
我们希望为模型准备或分析的数据是完美的。但是数据可能有缺失的值、异常值和复杂的数据类型。我们需要做一些预处理来解决这些问题。但是有时我们在分类任务中会遇到不平衡的数据。因为在我们的生活中,数据不可能是平衡的,这种不平衡的情况非常常见而且需要进行修正。
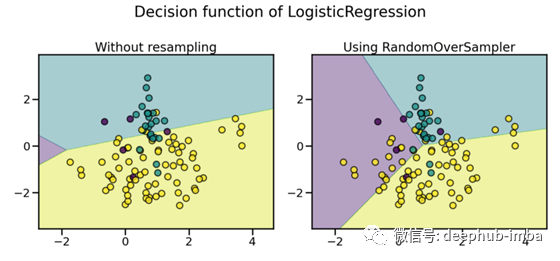
例如,有一个二进制分类任务,数据中有100条记录(行),其中90行标记为1,其余10行标记为0。
有了这些数据,我们的模型就会有偏差。预测将由多数类主导。
为了防止这种情况的发生,我们可以使用现成的imblearn。
imblearn是一个开源的由麻省理工学院维护的python库,它依赖scikit-learn,并为处理不平衡类的分类时提供有效的方法。
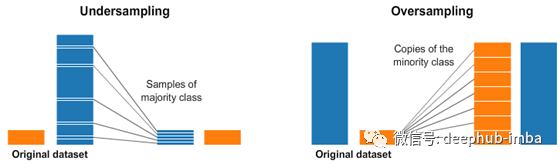
imblearn库包括一些处理不平衡数据的方法。欠采样,过采样,过采样和欠采样的组合采样器。我们可以采用相关的方法或算法并将其应用于需要处理的数据。
本篇文章中我们将使用随机重采样技术,over_sampling和under_sampling方法,这是最常见的imblearn库实现。这里我们需要使用RandomOverSampler和RandomUnderSampler类。
这些方法是做什么的?
- RandomOverSampler复制少数类的行。
- RandomUnderSampler删除多数类的行。
这两种方法使复制和删除随机进行。如果我们想快速,轻松地获取平衡数据,则最好使用这两种方法进行结合。
需要注意的是:我们仅将其应用于训练数据。我们只是平衡训练数据,我们的测试数据保持不变(原始分布)。这意味着我们在将数据分为训练和测试之后再应用重采样方法。
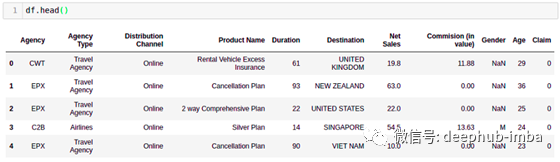
我们将分析旅行保险数据以应用我们的重采样方法,数据如下。
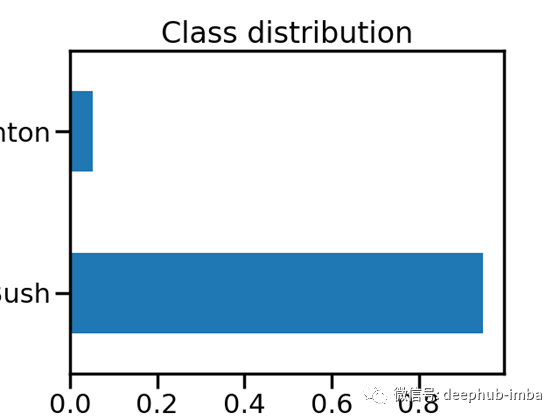
我们有一个二分类问题。我们的目标特征是“Claim”。0是多数,1是少数。目标分布是这样的;

我们将应用Logistic回归比较不平衡数据和重采样数据之间的结果。该数据集来自kaggle,并且以一个强大的不平衡数据集而成名。我们没有探索性的数据分析过程来更好地查看比较结果,这里我们只是做对比,而不考虑真正的比赛分数。
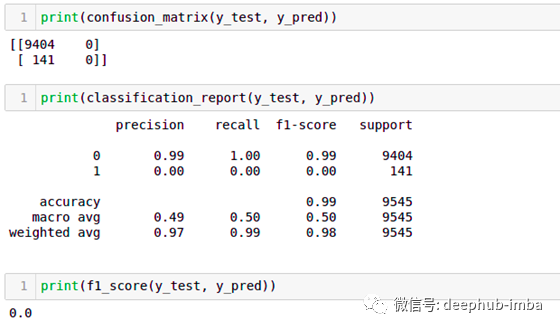
在重采样方法之前,我们对数据应用了Logistic回归。查看精度,召回率和f1得分均为0,因为该模型无法学习。该模型预测所有记录都为0,这对多数类有利。它为我们提供了一个始终返回多数类的预测模型。它无视少数分类。
对于不平衡的数据集模型,f1分数是最合适的度量。因此,我们使用f1得分进行比较。
现在,我们将按顺序应用RandomOverSampler,RandomUnderSampler和组合采样的方法。
过采样
我们用随机采样器将合成的行添加到数据中。我们通过增加少数分类来使目标值的数量相等。这对于分类有益还是有害取决于具体的任务 ,所以需要对于具体任务来说需要进行测试。这里我们不想使我们的数据产生问题,例如如果多数类和少数类之间存在显着差异,请仔细应用此方法,或者调整采样策略参数。
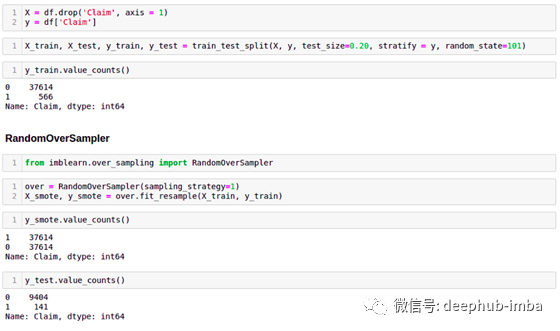
我们将采样策略设置为1。这意味着少数类别将与多类别具有相同的数量,少数类别将复制其行。检查y_smote的value_counts(使用重采样方法将y_train转换为y_smote)
我们将数据分为训练和测试,并将RandomOverSampler仅应用于训练数据(X_train和y_train)。如果我们重新采样测试数据或所有数据,则可能导致数据泄漏。
from imblearn.over_sampling import RandomOverSampler
over = RandomOverSampler(sampling_strategy=1)
X_smote, y_smote = over.fit_resample(X_train, y_train)
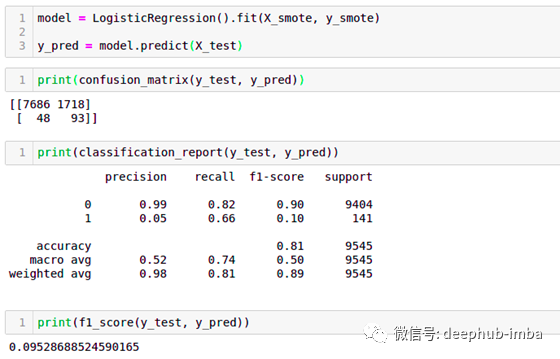
进行Logistic回归后。使用RandomOverSampler,得分提高了9.52%。
欠采样
RandomUnderSampler根据我们的采样策略随机删除多数类的行。需要注意的是,此重采样方法将删除实际数据。我们不想丢失或压缩我们的数据,这种方法就不太合适了。

我们将采样策略调整为1。这意味着多数类与少数类的数量相同多数类将丢失行。检查y_smote的value_counts(通过重采样方法将y_train转换为y_smote)。
我们将数据分为训练和测试,并将RandomUnderSampler仅应用于训练数据(X_train和y_train)。
from imblearn.under_sampling import RandomUnderSampler
under = RandomUnderSampler(sampling_strategy=1)
X_smote, y_smote = under.fit_resample(X_train, y_train)

进行Logistic回归后, 使用RandomUnderSampler,得分提高了9.37%。
这些重采样方法的常见用法是将它们组合在管道中。不建议在大型数据集中仅使用其中之一,这是多数和少数类之间的重要区别。
使用流水线管道
如上所述,不建议仅将过采样或欠采样方法应用于在类之间具有显着差异的大量数据。我们有一个额外的选择,我们可以在流水线中同时应用过采样和欠采样方法。我们将把这两种方法与调整抽样策略结合起来。
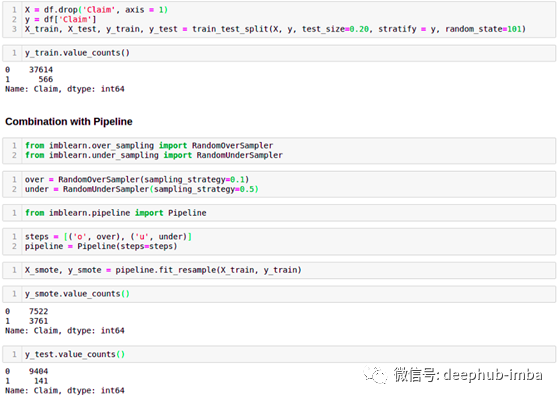
我们使用imblearn.pipeline创建一个管道,孙旭对我们的给出的策略进行处理。具有0.1采样策略的RandomOverSampler将少类提高到“ 0.1 *多数类”。接下来,采用0.5采样策略的RandomUnderSampler将多数类的数量减少为“ 2 *少数类”。在管道的最后,少数类和多数类之间的比率将为0.5。
from imblearn.over_sampling import RandomOverSampler
from imblearn.under_sampling import RandomUnderSampler
over = RandomOverSampler(sampling_strategy=0.1)
under = RandomUnderSampler(sampling_strategy=0.5)
from imblearn.pipeline import Pipeline
steps = [('o', over), ('u', under)]
pipeline = Pipeline(steps=steps)
X_smote, y_smote = pipeline.fit_resample(X_train, y_train)

在进行Logistic回归后, 经过管道的测试得分提高了11.83%。
总结
我们应该注意,我们仅将这些方法应用于训练数据。我们只是平衡训练数据,我们的测试数据保持不变(原始分布)。
imblearn库中还有其他技术和算法,请检查该库文档。
我们应该谨慎使用这些技术,因为它们会改便我们的数据分布。
作者:Hasan Ersan YAĞC
deephub翻译组