
生产者-同步消息发送
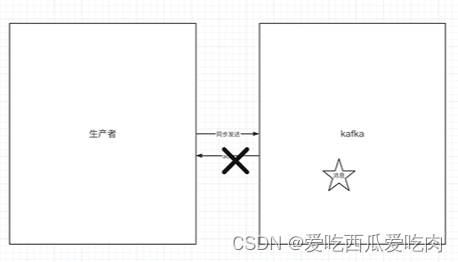
如果生产者发送消息没有收到ack,会阻塞到3s时间,如果还没收到消息,会重试,重试3次
生产者-异步消息发送(缺点:消息丢失情况,同步更优)
生产者发送消息后可以直接执行后面的业务,Broker接收到消息后异步调用生产者提供的callback回调方法

生产者-ack配置prop.put(ProducerConfig.ACKS_CONFIG,"1");
-ack = 0:kafka集群不需要任何的broker收到消息,就立即返回ack给生产者,最容易丢消息,性能是最高的。
-ack = 1:多个副本之间的leader已经收到消息,并把消息写入本地的log中,才会返回ack给生产者,性能和安全性最均衡。
-ack =-1/all:里面有默认配置min.insync.replicas=1(默认为1即和ack=1相同,推荐配置大于等于2)min.insync.replicas=3即将消息写入本地的log,且三个副本(即follower和leader同步)都同步后才返回。
生产者-关于消息发送的缓冲区
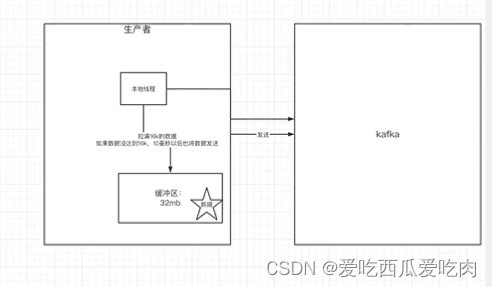
** Kafka默认会创建一个消息缓冲区,用来存放要发送的消息,缓冲区为32m**
prop.put(ProducerConfig.BUFFER_MEMORY_CONFIG,33554432);
Kafka本地线程会去缓冲区中一次拉16k的数据,发送到Broker
prop.put(ProducerConfig.BATCH_SIZE_CONFIG,16384);
如果线程拉不到16k,间隔10ms也会将已拉倒的数据发送给Broker
prop.put(ProducerConfig.LINGER_MS_CONFIG,10);
消费者需要将所属的消费组+消费的主体+消费的某个分区+消费的偏移量,将信息提交到集群的_consumer_offsets主题里面
消费者-自动提交
消息poll下来以后直接提交offset
可能丢消息:假设消费者poll消息下来(3条),offset提交3,还没消费消息消费者就宕了,再启动另一条消费者去消费,offset为3,从3以后拉取消费消息,前三条消息丢失未消费
消费者-手动提交
在消费消息时/后提交offset
自动提交设为false
prop.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
同时消费完消息,手动将offset提交上去
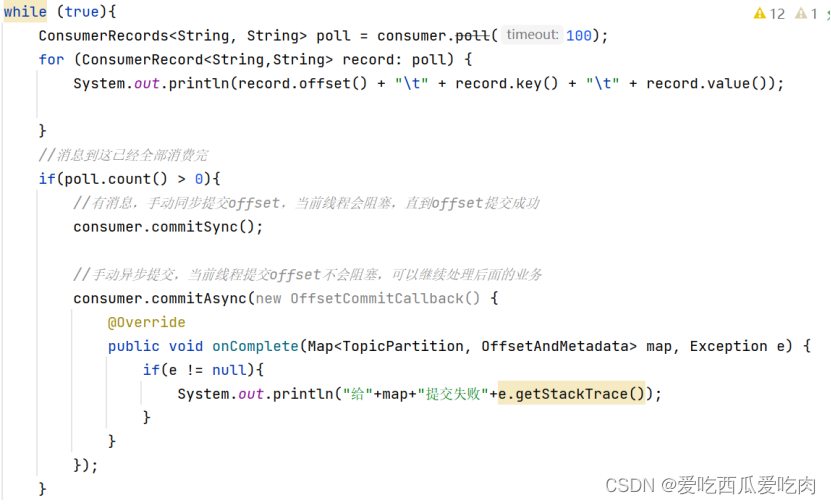
手动同步提交,程序应用会进行阻塞,而手动异步提交解决了这个问题,但是异步提交没有重试机制。因为如果程序返回提交失败,消息可能会出现重复消费的情况,假设发起异步提交A,此时提交偏移量是2000,同时又发起异步提交B为3000,此时A成功B失败,会将3000回滚到2000,出现消息重复消费
消费消息poll的细节
poll拉取消息设置拉取消息条数:500条——长轮询1秒
ConsumerRecords<String, String> poll = consumer.poll(1000);
** //1、假设拉到500条消息,则直接消费消息
//2.假设没有拉到500条,如果时间到了,也进行for循环消费消息**
prop.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG,500);可以根据消费速度来设置,如果两次Poll时间超过30s时间间隔,kafka会认为该消费者消费能力弱,从而踢出消费组,将分区分配给其他消费者
prop.put(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG,30*1000);//30秒
消费者指定分区偏移量和时间消费
consumer给broker发送心跳的时间间隔,1s一次
prop.put(ConsumerConfig.HEARTBEAT_INTERVAL_MS_CONFIG,1000);//1skafka如果超过10秒没有收到消费者的心跳,则会吧消费和踢出消费组,进行rebalance,把分区重新分配给其他消费者
prop.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG,10 * 100);指定主题和分区
consumer.assign(Collections.singleton(new TopicPartition("wangting",0)));//从头开始消费,可以重复消费消息
consumer.seekToBeginning(Collections.singleton(new TopicPartition("wangting",0)));//指定位置消费
consumer.seek(new TopicPartition("wangting",0),10);
新消费组消费offset规则
//新消费组消费规则
// earliest 从最早的开始(不记录提交点),如果消费者是新的,则从头,下次则从offset开始
//latest 从最新的开始(记录提交点)从当前分区的最后一条消息的offset+1开始消费(默认!)
//none 报错
prop.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
Kafka线上问题优化
如何防止消息丢失
发送方:ack是1 或者-1/all 可以防止消息丢失,如果要做到99.9999%,ack设成al,把min.insync.replicas配置成分区备份数。消费方:把自动提交改为手动提交。
如何防止消息的重复消费
一条消息被消费者消费多次。如果为了消息的不重复消费,而把生产端的重试机制关闭、消费端的手动提交改成自动提交,这样反而会出现消息丢失,那么可以直接在防治消息丢失的手段上再加上消费消息时的幂等性保证,就能解决消息的重复消费问题。幂等性如何保证:
- mysql 插入业务id作为主键,主键是唯一的,所以一次只能插入一条
- 使用redis或zk的分布式锁(主流的方案)
如何做到顺序消费
发送方:在发送时将ack不能设置0,关闭重试,使用同步发送,等到发送成功再发送下一条。确保消息是顺序发送的
接收方:消息是发送到一个分区中,只能有一个消费组的消费者来接收消息。
因此,kafka的顺序消费会牺牲掉性能。
解决消息积压问题
消息积压会导致很多问题,比如磁盘被打满、生产端发消息导致kafka性能过慢,就容易出现服务雪崩,就需要有相应的手段:
方案一:*** ***在一个消费者中启动多个线程,让多个线程同时消费。一一提升一个消费者的消费能力。
方案二:*** ***如果方案一还不够的话,这个时候可以启动多个消费者,多个消费者部署在不同的服务器上。其实多个消费者部署在同一服务器上也可以提高消费能力一一充分利用服务器的cpu资源。
方案三:*** ***让一个消费者去把收到的消息往另外一个topic上发,另一个topic设置多个分区和多个消费者,进行具体的业务消费。
延迟队列
延迟队列的应用场景:在订单创建成功后如果超过30分钟没有付款,则需要取消订单,此时可用延时队列来实现。
创建多个topic,每个topic表示延时的间隔
topic_5s:延时5s执行的队列
topic_1m: 延时1分钟执行的队列
topic_30m:延时30分钟执行的队列
消息发送者发送消息到相应的topic,并带上消息的发送时间
消费者订阅相应的topic,消费时轮询消费整个topic中的消息
如果消息的发送时间,和消费的当前时间超过预设的值,比如30分钟
如果消息的发送时间,和消费的当前时间没有超过预设的值,则不消费当前的offset及之后的offset的所有消息都消费
下次继续消费该offset处的消息,判断时间是否已满足预设值
JAVA实现生产者消费者
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>2.0.0</version>
</dependency>
import net.sf.jsqlparser.statement.select.Top;
import org.apache.kafka.clients.consumer.*;
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.PartitionInfo;
import org.apache.kafka.common.TopicPartition;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.kafka.common.serialization.StringSerializer;
import org.junit.Test;
import javax.xml.crypto.Data;
import java.text.SimpleDateFormat;
import java.util.*;
import java.util.concurrent.CountDownLatch;
import java.util.concurrent.TimeUnit;
public class KafkaTest {
@Test
public void consumer(){
Properties prop = new Properties();
//设置集群地址
prop.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.235.137:9092");
//设置key序列化器
prop.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
//设置值的序列化器
prop.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
prop.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG, "30000");
prop.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
prop.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
//earliest 从最早的开始(不记录提交点)
//latest 从最新的开始(记录提交点)
//none 报错
prop.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
//模拟多消费者在同一个消费者分组里G2
prop.put(ConsumerConfig.GROUP_ID_CONFIG, "G2");
//是否自动提交offset,默认是true
prop.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG,"true");
//自动提交offset时间间隔
prop.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG,"1000");
for (int i = 0; i < 3; i++) {
new Thread(() -> {
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(prop);
System.out.println(2);
consumer.subscribe(Collections.singleton("wangting"));
while (true){
ConsumerRecords<String, String> poll = consumer.poll(100);
for (ConsumerRecord<String,String> record: poll) {
System.out.println(Thread.currentThread().getName()+"\t"+record.offset() + "\t" + record.key() + "\t" + record.value());
}
}
}).start();
}
}
@Test
public void oneConsumer(){
Properties prop = new Properties();
prop.put(ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.235.137:9092");
prop.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
prop.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, StringDeserializer.class);
prop.put(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");
prop.put(ConsumerConfig.AUTO_COMMIT_INTERVAL_MS_CONFIG, "1000");
//新消费组消费规则
// earliest 从最早的开始(不记录提交点),如果消费者是新的,则从头,下次则从offset开始
//latest 从最新的开始(记录提交点)从当前分区的最后一条消息的offset+1开始消费(默认!)
//none 报错
prop.put(ConsumerConfig.AUTO_OFFSET_RESET_CONFIG, "earliest");
//分组
prop.put(ConsumerConfig.GROUP_ID_CONFIG, "G1");
//consumer给broker发送心跳的时间间隔
prop.put(ConsumerConfig.HEARTBEAT_INTERVAL_MS_CONFIG,1000);
//kafka如果超过10秒没有收到消费者的心跳,则会吧消费和踢出消费组,进行rebalance,把分区重新分配给其他消费者
prop.put(ConsumerConfig.SESSION_TIMEOUT_MS_CONFIG,10 * 100);
//poll拉取消息设置拉取消息条数:500条——长轮询1秒
//1、假设拉到500条消息,则直接消费消息
//2.假设没有拉到500条,如果时间到了,也进行for循环消费消息
prop.put(ConsumerConfig.MAX_POLL_RECORDS_CONFIG,500);
//可以根据消费速度来设置,如果两次Poll时间间隔超过30s,kafka会认为该消费者消费能力弱,从而踢出消费组,将分区分配给其他消费者
prop.put(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG,30*1000);
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(prop);
//消费者订阅主题
// consumer.subscribe(Arrays.asList("wangting"));或
consumer.subscribe(Collections.singleton("wangting"));
//指定主题和分区
consumer.assign(Collections.singleton(new TopicPartition("wangting",0)));
//从头开始消费,可以重复消费消息
consumer.seekToBeginning(Collections.singleton(new TopicPartition("wangting",0)));
//指定位置消费
consumer.seek(new TopicPartition("wangting",0),10);
//从指定时间点开始消费
// List<PartitionInfo> partitionInfos = consumer.partitionsFor("wangting");
// //从一小时前开始消费
// long fetchDateTime = new Date().getTime() - 1000 * 60 * 60;
// Map<TopicPartition,Long> map = new HashMap<>();
// for(PartitionInfo part : partitionInfos){
// map.put(new TopicPartition("wangting",part.partition()),fetchDateTime);
// }
// Map<TopicPartition,OffsetAndTimestamp> parMap = consumer.offsetsForTimes(map);
// for(Map.Entry<TopicPartition,OffsetAndTimestamp> entry : parMap.entrySet()){
// TopicPartition key = entry.getKey();
// OffsetAndTimestamp value = entry.getValue();
// if(key == null || value == null) continue;
// Long offset = value.offset();
// //根据消费者的timestamp确定offset
// if(value != null){
// consumer.assign(Arrays.asList(key));
// consumer.seek(key ,offset);
// }
// }
//一个消费者组G1里只有一个消费者
while (true){
//如果1s内每1s内没有poll到任何消息,则继续poll消息,知道Poll到消息。如果超过1s长轮询结束
ConsumerRecords<String, String> poll = consumer.poll(1000);
for (ConsumerRecord<String,String> record: poll) {
System.out.println(record.offset() + "\t" + record.key() + "\t" + record.value());
}
//消息到这已经全部消费完
if(poll.count() > 0){
//有消息,手动同步提交offset,当前线程会阻塞,直到offset提交成功
consumer.commitSync();
//手动异步提交,当前线程提交offset不会阻塞,可以继续处理后面的业务
// consumer.commitAsync(new OffsetCommitCallback() {
// @Override
// public void onComplete(Map<TopicPartition, OffsetAndMetadata> map, Exception e) {
// if(e != null){
// System.out.println("给"+map+"提交失败"+e.getStackTrace());
// }
// }
// });
}
}
}
@Test
public void oneProducer() throws InterruptedException {
Properties prop = new Properties();
prop.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG, "192.168.235.137:9092");
prop.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
prop.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class);
//重试次数-10次
prop.put(ProducerConfig.RETRIES_CONFIG,10);
//重试间隔设置,300ms
prop.put(ProducerConfig.RETRY_BACKOFF_MS_CONFIG,300);
//设置缓冲区大小
prop.put(ProducerConfig.BUFFER_MEMORY_CONFIG,33554432);
//kafka本地线程从缓冲区取数据,批量发送给Broker,默认值16kb,即16384,batch满16k就发送出去
prop.put(ProducerConfig.BATCH_SIZE_CONFIG,16384);
prop.put(ProducerConfig.LINGER_MS_CONFIG,10);
//ack配置
//prop.put(ProducerConfig.ACKS_CONFIG,"1");
KafkaProducer<String, String> producer = new KafkaProducer<>(prop);
//要发五条消息
int msgNum = 5;
final CountDownLatch downLatch = new CountDownLatch(msgNum);
for(int i = 0;i < 5;i++){
SimpleDateFormat format = new SimpleDateFormat();
Date date = new Date(System.currentTimeMillis());
ProducerRecord<String,String> record = new ProducerRecord<>("wangting",format.format(date));
//异步,发五条就要五个反馈
producer.send(record,new Callback(){
@Override
public void onCompletion(RecordMetadata recordMetadata, Exception e) {
if(e != null){
System.out.println("发送消息失败");
}
if(recordMetadata != null){
System.out.println("异步发送消息"+recordMetadata.topic()+recordMetadata.partition()+recordMetadata.offset());
}
downLatch.countDown();//减一
}
});
//同步
// try{
// producer.send(record);
//
// }catch (Exception e){
// e.printStackTrace();
// }
}
Thread.sleep(1000000);
downLatch.await(5, TimeUnit.SECONDS);//如果不是0继续等5秒
producer.close();
}
}
SpringBoot整合Kafka
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
spring:
kafka:
bootstrap-servers: 192.168.235.137:9092,192.168.235.137:9093,192.168.235.137:9094
producer:
# 重试次数,默认Integer.MAX_VALUE
retries: 1
# 同一批次内存大小(默认16K)
batch-size: 16384
# 生产者内存缓存区大小(32M)
buffer-memory: 33554432
# key和value的序列化(默认,可以不设置)
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
# ack应答机制,默认1,即只需要确认leader收到消息
acks: 1
# springboot1.5.16自动装配中不支持properties下的其他配置,不知道为啥。2.x版本可以
#properties:
# 使用自定义的分区选择器
#{partitioner.class: com.msy.kafka.MyPartition, acks: all}
consumer:
group-id: test
enable-auto-commit: false
# earliest:从头开始消费 latest:从最新的开始消费 默认latest
auto-offset-reset: latest
# key和value反序列化(默认,可以不设置)
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
listener:
# 消费者并发能力
concurrency: 6
# 设置手动提交的时候,需要设置ackMode
# RECORD :当listener一读到消息,就提交offset
# BATCH: poll() 函数读取到的所有消息,就提交offset
# TIME: 当超过设置的ackTime ,即提交Offset
# COUNT :当超过设置的COUNT,即提交Offset
# COUNT_TIME :TIME和COUNT两个条件都满足,提交offset
# MANUAL : 当每批poll的消息全部处理完,Acknowledgment.acknowledge()即提交Offset,和Batch类似
# MANUAL_IMMEDIATE: 只要调用Acknowledgment.acknowledge()即提交Offset
ack-mode: MANUAL
topic: wangting
@RestController
public class MyKafkaController {
@Resource
private KafkaTemplate<String,String> kafkaTemplate;
@RequestMapping("/send")
public String senMessage(){
kafkaTemplate.send("wangtng",0,"key","this is a message");
return "send success;";
}
}
@Component
public class MyConsumer {
//消费xx主题,为x消费组
// @KafkaListener(topics = "wangting",groupId = "test")
// public void listenGroup(ConsumerRecord<String,String> record, Acknowledgment ack){
// //对每条消息处理
// String value = record.value();
// System.out.println(value);
// System.out.println(record);
// //手动提交时如果不调用这个方法,消息会重复消费
// ack.acknowledge();a
// }
@KafkaListener(groupId = "test",topicPartitions = {
@TopicPartition(topic = "topic1",partitions = {"0","1"}),
@TopicPartition(topic = "topic2",partitions = "0",partitionOffsets = @PartitionOffset(partition = "1",initialOffset = "100"))},
//在消费topic2主题时,消费0分区不指定,消费1号分区从offset100位置消费
concurrency = "3")//在这个组下,kafka创建3个消费者去消费,并发消费,建议小于等于分区总数
public void listenGroup(ConsumerRecord<String,String> record, Acknowledgment ack){
//对每条消息处理
String value = record.value();
System.out.println(value);
System.out.println(record);
//手动提交时如果不调用这个方法,消息会重复消费
ack.acknowledge();
}
}
版权归原作者 爱吃西瓜爱吃肉 所有, 如有侵权,请联系我们删除。