
文章目录
内存模型
在编译器与实际硬件执行代码阶段都是乱序的,并且 cpu 多线程情况下,内存模型是:
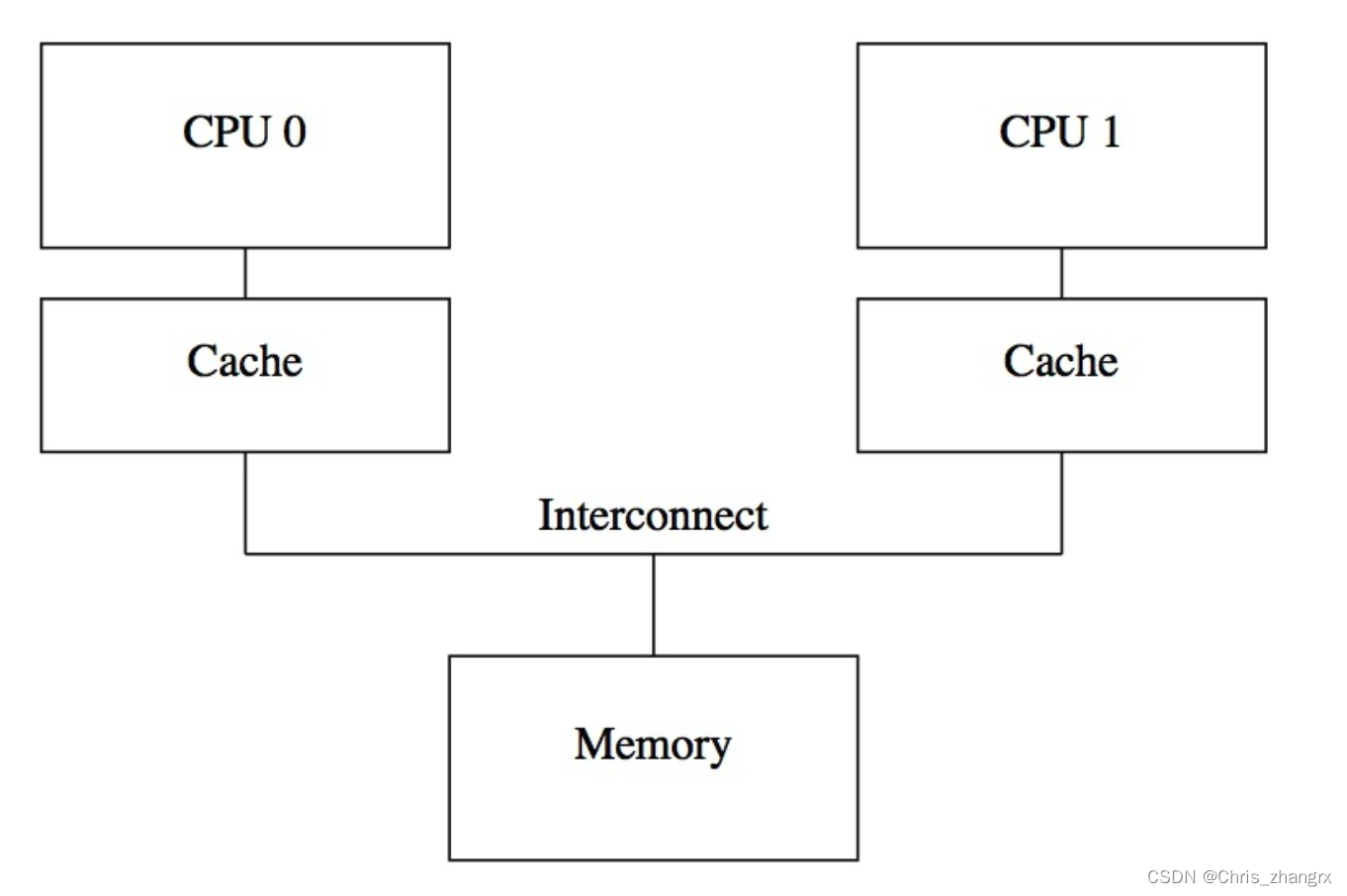
这其中就涉及到不同 cpu core 之间内存数据一致性的问题。 为了确保在乱序情况下。
typedefenummemory_order{
memory_order_relaxed = __mo_relaxed,
memory_order_consume = __mo_consume,
memory_order_acquire = __mo_acquire,
memory_order_release = __mo_release,
memory_order_acq_rel = __mo_acq_rel,
memory_order_seq_cst = __mo_seq_cst,} memory_order;
在 C++ atomic 中定义了上面 6 中内存顺序模型。主要是对汇编上的重排干预和硬件上乱序做干预和执行结果在多核上的可见性做干预。
core 里面分内存单元,控制单元和运算单元,当 load 指令时,alu 运算单元是空闲的,所以取值的时候预先做下一条指令。由此引入了在 core 与 L1 之间数据同步引入了 store buffer 硬件单元,和 不同 L1 cache 之间同步数据的 invalidate queue 硬件单元。为的都是通知之后可以立即得到回应,不至于空等,但是这样的设计也是有代价的。 这时就需要在软件上,由编程人员对相关的数据执行顺序进行一些约束。
store buffer
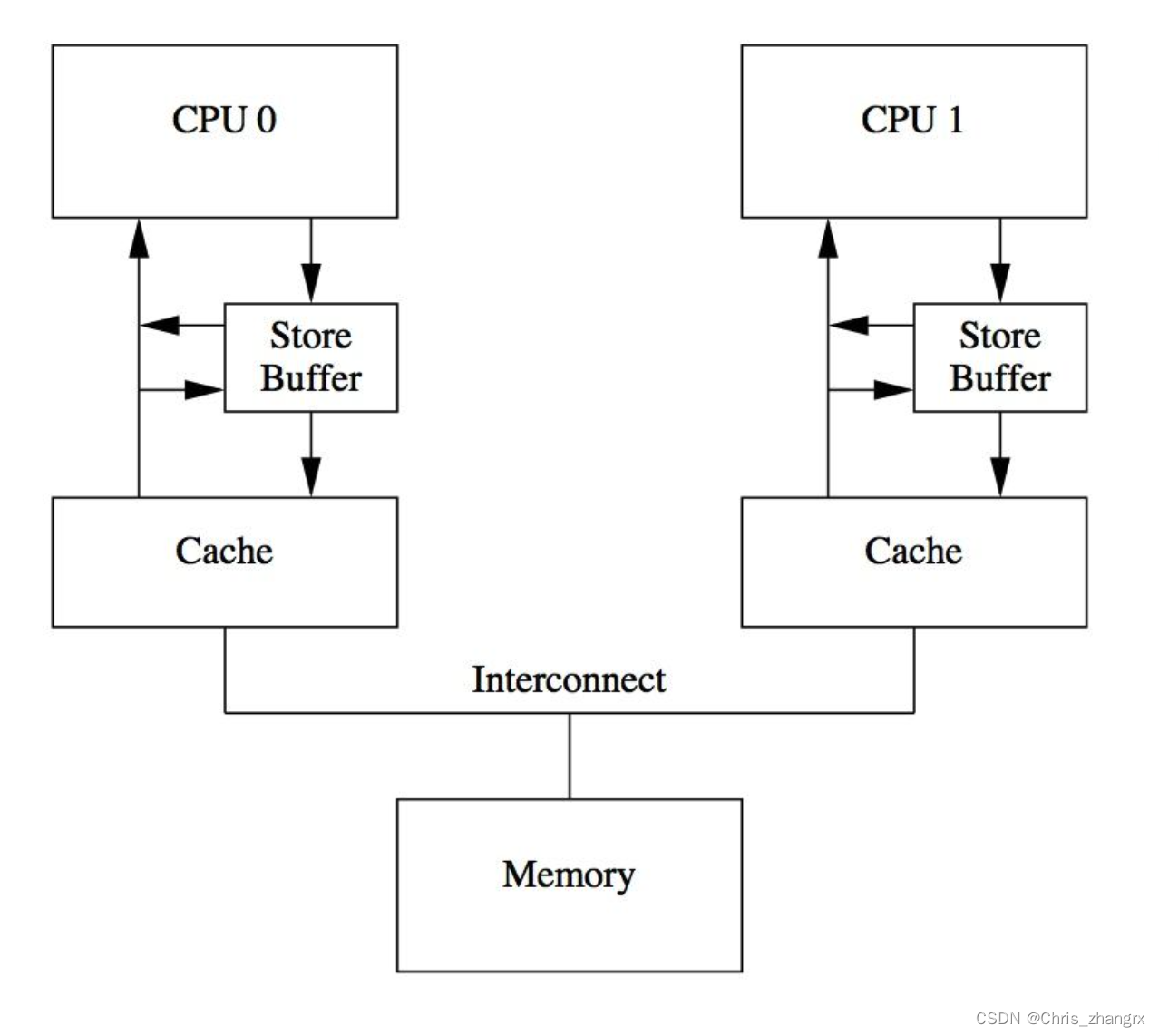
core0 在执行 store 操作之后,这个 store操作对应的 cacheline 会在其他 core 之间发送一个 invalidate message,并且要等到其他 core 都做了 invalidate ack 之后才能继续执行,那么在这个期间 core0 就只能处在盲等阶段,core0 真的需要等这么久吗? 硬件设计者引入了 store buffer 的硬件结构,这样当core0 执行 store 操作时,数值会先进入 store buffer,就不用立刻向其他 core 发送 invalidate message 了。写入 store buffer 只需要 1 个时钟周期,写入 L1 cache 则基本需要 3 个 cycles。 但是这会引起两个问题:
- 针对函数都在同一个 core 上运行,如果同一个变量的新值先 store 在 store buffer 中,但是 cache 中同样有一份旧值,在执行 load 变量操作的时候,需要先去 store buffer 中查找对应的 memory location,如果查到则使用新值。
- 针对函数在不同 core 上运行,数据之间有依赖关系,并且 cpu 硬件设计层面没办法判断是否当前 core 处理的变量是否与其他 core 存在关系, cpu 执行时都认为当前执行的程序是一个单线程的,感知不到多线程的存在,这时就需要编码人员告诉 cpu 现在需要将 store buffer flush 到 cache 中,于是 CPU 设计者提供了叫 memory barrier 的工具。
voidfoo(void){
a=1;smp_mb();// memory barrier
b=1;}voidbar(void){while(b ==0)continue;assert(a ==1);}
smp_mb 会在执行时将 store buffer 中的数据全部 flush 进 cache,这样就会执行成功了。
invalidate queue
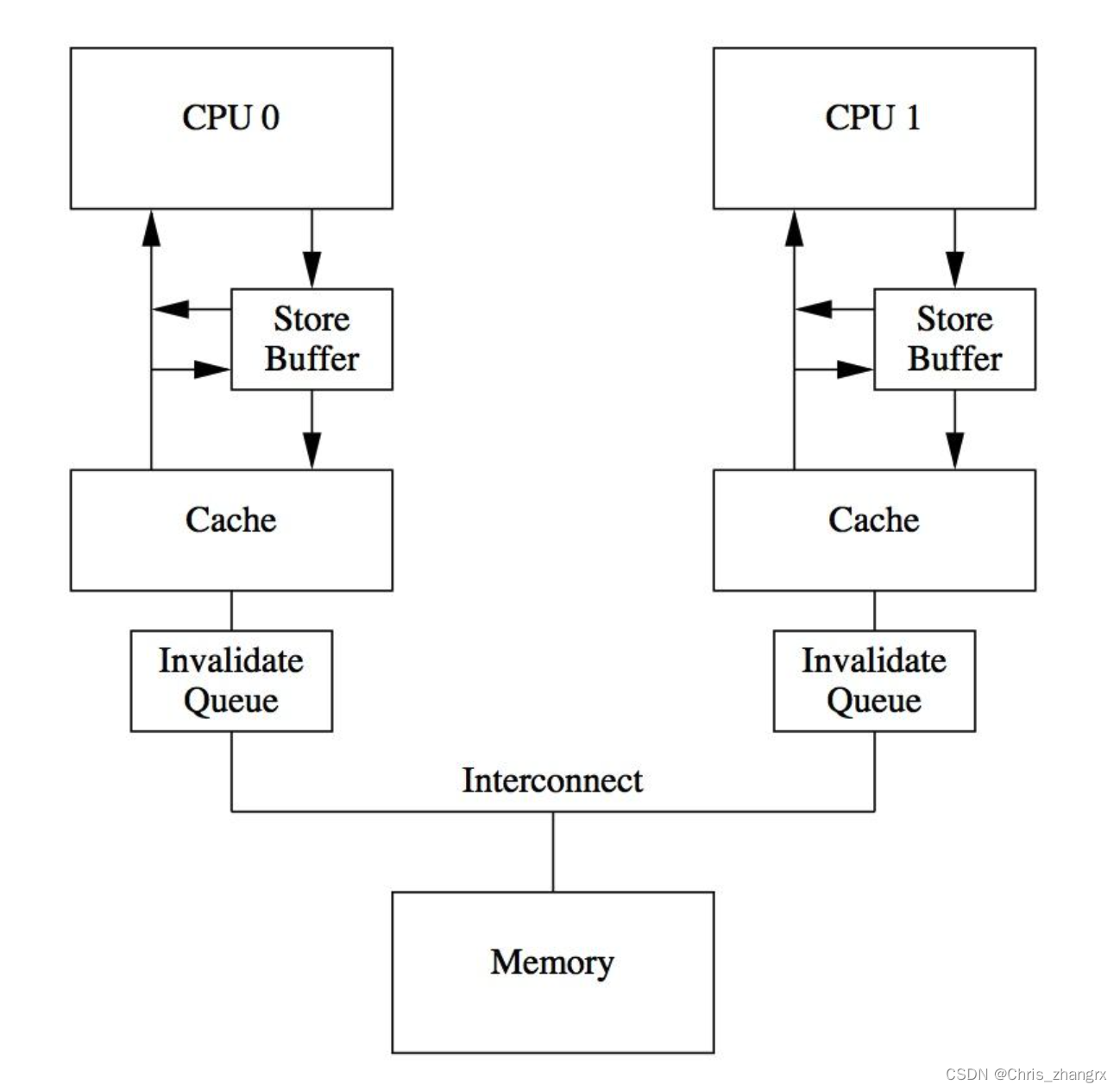
前面介绍 store buffer 帮助 core 在进行 store 操作时尽快返回,这里 buffer 和 cache 都是硬件元素,所以一般内存都比较小(几十个字节),当 store buffer 满了之后就需要将 buffer 内存刷新到 cache 中,刷新之后就会触发 cacheline 的 invalidate message, 这些 message 会一起发送给其他的 core,然后等到其他 core 返回 invalidate ack 之后才能继续往下执行。如果这些 core 有处理 invalidate message 不及时的,就会导致 core 等到的空闲。于是又增加了一个 invalidate queue 的硬件结构, 类似于 store buffer,有了 invalidate queue 之后,发送的 invalidate message 只需要 push 进对应 core 的 queue 中就行,然后这个 core 会立即返回对应的 invalidate ack,中间不需要等待。
但是这样也会带来一些问题。
voidfoo(void){
a=1;smp_mb();// memory barrier
b=1;}voidbar(void){while(b ==0)continue;// smp_mb(); // 也需要加入 memory_barrierassert(a ==1);}
加入 core0 运行 foo 函数,core1 运行 bar 函数。当 core0 中调用 smp_mb()刷新 store buffer,invalidate message 给到 core1 之后,然后运行 b =1。core1的bar函数会判断 b == 0 失败然后执行 assert,但是如果这时 core1 中的 invalidate queue 还没有刷到 core1 的 cache,assert 还是会失败。所以在 assert 之前也需要加入 memory barrier。 这个 memory barrier 会把 store buffer 和 invalidate queue 都刷新了。
memory barrier
上面提到的 smp_mb() 是一种 full memory barrier,它会将 store buffer 和 invalidate queue 都刷新一遍,于是硬件设计者又引入了:
read memory barrier 会将 invalidate queue 刷新
write memory barrier 会将 store buffer 刷新
顺序模型(SC)
顺序模型(sequential consistency model)简称 SC,多核读写 cache 使用 MESI 协议进行同步。在顺序模型下,多线程运行的期望的执行情况是一致的,不会出现内存访问乱序的情况。
Core 0Core 1S1: Store data = New;S2: Store flag = SET;L1: Load r1 = flag;B1: if(r1≠SET) goto L1;L2: Load r2 = data;
下面指令就会按照:S1→S2→L1→L2 的顺序运行完成。其特点就是指令的执行行为与单核上一致。
完全存储定序(TSO)
S1:Store flag = set
S2:load r1 = data
S3:store b = set
顺序模型则 S1→S2→S3,但是加入 sb 结构之后,S1 将指令放到了 sb 之后立即返回,这时候会立刻执行 S2,read 指令,CPU 必须等数据读取到 r1 之后才会继续执行。 完全存储定序(total store order)是 sb 结果必须严格按照 FIFO 的顺序将数据发送到主存。这里就有一个限制,为了保证数据一致性,S3 必须要在 S1 之后执行,且 S1 的数据要写到 cache 里。在单核下没什么问题,但是多核情况下,数据相互依赖就有可能有问题。
Core 0Core 1S1: store data = NEWS2: load r1 = FlagL1:store flag = NEWL2:load r1 = data
如果 data 和 flag 的值都在 sb,还没来得及同步到 L2 cache,那么 core0 和 core1 执行 S2 和 L2 指令时,得到的就还是初始化的 0。 这就是 store-load 乱序。 cpu 提供了一些指令来控制怎么把这些数据同步到其他核。
部分存储定序(PSO)
TSO 在 sb 结构下带来了不小的性能提升,但是还有进一步提升的空间。在 TSO 的基础上,继续放宽内存访问限制,允许 CPU 以 非 FIFO 来处理 sb 中的指令。 CPU 仅保证地址相关指令在 sb 中才会以 FIFO 的形式处理,而其他的则可以乱序执行,所以称为部分存储定序。
Core 0Core 1S1: Store data = New;S2: Store flag = SET;L1: Load r1 = flag;B1: if(r1≠SET) goto L1;L2: Load r2 = data;
上面 S1 和 S2 是地址无关的 store 指令, cpu 执行时会将其推到 sb 中。如果这时 flag 在 core0 的 cache 中存在,那么 CPU 会优先将 S2 的 store 执行完,然后等 data 缓存到 core1 的 cache 之后,再执行 store data = NEW 指令。
可能的执行顺序是:S2→L1→L2→S1, 这样 core0 将 data 设置为 NEW 之前,core1 已经执行完了,r2 的最终结果是 0,而不是我们期望的 NEW,这样 PSO 带来了 store-store 乱序。
宽松存储模型(RMO)
芯片设计人员为了榨取更多的性能,在 PSO 的基础上,进一步放宽了内存一致性模型,不仅允许 store-load, store-store 乱序。还进一步运行 load-load,load-store 乱序,只要是地址无关指令,在读写访存的时候就可以打乱所有的 load/store 顺序。
Core 0Core 1S1: Store data = New;S2: Store flag = SET;L1: Load r1 = flag;B1: if(r1≠SET) goto L1;L2: Load r2 = data;
还是上面的例子,在 PSO 里面 S2 可能会比 S1 先执行,并且由于 L1 和 L2 本身也是地址无关的,所以 load-load 之间也可以乱序,这样即使 core0 没有出现 store-store 乱序的问题,core 1 本身的 load-load 乱序就会导致 r2 为 0 的情况。
上面 4 种内存模型,是为了榨干 cpu 的性能而引入的,在单核模式下都没有问题,但是 cpu 和编译器是感知不到多线程存在的,所以这就会引起多线程的内存一致性问题。 由此就引出了下面的 6 种内存序。
C++ 内存序
C++ 中 atomic 变量的 store 和 load 提供了以下选项:
typedefenummemory_order{
memory_order_relaxed = __mo_relaxed,
memory_order_consume = __mo_consume,
memory_order_acquire = __mo_acquire,
memory_order_release = __mo_release,
memory_order_acq_rel = __mo_acq_rel,
memory_order_seq_cst = __mo_seq_cst,} memory_order;
定义了上面 6 中内存顺序模型。主要是对汇编上的重排干预和硬件上乱序做干预和执行结果在多核上的可见性做干预。
- memory_order_seq_cst : 这里要求底层提供顺序一致性(SC)模型,这种模式下不存在任何重排。在底层实现上,程序运行的底层架构如果是非内存强一致性模型,就会使用 cpu 提供的 memory barrier 操作来保证一致性。软件上,要求代码进行编译的时候不能做任何重排。
- memory_order_release/acquire/consume: 这些都是可以允许 cpu 或者编译器做一定的指令乱序重排,但是涉及到 TSO,PSO 的内存模型可能导致的 store-load,store-store 问题,涉及到多核交互的时候就需要手动使用 release,acquire 来避免这样的问题,其对具体代码可能出现的乱序做具体解决而不是要求都不能重排。
- memory_order_relaxed: 提供松散一致性模型,让 cpu 和编译器根据自己的支持情况,4 种 load. store 组合随意重排。 但是这样很容易出问题,一般在代码没有乱序要求或者没有多核交互的情况下,提升性能。
memory_order_seq_cst: 这是默认配置,表示这条语句所有前面的语句不能放到后面,后面的所有语句不能放到前面。(不仅是读写相关操作)
memory_order_acquire: 要求后面所有的读内存不能放在本句之前。
memory_order_release: 要求本句之前有任何写内存的操作,都不能放在本句之后。
memory_order_acq_rel: 可以同时表示读内存不能放在本句之前,写内存不能放在本句之后。
memory_order_consume: 要求后面依赖于本次整条语句的读写不能乱序。
参考文章:
版权归原作者 Chris_zhangrx 所有, 如有侵权,请联系我们删除。