
主从复制
**主从复制, 主要是针对MySQL数据库的高可用性, 容灾性上面. **
是叫做高可用性?
**高可用性可以简单的理解为容灾性, 稳定性, 针对故障,风险情况下的处理, 备案, 策略. **
指系统无中断地执行其功能的能力,代表系统的可用性程度
高可用性通常通过提高系统的容错能力来实现
**最常见的容错手段有哪些? **
备份, 简单来讲就是备份. 很容易想嘛, 当你不小心删除掉了自己最新的拍的照片, 急得要死,突然柳暗花明又一村我去,在自己的网盘上发现了备份.
说到备份策略: 本文的主从复制, 就是一个备份策略, 从服务器,甚至可以叫做备份服务器, 怎么容灾, 很简单, 主机挂掉, 迅速提拔一台从机成为新的主机, 其他的从机成为这台新主机的从机.
**说到这个备份, 其实redo log不也是用于容灾数据恢复的嘛. 本质上也是一种备份, 对数据操作的一个备份嘛. 写日志文件备份, 写日志数据库备份. (策略模式, 不同的备份容灾策略) **
首先需要理解主从复制是什么?
就是master主MySQL数据库将数据更新同步刷新复制到slave从MySQL数据库上去。一个主库可以对应多个从库. 从库和主库之间建立MySQL链接通道.
主库复制到从库中的是什么? 是更新操作, 写操作. 也就是insert update delete的操作对应更新到从库上. 这个是在MySQL Server层次上面的。通过binary log二进制日志实现主从复制.

**bin log 记录的是对MySQL数据库执行的写操作(写事件) eg: update insert delete **
- 将数据库的数据更新(做的什么操作, 操作的修改) 写入到主MySQL数据库所在服务器上的bin log 日志中.
- **slave机器通过I/O线程连接master机器, 然后开启一个binlog dump process将bin log中的内容(写事件)传输备份到slave机器上. **
- 传输到slave从机器上之后通过从机上面的IO线程将从bin log传输而来的数据(写事件)临时存储在relay log(中继日志)上 (中继缓冲, 缓存)
- **MySQL从服务器上会启动一个sql从线程, 从relay log 中继日志中读取写事件写sql, 并且将其重放似的重新执行在slave MySQL数据库上, 来保持数据一致性. **
思考: 为什么要存在relay log? 且为什么relay log放在OS缓存中?
**存在relay log,本质上就是作为一个缓冲. 写事件的回放执行, 是需要时间的, 所以必须将从master机器上传输过来的bin log 二进制日志(记录的跟新写操作)临时存储在relay log缓存中. **
(****说白了, 就是为了异步刷新写操作到master主机上嘛, 没有这个中继日志的缓冲, 数据得不到临时存储, 就需要同步传输且执行这些写事件sql. 但是明显同步会阻塞住IO线程的拷贝)
**缓存池, 缓存技术, 线程池, 任务线程池, 这种都是一个异步解耦, 都是为了临时缓存任务, 异步可以避免提供任务线程(主动方, 生产者方)的阻塞, 提升性能. **
relay log 放入OS缓存中是为了降低relay log的开销, 降低此处的IO操作开销, 提升性能.
**思考开启主从复制之前是否需要保证主从库的数据一致性? 是需要的, 如果主从库同时创建初始化, 从库需要做的事情是需要能找到主库的bin log二进制日志. (用于回放同步的磁带操作录像) **
如果master机器提前开启了一段时间了, 存在一定的业务数据了, 此时创建的slave机器则需要先备份mysqldump主库的数据, 然后再将其导入source到从库中,使其在开启主从复制之前保证数据一致.
**从库要可以作为主库的一个备份库,备用库, 我们首先应该保证的是主库有的数据, 从库中有, 数据一致之后才能进行主从复制(主从库的数据同步.) **
主从数据库的配置. 自己去实现一下主从数据库的配置对我们来说是有必要的, 但是可恶的是,我本意是先要用云服务器作为master机器, 本地主机作为slave机器. 但是我发现我在学校里面ipconfig之后看到的是一个局域网ip. 所以master机器ping不通我这个局域网ip, 所以我只能留着回去老家的时候再尝试. ---- 立下flag。
读写分离
如果说主从复制就是简单的备份, 容灾操作, 提升高可用性的.
那读写分离就是从高并发的角度来思考的. 提升抗压, 并发性能. 一台机器扛不住, 就来多台机器集群来扛住.
读写部署在不同的主从机器上, 一般而言数据写操作是比较少的, 大多都是读取操作比较多. 所以往往是一台master机器负责写sql, 并且及时将这些写操作回放同步到slave从机上去. (主从复制)多台slave机器就负责执行sql读请求.
说白了就是一个服务器集群, 这个也是一个经典的MySQL数据库服务器的集群模型. 一台master主机仅仅负责所有的sql写事件请求的执行服务, N台slave从机负责所有的sql读事件请求的执行服务.
这些请求的分发操作,依赖的是中间的一台反向代理服务器MyCat.
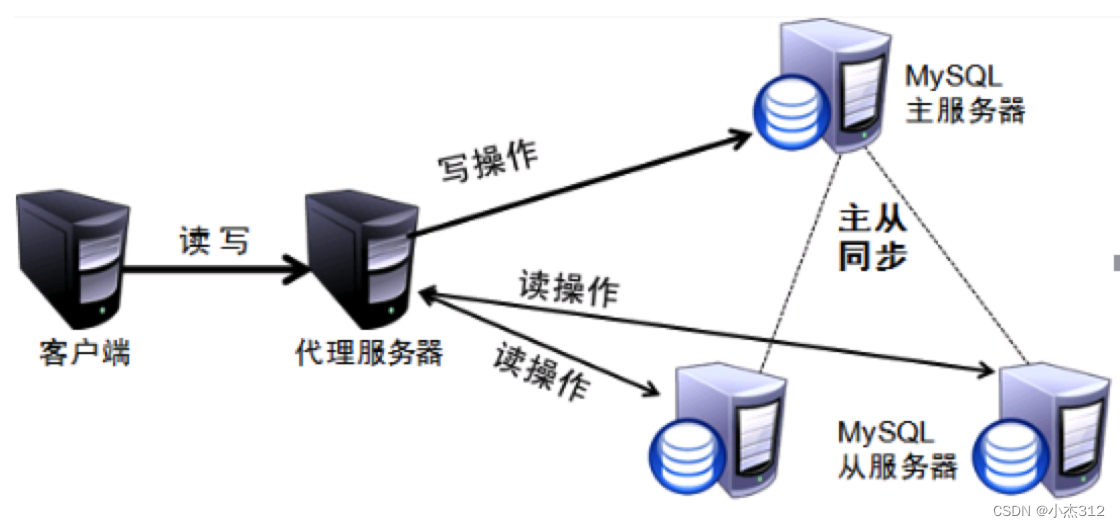
读写分离就是在主服务器上修改,数据会同步到从服务器,从服务器只能提供读取数据,不能写入,实现备份(主从复制)的同时也实现了数据库性能的优化,以及提升了服务器安全。
读写分离模型(1-N, N-M):
想一想如果master机器挂掉了, 我们应该怎样处理. 针对这种集群,最需要关注的就是监控的这些上游的真正提供业务服务的这些主机的存活情况, 以及硬件配置好坏. 监控存活可以通过维护心跳包.
**如果真的master机器挂掉了. 采取的方法是,将slave机器群中的一台提升为master机器, 其他的slave机器转而成为新的master机器的从机. **
还可能是一个反向代理服务器监控着两个master或者多个maser. 这个时候,两个master之间也可以来个主从复制, 互为主从, 要是一个集群挂掉了,从集群还可以顶替正常工作, 做一个容灾.
配置, 同样立下flag回老家完成, 加油, 立下的flag还是要实现的, 现在不研究配置, 将来去了公司谁管你配置. 加油,干掉一个配置是一个, 积累经验.
分库分表
分库分表的必要性? 原因? 还是一个流量的上升,单机写性能下降,业务需求促使架构的发展.
数据库架构的一个扩展演变, 最开始的时候大多数项目运用单机数据库就足够了,但是随着服务器的流量越来越大, 出现了读写分离. 多个从库副本负责数据库的读操作, 主库负责写. Master和slave通过主从复制, 保证数据的同步一致性. slave从库可以水平扩展, 所以对于读请求的处理是不成什么大问题的.
但是随着用户量级的进一步提升,写操作的压力越来越大,哪怕我们开启了读写分离, 性能依然下降的很严重. 这个时候我们就必须进行一个分库分表操作.
分库分表到底是个啥意思?
**就是说将存放大量数据的表或库中的数据分散到不同主机上, 使得单个主机的数据量减小, 而实现的一个大数据量下的分散压力,提升数据库性能, 切分操作. --- 切分后如何对数据的快速定位成为了关键的问题? 如何保证数据定位? 操作定位? 定位请求应该到那一台主机上. 数据在那一台主机上. **
**切分方式: 垂直切分/纵向扩展.本体拆分(大库拆小库. 大表拆小表. ), 水平切分 (分库 + 分表) **
**单库太大 **
单库处理能力有限、所在服务器上的磁盘空间不足、遇到IO瓶颈,需要把单库切分成更多更小的库
**单表太大 **
CURD效率都很低、数据量太大导致索引膨胀、查询超时,需要把单表切分成多个数据集更小的表
**垂直分库, 按照业务分类进行划分, 每个业务独有一个数据库 (将拆分出来的库分散在多个数据库服务器上. 纵向扩展) **
垂直分库
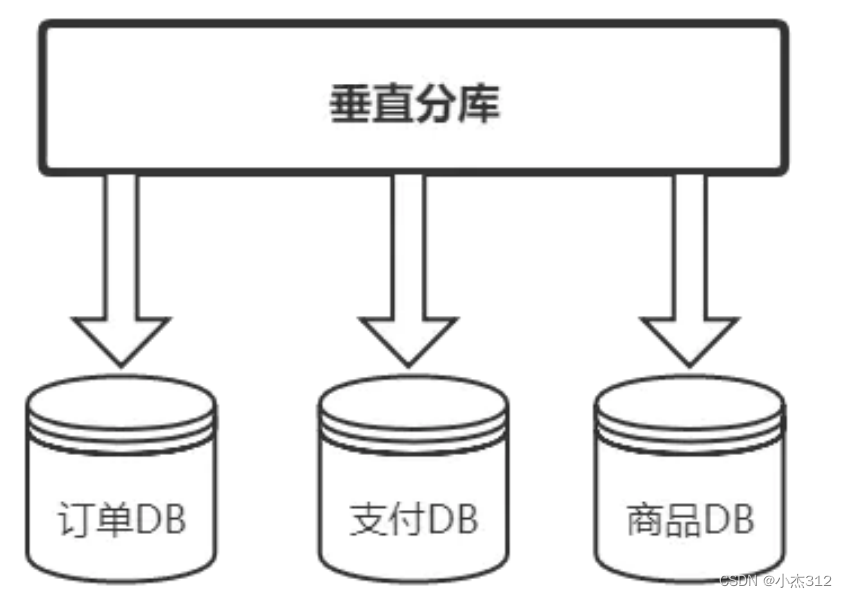
业务间解耦,不同业务的数据进行独立的维护、监控、扩展
垂直分表
**也就是“大表拆小表”,基于列字段进行。 一般是表中的字段较多,将不常用的, 数据较大,长度较长(比如text类型字段)的拆分到“扩展表“。 一般是针对几百列的这种大表,也避免查询时,数据量太大造成的“跨页”问题. **
例如: 一个order表有很多字段, 把长度较大且访问不频繁的字段, 拆分出来创建一个单独的扩展表work_extend进行存储.
核心表存储的是访问频次比较高, 且字段比较短的数据. 可以加载更多数据到内存中, 增加查询的命中率, 以此来提高数据库性能.
水平分表
**针对数据量巨大的单张表(比如订单表),按照某种规则(RANGE,HASH取模等),切分到多张表里面 去。 但是这些表还是在同一个库中,所以库级别的数据库操作还是有IO瓶颈,不建议采用。 (只是减少了单表的数据量,但是本质上还是在一个库中, 还在竞争同一个物理机的CPU、内存、网络IO)。 (水平分表,只是将数据拆拿出几行拆分成不同的表. 并不是拆分列.) **
水平分库分表
将分出来的表放到不同的库(多个服务器上去)中. 使得单个表的数据量变小,达到分布式的效果。真正解决了高并发时单库数据量过大的问题,提升系统稳定性和负载能力。
数据应该去往哪个表的问题?
不论是竖直方向上的分库分表. 还是水平方向上的一个分库分表. 都需要定位数据应该去哪里,我能想到的就是一个hash的方式
至于分库分表的一个配置也是留着回老家处理. ( 对于分库分表,小杰仅浅显理解, 感觉理解还不够深入, 浮于表层. 明显表述不清, 以后如果有机会真正实践几次分库分表的部署,希望能又更升入的清晰理解. )
版权归原作者 小杰312 所有, 如有侵权,请联系我们删除。