
系统架构
Flink 运行时的架构 —— 以 Standalone会话模式为例
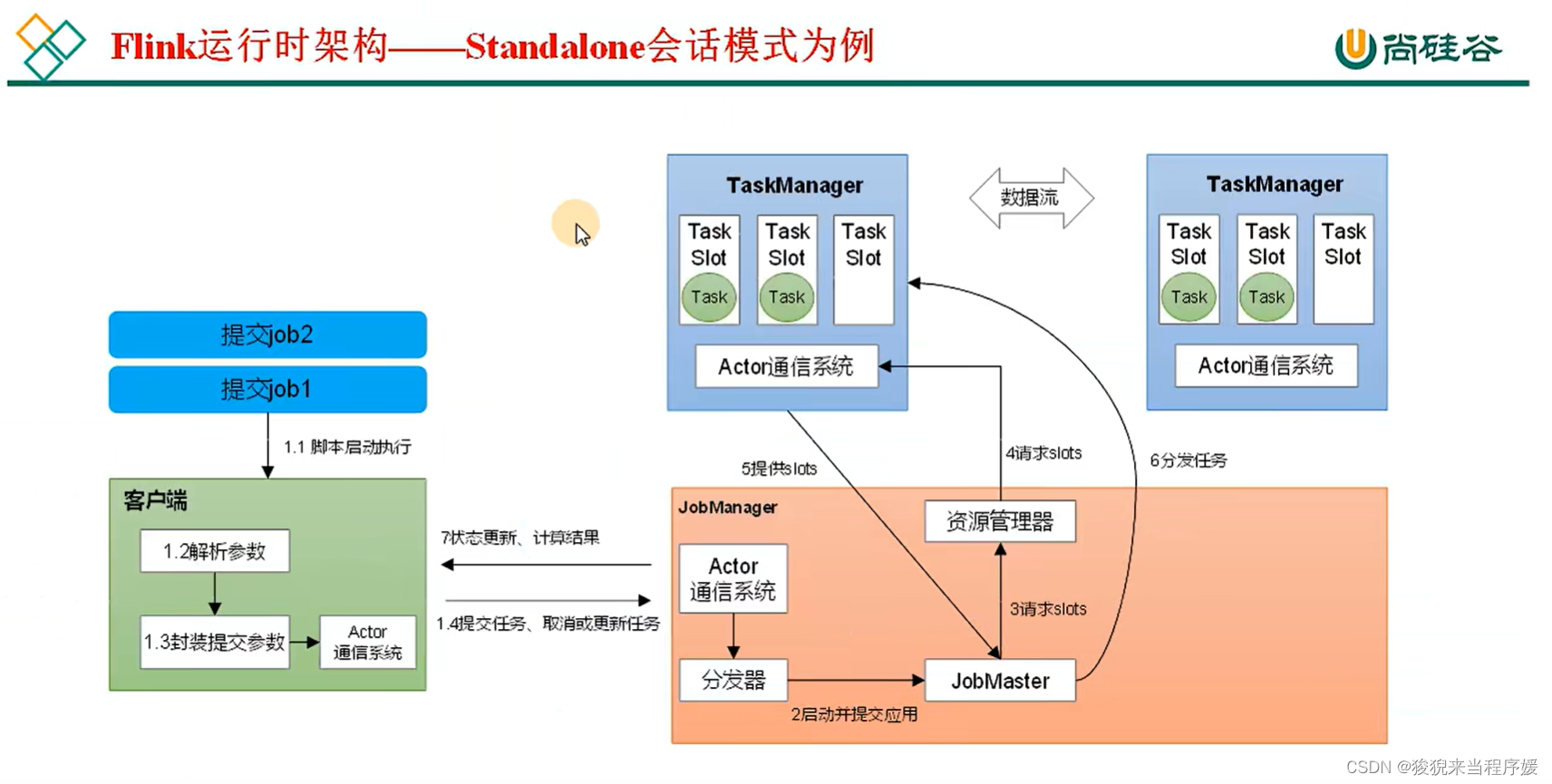
- 当 job 到来时,客户端解析参数,通过 Actor 通信系统进行任务提交,将 job 提交给 JobManager;
- Jobmanager 中有三个主要的模块,1) 分发器。通过分发器启动并提交应用。2) JobMaster,一个 job 提交给一个 JobMaster。3) 资源管理器。JobMaster向资源管理器(本质是Actor 通信系统提供)申请 Slot (槽);
- 申请到 Slot 后,JobMaster 将作业分发给多个干活的人(TaskManager)去干。
核心概念
并行度
一个算子被 “复制” 多份至多个节点,数据来了之后可以挑空闲的执行该算子。
这样,一个算子任务被拆成了多个并行的“子任务”,再分发到不同节点,即可实现并行计算。
Flink 执行过程中,每个算子可以包含一个或者多个子任务,这些子任务在不同线程、不同物理机或不同容器中完全独立运行。
一个算子,子任务的个数被称为并行度。
一个流程序的并行度,可以认为是所有算子中最大的并行度。
在 IDEA 运行,不指定并行度,默认是电脑线程数。
并行度优先级排序如下:
配置文件指定 < 提交时指定优先级 < 全局指定优先级 < 算子单独指定优先级
算子链
一个数据流在算子之间传输数据的形式可以有两种,一种是一对一的直通模式,另一种是打乱的重分区模式,这取决于算子的种类。
一对一模式
这种模式下,数据流维护着分区及元素的顺序。数据流在两个算子之间传输不需要重新分区,也不需要调整数据的顺序。这种模式类似于Spark中的窄依赖。
典型算子有: map、fliter、flatMap
重分区模式
这种模式下,数据流的分区会发生改变。
每个算子的子任务,会根据数据传输的策略,将数据发送到不同的下游目标。
这一过程类似于 Spark 的 shuffle。
合并算子链
Flink 中,并行度相同的 ont to one 算子操作,可以直接连接起来形成一个大的 task 任务,这样,每个 task 会被一个线程执行,这种技术叫算子链。
可以通过一个全局方法禁用算子链合并
【定位算子问题时,通常会禁用算子链】
env.disableOperatorChaining();
可以某个算子不参与链化的写法
算子A.disableChaining();
从某个算子开启新的链条(从A开始正常链化)
算子A.startNewChain()
任务槽(Task Slots)
就是 Task Manager 上,为了控制并发量,对每个任务所占用的资源做出明确划分的。
实际上,每个任务槽就表示了 Task Manager 拥有计算资源的一个固定大小的子集,用来独立执行一个一个的子任务。
slot 目前仅仅用来隔离内存,不会涉及CPU的隔离
一般将 slot 个数配置为CPU核心数,用来尽量避免对 CPU 的竞争。
同一个任务中,不同算子的子任务,可以共享同一个slot。
slot 表示最大的并发上限。
并行度表示实际运行占用了几个。
slot数量 >= job 并行度(算子最大并行度),job 才能运行。
提交流程
Standalone会话模式提交流程
图源:尚硅谷 Flink 教程
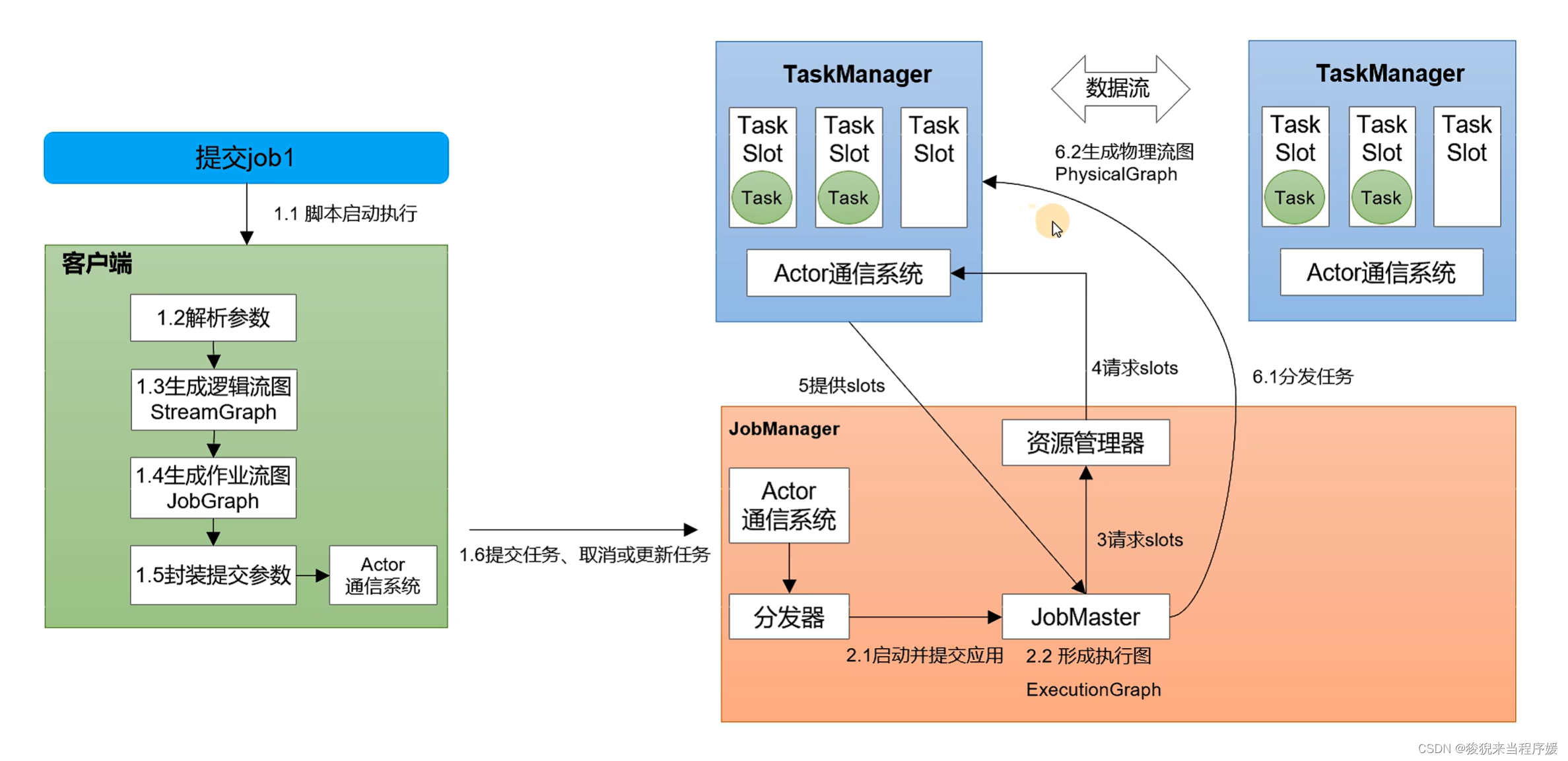
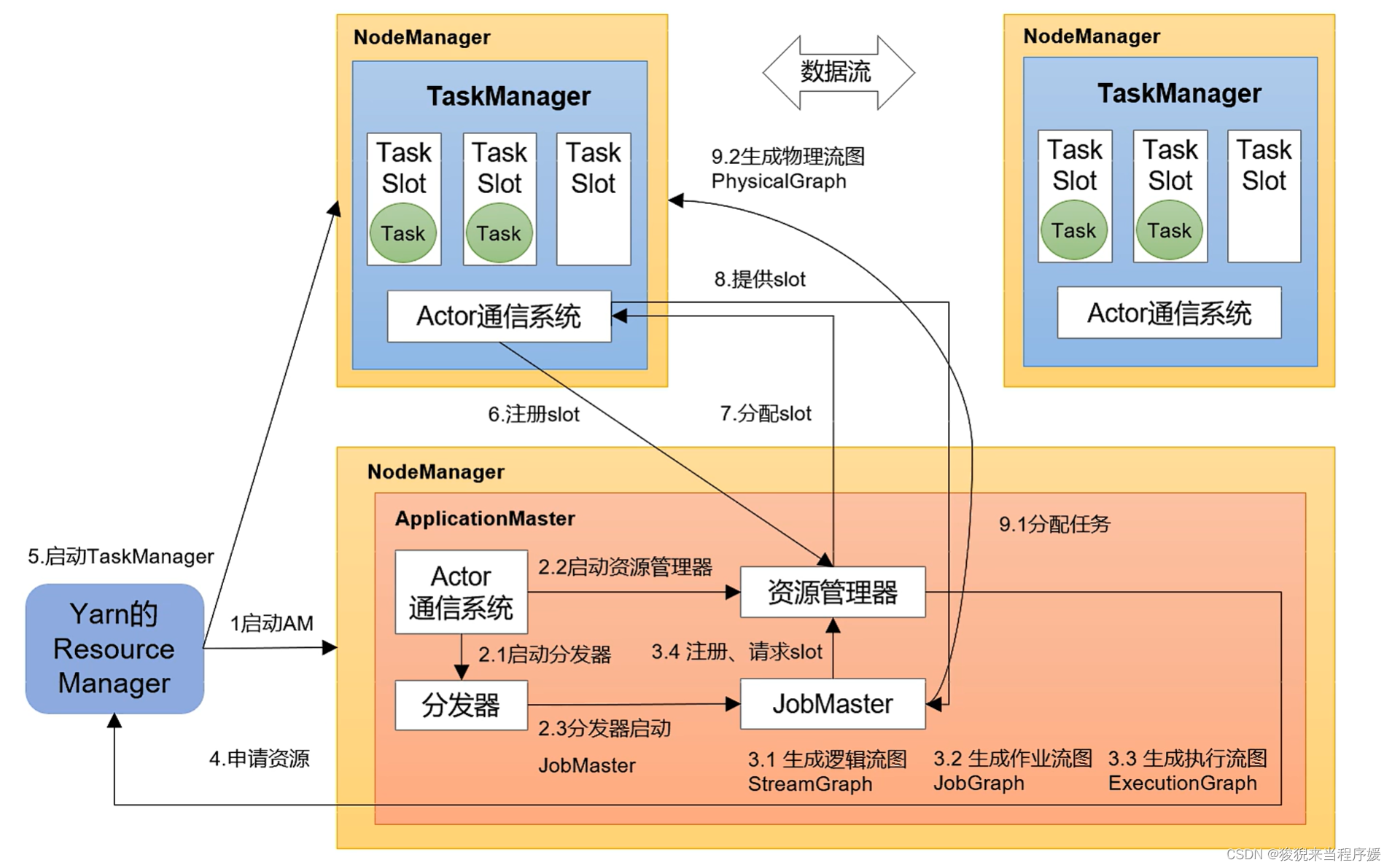
Yarn 应用模式作业提交流程
版权归原作者 狻猊来当程序媛 所有, 如有侵权,请联系我们删除。