
文章目录
回顾
什么是驱动?驱动的工作原理是什么?
举个例子:
将 浏览器 比作是一两出租车。
将自动化测试脚本 视作 用户的需求
驱动 好比是 司机
司机( webdriver)把乘客的“需求(脚本)”,“告诉 / 翻译(操作)” 出租车(浏览器)实现它。换个说法:
汽车有驱动,分别为 两轮驱动,四轮驱动,无卵是中驱动方式都可以使汽车跑起来。
计算机也有驱动,可以驱动计算机和设备工作起来打开浏览器也需要驱动!
人工测试情况下(人工手动的操作(驱动)浏览器)
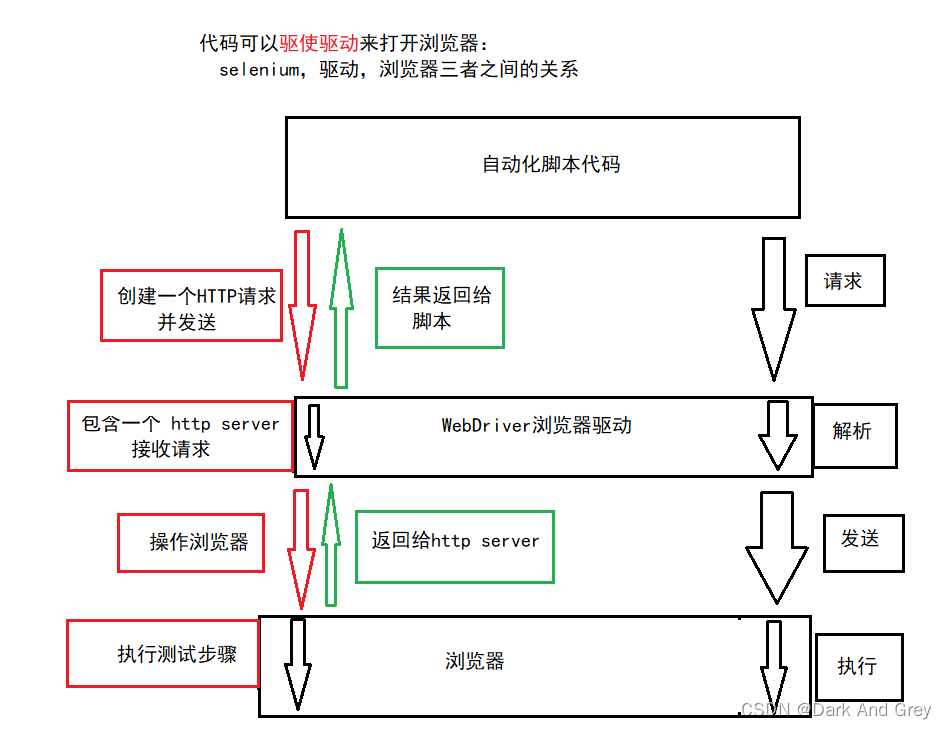
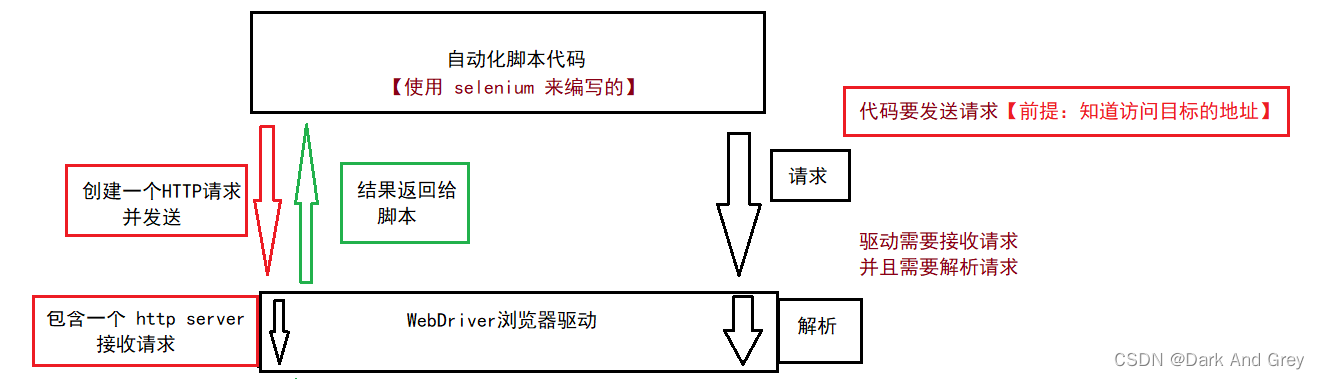
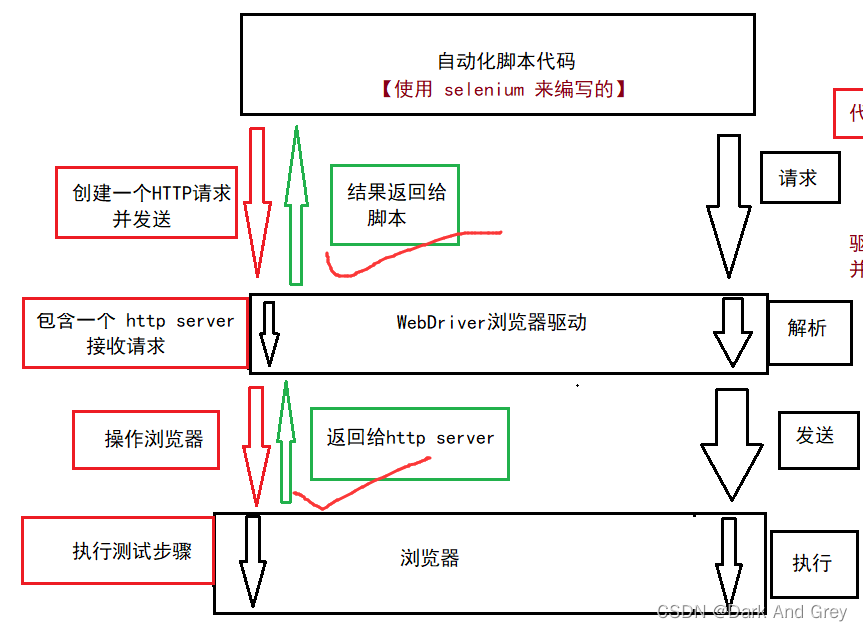
自动化来说,代码不能够直接打开浏览器,需要借助驱动程序来协助打开浏览器。下面我们来一下驱动的工作原理图:
先来看第一部分:自动化脚本代码
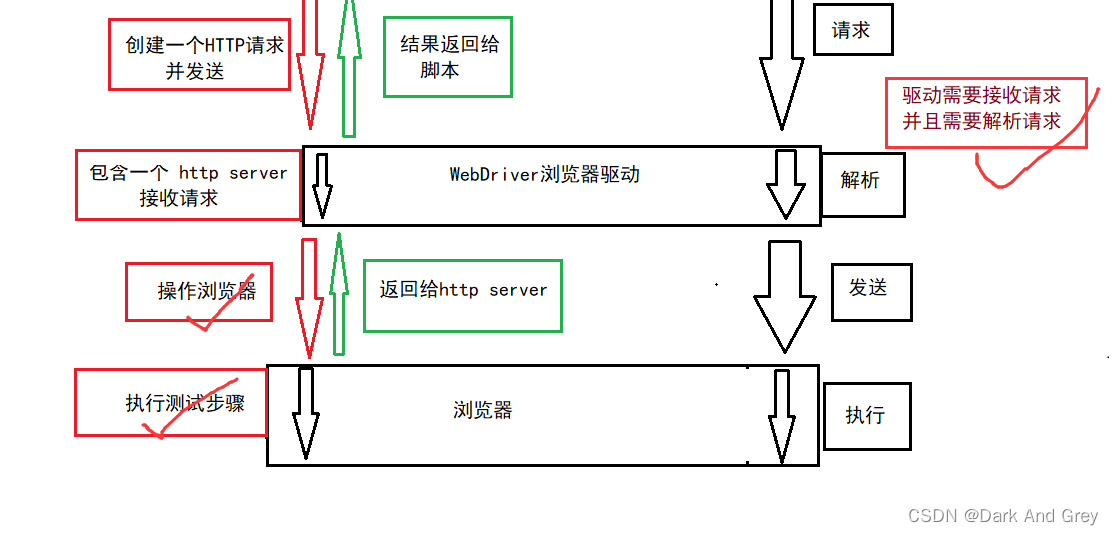
再来看第二部分:WebDriver 部分
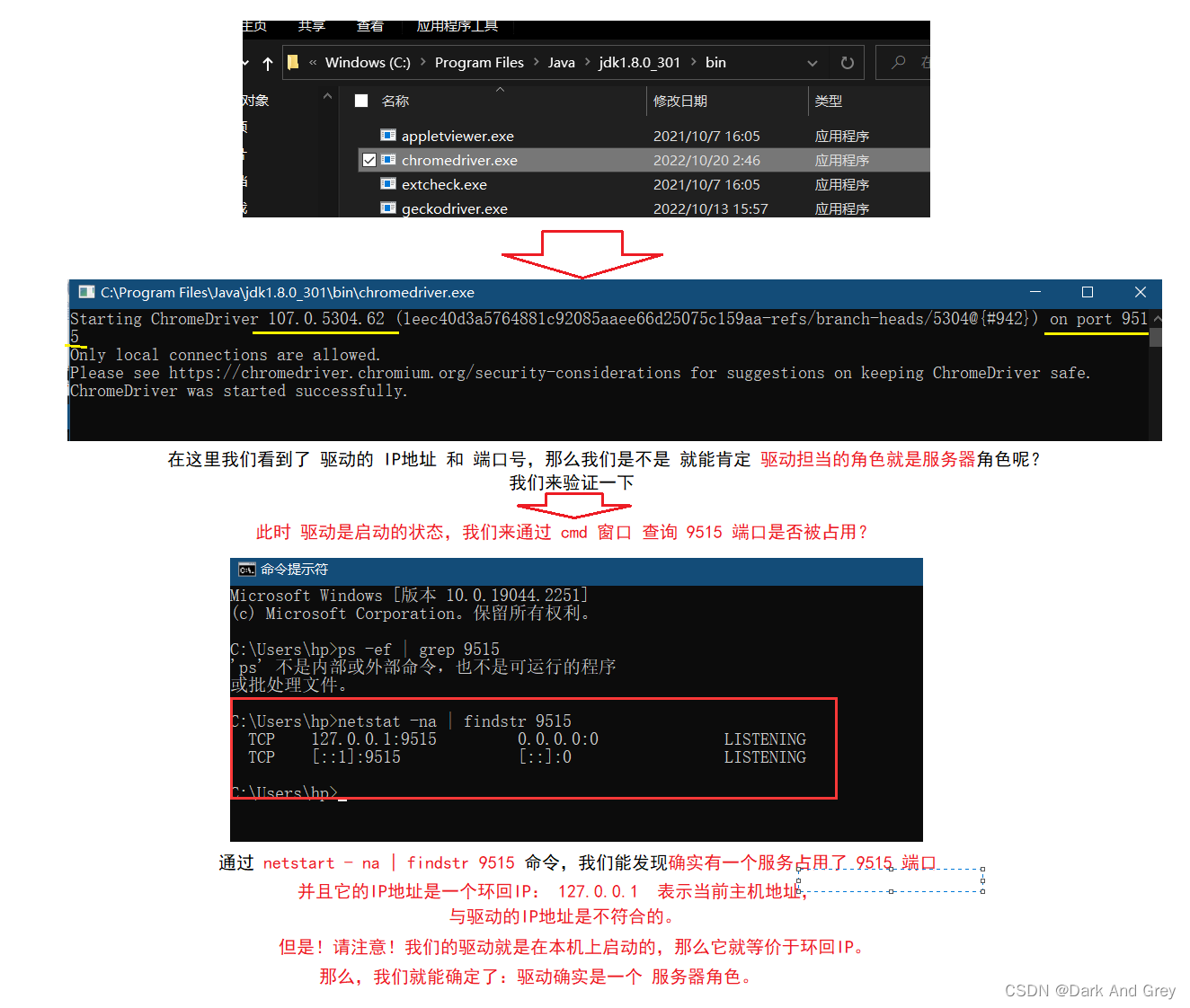
那么驱动在其中又担当什么角色呢?
既然能够接收请求的,驱动应该是一个服务器,那么就需要知道它的IP 和 端口号,才能定位它。
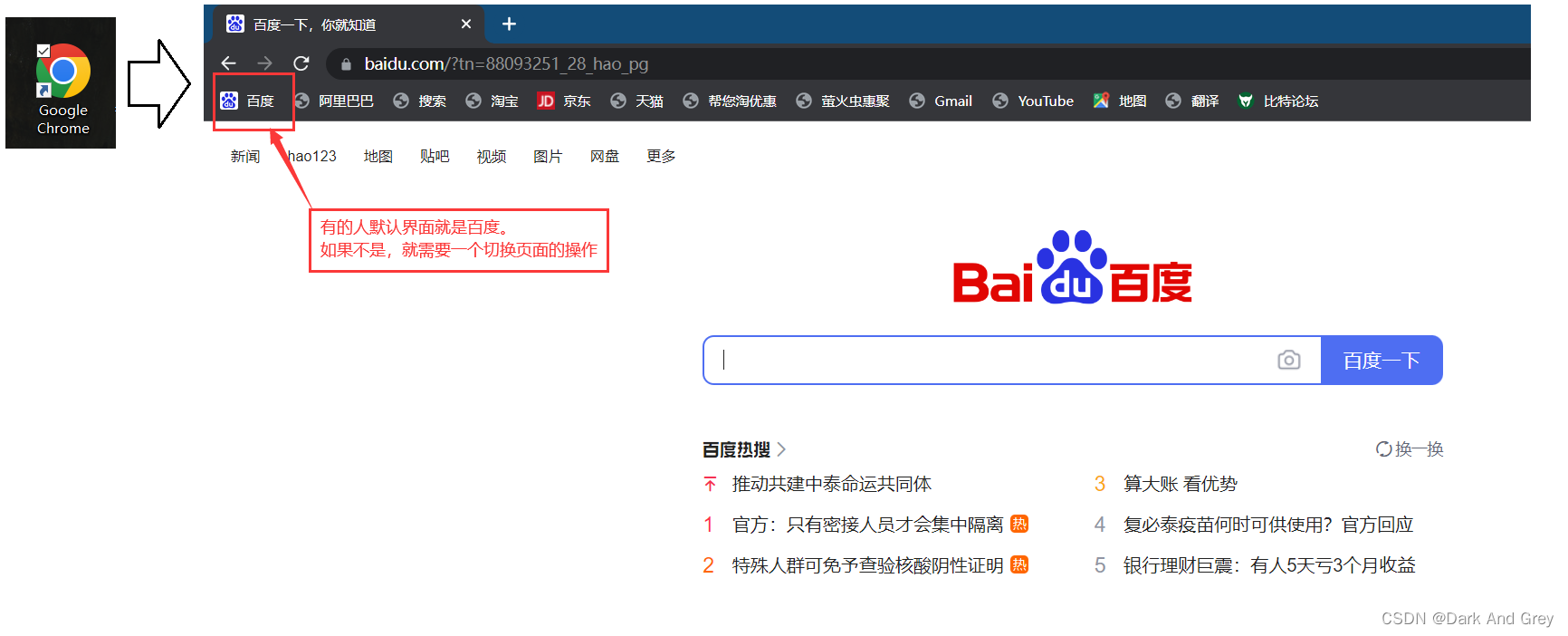
下面我们来打开 Chrome 浏览器的驱动,看一下究竟是否像我们想象的那样。
通过上述的分析,我们确认是 驱动就是一个服务器。接着我们继续分析:
当我们的脚本的代码生成一个HTTP请求 发送到 浏览器驱动(WebDrive)的时候,WebDrive 会对这个请求进行解析,然后再发送给我们的浏览器,让我们的浏览器以原生的方式去执行前端的一个命令。在浏览器执行完成之后,会把执行的结果返回 驱动,驱动再把这个结果传递给我们的脚本代码

一个简单的 Web自动化 演示
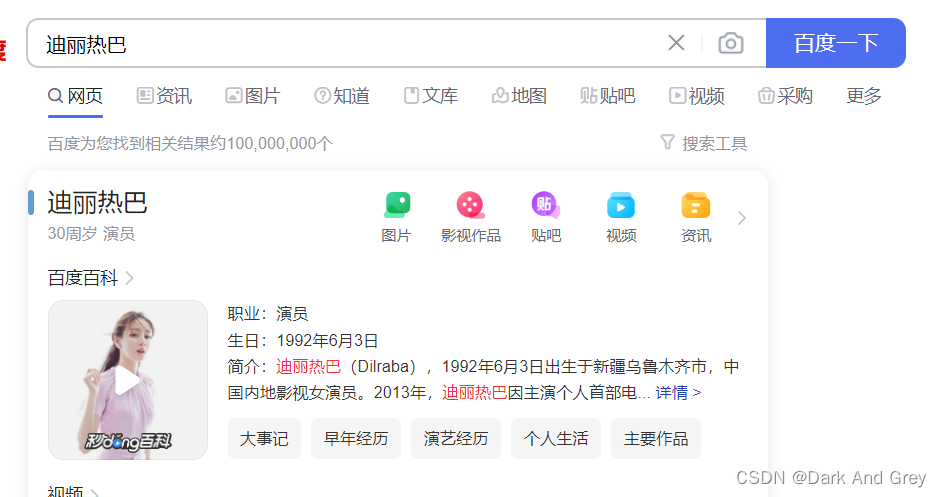
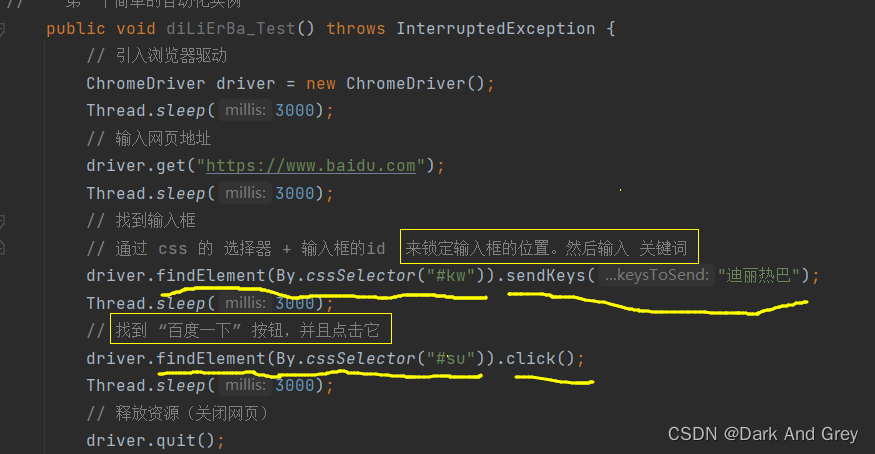
百度一下 迪丽热巴
这样的一个用户行为 ,会涉及的那些操作呢?
1、打开浏览器2、在输入框里面输入关键词【迪丽热巴】
PS:当然这里可能还涉及到一个操作,回车执行操作。
或者说:点击 “百度一下” 按钮。
只是说现在的浏览器将执行操作设置成自动执行了。3、在搜索完成之后,关闭浏览器
操作的大致流程就是这样的,那么自动化脚本该如何去写呢?
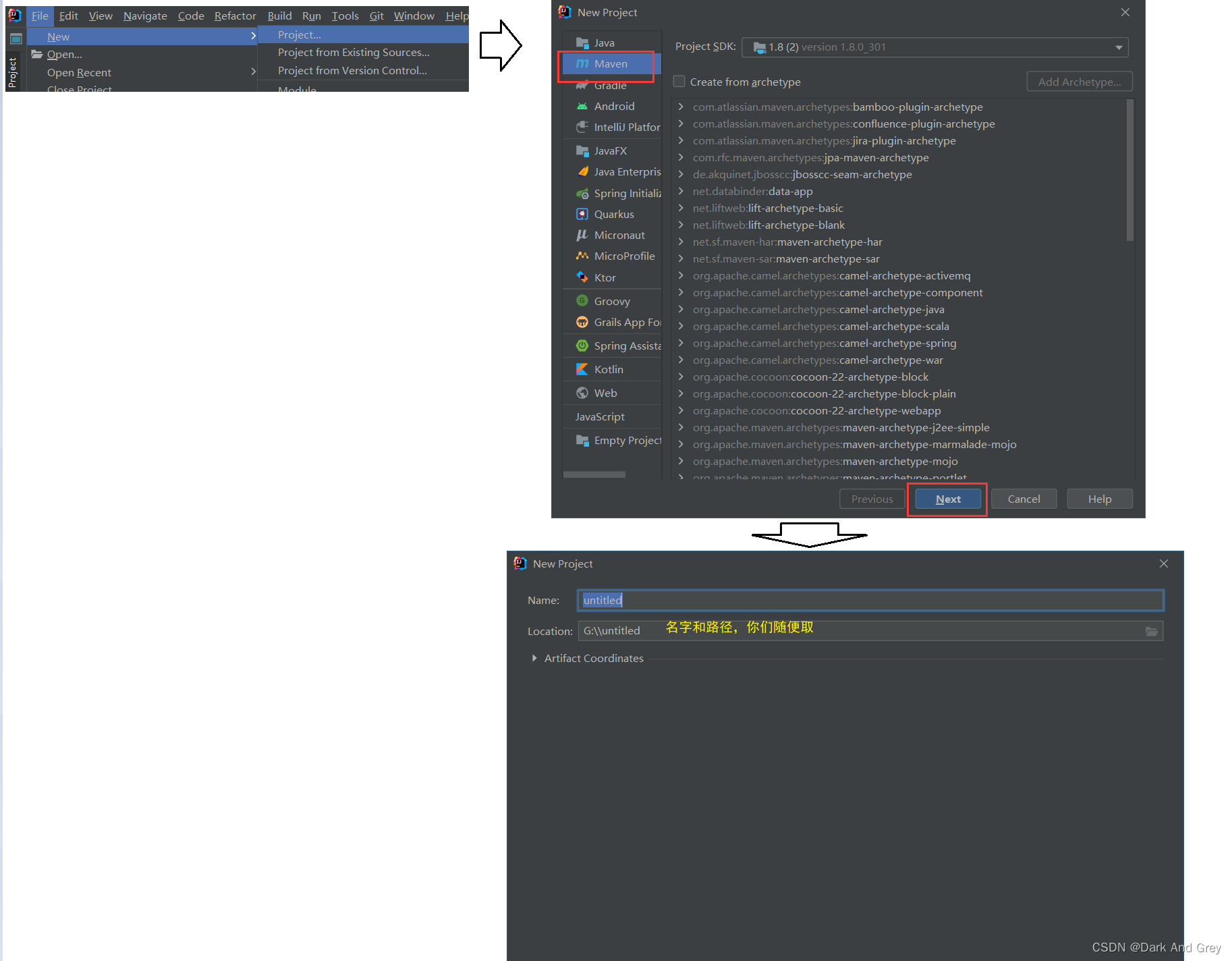
1、打开我们的 IDEA 编译器,新建一个项目
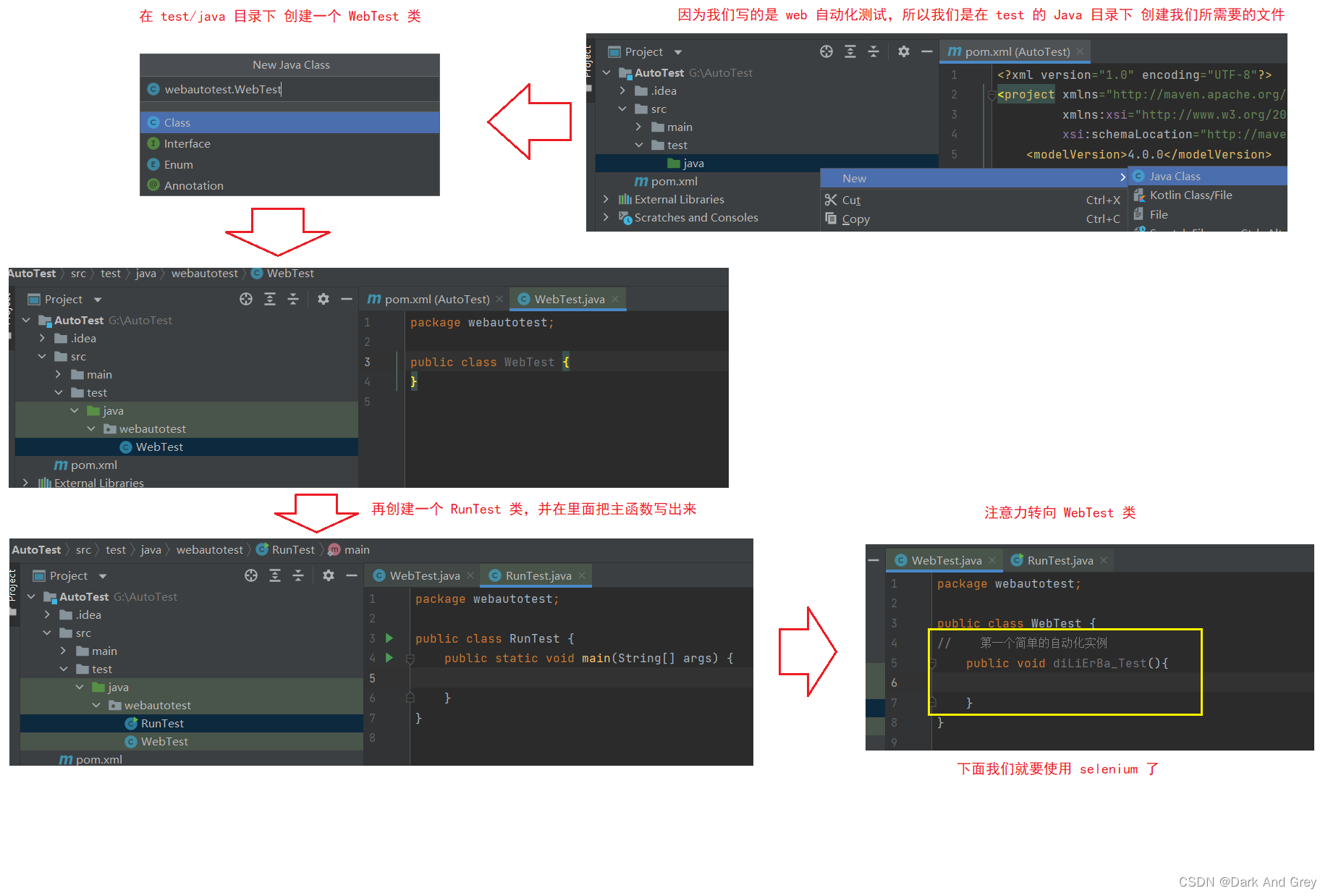
2、创建测试脚本文件
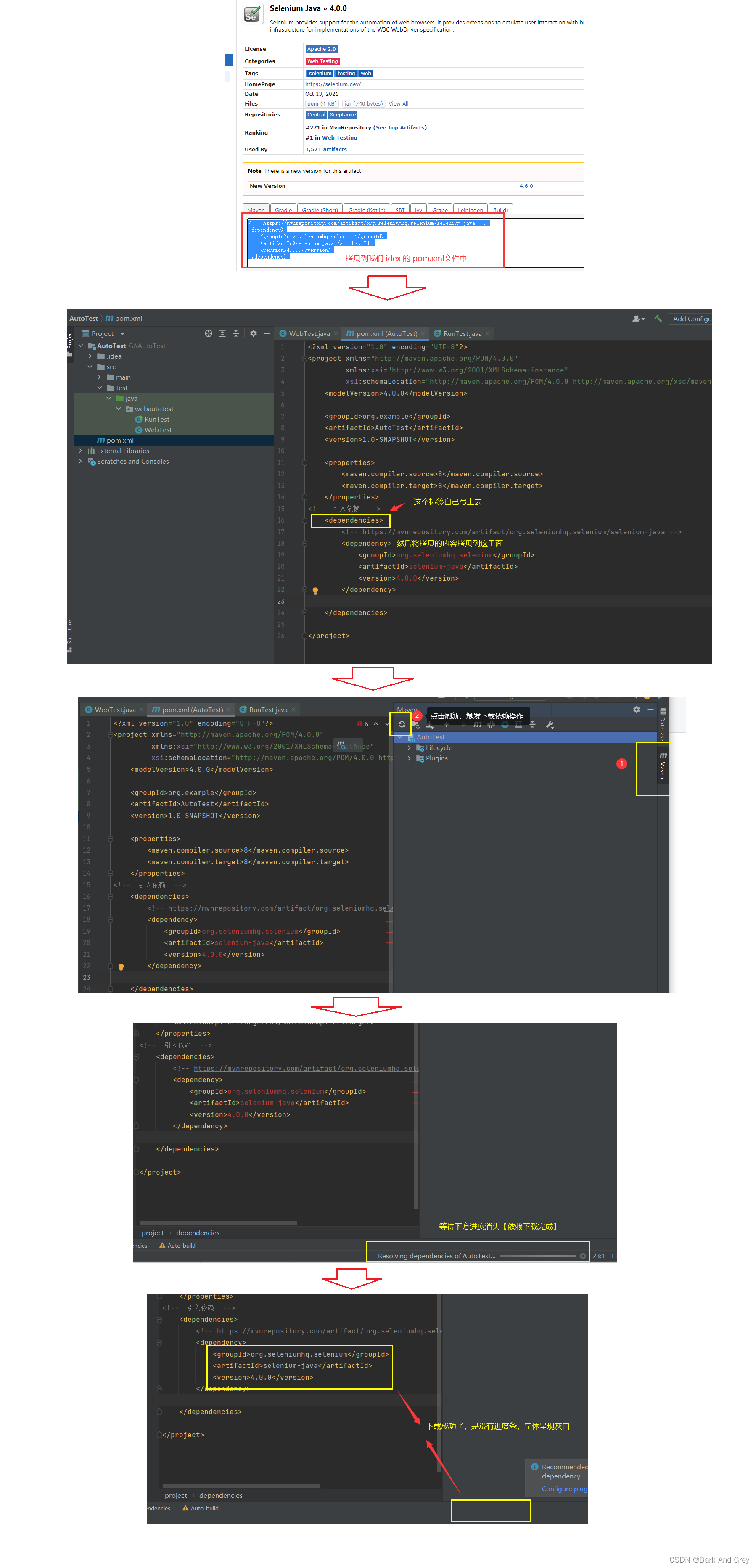
selenium 的 依赖我们去 Maven 的中央厂库里下载。
链接https://mvnrepository.com/artifact/org.seleniumhq.selenium/selenium-java
注意!千万不要下载 3.0版本 的 selenium,它的语法有所不同。
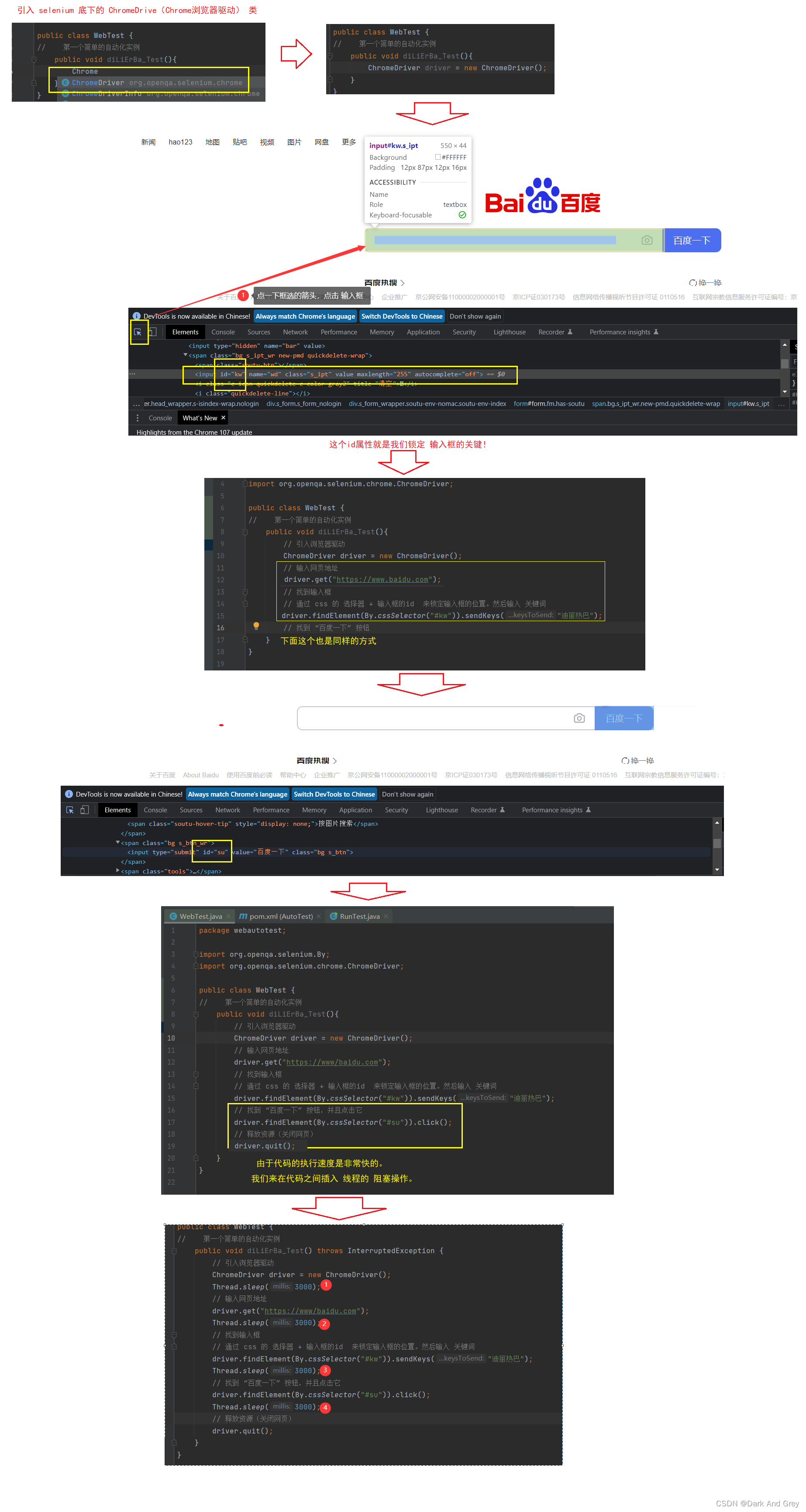
接下来,哦们就来使用 selenium
此时,脚本代码的测试逻辑已将完成了。
下面,我们回到 RunTest 类,去使用它。
下面我们执行这个类,你们就能看到现象:自动打开浏览器,进入到百度网页,输入关键词进行查询。查询之后,自动关闭浏览器。简单的自动化测试脚本 - 百度搜索

1、定位元素的方法 - 只介绍两种最常使用的
1、CSS 选择器【cssSelector 方法】
参考文章:https://blog.csdn.net/DarkAndGrey/article/details/124482318
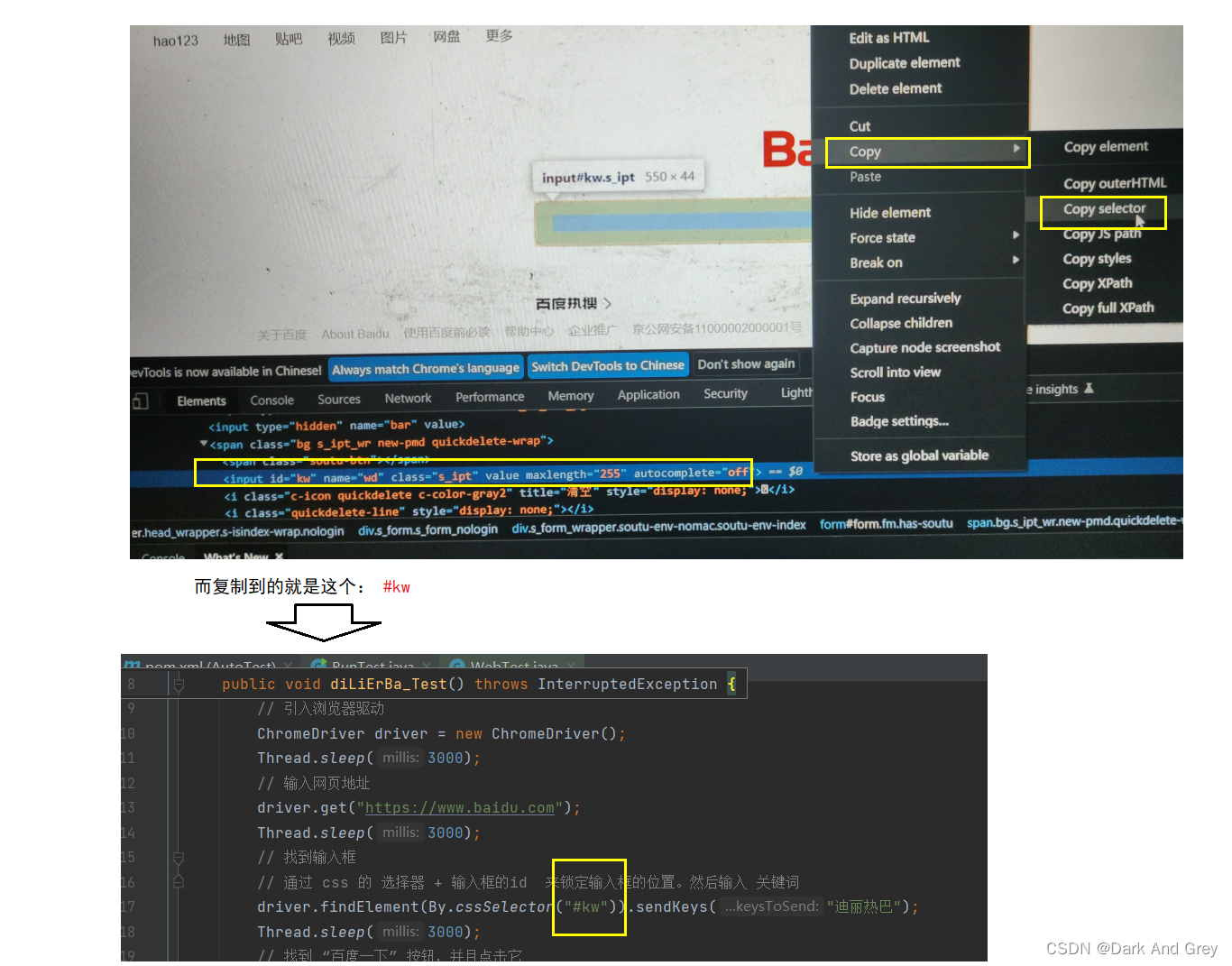
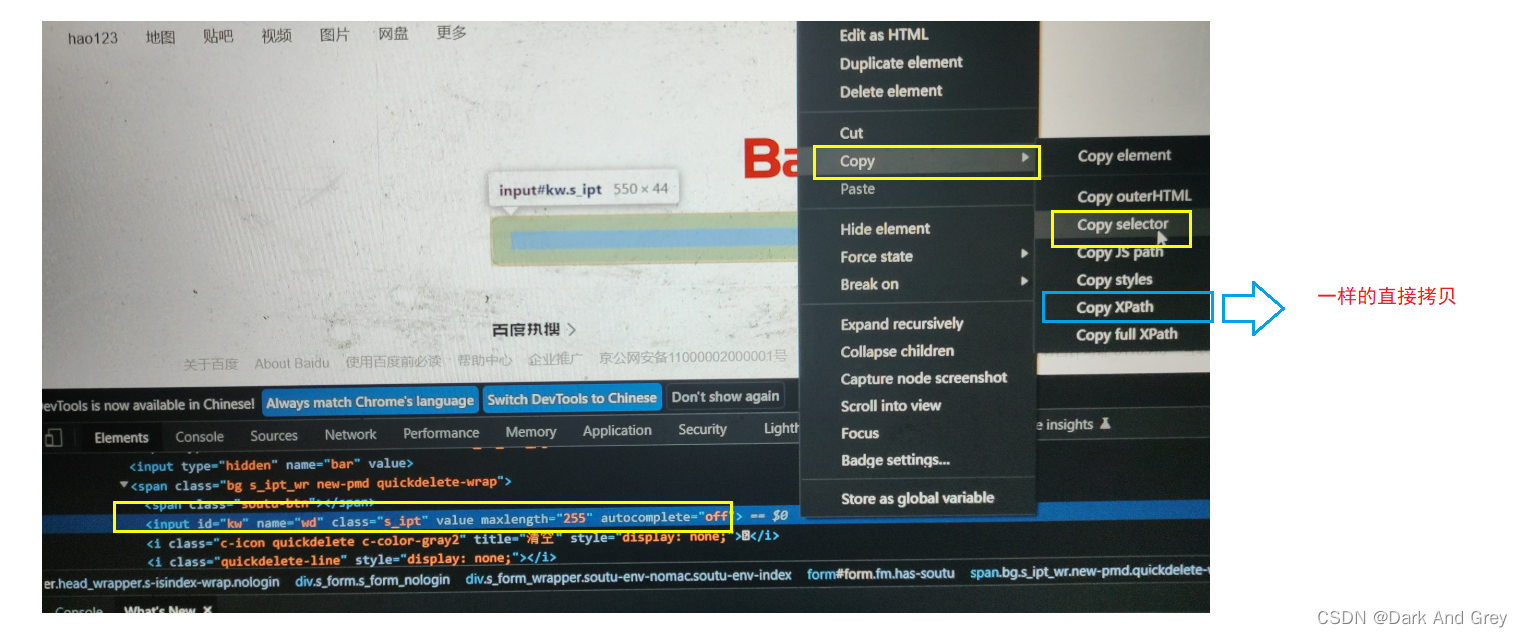
如果你不懂前端的知识,有更简单获取 css 选择器 的方式:
2、xpath 选择器 - 了解
xpath 语法:
1、层级: / 【表示 次级】; // 【表示 跳级】
2、属性: @ 等等。。。
3、函数: contains()等等。。。
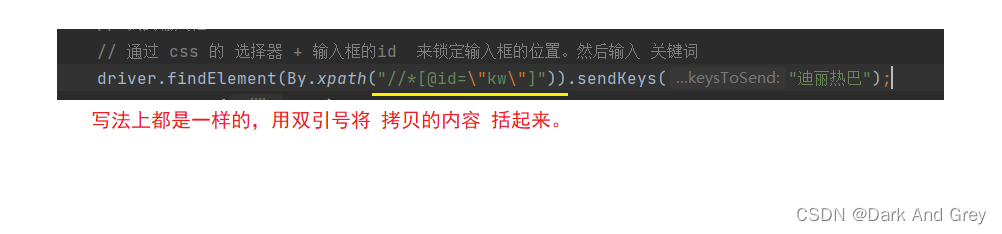
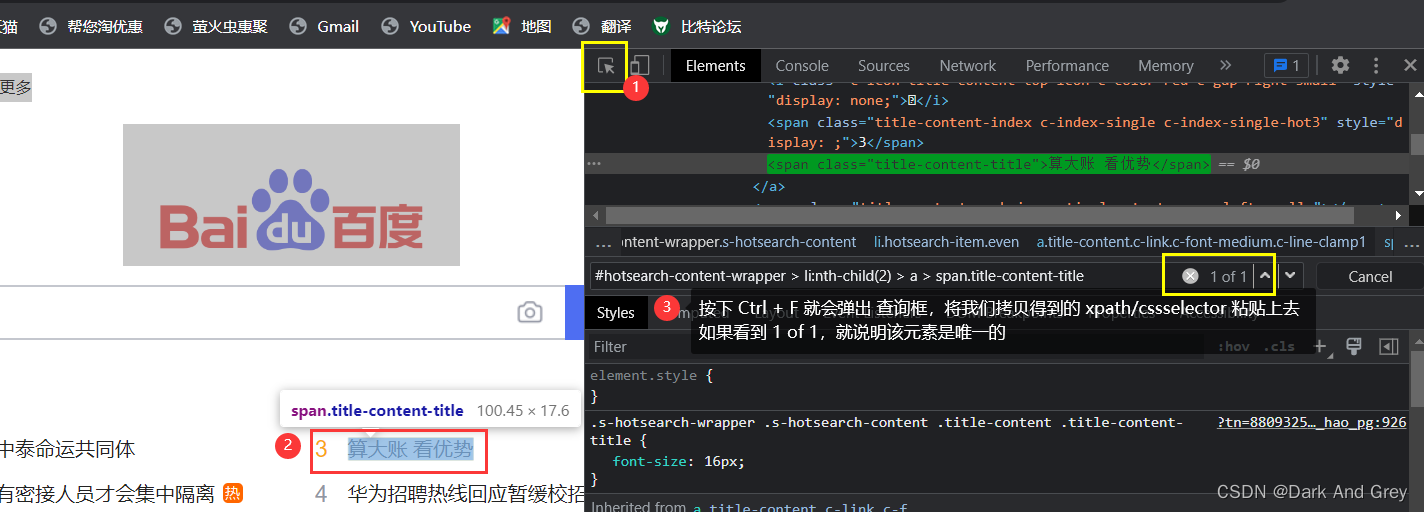
效果我就不展示了,都一样。需要注意的是:定位的元素必须要唯一。
意思就是说:
无论我们复制的是 css,还是xpath,都有可能找到复数的结果。
那么,就很有可能导致查询的结果,与预期结果不一样!
我们可以通过下面的方法来检查元素的唯一性。
2、元素的操作
前面讲到了不少知识都是定位元素,定位只是第一步,定位之后需要对这个元素进行操作。
是鼠标点击,还是键盘输入,或者清除元素的内容,或者提交表单等。
这个取决于定位元素需要进行的下一步操作。
其实在我们演示的自动化脚本中,我们已经对元素进行操作了。
后面的输入关键词,以及点击 百度一下的按钮,都是对元素的操作。元素的操作,又称操作测试对象。
webdriver 中比较常用的操作对象的方法有下面几个:
1、click 点击对象
2、sendKeys 在对象上模拟按键输入
3、clear 清除对象输入的文本内容
4、submit 提交【等价于 click】click 和 submit 都可以操作按钮
【前提:submit 操作的是按钮】
可以使用 submit 的地方,都可以使用 click 来实现。文本样式的超链接的触发,只能通过 click(点击)的方式来触发。
如果使用 sumbit 的方式来触发,就会报错。
在 selenium 官方文档中,更推荐使用 click
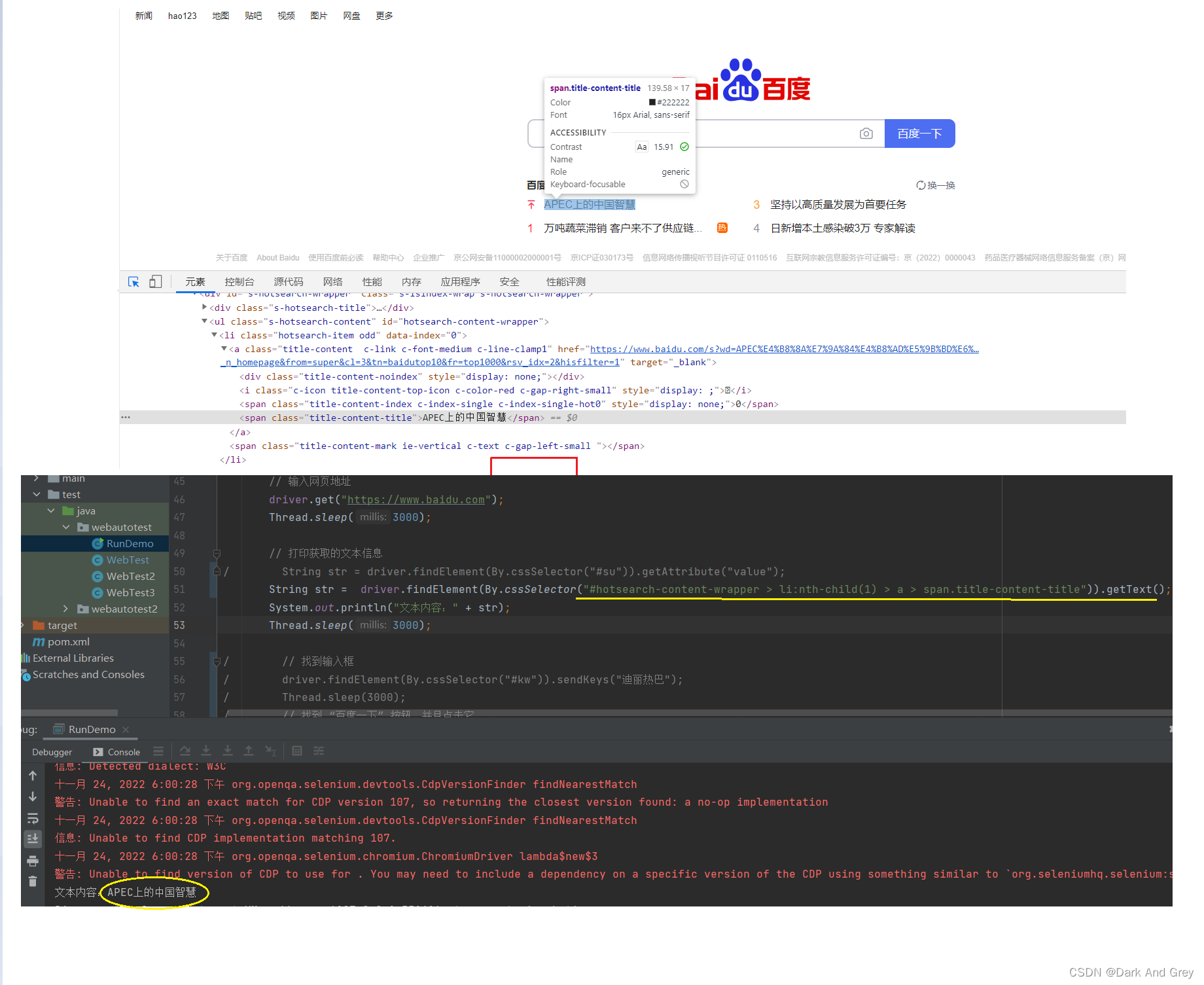
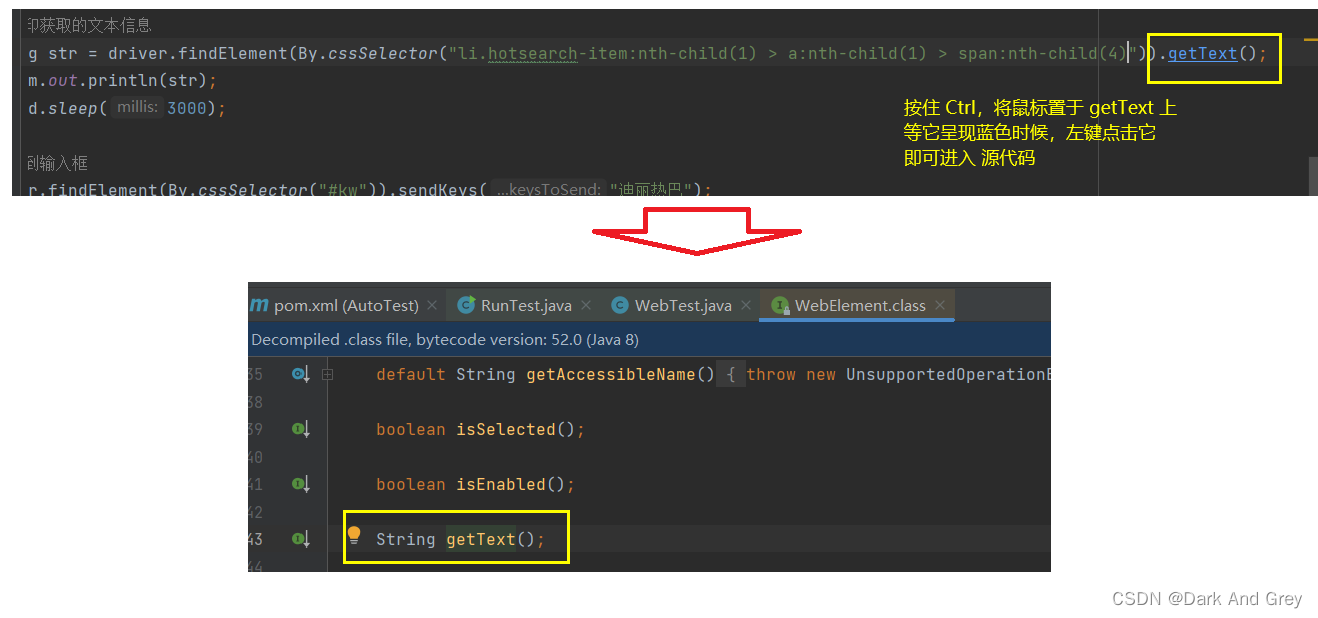
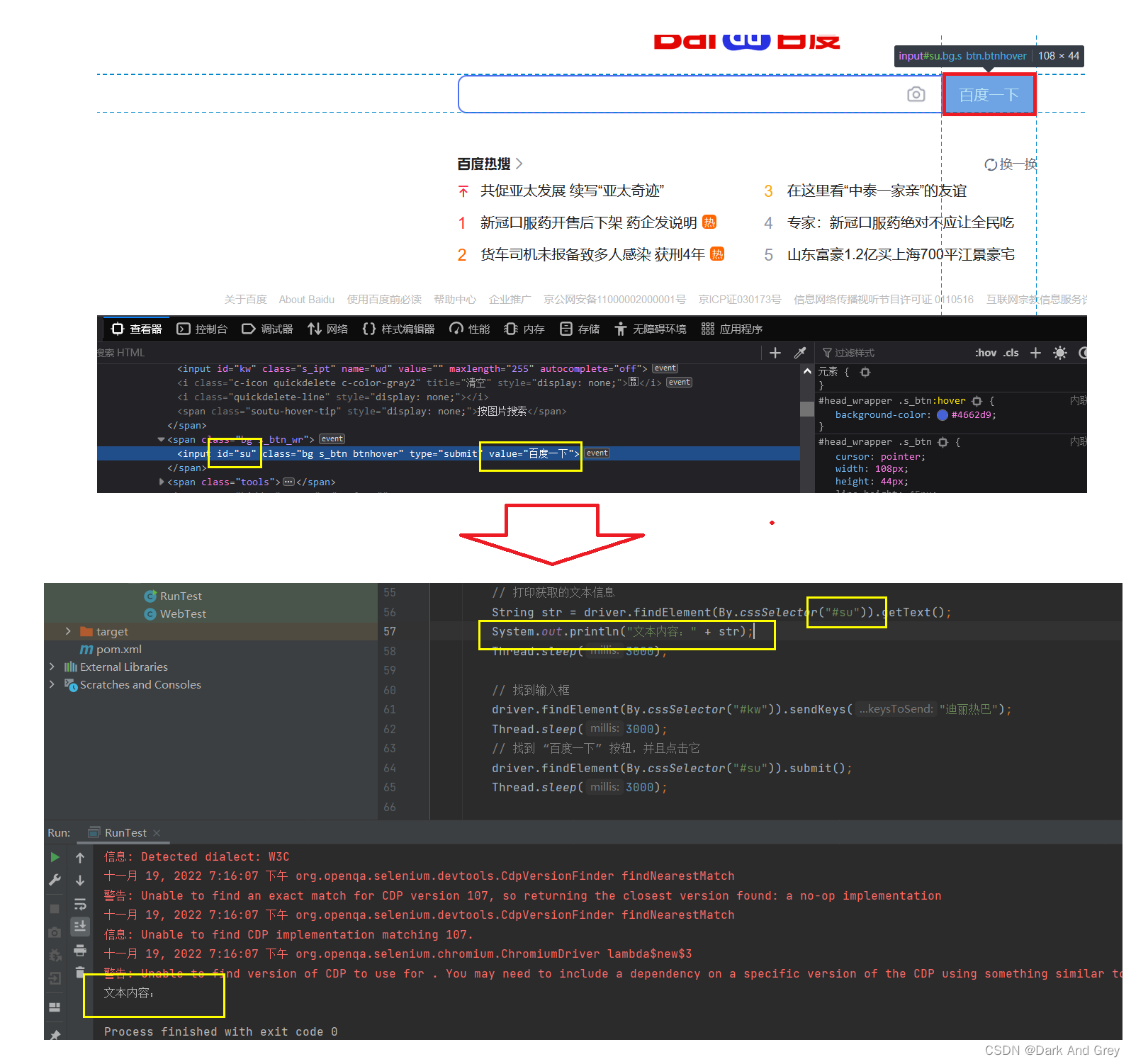
不推荐使用 submit。5、getText 用于获取元素的文本信息
另外,为什么我们是使用的 String 类型 来接收 getText 的 返回值呢?
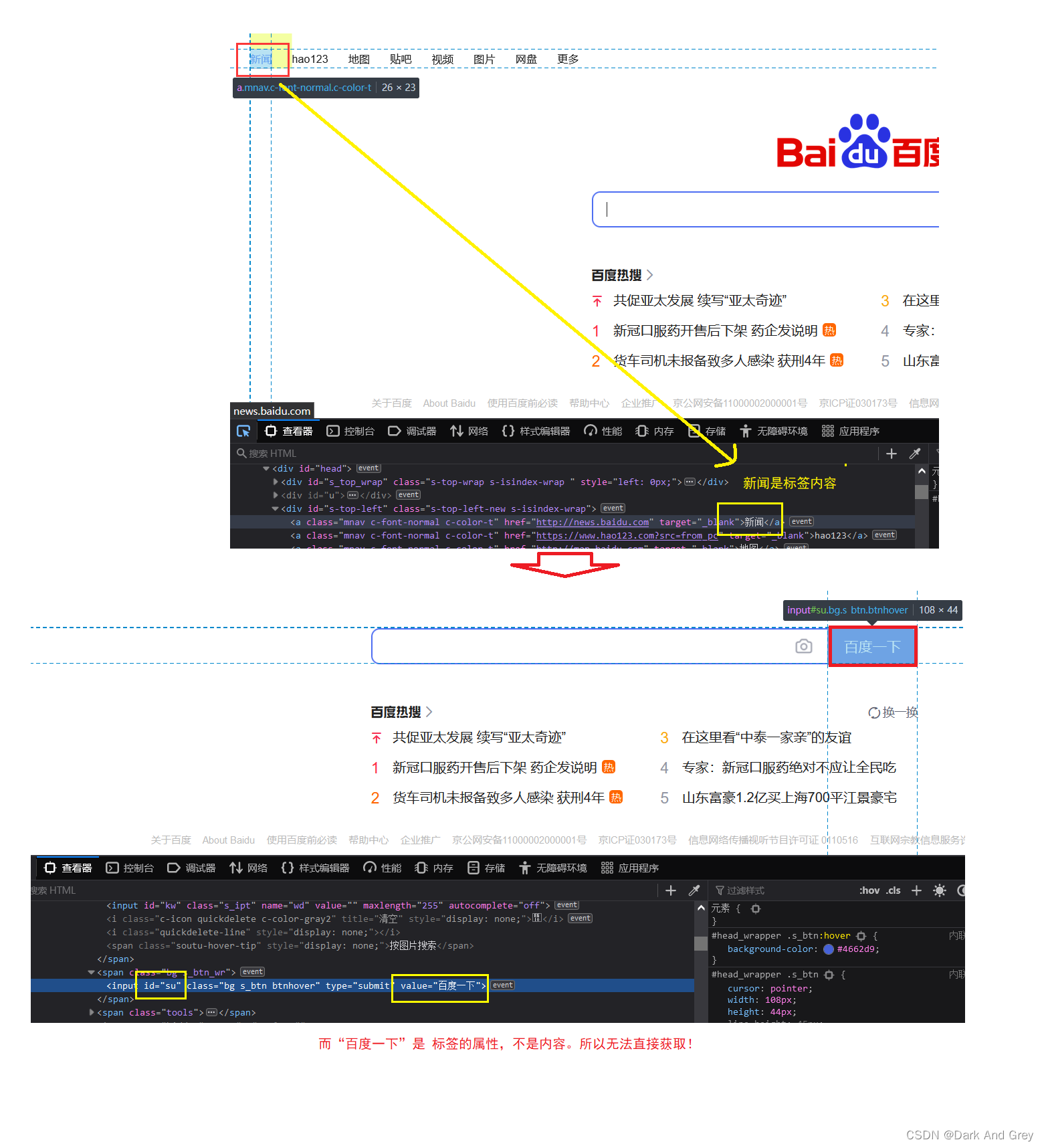
还有一个点,这个百度一下按钮的值是获取不到的
我们来分析一下原因:
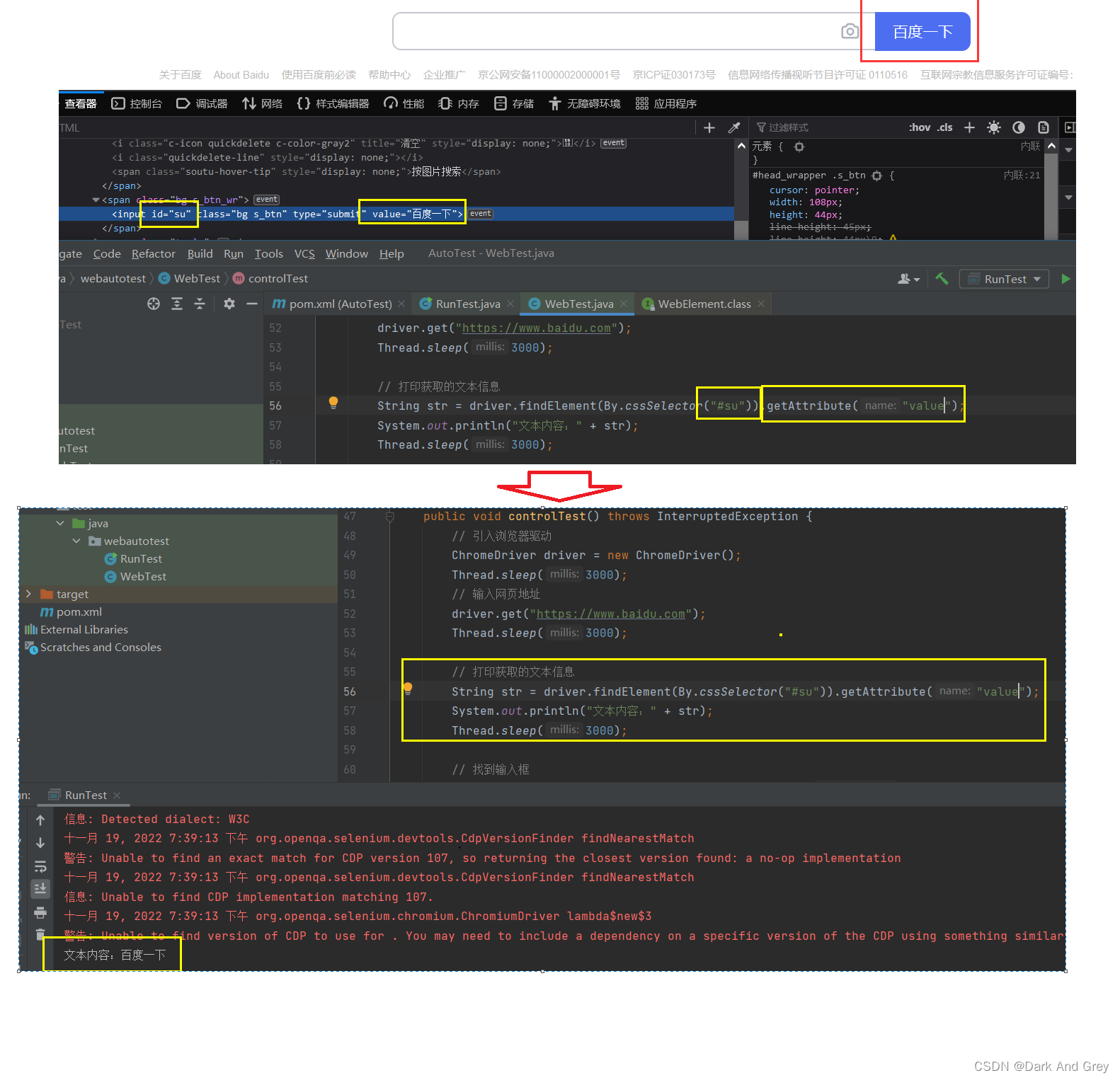
那么,我们如何获取到 标签的属性值呢?
使用 getAttribute 方法通过指定属性名称,来获取指定的属性值。这些你们有时间都可以尝试一下,反正也不难。

3、等待
3.1、强制等待
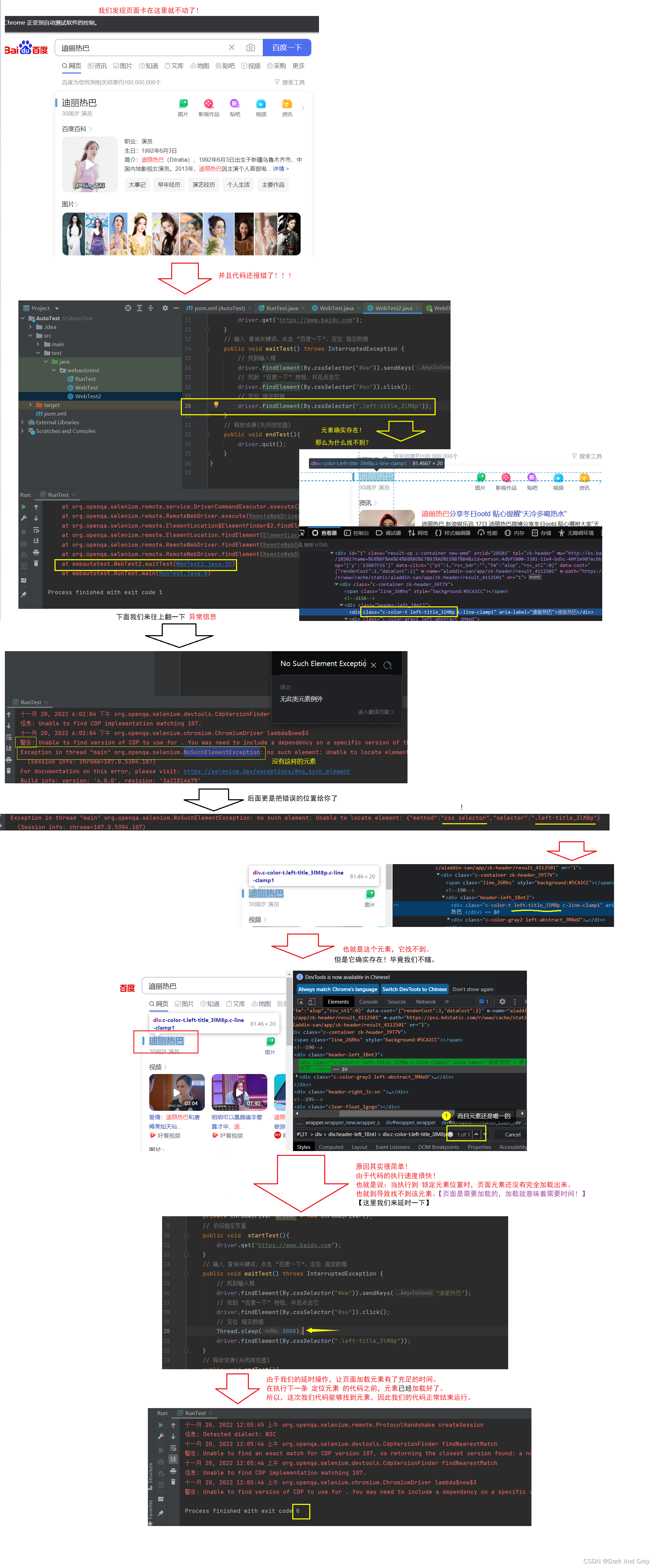
我们来为 “演出” 做一些准备。
下面我们把这个看似 “没问题” 的操作流程,来执行一下。
这里的延时(等待)操作,是非常重要的,关乎到脚本是否能正常运行!
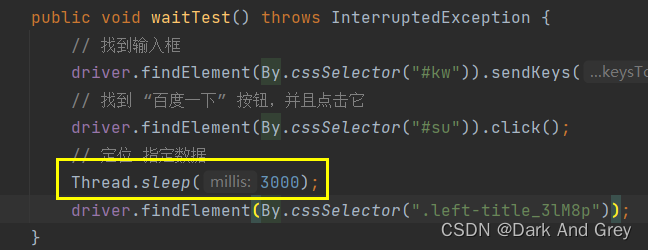
我们这里所采用的方式是属于:强制等待
让程序强制等待3s之后,给予前端页面加载的时间,再执行下一条程序。
强制等待的优点 && 缺点
优点:
语法简单,适合测试的时候复用。缺点:
效率很低!【延长测试时间】我们使用自动化测试 的 目的 就在于 提升效率。
将 人工测试操作 交由机器来进行,节省人力成本。
并且机器的执行效率是非常高的,这样就节省了时间成本(效率得到了提升)。但是由于我们的强制等待操作,让程序执行的过程中出现了 “停顿”,这毫无疑问会影响程序的执行效率。这种问题在 C++ 中是不被允许存在的!
另外,如果每个测试用例使用 强制等待的时间平均为 3 ~ 5s
我们以 5s 为例,通常一个web自动化测试用例与几百个,我们假如测试用例有 100个。
那么,强制等待的时间:100 x 5 == 500 s 约等于 8分钟.20s
还没完!还要加上 自动化测试脚本执行的时间呢!
考虑最坏情况(硬件环境,软件环境,网络环境都不太理想的情况),自动化测试的时间可能会超过 15 min,甚至更久!一刻钟,这是非常久的!
像我们这个测试用例执行的时间,如果不加sleep,(软硬件都非常给力的情况)执行 0.01s 都算是非常漫长的时间!!!
更别说 15 分钟了,简直就是离谱!!!那么,存不存在一种更高效的方法?
在获取(定位)一个元素的时候,如何没有获取到,进行等待,一旦元素加载完成,立即获取。
也就是说:等待的时间不再是固定的,而是自适应。
下面,我们就看看 “隐式等待”。
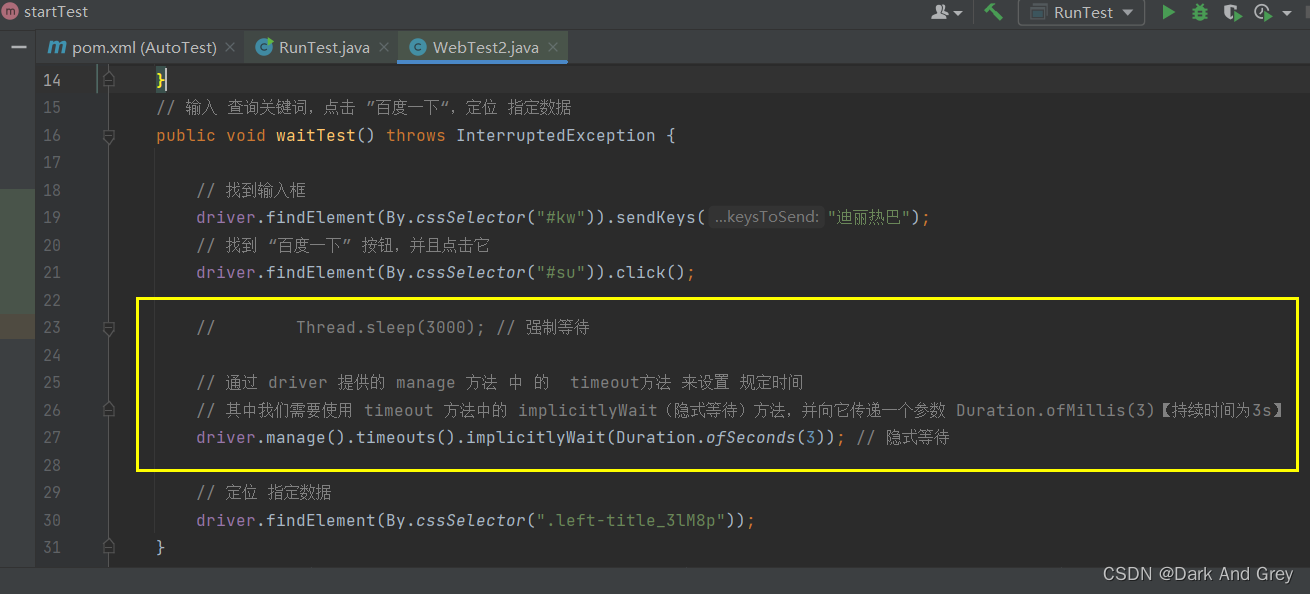
3.2、隐式等待
简单来说:
在规定的时间范围内,轮询等待元素出现之后就立即结束。
如果在规定的时间范围内,元素仍然没有出现,则会抛出一个异常【NoSuchElementException】,脚本停止运行。
效果图就不展示了,没有报错,执行过程非常丝滑!
另外, 隐式等待 作用于 WebDriver 整个生命周期。
【只要没有走到 driver.quit,即没有退出浏览器,隐式等待都是一直存在的】
所以,隐式等待的代码的位置,可以随意。
需要注意的是:
规定的时间要合理,时间太短,那就和没设置一样了。
隐式等待的优缺点
优点:
节省了大量的等待时间,元素展示之后,就可以直接执行下一步。缺点:
需要等待页面元素全部加载完成,才能执行下一步。
因此,仍然会有额外的时间浪费。【但是比强制等待要强一点】
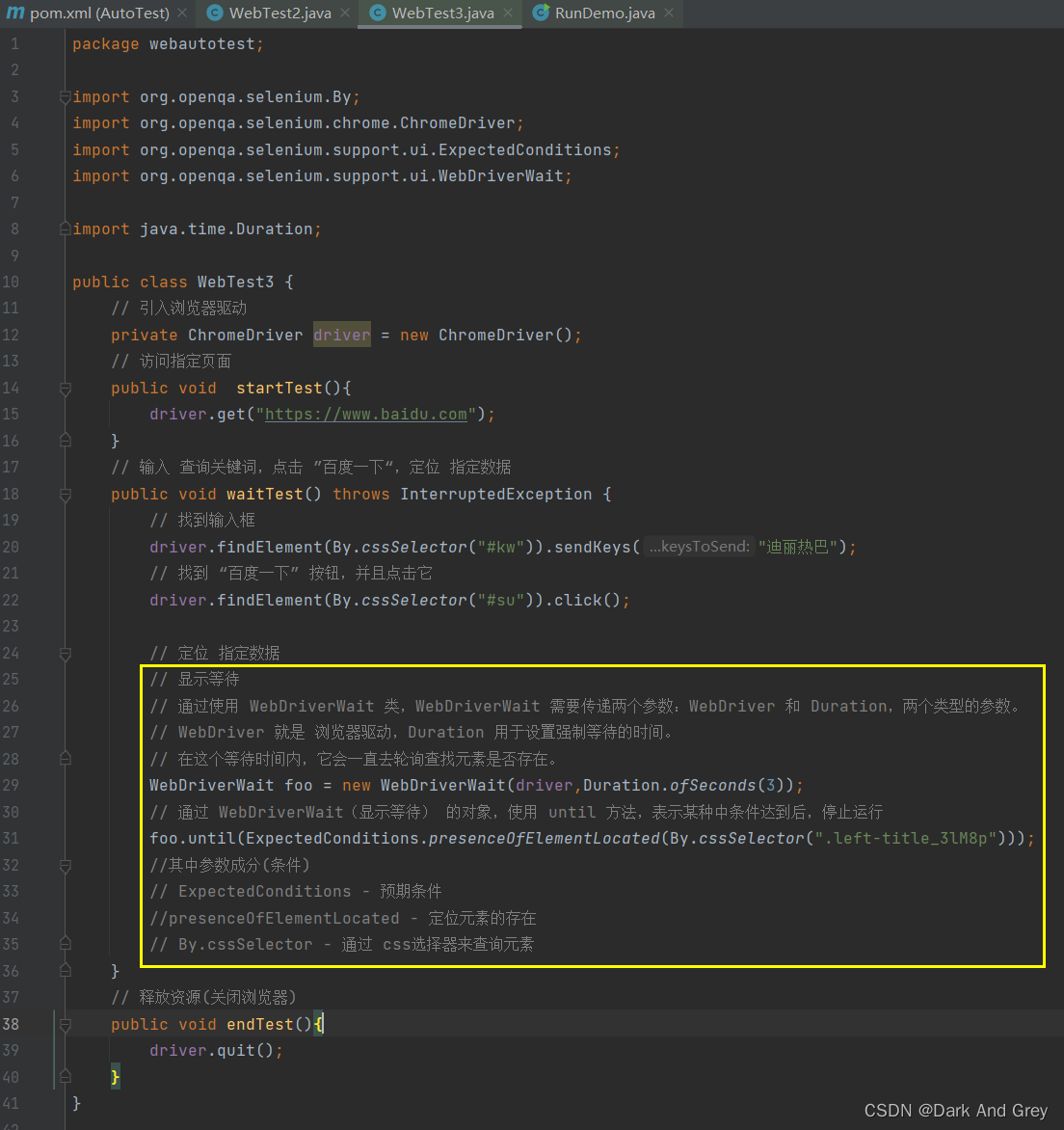
3.3、显示等待
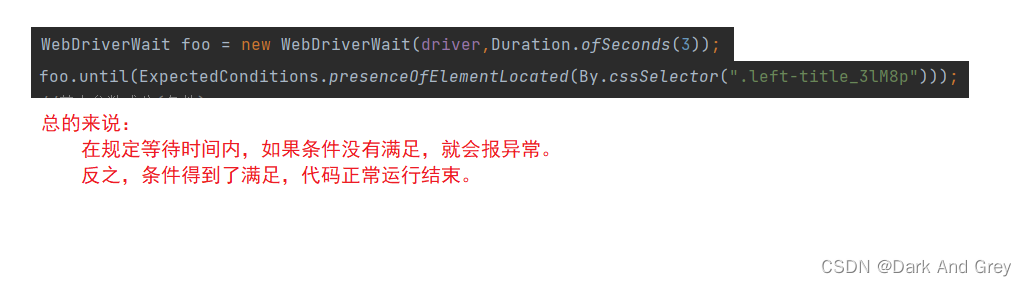
这里我们需要使用到 selenium 里中的一个类 ExpectedConditions,以及 until 方法。
如果在规定的等待时间内,没有找到元素,就会报异常【NoSuchElementException】。
至于代码运行,非常丝滑,没有问题。
非要说有问题的话:写法太复杂了。
ExpectedConditions 类中还有很多其它的方法,你们可以参考这篇博客https://blog.csdn.net/qq_39704682/article/details/85596644
显示等待的优缺点:
优点:
针对某一个元素来进行等待,极大降低了自动化整体的等待时间。缺点:
写法相比前面两种,要复杂一些。
注意事项
代码里面是可以同时使用显示等待和隐式等待!
但是!不推荐!
因为同时使用可能会造成一些意向不到的结果。
比如:
显示等待10s,隐式等待 5s。【等待时间不可以累加】
那么它等待时间可能是 10s,11s。。。。
总之等待时间不是固定的,
4、打印信息
我们先来做一些准备工作。
创建新的包 和 测试脚本类
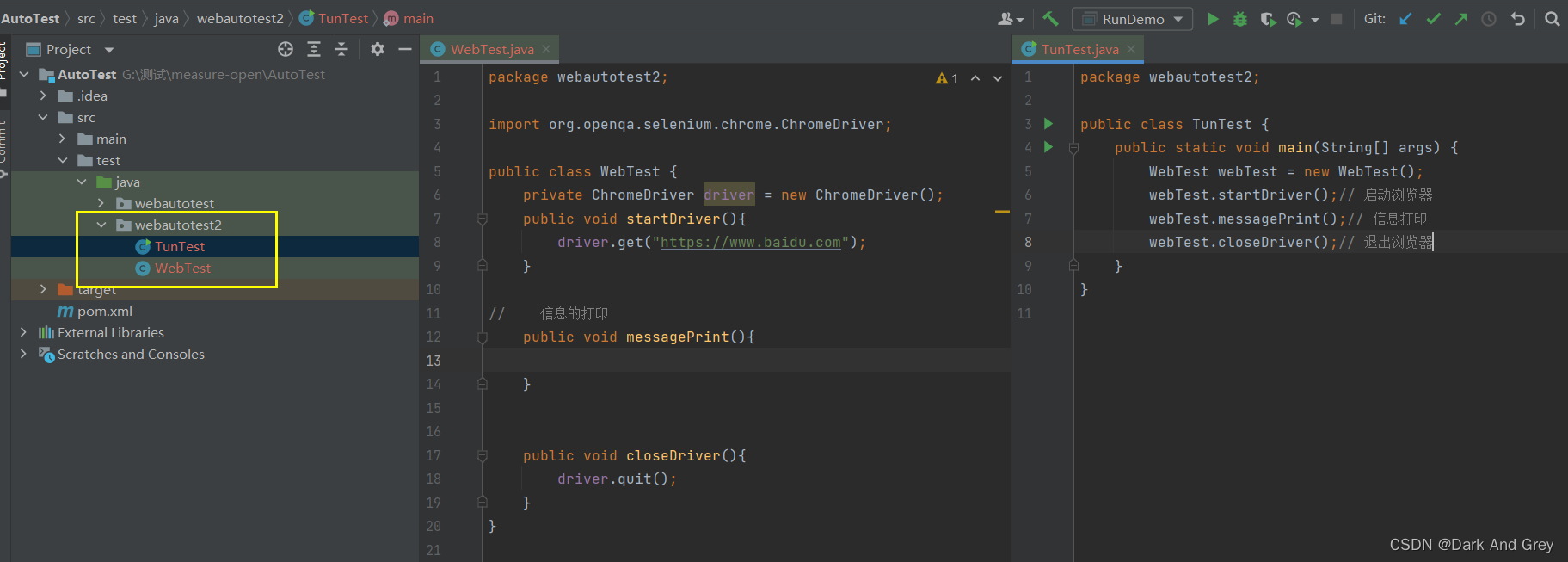
1、打印网页标题

下面我们就来书写 messagePrint 方法。

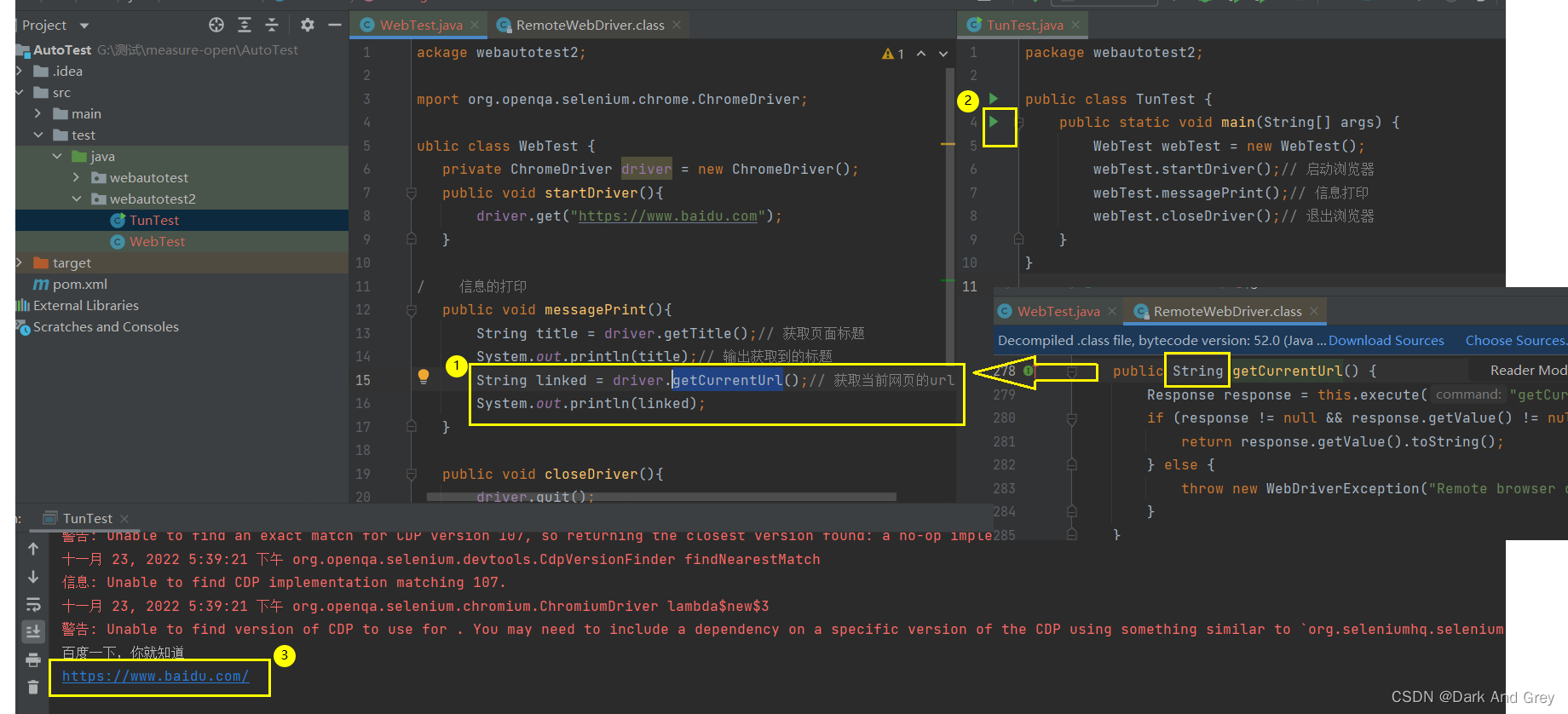
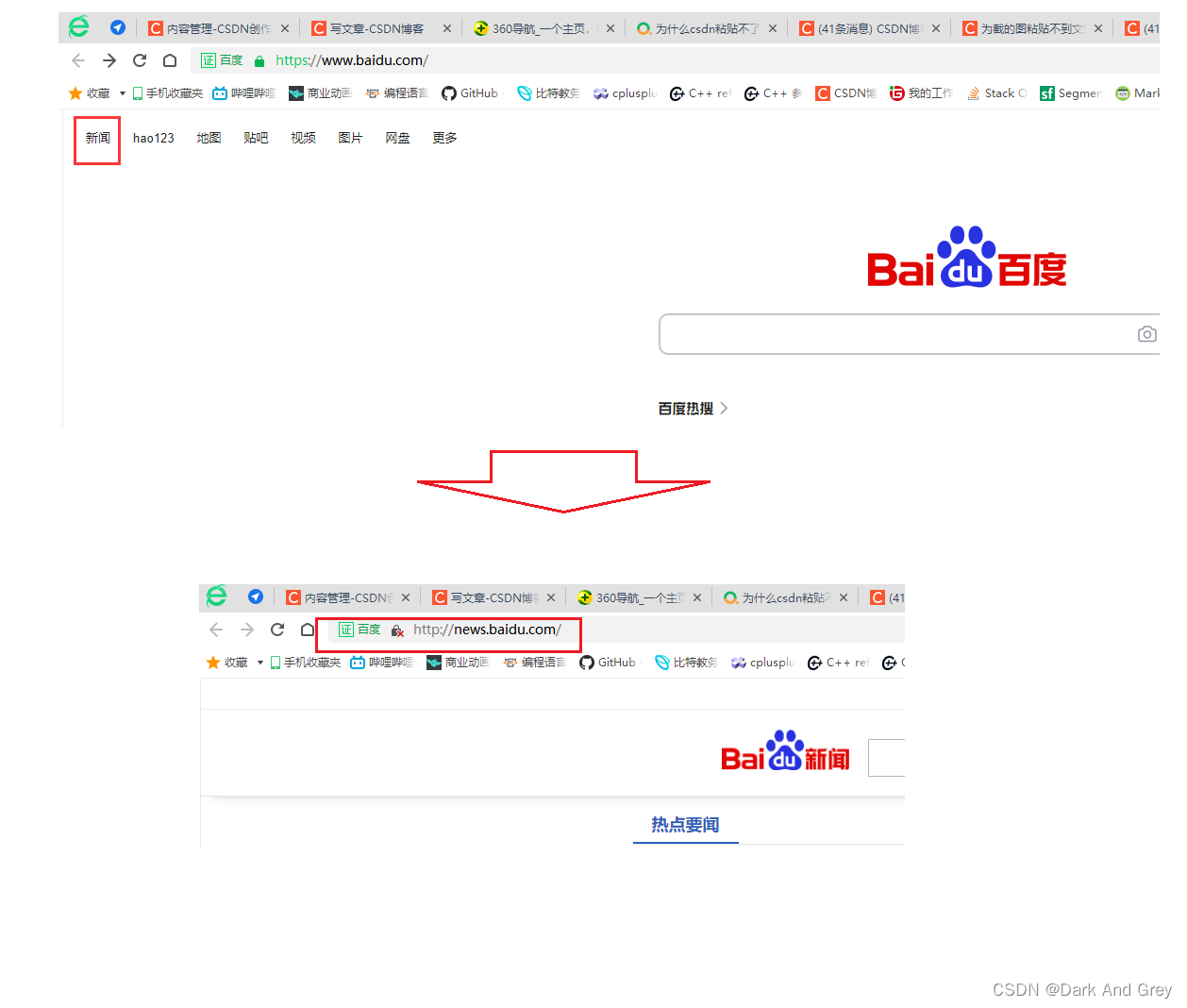
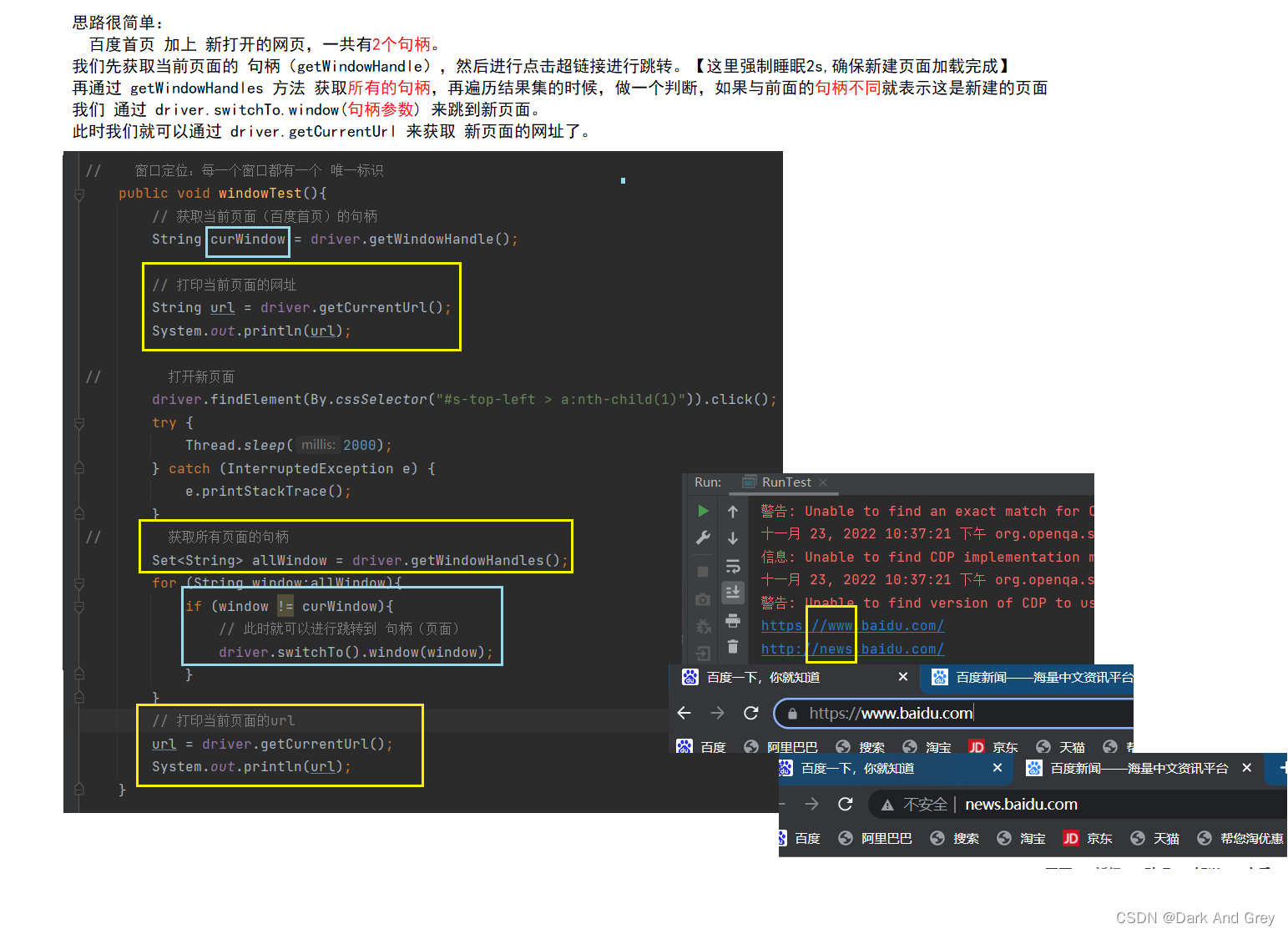
2、打印当前网页的链接(网址)
方法很简单,直接中译英:获取当前网址 -> getCurrentUrl
这里我们来增加一丢丢难度,我们来获取 点击 新闻之后的网址。
下面我们来修改一下代码
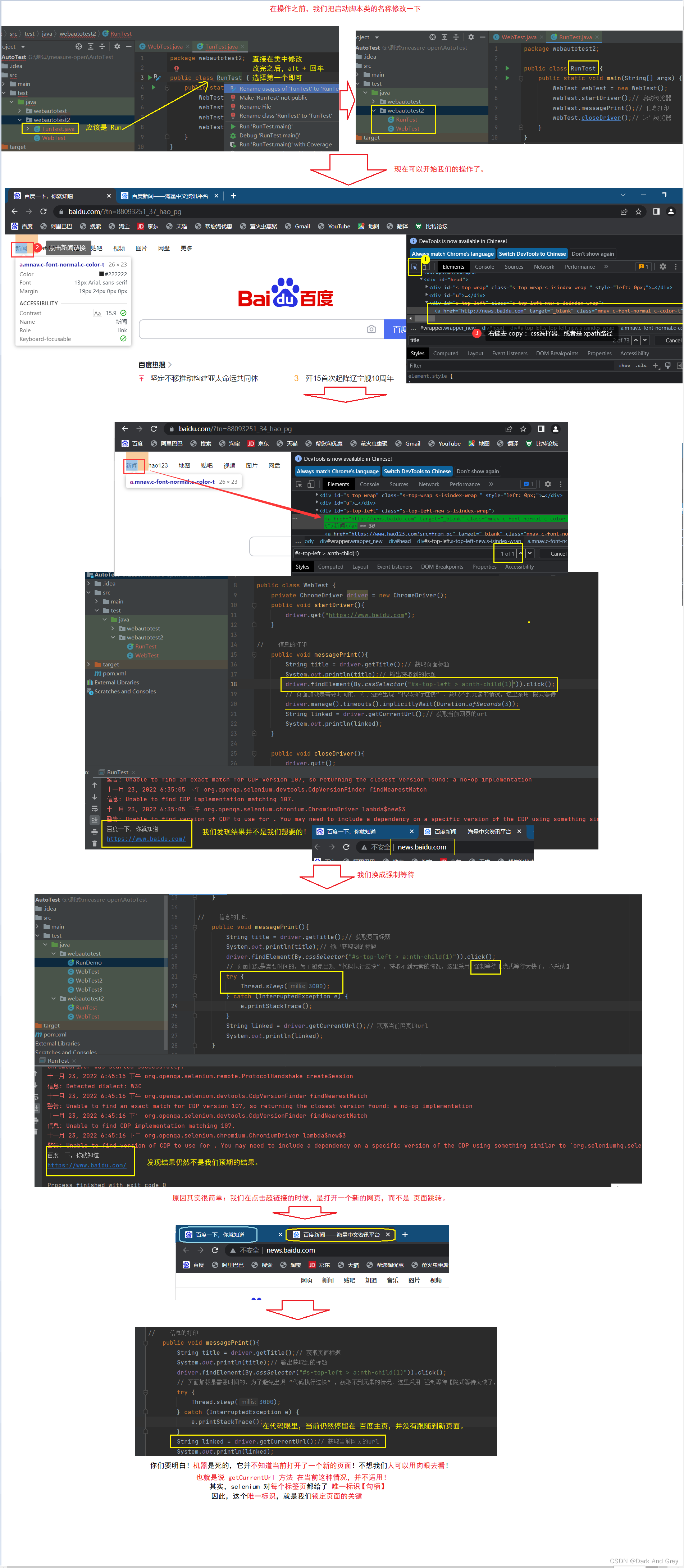
我们怎么去获取到句柄呢?
这就关乎到下一个内容:窗口
5、窗口
窗口切换
通过 driver 的 getWindowHandle 方法 来获取句柄.
我们来调用一下这个方法。
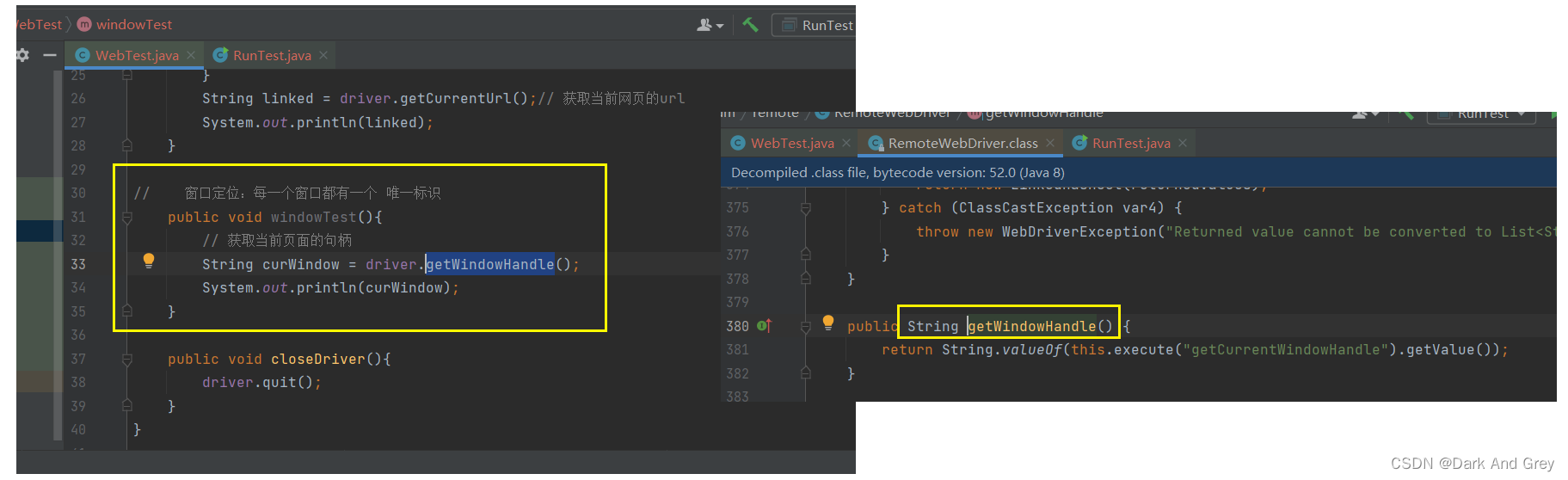
我们再来试试 上一个案例的情况,看看是否能获取到 新页面的句柄
此时,我们得出结论:
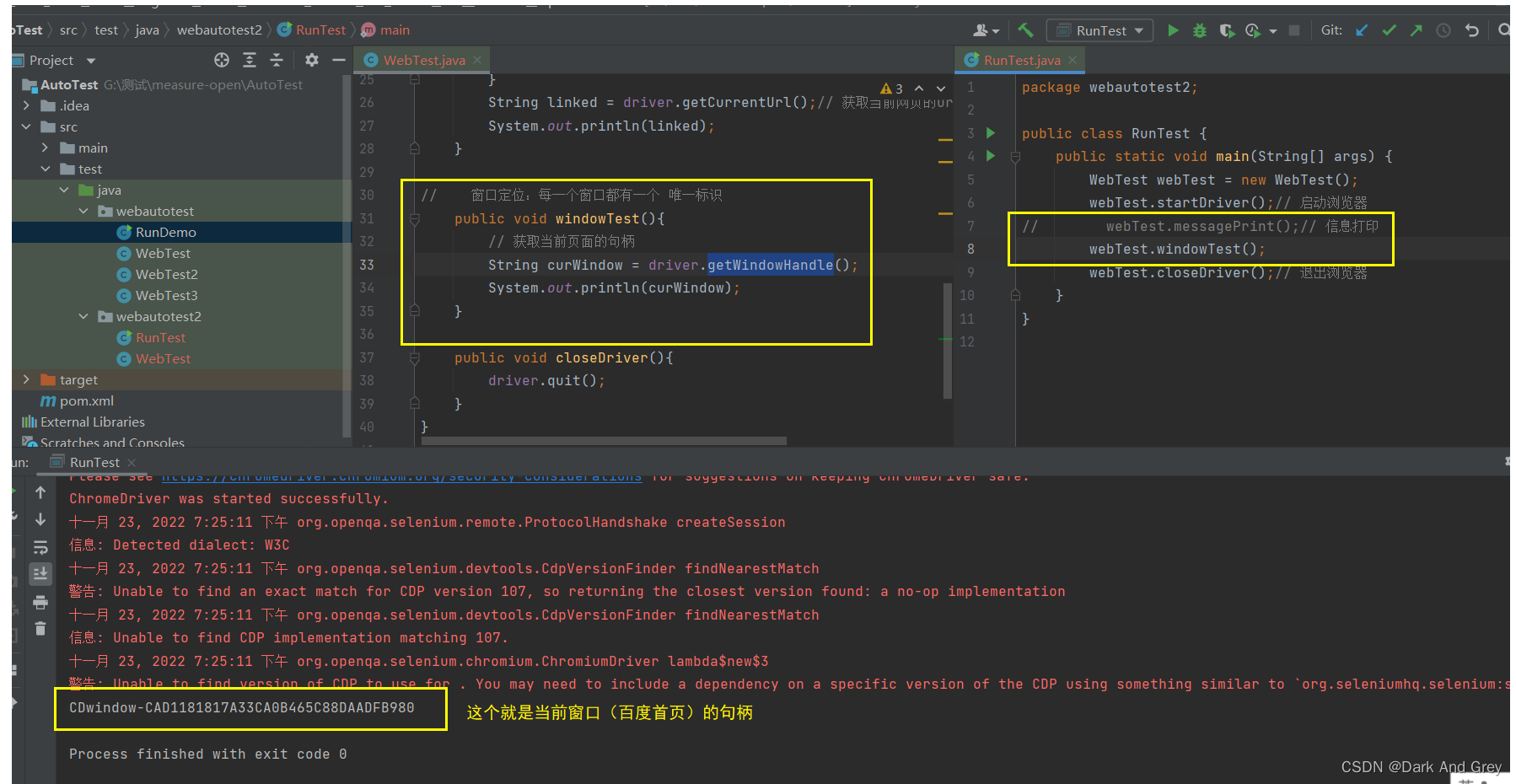
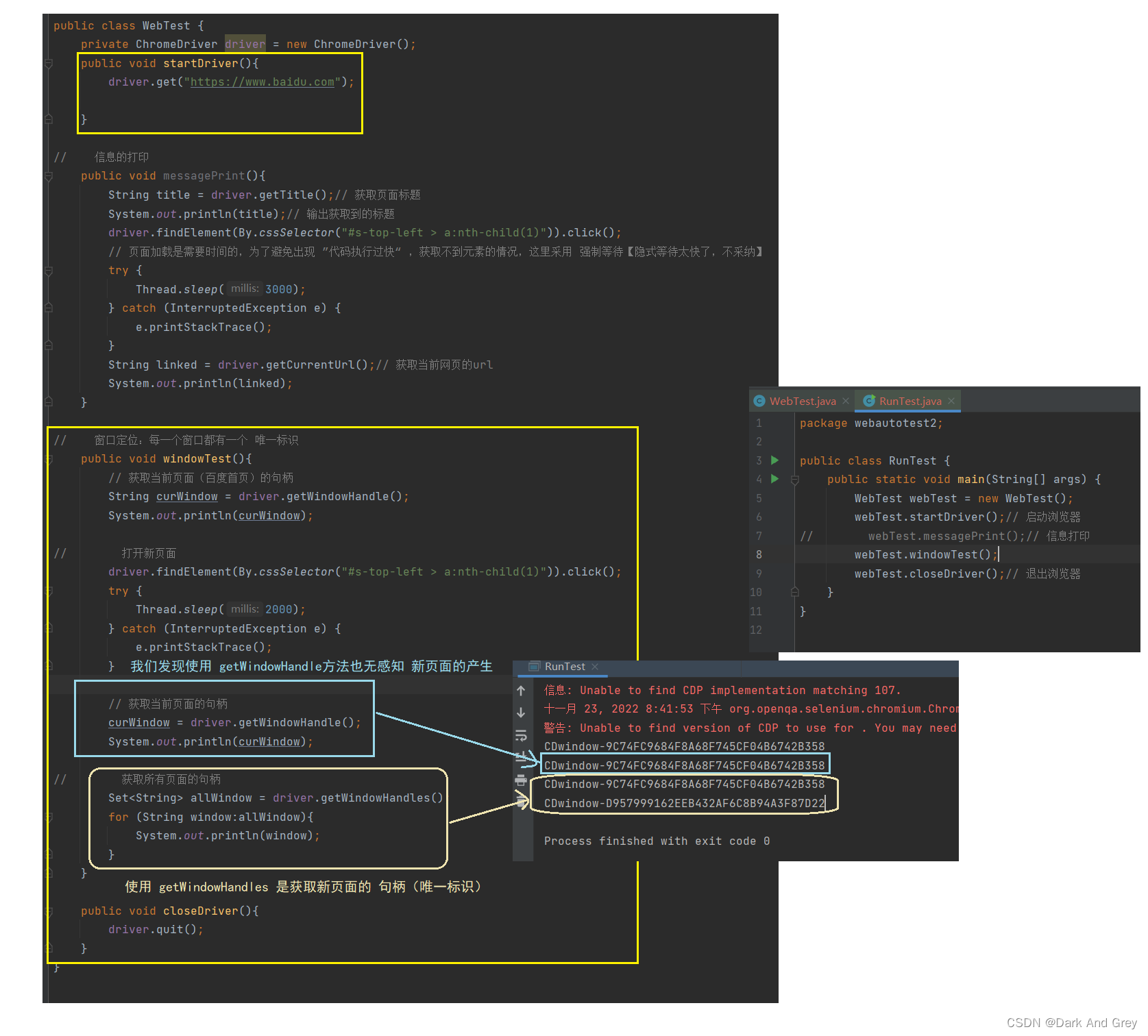
getWindowHandle 方法无法感知新键页面
getWindowHandles 可以获取到所有页面的句柄(唯一标识).那么问题来了,我们如何切换到最新页面呢?
关键就在于 getWindowHandles 上。
想要跳转到想要去的页面,从 getWindowHandles 的结果集(allWindow)中获取。
重点就在于 getWindowHandle 和 getWindowHandles 方法的配合。
再通过 switchTo.window 方法 来进行页面跳转。其实每次都要从一个页面跳转到另一个页面,不如直接 driver.get( url ) 直接访问来的简单。
像这种辗转操作,其实在自动化测试中,并不常见。
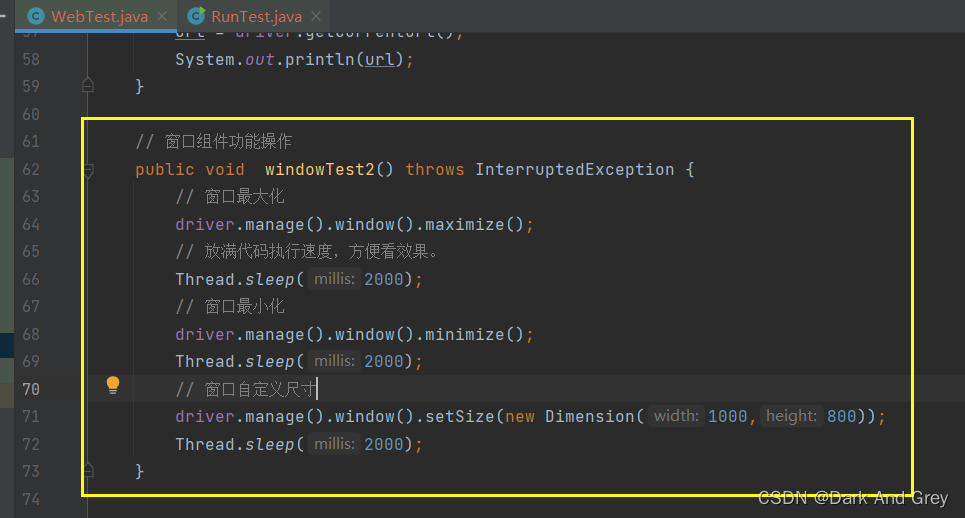
窗口大小的设置
这个很简单,自己尝试一下
窗口 置顶 / 置底 - 了解
相信大家都遇到过浏览器 “一键置顶”的功能。
点击一个 按钮,窗口自动回到 页面顶部
那么,有一键置顶,就有一键置底
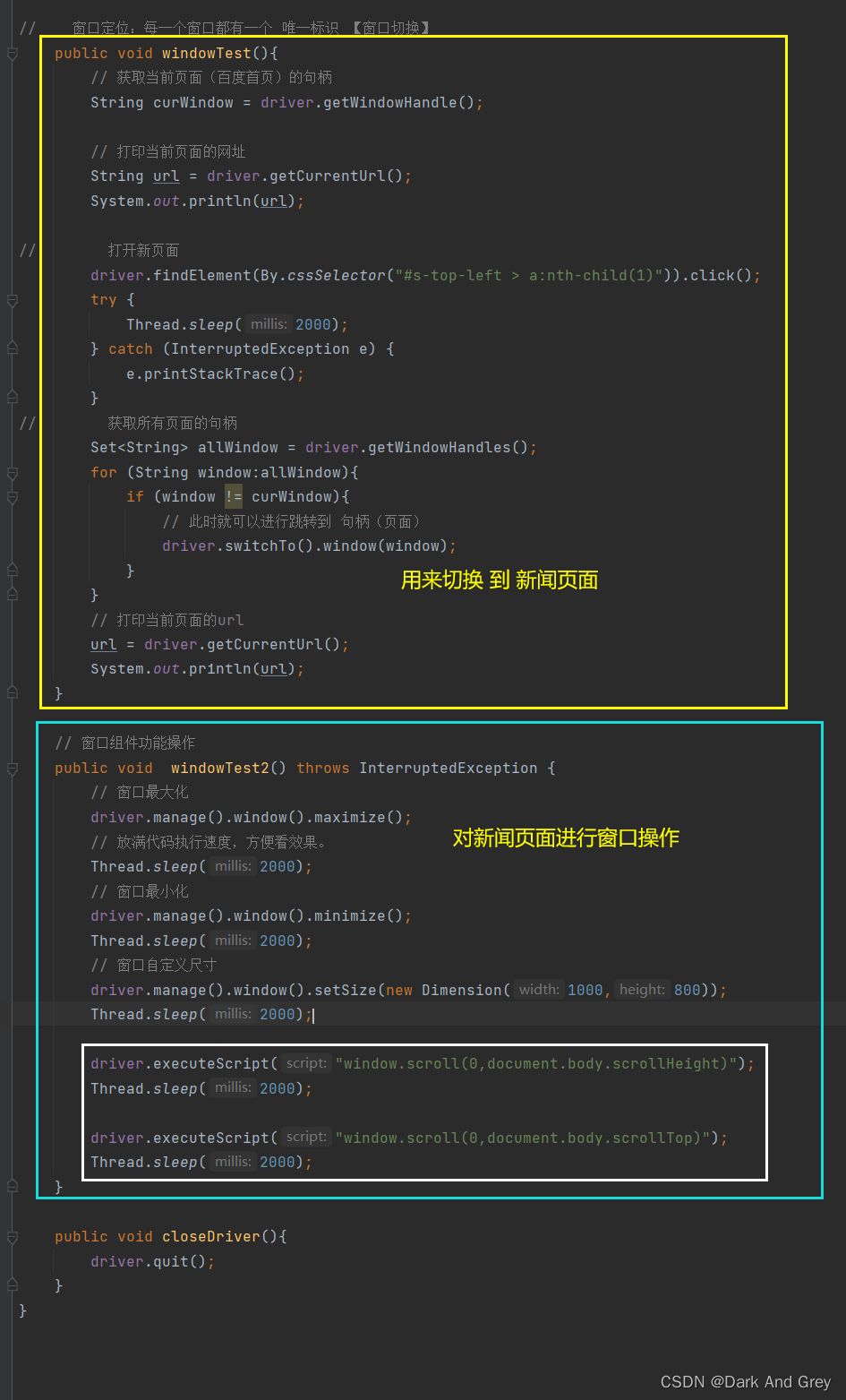
关于这个方法 selenium 提供了 driver.executeScript 方法。
意思就是执行一个 JS 语言(脚本),完成某项操作。
【PS:selenium 是无法直接编译 js 语言的,所以只能通过上面这个方法来执行】我们先来看置底操作【window.scroll(0,document.body.scrollHeight)】
再来看置顶操作【window.scroll(0,document.body.scrollTop)】
在 selenium 中 使用,就是将我们刚才那两条脚本语言 复制到 driver.executeScript 方法中。
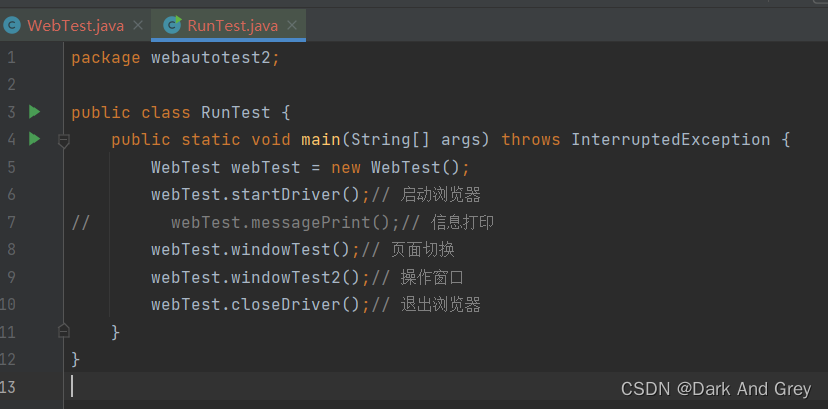
调用的时候,先调用 windowTest 方法 来切换页面,再来调用 windowTest2 来操作界面。
效果没有问题,我执行了。
操作浏览器的前进、后退
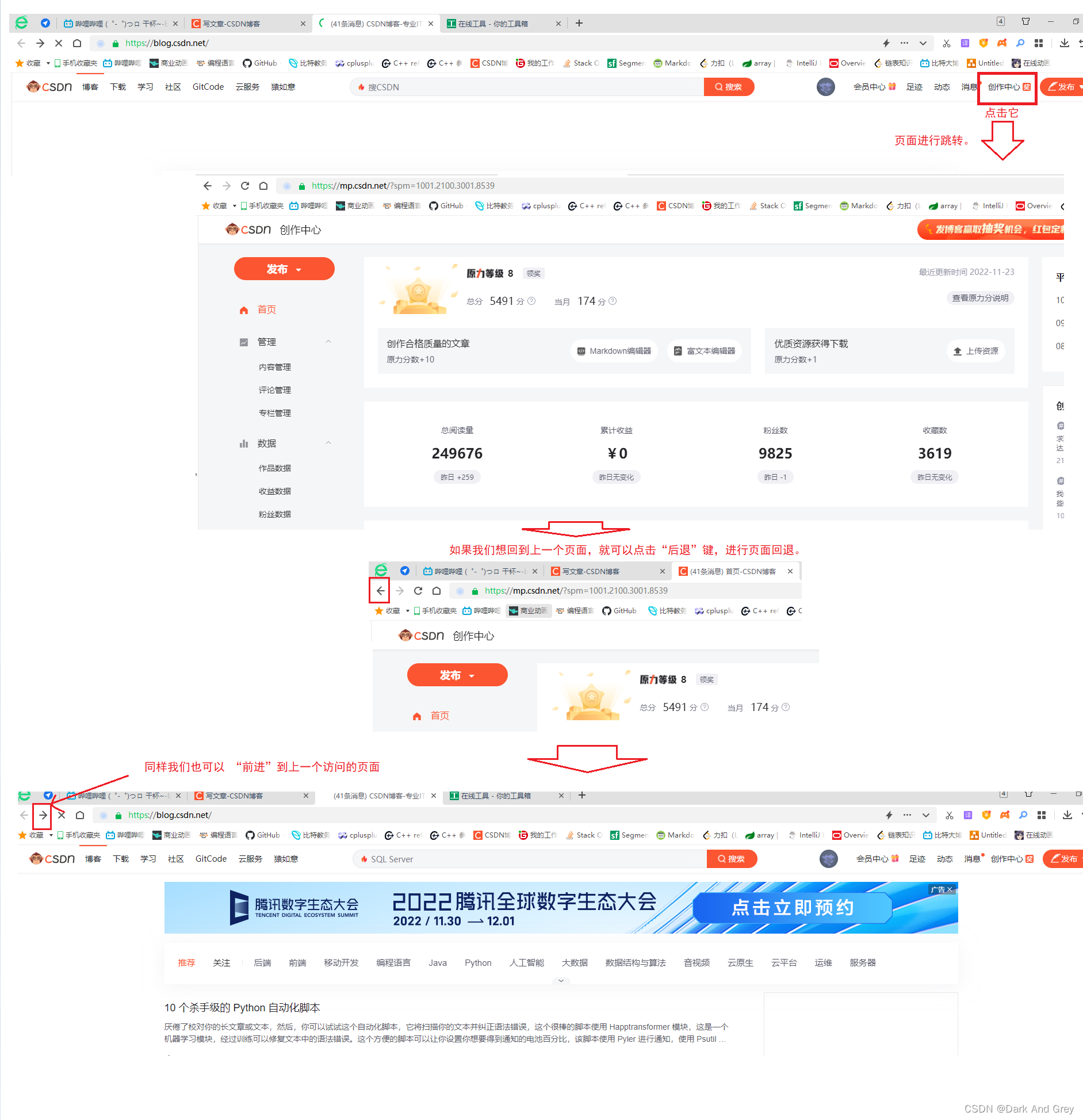
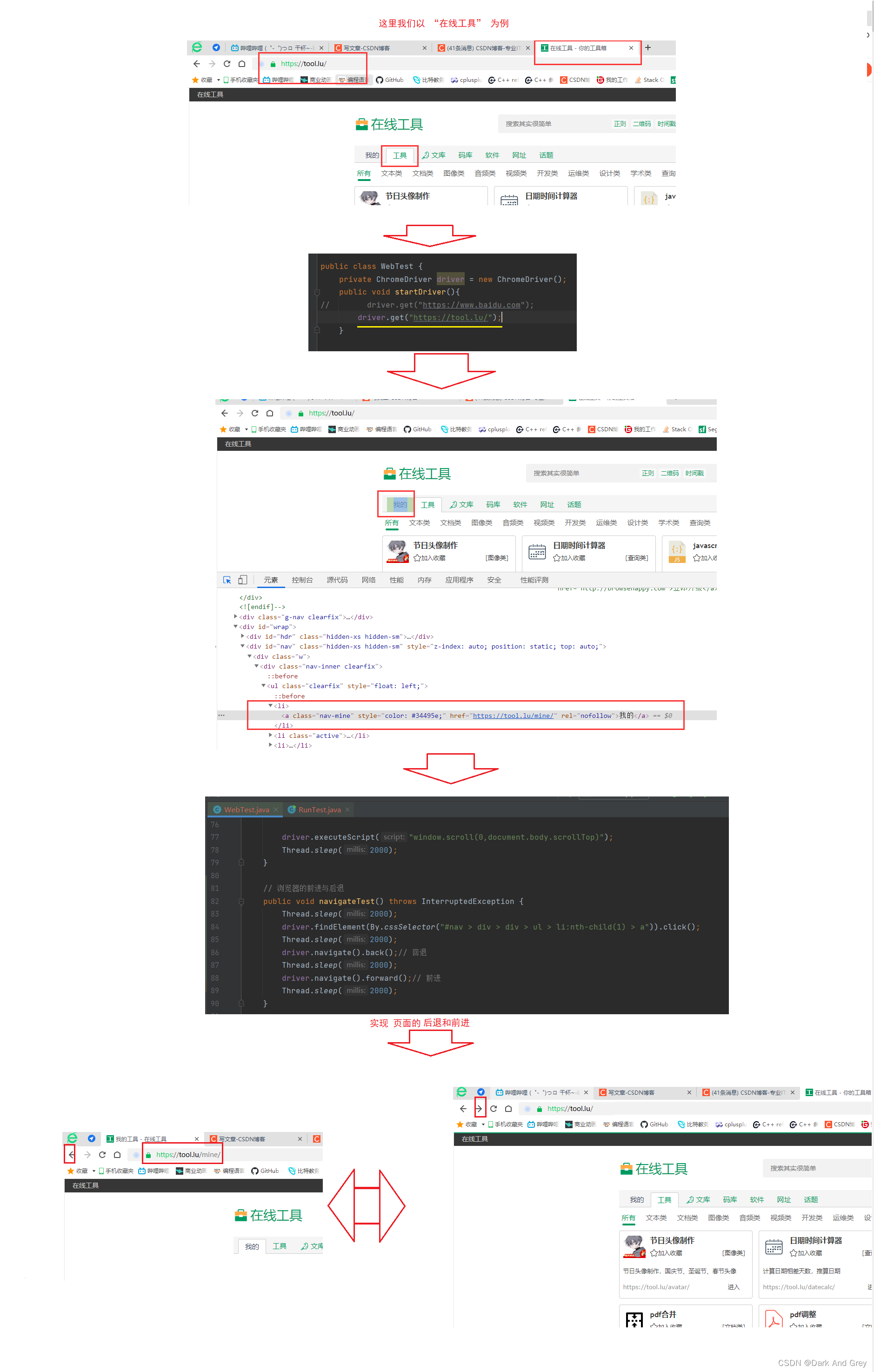
我以CSDN为例
接下来,我们就是要实现一组这样的操作。【页面的前进与后退】selenium 里提供了 navigate 接口 来实现页面的导航
浏览器的前进
通过 driver.navigate().forward()浏览器的后退
通过driver.navigate().back()
但是问题来了,我们的例子是在一个页面中执行。
如果是那种点击之后创建新页面的情况呢?答案是:不会跳转回到之前的页面。
因为弹出的是一个新的页面,与原先的页面并不是前后的关系。有点类似于 转发 和 重定向 之间的关系。
我们这个在线工具网站就相当于 转发。【同源】
新建页面 就相当于重定向。【异源】
操作弹窗
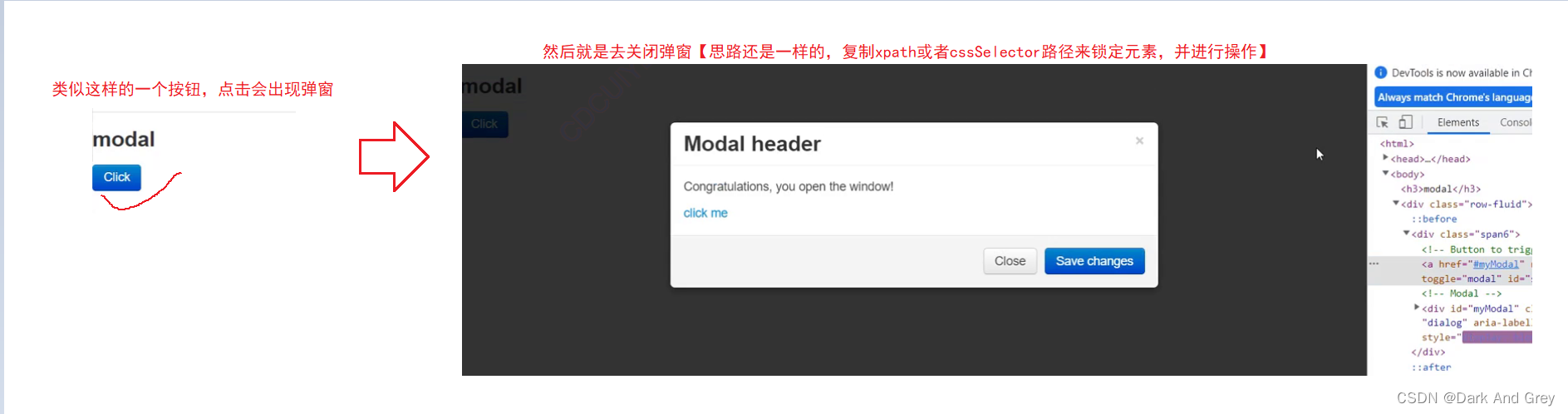
我就网上随便找了几个图,我就说一下思路。
就是找到点击键,点击之后,弹出窗口后,在锁定 关闭窗口键元素,进行点击(click)
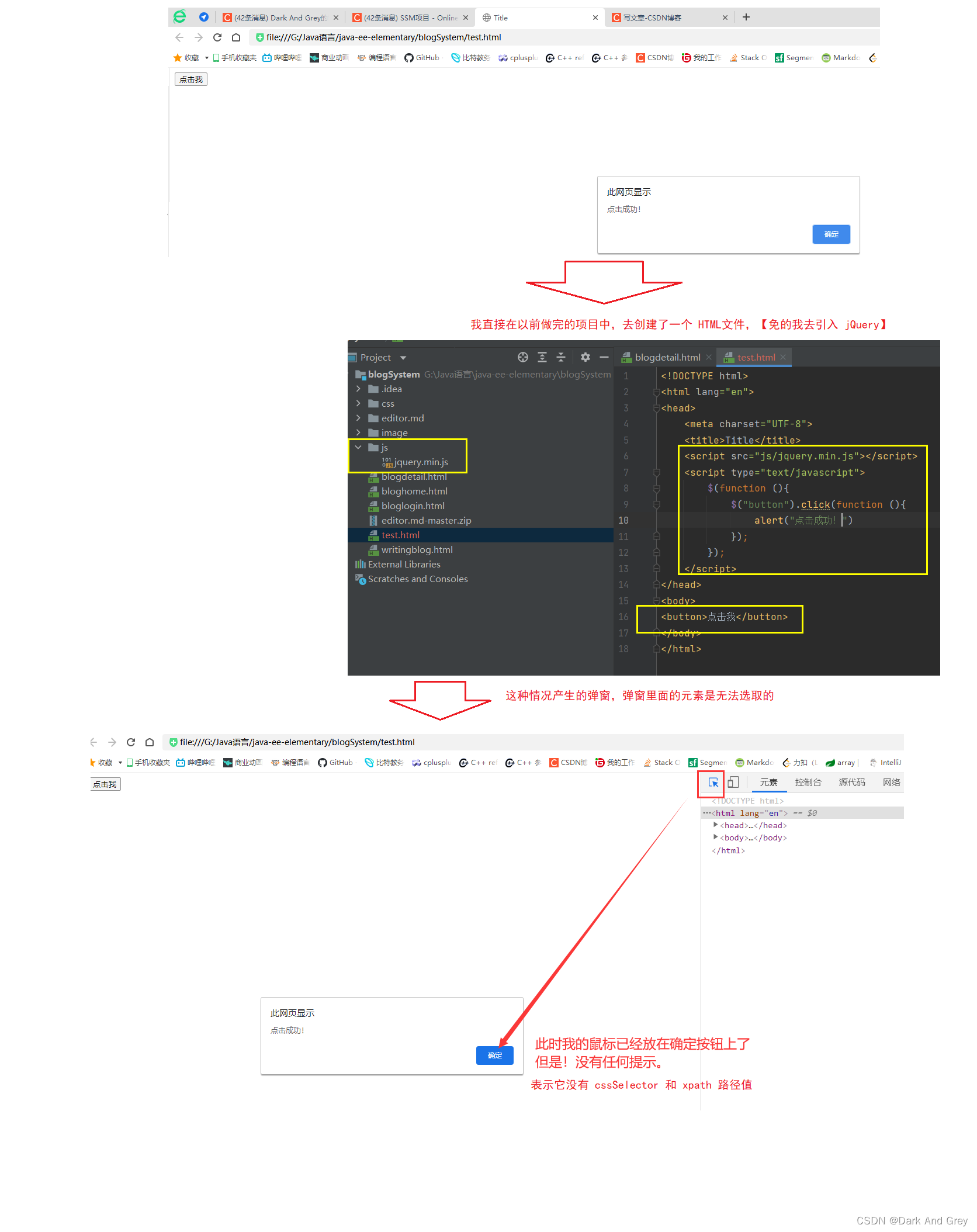
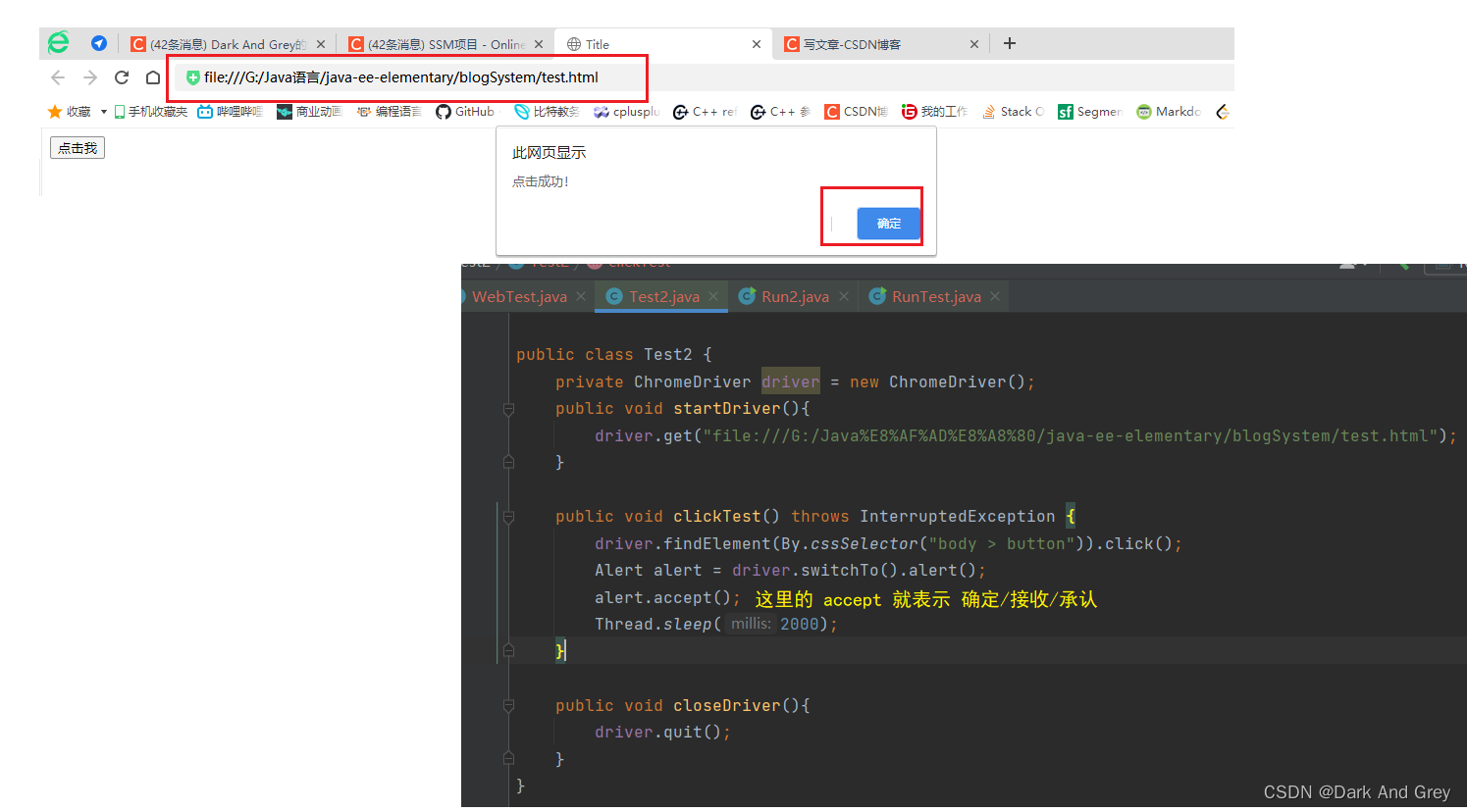
【 driver.findElement(By.cssSelector(“”)).click();】但是!,还有一种情况:弹窗元素无法选中的情况。
这种类型的弹窗被我们称为 “警告弹窗”
这种弹窗是无法通过 driver.findElement()方法 来定位元素。
这里需要用到 selenium 中提供的 Alert 接口。
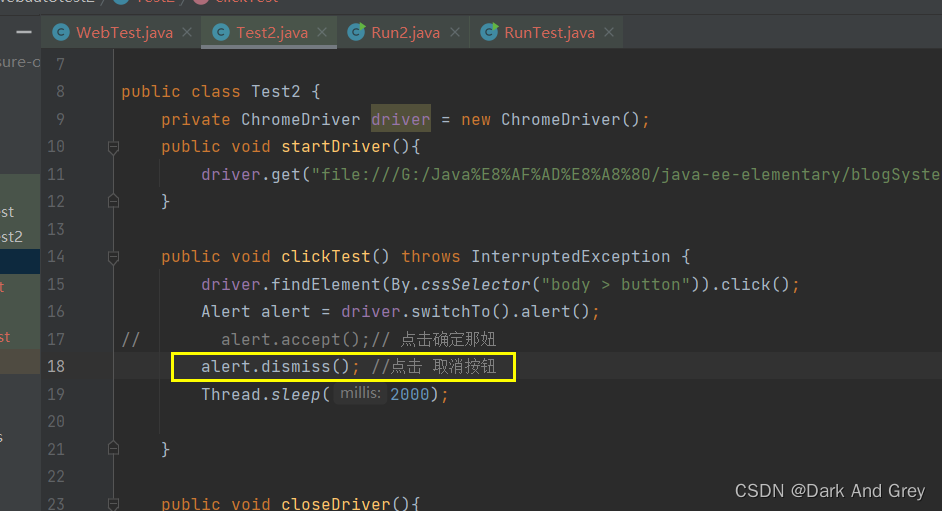
另外,有确认按钮,那么就有 取消按钮
使用 dismiss 方法就可以了。


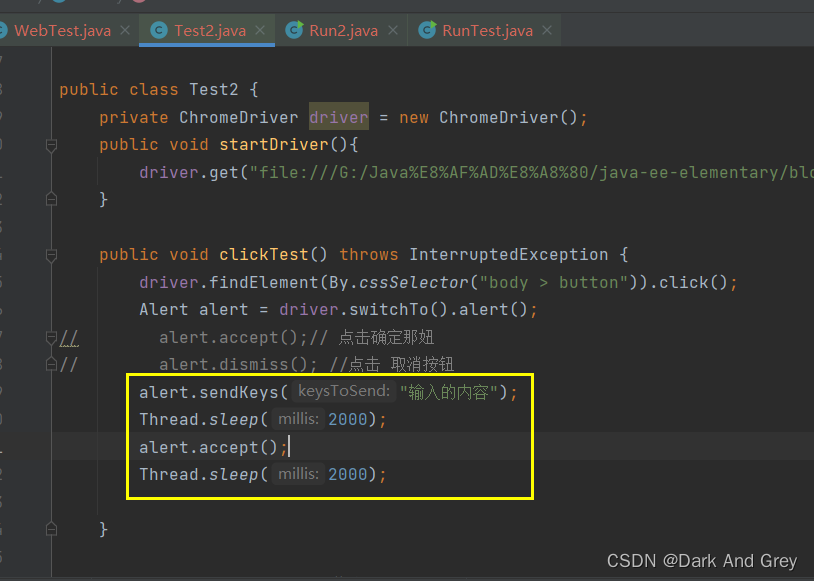
还有一种特别的弹窗,可以让我们进行输入
这里的输入框也是无法定位的!
想要输入内容也很简单!还是使用 sendKeys 方法

模拟 鼠标,键盘操作
selenium 提供了 Actions 接口,来模拟 鼠标的操作。
代码如下
虽然上述操作中,通过对元素的定位完成了选择。
但是,我们是要模拟 鼠标 操作的,因此我们需要鼠标 “动起来”,通过鼠标去点击选择。
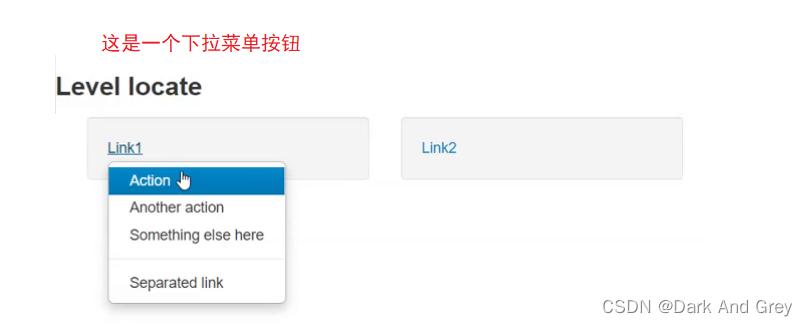
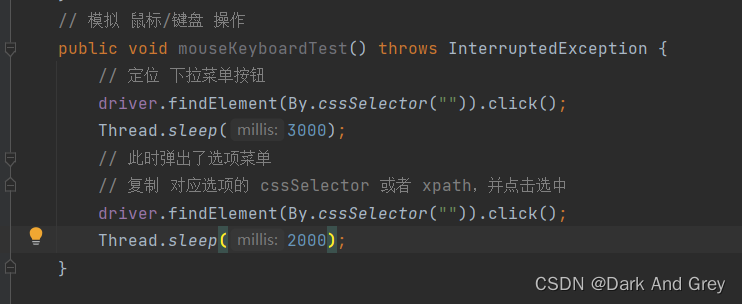
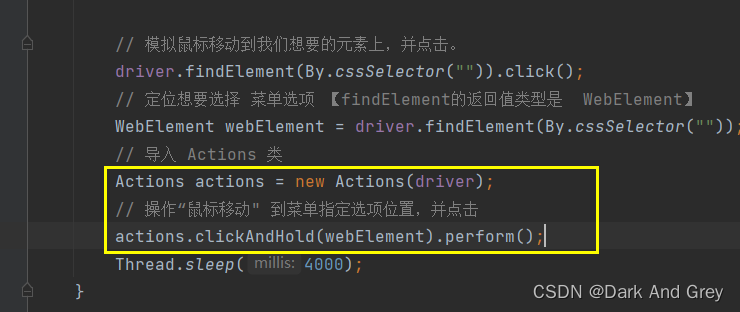
键盘的操作,我们已经用过了,就是 sendKeys 方法
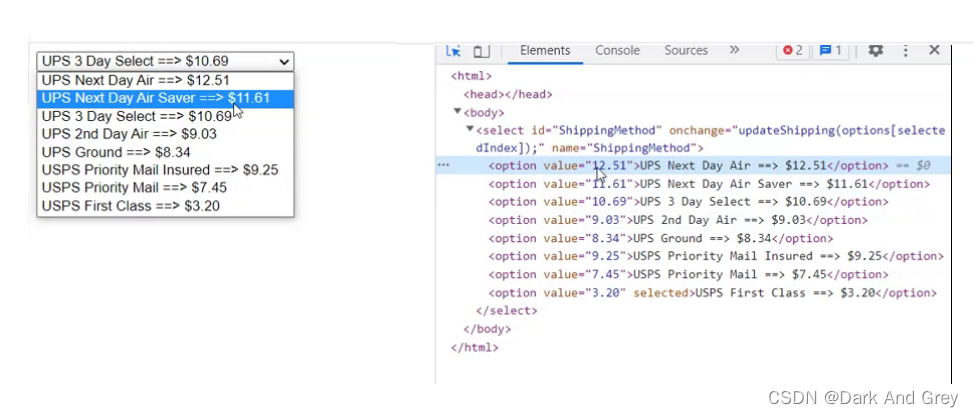
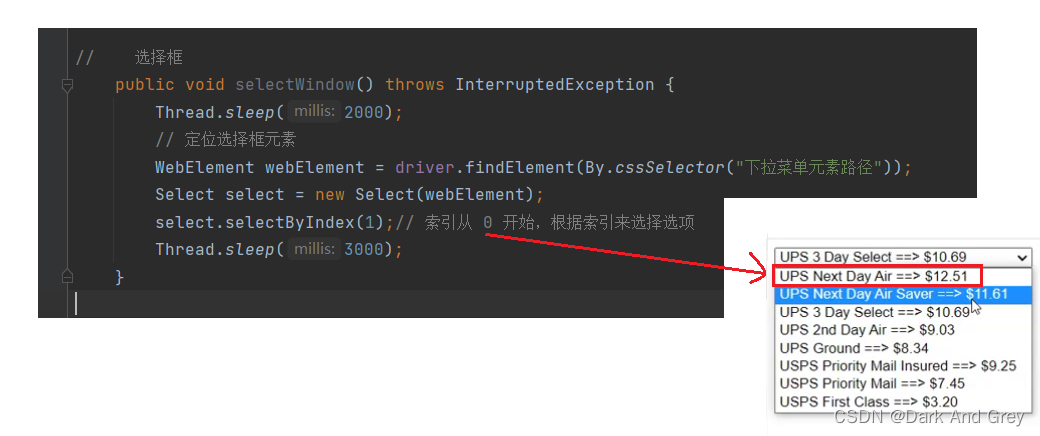
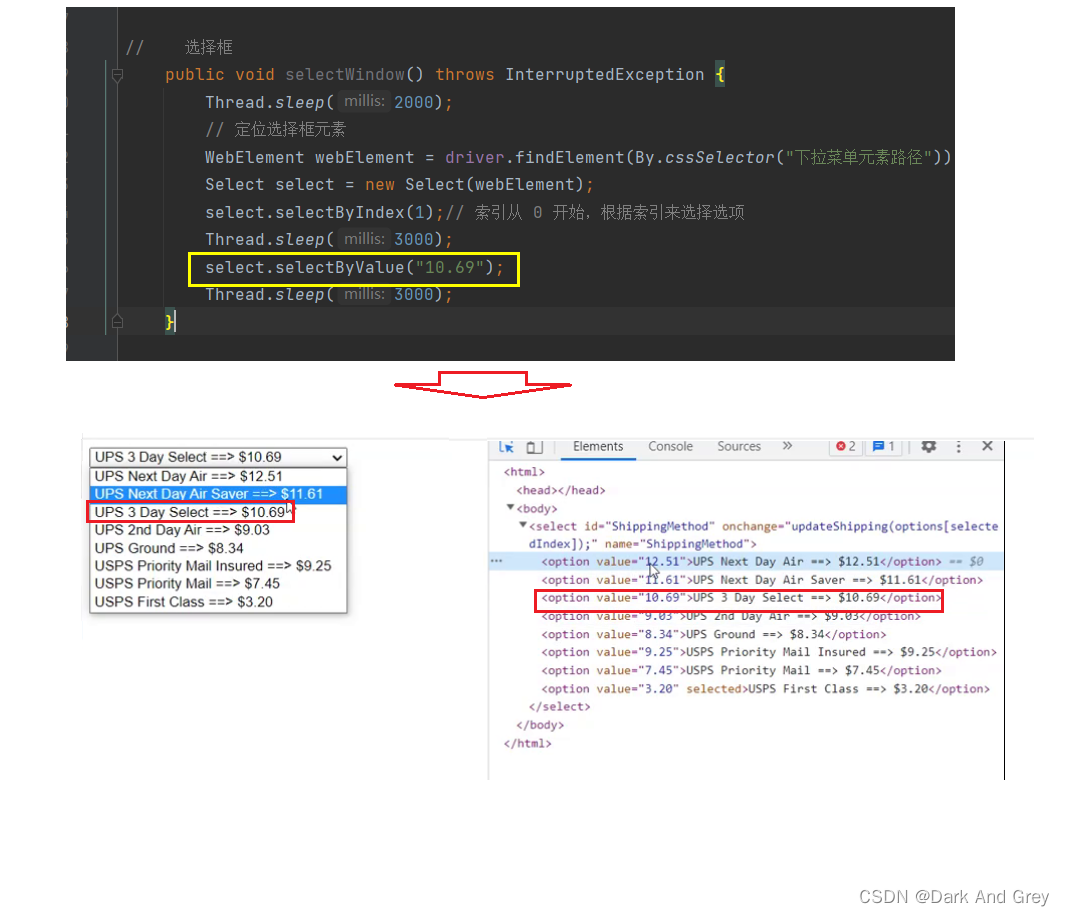
选择框
下面的这个场景才是真正的 下拉菜单,上面那个算是点击菜单
selenium 就是提供了 select 接口
我们还可以通过value属性值来选择选项
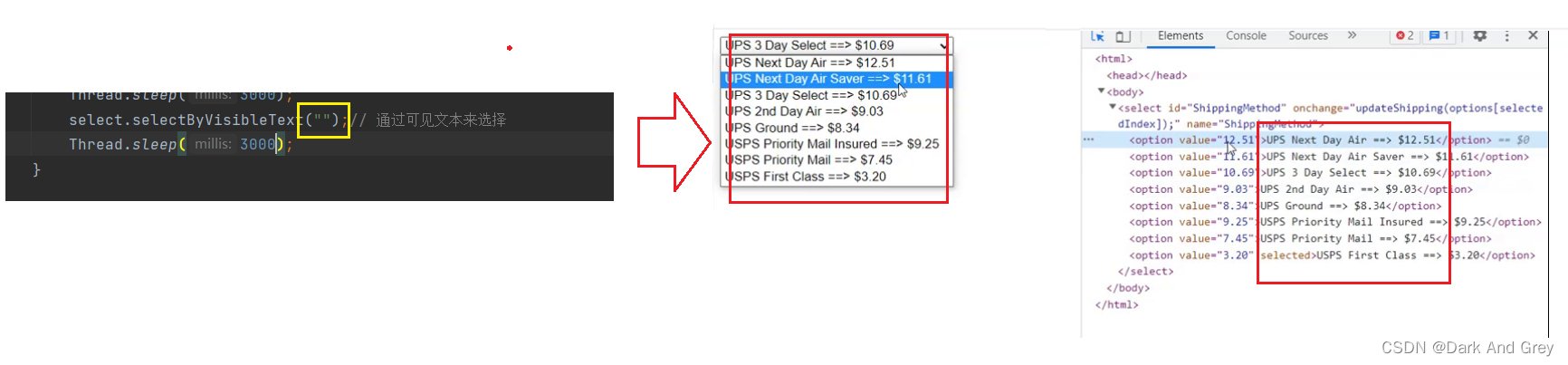
还有最后一个方法:根据可见文本来选择
文件的上传
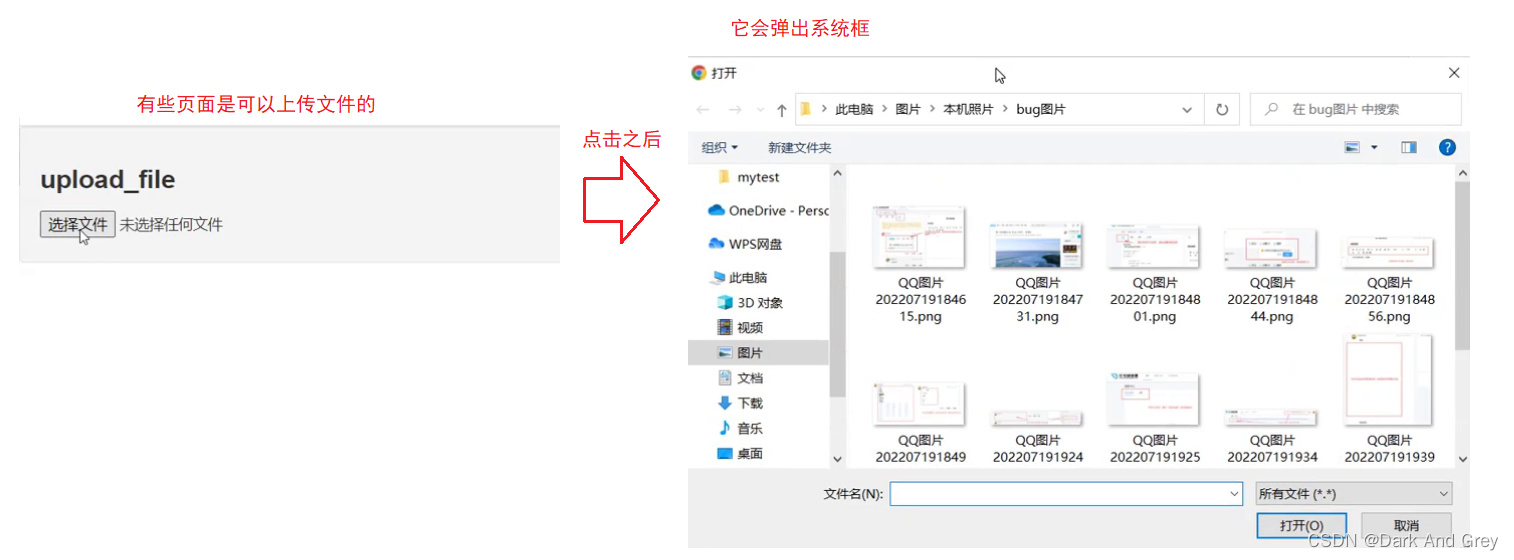
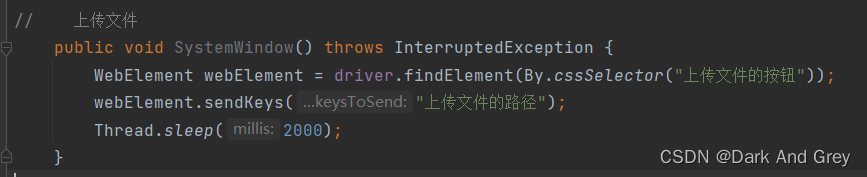
此时,我们来思考一件事:能不能定位 系统框中的元素,并进行操作?
selenium 不能直接操作系统框。但是,这个操作是可以模拟实现。【sendKeys方法 输入 上传文件路径(包含文件名称)】
8、屏幕截图
这里我们回顾一下前面的内容:
我们在百度页面搜索关键词 “迪丽热巴”,然后从中获取到某些数据。
在不添加等待的情况下,由于代码执行的速度过快,导致页面元素获取不到【页面元素还未加载完成】,从而抛出异常 【NoSuchElementException】如果我不告诉你:获取不到元素的原因,你能推导出原因吗?
这个时候就可以使用屏幕截图来解决。我对我的代码执行的过程进行 “拍照(截图)”,去发现它的一个问题是什么?
举个例子:
高速公路的车辆行驶速度是非常快的。【类比 代码的执行速度】
而且 在高速公路上是最容易发生 超速问题(元素获取不到的问题)的!
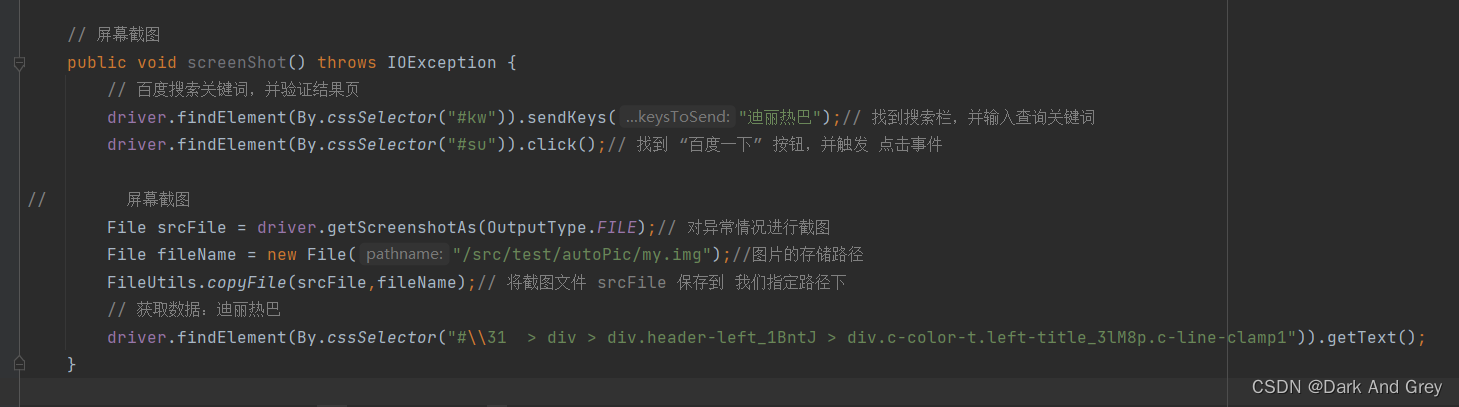
于是就有了高速抓怕摄像头(屏幕截图)来抓住 问题的情况(证据)。selenium 提供了相应的(屏幕截图)方法:driver.getScreenshotAs(OutputType.返回的文件类型);
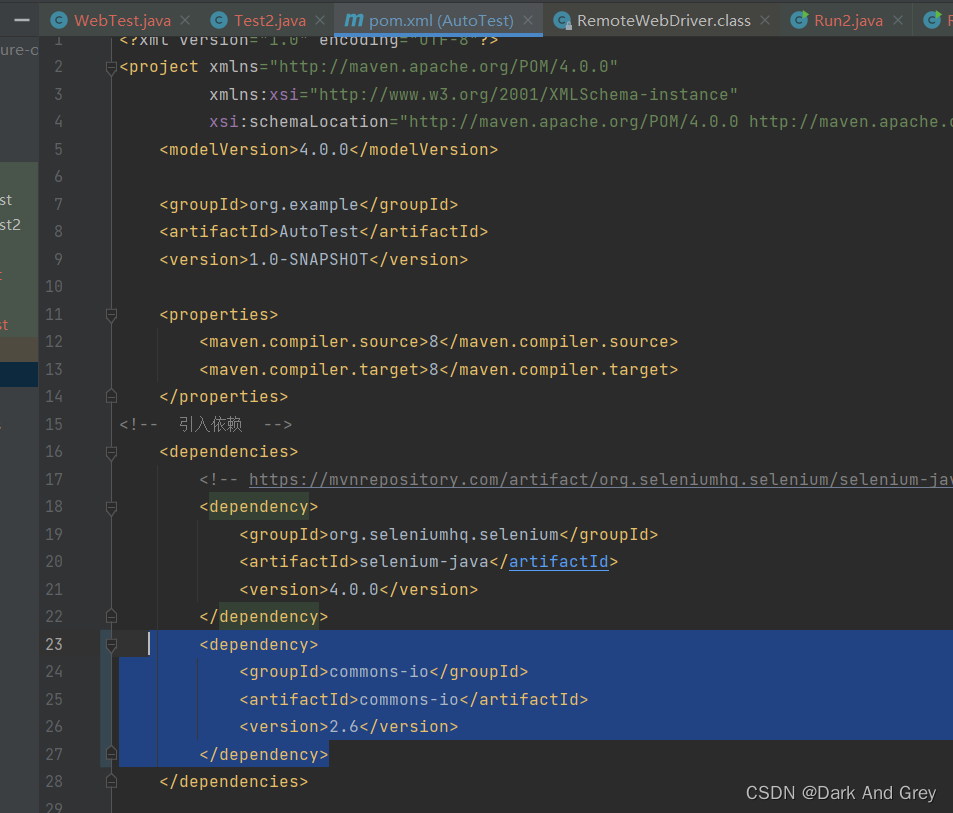
在使用之间,我们需要导入一个依赖
<dependency><groupId>commons-io</groupId><artifactId>commons-io</artifactId><version>2.6</version></dependency>
代码如下:
注意!我们是没有使用等待的,所以当前这个方法是一定会报异常的,会得到一下截图
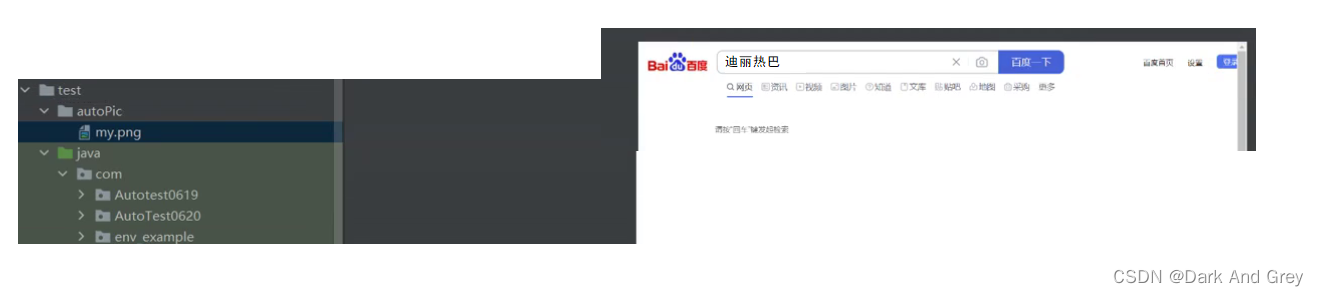
版权归原作者 Dark And Grey 所有, 如有侵权,请联系我们删除。