
HDFS上的数据均衡简介
文章目录
HDFS上的balance目前有两类:
- Balancer:多数据节点之间的balance
- Disk Balancer:单数据节点内磁盘之间的balance
NN增加新块时的默认策略(默认3副本)
- 将块的一份副本存储在接收写入请求的DN节点上;
- 在第一份副本所在DN的机架中寻找另一个DN,存放一份新副本。
- 在不同机架的DN上写入第三份副本。
重新平衡多DN之间的数据
入口Issue HADOOP1652
当一个新的数据节点加入hdfs集群时,它里面并没有数据。 因此分配给新机器的任何map任务很可能不会读取本地数据,从而增加了网络带宽的使用。 另一方面,当某些数据节点满了时,新的数据块只会被放置在非满的数据节点上,从而降低了它们的读取并行度。
这个特性的目的是种在集群出现不平衡时,在数据节点间重新分配数据块。
由于多种相互竞争的考虑因素,数据可能不会均匀地放置在 DNs 上。 HDFS 为管理员提供了一个工具,可以分析数据块的放置并重新平衡 DataNode 上的数据。Balancer 就是重新平台的工具,Banlancer有两种使用模式:
- 手动工具,均衡退出条件: - 集群是平衡的- 迭代次数超过阈值(默认5)- 没有块可以迁移- 集群正在升级- 发生错误
- 运行服务模式 (3.3.0版本开始支持 HDFS-13783) - 默认按一定时间间隔进行数据均衡。- 可以设置
dfs.balancer.service.interval来控制每轮均衡之间的间隔。- 当遇到意外异常时,会尝试多次才停止服务,这是由dfs.balancer.service.retries.on.exception设置的。
数据均衡的交互图
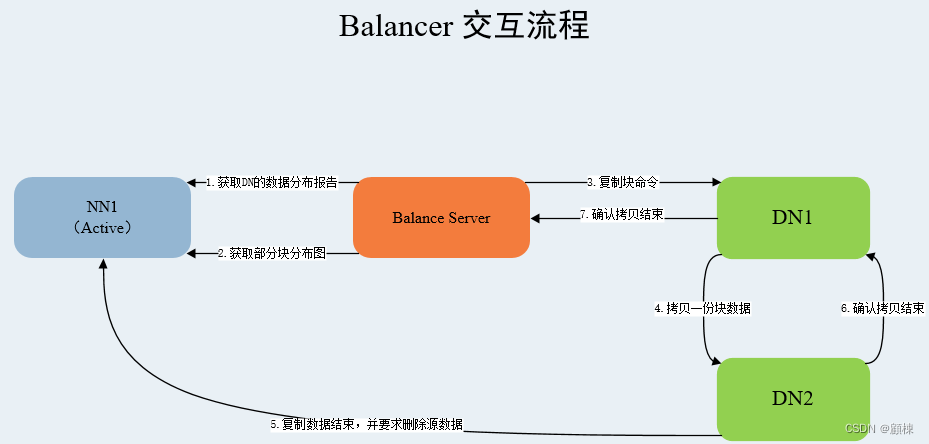
方案应满足以下要求:
- 保证数据可用性保证,即在重新平衡时,不会减少块具有的副本数量或块驻留的机架数量。
- 提供执行和中断重新平衡的管理员级别的命令。
- 应限制重新平衡,以便重新平衡不会导致名称节点太忙而无法服务任何传入请求或使网络饱和。
相关命令
hdfs balancer
[-policy <policy>][-threshold <threshold>][-exclude [-f <hosts-file>|<comma-separated list of hosts>]][-include [-f <hosts-file>|<comma-separated list of hosts>]][-source [-f <hosts-file>|<comma-separated list of hosts>]][-blockpools <comma-separated list of blockpool ids>][-idleiterations <idleiterations>][-runDuringUpgrade]
COMMAND_OPTIONDescription
-policy
datanode
(默认): 如果每个数据节点都是平衡的,集群就是平衡的。
blockpool
: 如果每个数据节点的每个块池都是平衡的,那么集群就是平衡的。
-threshold
磁盘容量的百分比。这覆盖了默认的阈值。
-exclude -f
| 将指定的数据节点排除在平衡器的平衡范围之外。
-include -f
| 只包括要被平衡器平衡的指定数据节点。
-source -f
| 只挑选指定的数据节点作为源节点。
-blockpools
平衡器将只在这个列表中包括的区块池上运行。
-idleiterations
退出前的最大空闲迭代次数。这覆盖了默认的idleiterations(5)。
-runDuringUpgrade
是否在正在进行的HDFS升级中运行平衡器。这通常是不需要的,因为它不会影响过度使用的机器上的使用空间。
注意:
blockpool
策略优先级高于数据节点策略。
除了上述命令选项,从2.7.0开始,引入了钉住功能,以防止某些副本被balancer/mover移动。这个钉住功能默认是禁用的,可以通过配置属性
dfs.datanode.block-pinning.enabled
来启用。当启用时,这个功能只影响写到 create() 调用中指定的特定节点的块。当我们想保持数据的局部性时,这个功能很有用,比如HBase Regionserver的应用。
重新平衡单DN内磁盘间的数据
入口Issue HDFS-1312
数据节点存储数据到其存储目录不均匀,导致某些磁盘间的使用差值比较大。 目前的解决方式是:
- 手动重新平衡存储目录中的块
- 停用节点并稍后读取它们
在利用所有可用的主轴和以相同的速率填充磁盘之间存在权衡。 可能的解决方案包括:
- 在数据节点上放置新块时,对较少使用的磁盘进行更重的权重。 在写入繁重的环境中,这仍将利用所有主轴,随着时间的推移均衡磁盘使用。
- 在本地重新平衡块。 当在旧集群节点中添加/替换磁盘时,这将有助于均衡磁盘使用。
数据节点应主动管理其本地磁盘,因此不需要人工干预。
磁盘平衡器是一个命令行工具,它在数据节点的所有磁盘上均匀地分配数据。这个工具与Balancer不同,Balancer负责整个集群的数据平衡。会出现数据可能在一个节点的磁盘之间有不均匀的分布的场景。这可能是由于大量的写入和删除或由于磁盘更换而发生的。这个工具对一个给定的数据节点进行操作,将块从一个磁盘移动到另一个磁盘。
磁盘平衡器通过创建计划来运行,并继续在数据节点上执行该计划。 计划是一组语句,描述应在两个磁盘之间移动多少数据。 计划由多个移动步骤组成。 移动步骤具有源磁盘、目标磁盘和要移动的字节数。 可以针对操作数据节点执行计划。 磁盘平衡器不应干扰其他进程,因为它会限制每秒复制的数据量。
要配置磁盘平衡器,可以在
hdfs-site.xml
中将
dfs.disk.balancer.enabled
设置为
true
或者
false
。
相关命令
Plan
可以通过运行以下命令对给定的数据节点运行plan命令
hdfs diskbalancer -plan node1.mycluster.com
COMMAND_OPTIONDescription
-out
允许用户控制计划文件的输出位置。
-bandwidth
由于 DN 正在运行并且可能正在运行其他作业,因此磁盘平衡器限制每秒移动的数据量。 该参数允许用户设置要使用的最大带宽。 不需要设置,因为如果未指定,diskBalancer 将使用默认带宽。单位呢?
-thresholdPercentage
由于我们针对数据节点的快照进行操作,因此移动操作有一个容差百分比来声明成功。 如果用户指定 10% 并且移动操作的大小为 20GB,如果我们可以移动 18GB,则该操作被认为是成功的。 这是为了实时适应DN的变化。 不需要此参数,如果未指定,则使用默认值。
-maxerror
最大错误允许用户指定在我们中止移动步骤之前必须失败多少块复制操作。 再次强调,这不是必需的参数,如果未指定,则使用系统默认值。
-v
详细模式,指定此参数会强制计划命令在标准输出上打印出计划的摘要。
-fs
指定要使用的NN。 如果未指定,则使用配置中的默认值。
plan 命令写入两个输出文件。 它们是
<nodename>.before.json
(在磁盘平衡器运行之前捕获集群的状态)和
<nodename>.plan.json
。
Execute
执行命令采用计划命令,针对生成计划的数据节点执行它。
hdfs diskbalancer -execute /system/diskbalancer/nodename.plan.json
这通过从计划文件中读取数据节点的地址来执行计划。 当 DiskBalancer 执行计划时,这是一个可能需要很长时间的异步过程的开始。 因此,查询命令可以帮助获取执行命令的当前状态。
COMMAND_OPTIONDescription
-skipDateCheck
跳过日期检查并强制执行计划。
Query
查询命令从数据节点获取磁盘平衡器的当前状态。
hdfs diskbalancer -query nodename.mycluster.com
COMMAND_OPTIONDescription
-v
Verbose mode, Prints out status of individual moves
Cancel
取消命令取消正在运行的计划。 重新启动数据节点与取消命令具有相同的效果,因为数据节点上的计划信息是暂时的。
hdfs diskbalancer -cancel /system/diskbalancer/nodename.plan.json
or
hdfs diskbalancer -cancel planID -node nodename
可以使用查询命令从数据节点读取planID。
Report
报告命令提供将从运行磁盘平衡器中受益的指定节点或顶级节点的详细报告。 节点可以由主机文件或逗号分隔的节点列表指定。
hdfs diskbalancer -fs http://namenode.uri -report -node <file://>|[<DataNodeID|IP|Hostname>,...]
or
hdfs diskbalancer -fs http://namenode.uri -report -top topnum
相关配置
磁盘平衡器的配置在
hdfs-site.xml
文件中
SettingDescription
dfs.disk.balancer.enabled
此参数控制是否为集群启用磁盘平衡器。 如果不启用,任何执行命令都会被datanode拒绝。默认值为true。
dfs.disk.balancer.max.disk.throughputInMBperSec
这控制复制数据时磁盘平衡器消耗的最大磁盘带宽。 如果指定 10MB 之类的值,则磁盘平衡器平均只会复制 10MB/S。 默认值为 10MB/S。
dfs.disk.balancer.max.disk.errors
设置在两个磁盘之间的特定移动被放弃之前我们可以忽略的最大错误数的值。 例如,如果一个计划有 3 对磁盘要在 之间进行复制,并且第一个磁盘组遇到超过 5 个错误,那么我们放弃第一个副本并开始计划中的第二个副本。 最大错误的默认值设置为 5。
dfs.disk.balancer.block.tolerance.percent
容差百分比指定我们何时达到任何复制步骤的足够好的值。 例如,如果您指定 10%,那么接近目标值的 10% 就足够了。
dfs.disk.balancer.plan.threshold.percent
计划中磁盘数据密度的百分比阈值。 如果节点中磁盘数据密度的绝对值超出阈值,则表示磁盘对应的磁盘应该在计划中进行平衡。 默认值为 10。
dfs.disk.balancer.plan.valid.interval
磁盘平衡器计划有效的最长时间。 支持以下后缀(不区分大小写):ms(毫秒)、s(秒)、m(分钟)、h(小时)、d(天)来指定时间(如2s、2m、1h等)。 如果未指定后缀,则假定为毫秒。 默认值为 1d
dfs.disk.balancer.plan.valid.interval
从版本3.1.0开始支持。
调试
磁盘平衡器生成两个输出文件。
nodename.before.json
包含我们从名称节点读取的集群状态。 该文件包含有关数据节点和磁盘的详细信息。
nodename.plan.json
包含特定节点的计划。 该计划文件包含一系列步骤。 步骤作为数据节点内的一系列移动操作来执行。
要区分节点之前和之后的状态,您可以重新运行 plan 命令并将新的
nodename.before.json
与旧的
before.json
进行比较,或者针对该节点运行 report 命令。
要查看运行计划的进度,请运行带有选项 -v 的查询命令。 这将打印出一组步骤 - 每个步骤代表从一个磁盘到另一个磁盘的移动操作。
移动速度受到指定带宽的限制。 带宽的默认值设置为 10MB/秒。 如果您使用 -v 选项进行查询,您将看到以下值。
"sourcePath":"/data/disk2/hdfs/dn","destPath":"/data/disk3/hdfs/dn","workItem":"startTime":1466575335493,"secondsElapsed":16486,"bytesToCopy":181242049353,"bytesCopied":172655116288,"errorCount":0,"errMsg":null,"blocksCopied":1287,"maxDiskErrors":5,"tolerancePercent":10,"bandwidth":10
source path- 迁移数据的源路径.
dest path- 迁移数据的目标路径.
start time- 是以毫秒为单位的的开始时间
seconds elapsed- 每当更新统计数据时都会更新。 这可能比现实时间慢。
bytes to copy- 应该复制的字节数。 我们复制正负一定的百分比。 通常,您会看到 bytesCopied – 作为小于要复制的字节的值。 在默认情况下,移动字节数在 10% 以内就足够了.
bytes copied- 从源磁盘移动到目标磁盘的实际字节数.
error count- 每次遇到错误时,我们都会增加错误计数。 只要错误计数保持小于最大错误计数(默认值为 5),我们就会尝试完成此移动。 如果我们达到最大错误计数,我们将放弃当前步骤并执行计划中的下一步。
error message- 当前报告最后一条错误消息的单个字符串。 较旧的消息应该位于数据节点日志中。
blocks copied- 复制的块数
max disk errors- 用于此移动步骤的配置。 目前,它将报告默认配置值,因为用于控制每个步骤的这些值的用户界面尚未到位。尚未实现
tolerance percent- 这表示我们在移动数据时可以偏离多少。 在繁忙的集群中,这允许管理员说,计算一个计划,但我知道这个节点正在被使用,所以如果磁盘平衡器可以达到要复制的字节的 +/- 10% 就可以了。
bandwidth- 这是磁盘平衡器使用的最大聚合源磁盘带宽。 移动块后,磁盘平衡器计算以指定带宽移动该块应花费多少秒。 如果实际移动花费的时间少于预期,则磁盘平衡器将在该持续时间内休眠。 请注意,当前所有移动都是由单个线程顺序执行的。
版权归原作者 顧棟 所有, 如有侵权,请联系我们删除。