

本文介绍了现代计算机视觉的主要思想。我们探索如何将数百个学习图像中低级特征的神经元堆叠成几层。

视觉,源于自然
哺乳动物视觉皮层中的神经元被组织成一层一层地处理图像,其中一些神经元在识别线和边等局部特征方面具有特殊的功能;当位置和方向改变时,一些层被激活;其他层对复杂的形状(如交叉线)做出反应。

这激发了堆叠的卷积层,它包括将每个神经元的视野限制在输入图像的一小块区域。接受域的大小由过滤器的大小给出,也称为内核大小。当滤波器在图像中滑动时,它的工作原理就像信号处理中的卷积,因此它允许特征检测。
卷积是一个积分,表示一个函数(核函数或滤波器)在另一个函数(输入)上移位时的重叠量。卷积用于过滤信号(一维音频、二维图像处理),检查一个信号与另一个信号的相关性,或在信号中寻找模式。
例如,可以使用特定的内核从图像中提取边缘。
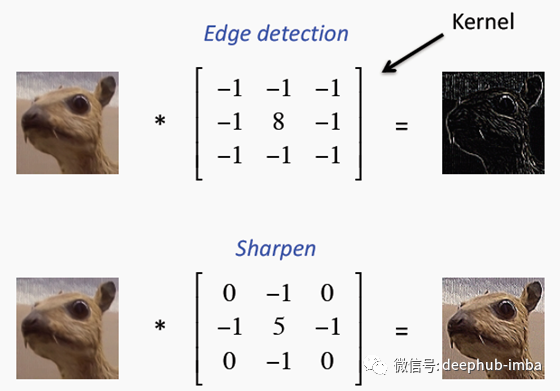
我们可以使用许多这样的过滤器来检测图像的所有有价值的特征。起初,这些过滤器是手工制作的;后来,他们从这些图像中自己学习。在训练中寻找权重的过程也会产生这些过滤器。
特征映射
我们需要多少这样的卷积?通过引入尺度的概念,借用分形数学,卷积神经网络将几个卷积层叠加起来,这样一来,第一个层可以识别更小的特征,而更深的层则专门处理更大的特征。
分形是一种具有无限尺度的图像。我们通常需要多少层就有多少层来检测尺度。单个卷积层的目的是在特定的单一尺度上学习一组特征。
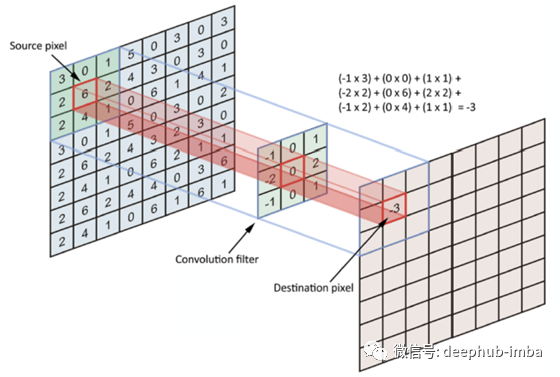
每个卷积层也由层组成,但是这些层不是完全连接的。让我们假设一个28x28的RGB图像作为第一个卷积层的输入,带有四个3x3过滤器F1, F2, F3, F4。每个过滤器是大小为3x3x3的立方体形状,应用于整个图像,每次产生一个数字。
过滤器在图像中移动的步数称为stride,通常为1。生成的功能映射的深度等于过滤器的数量。它的宽度和高度取决于图像大小、过滤器大小和填充。
在我们的例子中,在全填充的情况下,我们将有一个feature map维度28x28x4。在没有填充的情况下,我们将拥有26x26x4维度。因此通道的数量不影响feature map的大小。
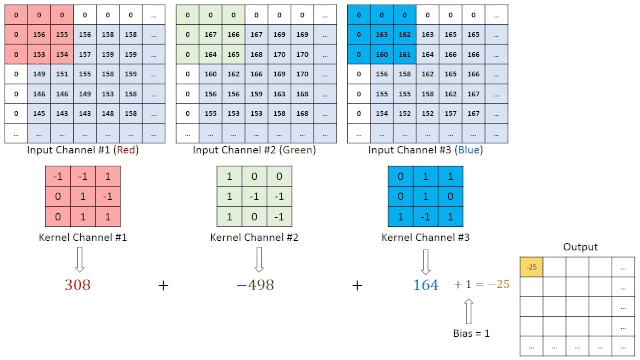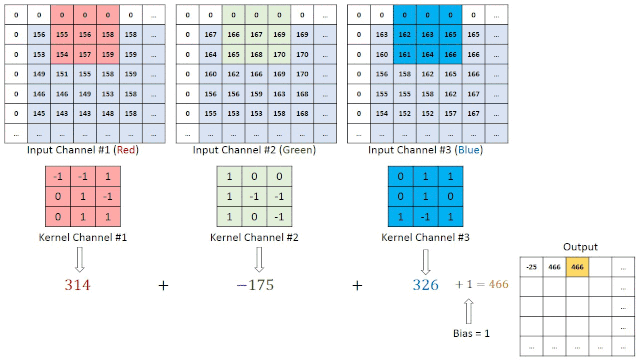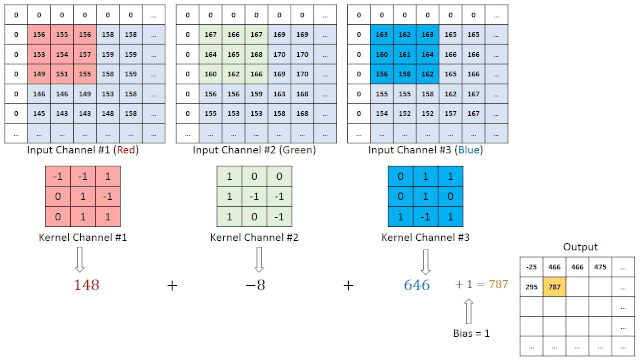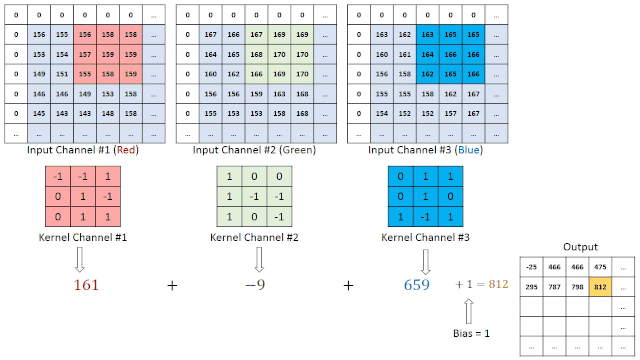
池化
卷积导致来自图像相邻区域的信息重复,导致高维性。池化卷积层输出的一个区域并返回一个聚合值:通常是最大值,但也可以使用平均值、最小值或任何函数。
CNNs在考虑多尺度时效果最好。因此,我们通常会多次复制convolutional和pooling层
获得更深层次的
将卷积层堆叠在一起的方法与其说是一门科学,不如说是一门艺术。下面的VGG网络是在2014年提出的,用于将1400万幅图像分类为1000个类别,测试准确率为92.7%。它接受了2周的训练,估计它的参数总量为14,714,688。还有更多这样的超大网络:GoogLeNet、ResNet、DenseNet、MobileNet、Xception、ResNeXt等等。
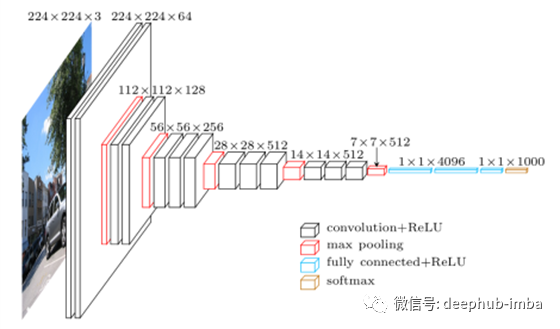
深度学习的一个建议和高度有效的方法是利用那些预先训练过的网络。一个预先训练好的网络只是一个之前在大数据集上训练过的保存的网络,它可以有效地作为真实世界的一个通用模型。
特征提取是一种使用预处理网络学习到的表示的方法,它以预处理网络的卷积基为基础,通过它运行新数据,并使用一个新的小数据集在输出之上训练一个新的简单分类器,如下图所示。
另一种方法是冻结预先训练好的网络的基础,附加一个简单的分类器,然后对整个网络进行训练。另一种被称为微调的方法是在训练前解冻基地的特定层。
总结
为计算机提供感知能力对社会有重大影响。如今,相机系统可以捕捉世界的实时图像,从而实现突破性的应用,比如自动驾驶。在本文中,我们解释了计算机视觉机器学习背后的一些机制。
DeepHub
微信号 : deephub-imba
每日大数据和人工智能的重磅干货
大厂职位内推信息
长按识别二维码关注 ->
好看就点在看!********** **********