
写在前面,本篇文档收录于前公司文档库内,具体作者未知。网络也没有相关内容介绍,觉得在网络测试这块chariot是用的最多的性能测试工具,分享这篇文档。如有侵权请告知删除,谢谢。
现行的网卡测试中,CHARIOT吞吐量性能是衡量网卡性能的关键性数据。该项测试主要通过使用CHARIOT软件中Throughput脚本进行测试,而脚本本身有其自身的结构和各种不同的参数变量需要进行设置,这些参数的设置对测试结果有着直接的影响,只有充分地理解脚本的结构及其各项变量的含义,在此基础上才能对脚本参数进行合理的配置,改进目前测试中的不足之处,提出相应的改善方法和措施。所以下面主要针对网卡CHARIOT测试脚本的参数如何进行合理的配置进行一些探讨,从而提出较为优化的测试方案。
- CHARIOT****软件简介
CHARIOT是目前世界上唯一认可的应用层IP网络及网络设备的权威测试软件,它能够提供端到端,多操作系统,多协议测试,多应用模拟测试,其应用范围非常广泛,测试功能十分强大。
在我们公司,网卡系列产品的测试中,主要通过使用Chariot软件进行网卡的吞吐量测试,从软件测试的结果中反映网卡的基本性能。所以,如何将该软件进行合理的配置,正确的使用这个优秀的测试工具,准确的反映网卡的客观真实性能,是我们测试工作中需要进行深入研究的一个课题。
1.1 CHARIOT**工作原理:**
CHARIOT测试原理是通过产生模拟真实的流量,采用端到端的方法测试网络设备或网络系统在真实环境中的性能。
CHARIOT软件的基本组成包括两部分:CHARIOT控制台和Endpoint。
其中CHARIOT控制台可以运行于Microsoft的各种Windows平台。在CHARIOT控制台上可以定义各种可能的测试拓扑结构和测试业务类型。
Endpoint可以运行在几乎目前流行的所有操作系统上。CHARIOT Endpoint能够充分利用运行主机的资源,执行CHARIOT控制台发布的Script命令,从而完成需要的测试。
当你开始一项测试时,CHARIOT通过从控制台向每一个节点1所在的电脑发送测试建立信息来开始进行测试。下图是一个最简单的例子,使用一组Pair(节点1和节点2):
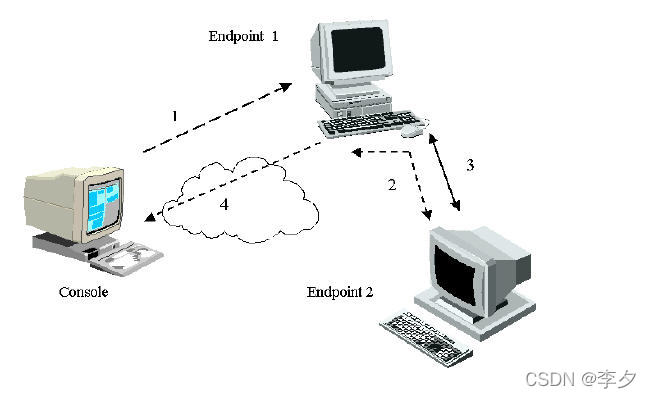
上图中的数据流向和解释如下:
- 首先,在控制台创建一项测试,然后点击“运行”按钮。控制台就会向节点1发送建立信息。这个建立信息包括应用脚本,节点2所在电脑的地址,连接节点2时所要使用的协议,所要使用的服务质量,测试运行的时间,报告测试结果的方式等。
- 节点1保留它自身的那一半应用脚本,然后把另一半发送给节点2。当节点2向节点1确认了它已经准备好接收数据了,节点1回复给控制台,控制台确认了这一对节点已经准备好了,控制台就控制这一对节点开始进行测试。
- 两个节点执行它们各自的应用脚本,然后节点1收集包含测试结果的测试记录。
- 节点1将测试记录发送给控制台,然后控制台对这些数据进行解释、分析并显示出结果。
Chariot软件的中所有的测试,都是基于测试脚本的架构来进行的,不同的测试目的使用不同的测试脚本。软件本身提供了丰富的测试脚本,使Chariot能够进行多种功能的测试。
就总体来说,最常用的基本的测试项目有三个:
1、Throughput测试
2、response time测试
3、Transaction rate测试
其中Throughput的测试更是该软件最核心的测试应用,由于Throughput测试是基于使用Throughput脚本来进行的,所以,下面我们将对Throughput脚本进行详细的说明。
- Throughput****脚本分析
- Throughput****脚本基本介绍
这一节主要对于Throughput脚本的结构进行详细的分析,列举测试脚本中的各个变量、具体含义以及各变量的不同设置对测试结果的影响。在分析完变量意义的基础上对Chariot软件测试脚本的基本结构形式进行了熟悉。
2.1.1 Throughput****脚本简介:
Chariot软件有三个最基本的测试项目,包括吞吐量测试、响应时间测试、传输率测试。其中吞吐量测试就是测试一个标准网络的最大数据吞吐量,它是通过执行Chariot软件中的Throughput脚本来测试的。在测试中,默认的Throughput脚本会发送一个100k字节的文件从E1到E2,然后等待E2的一个确认应答。从而通过这种方式模拟了在多种应用时的核心文件传输交换的过程。
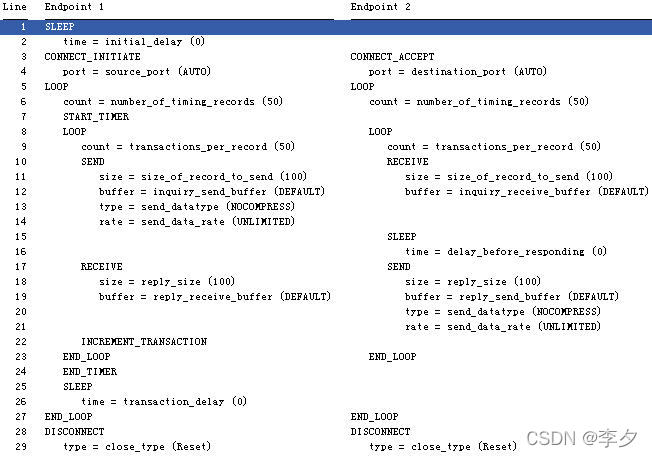
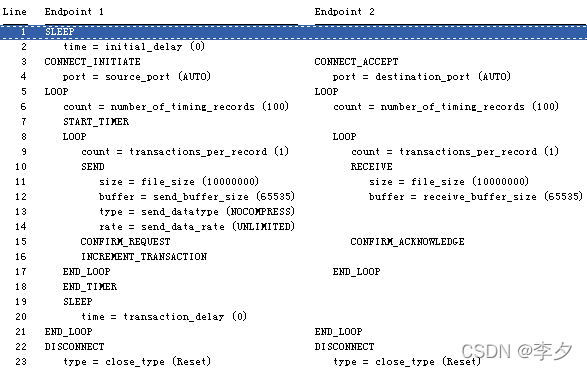
2.1.2 Throughput****脚本内容
Endpoint1 Endpoint2
SLEEP
time=initial_delay(0)
CONNECT_INITIATE CONNECT_ACCEPT
port=source_port (AUTO) port=destination_port(AUTO)
LOOP LOOP
count=number_of_timing_records(100) count=number_of_timing_records(100)
START_TIMER
LOOP LOOP
count=transaction_per_record(1) count=transaction_per_record(1)
SEND RECEIVE
size=file_size(100000) size=file_size(100000)
buffer=send_buffer_size(DEFAULT) buffer=receive_buffer_size(DEFAULT)
type=send_datatype(NOCOMPRESS)
rate=send_data_rate(UNLIMITED)
CONFIRM_REQUEST CONFIRM_ACKNOWLEDGE
INCREMENT_TRANSACTION
END_LOOP END_LOOP
END_TIMER
SLEEP
time=transaction_delay(0)
END_LOOP END_LOOP
DISCONNET DISCONNET
type=close_type(reset) type=close_type(reset)
2.1.3 Throughput****脚本流程图
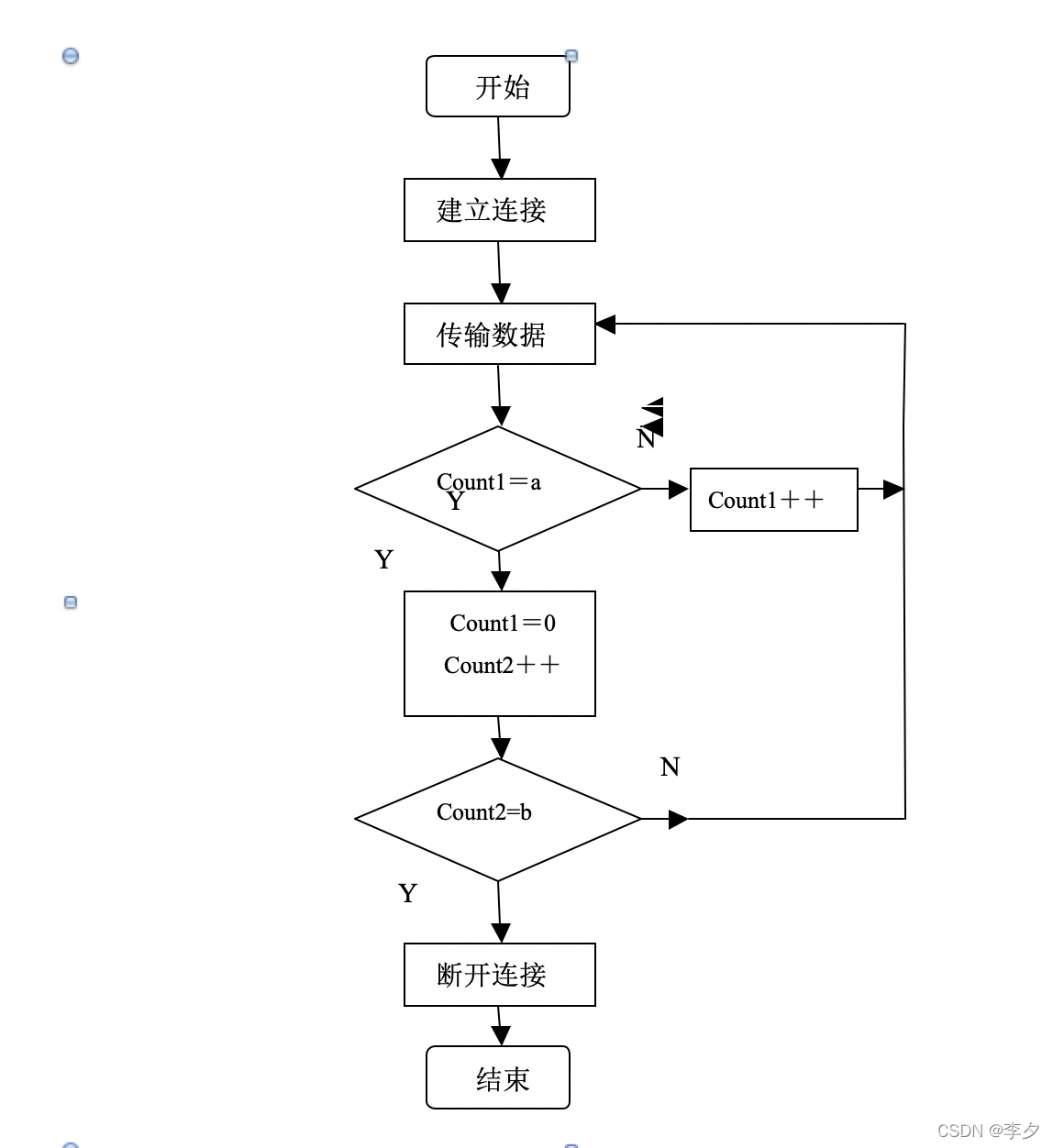
*2.2 脚本变量说明:*
在Throughput脚本中,有两个关键的循环,外部循环和内部循环:外部循环控制定时记录的数量,就是在整个测试过程中测试记录的次数,最终通过这些记录的内容,控制台统计出最后的测试结果。而内部循环控制每次定时记录交换数据的数量,即测试中传送多少数据量时产生一次记录。我们先从内循环讲起,从图中,我们可以看到,在内循环中,一共有5个变量。
2.2.1 Loop (inner)
这个变量控制每一次定时记录的中间发生多少次数据交换。将其值设置为“1”就可以使一次数据交换有一次数据记录。这样可以给出最为粒状分布的结果,可以让你看到每一个响应时间内的测试中的吞吐量变化。然而,这样做也会明显的增大一次测试中的数据记录次数。
将这个数值设置较大可以使你运行测试的过程中产生少一些的数据记录。因为节点返回的数据记录是每一个循环内的数据交换的平均结果。即可以进行多次数据的传送,然后将这些传送的总的数据计算出一个平均值,但是这样就一定程度上掩盖了网络响应的变化情况。
软件中有关这个变量应当如何设置的描述是:“这个变量的最佳值是要使脚本循环有足够的时间可以使一个定时记录1秒钟进行一次。这需要一些反复试验,它决定于网络的速度和数据传输的类型。”从中我们可以根据所要测试的网络的速度,计算出内循环中Transaction per record这一项到底需要设置为多少,当然这和所设置的文件大小也有重要的关系。后面将针对这个问题进行更详细的讨论。
2.2.2. Send data size
发送命令有四个变量:1)发送多少字节的文件,2)每一次发送用多大的缓存,3)发送数据的类型是什么4)发送数据的速率。例如,如果你选择“发送 1000,100,ZEROS,UNLIMITED”一个节点就会发送1000个字节,每次100个字节,数据全都是0,以最快速度。这个发送命令会使10个发送指令访问通信应用编程接口。
在文件传输脚本中,你可以设置模拟被发送文件的大小。要注意的是一个节点是发送这些量的数据,而不是任何文件的输入输出。
2.2.3 Send_buffer_size
一些脚本使用相同的发送大小和缓存大小变量。这样设计可以使数据总是在一帧中传完。
发送和接受缓存可以被设置成默认值。这告诉了节点使用网络协议使用的默认大小来做为缓存的大小。默认值使你使用每种协议默认的缓存大小,而不必去修改脚本来处理与协议的差别。这个默认值取决于使用的不同协议和平台。一个节点在它的环境下使用通用的值。这样这个脚本就能够自动适应多个协议和平台,而不用我们去手动修改。
如果要使节点发送数据包的大小是变化的,软件也提供了相应的设置选项。我们可以使用随机分布:统一分布,一般分布,泊松分布,或指数分布。如果你使用TCP,要使用变化包长度的话你必须将Nagle算法禁用。在选择插入目录中的选项可以禁用Nagle算法。
下图是采用Throughput默认脚本时,将send buffer size改为统一分布,禁用Nagle算法时的抓图,我们可以看到,发送方发送的数据长度是不断的变化的。

2.2.4 Send_date_type
这个变量可以使你控制测试中发送数据的内容。默认值,NOCOMPRESS,是针对大多数网络的压缩算法,发送一个连续的随机生成的数据,即其文件当中的内容都是随机生成的。ZEROS选项是发送所有为0的数据。标准文本文件NEWS.CMP和标准图像文件LENA.CMP在大多数文本数据和图像数据传输的情况下被使用。
ZEROS和NOCOMPRESS是在内部生成的而不需要其它附加的文件。所有的其它的都要求相应的.CMP文件在节点的主机上安装,软件自动在测试连接建立时进行文件的装载。只有标准的数据类型,NEWS.CMP,LENA.CMP,和TRANS.CMP是软件默认安装的。
你可以增加到10个包含任意需要数据的“用户文件”,但是如果需要进行数据的确认的话,它们应该包含相同的数据安装在每一个你要使用的节点的计算机上。剩下的数据文件来自叫“Calgary Text Compression Corpus”的一个标准。
下图中显示了文件采用NOCOMPRESS时,传送数据的内容:

从图中我们可以看出这些数据内容都是随机生成的,没有任何规律。这种数据类型最为适合模拟广泛的数据传输情况。
下图是数据类型为ZERO时,传输的数据内容,可以看出全部都是0。

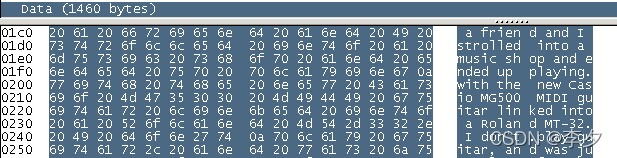
下面这张图是采用软件本身提供的new.cap文件提供的文件类型进行测试的数据内容的抓图。我们可以看到,数据的内容是一些文本的信息。
下图是文件类型为lena.cap文件提供的类型,它主要模拟了图像文件为gif格式的数据的传输

软件中还提供了可以让用户自定义所要传输的文件的类型,通过将所要使用的文件转变为.cap的文件类型,即可在测试中使用。由于软件自带的文件类型以足够满足我们正常测试的需要,所以这里没有就这一点进行更进一步的讨论。
2.2.5 Send_date_rate
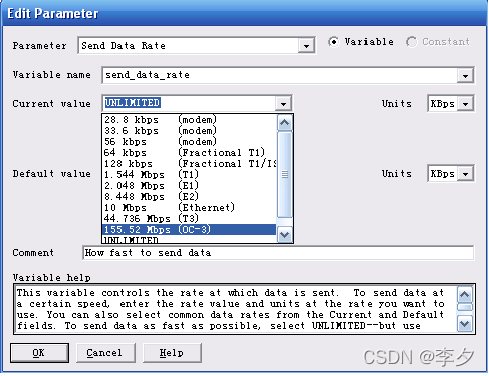
这个变量控制数据发送的速率。要采用定值来发送数据的话,输入一个你想要使用的速度值和单位。你也能够从Current和Default区域选择普通的数据速率。若要以最大速率发送数据,选择UNLIMITED模式,但是使用UNLIMITED时在流量脚本时会有警告,因为它可能在一些网络上有负面的效果。
下图是Send date rate选项可以设置的多种的速度,其中可以模拟各种网络所使用的速度来进行测试。在我们100M/1000M的网络测试中,我们一般情况使用不限速度的模式进行测试。
通过这些变量的设置,我们可以模拟出很多种不同情况下的测试环境。在一个内循环的最后发送端会发送确认请求,接收端会发送确认回复来结束一次Transaction。接下来进行下一次的Transaction。一个Transaction传送一个file size规定大小的文件。当Transaction的次数达到内循环变量count设定的值时,外循环就记录一次Timing record,直到记录的Timing record达到了外循环规定的记录次数则一次测试结束。(在非规定测试时间模式下),当我们规定了测试时间时,外循环这一项所设置的数值就自动被忽略了。
**2.2.6 **外部循环的设置:
一个节点在每次传送一次循环产生的数据量的时候就增加一次定时记录。(我们可以通过调整内循环,在运行一个大数据量脚本时,减少产生的定时记录。)
外循环这个变量在运行“指定时间段模式”时可以被忽略。
如果一个脚本产生了太少的定时记录(少于每个pair 30次),测试的数据就会太少以至于你无法看到在数据交换的响应时间内所产生的变化。如果你做了太多的定时记录(超过10,000每次测试),测试数据会非常的巨大,消耗硬盘空间而且降低了控制台的显示处理速度。
当你运行一项测试时,指定采用批报告结果(不是实时),节点会保留这些结果直到测试结束,或者它运行到了极限。举例,当一个节点得到了500个定时记录,它会将这些记录发回控制台,即使这时测试并没有结束。这点会影响到你的性能测试结果。
Timing record这个变量Chariot软件也有相应的推荐使用值,在软件中是这样描述的“在30到200之间的值通常可以得到最佳的测试结果。”我们后面的优化参数设置方案都会将这些因素考虑进去,再结合理论的计算结果来得出优化的设置。
**2.2.7 **两个时延的说明:
*2.2.7.1 Sleep time (initial delay*)
这个变量让你模拟一个用户时延,或客户端处理过程。在脚本命令第一次执行前,E1在这里指定的几毫秒中是休眠的。这个休眠并不消耗CPU周期,所以它只是仅仅模拟时延,而不是在真实的应用和用户使用时CPU或其它系统软件运行时所需要的时间。
最长的初始时延允许时间是90分钟,即540万毫秒。比此更长的时间会导致E2中止连接,连接断开。
你可以选择每次休眠相同的量(通过选择“定值”),或者休眠一个随机的时间段(通过选择其中一种分布),输入一个定值1000可以使一个节点休眠一秒钟,若是其它四种分布的任意一种,输入一个随机休眠的时间范围。例如,你想休眠2到5秒钟,在lower limit value中输入2000在upper limit value中输入5000即可。
所有的默认设定的测试脚本这一项被设为定值为0的初始时延,也就是说一个节点开始执行脚本时是没有时延的。在我们的测试中时延这一项也总是被设置为0。因为在测试吞吐量的过程中我们并不需要脚本产生时延。
2.2.7.2 Sleep time (transaction_delay)
这个变量可以使你控制传输执行的频繁程度你可以在开始执行更多命令之前设定一个几毫秒的休眠时间。这一般用来模拟用户端在正常的基础上运行的数据传输;例如,1秒钟一次。1000这个值可以使一个节点休眠1秒钟。所有的设定好的测试脚本都将它们的默认延迟设为0。这意味着一个节点以最大的速度执行这个脚本。
如果对这两个休眠时间设置为不为0的话,有可能在成在测试结果当中的曲线中出现曲线突然降到零的情况。
2.2.8 Source port
你可以在建立两个节点的连接时,指定源端口的端口号,或者你可以让它自动分配。将它设置为AUTO就可以让它自动分配。这可以使结果表现达到最佳。清除AUTO,输入端口的号码在1至65535之间,如果你是试着模拟一个特殊的应用。这项功能在测试基于端口号进行通信过滤的设备时是很有用的,例如,防火墙。
当测试多组Pair时,尽量可能选择使用AUTO,如果相同的接口被指定给了多组Pair,性能表现就会降低,因为多组Pair会分用(连续的)接口的使用权来进行测试。
Chariot软件的RTP、TCP和UDP建立连接时的Sockets接口是10115,这是软件固定的端口号。
2.2.9 Disconnection type:
这个变量决定在应用脚本中的TCP DISCONNECT命令是异常中断的还是正常中断。就默认方式来说,Chariot脚本会使用异常中断来结束,使用一个可以立刻关闭连接的RST标志。改变关闭模式为正常模式,需使用FIN标志来较慢的关闭连接,而且要从接收端主机接收确认。如果使用异常中止模式,在接收端的协议栈如果没有接收到RST标志,就不能声明网络源已经被连接停止了,而且停留在一个不确定的FIN_WAIT状态。正常的连接中止方式指定,如果FIN标志丢失,节点仍然停留在TIME_WAIT状态直到栈内休息时间区域释放。这个关闭模式的变量只对TCP有效。
**2.2.10 **对各变量设置的一些思考:
** **从Throughput脚本来看,外循环loop控制测试的文件记录的次数,内循环loop控制每传输几个测试文件记录一次。内、外循环的值的设置并不会直接影响到测试结果。因为这两个变量的设置只是关系到软件记录测试结果的方式,这两个变量对测试结果的影响并不是本质上的。引用Chariot软件中关于外循环最佳值的描述为“在30到200之间的值通常可以得到最佳的测试结果”。有关内循环的最佳值在Chariot软件中是这样描述的“这个变量的最佳值是要使脚本循环有足够的时间可以使一个定时记录1秒钟进行一次。这要求一些“试错”的过程,它决定于网络的速度和数据传输的类型”。从中我们可以看到外循环的设置是有一个大概的最佳值范围的,而内循环最佳值的设定是取决于外部因素的。从有关内循环的描述中我们可以看出在100M网络中若内循环的值为1,即每传输一个设置文件大小的数据就要进行一次记录。这时如果我们把文件大小设置为10M,百兆网络每秒可以传输的数据理论值是100Mbps / 8 =12.5Bps,因为实际网络中传输速率由于各种损耗不会有那么高,所以我们为了取整数,将值设为10个1M的pair,这样就基本接近于每秒记录一次的最佳状态了,其实有关这个值的设置是否合理,我们也可以通过观察Response Time这一选项来看是否合适,因为Response Time=Measured_Time / Transaction_Count,若Response Time的值越接近1,证明这个值越合理。这些变量的设置都是根据Chariot软件的帮助文档中的说明简单推算得来的,通过这些信息我们可以对测试时间的设置、Pair数量的设置得到一些启发,但是真正关键的、对测试结果影响最大的参数还是文件大小和缓存大小的设置,这一点将在后面章节中继续讨论。
**2.3 **常用的脚本结构形式
根据对比Chariot软件的常用脚本,High Performance Throughput脚本和Throughput脚本还有Response-time脚本可以发现,这些脚本的基本形式都是采用如Throughput脚本的内外循环的结构来发送数据,通过对所发数据文件的大小不同,和发送的参数大小不同对所要测试的重点进行不同的参数大小的配置。在Response-time脚本中发送数据的Transaction变为E1和E2互相传送数据,在High Performance Throughput脚本中,则针对传输速率较高的网络,对文件大小进行了修正等等,但是基本的结构依然是通过两个循环的模式来进行的。

High Performance Throughput脚本
我们可以看到在High Performance Throughput脚本中与Throughput脚本的区别有两点:
1、file size从100K增大为10M。
2、发送缓存和接收缓存将原来的Default设置更改为65535Bytes。
High Performance Throughput脚本是Chariot软件专门针对高性能网络测试所制定的脚本,主要针对100M/1000M网络,我们可以发现这个脚本单从结构上来看,和Throughput脚本十分接近。我们甚至可以修改Throughput脚本的两个简单的参数,从而使其成为High Performance Throughput脚本,但是实际中的情况是否是这样的,这个问题将在后面的章节中讨论。
Response-time脚本
- 协议的通信过程分析及优化值计算
3.1 CHARIOT测试中的TCP和UDP**协议运行过程分析:**
网卡CHARIOT测试中主要选用TCP和UDP两种协议,分别进行Throughput的测试。这两种协议各自传输过程的基本原理又有各自的区别。只有清楚了每种协议的通信过程,才能对脚本中不同的变量有更本质的了解,从而进行更优化的设置。
我主要通过使用抓包工具Ethereal对Chariot测试过程中TCP和UDP协议的运行进行了分析。以下所有的截图都是在采用Chariot软件的Throughput脚本测试时,只改变文件大小的情况下进行的。其它参数均是该脚本的默认值设置。其中所使用到的软件的版本分别为:
NetiQ.Chariot.v4.3.1212.for.Windows
Chariot.Endpoint.4.5.for.Windows
Ethereal Version 0.10.9
- Throughput测试中TCP****协议的运行过程:
通过大量的测试和分析,我发现多个Pair和单个Pair在TCP协议运行的过程中原理基本是相同的,只是多个Pair采用了较多的端口来进行文件的传输,而且其中每个Pair的传输过程都是相同的。由于采用多个Pair进行传输时的抓图数据非常多,数据量很大,并不方便将整个过程进行展示,所以在这里就只针对单个Pair的情况进行说明。
**3.1.1.1 **建立连接过程说明
首先,就连接的建立举例如下,下图是连接建立过程的抓包展示:
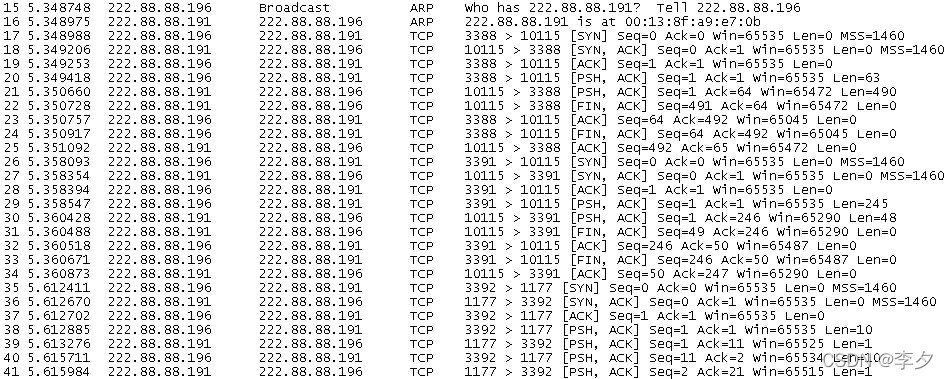
下图是上图的局部放大:
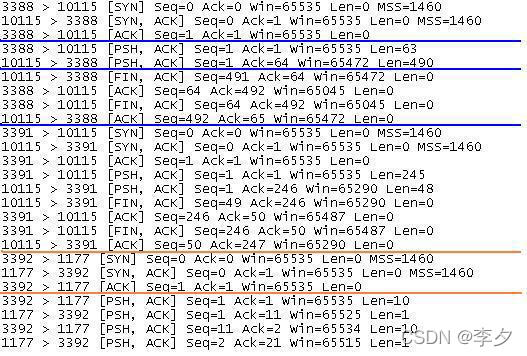
开始的三行是TCP连接建立的三步握手规则(标有蓝色下划线的九行)。
第一步:主机1向主机2发送一个SYN段指明主机1想连接主机2的端口号,以及初始的序号(在图中所示的是相对的序号)。
第二步:主机2发回包含它的主机的初始序列号(在这里是相对序列号)的SYN报文段作为应答。同时主机2将确认序列号设置为主机1的SEQ加1以对主机1的SYN报文段进行确认。一个SYN将占用一个序号。
第三步:主机1必须将确认序号设置为主机2的SEQ加1以对主机2的SYN报文段进行确认。
这样主机1就与主机2之间建立了连接。
接下来,Chariot软件会进行两台主机之间数据的互传。互传的信息内容是有关Chariot软件的一些信息。这两步的目的是用来验证连接是否可靠。
完成简单的数据互传后,连接就按照4步断开的步骤断开连接。具体过程如下:
第一步:主机2向主机1发送一个FIN。
第二步:主机1收到这个FIN后,发回一个ACK,确认序号为收到的序号加1。和SYN一样,一个FIN将占用一个序号。
第三步:同时主机1向主机2发送一个文件结束符(FIN)。
第四步:主机2收到后回复一个确认,并将确认的序号设置为收到的序号加1。
这样4步的连接中止就完成了。
Chariot软件会进行两次这样的连接――传输--断开的过程,第三次正式建立连接来发送数据。
Chariot软件的RTP、TCP和UDP建立连接时的Sockets接口号是10115,这是固定的。
- ** File Size**影响说明
首先,在Chariot软件Throughput脚本的设置中,文件大小的不同,在传输的过程中的区别是比较明显的,我将以文件大小为1460B和32767B为两个分界点来进行说明,因为取值在这两个数值两边的文件大小在传输过程中将有不同。
文件大小为1000B(小于1460B)时:

在上图中,我们可以清晰的看到,数据的传送是这样的。发送端向接收端发送1000Bytes的数据,接收端接收后向发送端发送数据长度为1的确认。Data的数据内容是0x00。然后这样一直重复下去,直到按照软件设置的结束条件结束数据的传输。
文件大小为1460Bytes时:

这种情况和1000Bytes时的情况相同。举它为例是因为这个值是临界点,这样可以使我们看得更明白。
文件大小为7300Bytes(1460的5倍)时:

从这张图中我们可以看到,文件的传输并不是简单的一次发送、一次接收就可以完成的。因为当文件的大小超过1460Bytes时,一个数据段已经无法将一个文件大小的数据装下,必须分成多个数据段进行发送。(1460Bytes=1500Bytes-20Bytes-20Bytes)1500Bytes为以太网的IP数据报最大长度。两个20Bytes分别为IP首部和TCP首部长度。
从上图中我们可以看出,发送数据时,只有最后完整发完文件大小的那个数据段带有PSH标志,其它的没有这个标志。而接收数据的数据段时也是这样的,只有最后接收完整数据段的那一个确认才会有PSH标志。PSH标志的意义是接收方应尽快将这个报文段交给应用层。
而且从这里可以看出,在接收文件发送确认时,一次最多可以接收确认两个数据段的内容,即传输最大为2920B的数据就需要进行确认。
文件大小为32767B时:
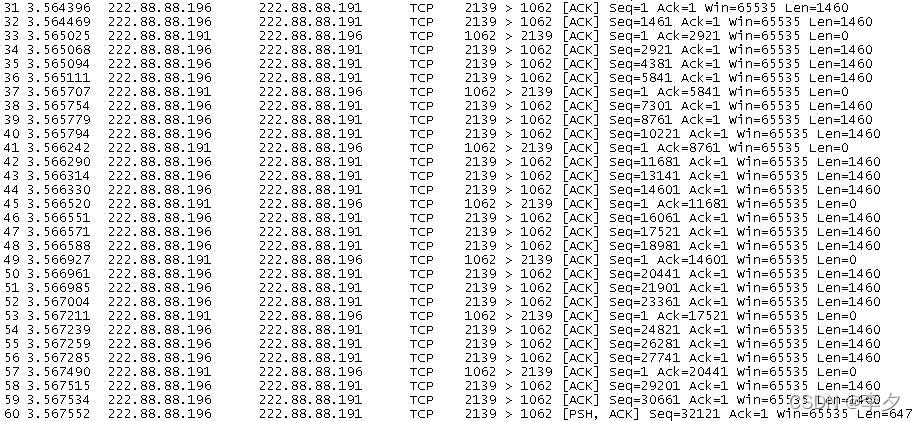
我们可以看到,传输的规律与7300Bytes时基本相同。上图是完整传输一个32767B数据的过程截图,后面的数据段传输情况和这张图上所显示的相同。但是这个值,其实是一个临界点,文件大小超过这个值后,传输过程又将会有不同。
文件大小为32769Bytes(比32767B大2Bytes)时:
这是我抓下来的整个数据传输开始的第一个传输的数据段的情况,这和前面的规律也相同。
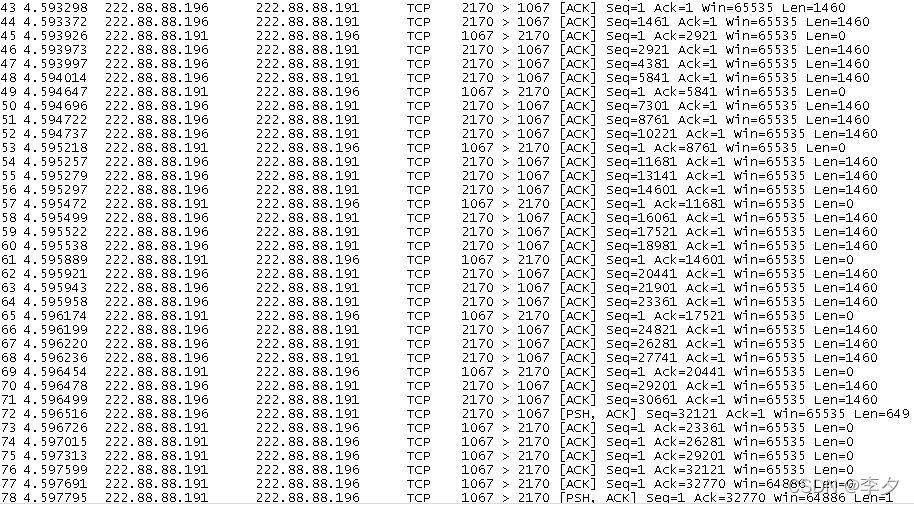
接下来我抓的这一张图,和上面的图都是同一组数据传输的过程,只不过下面的这张图是整个过程中后面数据传输的情况。
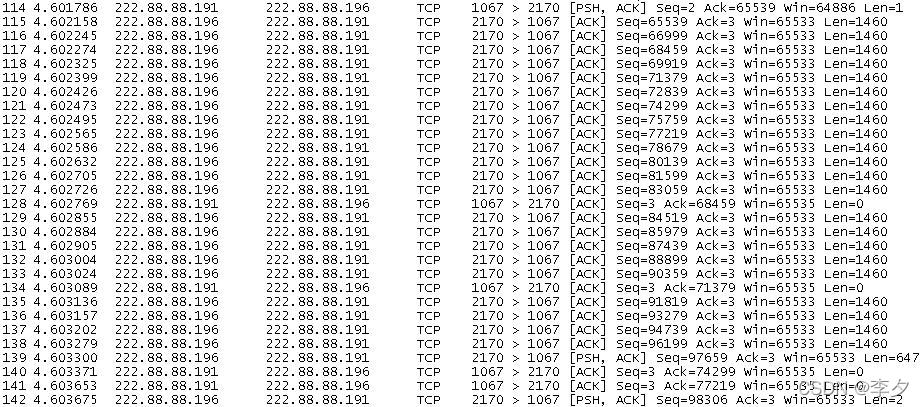
我们会发现,原来应该传大小为649Bytes的那一个数据段只传了647Bytes,剩下的那两个字节的数据是分给下一个数据段进行传输的。这就是为什么我选择32767Bytes作为特殊的文件大小来进行区分的原因了。Chariot软件在这个值时会自动将文件分开,大于这个值的文件将再分开进行传输。为什么上上一个图中就没有这种情况呢?这点现在也不好解释,因为经过我的观察大于32767Bytes的文件在传输时的前两个包一般都可以以超过32767Bytes的方式传输,剩下的所有的包,都将以32767Bytes为界限,分开进行传输。
文件大小为100k(这是软件默认的文件大小)时:
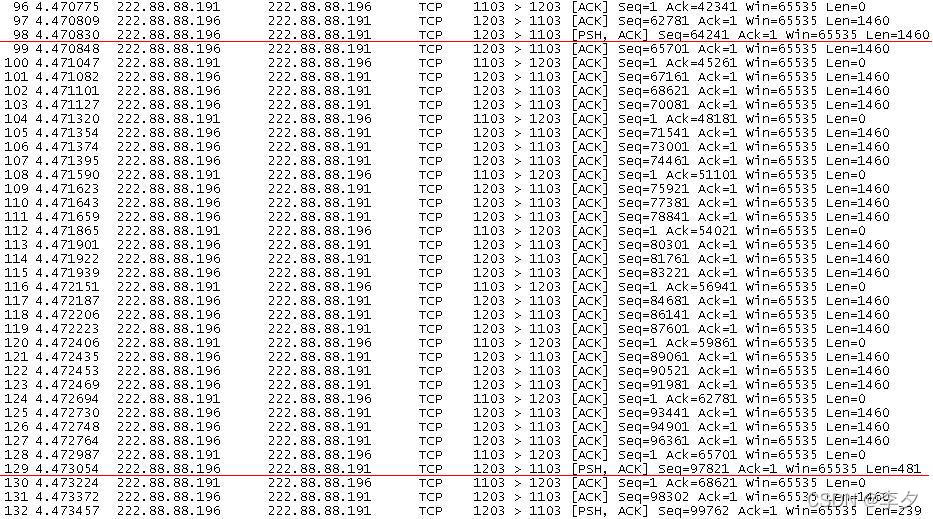
这张图展示了100k的数据段是如何被分割开来传输的过程。在传送数据为481Bytes的那个数据段之前一共有67个数据段传送了数据为1460Bytes的数据,即1460×67=97820。97820Bytes的数据已经传送完毕,由于这个截图是在数据传输开始截得的,所以前两次在32767Bytes倍数分界点时传输的都是1460Bytes的倍数,所以才能够传输67个,接下来第三个32767Bytes的倍数98301Bytes时,发送端就要发送一个PSH标志了,所以97820+481=32767×3=98301Bytes,在传完100,000Bytes数据时,按规则还会发一个PSH标志,所以98301+1460+239=100,000。这样第一个100,000Bytes的数据段就传输完毕了。接下来的传输就是对上述过程的重复,只是在传输前两个32767B数据时进行文件的分割。经过试验发现,采用Chariot软件的Throughput脚本可设置的最大文件100,000,000Bytes传输时,传输的规则也是相同的。
**3.1.1.3 **文件传输结束说明

上图为TCP文件大小为32769B时,1个pair结束时的数据传输过程。我们会发现这个连接的中止是通过发送一个复位报文段(而不是FIN)来中途释放一个连接。这称为异常中止,Chariot软件的脚本中默认采用这样的方式来结束连接,也可以通过在脚本文件中修改这种结束方式。同样,这种连接的断开方式仍然与Pair数目的多少没有关系,即Pair数目较多时,每个Pair都是采用这种方式结束连接的。
3.1.2 Throughput测试中UDP****协议的运行过程:
在对UDP协议进行测试时,多个Pair和单个Pair在运行的过程中与TCP协议的情况是相同的,只是多个Pair采用了较多的端口来进行文件的传输,而且其中每个Pair的传输过程都是相同的。所以在这里就只针对单个Pair的情况进行说明。
由此可以看出Chariot软件中有关Pair数目的设置,在实际测试中主要是从数学统计中平均值的角度去考虑,因为如果取多组Pair进行测试,最后取这些Pair的平均值,这样做就会降低由于使用单个Pair进行测试时,数据产生的波动给测试结果带来的不准确性。而通信过程本身与Pair数目的多少只是在传输建立时,如果测试的Pair数量非常的巨大,对测试用机的配置要求就会很高。所以在实际测试中Pair的设置要根据实际测试的需要进行相应的调整,需要根据实际情况,在数量的多与少之间找到一个平衡的值。
**3.1.2.1 **连接建立过程说明
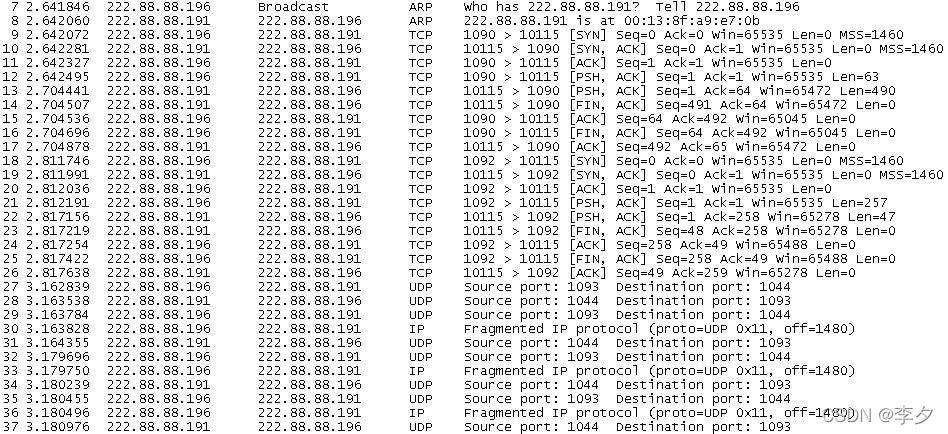
上图是文件大小为1472B的一个Pair时的UDP连接建立时的情况。我们从图中可以看出UDP建立开始时,它使用TCP协议来建立一个连接,然后进行文件的传输。根据理论计算,可以得出UDP传输时最长的数据报大小应该是1500-20-8=1472Bytes。1500Bytes为以太网的IP数据报最大长度,20Bytes为IP首部长度,8Bytes为UDP首部长度。
所以就以1472为报文大小的分界点。来对传输过程进行说明。
3.1.2.2 File Size****影响说明:
文件大小为1400Bytes(小于1472Bytes)时:
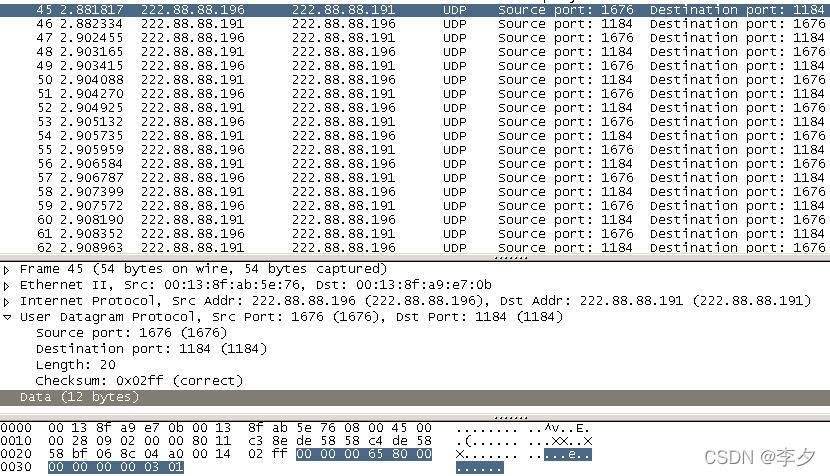
从上图中我们可以看出主机1向主机2发送的第一个数据报并不是我们要传输的数据。这个数据报的数据部分是12Bytes的一个数据,这个数据通过下面的分析,可以看出它是一个用于计数的数据。
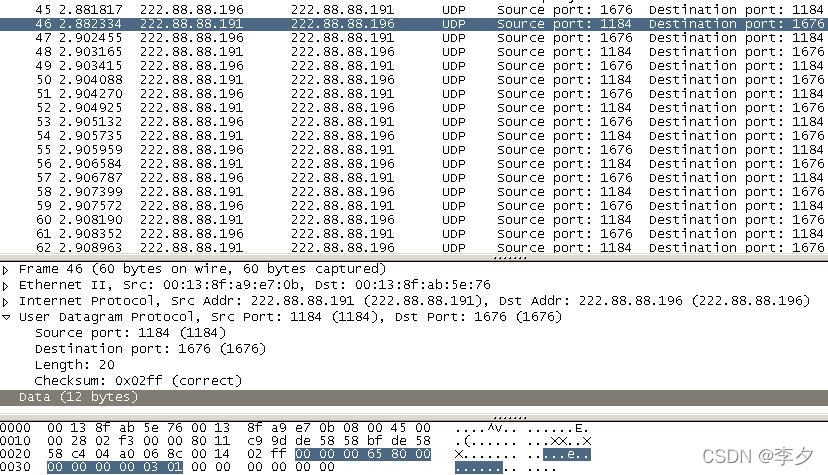
第二个数据段,同样也是主机2向主机1发送的一个12Bytes用于计数和确认的数据段。
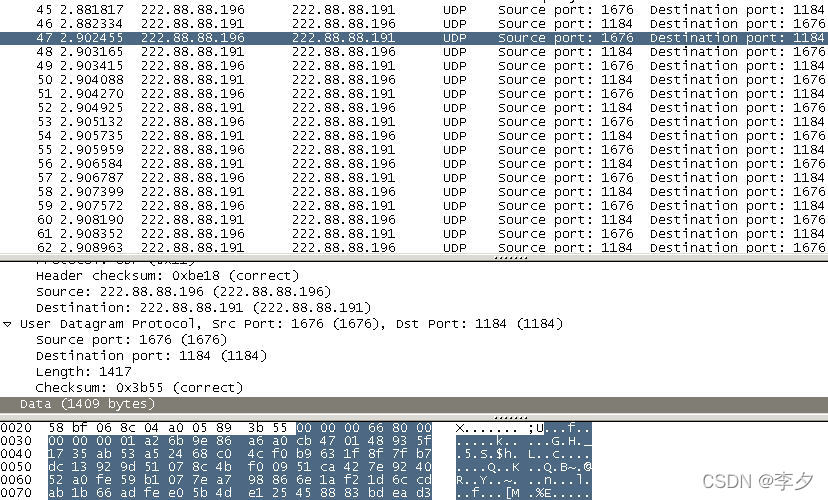
上图中的第三个数据报才是真正传输数据的数据报,但是设定的传输数据是1400Bytes而数据报部分却又1409bytes,经过观察发现这多出的9bytes的数据依然是一个用于计数的数据。
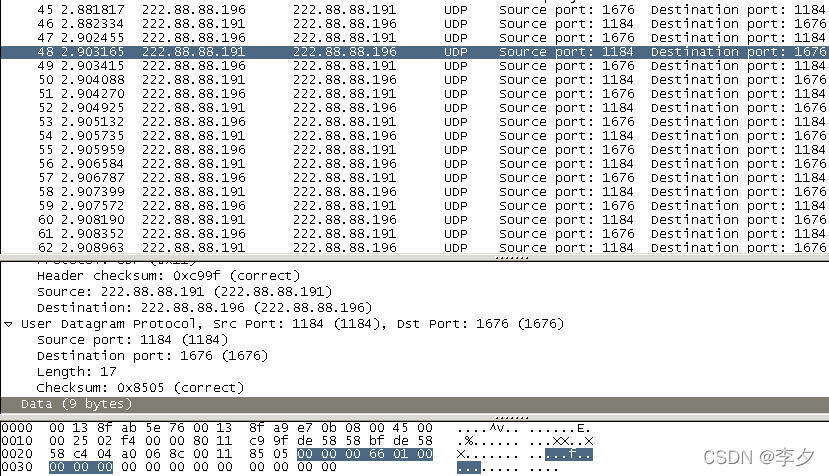
这是数据传输的最后一步,主机2在向主机1发送了一个包含有9bytes计数确认数据的数据报。这样四步,一个小于1472bytes的数据就发送完成了,接下来就是重复这两步的过程,直到数据发送结束。
文件大小为1472bytes时:
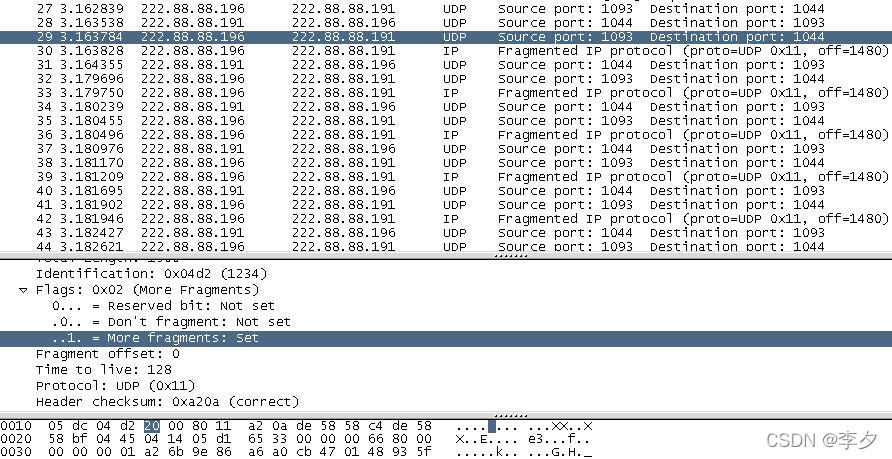
从上图中我们可以看出,发送数据的前面两步与文件大小为1400bytes时相同。原本可以传输1472bytes数据的数据报由于要传输9bytes的计数数据,所以1472bytes的数据本身就要进行分片,通过上面的截图我们可以清晰的看到more fragment位被置为了1。
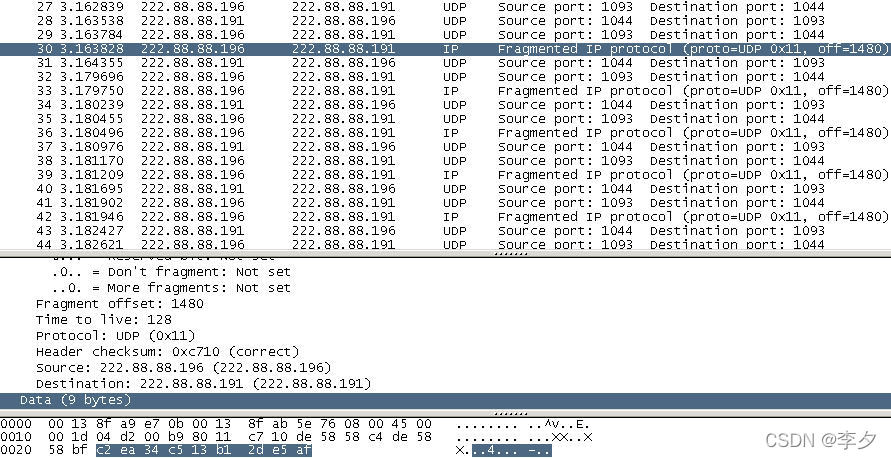
通过上图我们可以看到这一个数据报最大可以传输1480的数据,因为它除去了8bytes的UDP头部。图中这一数据报传送了上一数据报没有传送完的9bytes数据。下一数据报仍然为主机2向主机1传送9bytes的确认计数数据。这样一个1472Bytes的数据就传输完了。经过我的测试发现,与TCP相同,UDP在文件数据增大后传输过程仍然会有一定的变化,经过测试得出这个数据的分界点是8183bytes。为了更好的说明问题,我以8184bytes为例进行说明。
文件大小为8184Bytes时:
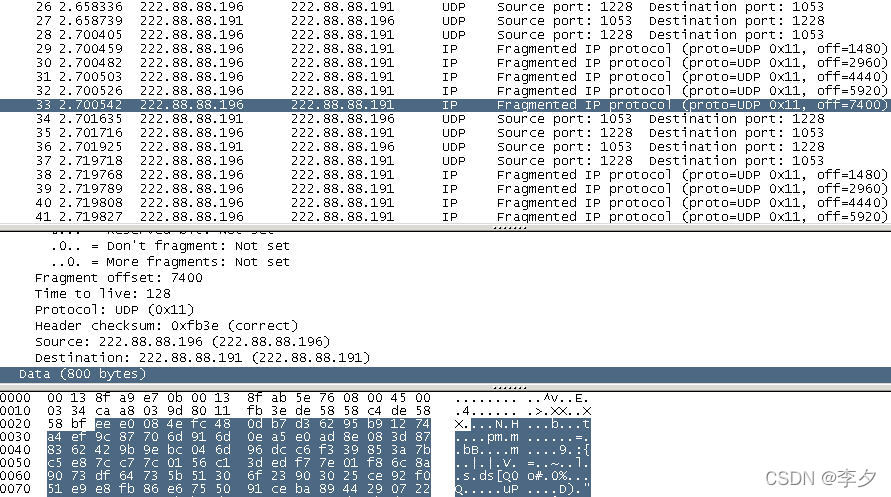
我们可以发现,蓝色区域的这一数据报只发送了800bytes的数据就结束了,但是经过计算,发送8184bytes的数据时这一数据报应该发送大小为801bytes的数据,而它只发送了800bytes的数据就结束了。其中的原因可以通过下面的截图解释。
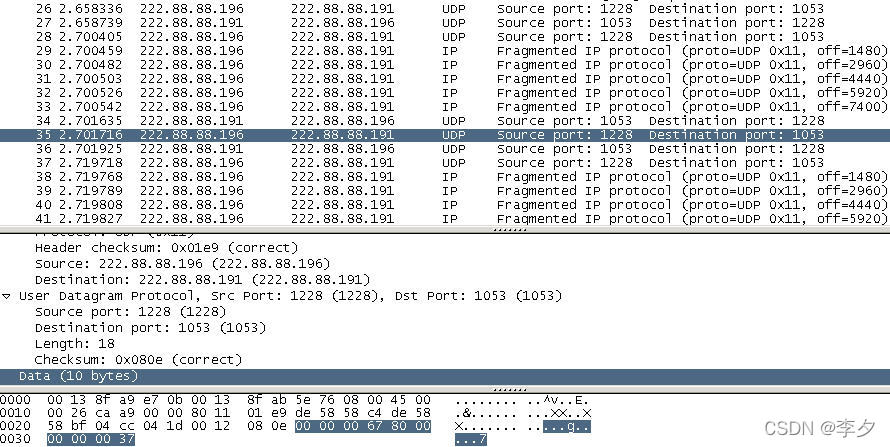
从上面的截图可以看出没有传完的1bytes数据在接下来的数据报中进行了传送,并且数据部分仍然包含了9bytes的确认计数部分。
所以通过上面传输文件大小为8184Bytes的过程可以看出,在UDP传输的过程中,Chariot软件在文件大小为8183Bytes时对文件进行了分割。这个规律与TCP传输时基本相同。
3.1.2.3 文件传输结束说明:
由于UDP协议本身是面向无连接的,所以通过抓包我发现它并没有像TCP协议那样终止连接的过程,而是就直接停止了数据的发送。
**3.2 **脚本优化设置的计算和讨论
前面对Throughput脚本的变量的意义和不同协议的具体通信过程分别进行了讨论。通过前面的总结,可以从一些思路中探求优化变量设置的方案。通过计算,对Throughput脚本调整相应的变量参数,对不同变量值的实际验证,求证最佳的变量设置,从而最终得到最优的变量配置方案。
3.2.1 Throughput****的计算:
Throughput的计算公式:
(Bytes_Sent + Bytes_Received_By_Endpoint_1) / (Throughput_Units) / Measured_Time
Bytes_Sent—一组pair 中E1发送的数据的数量
从上面公式中可以看到E1发送和接收的数据对Throughput的影响是最直接的。单位和测量时间都是一定的情况下,使E1发送和接收的数据最多,就可以得到最大的Throughput值。
通过抓包分析我们可以看到,使用Chariot软件进行数据传输时,公式中所指的E1发送和接收的数据是每一个数据报中所携带的data部分,并不包含发送这个数据报的帧头的开销。而只有data部分对我们来说才是有效的数据部分,才是用于Throughput计算的数据。所以如果使每一个数据报中的有效部分最大,就可以在发送数据速率相同的条件下,得到最大的Throughput。
通过第一阶段对Chariot软件的通信过程的抓包分析,我们可以看出TCP和UDP在这一过程中的具体细节是不相同的。所以接下来针对TCP和UDP两个协议,分别进行说明。
在TCP和UDP传输建立时,两种协议Chariot软件都要求使用TCP来进行连接的建立,每一个pair就会建立一组连接进行通信。在整个数据传输的过程中,这个连接只进行一次建立,如果测试时间在一个合理的范围的话,建立连接所产生的数据不会对整个测试结果有大的影响,所以这部分的数据传输就不必进行分析计算了。
在Chariot软件中我们可以设置每次传输文件的大小,我们可以通过合理的设置这个文件的大小,使发送的有效数据部分增大。下面的计算也主要是通过这个思路来进行的。
3.2.2 TCP****优化值计算:
在使用TCP连接时,当传输文件小于1460bytes时,文件每发送1帧,需要在有效数据中增加54bytes的没有被算作有效data的数据,接收端就会发送回一个确认,而确认帧本身需要发送60bytes而其中的有效数据只有1byte,这样传输的效率就非常的低。所以当文件为1460bytes时,总的1帧的数据量就是1460+54=1514,只有这时的数据有效率才是最大,所以我们只要使文件大小尽量是1460的整数倍,而且越大越好,因为回复确认帧是最多每两个发送数据帧就会有一个回复确认帧。但是经过对数据抓包发现,在数据为32767bytes时,软件会自动的对发送的数据进行分割,32767=22×1460+647,所以发送647bytes的那一帧的有效率为647/(647+54)=647/701≈92.30%。相对1460/1514=96.43%来说,是下降了。所以应该去除发送647bytes数据这一帧。所以文件大小应该设置为1460×22=32120bytes,但是我们发现,在使用这个文件大小时,节点会多接收一个确认,所以最佳的数值应当是1460×21=30660bytes。
文件大小为32120bytes时:
(1460×22+0×11+1)/(1514×22+60×11+60)≈94.40%
文件大小为30660bytes时:
(1460×21+10×0+1)/(1514×21+60×11)≈94.48%
所以30660的效率更高。
3.2.3 UDP****优化值计算:
在进行UDP模式传输时,建立数据传输连接的部分基本相同,而且由于这部分传输的数据量有限,基本不会影响的传输的结果,所以只分析传输设定文件大小的部分的传输过程。当文件大小较小时,由于UDP会发送60bytes大小的数据报进行确认,其中只有9bytes被用于Throughput的计算,所以效率较低。而且UDP不像TCP那样最多每传输两个1460bytes大小的数据就会进行一次确认,UDP是将文件大小的数据全部传输结束才会进行确认,按这样来推断,相对来说数据较大时效率高一些。但是在实际中,传输的文件如果大于8183bytes,文件大小会在8183bytes处被强行的分开,这与TCP模式有些类似。
文件大小为8183bytes时,传输的效率为:
(1472+1480×4+800+9)/(1514+1514×4+834+60)≈ 96.89%
但是在传输最后一帧时的效率为:
800/834 ≈ 95.92%,相对1480/1514=97.75%,是降低了,所以最佳值应当是
8183-800=7383bytes
当传输文件大小为7383bytes时的效率为:
(1472+1480×4+9)/(1514+1514×4+60)≈ 97.00%
*3.3 脚本中buffer size*值的设置
Throughput脚本中的buffer size设置这一项,脚本本身采用了default值来进行设置,但是具体default值是什么,为什么要这样设置。前面有关脚本变量意义的研究并没有详细就这一问题进行解答。因为要说明这个问题,必须从本章中的内容找到答案。当采用TCP协议进行测试时,如果将脚本中的default值进行修改,单从测试结果的数据上我们很难看出到底发生了什么,无法从测试结果的大小变化上直接的得到与buffer size的关系,所以我依然采用了抓包的方式来对这一问题进行研究。
进行TCP协议测试,将Send buffer size修改为100Bytes。Receive buffer size保持不变。其它测试参数均采用脚本默认值设置。

测试过程中,抓包如下:
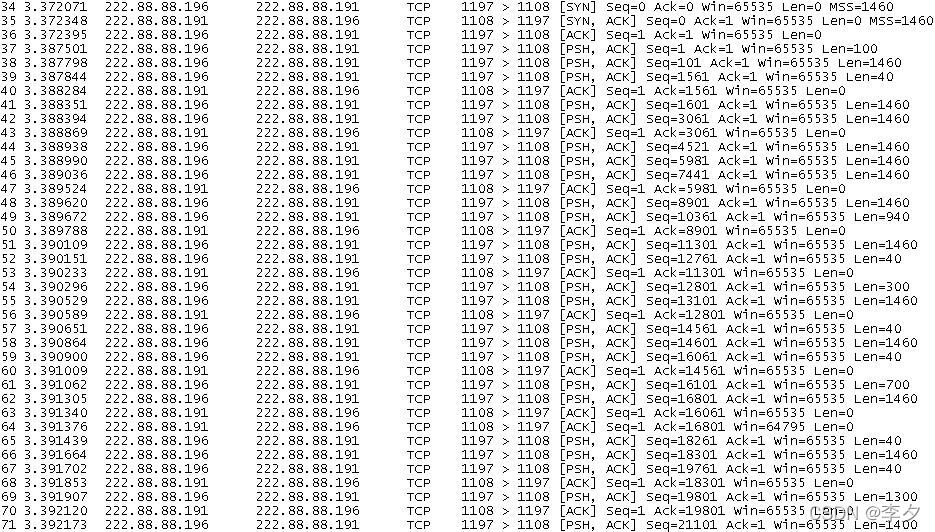
我们可以看到整个数据包的传输显得比较混乱,几乎没有什么规律可寻,但是经过仔细分析,我们还是可以看到所有的发送方的数据包都是在100Bytes的整数倍分开或者在1460Bytes的整数倍处分开进行传输。但是具体到底是应该在这两者中的那个值分开传输,这其中似乎又没有一个准确的规律。这一点与前面总结出的在32767Bytes的整数倍分开有些相似。但是在这里文件并不是完全按照100Bytes大小分开传输。
经过进一步测试,我发现如果将send buffer size的值设置的大于1460bytes时,文件传输时分开的规律就比较明显了。它会在设定的缓存大小处分开传输。下图是throughput脚本,只改变send buffer size为2000Bytes,其它教本参数均为默认值的情况下进行的截图。

我将send buffer size的值设置为32767Bytes,将传输文件的大小设置为32767Bytes,这时进行抓包的结果如下所示:
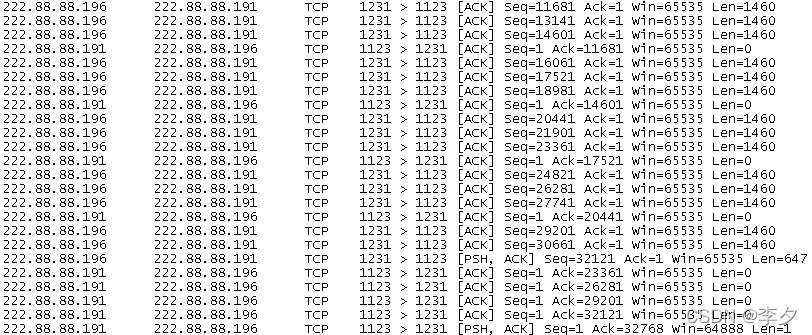
我发现这时的规律与只设置文件大小为32767B时相同,那么脚本默认的default值是否就是32767B,通过下面的设置即可验证,我将文件大小仍然设置为32767B,而send buffer size设置为32766B,这时运行过程抓图如下:
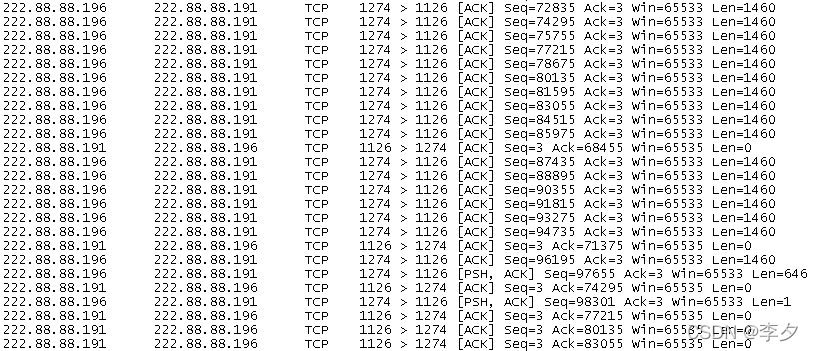
这时我发现与我设想的结果相同,果然在32766B处,文件被分开传输了,那么现在就明白了为什么设为default值时文件会进行分开传输,因为这时软件的默认值其实就是32767B。
同样UDP也是这样的情况,经过测试发现,结论是一样的。在使用UDP传输时,软件的默认值为8183B。在上面的对Buffer size的设置中,没有列举将receive buffer size改变后的情况。实际情况是这样的,当改变receive buffer size的大小后,文件并不会在所设定大小的位置分开接收或者发送。在receive buffer size小于send buffer size时,接收数据方会不时的向发送数据一方发送一个表明tcp 窗口更新的信息的数据帧,这些信息的传输需要占用60Bytes,而且其中并不包含任何有效的用于计算Throughput的数据,所以这会明显的降低我们需要测试的吞吐量,由于我们研究的目的是得到最佳配置的参数,有关tcp窗口的内容在Chariot软件中无法对其进行直接的设置,所以为了避免产生tcp窗口更新的信息,在进行设置时一般将两个buffer size 的数值设置为相等的数值。虽然在软件自带的帮助文档中对default这个值的设置没有进行明确的说明,只是告诉我们这个默认值会根据协议的不同而改变,但是具体数值是多少并没有提供给我们。为了验证这一点,我在Ixia公司的官方网站上找到了相应的依据,截图如下:
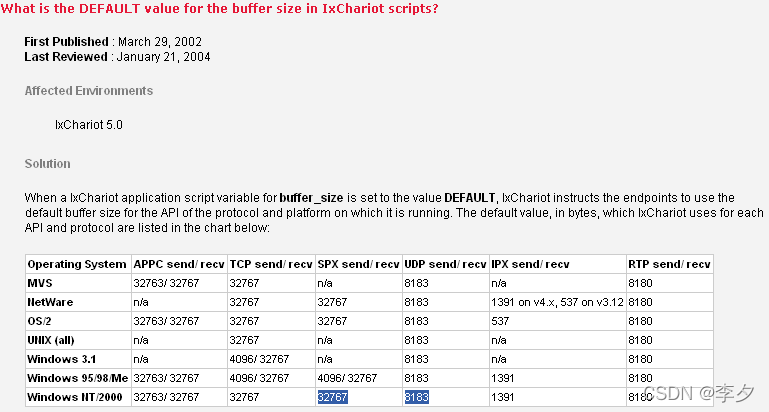
脚本中可以设置的最大的buffer size,如上图所示TCP为65535B,UDP为8183B。UDP使用的默认值已经是它的最大的可设置的buffer size,而TCP的默认的buffer size只是最大值的一半,在这里就可以看出,我们完全可以通过调整TCP协议测试中的buffer size来进行更优化的设置,来测得更高的Throughput。这个问题将在下一节中介绍。
3.4 High Performance Throughput和Throughput****脚本深入对比
在Chariot软件中还有一个脚本是用来测试Throughput的,那就是High Performance Throughput脚本,这个脚本是用来测试100M/1000M高性能网络的,但是实际中我们大多数情况下并没有使用这个脚本,这种做法其实是不正确的。下面是High Performance Throughput脚本的截图。
从图中我们可以看出这个脚本与Throughput脚本只有两点不一样:1、文件大小不同。2、buffer size大小不同。在这里send和receive的buffer size都设置为65535B。请注意,这就是这个脚本只能针对TCP使用的原因,因为UDP的buffer size无法设置这么高。这些是由操作系统,协议本身等原因造成的。在使用High Performance Throughput测试时,运行过程抓图如下:
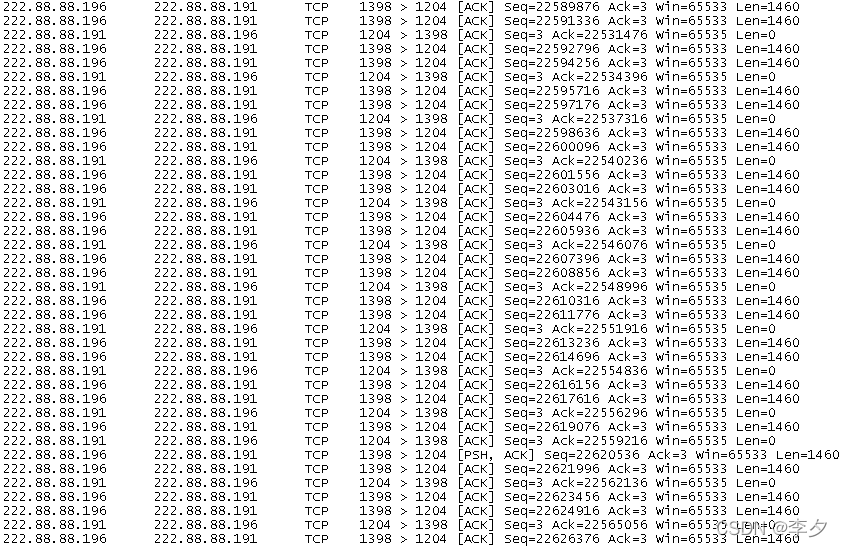
我们看到在这个脚本中,传输数据并没有受到所设置的buffer size――65535Bytes的影响,所有传输的数据段都是以能传输的最大有效数据1460B进行传输的。这一点很奇怪,于是,我又试验使用Throughput脚本,将二者的参数设置设成完全一样,进行了传输过程的抓图如下:
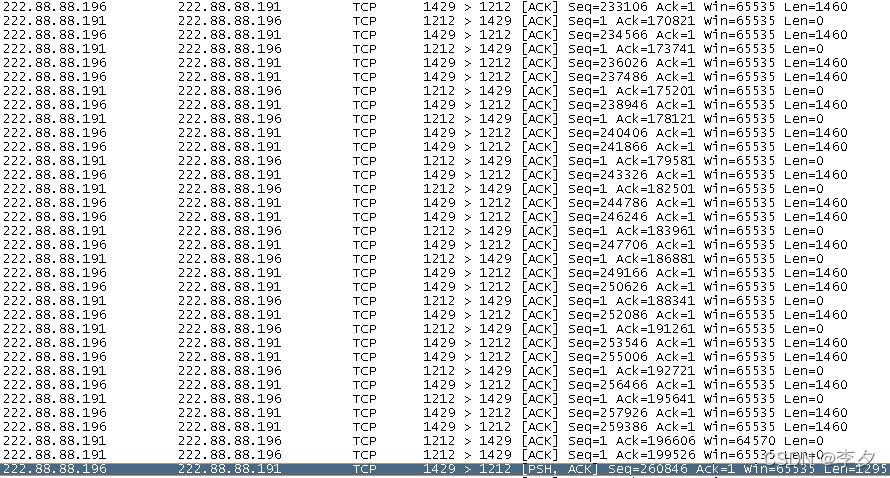
我们可以看出,两个脚本在已经设置完全相同的参数下,真正的通信过程依然是有差别的。上图中的最后一帧是按照65535B进行了分开传输。图中只是截取了整个传输过程中的一小部分,后面的传输中还有一些数据帧存在一些TCP 窗口方面的变化,但是这个情况并不影响我们问题的重点,那就是:这两种脚本即使设置了完全相同的参数,仍然是High Performance Throughput脚本的效率最高。而且High Performance Throughput脚本已经达到了测试Throughput值时可以达到的最优化设置。因为它的文件传输效率已经是理论计算的极限了。我们都知道Chariot是靠不同的脚本来对不同的项目进行测试的,那么当两个脚本设置的完全一样时为什么会出现传输过程不一样的结果呢,这个问题还需要从两个脚本本身的区别来分析,两个脚本除了buffer size和file size设置的不相同外,还有一个重要的区别,那就是High Performance Throughput脚本采用了Microsoft's Overlapped IO socket operation(微软公司的交叠IO接口控制)技术,而普通的Throughput脚本并没有使用。这一点在Ixia公司的网站上也有相关的描述。截图如下:

这就是造成了两者传输效率在设置参数相同的情况下,测试结果High Performance Throughput脚本仍然要高出Throughput脚本一些的原因。当然有关Microsoft's Overlapped IO socket operation的具体内容,在这里就没有进一步深入了解,但是这应当就是使每一帧都能够传输1460Bytes数据的原因。
4.3****总结:
以上结论可以使我们在测试时,所测得结果的准确性达到比较理想的目的,但是在实际的应用中我们可以根据具体条件来选择不同的方案。在误差范围可以控制或忽略的情况下,其它测试方案也都可以在一定的情况下得到理想的测试结果。提出优化方案的最终目标是使我们在今后的测试工作中,尽量避免因为软件设置等外界因素给测试结果带来的影响,使我们能更加客观的得到更真实的测试数据,从而提高我们的测试质量。Chariot软件中提供测试的脚本非常多,功能十分强大,要想将这些应用真正熟练的掌握绝对不是短期内可以实现的。经过前面几周对Chariot软件的学习,深深的感觉到需要进一步深入的内容还有很多,这些都是在今后的工作中都是应该进一步去探求的方向。
版权归原作者 李夕 所有, 如有侵权,请联系我们删除。