
原文链接:http://www.ibearzmblog.com/#/technology/info?id=8ac4902f82f525e1456624d5d7a545dc
前言
大数据的核心问题无非就是存储和计算这两个。Hadoop中的HDFS解决了数据存储的问题,而HBase就是在HDFS上构建,因此Hbase既能解决大数据存储的问题,又能解决数据实时查询的问题。
是什么
HBase是一个高可靠、高性能、可伸缩的分布式存储系统,是一个NoSQL数据块,它同样包含行和列,不过从底层来看,跟关系型数据库比,本质的数据存储结果有着本质的差别。
特点
Hbase是通过RowKey(即是行键)来检索数据的,主要用于存储非结构化、板结构化数据,像图片、视频、视频这些非结构化数据,XML这些半结构化数据都可以用HBase来存储。Hbase的特性跟HDFS也类似,主要依靠横向扩展来提高自身的存储和计算能力。
下面是一些HBase的重要特性:
- 容量大:单表可以支持百亿级的行、百万级的列。
- 无模式:同一个表的不同行可以有不同列。
- 面向列:支持列独立索引。
- 稀疏性:表设计可以非常稀疏,当值为空的时候并不会占用存储空间。
- 扩展性:底层依赖HDFS,HDFS怎么样它就怎么样。
- 高可靠性:提供了副本机制,防止数据丢失。
HBase的组成
HBase的模型由四个部分组成:表、行键、列簇、单元格。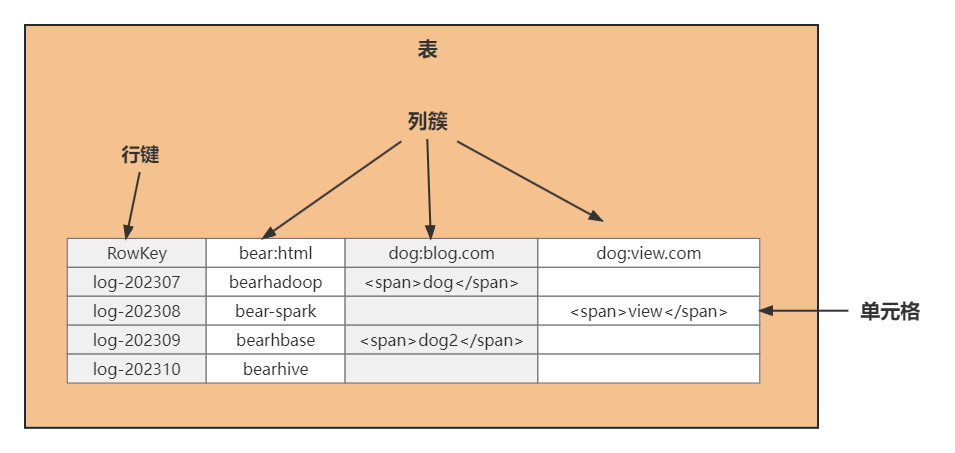
表
表是HBase作为分布式数据库的核心概念,跟传统的关系型数据库一样,HBase的表也是由行和列组成的,多个列可以组成列簇。
行键(RowKey)
可以等同于关系型数据库里的主键,HBase是按照RowKey进行排序的,所以需要设计良好的行键来提高查询性能。
列簇(ColumnFamily)
HBase的每个列都会归属于某个列簇,每个列簇里的所有成员都会有相同的前缀,例如上图bear:html、dog:blog.com和dog:view.com这三列,一共包含两个列簇,分别是bear和dog,列名由列簇前缀+修饰符组成。
列簇是表结构的一部分,在使用表前就需要提前定义好,而其中的列并不是必须的,可以在插入数据的时候生成。如果经常一起查询的多列建议都放在同一个列簇里,因为跨列簇查询也会影响查询效率。
单元格(Cell)
HBase中通过行键和列确定的一个存储单元成为单元格。每个单元格的内部都保存了同一份数据的多个版本,并且按时间戳倒叙排序,如下图:
时间戳(TimeStamp)可以在用户插入的时候赋值,或者让RegionServer自动赋值。
HBase的物理模型
在实际的物理存储上,HBase是按列分开存储的,而列则是按列簇进行分组,而一个列簇的数据都会被同一个Region进行管理(这里是指同一个列簇的数据由同一个Region管理,并不是指一个Region只负责一个列簇)。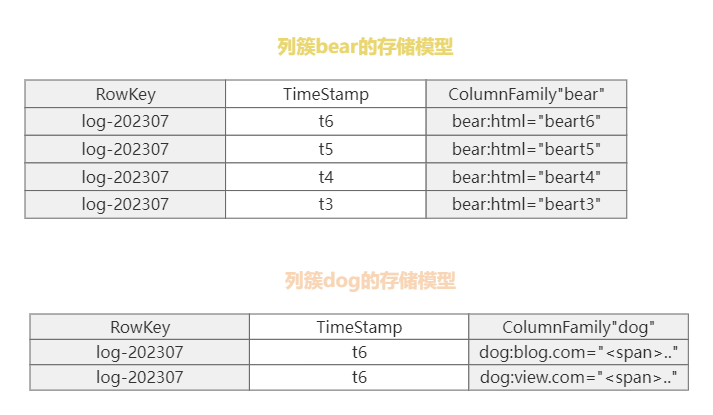
Region是Hbase数据管理的基本单位,数据的移动、分裂等等都是以Region来进行处理。HBase表的行会按照Rowkey进行排序,而在表里的行会被分割成多个Region,如下图所示: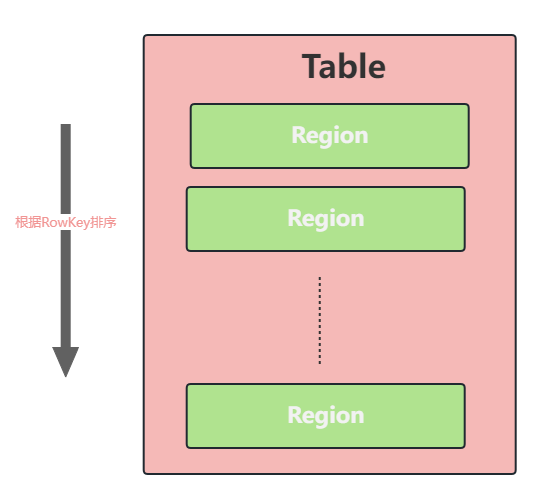
在初期数据不大的时候,默认只有一个Region,后面随着记录的疯狂式增长,Region就会分裂,不同的Region会被Master分发到不同的RegionServer上。
但是在HBase中,Region虽然是分布式存储的最小单元,但并不存储的最小单元。Region由一个或多个Store组成,每个Store保存一个Column Family,每个Store又由一个memStore和多个StoreFile组成,memStore存储在内存中,StoreFile则是在HDFS上,结构如下所示: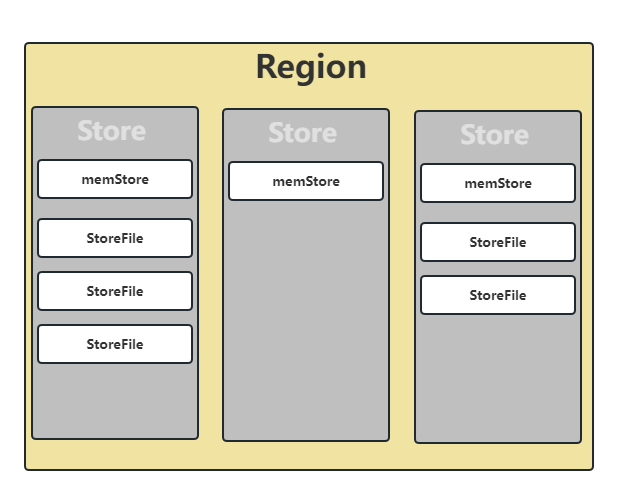
HBase的架构
HBase包含4个核心模块,分别是客户端(Client)、协调服务(Zookeeper)、主节点(HMaster)、从节点(HRegionServer)。
客户端(Client)
Client是HBase系统的入口,可以通过Client来操作HBase。Client都是通过RPC调用来与HMaster和RegionServer通信。
Zookeeper
负责管理HMaster的选举,保证集群中只有一个HMaster是Active状态,实时监控HRegionServer状态并通知给HMaster。存储HBase的Schema和Table的元数据。
HMater
在HBase中可以启动多个HMaster,但是在正常情况下只有一个HMaster是对外提供服务的,而其他的HMaster则负责备用(一主多从结构),这些由zookeeper来控制。HMaster的主要作用如下:
- 管理用户对表的CRUD操作。
- 调整HRegion的分布,管理HRegionServer的负载均衡。
- HRegion分裂后,负责将新的HRegion分配到其他的HRegionServer上。
- 当某个HRegionServer失效后,负责迁移HRegion到正常的HRegionServer上。
HRegionServer
主要负责响应客户端的I/O请求。HRegionServer内部维护了一系列的HRegion对象,一个HRegion对象等于一个Region,每个HRegion对应多个HStore,每个HStore对应一个列簇,每个列簇就是一个集中的存储单元。
总体架构如下: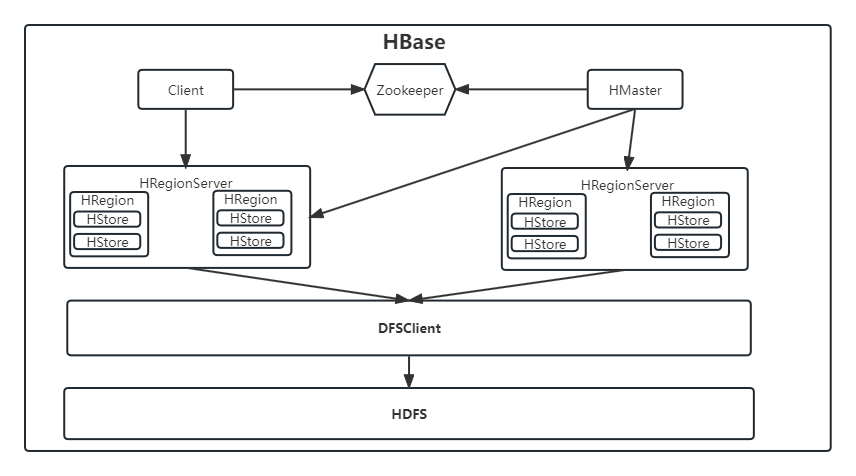
结尾
HBase的总体结构介绍到这里,后面会更新它的部署方式。
版权归原作者 熊小哥~ 所有, 如有侵权,请联系我们删除。