
文章目录
传统 IO 问题
传统的 IO 将一个文件通过 socket 写出
File f =newFile("helloword/data.txt");RandomAccessFile file =newRandomAccessFile(file,"r");byte[] buf =newbyte[(int)f.length()];
file.read(buf);Socket socket =...;
socket.getOutputStream().write(buf);
读取磁盘数据的时候,之所以要发生上下文切换,这是因为用户空间没有权限操作磁盘或网卡,内核的权限最高,这些操作设备的过程都需要交由操作系统内核来完成,所以一般要通过内核去完成某些任务的时候,就需要使用操作系统提供的系统调用函数。
而一次系统调用必然会发生 2 次上下文切换:首先从用户态切换到内核态,当内核执行完任务后,再切换回用户态交由进程代码执行。
所以,要想减少上下文切换到次数,就要减少系统调用的次数。
内部工作流程是这样的:

共有四次数据拷贝:
- Java 本身并不具备 IO 读写能力,因此 read 方法调用后,要从 Java 程序的用户态切换至内核态,去调用操作系统的读能力,将数据读入内核缓冲区。这期间用户线程阻塞,操作系统使用 DMA(Direct Memory Access)来实现文件读,期间也不会使用 cpu。> DMA 也可以理解为硬件单元,用来解放 cpu 完成文件 IO。
- 从内核态切换回用户态,将数据从内核缓冲区读入用户缓冲区(此处的用户缓存也就是 byte[] buf),这期间 cpu 会参与拷贝,无法利用 DMA。
- 调用 write 方法,这时将数据从用户缓冲区(byte[] buf)写入 socket 缓冲区,cpu 会参与拷贝
- 接下来要向网卡写数据,这项能力 Java 又不具备,因此又得从用户态切换至内核态,调用操作系统的写能力,使用 DMA 将 socket 缓冲区的数据写入网卡,不会使用 cpu。
在前面我们知道了,传统的文件传输方式会历经 4 次数据拷贝,而且这里面,「从内核的读缓冲区拷贝到用户的缓冲区里,再从用户的缓冲区里拷贝到 socket 的缓冲区里」,这个过程是没有必要的。
因为文件传输的应用场景中,在用户空间我们并不会对数据「再加工」,所以数据实际上可以不用搬运到用户空间,因此用户的缓冲区是没有必要存在的。
中间环节较多,Java 的 IO 实际不是物理设备级别的读写,而是缓存的复制,底层的真正读写是操作系统来完成的。
- 用户态与内核态的切换发生了 3 次,这个操作比较重量级。
- 数据拷贝了共 4 次。
NIO 优化
1、通过 DirectByteBuf
- ByteBuffer.allocate(10) HeapByteBuffer 使用的还是 Java 内存
- ByteBuffer.allocateDirect(10) DirectByteBuffer 使用的是操作系统内存

减少了1次数据拷贝。
两个缓冲区用同一块内存。大部分步骤与优化前相同,不再赘述。
Java 可以使用 DirectByteBuf 将堆外内存映射到 Jvm 内存中来直接访问使用。
- 这块内存不受 Jvm 垃圾回收的影响,因此内存地址固定,有助于 IO 读写。
- Java 中的 DirectByteBuf 对象仅维护了此内存的虚引用,内存回收分成两步: - DirectByteBuf 对象被垃圾回收,将虚引用加入引用队列。- 通过专门线程访问引用队列,根据虚引用释放堆外内存。
- 减少了一次数据拷贝,用户态与内核态的切换次数没有减少。
2、进一步优化(linux 2.1)
(底层采用了 linux 2.1 后提供了一个专门发送文件的系统调用函数 sendfile()),Java 中对应着两个 channel 调用 transferTo/transferFrom 方法拷贝数据。
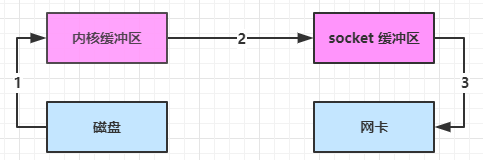
- Java 调用 transferTo 方法后,要从 Java 程序的用户态切换至内核态,使用 DMA将数据读入内核缓冲区,不会使用 cpu。
- 数据从内核缓冲区传输到 socket 缓冲区,cpu 会参与拷贝。
- 最后使用 DMA 将 socket 缓冲区 的数据写入网卡,不会使用 cpu,之后又从内核态切换到用户态来执行程序。
可以看到,减少了1次上下文切换和1次数据拷贝。
- 只发生了 2 次用户态与内核态的切换,因为此时无需用户缓存区,所以无需从内核态切换到用户态。
- 数据拷贝了 3 次
3、进一步优化(linux 2.4)
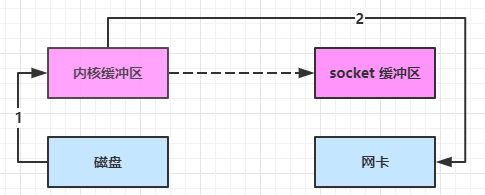
linux2.4后,对于支持网卡支持 SG-DMA 技术的情况下, sendfile() 系统调用的过程发生了点变化。
- Java 调用 transferTo 方法后,要从 Java 程序的用户态切换至内核态,使用 DMA将数据读入内核缓冲区,不会使用 cpu。
- 只会将一些 offset 和 length 信息拷入 socket 缓冲区,几乎无消耗,可忽略不计。所以此过程不需要将数据从操作系统内核缓冲区拷贝到 socket 缓冲区中,这样就减少了一次数据拷贝。
- 使用 DMA 将 内核缓冲区 的数据直接写入网卡,不会使用 cpu。
再次减少了1次拷贝。
整个过程发生了2次内核态和用户态的上下文切换,数据拷贝了 2 次。
零拷贝
零拷贝技术的文件传输方式相比传统文件传输的方式,减少了 1 次上下文切换和 2 次数据拷贝次数,只需要 2 次上下文切换和数据拷贝次数,就可以完成文件的传输,而且 2 次的数据拷贝过程,都不需要通过 CPU,2 次都是由 DMA 来搬运。
所谓的【零拷贝】,并不是真正无拷贝,而是再也不会拷贝重复数据到 Jvm 内存中,零拷贝的优点有
- 更少的用户态与内核态的切换。
- 不利用 cpu 计算,减少 cpu 缓存伪共享。
- 零拷贝适合小文件传输。
版权归原作者 Charte 所有, 如有侵权,请联系我们删除。