
contents
CSS selector
HTML中经常要为某些元素指定显示效果,CSS就是浏览器用来选择元素,使其具有指定显示风格。只要CSS Selector的语法是正确的, Selenium就可以选择到该元素。
通过CSS Selector选择单个元素的方法是
driver.find_element(By.CSS_SELECTOR, CSS Selector参数)
选择所有元素的方法是
driver.find_elements(By.CSS_SELECTOR, CSS Selector参数)
。
下面就来具体介绍CSS Selector参数应该怎么写。更多语法可以参考CSS选择器参考手册。
根据 tag名、id、class 选择元素
示例:
<input class="plant" type="text" id='searchtext' />
- 根据tag名选择元素,直接写上tag名,例如选择所有的tag名为input的元素
elements = driver.find_elements(By.CSS_SELECTOR, 'input')等价于于elements = driver.find_elements(By.TAG_NAME, 'input')。 - 根据id属性选择元素,在id值前面加上一个井号:**#id值**,例如选择所有的id为searchtext的元素
elements = driver.find_elements(By.CSS_SELECTOR, '#searchtext')等价于于elements = driver.find_elements(By.ID, 'searchtext')。 - 根据class属性选择元素,在class值前面加上一个点:**.class值**,例如选择所有的class为plant的元素
elements = driver.find_elements(By.CSS_SELECTOR, '.plant')等价于于elements = driver.find_elements(By.CLASS_NAME, 'plant')。
注意:点号,井号后面不能有空格
选择子元素和后代元素
元素内部可以包含其他元素
子元素和后代元素借用白月黑鱼老师的博客说明:
id为 container 的div元素 包含了 id 为
layer1和
layer2的两个div元素。
这种包含是直接包含, 中间没有其他的层次的元素了。 所以 id 为layer1和
layer2的两个div元素 是 id 为
container的div元素的直接子元素。
而 id 为layer1的div元素 又包含了 id 为
inner11和
inner12的两个div元素。 中间没有其他层次的元素,所以这种包含关系也是直接子元素关系
id 为 layer2 的div元素 又包含了id为inner21这个div元素。 这种包含关系也是直接子元素关系
而对于id为 container 的div元素来说, id 为
inner11、
inner12、
inner22的元素 和 两个
span类型的元素都不是它的直接子元素, 因为中间隔了 几层。
虽然不是直接子元素, 但是它们还是在container的内部,可以称之为它的后代元素。
后代元素也包括了直接子元素, 比如 id 为layer1和
layer2的两个div元素 也可以说是id为
container的div元素的直接子元素,同时也是后代子元素
- 选择元素1的直接子元素元素2, 用CSS Selector选择子元素(元素2)的语法是
elements = driver.find_elements(By.CSS_SELECTOR, '元素1 > 元素2')中间用一个大于号 。 同时,这种方法支持多层级的选择,例如,元素1里面的子元素 元素2里面的子元素 元素3里面的子元素 元素4 ,则为elements = driver.find_elements(By.CSS_SELECTOR, '元素1 > 元素2 > 元素3 > 元素4')。 - 选择元素1的后代元素元素2, 用CSS Selector选择后代元素(元素2)的语法是
elements = driver.find_elements(By.CSS_SELECTOR, '元素1 元素2')中间是一个或者多个空格隔开。 同时,也支持更多层级的选择, 例如,元素1里面的后代元素 元素2里面的后代元素 元素3里面的后代元素 元素4 ,则为elements = driver.find_elements(By.CSS_SELECTOR, '元素1 元素2 元素3 元素4') - 上述1.和2. 可混用
根据属性选择
css 选择器除了支持class,id属性,还支持任何属性来选择元素,语法是用一个方括号
[属性名="属性值"]
。
例如元素
<a target="kcmstarget" href="/kcms/detail/">医疗保障研究</a>
,选择该元素的方式为
elements = driver.find_element(By.CSS_SELECTOR, '[href="/kcms/detail/"]')
。
note:
- 若属性值省略,即不指定属性值,例如
elements = driver.find_elements(By.CSS_SELECTOR, '[href]'), 表示选择所有具有属性名为href的元素。 - 可以加上其他限制(不要随意加空格,否则会被认为是后代元素的关系),例如标签名的限制,
elements = driver.find_elements(By.CSS_SELECTOR, 'a[href="/kcms/detail/"]')表示选择所有标签名为a,且href属性值为/kcms/detail/的元素。详见下表
元素特征代码示例说明属性值包含某个字符串a[href*=“kcms”]选择标签为a,且里面的href属性包含kcms字符串的元素属性值以某个字符串开头的元素#a[href^=“http”]选择id为a,且里面的href属性以http开头的元素属性值以某个字符串结尾的元素.a[href$=“cn”]选择class为a,且里面的href属性以cn结尾具有多个属性a[target^=“kcms”][href$=“cn”]选择标签为a,且里面的target属性以kcms开头,href属性以cn结尾的元素组选择
elements=driver.find_elements(By.CSS_SELECTOR, '[href*="kcms"],[target^="kcms"]')
表示定位到 href属性包含kcms字符串 或者target属性以kcms开头的元素。
css选择器使用逗号将多个属性并列,表达的是多个属性之间的并列关系,称之为组选择 。
注意:
- 逗号两侧的表达式不用是同一种类型,只要是合理的选择器即可
- 逗号两侧的表达式必须都是完整的,如要选择t1元素下的标签为span或t1元素下Id为p的元素
t1>span,p是错的,t1>span,t1>#p才对。
根据次序选择
- 用
:nth-chlid(n)选择任意父元素(包括html)第n个直接子元素,可在次序限制前加上其他限制,如span:nth-child(2)表示任意父元素的第2个子元素且标签为span的元素。 用:nth-last-child(n)选择的是任意父元素的倒数第几个直接子元素,使用方法同上 - 用
类型:nth-of-type(n)选择任意父元素的某类型的第n个直接子元素。若类型不加:nth-of-type(n),则会选择父元素下各个类型的第n个元素 用类型:nth-last-of-type(n)选择任意父元素的某类型的倒数第n个直接子元素,使用方法同上。
注意:
- 次序使用冒号进行限制的
- 次数从1开始
- 若括号除了数字还可写even(表示第偶数个元素)和odd(表示第奇数个元素),如
:nth-last-of-type(odd)。
兄弟关系选择
兄弟关系:同一个父元素下的平级关系,区别之前的父子关系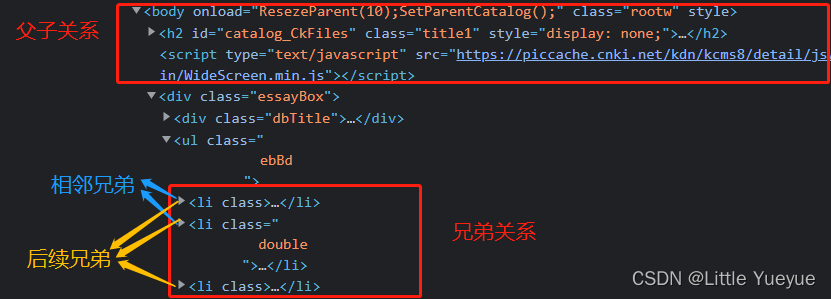
相邻兄弟关系用加号+ ,表示元素紧跟关系的,例如
li + span
表示标签li后面紧跟着标签为span的元素。
后续兄弟关系用**波浪~**,表示元素在其后的关系,例如
li ~ span
表示标签li后面所有标签为span的元素。
验证 CSS Selector
打开开发者工具,点击元素(element),ctrl+f,出现红框,在此处可验证css是否写正确。(但是涉及frame中元素的好像不行哦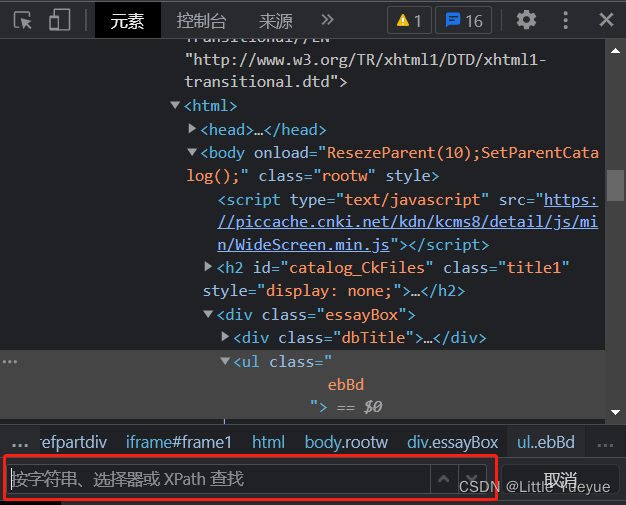
版权归原作者 Little Yueyue 所有, 如有侵权,请联系我们删除。