
hello,大家好,这里是bang_bang,今天我们来讲一下语言层级上的程序地址空间和系统层级上的进程地址空间的区别,在下面中我举的例子会设计到环境变量,所以开篇我先讲讲环境变量。


1️⃣环境变量
初识:
大家在Linux下执行自己写的程序的时候不知道有没有注意到一个细节。命令行是这样的:
[roothost]$ ./可执行程序文件名
** ./ **是当前路径,也就是说我们要执行我们的程序需要带上路径!!!

那么有没有方法可以让我们的程序执行不需要带路径,而是像系统命令一样,直接输入命令执行呢?
——这就需要环境变量了!!!
🍙 基本概念
⭐环境变量一般是指在操作系统中用来指定操作系统运行环境的一些参数
如:我们在编写C/C++代码的时候,在链接的时候,从来不知道我们的所链接的动态静态库在哪里,但是照样可以链接成功,生成可执行程序,原因就是有相关环境变量帮助编译器进行查找。
⭐环境变量通常具有某些特殊用途,还有在系统当中通常具有全局特性
常见环境变量:
** ★**PATH : 指定命令的搜索路径
** ★**HOME : 指定用户的主工作目录(即用户登陆到Linux系统中时,默认的目录)
** ★**SHELL : 当前Shell,它的值通常是/bin/bash。
🍙环境变量相关命令
🍥查看环境变量echo
echo $NAME //NAME是你的环境变量名称
🌰查看环境变量PATH

如何直接使我们写的程序不用带上路径,像系统命令一样执行?
我们可以在PATH路径下加入我们这个可执行程序文件的当前路径。
🍥添加全局环境变量export
命令行改环境变量,只在本次登陆中生效。环境变量具有全局性!
export将环境变量设置为全局环境变量
export NAME=$NAME:添加的路径 //添加环境变量 export全局
$NAME:表示在原路径后增加路径
目录之间用冒号(:)隔开

🍥显示环境变量env/set
env //显示全局环境变量
set //显示本地shell变量和环境变量
这2条命令显示的结果太长,这里就不贴了,小伙伴们可以自己在Linux中使用查看结果。
查看env和set的详细信息可以使用 man命令进行查看
man set
man env
🍥清除环境变量unset
unset NAME //NAME为要清除的变量
🌰清除环境变量XDG_SESSION_ID

🍥全局与局部环境变量对比
局部环境变量只能在当前shell中使用,无法在子shell中使用。(局部性)
创建局部shell变量:
NAME=内容 //创建shell变量,局部性
🌰创建一个AAA的局部环境变量

🌰创建一个HOST的全局环境变量

🍥系统调用getenv获取特定环境变量
#include <stdlib.h>
char *getenv(const char *name);
🌰获取PATH环境变量
#include<stdio.h>
#include<stdlib.h>
int main()
{
printf("PATH:%s\n",getenv("PATH"));
return 0;
}

🍥系统定义全局变量environ
#include<unistd.h>
extern char **environ;
environ是C语言提供的一个全局变量,其指向环境表,环境表是一个字符指针数组,每个指针指向以'\0‘结尾的环境字符串。注意:环境表最后是NULL

🍥浅谈main函数参数及environ的使用
前两个参数是命令行参数,最后一个参数是环境变量参数。
int main(int argc, char *argv[], char *env[])
🌰测试命令行参数:argc是命令参数个数(命令本身算1个参数),字符指针数组argv存放命令
//测试argv[]
int main(int argc,char* argv[])
{
if(argc != 2)
{
printf("Usage: %s 至少要有一个选项\n", argv[0]);
return 1;
}
if(strcmp("-a", argv[1]) == 0)
{
printf("这个是功能一\n");
}
else if(strcmp("-b", argv[1]) == 0)
{
printf("这个是功能二\n");
}
return 0;
}

🌰测试环境变量参数:
#include<stdio.h>
int main(int argc,char* argv[],char* env[])
{
for(int i=0;env[i];i++)
{
printf("env[%d]:%s\n",i,env[i]);
}
return 0;
}

🌰使用系统定义变量environ测试:
#include<stdio.h>
#include<unistd.h>
int main(int argc,char* argv[],char* env[])
{
extern char** environ;
for(int i=0;environ[i];i++) //环境表最后是NULL,可以直接做for的循环退出条件
{
printf("environ[%d]:%s\n",i,environ[i]);
}
return 0;
}

2️⃣进程地址空间
🍙程序地址空间(语言层级)
相信大家无论在学习何种语言的时候都听说过“地址”这个概念,但不知道大家有没有仔细想过这个“地址”有没有可能不是物理内存上的呢?
在这里我明确的告诉大家,语言上说的“地址“不是物理内存地址,而是虚拟内存地址!!!
🍥验证地址空间排布

32位下地址空间
🌰测试各区域地址空间排布:
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
int g_unval;
int g_val = 100;
int main(int argc, char *argv[], char *env[])
{
//字面常量
const char *str = "helloworld";
//代码区
printf("code addr: %p\n", main);
//位于代码区和全局初始化数据之间(有的教材叫常量区)
printf("constant addr:%p\n",str);
//全局初始化数据
printf("init global addr: %p\n", &g_val);
static int test = 10;
printf("test static addr: %p\n", &test);
//全局未初始化数据
printf("uninit global addr: %p\n", &g_unval);
char *heap_mem = (char*)malloc(10);
char *heap_mem1 = (char*)malloc(10);
char *heap_mem2 = (char*)malloc(10);
char *heap_mem3 = (char*)malloc(10);
//堆
printf("heap addr: %p\n", heap_mem); //heap_mem(0)
printf("heap addr: %p\n", heap_mem1); //heap_mem(1)
printf("heap addr: %p\n", heap_mem2); //heap_mem(2)
printf("heap addr: %p\n", heap_mem3); //heap_mem(3)
//栈
printf("stack addr: %p\n", &heap_mem); //&heap_mem(0)
printf("stack addr: %p\n", &heap_mem1); //&heap_mem(1)
printf("stack addr: %p\n", &heap_mem2); //&heap_mem(2)
printf("stack addr: %p\n", &heap_mem3); //&heap_mem(3)
//命令行参数环境变量
for(int i = 0 ;i < argc; i++)
{
printf("argv[%d]: %p\n", i, argv[i]);
}
for(int i = 0; env[i]; i++)
{
printf("env[%d]: %p\n", i, env[i]);
}
return 0;
}

验证结果讲解图
进程地址空间分为:正文代码、初始化数据、未初始化数据、堆、栈、命令行参数环境变量,其中堆、栈相对而生。
static修饰局部变量(本质:将该变量开辟在全局区域)
🍥探究物理内存or虚拟内存
我上面一开始就说语言上的地址是虚拟地址,为什么?
🌰下面代码中,我们仔细观察全局变量g_val,在进程中,我们讲过子进程和父进程共享代码。
那g_val理论上应该是一模一样的,实际中是这样吗?
#include<stdio.h>
#include<stdlib.h>
#include<unistd.h>
#include<sys/types.h>
int g_val=10;
int main()
{
pid_t id=fork();
if(id==0)
{
//child
g_val=100;
printf("child:pid:%d,val:%d,addr:%p\n",getpid(),g_val,&g_val);
}
else if(id>0)
{
//parent
printf("parent:pid:%d,val:%d,addr:%p\n",getpid(),g_val,&g_val);
}
return 0;
}

这怎么可能!这说明语言层级的地址一定不是物理内存地址,而是虚拟内存地址!
🍙进程地址空间(系统层级)
所以之前说的程序地址空间并不准确,准确的应该称作进程地址空间。
虚拟地址肯定不止一份,每一个进程都会有一个虚拟地址,所以它会被管理,那么管理本质又回到了先描述再管理。那么虚拟地址我们猜一定也是一种数据结构!
🍥地址空间发展由来
⭐历史计算机,程序直接放到物理内存,进程中如果出现野指针或者指针指向另一个进程,可以直接读取另一个进程的内容,十分不安全。并且当物理内存满的时候,再插入进程,需要重新排序,十分繁琐。
⭐现代计算机,提出了下面的方式!
——给每个进程一个虚拟地址空间(本质:一个数据结构)(0x0000 0000~0xFFFF FFFF)
🍥地址空间结构
地址空间是一种内核数据结构mm_struct,进程控制块(PCB)包含着mm_struct数据结构的指针
根据上面验证的地址空间排布,我们得知mm_strcut内至少要有各区域的划分,那么是如何实现划分呢?我来讲个小故事引导大家理解。
上小学的时候,我们应该都见过三八线(或者正是你的亲身经历),当你和同桌小美闹矛盾的时候,五五开的桌子变会被重新划分,中间划分的线便是三八线。
不难看出,划分的本质就是使用2个数作为两边界+或者-去一定的范围作划分区域。
mm_struct同样如此,通过2个数确定上下边界来划分区域。
我们可以猜测mm_struct是这样定义的:
struct addr_room { int code_start; int code_end; int init_start; int init_end; int uninit_strat; int uninit_end; int heap_start; int heap_end; int stack_start; int stack_end; 其他属性; }

Linux源码中mm_struct结构体部分定义:
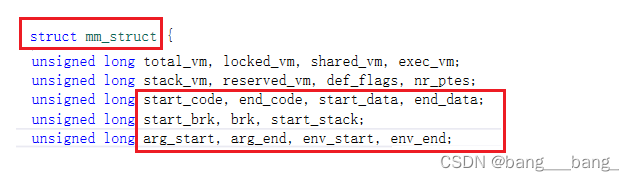
所谓的区域划分(也就是范围变化),本质是对start或者end标记值+-特定的范围即可!!!
🍥地址空间与物理内存的联系
地址空间和物理内存是通过页表映射联系起来的!
我们的程序是在磁盘中的,当要运行这个程序的时候,程序就会被加载到物理内存中,CPU寻虚拟地址,通过页表映射找到对应的物理地址,读取数据。
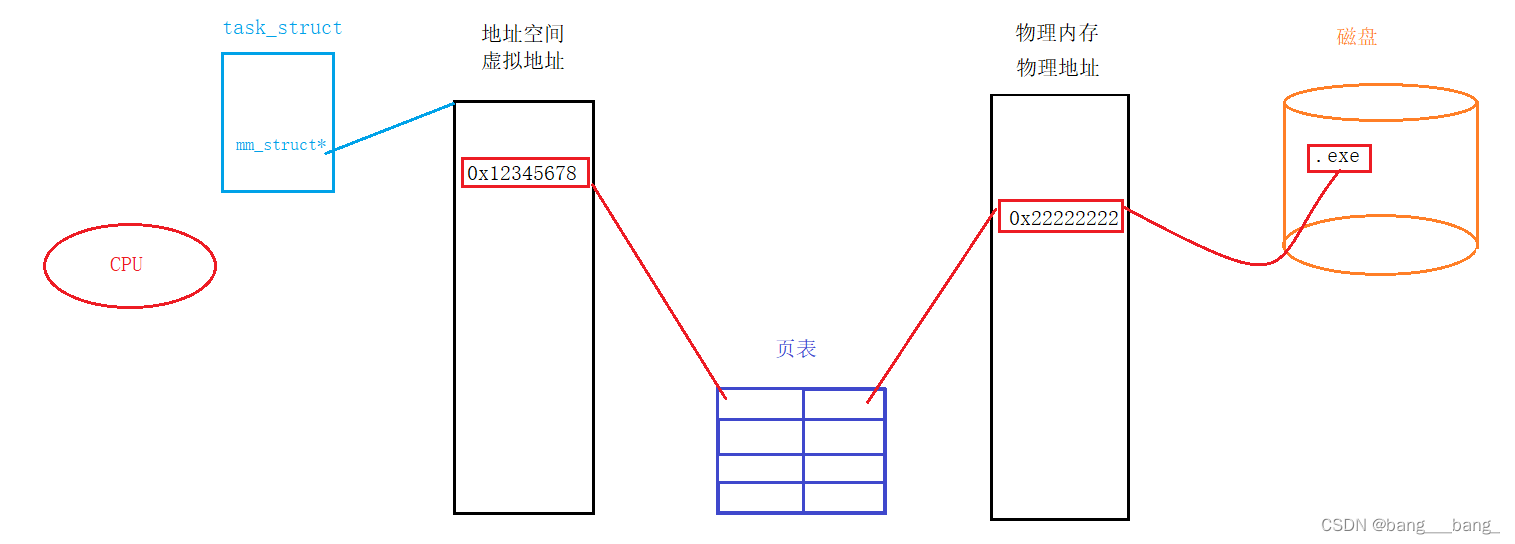
上篇文章进程详解中,我们提到进程具有独立性!如何实现呢?
其实只需要我们每个进程都有一份自己的地址空间和页表就可以做到进程彼此分开独立运行!
✦OS是通过什么机制给每个进程都分配独属于自己的地址空间呢?
通俗的讲是'画饼',32位的物理内存有4G,OS欺骗每个进程,我物理内存的4G是独属于你的,每个进程往往需要的空间都是很少的,想想你平时写的程序才多大(可能不会超过几Kb),OS自然很乐意的分配给这个进程,但当这个进程需要的空间过大(比如:正好4个G),OS肯定会拒绝,因为它还要管理其他的进程,但是这个进程平时申请的空间OS又都允许了,进程仍旧认为他拥有全部内存的使用权。✦如果上面讲的你很难理解,那就看我接下来描述的生活例子,有助于你理解刚刚所说。
我们在电影中曾看到过富豪在即将去世的时候,会把家产继承给自己的孩子。 假如现在就有一个富豪,他的家产有4个亿,并且他有3个孩子,3个孩子彼此都认为自己是富豪唯一的孩子,这3个孩子为了子承父业,各自在不同的行业上努力拼搏,平时的一些必要小花销投资向富豪申请,富豪也会同意,但是当有一天,老大向富豪要3个亿去投资大项目,富豪肯定会拒绝他(已经没这么多钱了),老大或许只会抱怨几句,但他还是深信不疑自己就是富豪唯一的孩子,这就是吃了富豪画的饼。✦为什么地址空间要被管理?
你可以想象,一个公司企业的老板,给A员工说你好好干活,我给你加薪;给B员工说你好好干活,我给你升职......画的饼多了,他很有可能会记错,等再给A员工画饼的时候,给他说我给你升职(A员工一定会满脸???之前不是说给我加薪吗)所以为了防止出现错误,老板一定会通过某种手段管理给员工画的饼。 OS同样如此,他给每个进程画饼,也需要管理,这就回到了上面说的地址空间需要被管理,管理的本质又是先描述再管理。
🍥写时拷贝
会到上面我们探究的例子,地址相同却有2个不同的值!这里面其实发生了一个机制:写时拷贝
我们在上篇文章中说父子进程代码和数据是共享的,也就是说父子进程的地址空间通过页表映射到物理内存上应该是一个位置(这是对的!)但是当我们子进程要进行写入的时候,这时为了不影响父进程的数据,OS就会在内存中拷贝出一个新的位置,同时断开页表的映射关系,让页表映射到这个新的位置,供子进程使用。

子进程执行读权限的时候,父子进程页表映射到同一物理内存,当执行写权限时,OS重新拷贝一份数据到物理内存上,同时子进程的页表断开原来的映射关系,映射到拷贝数据的物理地址。
🍥编译器同样遵守虚拟地址
地址空间不要仅仅理解成为是OS内部要遵守的,其实编译器也要遵守!!
即编译器编译代码的时候,就已经给我们形成了 各个区域 代码区,数据区........并且,采用和Linux内核中一样的编址方式,给每一个变量,每一行代码都进行了编址,故,程序在编译的时候,每一个字段早已经具有了一个虚拟地址!!!

CPU读取指令的时候寻址如下:

CPU读取到指令的时候指令内部也有虚拟地址,CPU读取到指令内部的虚拟地址再用该虚拟地址通过页表映射找到数据的物理地址。
🍙 为什么需要进程地址空间
🍥安全性
凡是非法的访问或者映射,OS都会识别到,并终止你这个进程!!(富翁拒绝4个亿的请求)
有效保护了物理内存。也有效的保护了物理内存中的所有有效数据以及内核的相关有效数据!
比如:修改字符常量区,页表管理的代码区没有写权限。
所有的进程崩溃,本质是进程退出!(OS杀掉这个进程)
🍥独立性
因为有地址空间的存在,页表的映射的存在。我们的物理内存中可以对未来的数据进行任意位置的加载。物理内存的分配就可以和进程的管理,可以做到没有关系!(不关心数据所在物理内存位置,只关心能否映射到物理内存对应位置)
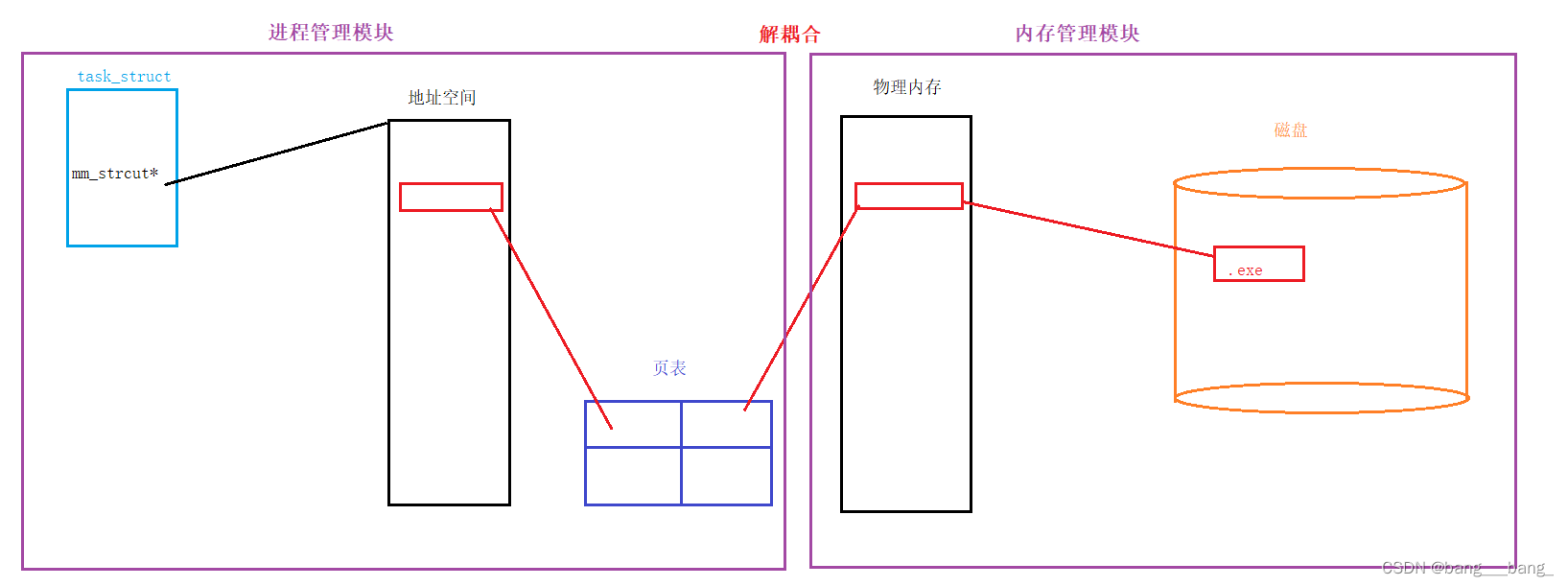 内存管理模块 vs 进程管理模块就完成了解耦合!(减少模块和模块的关联性
内存管理模块 vs 进程管理模块就完成了解耦合!(减少模块和模块的关联性
✦因为在物理内存中理论上可以任意位置加载,那么物理内存中的所有的数据和代码在内存中是乱序的!但是,因为页表的存在,它可以将地址空间上的虚拟地址和物理地址进行映射,那么在进程视角所有的内存分布,都可以是有序的!
地址空间+页表的存在 可以 将内存分布 有序化!
✦地址空间是OS给进程画的大饼+任意加载:进程要访问的物理内存中的数据和代码,可能目前并没有在物理内存中,同样的,也可以让不同的进程映射到不同的物理内存,便很容易做到,进程独立性的实现!!
进程的独立性,可以通过地址空间+页表的方式实现。
**因为有地址空间的存在,每一个进程都认为自己独占内存4G(32)空间,并且各个区域是有序的,进而可以通过页表映射到不同的区域,来实现进程的独立性!!**
🍥分批加载and分批换出
✦我们在C、C++new,malloc空间的时候,本质是在虚拟地址空间申请的。
本质上,(因为有地址空间的存在,所以上层申请空间,其实是在地址空间上申请的,物理内存可以甚至一个字节都不给。而当你真正进行对物理地址空间访问的时候,才执行内存的相关管理算法,帮你申请内存,构建页表映射关系)**延迟分配策略(页表中断)**,然后,再让你进行内存的访问。
通过延迟分配策略我们可以实现分批加载, 我们下载的大型程序(几个G)实际上就运用了分批加载的方式,要不然超过了我们的物理内存大小,我们是如何下载下来的?
✦加载本质就是 创建进程,但不是必须飞的立马把所有的的程序的代码和数据加载到内存中并创建内核数据结构建立映射关系。在最极端的情况下:只有内核结构被创建出来!进程这种状态叫做新建状态!
✦既然可以分批加载,可以分批换出吗?
当然可以,甚至这个进程短时间不会再被执行了(比如网络太卡了,要等很久,OS不想让该进程的数据和代码占着位置,那么就换出),进程的数据和代码被换出了,就叫做**挂起**!
文末结语,本篇文章详细讲解了探究地址空间排布的前言知识环境变量,通过程序验证了地址空间排布,并探究程序所说的地址究竟是物理地址还是虚拟地址,铺垫完后进入重点进程地址空间,详细介绍了进程地址空间是什么?结构,与物理内存的联系,并讲解写时拷贝的现象,拓展补充编译器同样遵守虚拟地址;最后讲解为什么需要地址空间,分为3个部分:安全性,独立性和OS的延迟分配策略实现内存的分批换出and分批换入。
版权归原作者 bang___bang_ 所有, 如有侵权,请联系我们删除。