
前言
在日常生活中,我们看到可爱的猫咪表情包,总是会忍不住收藏

认识的一些朋友也养了猫,比如橘猫、英短、加菲猫之类的

看他们发朋友圈撸猫,老羡慕了,猫咪真的太可爱啦。

你是不是也动过养猫猫的小心思呢~反正我是动过了
于是,网上闲逛的时候发现一个专门交易猫猫的网站—猫猫交易网
这不得采集20W+ 条猫猫数据,以此来了解一下可爱的猫咪。

数据获取
打开猫猫交易网,先采集猫咪品种数据,首页点击猫咪品种
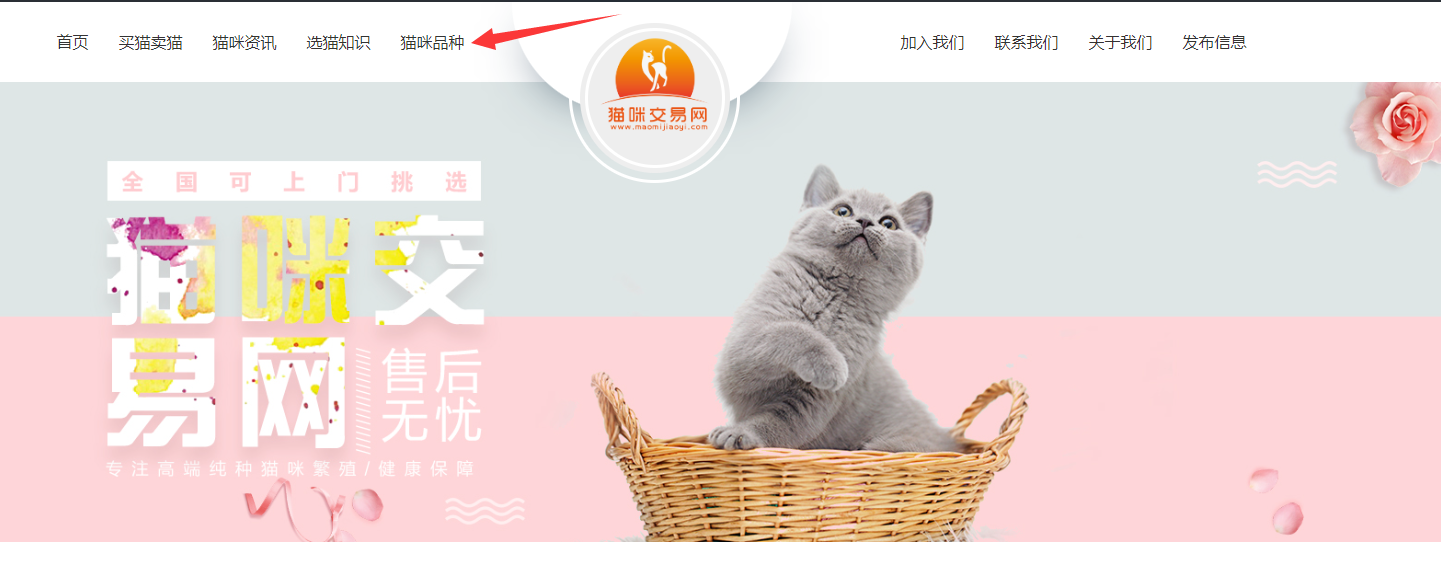
这里打开页面可以看到猫猫品种列表:
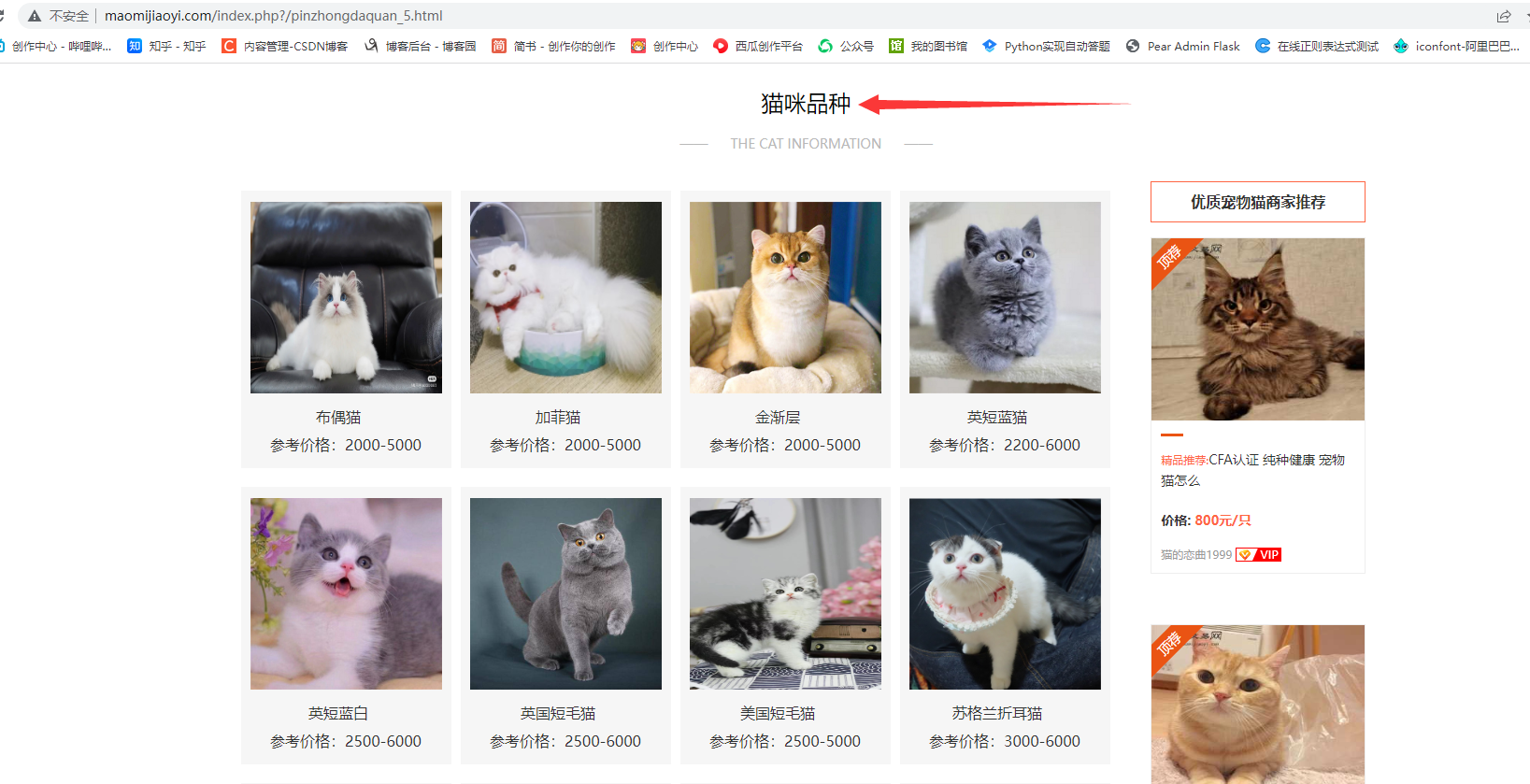
但只显示了每种猫猫的品种名,参考价格,我们点进详情页,可以看到更加详细的数据:
品种名、参考价格、中文学名、基本信息、性格特点、生活习性、优缺点、喂养方法等。
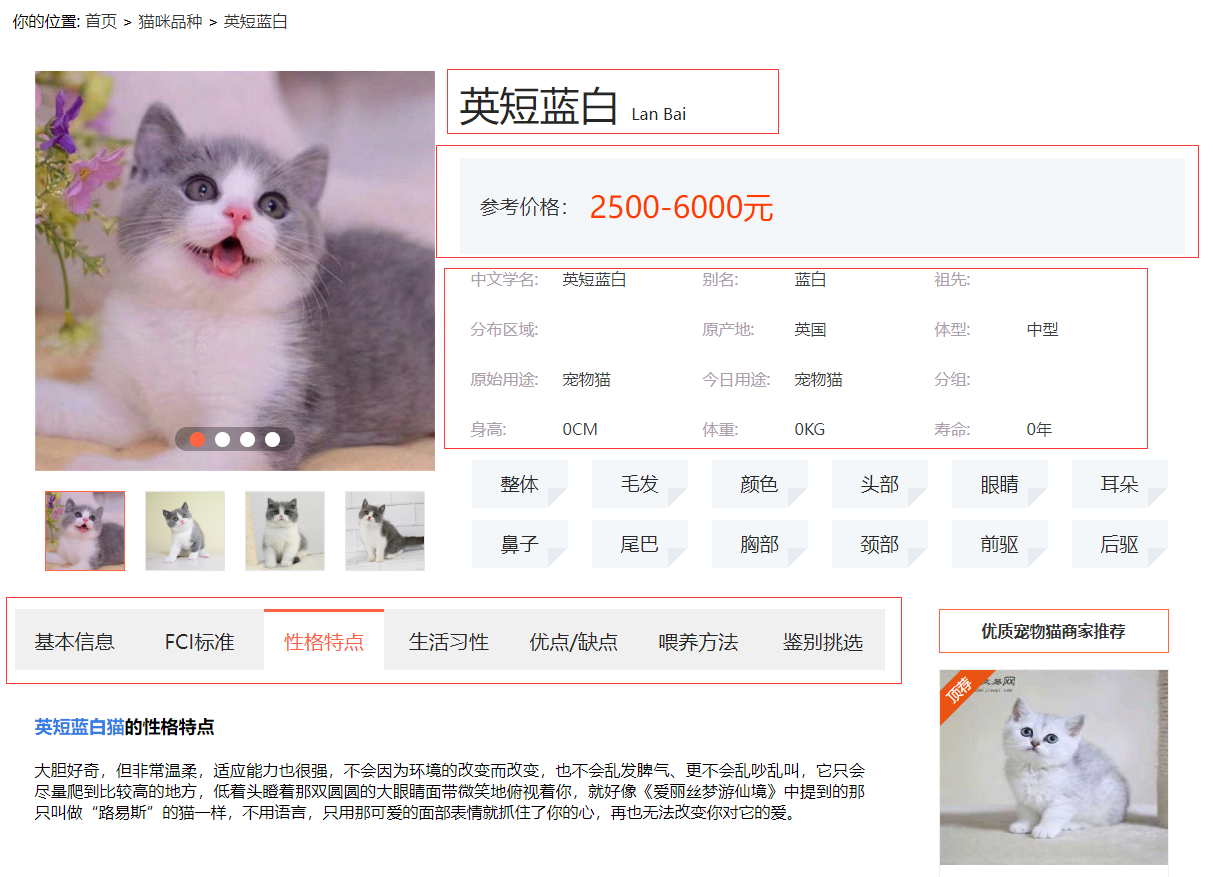
检查网页,可以发现网页结构简单,容易解析和提取数据。
代码如下:
import requests
import re
import csv
from lxml import etree
from tqdm import tqdm
from fake_useragent import UserAgent
随机产生请求头
ua = UserAgent(verify_ssl=False, path='fake_useragent.json')defrandom_ua():# 用于随机切换请求头
headers ={"Accept-Encoding":"gzip","Accept-Language":"zh-CN","Connection":"keep-alive","Host":"www.maomijiaoyi.com","User-Agent": ua.random
}return headers
创建保存数据的csv
defcreate_csv():withopen('./data/cat_kind.csv','w', newline='', encoding='utf-8')as f:
wr = csv.writer(f)
wr.writerow(['品种','参考价格','中文学名','别名','祖先','分布区域','原产地','体型','原始用途','今日用途','分组','身高','体重','寿命','整体','毛发','颜色','头部','眼睛','耳朵','鼻子','尾巴','胸部','颈部','前驱','后驱','基本信息','FCI标准','性格特点','生活习性','优点/缺点','喂养方法','鉴别挑选'])
获取HTML网页源代码 返回文本
defscrape_page(url1):
response = requests.get(url1, headers=random_ua())# print(response.status_code)
response.encoding ='utf-8'return response.text
获取每个品种猫咪详情页url
defget_cat_urls(html1):
dom = etree.HTML(html1)
lis = dom.xpath('//div[@class="pinzhong_left"]/a')
cat_urls =[]for li in lis:
cat_url = li.xpath('./@href')[0]
cat_url ='http://*****'+ cat_url
cat_urls.append(cat_url)return cat_urls
采集每个品种猫咪详情页里的有关信息
defget_info(html2):# 品种
kind = re.findall('div class="line1">.*?<div class="name">(.*?)<span>', html2, re.S)[0]
kind = kind.replace('\r','').replace('\n','').replace('\t','')# 参考价格
price = re.findall('<div>参考价格:</div>.*?<div>(.*?)</div>', html2, re.S)[0]
price = price.replace('\r','').replace('\n','').replace('\t','')# 中文学名
chinese_name = re.findall('<div>中文学名:</div>.*?<div>(.*?)</div>', html2, re.S)[0]
chinese_name = chinese_name.replace('\r','').replace('\n','').replace('\t','')# 别名
other_name = re.findall('<div>别名:</div>.*?<div>(.*?)</div>', html2, re.S)[0]
other_name = other_name.replace('\r','').replace('\n','').replace('\t','')# 祖先
ancestor = re.findall('<div>祖先:</div>.*?<div>(.*?)</div>', html2, re.S)[0]
ancestor = ancestor.replace('\r','').replace('\n','').replace('\t','')# 分布区域
area = re.findall('<div>分布区域:</div>.*?<div>(.*?)</div>', html2, re.S)[0]
area = area.replace('\r','').replace('\n','').replace('\t','')# 原产地
source_area = re.findall('<div>原产地:</div>.*?<div>(.*?)</div>', html2, re.S)[0]
source_area = source_area.replace('\r','').replace('\n','').replace('\t','')# 体型
body_size = re.findall('<div>体型:</div>.*?<div>(.*?)</div>', html2, re.S)[0]
body_size = body_size.replace('\r','').replace('\n','').replace('\t','').strip()# 原始用途
source_use = re.findall('<div>原始用途:</div>.*?<div>(.*?)</div>', html2, re.S)[0]
source_use = source_use.replace('\r','').replace('\n','').replace('\t','')# 今日用途
today_use = re.findall('<div>今日用途:</div>.*?<div>(.*?)</div>', html2, re.S)[0]
today_use = today_use.replace('\r','').replace('\n','').replace('\t','')# 分组
group = re.findall('<div>分组:</div>.*?<div>(.*?)</div>', html2, re.S)[0]
group = group.replace('\r','').replace('\n','').replace('\t','')# 身高
height = re.findall('<div>身高:</div>.*?<div>(.*?)</div>', html2, re.S)[0]
height = height.replace('\r','').replace('\n','').replace('\t','')# 体重
weight = re.findall('<div>体重:</div>.*?<div>(.*?)</div>', html2, re.S)[0]
weight = weight.replace('\r','').replace('\n','').replace('\t','')# 寿命
lifetime = re.findall('<div>寿命:</div>.*?<div>(.*?)</div>', html2, re.S)[0]
lifetime = lifetime.replace('\r','').replace('\n','').replace('\t','')# 整体
entirety = re.findall('<div>整体</div>.*?<!-- 页面小折角 -->.*?<div></div>.*?<div>(.*?)</div>', html2, re.S)[0]
entirety = entirety.replace('\r','').replace('\n','').replace('\t','').strip()# 毛发
hair = re.findall('<div>毛发</div>.*?<div></div>.*?<div>(.*?)</div>', html2, re.S)[0]
hair = hair.replace('\r','').replace('\n','').replace('\t','').strip()# 颜色
color = re.findall('<div>颜色</div>.*?<div></div>.*?<div>(.*?)</div>', html2, re.S)[0]
color = color.replace('\r','').replace('\n','').replace('\t','').strip()# 头部
head = re.findall('<div>头部</div>.*?<div></div>.*?<div>(.*?)</div>', html2, re.S)[0]
head = head.replace('\r','').replace('\n','').replace('\t','').strip()# 眼睛
eye = re.findall('<div>眼睛</div>.*?<div></div>.*?<div>(.*?)</div>', html2, re.S)[0]
eye = eye.replace('\r','').replace('\n','').replace('\t','').strip()# 耳朵
ear = re.findall('<div>耳朵</div>.*?<div></div>.*?<div>(.*?)</div>', html2, re.S)[0]
ear = ear.replace('\r','').replace('\n','').replace('\t','').strip()# 鼻子
nose = re.findall('<div>鼻子</div>.*?<div></div>.*?<div>(.*?)</div>', html2, re.S)[0]
nose = nose.replace('\r','').replace('\n','').replace('\t','').strip()# 尾巴
tail = re.findall('<div>尾巴</div>.*?<div></div>.*?<div>(.*?)</div>', html2, re.S)[0]
tail = tail.replace('\r','').replace('\n','').replace('\t','').strip()# 胸部
chest = re.findall('<div>胸部</div>.*?<div></div>.*?<div>(.*?)</div>', html2, re.S)[0]
chest = chest.replace('\r','').replace('\n','').replace('\t','').strip()# 颈部
neck = re.findall('<div>颈部</div>.*?<div></div>.*?<div>(.*?)</div>', html2, re.S)[0]
neck = neck.replace('\r','').replace('\n','').replace('\t','').strip()# 前驱
font_foot = re.findall('<div>前驱</div>.*?<div></div>.*?<div>(.*?)</div>', html2, re.S)[0]
font_foot = font_foot.replace('\r','').replace('\n','').replace('\t','').strip()# 后驱
rear_foot = re.findall('<div>前驱</div>.*?<div></div>.*?<div>(.*?)</div>', html2, re.S)[0]
rear_foot = rear_foot.replace('\r','').replace('\n','').replace('\t','').strip()
保存前面猫猫的各种有关信息
cat =[kind, price, chinese_name, other_name, ancestor, area, source_area,
body_size, source_use, today_use, group, height, weight, lifetime,
entirety, hair, color, head, eye, ear, nose, tail, chest, neck, font_foot, rear_foot]
提取标签栏信息(基本信息-FCI标准-性格特点-生活习性-优缺点-喂养方法-鉴别挑选)
html2 = etree.HTML(html2)
labs = html2.xpath('//div[@class="property_list"]/div')for lab in labs:
text1 = lab.xpath('string(.)')
text1 = text1.replace('\n','').replace('\t','').replace('\r','').replace(' ','')
cat.append(text1)return cat
保存数据 追加写入
defwrite_to_csv(data):withopen('./data/cat_kind.csv','a+', newline='', encoding='utf-8')as fn:
wr = csv.writer(fn)
wr.writerow(data)
创建保存数据的csv
if __name__ =='__main__':
create_csv()# 猫咪品种页面url
base_url ='http://*****/index.php?/pinzhongdaquan_5.html'# 获取品种页面中的所有url
html = scrape_page(base_url)
urls = get_cat_urls(html)# 进度条可视化运行情况 就不打印东西来看了
pbar = tqdm(urls)
开始采集
for url in pbar:
text = scrape_page(url)
info = get_info(text)
write_to_csv(info)
成功采集了猫咪品种数据保存到csv,接下来采集猫猫交易数据

进入到买猫卖猫页面:

爬取更详细的数据需要进入详情页,包含商家信息、猫咪品种、猫龄、价格、标题、在售只数、预防等信息。
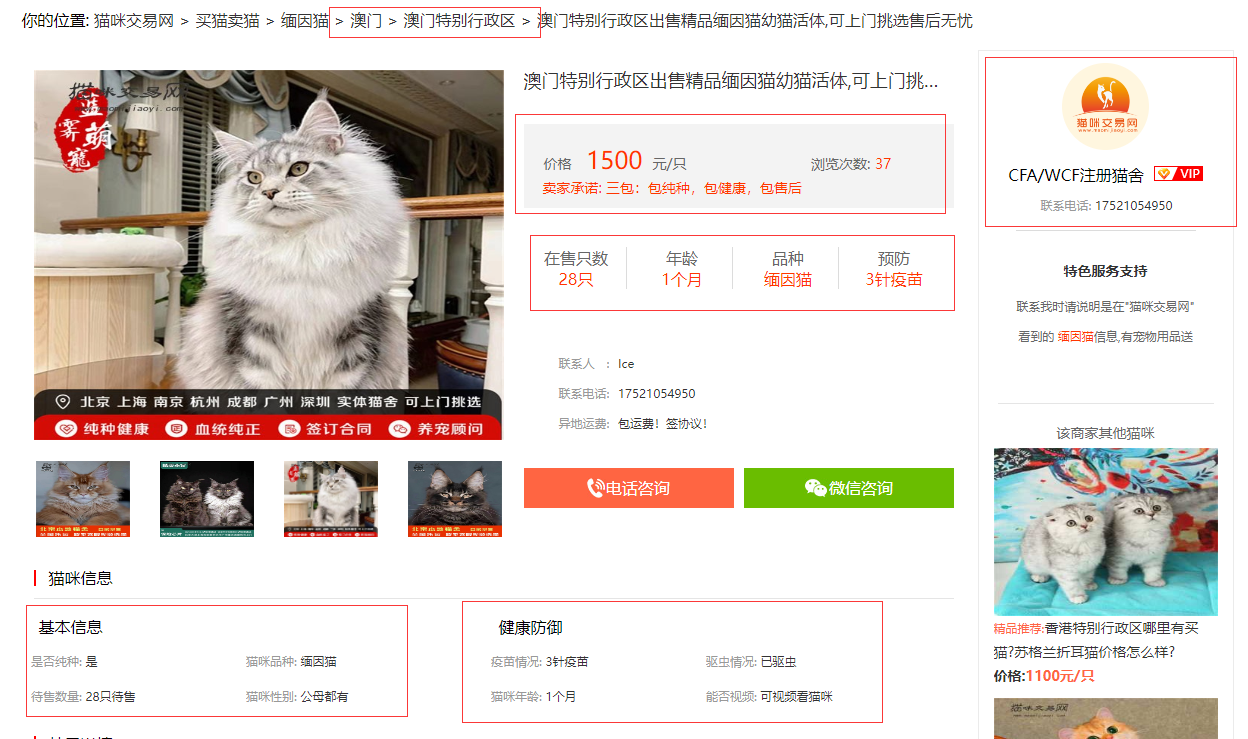
由于数据量较大,可以分开爬取,先获取到每一页中的所有猫猫详情交易链接的 url 保存到csv,再
读取 csv 中的 url 来请求,爬取每条交易数据,爬虫思路跟前面类似,为了加快爬取效率,可以使用多线程或者异步爬虫。
最终获取了 20W+ 条数据。
尾语 💝
要成功,先发疯,下定决心往前冲!
学习是需要长期坚持的,一步一个脚印地走向未来!
未来的你一定会感谢今天学习的你。
—— 心灵鸡汤
本文章到这里就结束啦~感兴趣的小伙伴可以复制代码去试试哦 😝

👇问题解答 · 源码获取 · 技术交流 · 抱团学习请联系👇
版权归原作者 魔王不会哭 所有, 如有侵权,请联系我们删除。