
1.Interval Joins(区间Join)
区间是双流join的优化,基于处理时间或事件时间,在一定时间区间内数据,相同的key进行join(支持 Batch\Streaming)。Interval Join 可以让一条流去 Join 另一条流中前后一段时间内的数据。
对于stream查询,时间区间join只支持有时间属性的 append-only表。由于时间属性是准单调递增的,Flink可以从其状态中删除旧值,而不会影响结果的正确性。

优点:由于给定了关联的区间,因此只需要保留很少的状态,内存压力较小。
缺点:如果关联的数据晚到或者早到,导致落不到 JOIN 区间内,就可能导致结果不准确。只支持普通 Append 数据流,不支持含 Retract 的动态表。支持事件时间和处理时间
区间join支持基本特征如下:
- 支持INNER、LEFT、RIGHT、FULL OUT JOIN
- 语义语法和传统sql join一致
- 左右流都会触发更新
- state根据时间区间保留,自动清理
- 输出流保留时间属性
2.语法
语法和sql join一致。
SELECT * FROM Orders
[INNER|RIGHT|LEFT|FULL OUTER] JOIN Product
ON Orders.productId = Product.id
区别在于join连接条件,有效的join连接条件如下:
- ltime = rtime
- ltime >= rtime AND ltime < rtime + INTERVAL '10' MINUTE
- ltime BETWEEN rtime - INTERVAL '10' SECOND AND rtime + INTERVAL '5' SECOND
3.Interval Join实例
如果订单在收到订单10小时后发货,则此查询将把所有订单与其相应的发货联系起来
# 两表有时间戳字段,并且作为 watermark。或者使用PROCTIME() 函数来生成一个处理时间戳
SELECT *
FROM Orders o, Shipments s
WHERE o.id = s.order_id
AND o.order_time BETWEEN s.ship_time - INTERVAL '10' HOUR AND s.ship_time
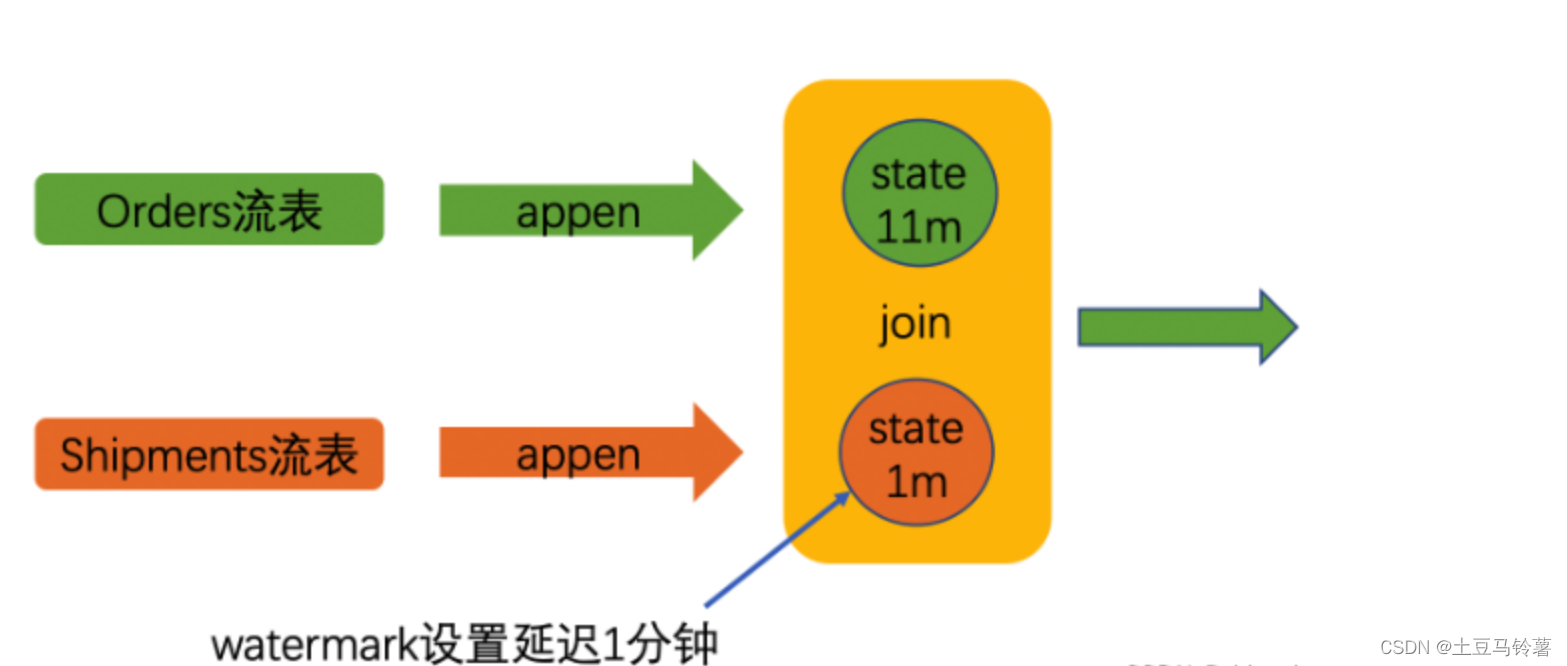
总的来说,Interval join 主要用于处理时间序列数据的场景,在 join 操作时需要在时间窗口内匹配数据;而 Regular join 主要用于一般的数据 join 操作。Interval join处理更高效,可定时清除状态数据,性能更好。实际开发中,需要考虑具体业务场景、流表数据大小及更新频率、源数据是否有时间属性等因素,选择适合的方式。
本文转载自: https://blog.csdn.net/marui156/article/details/131209372
版权归原作者 土豆马铃薯 所有, 如有侵权,请联系我们删除。
版权归原作者 土豆马铃薯 所有, 如有侵权,请联系我们删除。