
一:简化
1. 新建common 包 新建diver.py
封装浏览器驱动类
from selenium import webdriver
class Driver():
"""
浏览器驱动类
定义 一个【获取浏览器驱动对象driver的方法】。支持多种类型浏览器
"""
def get_driver(self,browser_type):
if browser_type == 'chrome':
self.driver = webdriver.Chrome()
elif browser_type == 'Firefox':
self.driver = webdriver.Firefox()
# 最大化窗口、隐式等待、最大加载时长
self.driver.maximize_window()
self.driver.implicitly_wait(20)
self.driver.set_page_load_timeout(20) # 页面加载时长, 超时则停止,避免因页面加载过慢而拖延整个测试流程
return self.driver
新建configs包,config.py
把超时时间,隐式等待时间写到配置里
两种写配置的方式,都行
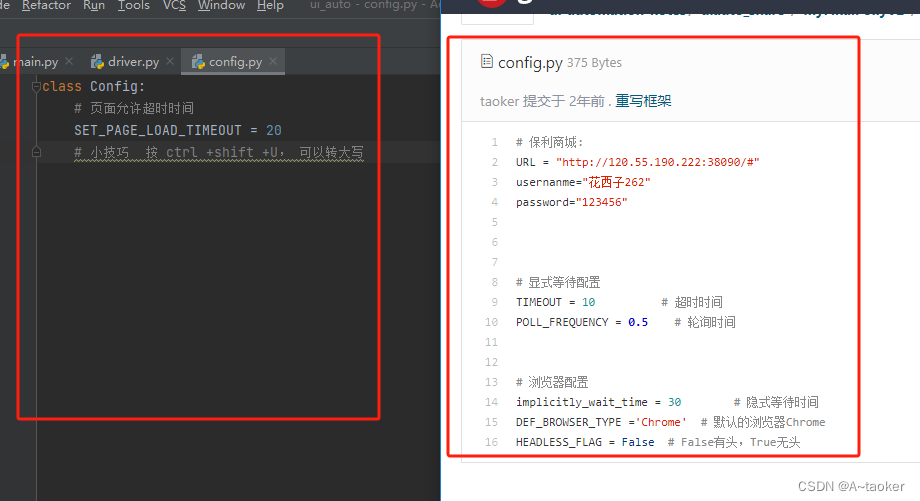
# 页面允许超时时间 小技巧 按 ctrl +shift +U, 可以转大写
SET_PAGE_LOAD_TIMEOUT = 20
# 默认浏览器类型
DEF_BROWSER_TYPE = 'chrome'
我用第二种方式,那么在driver.py 中,就这么导入
from configs.config import SET_PAGE_LOAD_TIMEOUT,DEF_BROWSER_TYPE
driver.py 中,引入config的配置的时间,引用config中配置的浏览器类型
from selenium import webdriver
from configs.config import SET_PAGE_LOAD_TIMEOUT,DEF_BROWSER_TYPE
class Driver():
"""
浏览器驱动类
定义 一个【获取浏览器驱动对象driver的方法】。支持多种类型浏览器
"""
def get_driver(self,browser_type = DEF_BROWSER_TYPE):
if browser_type == 'chrome':
self.driver = webdriver.Chrome()
elif browser_type == 'Firefox':
self.driver = webdriver.Firefox()
# 最大化窗口、隐式等待、最大加载时长
self.driver.maximize_window()
self.driver.implicitly_wait(20)
self.driver.set_page_load_timeout(SET_PAGE_LOAD_TIMEOUT) # 页面加载时长, 超时则停止,避免因页面加载过慢而拖延整个测试流程
return self.driver
2. 新建页面基类
在common包中,新建basePage.py , BasePage类,
表示页面基类, 把不同的页面,能做的同样的事情,都封装在这个类中。
**new_Driver() **方法,返回的是driver,页面类示例对象就可以用到
back() ,表示二次封装的回退方法
get_element(), 表示定位方法
input_text ,表示文本框的输入方法
暂时先写这么多,还可以封装点击, 等等方法
from common.driver import Driver
class BasePage:
"""
页面基类:不同的页面 能做同样的事,封装在这个类中
打开浏览器、进入页面、定位元素、点击、输入等
"""
def __init__(self):
self.driver = Driver().get_driver() # 这个就表示打开浏览器
# 打开网址
def open_url(self,url): # 二次封装,提供更多的可能性
self.driver.get(url)
# 定位到元素
def get_element(self,locator):
"""
:param locator: 如: 'id','kw'
:return:
"""
return self.driver.find_element(*locator)
# 输入文本
def input_text(self,locator,text,append=False):
# 默认:清空后输入
if not append:
self.get_element(locator).clear()
self.get_element(locator).send_keys(text)
# 否则是追加输入
else:
self.get_element(locator).send_keys(text)
# 返回driver对象, 让页面对象灵活操作
def new_Driver(self):
return self.driver
# 倒退
def back(self):
self.driver.back()
3.新建pages包
一个页面一个py文件, 在pages目录下,
新增baidu_page.py
表示 百度的页面,里面
有纯元素,比如下面的 “【百度一下】 按钮元素”
有元素做动作的方法,“输入框输入文本”
在main中,可以进行调试
from common.basePage import BasePage
# 继承基类
class BaiduPage(BasePage):
def open_baidu_page(self):
# self.open_url(f"{URL}/login")
self.open_url("https://www.baidu.com/")
return self # 返回后,可以链式调用 BaiduPage().open_baidu_page().login_polly('花西子262','123456')
# (动作)输入框输入xx
def input_ele_input(self,text):
self.input_text(('id','kw'),text)
# (元素) 百度一下 按钮
def submit_ele(self):
return self.get_element(('id','su'))
Baidu_Page_Obj = BaiduPage()
if __name__ == '__main__':
Baidu_Page_Obj = BaiduPage()
# 输入
Baidu_Page_Obj.open_baidu_page().input_ele_input("测试一下")
# 点击确定
Baidu_Page_Obj.submit_ele().click()
新建sahitest_page.py
再新增一个页面,其中,封装了两个元素
main 中
- 点击一个元素,然后 使用 basePage中封装的 back方法,回退
- 再点击另一个元素,使用basePage中,先获取到driver,然后再用driver
import time
from common.basePage import BasePage
# 继承基类
class SahiTestPage(BasePage):
def open_sahi_page(self):
self.open_url("https://sahitest.com/demo/")
return self
# (元素1)
def _ele1(self):
return self.get_element(("link text",'Drag Drop Test'))
# (元素2)
def _ele2(self):
return self.get_element(("link text",'Alert Test'))
sihi_Page_Obj = SahiTestPage()
if __name__ == '__main__':
sihi_Page_Obj = SahiTestPage()
# 打开网址
sihi_Page_Obj= sihi_Page_Obj.open_sahi_page()
# 点击一个元素
sihi_Page_Obj._ele2().click()
time.sleep(2)
# 回退 (使用封装的back方法)
sihi_Page_Obj.back()
# 点击第二个元素
sihi_Page_Obj._ele1().click()
time.sleep(2)
# 回退(使用dirver对象 的)
sihi_Page_Obj.new_Driver().back()
4 . 新建testCases包。
新建test_demo1.py
一个py文件就用来写一个 页面的测试用例,可以这么设计,那这个就写百度页面的测试用例。
我就直接两个用例,对应两个页面了
- 用例1: 百度页面 输入 CSDN,百度一下
- 用例2: sahitest页面,点击一个, 回退,点击另一个,再回退
from pages.baidu_page import Baidu_Page_Obj
from pages.sahitest_page import sihi_Page_Obj
import time,pytest
class Test_Demo():
def test_case1(self):
"""打开百度"""
Baidu_Page_Obj.open_baidu_page().input_ele_input("CSDN")
Baidu_Page_Obj.submit_ele().click()
time.sleep(1)
def test_case2(self):
"""打开sihitest网页"""
time.sleep(1)
sihi_Page_Obj.open_sahi_page()
# 点击一个元素
sihi_Page_Obj._ele2().click()
time.sleep(2)
# 回退 (使用封装的back方法)
sihi_Page_Obj.back()
# 点击第二个元素
sihi_Page_Obj._ele1().click()
time.sleep(2)
# 回退(使用dirver对象 的)
sihi_Page_Obj.new_Driver().back()
if __name__ == '__main__':
pytest.main([__file__])
pytest的知识,要执行main中的代码要设置pycharm:不明白可以看 【自动化总结1】pytest使用整理
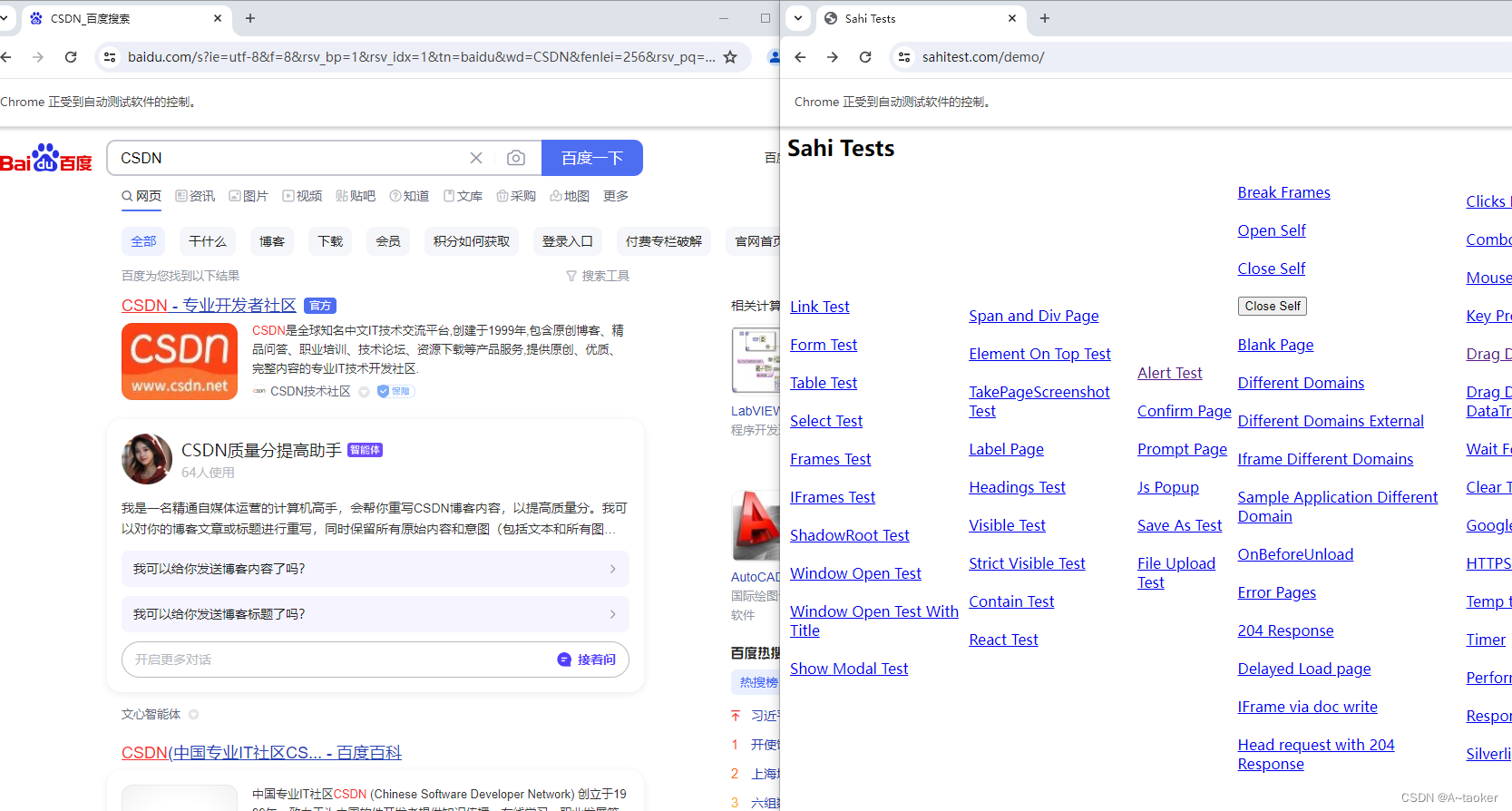
执行时,会完成测试用例 ,但是会打开两个浏览器。这个是可以去解决的问题
二:升级
集中管理元素定位、解决打开多个浏览器问题(如果只打开一次,就只登录一次就够了) 、
升级1:补充basePage,基类中的方法
get_element 查找元素,用显示等待
driver.py中,代码补充。get_element 查找元素,用显示等待的方式来查
# 定位到元素
def get_element(self,locator):
"""
:param locator: 如: 'id','kw'
:return:
"""
# return self.driver.find_element(*locator)
# 改用下面的显示等待的定位
return WebDriverWait(driver=self.driver, timeout=10, poll_frequency=0.5).until(
EC.visibility_of_element_located(locator))
和 get_elements 获取元素列表
def get_elements(self, locator):
# ------------这段代码生效否,有待考究----------------------
WebDriverWait(
# 传入浏览器对象
driver=self.driver,
# 传入超时时间
#timeout=TIMEOUT, # 可以写到配置里
timeout=10,
# 传入轮询时间
# poll_frequency=POLL_FREQUENCY).until( # 也可以写到配置里
poll_frequency=0.5).until(
EC.visibility_of_element_located(locator))
# ------------这段代码生效否,有待考究----------------------
# 返回元素列表
return self.driver.find_elements(*locator)
再添加一个点击元素的方法。和获取元素文本的方法
# 点击元素
def click_element(self,locator):
self.get_element(locator).click()
# 获取元素文本信息(用来断言)
def get_element_text(self, locator):
# 获取元素文本(查找元素时,已经做了等待)
return self.get_element(locator).text
def get_elements_text(self,locator):
#遍历得到每个元素的text
return [ele.text for ele in self.get_elements(locator)]
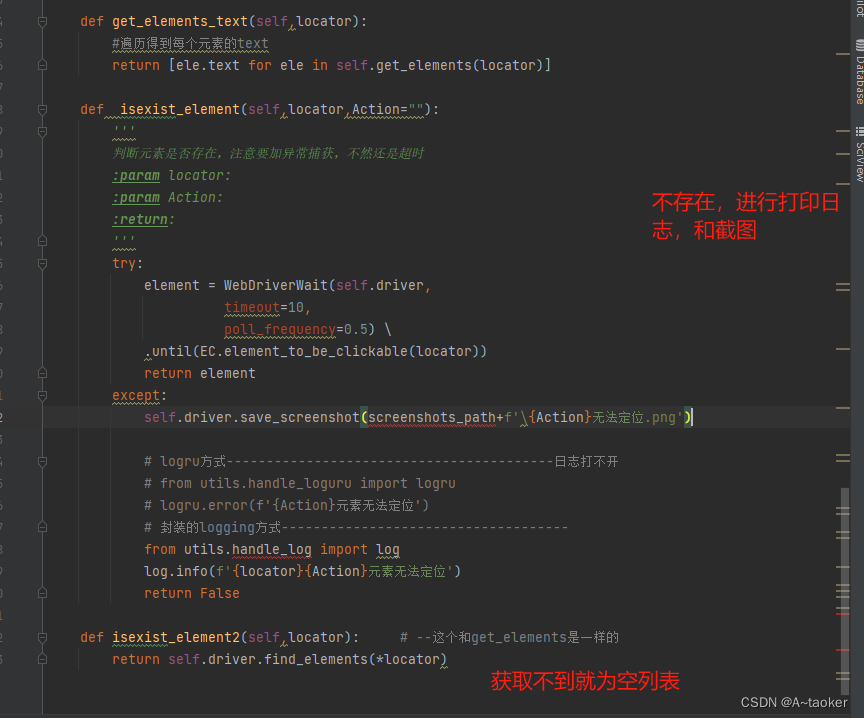
写判断元素是否存在方法
def isexist_element(self,locator,Action=""):
'''
判断元素是否存在,注意要加异常捕获,不然还是超时
:param locator:
:param Action:
:return:
'''
try:
element = WebDriverWait(self.driver,
timeout=10,
poll_frequency=0.5) \
.until(EC.element_to_be_clickable(locator))
return element
except:
self.driver.save_screenshot(screenshots_path+f'\{Action}无法定位.png')
# logru方式-----------------------------------------日志打不开
# from utils.handle_loguru import logru
# logru.error(f'{Action}元素无法定位')
# 封装的logging方式------------------------------------
from utils.handle_log import log
log.info(f'{locator}{Action}元素无法定位')
return False
def isexist_element2(self,locator): # --这个和get_elements是一样的
return self.driver.find_elements(*locator)
升级2:封装使用 元素定位器的yml文件or py文件
pages中写 login_page.py ,定位器写死
来写一次登录页,首先先把元素定位器写死
from selenium.webdriver.common.by import By
from common.basePage import BasePage
from configs.config import HOST
class LoginPage(BasePage):
# 打开登录页面
def open_loginpage(self):
self.open_url(f"{HOST}/#/login")
# def login_polly(self, username, password):
# # 定位器是通过基类定义的方法获取的
# # self.input_text([By.ID, 'username'], username)
# time.sleep(0.5)
# self.input_text(self.username_input, username)
# time.sleep(0.5)
# self.input_text(self.password_input, password)
# time.sleep(0.5)
# self.click_element(self.login_button)
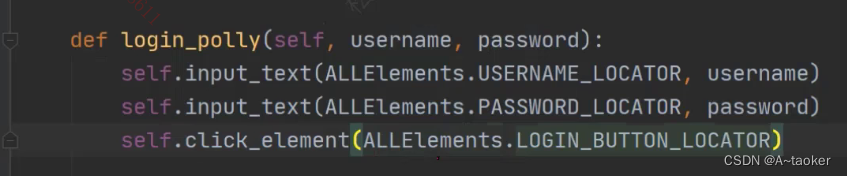
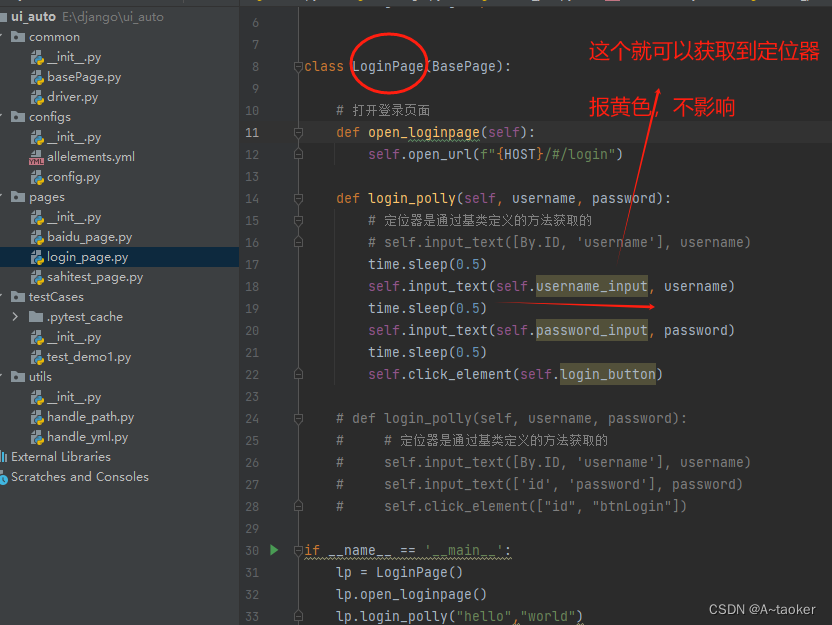
def login_polly(self, username, password):
# 定位器是通过基类定义的方法获取的
self.input_text([By.ID, 'username'], username)
self.input_text(['id', 'password'], password)
self.click_element(["id", "btnLogin"])
if __name__ == '__main__':
lp = LoginPage()
lp.open_loginpage()
lp.login_polly("hello","world")
管理定位器方式1(推荐):
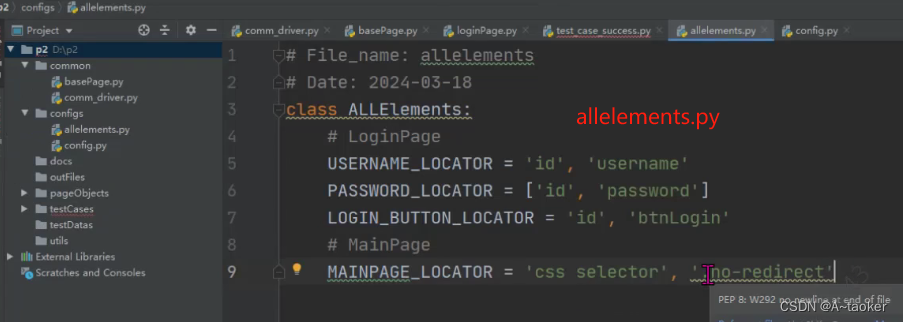
新建 allelements.py 文件中。
按如下的方式,就是所有的页面的元素都写在一个类中。 还有一种思路可以尝试,一个页面一个类,这样就和yml方式一样了,更加的易读。
然后 login_page.py 中, 去读取配置。
管理定位器方式2 :使用yml文件(太复杂,没必要)
方式: 目标是在页面基类中的init方法中,就直接能获取各自页面的定位器。
1.在configs中,新建 allelements.yml
其中: LoginPage就表示 登录页, MainPage表示首页。 后续在定义页面类时,就要写同样的类名
LoginPage: # 登录页面 这个key要和 class页面类名一致
username_input : ["id", username] # 用户输入框 会默认成字符串
password_input: ["id", "password"] # 密码输入框
login_button: ["id", "btnLogin"] # 登录按钮
message_text: [ 'css selector','.el-message--error' ] #登录错误消息文本
message_text_less: [ 'css selector','.el-form-item__error' ] #密码不能小于3位
MainPage: #首页
home_button: [ 'xpath','//*[text()="首页"]' ] #首页按钮
logout_button: [ 'xpath',"//span[text()='退出']" ] #退出按钮
personal_button: [ 'xpath','//img' ] #个人中心按钮
menu_productmanage: [ 'xpath',"//span[text()='商品管理']" ]
submenu_pm_productlist: [ 'xpath',"//span[text()='商品列表']" ]
submenu_pm_addproduct: [ 'xpath',"//span[text()='添加商品']" ]
submenu_pm_productkind: [ 'xpath',"//span[text()='商品分类']" ]
submenu_pm_producttype: [ 'xpath',"//span[text()='商品类型']" ]
submenu_pm_brandmanage: [ 'xpath',"//span[text()='品牌管理']" ]
submenu_pm_productattr: [ 'xpath',"//span[text()='商品规格']" ]
submenu_pm_productgift: [ 'xpath',"//span[text()='赠礼列表']" ]
submenu_pm_productconsult: [ 'xpath',"//span[text()='商品评论']" ]
menu_ordermanage: [ 'xpath',"//span[text()='订单管理']" ]
menu_membermanage: [ 'xpath',"//span[text()='会员管理']" ]
today_orders: [ 'css selector','.el-row > div:nth-child(1) .total-value' ] #今日下单数
today_sales: [ 'css selector','.el-row > div:nth-child(2) .total-value' ] #今日销售总额
today_product: [ 'css selector','.el-row > div:nth-child(3) .total-value' ] #今日商品数
today_members: [ 'css selector','.el-row > div:nth-child(4) .total-value' ] #今日会员
2. 新建utils包,新建 handle_path.py
有了它,路径大概率不会出错。
f'{config_path}/allelements.yml' 这样就表示定位器的路径
import os
"""
需求: 代码在任意路径都可以获取到项目工程的绝对路径
"""
"""工程路径"""
project_path = os.path.dirname( os.path.dirname(os.path.abspath(__file__)))
"""配置路径"""
config_path = os.path.join(project_path,'configs')
"""测试数据路径"""
# case_data_path = os.path.join(project_path,'datas')
# logs_path = os.path.join(project_path,'outFiles\logs')
# screenshots_path = os.path.join(project_path,'outFiles\screenshots')
# reports_path = os.path.join(project_path,'outFiles\\reports')
common_path = os.path.join(project_path,'common')
testcase_path = os.path.join(project_path,'testCases')
if __name__ == '__main__':
print(common_path)
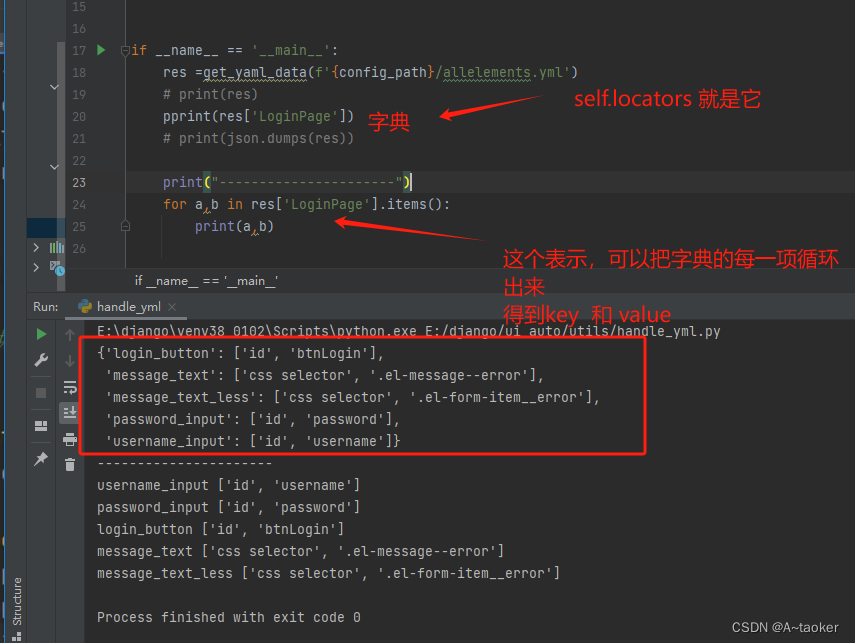
3. 在utils包中,新建 handle_yml.py
里面写一个获取yml文件的方法。 获取出来得到 字典的形式, 长下面这个样子

- 在basePage.py 中, 更新init方法。
from utils.handle_path import config_path
from utils.handle_yml import get_yaml_data
class BasePage:
"""
页面基类:不同的页面 能做同样的事,封装在这个类中
打开浏览器、进入页面、定位元素、点击、输入等
"""
def __init__(self):
self.driver = Driver().get_driver() # 这个就表示打开浏览器
"""
1.读取yml配置文件中各个页面的定位器
- 哪个页面类继承basepage,就能得到哪个页面的定位器
- 通过 self.__class__.__name__ 获取当前类名
"""
self.locators = get_yaml_data(f'{config_path}/allelements.yml')[self.__class__.__name__]
# 设置 实例 element_name 属性 的值是locator ----有利于代码编写
for element_name, locator in self.locators.items():
setattr(self, element_name, locator)
解析:其中:self.locators 就是一个字典。 把 键和值获取出来。
再用 setattr 设置成属性对。, 把他们变成属性,就可以通过,对象.属性,就能获取
4.使用定位器
首先类名要LoginPage和 yml文件中的是一致的、这样也可以运行, 这么做的好处时,页面元素好管理,代码也好读。
解决这个黄的,可以这么搞
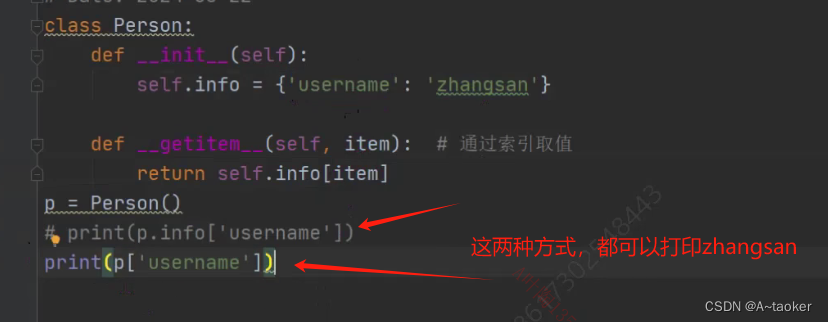
再basePage中,加
def __getitem__(self,item):
return self.locators[item]
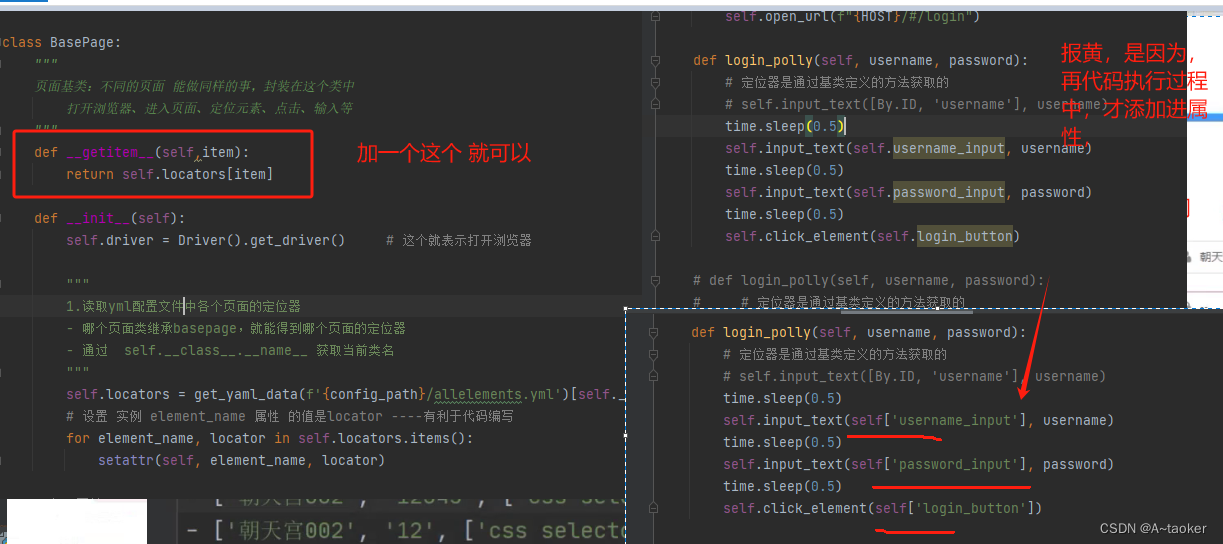
5.yml的优势和弊端分析
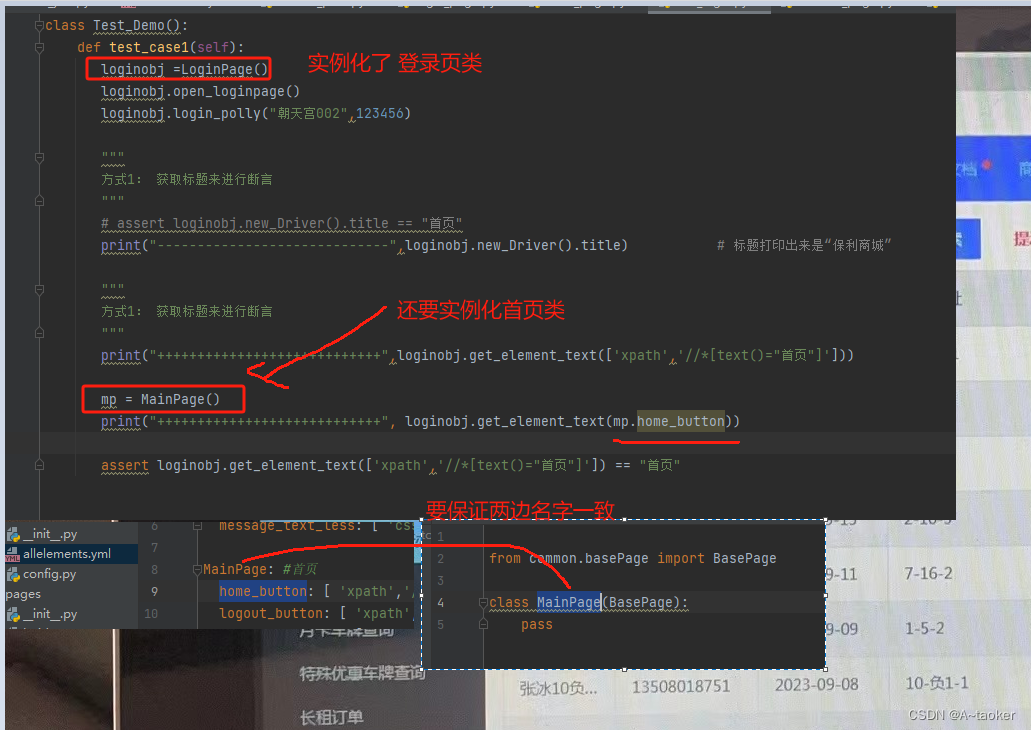
这种方式,是把定位器强行绑定到类 身上。可以通过类对象来获取, 代码上好读一点。
但是每次需要实例化一个类对象,才能使用,
比如这里的例子,它是登录页,登录成功后进入了首页。 代码中就必须要实例化一个首页类,才能拿到首页的定位器。并且还需要保持 yml文件中的名称 和类名一致,有点麻烦
升级3:控制运行用例时,只打开一个浏览器
之前为什么打开两个浏览器
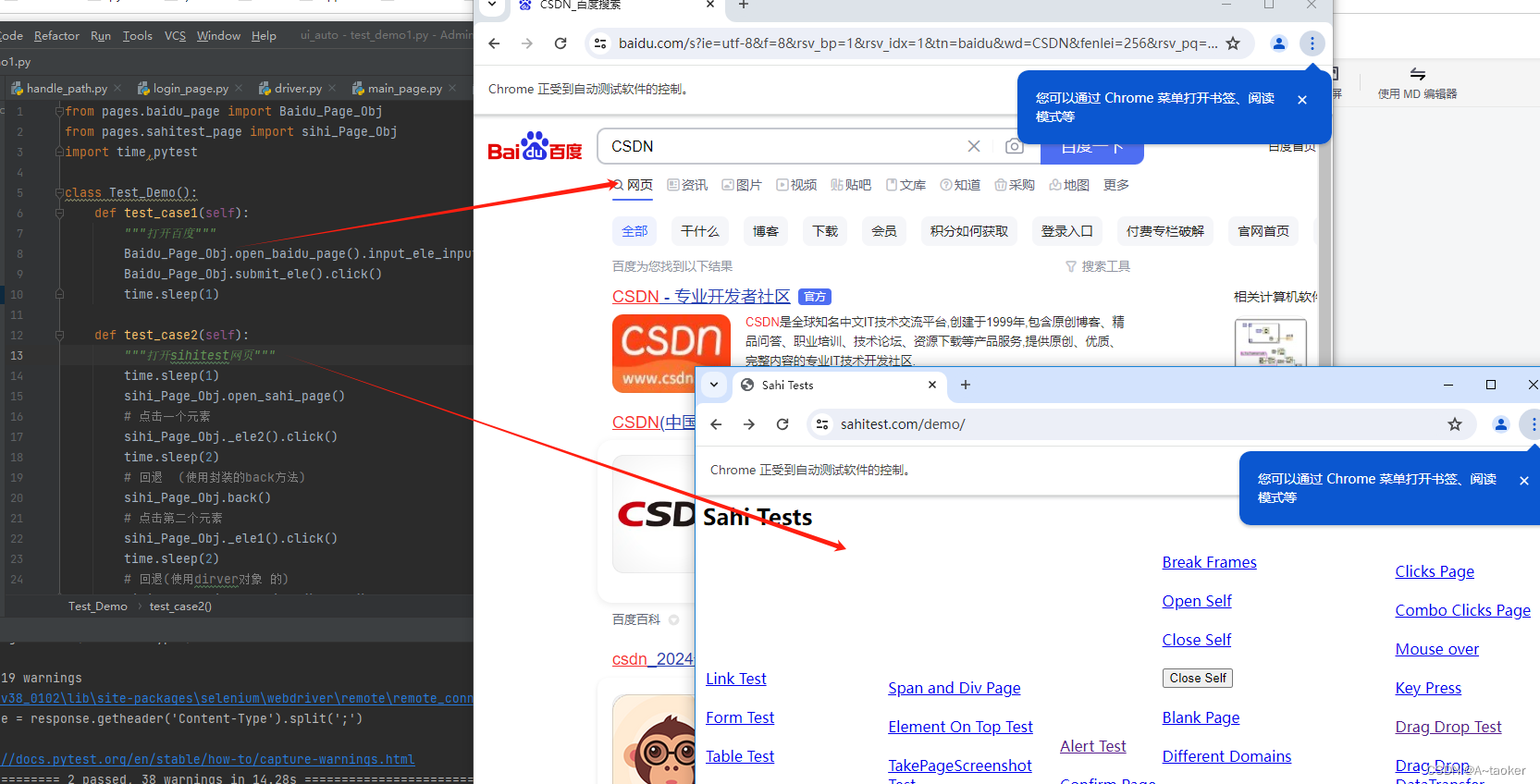
能看到代码,进行两次测试用例时,都进行了一次实例化,每次实例化一下,都会走一次 get_driver方法
1. 修改成单例模式(不推荐,暂时不好理解)
单例的大概意思,就是这样写后,表示这个类只有一个实例对象, 目的是想要只有一个 self.driver
写一个单例类,并且Driver继承它
class Single:
def __new__(cls, *args, **kwargs):
if not hasattr(cls,'instance'):
cls.instance = super().__new__(cls, *args, **kwargs)
return cls.instance
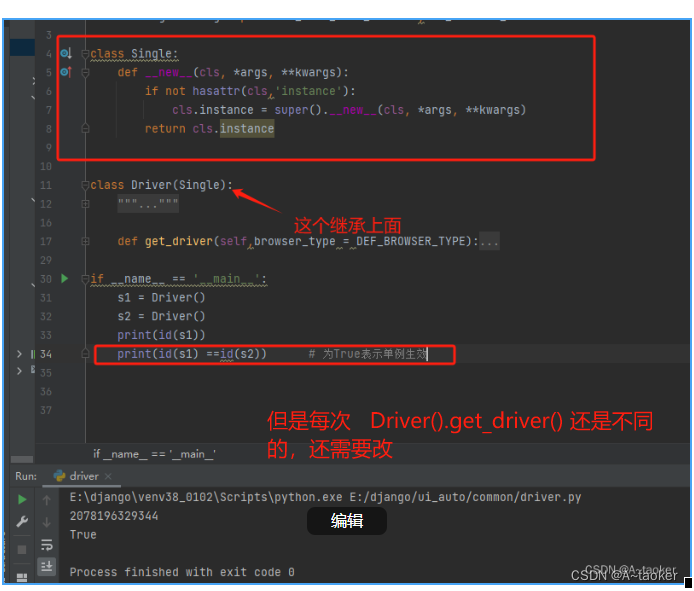
还需要修改修改
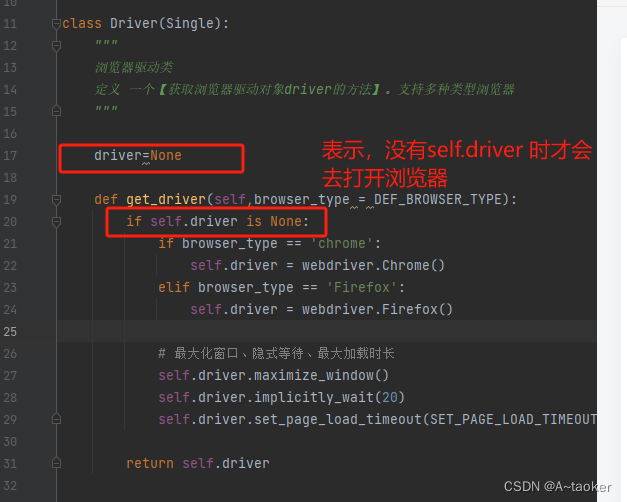
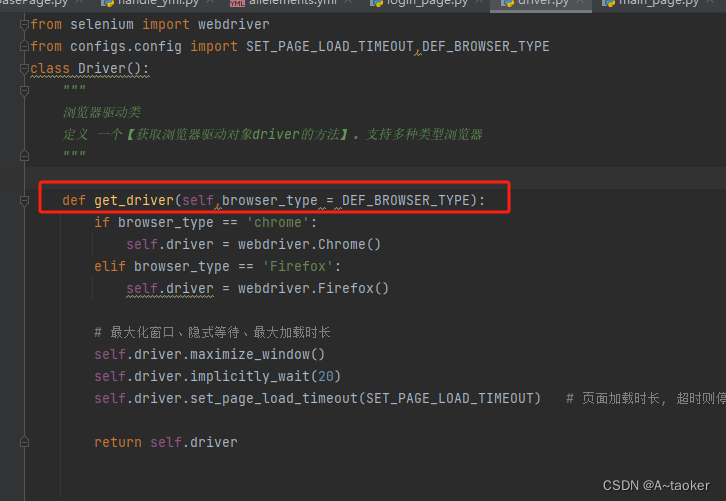
2. 把get_driver设置为类方法(推荐)
这样也能保证只有一个 cls.driver
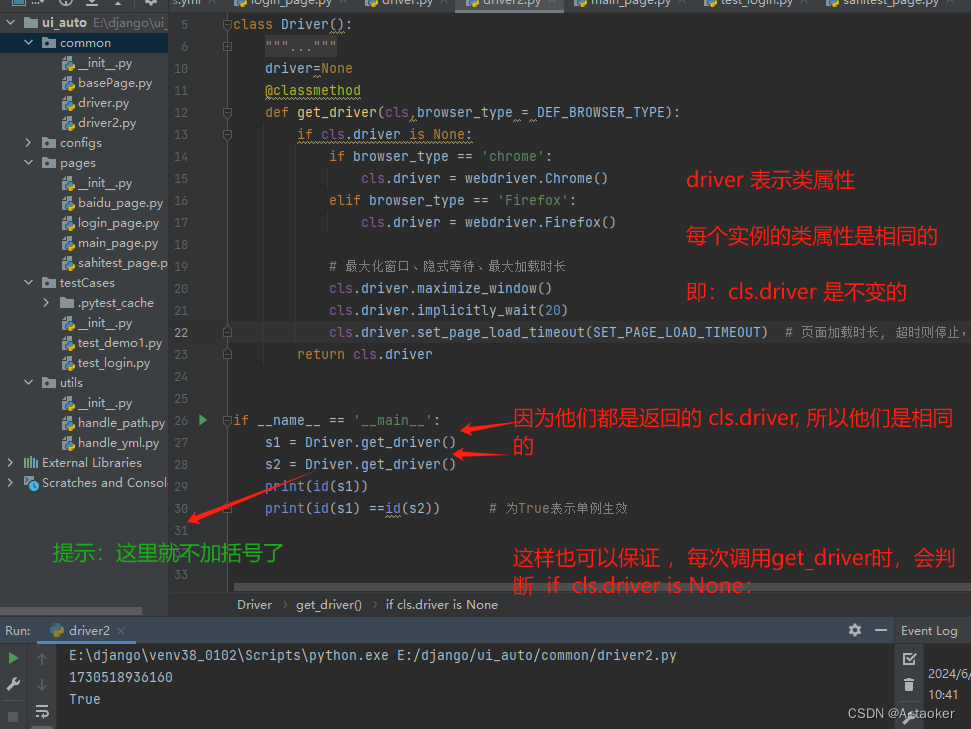 上图的绿色不对,应该是不加括号,加括号都可以,表示类或者实例都能调用这个方法
上图的绿色不对,应该是不加括号,加括号都可以,表示类或者实例都能调用这个方法
from selenium import webdriver
from configs.config import SET_PAGE_LOAD_TIMEOUT,DEF_BROWSER_TYPE
class Driver():
"""
浏览器驱动类
定义 一个【获取浏览器驱动对象driver的方法】。支持多种类型浏览器
"""
driver=None
@classmethod
def get_driver(cls,browser_type = DEF_BROWSER_TYPE):
if cls.driver is None:
if browser_type == 'chrome':
cls.driver = webdriver.Chrome()
elif browser_type == 'Firefox':
cls.driver = webdriver.Firefox()
# 最大化窗口、隐式等待、最大加载时长
cls.driver.maximize_window()
cls.driver.implicitly_wait(20)
cls.driver.set_page_load_timeout(SET_PAGE_LOAD_TIMEOUT) # 页面加载时长, 超时则停止,避免因页面加载过慢而拖延整个测试流程
return cls.driver
if __name__ == '__main__':
s1 = Driver().get_driver()
s2 = Driver().get_driver()
print(id(s1))
print(id(s1) ==id(s2)) # 为True表示单例生效
测试场景1:用例中,进行断言
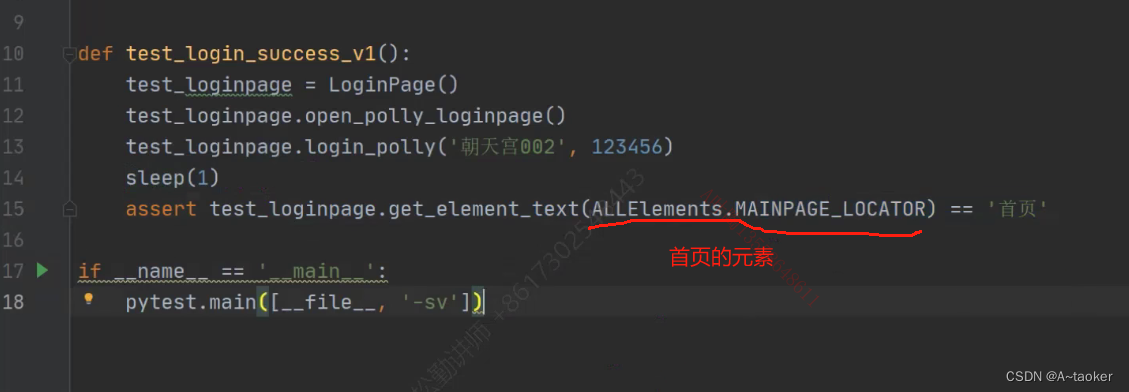
testcases包中,新建test_login_success.py , 从这个文件命名中,可以看出,登录成功的用例会写到这里,登录失败的会写到其他地方。
但我一般,不会反复进行登录,我只会写一个登录成功的用例,执行后,后续就不会执行它了
这里主要介绍下如何断言。新建 test_login.py
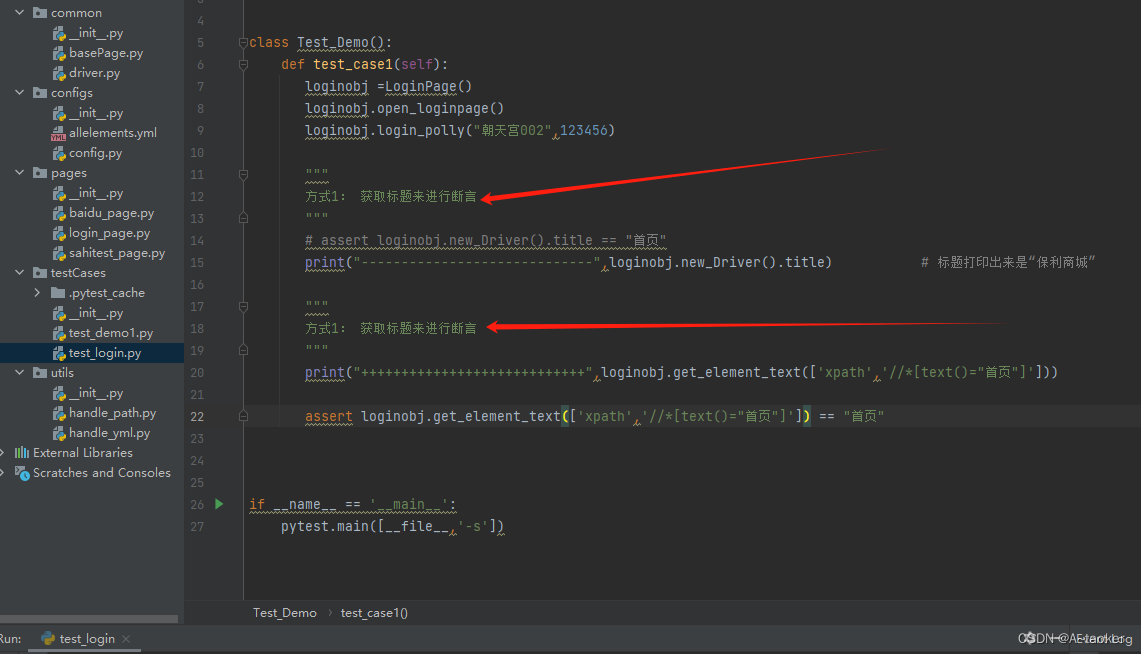
利用。basePage 中定义的获取文本信息来进行断言、 或者获取页面标题,来进行断言
如登录成功后,获取页面标题,判断标题是不是“首页”
from pages.login_page import LoginPage
import pytest
class Test_Demo():
def test_case1(self):
loginobj =LoginPage()
loginobj.open_loginpage()
loginobj.login_polly("朝天宫002",123456)
"""
方式1: 获取标题来进行断言
"""
# assert loginobj.new_Driver().title == "首页"
print("-----------------------------",loginobj.new_Driver().title) # 标题打印出来是“保利商城”
"""
方式1: 获取标题来进行断言
"""
print("++++++++++++++++++++++++++++",loginobj.get_element_text(['xpath','//*[text()="首页"]']))
assert loginobj.get_element_text(['xpath','//*[text()="首页"]']) == "首页"
if __name__ == '__main__':
pytest.main([__file__,'-s'])
测试场景2,在用例中使用数据驱动
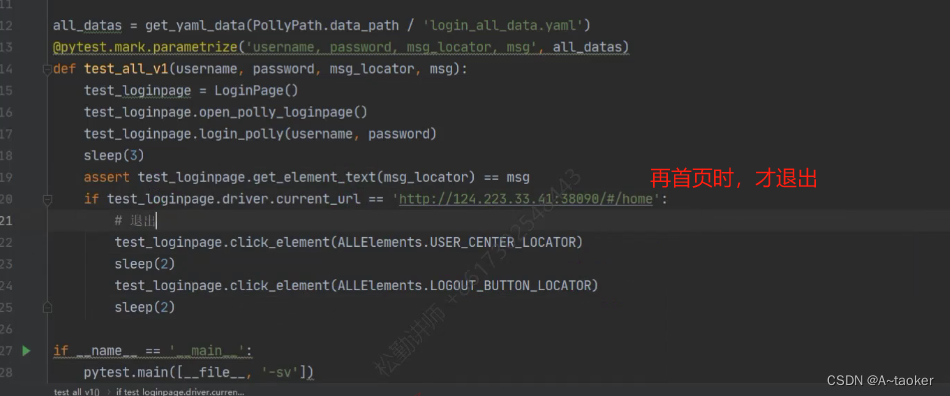
同一个动作要执行多次,要考虑用例清除,比如登录用例,每次登录后要退出到登录页
登录成功时,用退出的方式,没有登录成功时,不用退出
所以登录用例还是有点麻烦(下面看着玩就好),建议不写这种用例,这里只是举例说明可以进行数据驱动
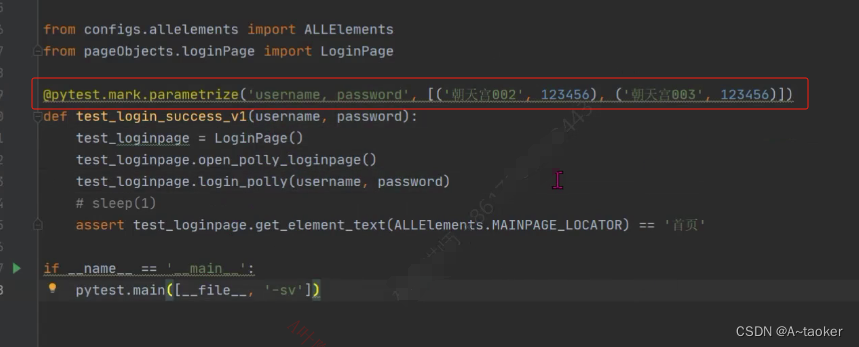
用例恢复
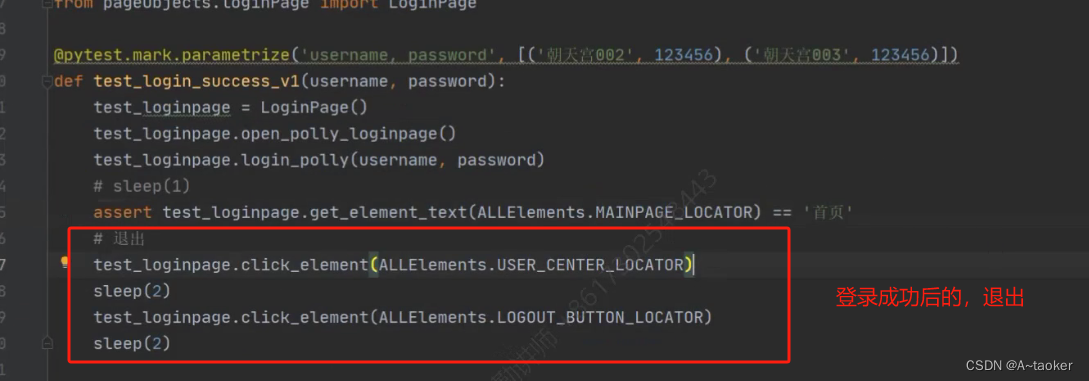
登录用例登录失败的情况
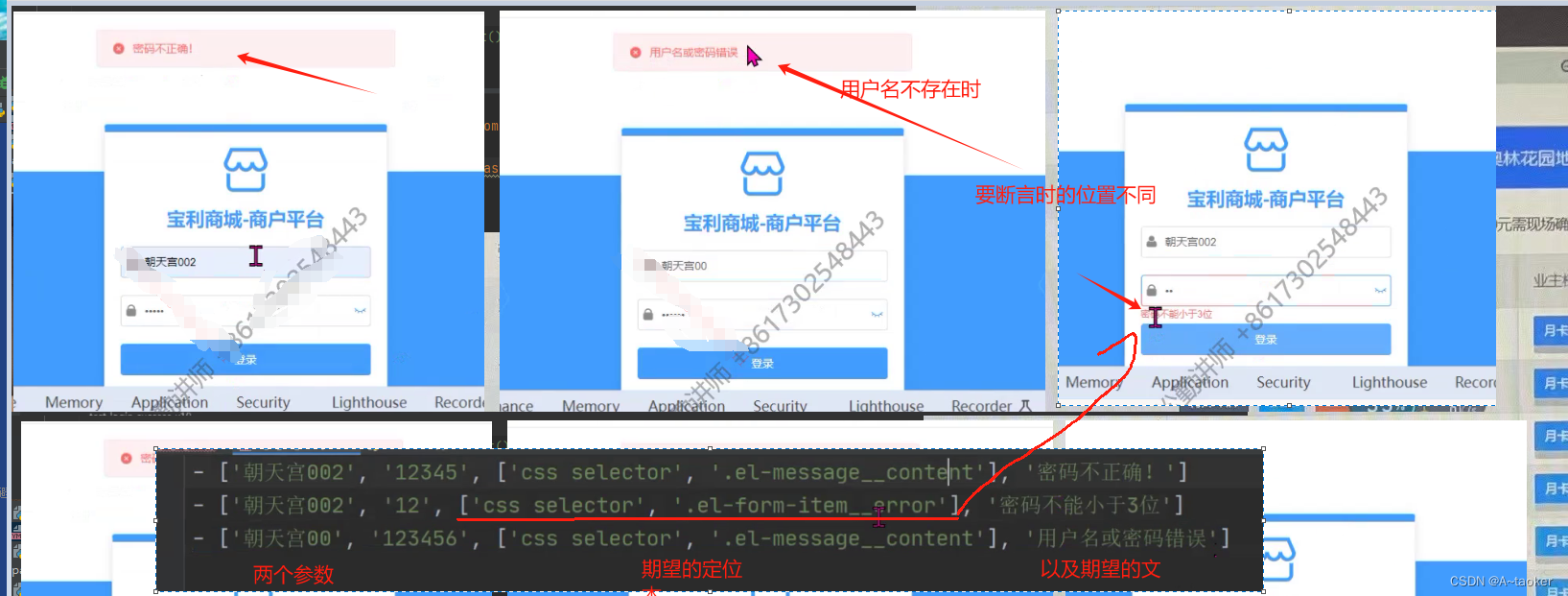
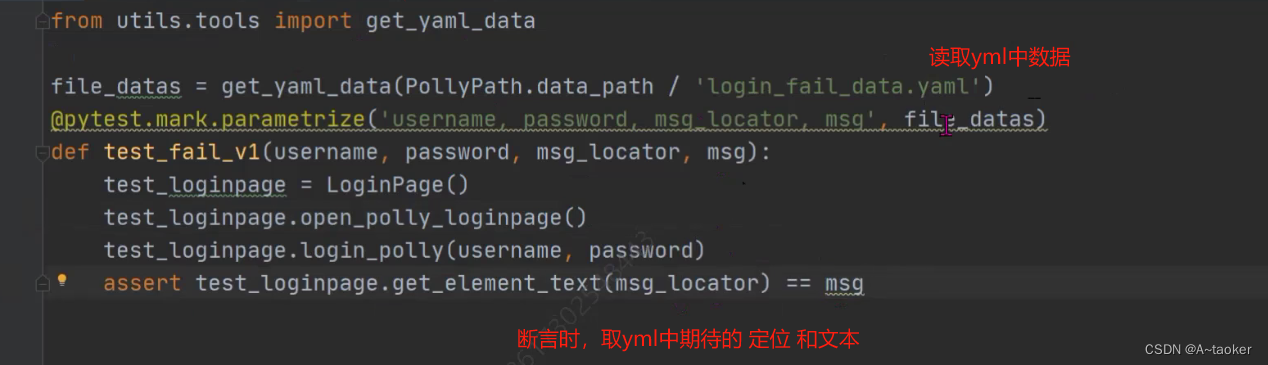
成功和失败都写到参数化里边,同时用例也写到一起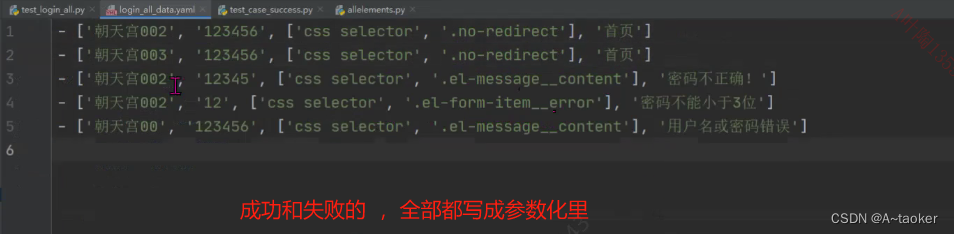
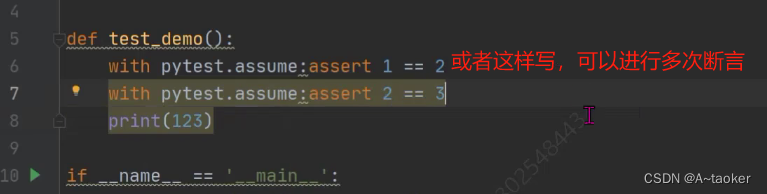
测试场景3:第一个用例失败,如何继续跑后续的用例
参考【自动化总结1】pytest使用整理_cento执行pytest,执行时用unitest-CSDN博客

测试场景4.解决需要登录后操作的问题
**方式1,每个用例都登录 **:
进行添加商品用例,每次先登录一次,然后再首页,一步步点到
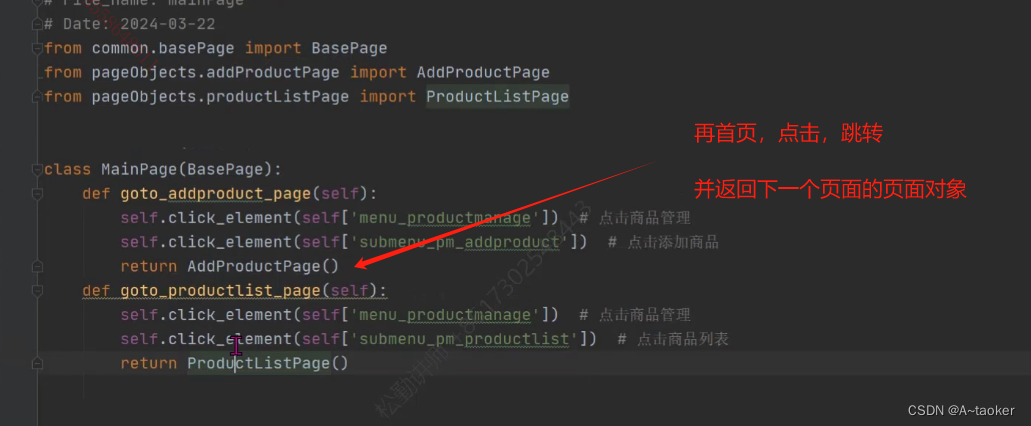
添加商品页面的 添加商品方法
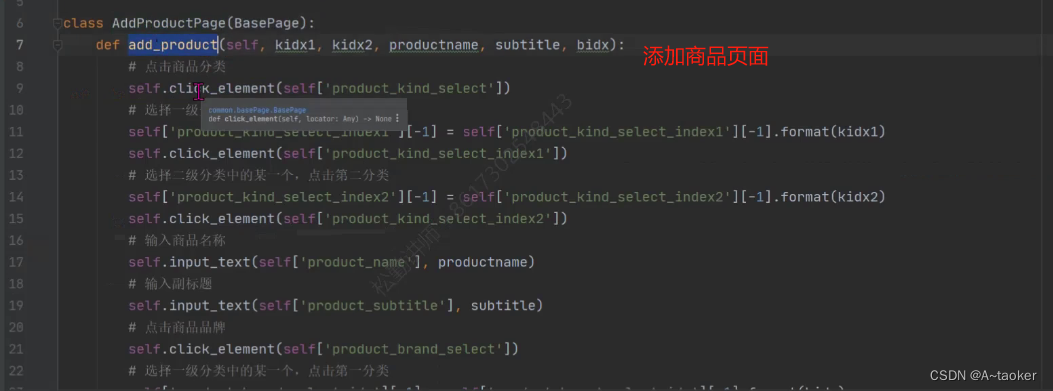
添加商品用例
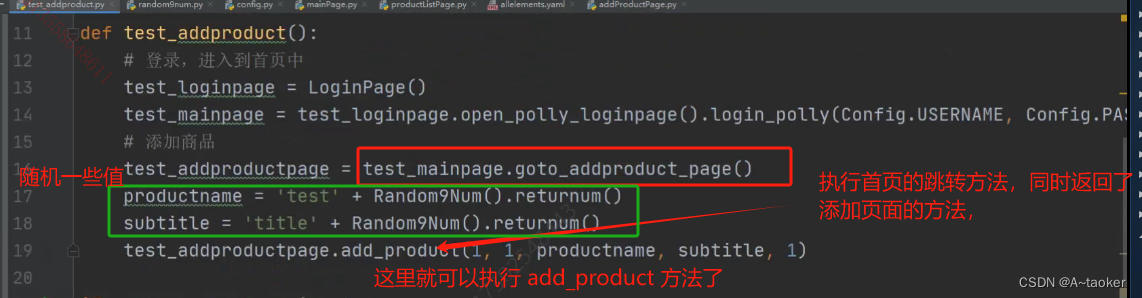
再进入到商品列表页,进行断言
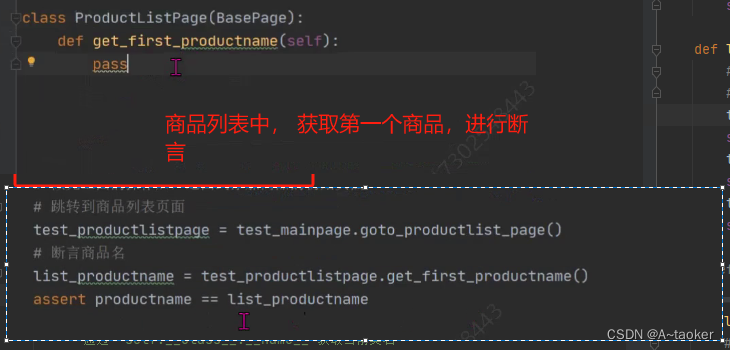
方式2(推荐):
直接写在这里,打开浏览器时,就进行登录,
然后其他页面直接get url 到页面里面去
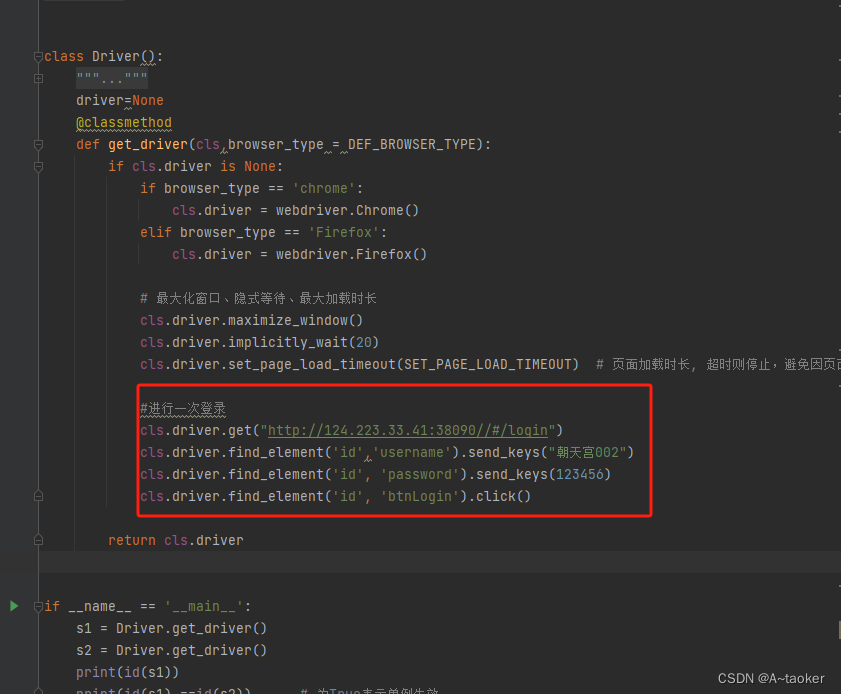
如下图片,可以看出,打开浏览器就登录了一次,后续,直接进入页面操作就好了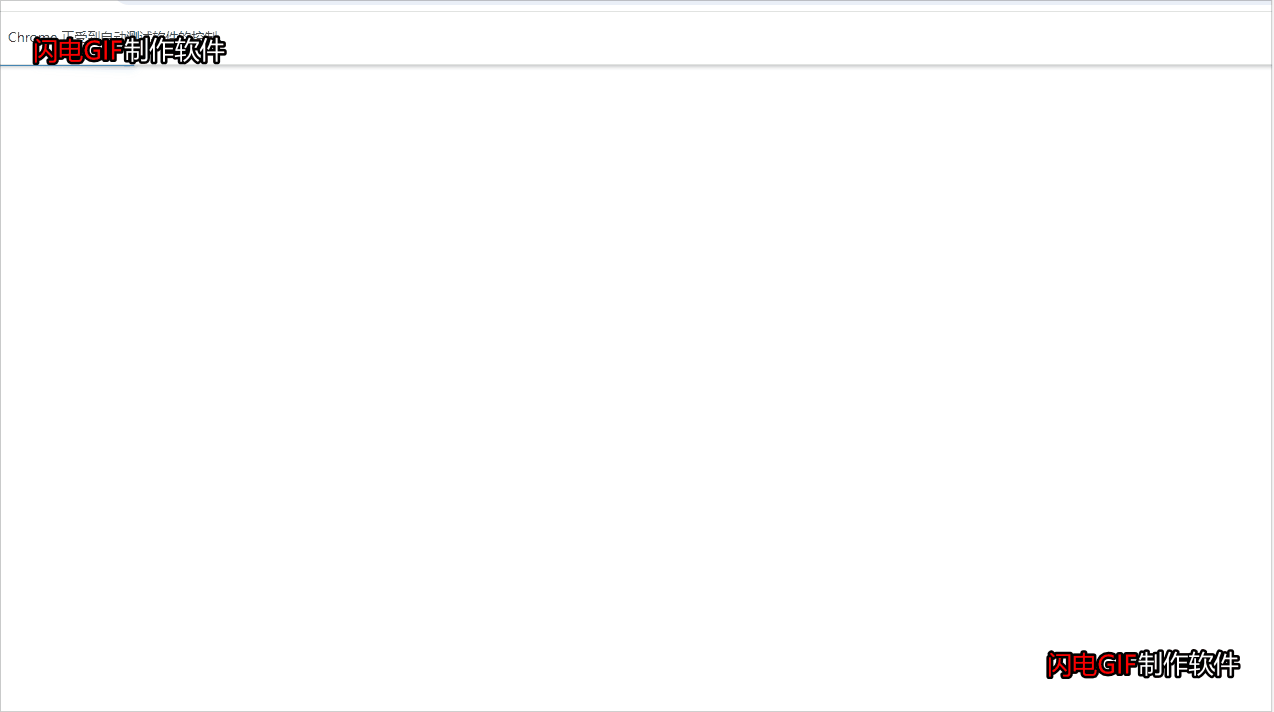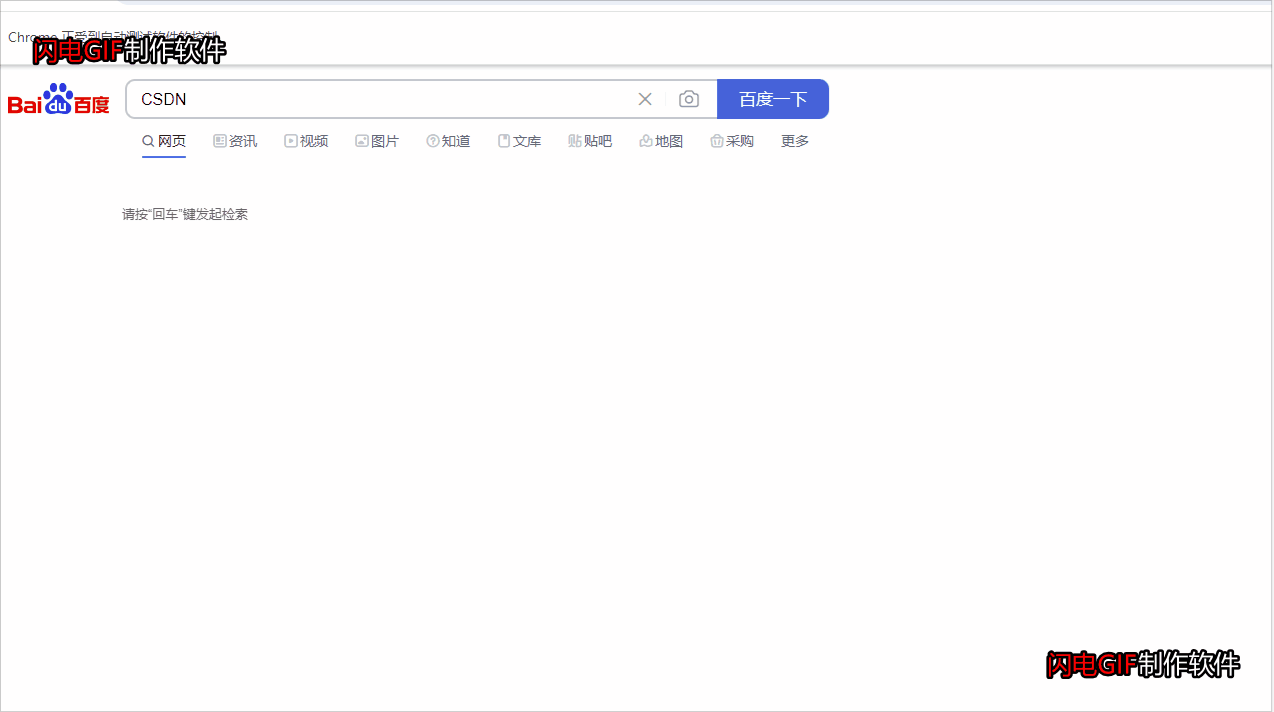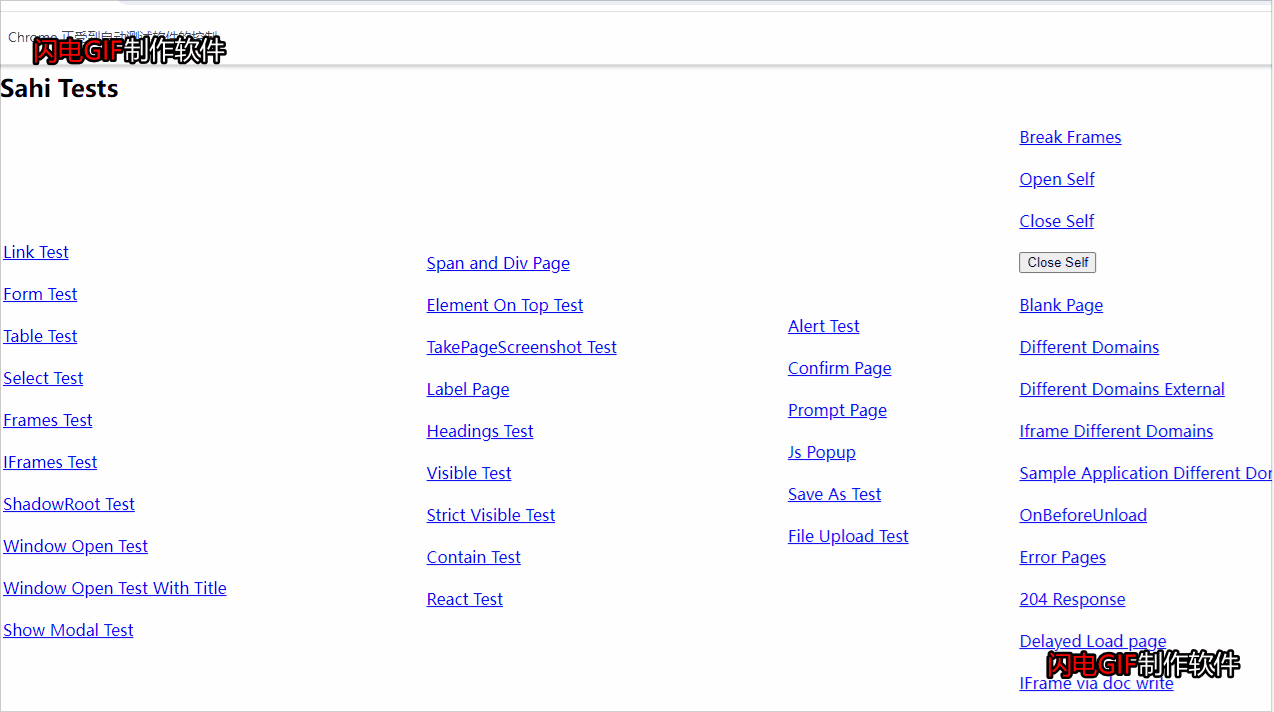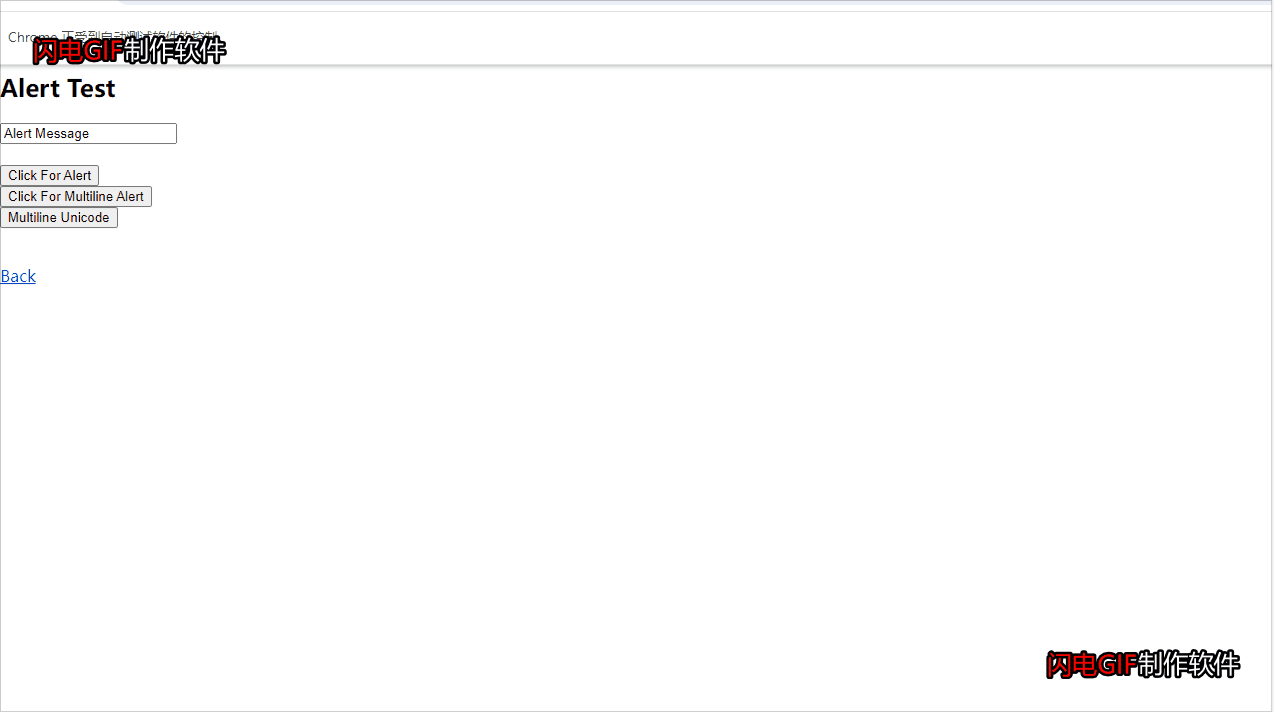
测试场景5: 有些地方需要加日志、
加截图和日志同理
configs包中,新建logru.ini
[log]
format = {time:YYYY-MM-DD HH:mm:ss},{module}(line:{line}),{level}||{message}
level = ERROR
rotation = 10 MB
retention = 2 days
再utils包中,新建handler_log.py
print()
"""
日志相关内容:
1- 日志的输出渠道:文件xxx.log 控制台输出
2- 日志级别: DEBUG-INFO-WARNING-ERROR-CRITICAL
3- 日志的内容:2021-10-20 13:50:52,766 - INFO - handle_log.py[49]:我是日志信息
年- 月 - 日 时:分:秒,毫秒 -级别 -哪个文件[哪行]:具体报错信息
https://www.liujiangblog.com/course/python/71
"""
from time import strftime
import logging
from utils.handle_path import logs_path
#这部分不存在单例
def logger(fileLog=True,name=__name__):
"""
:param fileLog: bool值,如果为True则记录到文件中否则记录到控制台
:param name: 默认是模块名
:return: 返回一个日志对象
"""
#0 定义一个日志文件的路径,在工程的logs目录下,AutoPolly开头-年月日时分.log
logDir = f'{logs_path}/AutoPolly-{strftime("%Y%m%d%H%M")}.log'
#1 创建一个日志收集器对象
logObject = logging.getLogger(name)
#2- 设置日志的级别
logObject.setLevel(logging.INFO)
#3- 日志内容格式
fmt = "%(asctime)s - %(levelname)s - %(filename)s[%(lineno)d]:%(message)s"
formater = logging.Formatter(fmt)
if fileLog:#输出到文件
#设置日志渠道--文件输出
handle = logging.FileHandler(logDir,encoding='utf-8')
#日志内容与渠道绑定
handle.setFormatter(formater)
#把日志对象与渠道绑定
logObject.addHandler(handle)
else: #输出到控制台
#设置日志渠道--控制台输出
handle2 = logging.StreamHandler()
#日志内容与渠道绑定
handle2.setFormatter(formater)
#把日志对象与渠道绑定
logObject.addHandler(handle2)
return logObject
log = logger()#文件输出日志
if __name__ == '__main__':
log = logger(fileLog=False)#控制台输出日志
log.info('我是日志信息')
handle_path.py 里边同时要加上 ,还要新建好文件 outFiles\logs
logs_path = os.path.join(project_path,'outFiles\logs')
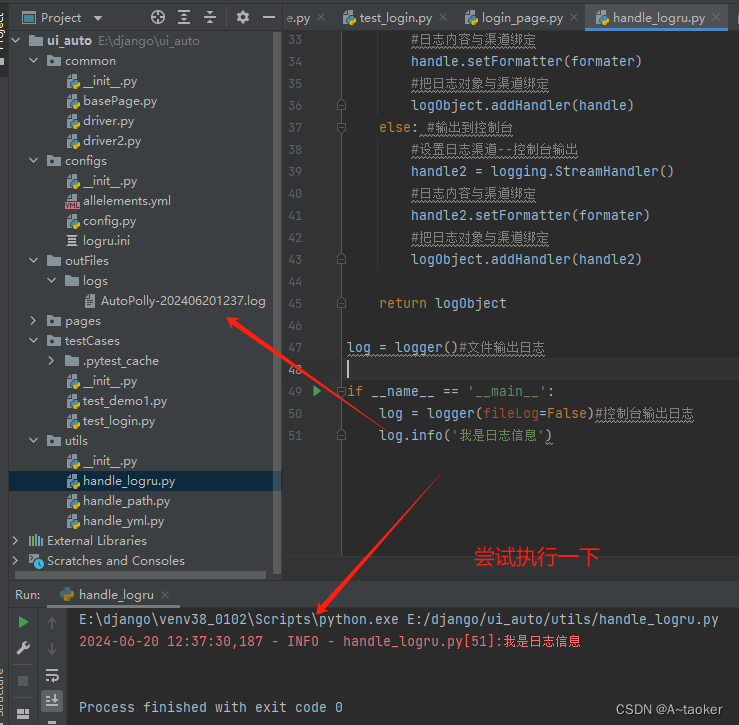
BasePage.py中就可以加一些日志,运行后会生成在一个文件。
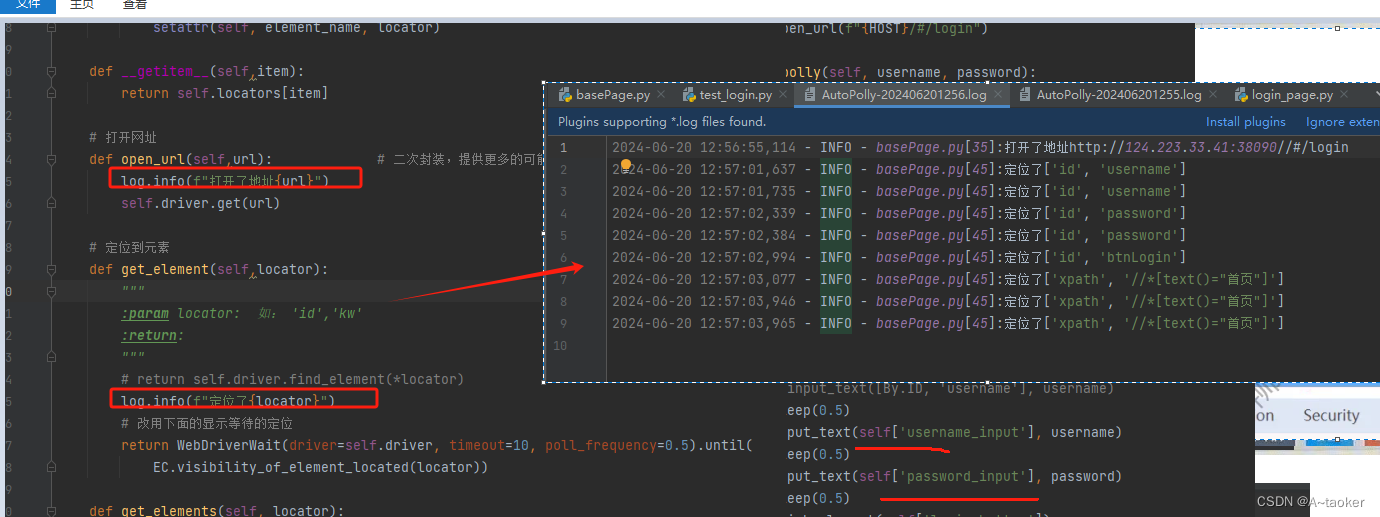
查找元素方法,也可以增加错误日志打印
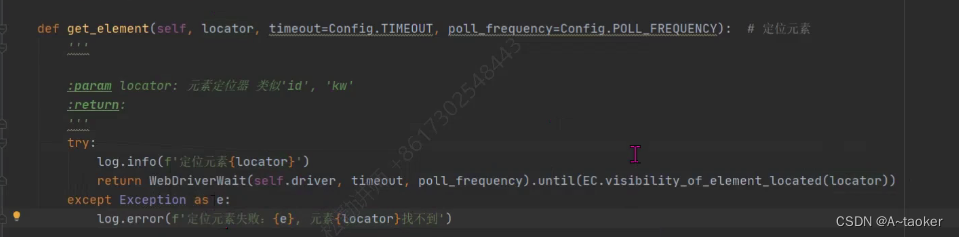
# 定位到元素
def get_element(self,locator):
"""
:param locator: 如: 'id','kw'
:return:
"""
try:
# return self.driver.find_element(*locator)
log.info(f"定位了{locator}")
# 改用下面的显示等待的定位
return WebDriverWait(driver=self.driver, timeout=10, poll_frequency=0.5).until(
EC.visibility_of_element_located(locator))
except Exception as e:
log.error(f"定位元素失败{e},元素{locator}找不到")
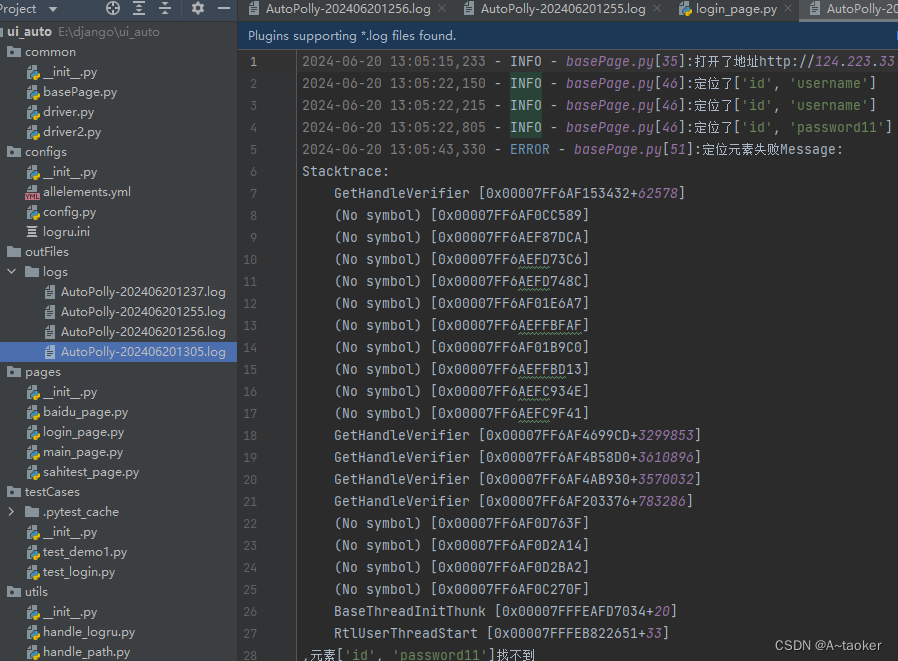
测试场景6,加alluer报告
参考 【自动化总结1】pytest使用整理_cento执行pytest,执行时用unitest-CSDN博客
版权归原作者 A~taoker 所有, 如有侵权,请联系我们删除。