookies.载入cookies后发现依旧是不现实数据,经过检查发现有个js文件监测webdriver访问,所以要将selenium伪装。最后成功加载出内容。接着获取页面源代码看看,结果又再次发现新问题!!!页面获取后发现是经过ob混淆的页面源代码,处理起来难度又更高了(最后总结发现并非全部混淆只是哈有ob混淆的代码就以为运用上了),最后几经思考了解到利用日志定位到页面加载的数据从而获取加载过了什么数据,等于抓包软件抓取的原理。经过测试终于成功获得api返回的数据。
(虽然后面发现可以定位页面获取想要的数据并没有ob混淆只是部分运用了,但获取请求的返回更高效不需要翻页请求一次获取全部内容,并且摸索学会了新的爬取技术)
下面记录一下本次学习到的获取方法:
先记录一下学习过程遇到的问题:
1.为获取performance日志添加项的报错
因为pip下载是最新版本的selenium所以option.add_experimental_option('w3c',False),会报错因为4.3版本后w3c默认了不允许设置False。降版本到3.141.0即可解决。
2.定位标签点击却报错字典类型无法使用click(),解决方法也是降低版本解决。
需要添加一些项才能使用driver.get_log('performance')获取日志,具体原理因为我也不是很了解浏览器设计原理所以没有深究
caps = DesiredCapabilities.CHROME
caps['loggingPrefs'] = {
'browser':'ALL',
'performance':'ALL',
}
caps['perfLoggingPrefs'] = {
'enableNetwork' : True,
'enablePage' : False,
'enableTimeline' : False
}
option = webdriver.ChromeOptions()
option.add_experimental_option('perfLoggingPrefs',{
'enableNetwork':True,
'enablePage':False,
})
driver = webdriver.Chrome(options=option,desired_capabilities=caps)
伪装浏览器的基础上再加上上面内容才能获取日志
接着获取到日志后,循坏查找里面允许了api的那一条获取他的requestid再通过id定位到加载的数据:
具体代码如下:
def get_xhr(driver,url1):
driver.get(url1) #访问地址
time.sleep(2) #给予时间载入日志
try:
request_log = driver.get_log('performance') #获取日志
# print(request_log)
print(len(request_log)) #查看数据数量
for i in range(len(request_log)): #通过循环获取request中的url
message = json.loads(request_log[i]['message'])
message = message['message']['params']
# .get() 方式获取是了避免字段不存在时报错
request = message.get('request')
if (request is None):
continue#
url = request.get('url')
if (url == "https://flight.qunar.com/touch/api/domestic/wbdflightlist"):
# 定位得到requestId
requestid = message['requestId']
print(requestid)
# 通过requestId获取接口内容
content = driver.execute_cdp_cmd('Network.getResponseBody', {'requestId': requestid})
print(content)
break
except:
# 因为selenium原因载入cookie维持登录状态需要刷新,而刷新会影响工作日志,导致获取不到这时递归再次获取一次即可
get_xhr(driver,url1)
运行代码:
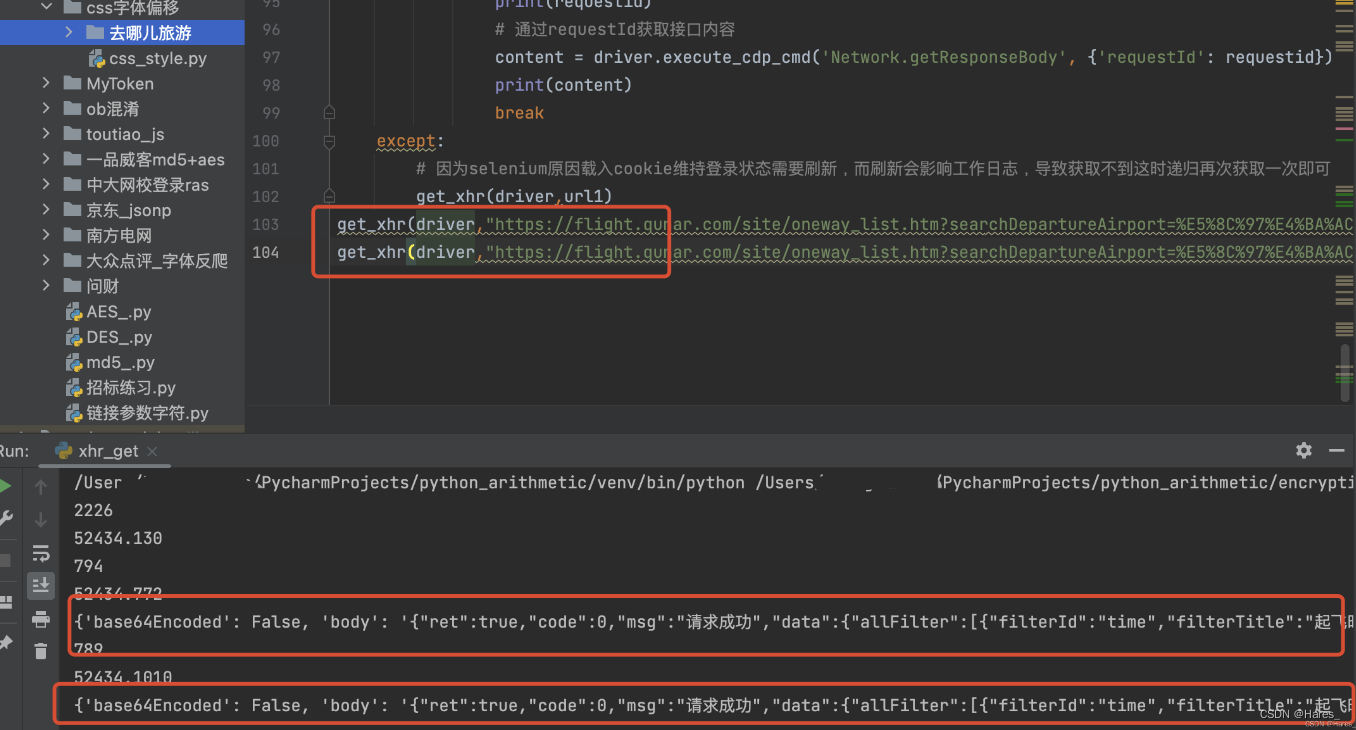
成功获取到数据,因为此网站的数据是直接返回所有当天的所有机票数据,所以更方便不需要跳转页面来获取,只需要对数据进行提取即可!
本文转载自: https://blog.csdn.net/weixin_47481982/article/details/128395351
版权归原作者 Hares_ 所有, 如有侵权,请联系我们删除。
版权归原作者 Hares_ 所有, 如有侵权,请联系我们删除。