
X2Doris实现Hive离线数据自动化一键迁移至Doris
提示:以下是本篇文章正文内容,下面案例可供参考
一、X2Doris是什么?
X2Doris 是 SelectDB (Doris主要开发维护团队)开发的,专门用于将各种离线数据迁移到 Apache Doris 中的核心工具,该工具集 自动建 Doris 表 和 数据迁移 为一体,目前支持了 Apache Doris/Hive/Kudu、StarRocks 数据库往 Doris 或 SelectDB Cloud 迁移的工作,整个过程可视化的平台操作,非常简单易用,减轻数据同步到 Doris 中的门槛。
二、安装部署
1.安装环境要求
- 部署节点必须可以连接hadoop集群,是hadoop的⼀个节点,或⾄少有 hadoop gateway 环境
- 部署节点必须配置了 hadoop 环境变量, 如 HADOOP_HOME , HADOOP_CONF_DIR
eg:
exportHADOOP_HOME=/opt/cloudera/parcels/CDH/lib/hadoop #hadoop 安装⽬录exportHADOOP_CONF_DIR=/etc/hadoop/conf
exportHIVE_HOME=$HADOOP_HOME/../hive
exportHBASE_HOME=$HADOOP_HOME/../hbase
exportHADOOP_HDFS_HOME=$HADOOP_HOME/../hadoop-hdfs
exportHADOOP_MAPRED_HOME=$HADOOP_HOME/../hadoop-mapreduce
exportHADOOP_YARN_HOME=$HADOOP_HOME/../hadoop-yarn
# 注:在 HADOOP_CONF_DIR 下 必须要有 hive-site.xml
- 部署节点可以连接⽬标 doris
- 部署节点可以连接mysql (存放平台元信息)
2.安装步骤
1.下载安装包
wget https://selectdb-doris-1308700295.cos.ap-beijing.myqcloud.com/x2doris/selectdb-x2doris-1.0.3_2.12-bin.tar.gz
2. 解压安装包
tar-zxvf selectdb-x2doris-1.0.3_2.12-bin.tar.gz -C /opt/module
mv /opt/module/selectdb-x2doris-1.0.3_2.12-bin /opt/module/x2doris
cd /opt/module/x2doris
3.初始化元数据
- 将系统的数据库类型改成 mysql (默认的h2, 会导致系统重启后,数据会丢失) :
vim conf/application.yml
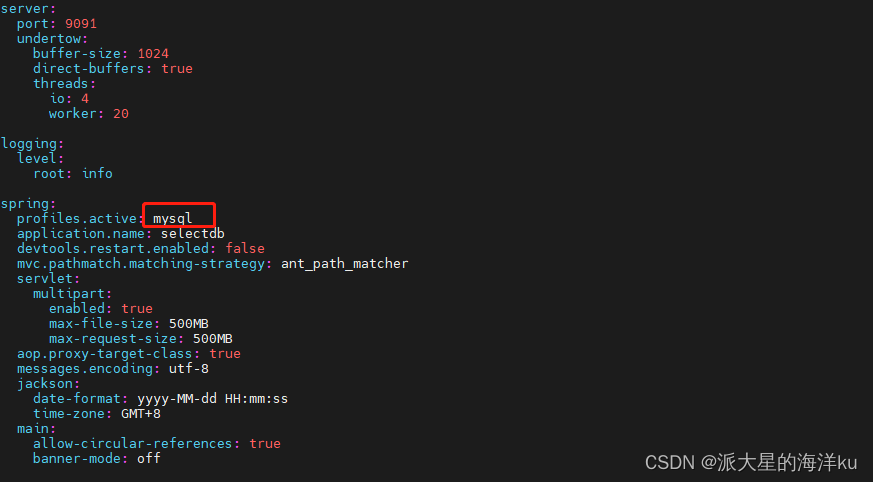
- 修改 conf/application-mysql.yml ⽂件,指定mysql的连接信息
vim conf/application-mysql.yml

3. 进⼊到 script 下:有两个⽬录,分别是 schema 和 data
- 先执⾏ schema 下的 mysql-schema.sql 完成表结果的初始化
- 再执⾏ data 下的 mysql-data.sql
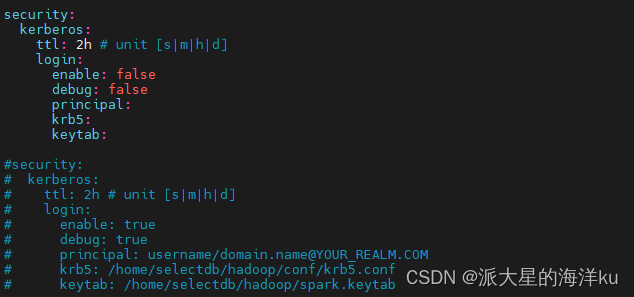
4.配置 kerberos:
如果你的hadoop集群开启了kerberos认证(未开启kerberos认证则可以跳过此步骤),则需要配置下kerberis
的信息,编辑 conf/kerberos.yml
vim conf/kerberos.yml
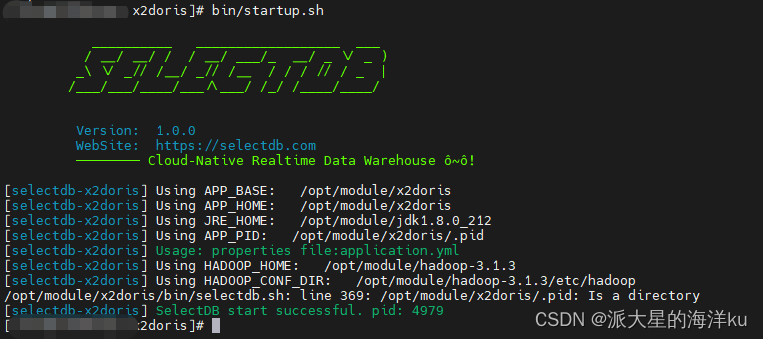
5. 启动项⽬:
bin/startup.sh
- 进⼊平台: 访问地址: http://$host:9091 ⽤户名密码: admin / selectdb
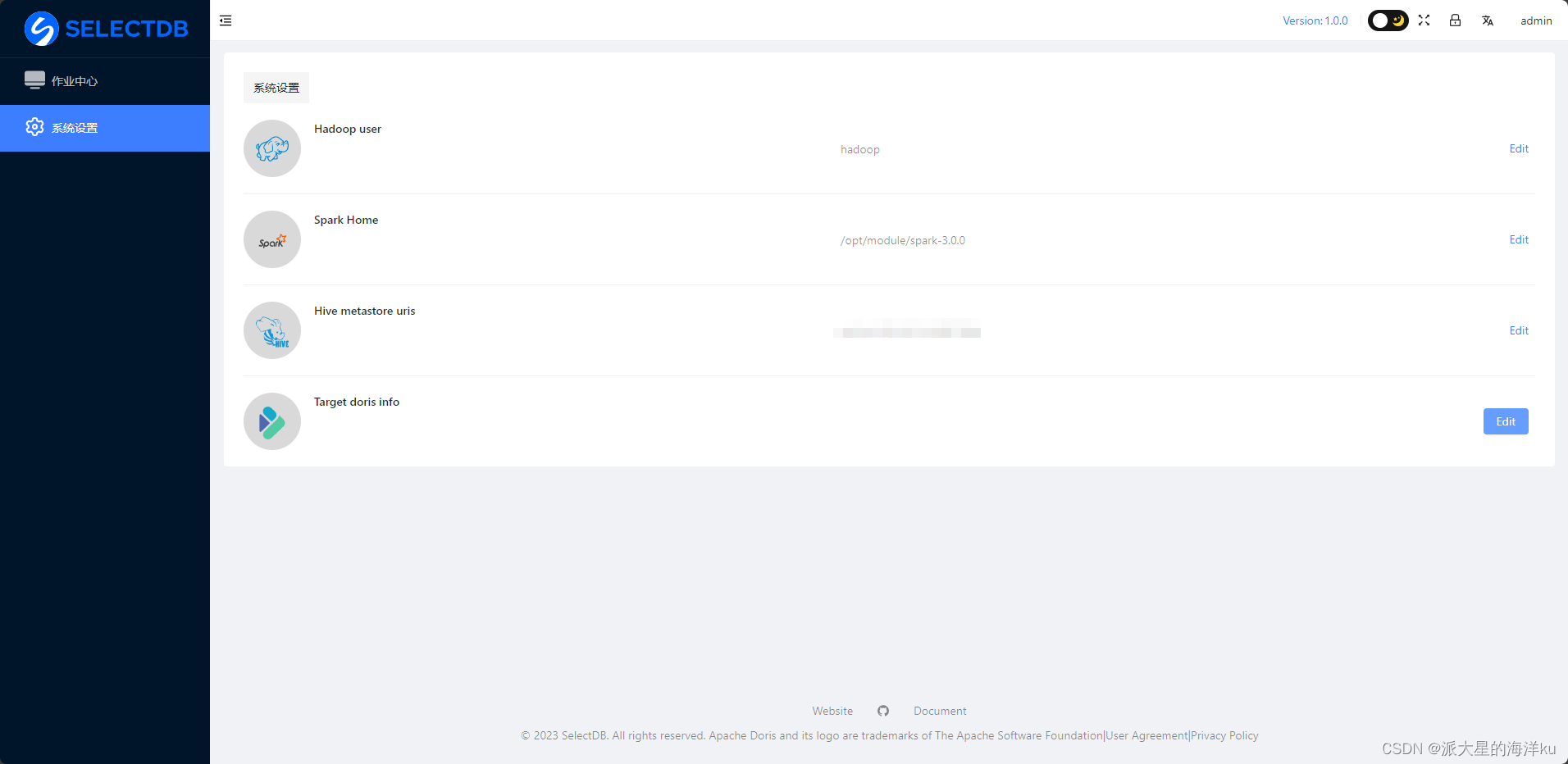
4.设置系统参数
进⼊平台之后,第⼀步就是要进⼊ 设置中⼼ 设置系统参数,该部分参数都为必须要设置的参数, 具体如下:
- Hadoop user : 该作业会访问hive数据,该 hadoop user 即为操作 hive 表的 hadoop ⽤户(⽇程hive作业的 操作⽤户即可)
- Spark Home : 指定部署机安装的spark的路径
- Hive metastore Uri : Hive 的 metastore uri ,可以去 $HADOOP_CONF_DIR 下查询 hive-site.xml
- 目标 Doris (SelectDB Cloud): 迁移数据的目标 Doris 或者 SelectDB Cloud 连接信息设置
三、使用
系统参数设置完成之后,就可以进⼊到 作业中⼼ 了,这⾥可以点击 “添加” ⼀个作业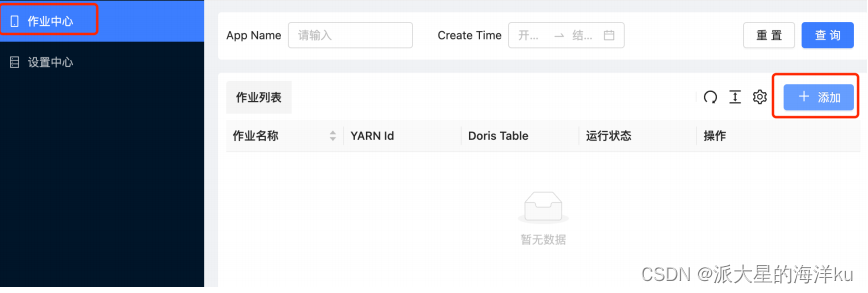
1. 字段类型映射
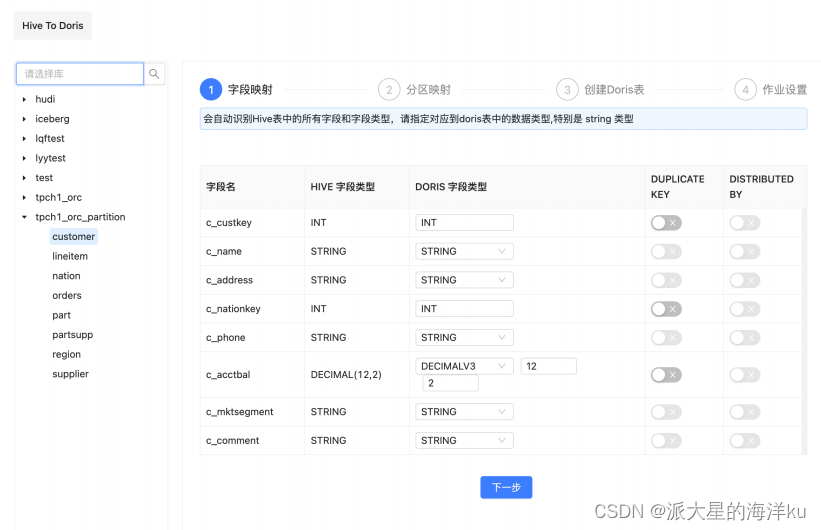
已经把hive数仓中所有的库和表都罗列出来了。可以点击左侧的树形⽬录,选择⽬标表进⾏操作,选中⼀个
表之后,右侧会⾃动罗列出该表与 doris的字段映射关系,可以很轻松的映射⽬标doris表的字段类型。根据
提示⼀路进⾏操作即可完成字段的映射。 DUPLICATE KEY 和 DISTRIBUTED KEY 是 doris Duplicate 模型中
必须要指定的参数,按需进⾏指定即可。
注意:
- 创建的doris表为 Duplicate 模型
- STRING 类型不能设置为 DUPLICATE KEY , 你需要将 STRING 类型改成 VARCHAR 类型即可
2.分区映射
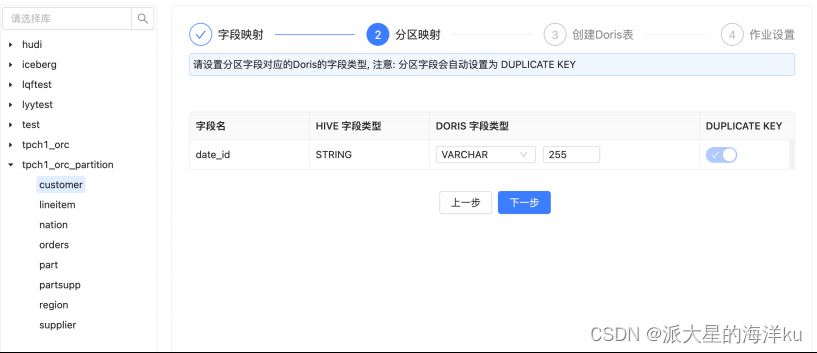
在第⼆步分区映射中,已经⾃动识别了Hive表中的分区字段,并且⾃动强制将分区⾃动设置为 DUPLICATE
KEY 如果 Hive 原表中的 字段类型是 STRING ,则可以根据数据实际类型判断是否需要将对应的doris表的字
段类型转成时间类型。如果转成时间类型的话,则需要设置分区的区间。
3. 创建Doris表
完成前两步即可进⼊到 doris 表 ddl 的确认阶段,在该阶段已经⾃动⽣成了对应的 doris 表的建表 ddl 语句,你可以进⾏review确认,⼿动修改 ddl。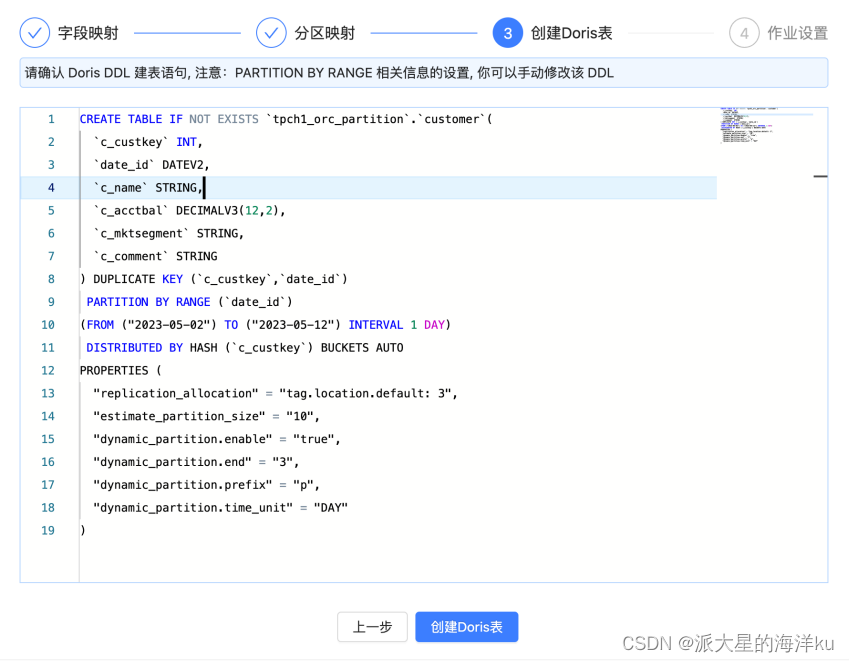
确认⽆误后,可以点击 创建 doris表
注意: 要确保对应doris的库存在,库需要⽤户⼿动创建
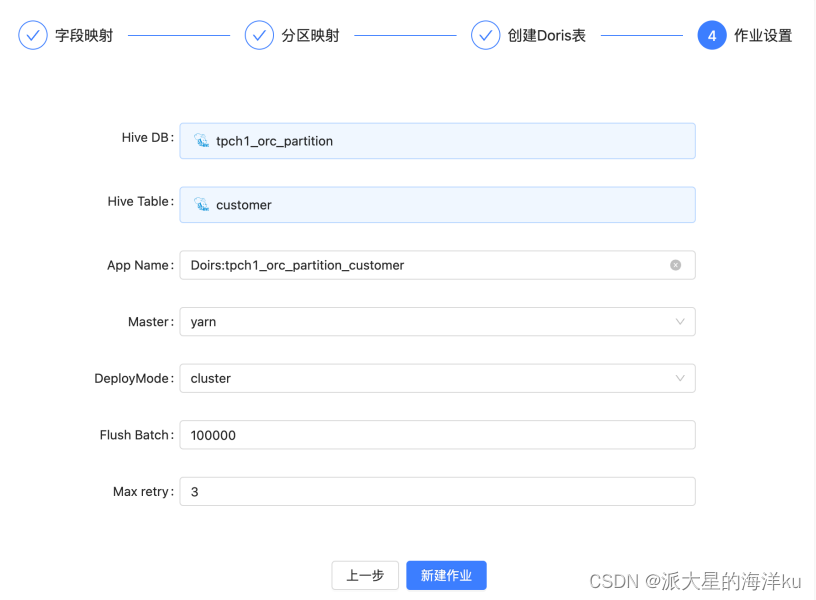
4. 作业设置
最后⼀步是同步作业的参数设置。具体如下:
App Name : 通过作业名,默认是: Doris:KaTeX parse error: Expected group after '_' at position 3: db_̲table
Master : 有两个可选项(yarn 和 local)
DeployMode : 有两个可选项( client 和 cluster)
Flush Batch : 底层写⼊doris表的批次⼤⼩,可以根据表的数据⼤⼩和写⼊吞吐⾃⾏设置
Max retry : 写⼊doris失败最⼤的重试次数
特别注意:
Master 和 DeployMode 为 spark提交的参数,同步作业底层采⽤了spark
- ⽣产环境使⽤建议将 Master 设置为 yarn , DeployMode 设置为 cluster
- 如果是单机测试,可以选择 local ,如果 Master 为 local 的话,对应的 DeployMode 只能为client
这两个参数的设置⼀定要遵循spark的要求,更多信息可以查阅spark⽂档
确定好之后就可以点击“新建作业”, 作业创建完成会⾃动跳转到作业列表⻚⾯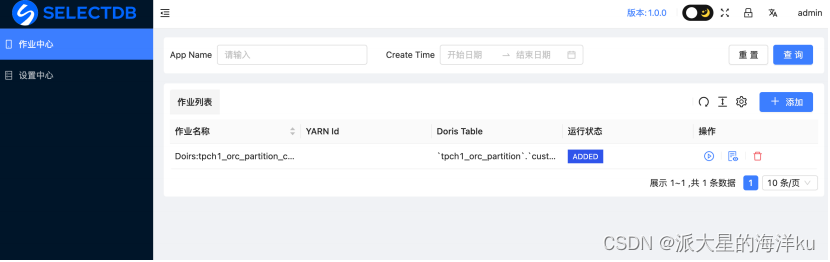
点击 启动 即可启动该同步作业。
即可手动一键同步各表数据
版权归原作者 派大星的海洋ku 所有, 如有侵权,请联系我们删除。