

🐇明明跟你说过:个人主页
🏅个人专栏:《洞察之眼:ELK监控与可视化》🏅
🔖行路有良友,便是天堂🔖
一、引言
1、Elasticsearch简介
Elasticsearch是一个开源的、基于Lucene的分布式搜索和分析引擎,设计用于云计算环境中,能够实现实时的、可扩展的搜索、分析和探索全文和结构化数据。
1. 核心特性:
- 分布式:Elasticsearch是分布式的,可以在多个服务器上运行,并且能够自动将数据在服务器之间进行负载均衡。
- 可扩展性:Elasticsearch提供了可扩展的架构,无论是存储、节点还是查询吞吐量,都可以随着业务需求的变化而增加资源。它可以扩展到上百台服务器,处理PB级别的数据。
- 实时性:Elasticsearch能够实时地处理数据,提供了近实时的搜索和分析功能。
- 全文检索:Elasticsearch提供了全文检索功能,支持对大量数据进行复杂的搜索和分析。
- 分析性:Elasticsearch提供了强大的分析功能,包括聚合、统计和排序等。
- 多租户能力:Elasticsearch可以配置为多租户环境,允许不同的用户和应用共享相同的集群资源。
- 监控和警报:Elasticsearch提供了内置的监控和警报功能,使得用户可以实时了解系统的运行状态,并在出现异常时得到通知。
2. 数据支持:
- Elasticsearch为所有类型的数据提供近乎实时的搜索和分析。无论您拥有结构化或非结构化文本、数字数据还是地理空间数据,Elasticsearch都能以支持快速搜索的方式高效地存储和索引它。
3. 技术实现:
- Elasticsearch使用Java开发,并基于Lucene作为其核心来实现所有索引和搜索的功能。但其目的是通过简单的RESTful API来隐藏Lucene的复杂性,通过面向文档从而让全文搜索变得简单。
- Elasticsearch支持多种数据类型,包括字符串、数字、日期等。
- Elasticsearch的水平可扩展性允许通过增加节点来扩展其处理能力。
- 在硬件故障或节点故障的情况下,Elasticsearch具有容错能力,能够保持数据的完整性和服务的可用性。
4. 应用场景:
- Elasticsearch在众多场景下都有广泛的应用,如企业搜索、日志和事件数据分析、安全监控等。
5. 集成方案:
- Elasticsearch与名为Logstash的数据收集和日志解析引擎以及名为Kibana的分析和可视化平台一起开发的。这三个产品被设计成一个集成解决方案,称为“Elastic Stack”(以前称为“ELK stack”)。

2、为什么在k8s中部署elasticsearch
1. 自动化和编排
- 自动化部署和管理: - Kubernetes 提供了自动化的部署、扩展和管理功能,可以简化 Elasticsearch 集群的配置、启动和监控。
- 自愈能力: - Kubernetes 能够自动检测并重新调度失败的 Pod,确保 Elasticsearch 集群的高可用性和稳定性。
2. 可扩展性
- 水平扩展: - Elasticsearch 的节点可以在 Kubernetes 中水平扩展,通过增加或减少节点数目来应对数据量和查询量的变化。
- 弹性资源分配: - Kubernetes 允许为不同的 Elasticsearch 节点(如数据节点、主节点、协调节点)分配不同的资源配额,确保资源的合理利用和优化。
3. 高可用性
- 多副本管理: - Kubernetes 能够通过其副本控制器和 StatefulSets 管理 Elasticsearch 的数据副本和分片,确保在节点失败时数据不会丢失,并且服务能迅速恢复。
- 跨可用区分布: - Kubernetes 可以将 Elasticsearch 节点分布在不同的可用区(Availability Zones),提高容灾能力。
4. 容器化优势
- 一致的环境: - 使用容器化的 Elasticsearch 可以确保在开发、测试和生产环境中运行的一致性,减少环境差异带来的问题。
- 依赖管理: - 容器化可以简化依赖管理,确保 Elasticsearch 及其依赖组件能够在独立的环境中运行,不会相互干扰。

二、k8s基础
1、k8s简介
K8s,全称Kubernetes,是一个开源的容器编排系统,旨在自动化容器化应用程序的部署、扩展和管理。
1. 定义与概念:
- K8s是一个用于管理容器的开源平台,允许用户方便地部署、扩展和管理容器化应用程序。
- 它通过自动化的方式实现负载均衡、服务发现和自动弹性伸缩等功能。
- Kubernetes将应用程序打包成容器,并将这些容器部署到一个集群中,自动处理容器的生命周期管理、自动扩容等操作。
2. 主要特点:
- 自动化管理:自动化管理容器应用程序的部署、扩展、运维等一系列操作,减少了人工干预,提高了效率。
- 弹性伸缩:根据应用负载情况自动进行扩容或缩容,保证应用的性能和稳定性。
- 高可用性:当某个节点故障时,K8s会自动将应用迁移至其他健康节点,保证应用的正常运行。
- 自愈能力:能够监测应用状态并进行自动修复,如自动重启或迁移故障应用。
3. 架构与组件:
- K8s集群由多个节点(Node)组成,包括Master节点和Worker节点。
- Master节点作为整个集群的控制中心,负责集群的管理和调度工作,包括API服务器、调度器、控制器管理器等核心组件。
- Worker节点是集群的工作节点,负责运行Pod(容器组)并提供应用程序的运行环境。

2、Pods、Services、StatefulSet等基本概念
2.1 Pods
Pods 是Kubernetes中最小的可部署计算单元。一个Pod可以包含一个或多个容器,这些容器共享网络命名空间和存储资源,并总是共同调度在同一个节点上。
- 单容器Pod: 最常见的情况,一个Pod包含一个容器。
- **多容器Pod: **包含多个需要紧密协作的容器,例如共享存储或网络的协同进程。
特点:
- 共享相同的存储卷和网络命名空间。
- 作为一个整体被调度到同一个节点上。
2.2 Services
Services 是一种抽象,它定义了一组逻辑上相同的Pods,并且提供一个稳定的访问入口(IP地址和端口)。Services实现了负载均衡,并且允许Pod进行自动发现和通信。
类型:
- **ClusterIP: **默认类型,仅在集群内部可访问。
- **NodePort: **在每个节点上开放一个静态端口,使得服务可以通过<NodeIP>:<NodePort>访问。
- **LoadBalancer: **使用云提供商的负载均衡器,公开服务到外部网络。
- **ExternalName: **将服务映射到外部名称,比如DNS名称。
功能:
- 提供Pod的负载均衡。
- 稳定的网络接口,不会因为Pod的创建和销毁而变化。
2.3 StatefulSets
StatefulSets 专门用于管理有状态应用,确保Pod有固定的标识符和稳定的存储。适用于数据库、分布式文件系统等需要持久化存储的应用。
特点:
- 稳定的网络标识: 每个Pod有一个固定的DNS名,例如pod-0.service.namespace.svc.cluster.local。
- 有序部署和更新: Pod按顺序进行创建、删除和更新(例如从pod-0到pod-N)。
- 稳定的存储: 每个Pod可以有一个独立的PersistentVolume,与Pod的生命周期无关。

三、Elasticsearch集群架构
1、Elasticsearch集群的组成
一个Elasticsearch集群主要由以下几个部分组成:
1. 节点(Node):
- 节点是Elasticsearch集群中的一个单独运行实例,每个节点都存储数据并参与集群的索引和搜索功能。
2. 主节点(Master Node):
- 负责集群范围内的管理任务,如创建或删除索引、跟踪集群中各个节点的状态,并选择主分片和副本分片的位置。
- 一个集群中只有一个主节点是活动的,但可以配置多个候选主节点以提高容错性。
3. 数据节点(Data Node):
- 负责存储数据和处理CRUD(创建、读取、更新、删除)操作以及搜索请求。数据节点需要较多的内存和存储资源。
4. 协调节点(Coordinating Node):
- 处理来自客户端的请求,将请求分发到合适的数据节点,并汇总结果后返回给客户端。
- 任何节点都可以作为协调节点,但可以专门配置一些节点只作为协调节点。
5. 主节点候选节点(Master-Eligible Node):
- 可以被选举为主节点的节点。通常,集群会配置多个候选主节点,以防止单点故障。
6. 专用节点(Dedicated Node):
- 可以配置专门的节点来处理特定任务,如专用的主节点、数据节点或协调节点,以优化集群性能。
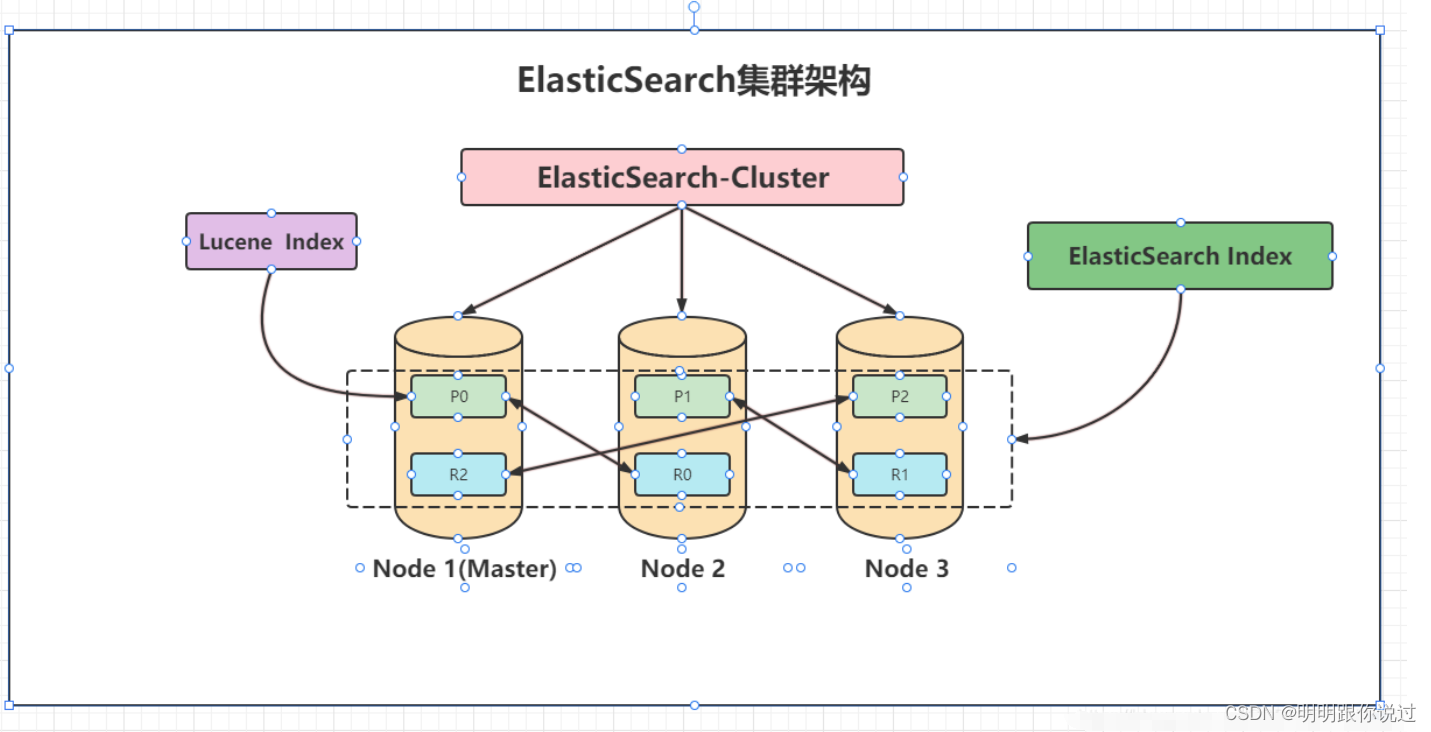
2、Elasticsearch工作原理
1. 索引和分片(Shards):
- 数据在存储时被划分为多个分片。每个索引(类似于关系数据库中的表)可以被分成一个或多个主分片(Primary Shard),每个主分片可以有多个副本分片(Replica Shard)。
- 主分片负责处理数据写入,副本分片用于数据冗余和读取操作,以提高查询性能和数据安全性。
2. 数据分布:
- Elasticsearch使用一致性哈希算法将分片分布到集群中的各个节点上。主节点负责跟踪分片的位置,并在节点故障时重新分配分片。
3. 查询和搜索:
- 当客户端发送查询请求时,协调节点会解析请求并将其分发到相关的分片上。每个分片在本地执行查询,并返回结果给协调节点,协调节点汇总结果后返回给客户端。
- 查询可以并行执行,从而提高性能。
4. 数据写入:
- 当客户端发送数据写入请求时,协调节点将数据发送到相关的主分片。主分片处理写入后,将数据同步到所有副本分片。确保所有副本分片都成功写入数据后,协调节点才会向客户端确认写入成功。

3、集群高可用设计
本次部署的elasticsearch设计为5节点,一主多从的高可用方式,如果一个主节点意外宕掉,其他节点自主选举出新的Master节点接管任务,从而保证集群的高可用性

四、部署环境准备
1、准备k8s集群
这里我们使用的k8s集群版本为 1.23,也可以使用其他的版本,只是镜像导入命令不通,如果还未搭建k8s集群,请参考《在Centos中搭建 K8s 1.23 集群超详细讲解》这篇文章

2、准备StorageClass
因为我们要对Elasticsearch中的数据进行持久化,避免Pod漂移后数据丢失,保证数据的完整性与可用性
如果还未创建存储类,请参考《k8s 存储类(StorageClass)创建与动态生成PV解析,(附带镜像)》这篇文件。

五、部署Elasticsearch集群
1、编写部署Elasticsearch的YAML文件
apiVersion: v1
kind: Namespace
metadata:
name: es
---
#创建ConfigMap用于挂载配置文件
apiVersion: v1
kind: ConfigMap
metadata:
name: sirc-elasticsearch-config
namespace: es
labels:
app: elasticsearch
data: #具体挂载的配置文件
elasticsearch.yml: |+
cluster.name: "es-cluster"
network.host: 0.0.0.0
http.cors.enabled: true
http.cors.allow-origin: "*"
http.cors.allow-headers: "*"
bootstrap.system_call_filter: false
xpack.security.enabled: false
index.number_of_shards: 5
index.number_of_replicas: 1
#创建StatefulSet,ES属于数据库类型的应用,此类应用适合StatefulSet类型
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: elasticsearch
namespace: es
spec:
serviceName: "elasticsearch-cluster" #填写无头服务的名称
replicas: 5
selector:
matchLabels:
app: elasticsearch
template:
metadata:
labels:
app: elasticsearch
spec:
initContainers:
- name: fix-permissions
image: busybox
imagePullPolicy: IfNotPresent
command: ["sh", "-c", "chown -R 1000:1000 /usr/share/elasticsearch/data"]
securityContext:
privileged: true
volumeMounts:
- name: es-data
mountPath: /usr/share/elasticsearch/data
- name: increase-vm-max-map
image: busybox
imagePullPolicy: IfNotPresent
command: ["sysctl", "-w", "vm.max_map_count=262144"]
securityContext:
privileged: true
- name: increase-fd-ulimit
image: busybox
imagePullPolicy: IfNotPresent
command: ["sh", "-c", "ulimit -n 65536"]
securityContext:
privileged: true
containers:
- name: elasticsearch
image: elasticsearch:7.17.18
imagePullPolicy: Never
resources:
requests:
memory: "1000Mi"
cpu: "1000m"
limits:
memory: "2000Mi"
cpu: "2000m"
ports:
- containerPort: 9200
name: elasticsearch
env:
- name: node.name
valueFrom:
fieldRef:
fieldPath: metadata.name #metadata.name获取自己pod名称添加到变量MY_POD_NAME,status.hostIP获取自己ip等等可以自己去百度
- name: discovery.type
value: zen
- name: cluster.name
value: elasticsearch
- name: cluster.initial_master_nodes
value: "elasticsearch-0,elasticsearch-1,elasticsearch-2,elasticsearch-3,elasticsearch-4"
- name: discovery.zen.minimum_master_nodes
value: "3"
- name: discovery.seed_hosts
value: "elasticsearch-0.elasticsearch-cluster.es,elasticsearch-1.elasticsearch-cluster.es,elasticsearch-2.elasticsearch-cluster.es,elasticsearch-3.elasticsearch-cluster.es,elasticsearch-4.elasticsearch-cluster.es"
- name: network.host
value: "0.0.0.0"
- name: "http.cors.allow-origin"
value: "*"
- name: "http.cors.enabled"
value: "true"
- name: "number_of_shards"
value: "5"
- name: "number_of_replicas"
value: "1"
- name: path.data
value: /usr/share/elasticsearch/data
volumeMounts:
- name: es-data #挂载数据
mountPath: /usr/share/elasticsearch/data
volumes:
- name: elasticsearch-config
configMap: #configMap挂载
name: sirc-elasticsearch-config
volumeClaimTemplates: #这步自动创建pvc,并挂载动态pv
- metadata:
name: es-data
spec:
accessModes: ["ReadWriteMany"]
storageClassName: nfs
resources:
requests:
storage: 10Gi
#创建Service
---
apiVersion: v1
kind: Service
metadata:
name: elasticsearch-cluster #无头服务的名称,需要通过这个获取ip,与主机的对应关系
namespace: es
labels:
app: elasticsearch
spec:
ports:
- port: 9200
name: elasticsearch
clusterIP: None
selector:
app: elasticsearch
---
apiVersion: v1
kind: Service
metadata:
name: elasticsearch #service服务的名称,向外暴露端口
namespace: es
labels:
app: elasticsearch
spec:
ports:
- port: 9200
name: elasticsearch
type: NodePort
selector:
app: elasticsearch
---
apiVersion: v1
kind: Service
metadata:
name: my-nodeport-service-0
namespace: es
spec:
type: NodePort
selector:
statefulset.kubernetes.io/pod-name: elasticsearch-0
ports:
- protocol: TCP
port: 80 # Service 暴露的端口
targetPort: 9200 # Pod 中容器的端口
nodePort: 30000 # NodePort 类型的端口范围为 30000-32767,可以根据需要调整
---
apiVersion: v1
kind: Service
metadata:
name: my-nodeport-service-1
namespace: es
spec:
type: NodePort
selector:
statefulset.kubernetes.io/pod-name: elasticsearch-1
ports:
- protocol: TCP
port: 80 # Service 暴露的端口
targetPort: 9200 # Pod 中容器的端口
nodePort: 30001 # NodePort 类型的端口范围为 30000-32767,可以根据需要调整
---
apiVersion: v1
kind: Service
metadata:
name: my-nodeport-service-2
namespace: es
spec:
type: NodePort
selector:
statefulset.kubernetes.io/pod-name: elasticsearch-2
ports:
- protocol: TCP
port: 80 # Service 暴露的端口
targetPort: 9200 # Pod 中容器的端口
nodePort: 30002 # NodePort 类型的端口范围为 30000-32767,可以根据需要调整
---
apiVersion: v1
kind: Service
metadata:
name: my-nodeport-service-3
namespace: es
spec:
type: NodePort
selector:
statefulset.kubernetes.io/pod-name: elasticsearch-3
ports:
- protocol: TCP
port: 80 # Service 暴露的端口
targetPort: 9200 # Pod 中容器的端口
nodePort: 30003 # NodePort 类型的端口范围为 30000-32767,可以根据需要调整
---
apiVersion: v1
kind: Service
metadata:
name: my-nodeport-service-4
namespace: es
spec:
type: NodePort
selector:
statefulset.kubernetes.io/pod-name: elasticsearch-4
ports:
- protocol: TCP
port: 80 # Service 暴露的端口
targetPort: 9200 # Pod 中容器的端口
nodePort: 30004 # NodePort 类型的端口范围为 30000-32767,可以根据需要调整
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: elasticsearchhead
namespace: es
spec:
replicas: 1
selector:
matchLabels:
app: elasticsearchhead
template:
metadata:
labels:
app: elasticsearchhead
spec:
containers:
- name: elasticsearchhead
image: mobz/elasticsearch-head:5
ports:
- containerPort: 9100
---
apiVersion: v1
kind: Service
metadata:
name: elasticsearchhead-service
namespace: es
spec:
type: NodePort
ports:
- port: 9100
targetPort: 9100
nodePort: 30910 # 可根据需要选择合适的端口号
selector:
app: elasticsearchhead
上述Kubernetes配置文件定义了Elasticsearch集群的部署,使用StatefulSet来管理其有状态的Pod。
配置说明
1. 命名空间 (Namespace)
- 创建一个命名空间es,用于组织和隔离Elasticsearch资源。
2. ConfigMap
- 创建一个ConfigMap,用于存储Elasticsearch的配置文件elasticsearch.yml。
3. StatefulSet
- StatefulSet 用于部署和管理有状态应用。
- 包含5个副本(replicas),每个副本都有唯一的标识符(如elasticsearch-0)。
- 使用初始化容器(initContainers)来处理权限、系统参数和文件描述符的设置。
- 定义了主容器elasticsearch,并指定了环境变量、资源请求和限制,以及挂载数据卷。
4. Services
- 创建了一个无头服务elasticsearch-cluster,用于Pod之间的内部通信。
- 创建了一个NodePort服务elasticsearch,暴露9200端口到集群外部。
- 为每个StatefulSet的Pod创建单独的NodePort服务,分别暴露在不同的端口(30000-30004),用于直接访问特定的Pod。
5. Elasticsearch Head 部署和服务
- 部署Elasticsearch Head插件,用于图形化管理和浏览Elasticsearch集群。
- 暴露Elasticsearch Head的9100端口,使用NodePort类型服务,端口号为30910。
2、部署 Elasticsearch
执行下面的命令
3、查看Pod状态
执行下面的命令

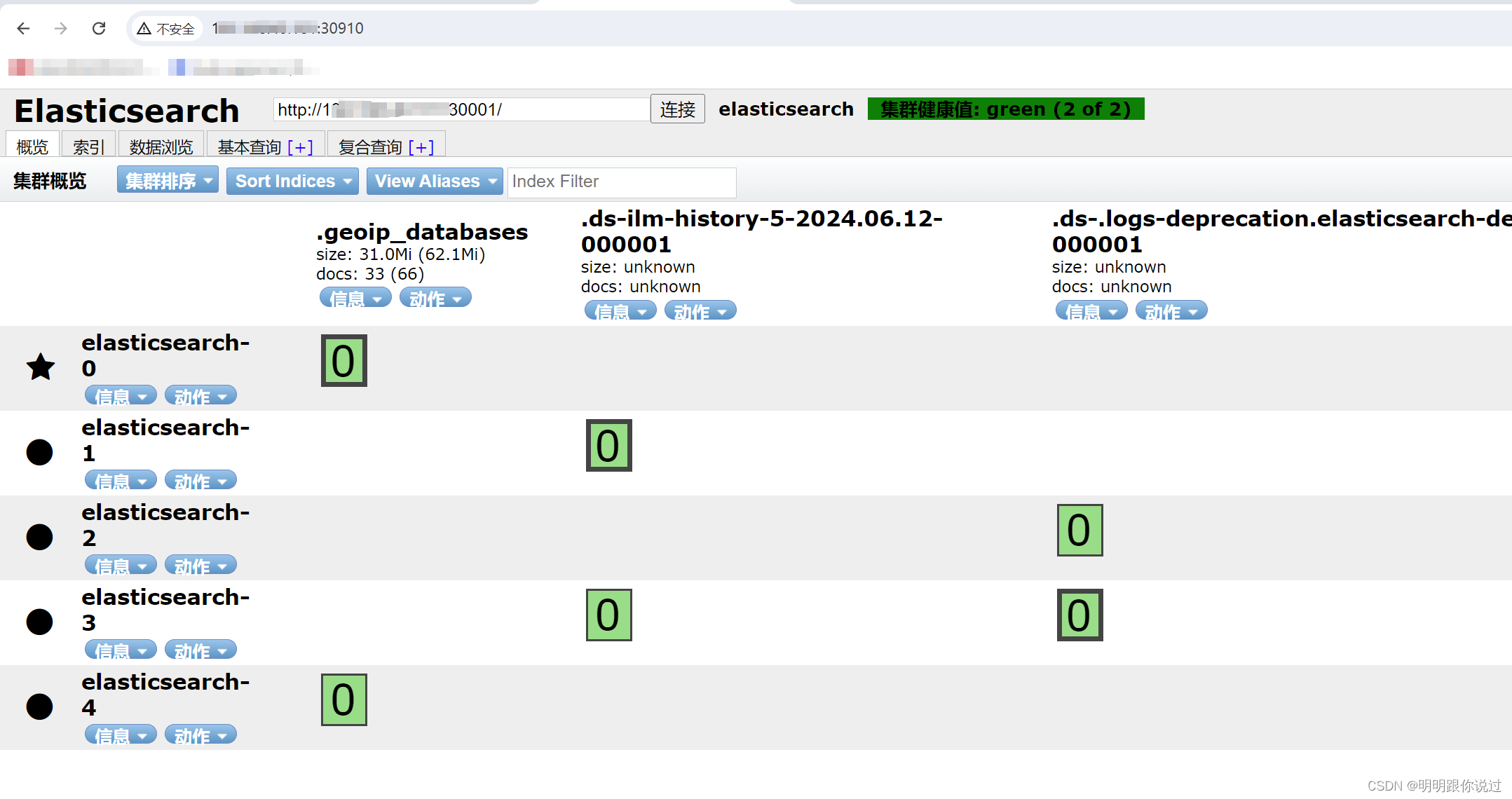
4、访问测试
查看svc的nodeport端口

在浏览器输入Node的IP加30910端口
在连接窗口输入 Node的IP加30001端口,点击连接
如果能显示下面的结果,则集群部署成功
💕💕💕每一次的分享都是一次成长的旅程,感谢您的陪伴和关注。希望这些关于Elasticsearch的文章能陪伴您走过技术的一段旅程,共同见证成长和进步!😺😺😺
🧨🧨🧨让我们一起在技术的海洋中探索前行,共同书写美好的未来!!!
版权归原作者 明明跟你说过 所有, 如有侵权,请联系我们删除。