
2023最全kafka面试和答案
1.Kafka中的ISR(InSyncReplicate)、OSR(OutSyncReplicate)、AR(AllReplicate)代表什么?
- ISR : 速率和leader相差低于10秒的follower的集合
- OSR : 速率和leader相差大于10秒的follower
- AR : 所有分区的follower
- AR=ISR+OSR
2.Kafka中的HW、LEO、LSO、LW等分别代表什么
- HW:High Watermark 高水位,取一个partition对应的ISR中最小的LEO作为HW,consumer最多只能消费到HW所在的位置上一条信息。
- LEO:LogEndOffset 当前日志文件中下一条待写信息的offset
- HW/LEO这两个都是指最后一条的下一条的位置而不是指最后一条的位置。
- LSO:Last Stable Offset 对未完成的事务而言,LSO 的值等于事务中第一条消息的位置(firstUnstableOffset),对已完成的事务而言,它的值同 HW 相同
- LW:Low Watermark 低水位, 代表 AR 集合中最小的 logStartOffset 值
3.Kafka中是怎么体现消息顺序性的?
每个分区内,每条消息都有offset,所以只能在同一分区内有序,但不同的分区无法做到消息顺序性;如果实在想顺序消费的话,可以要将消费组只弄一个消费者
4.“消费组中的消费者个数如果超过topic的分区,那么就会有消费者消费不到数据”这句话是否正确?
对的,超过分区数的消费者就不会再接收数据
5.有哪些情形会造成重复消费?或丢失信息?
- 先处理后提交offset,会造成重读消费
- 先提交offset后处理,会造成数据丢失 6.Kafka 分区的目的?
- 对于kafka集群来说,分区可以做到负载均衡,对于消费者来说,可以提高并发度,提高读取效率。
7.Kafka 的高可靠性是怎么实现的?
- 7.1 消息生成端可靠性保证(设置ack参数): 当ack=0时,producer不等待broker的ack,不管数据有没有写入成功,都不再重复发该数据 当ack=1时,broker会等到leader写完数据后,就会向producer发送ack,但不会等follower同步数据,如果这时leader挂掉,producer会对新的leader发送新的数据,在old的leader中不同步的数据就会丢失 当ack=-1或者all时,broker会等到leader和isr中的所有follower都同步完数据,再向producer发送ack,有可能造成数据重复
- 7.2 消息消费端可靠性保证(设置ack参数)
- topic的分区数可不可以增加?如果可以怎么增加?如果不可以,那又是为什么? 可以增加
bin/kafka-topics.sh --zookeeper localhost:2181/kafka --alter --topic topic-config --partitions 3
9.topic的分区数可不可以减少?如果可以怎么减少?如果不可以,那又是为什么?
- 不可以,先有的分区数据难以处理 10.简述Kafka的日志目录结构?
- 每一个分区对应一个文件夹,命名为topic-0,topic-1,每个文件夹内有.index和.log文件 11.如何解决消费者速率低的问题?
- 增加分区数和消费者数
- Kafka的那些设计让它有如此高的性能?? kafka是分布式的消息队列,对log文件进行了segment,并对segment建立了索引,(对于单节点)使用了顺序读写,速度可以达到600M/s,引用了zero拷贝,在os系统就完成了读写操作 13.kafka启动不起来的原因?
- 在关闭kafka时,先关了zookeeper,就会导致kafka下一次启动时,会报节点已存在的错误
- 只要把zookeeper中的zkdata/version-2的文件夹删除即可
14.聊一聊Kafka Controller的作用?
负责kafka集群的上下线工作,所有topic的副本分区分配和选举leader工作
15. Kafka中有那些地方需要选举?这些地方的选举策略又有哪些?
在ISR中需要选择,选择策略为先到先得
16.失效副本是指什么?有那些应对措施?
- 失效副本为速率比leader相差大于10秒的follower
- 将失效的follower先提出ISR
- 等速率接近leader10秒内,再加进ISR
17.Kafka消息是采用Pull模式,还是Push模式?
- 在producer阶段,是向broker用Push模式
- 在consumer阶段,是向broker用Pull模式 *在Pull模式下,consumer可以根据自身速率选择如何拉取数据,避免了低速率的consumer发生崩溃的问题 但缺点是,consumer要时不时的去询问broker是否有新数据,容易发生死循环,内存溢出。
- Kafka创建Topic时如何将分区放置到不同的Broker中?
- 首先副本数不能超过broker数
- 第一分区是随机从Broker中选择一个,然后其他分区相对于0号分区依次向后移
- 第一个分区是从nextReplicaShift决定的,而这个数也是随机产生的
19.Kafka中的事务是怎么实现的?
- producer事务是为了解决kafka跨分区跨会话问题,kafka不能跨分区跨会话的主要问题是每次启动的producer的PID都是系统随机给的 所以为了解决这个问题,我们就要手动给producer一个全局唯一的id,也就是transaction id 简称TID 我们将TID和PID进行绑定,在producer带着TID和PID第一次向broker注册时,broker就会记录TID,并生成一个新的组件transaction_state用来保存TID的事务状态信息。当producer重启后,就会带着TID和新的PID向broker发起请求,当发现TID一致时,producer就会获取之前的PID,将覆盖掉新的PID,并获取上一次的事务状态信息,从而继续上次工作
- consumer事务相对于producer事务就弱一点,需要先确保consumer的消费和提交位置为一致且具有事务功能,才能保证数据的完整,不然会造成数据的丢失或重复
- Kafka中的分区器、序列化器、拦截器是否了解?它们之间的处理顺序是什么? 拦截器>序列化器>分区器
- Kafka生产者客户端的整体结构是什么样子的?使用了几个线程来处理?分别是什么?
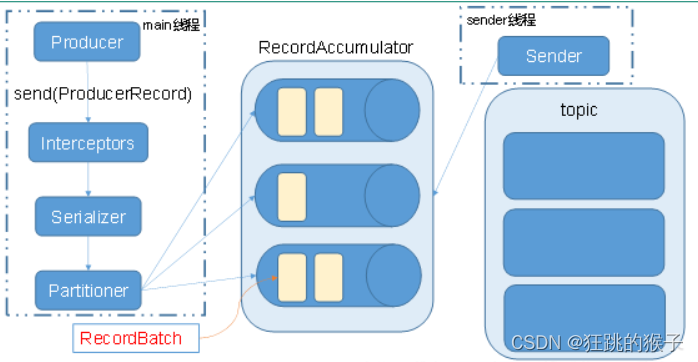 使用两个线程: main线程和sender线程 main线程会依次经过拦截器,序列化器,分区器将数据发送到RecourdAccumlator(线程共享变量)。再由sender线程从RecourdAccumlator中拉取数据发送到kafka broker 相关参数:
使用两个线程: main线程和sender线程 main线程会依次经过拦截器,序列化器,分区器将数据发送到RecourdAccumlator(线程共享变量)。再由sender线程从RecourdAccumlator中拉取数据发送到kafka broker 相关参数:
- batch.size:只有数据积累到batch.size之后,sender才会发送数据。
- linger.ms:如果数据迟迟未达到batch.size,sender等待linger.time之后就会发送数据。
- 消费者提交消费位移时提交的是当前消费到的最新消息的offset还是offset+1?
- offset + 1
本文转载自: https://blog.csdn.net/qq_35725645/article/details/130979183
版权归原作者 狂跳的猴子 所有, 如有侵权,请联系我们删除。
版权归原作者 狂跳的猴子 所有, 如有侵权,请联系我们删除。