
前言
众所周知要玩转SQL查询光靠那个几个查询关键字是远远不够的,SQL作为数据库的存在,往往存在多个物理表或者映射,有时候存在内容吃紧的情况,或者是查询结果表存在多个指标。这需要我们进行单表操作,实现统计不同的指标或者不同条件查询结果进行计算。要进行指标提取或者是创建新指标,推荐是使用自连接的方法可以快速从原始表根据相关指标,如:时间、主键等相关联相同数值的特征连接。下面不再废话让我们一步一步实现。
一、基础前提
首先我们需要了解,任何的编程语言都有一定的共性。但是SQL语言的话,对我们开发者经常使用的Python和JAVA而言属实操作僵硬,不像Pandas的DataFrame数据类型那样操作灵活。让我们感觉写SQL语言并没有那种如鱼得水的畅快感,这是有原因的:SQL 是一种声明式语言。
从我们开始学编程基本都是学的C语言这种强面向过程结构化语言,逐条执行,按条件查询检索后再执行这样的思维。而对于SQL语言来讲,它的执行顺序并没有我们想的过程一步一条执行。
SQL语句的执行顺序跟其语句的语法顺序是不一样的。
SQL执行顺序:
(1)FROM
<表名> # 选取表,将多个表数据通过笛卡尔积变成一个表。
(2)ON
<筛选条件> # 对笛卡尔积的虚表进行筛选
(3)JOIN <join, left join, right join…>
<join表> # 指定join,用于添加数据到on之后的虚表中,例如left join会将左表的剩余数据添加到虚表中
(4)WHERE
<where条件> # 对上述虚表进行筛选
(5)GROUP BY
<分组条件> # 分组
(6)<SUM()等聚合函数> # 用于having子句进行判断,在书写上这类聚合函数是写在having判断里面的
(7)HAVING
<分组筛选> # 对分组后的结果进行聚合筛选
(8)SELECT
<返回数据列表> # 返回的单列必须在group by子句中,聚合函数除外
(9)DISTINCT # 数据除重
(10)ORDER BY
<排序条件> # 排序,如非必要尽量不用
(11)LIMIT
<行数限制>
SQL语句顺序:
(8) SELECT (9)DISTINCT < 去重列 >
(1) FROM < 左表 >
(3) < 连接类型 > JOIN < 右表 >
(2) ON <连接条件>
(4) WHERE < 筛选条件 >
(5) GROUP BY < 分组列 >
(6) WITH {CUBE|ROLLUP}
(7) HAVING < 分组筛选 >
(10) ORDER BY < 排序列 >
(11) LIMIT < 行数限制 >
注:这里大家注意,(4)WHERE 筛选的是连接后的新表。
通过SQL的语法顺序和执行顺序很容易就看出,这和我们一步一步一个语句实现一个效果不同。要是我们按照面向过程来编程。那肯定首先是from先拿出表格,再考虑是否根据条件连接其他表格实现多表格联合处理。但是我们写的时候不能这么写,所以会感觉比较不适。了解了原理之后我们便可真正开始进行单表操作了。
二、单表操作
1.自连接
创建
为了方便演示这里创建一张value_test:
CREATE TABLE `value_test` (
`code` int(20) NOT NULL,
`time` bigint(124) NOT NULL,
`value` bigint(124) NOT NULL,
PRIMARY KEY (`value`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb3;
插入数据:
INSERT INTO value_test(`code`,time,`value`) VALUES('1','20220601','101');
INSERT INTO value_test(`code`,time,`value`) VALUES('1','20220602','102');
INSERT INTO value_test(`code`,time,`value`) VALUES('1','20220603','103');
INSERT INTO value_test(`code`,time,`value`) VALUES('1','20220604','104');
INSERT INTO value_test(`code`,time,`value`) VALUES('1','20220605','105');
INSERT INTO value_test(`code`,time,`value`) VALUES('1','20220606','106');
INSERT INTO value_test(`code`,time,`value`) VALUES('1','20220607','107');
INSERT INTO value_test(`code`,time,`value`) VALUES('2','20220601','201');
INSERT INTO value_test(`code`,time,`value`) VALUES('2','20220602','202');
INSERT INTO value_test(`code`,time,`value`) VALUES('2','20220603','203');
INSERT INTO value_test(`code`,time,`value`) VALUES('2','20220604','204');
INSERT INTO value_test(`code`,time,`value`) VALUES('2','20220605','205');
INSERT INTO value_test(`code`,time,`value`) VALUES('2','20220606','206');
INSERT INTO value_test(`code`,time,`value`) VALUES('2','20220607','207');
INSERT INTO value_test(`code`,time,`value`) VALUES('3','20220601','301');
INSERT INTO value_test(`code`,time,`value`) VALUES('3','20220602','302');
INSERT INTO value_test(`code`,time,`value`) VALUES('3','20220603','303');
INSERT INTO value_test(`code`,time,`value`) VALUES('3','20220604','304');
INSERT INTO value_test(`code`,time,`value`) VALUES('3','20220605','305');
INSERT INTO value_test(`code`,time,`value`) VALUES('3','20220606','306');
INSERT INTO value_test(`code`,time,`value`) VALUES('3','20220607','307');
得到了这张表格:
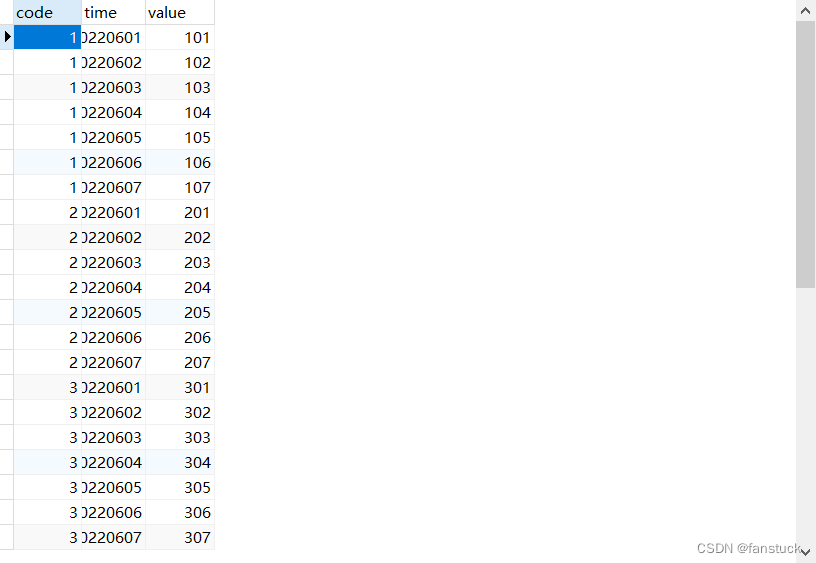
自连接
自连接可以这么理解,我们把原始表value_test作为镜像再去生成另一张一模一样的表,也就是自身的映射,该表设定命名为其他的名字,这样以来便存在两张表可以连接作用。但是因为存在着两张表,那么我们select的字段也不能写原始表的字段,因为两张表存在着相同的字段名称会报错:
select code,time,value
from value_test as v1,value_test as v2
所以需要指定两张某一张表的字段。
select v1.code,v1.time,v1.value
from value_test as v1,value_test as v2

我们现在需要两个指标,code分别为1和2,根据time来索引。通过自连接的方法我们不需要构建新的表就可以实现:
select v1.time,v1.`value` as value_1,v2.`value` as value_2
from value_test as v1,value_test as v2
WHERE v1.`code`=1
and v2.`code`=2
and v1.time=v2.time
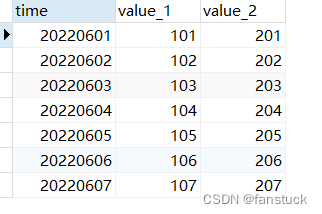
也就是说我们可以总结一下自连接的模版:
select a.【字段名】,b.【字段名】
from 【原始表】 AS a,【原始表】 AS b
where a.【共值字段名】=b.【共值字段名】
and a.【字段名】?条件
and a.【字段名】?条件
and b.【字段名】?条件
and b.【字段名】?条件
....
点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
以上就是本期全部内容。我是fanstuck ,有问题大家随时留言讨论 ,我们下期见。
参阅:
SQL规范一《SQL 语法顺序与编码规范 》
版权归原作者 fanstuck 所有, 如有侵权,请联系我们删除。