
1.框架搭建
优化前的框架: 优化后的框架:
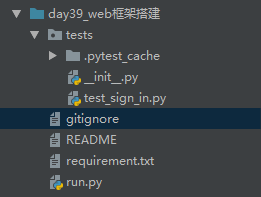

UI自动化框架跟接口自动化框架相似,我们拿到一个项目之后,首先把需要的框架先搭建好,然后再一点一点去进行优化,不要急着一步到位,先把基本的流程跑通
gitignore文件:存放不上传到git上的内容
README文件:这个是框架的简单说明,供同事,领导等查看,以及自己时间长了记不清楚查看
requirements.txt文件:需要安装的第三方库
run.py文件:收集并运行用例
tests文件:存放所有的测试用例
data文件:存放所有的测试数据,如登录的账号密码
drivers文件:存放不同版本的驱动
output文件:存放allure生成的测试报告文件
pages文件:存放所有的页面元素操作封装的内容
report文件:pytest生成的测试报告(测试报告二选一即可)
setting文件:存放配置文件
2.UI自动化测试的地位
UI自动化测试在整个测试过程中占据的地位:
这个比例主要还是看公司,手工测试/自动化测试,60%/40%(比较厉害的公司)大多数公司自动化占据的比例还是相对要少的,自动化占20%左右
自动化测试又分:接口自动化/UI自动化/性能/安全
70-80%/20-30%
优先实现正向用例,回归
3.UI自动化测试的特征
- 界面修改频繁(前端喜欢加)
- 界面需求变动也大
- 运行速度很慢(浏览器打开速度慢,页面加载速度慢,占用CPU很多)
- 界面稳定性不够
- 界面排版是不方便做自动化
4.UI自动化测试流程
- 需求分析
- 用例设计:提供什么参数以及数据,测试步骤
- 用例评审(这步就不详细介绍了,主要看公司如何做)
- 编写代码
- 测试报告
4.1需求分析
拿到一个项目后,首先是分析这个产品是做什么的,都有什么样的功能,例如课堂派web端,先整理出都分什么角色,分别对应什么功能,进行自动化测试前,肯定是手工测试已经进行了测试,并且功能稳定没有bug
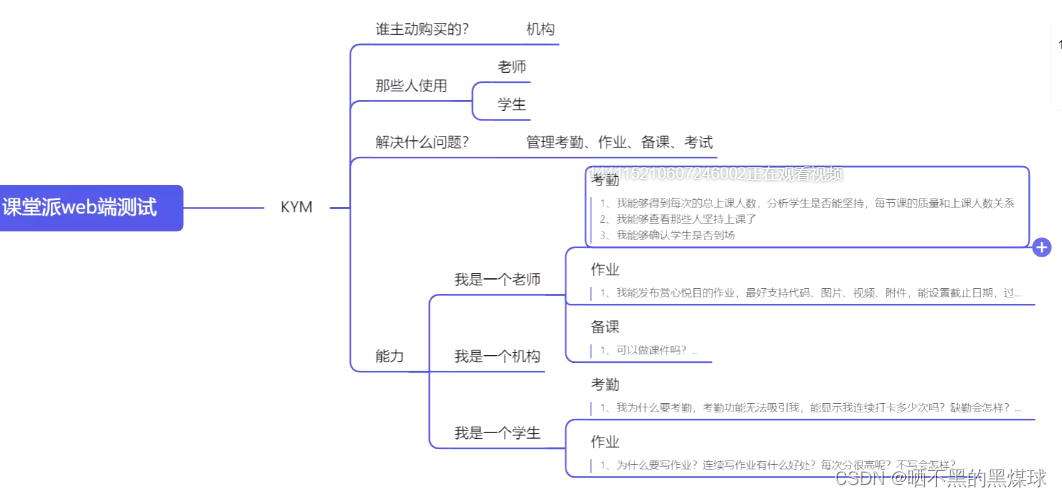
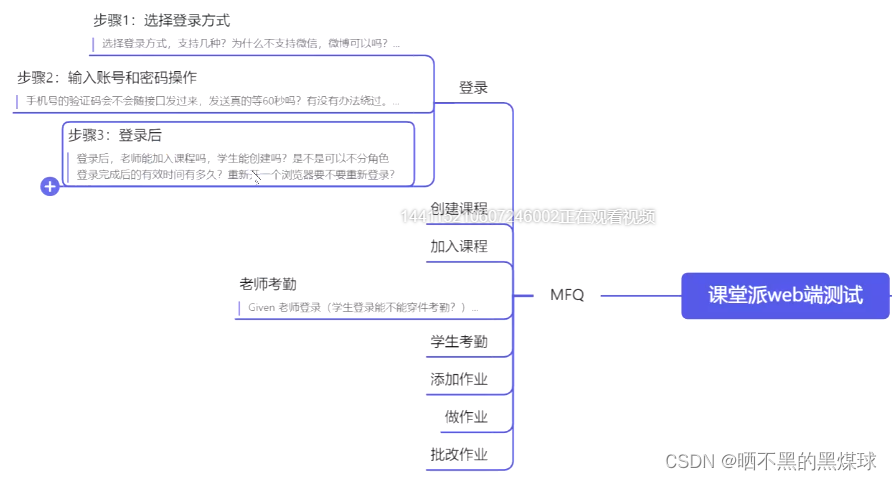
4.2用例设计
编写UI自动化测试用例的流程:
- 手工测试用例编写
- 自动化测试用例代码编写
测试用例其实就是一个脚本script(这里指的不是代码中的脚本),作用是为了记录自己的一个思路,方便下次再去根据这个脚本去测试,方便管理,以免漏测等

我这里为了介绍就不一一去编写了,实际工作中需要把所有的用例测试点都转化成测试用例 ,有了测试用例之后,我们就可以把用例转化成自动化测试代码了
4.3编写代码
根据编写的测试用例,进行代码编写,如登录功能
步骤:
- 输入登录url:https://v4.ketangpai.com/Home/User/login.html
- 输入用户名:aaa name="account"
- 输入密码:123 name="pass"
- 点击登录按钮:class="btn-btn" (虽然找到两个相同元素,但fide_element只取第一个,正好我们需要的是第一个)
- 进行断言
具体代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
class TestSignIn:
def test_sing_in_01(self):
username = 'aaa'
password = '123'
expected = '密码有效长度是6到30个字符'
with webdriver.Chrome(executable_path=r'E:\lemon\lianxi\day39_web框架搭建\chromedriver_96.exe') as browser:
browser.implicitly_wait(5)
browser.maximize_window()
# 访问url
url = 'https://v4.ketangpai.com/Home/User/login.html'
browser.get(url)
# 输入用户名
el_user = browser.find_element(By.NAME, 'account')
el_user.clear()
el_user.send_keys(username)
# 输入密码
el_pwd = browser.find_element(By.NAME, 'pass')
el_pwd.clear()
el_pwd.send_keys(password)
# 点击登录按钮
browser.find_element(By.CSS_SELECTOR, '.btn-btn').click()
# 获取登录后报错的文本
actual = browser.find_element(By.CSS_SELECTOR, '.error-tips').text
# 通过属性名称获取属性值
# actual = browser.find_element('xpath', '//p[@class="error-tips"]').get_attribute('name')
assert expected == actual
注意:
executable_path=r'E:\lemon\lianxi\day39_web框架搭建\chromedriver_96.exe'这个是可以不用填写的前提是:把该驱动放到了环境变量中了,前面有介绍,可以参考此篇文章:selenium-webdriver环境搭建_晒不黑的黑煤球的博客-CSDN博客
之所以编写此名代码,是在实际项目中,可能会测试多个不同版本的驱动与浏览器时方便管理
这是拿到一个项目后,先保证编写的代码可以顺利的执行没有报错,再去进行优化,我这里是演示就不一一编写所有用例代码了,编写过程是一样的,就是输入的数据与断言有所有更改
接下来,我们就对代码进行各种封装及优化
4.3.1优化代码
优化方向:
- 更好用
- 更易懂
- 维护代码方便
- 更通用
- 扩展性
优化点:
- 隔离测试数据,当需要添加或修改数据时,可以在单独的模块中进行修改
- 浏览器管理可以重复使用,所以可以进行单独封装
- 需要把驱动进行隔离管理:1.可以存储多个浏览器驱动,2.想用哪个用哪个
- base url域名ip
- 登录操作可以重复使用(项目通用)
- 登录操作:已经登录过了,不需要重新再登录,记住用户登录状态
- PO模式
优化第一点:
测试数据我们可以从配置文件,或者execl表格获取,也可以直接新建一个模块来保存数据,我这里新建了一个login_data.py来存储
login_fail = {'username': 'aaa', 'password': '123', 'expected': '密码有效长度是6到30个字符'}
自动化测试用例修改如下:

优化第二点:
因为我们执行测试用例之前是先打开浏览器操作,用例执行后再进行浏览器关闭,因此把浏览器的封装放到夹具中最合适,之前我们介绍过共享fixture,就是把所有的夹具放到固定的conftest.py文件中,这样不需要导入,pytest会自动调用
注意:conftest.py文件不能放到其他包下,放在根目录或tests包下即可,否则会报错
import pytest
from selenium import webdriver
# 打开浏览器
def get_browser():
# 因为要在测试用例后执行闭关浏览器,因为不要使用with的打开方式
browser = webdriver.Chrome(executable_path=r'E:\lemon\lianxi\day39_web框架搭建\chromedriver_96.exe')
browser.implicitly_wait(5)
browser.maximize_window()
return browser
# 设置夹具
@pytest.fixture()
def browser():
driver = get_browser()
yield driver
driver.quit()
自动化测试用例修改如下:

把相关打开浏览器,设置隐性等待,窗口最大化的代码删除掉,只传入夹具browser即可
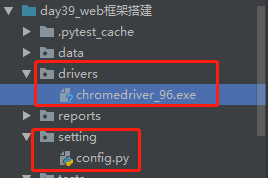
优化第三点:
把所有的驱动放到一个目录中,这样方便管理与操作,我新建了drivers目录存放驱动,新建了setting包,config.py配置文件(为了动态获取驱动的目录)
config.py代码如下:
import os
# 获取config.py当前文件的路径
curren_path = os.path.abspath(__file__)
# 配置文件目录的路径
config_dir = os.path.dirname(curren_path)
# setting包的路径
cf_dir = os.path.dirname(config_dir)
# host地址
host = 'https://v4.ketangpai.com/'
# 驱动的路径
driver_dir = os.path.join(cf_dir, 'drivers')
修改conftest.py代码如下:
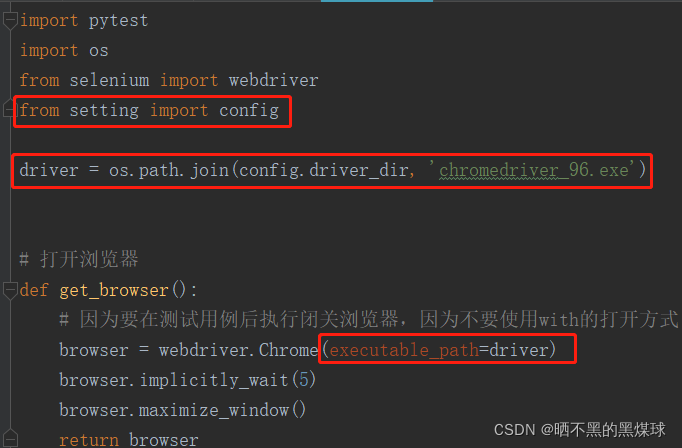
4.3.2PO模式
PO/POM模式(Page Object 或Page Object Model)是UI测试模式,字面意思就是页面对象模型,从本质上来说就是把页面的元素操作封装成类当中的方法,在测试过程中不再需要关注页面的结构,只需要关心执行的操作,这样测试用例中的代码看起来简单明了易懂
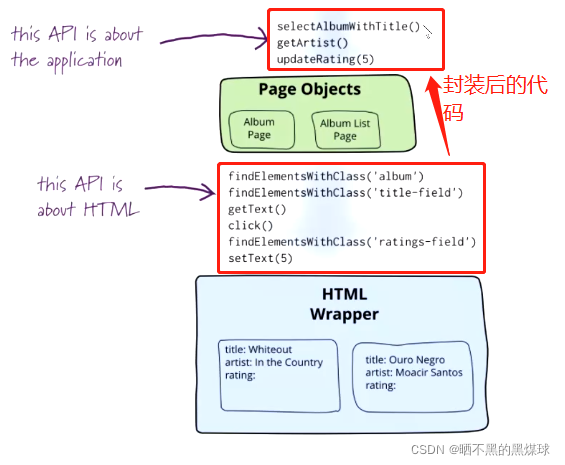
具体操作就是上面优化第七点的过程,好处就是:
- 测试用例中的代码变更加精简
- 代码可读性变强
- 页面操作封装完成,进行隔离管理(也就是分层设计理念):前端发生变化,只需要维护PO封装后的代码,如果测试数据修改了,只需要修改测试数据即可
- PO封装的页面操作是可以重复使用的
PO的封装有以下原则,如果遵守的话会达到更好的效果:
最后两条可以不参考
- 页面封装里不应该包含断言或者测试,否则就不能做到页面操作和测试操作分离
- 唯一可以放在页面当中的测试是判断一个元素是否能找到
- 不需要封装所有的页面操作,用到什么封装什么
- 页面封装也可以使用组件方式:如导航栏,object,footer object等在多个页面重复出现的,使用组件可以增强代码复用性
- 封装方法返回self,其他po,或者基础数据结构,string,dates,不应该element对象等
- 如果同一个操作引发不同的结果,可以封装多个方法,如:login_failed,login_success
优化第七点:
就是使用PO模式进行封装代码,把页面操作的相关代码都封装到单独的类方法中,具体操作如下
新建page目录下login_page.py文件,代码如下:
from selenium.webdriver.common.by import By
class LoginPage:
def __init__(self, browser):
self.browser = browser
def login(self, username, password):
"""登录"""
# 输入用户名
el_user = self.browser.find_element(By.NAME, 'account')
el_user.clear()
el_user.send_keys(username)
# 输入密码
el_pwd = self.browser.find_element(By.NAME, 'pass')
el_pwd.clear()
el_pwd.send_keys(password)
# 点击登录按钮
self.browser.find_element(By.CSS_SELECTOR, '.btn-btn').click()
def get_error_tips(self):
"""获取错误信息"""
return self.browser.find_element(By.CSS_SELECTOR, '.error-tips').text
** 自动化测试用例修改如下:**
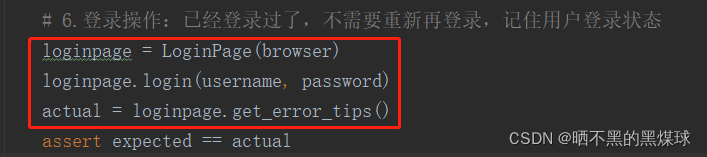
此步还可以进一步优化,设置一个夹具,依赖browser夹具,然后测试用例就不需要初始化loginpage了,直接调用login_page夹具即可
修改conftest.py代码如下:
import pytest
import os
from selenium import webdriver
from setting import config
from pages.login_page import LoginPage
driver = os.path.join(config.driver_dir, 'chromedriver_96.exe')
# 打开浏览器
def get_browser():
# 因为要在测试用例后执行闭关浏览器,因为不要使用with的打开方式
browser = webdriver.Chrome(executable_path=driver)
browser.implicitly_wait(5)
browser.maximize_window()
return browser
# 设置夹具
@pytest.fixture()
def browser():
driver = get_browser()
yield driver
driver.quit()
# 依赖上一个夹具(上一个夹具是这个夹具的前置条件)
@pytest.fixture()
def login_page(browser):
return LoginPage(browser)
夹具的套娃:(一个夹具可以依赖另一个夹具)
夹具 --> 用例的依赖关系
夹具 --> 夹具的依赖关系
**自动化测试用例修改如下: **
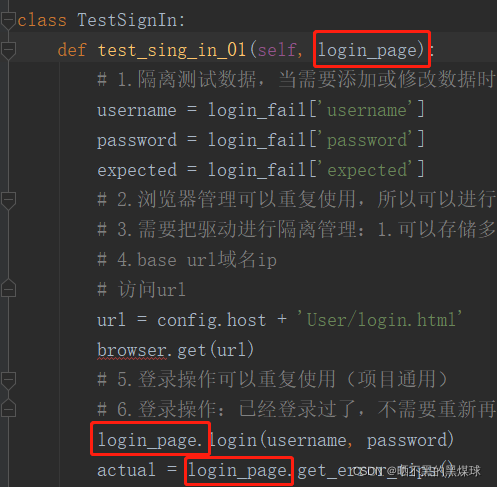
这个封装的过程就是PO模式,所有的页面操作代码都不会编写在测试用例代码中,而是放在一个类中独立管理
优化第四点:
url也放到login_page.py文件中,增加一个加载登录页面的方法,代码如下
from selenium.webdriver.common.by import By
from setting import config
class LoginPage:
url = config.host + 'User/login.html'
def __init__(self, browser):
self.browser = browser
def load(self):
"""加载页面"""
self.browser.get(self.url)
def login(self, username, password):
"""登录"""
# 输入用户名
el_user = self.browser.find_element(By.NAME, 'account')
el_user.clear()
el_user.send_keys(username)
# 输入密码
el_pwd = self.browser.find_element(By.NAME, 'pass')
el_pwd.clear()
el_pwd.send_keys(password)
# 点击登录按钮
self.browser.find_element(By.CSS_SELECTOR, '.btn-btn').click()
def get_error_tips(self):
"""获取错误信息"""
return self.browser.find_element(By.CSS_SELECTOR, '.error-tips').text
自动化测试用例修改如下:
from data.login_data import login_fail
class TestSignIn:
def test_sing_in_01(self, login_page):
# 数据
username = login_fail['username']
password = login_fail['password']
expected = login_fail['expected']
# 获取实际结果
login_page.load()
login_page.login(username, password)
actual = login_page.get_error_tips()
# 断言
assert expected == actual
调用过程图如下:

剩下还没优化的点,在之后的文章中会详细介绍,此篇就介绍到这里
4.4测试报告
获取当前系统时间戳来生成测试报告名+时间戳来存储测试报告,具体代码如下:
import pytest
import datetime
# 获取当前时间戳
ts = datetime.datetime.now().strftime('%Y-%m-%d-%H-%M-%S')
# 路径拼接
filename = f'reports/report-{ts}.html'
# 收集并执行用例(注意加上[])
pytest.main([f'--html={filename}'])
版权归原作者 晒不黑的黑煤球 所有, 如有侵权,请联系我们删除。