
Python pandas库㈡
前言
python pandas库㈠学习通道
Python pandas库㈢学习通道
Python pandas库㈣学习通道
一、数据读写
①读写.xls或.xlsx文件
(1)安装库
Python操作.xls及.xlsx文件可使用xlrd、xlwt、openpyxl等库,其中xlrd用于读取.xls及xlsx文件,而xlwt是用于写入.xls文件的,openpyxl则可用于读写.xlsx文件。pandas对这三个库进行了封装,可以很方便的读写Excel文件,也支持xls和xlsx等格式。但是,在使用pandas的方法之前,需要先安装它们,如下所示:
pip install xlrd #安装读取.xls文件的库
pip install xlwt #安装写入.xls文件的库
pip install openpyxl #安装读写.xlsx文件的库
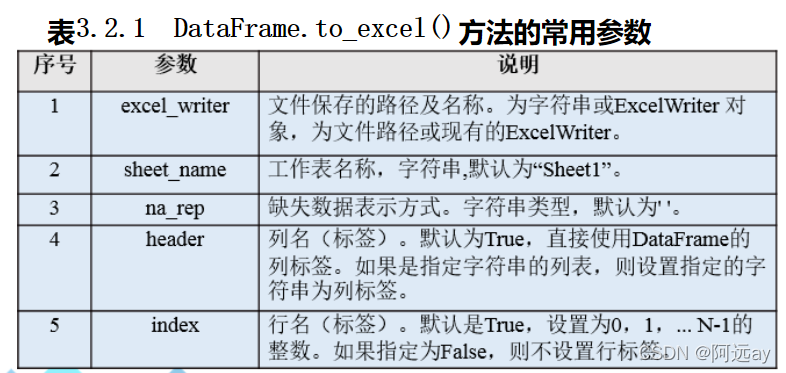
(2)to_excel()方法
写入Excel文件,可以直接使用DataFrame对象的to_excel()方法
#语法:import pandas as pd
DataFrame.to_excel(excel_writer,sheet_name='Sheet1',na_rep="",float_format=None,columns=None,header=True,index=True,index_label=None,startow=0,startcol=0)
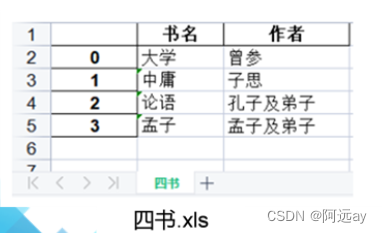
import pandas as pd
df = pd.DataFrame({'作者':['曾参','子思','孔子及弟子','孟子及弟子'],'书名':['大学','中庸','论语','孟子']})
df.to_excel('四书.xls','四书')#写入xls文件
df.to_excel('四书2.xlsx','四书2')#写入xlsx文件

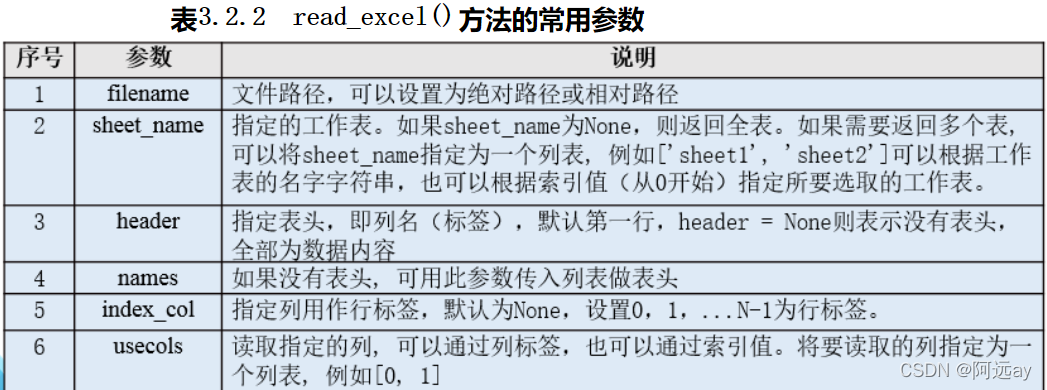
(3)read_excel()方法
读取Excel文件:read_excel()方法
#语法:import pandas as pd
df = pd.read_excel(filename,sheet_name=0,header=0,names=None,index_col=None,usecols=None)
import pandas as pd
df1 = pd.read_excel('四书.xls')
df1
df2 = pd.read_excel('四书.xlsx')
df2


- 若文件读取成功,read_excel()方法将返回一个DataFrame对象,这样在处理数据时就能使用DataFrame提供的方法。
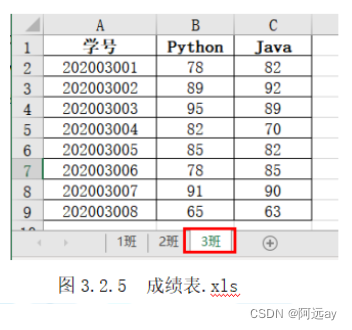
读取excel文件中指定的sheet表:read_excel()方法
- 一个excel文件可以包含多个sheet表,如果要读取指定的sheet表,在read_excel()方法中指定sheet_name参数。
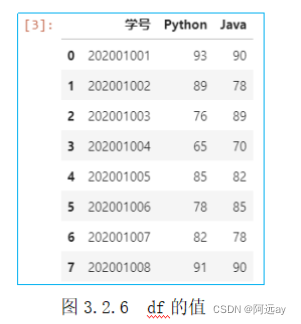
import pandas as pd
df = pd.read_excel('成绩表.xls',sheet_name='3班')#读取成绩表.xls文件中的sheet表中3班的数据
df
②读写.csv文件
(1)read_csv()方法
读取csv文件:read_csv()方法
- CSV(Comma-Separated Values,逗号分隔值),有时也称为字符分隔值,其文件以纯文本形式存储表格数据(数字和文本)。
- pandas读取csv文件使用read_csv()方法,其返回值为DataFrame对象,常用参数如下:

(2)to_csv()方法
写入csv文件:to_csv()方法:
- pandas写入csv文件,通过DataFrame对象使用to_csv()方法,常用参数如下:
import pandas as pd
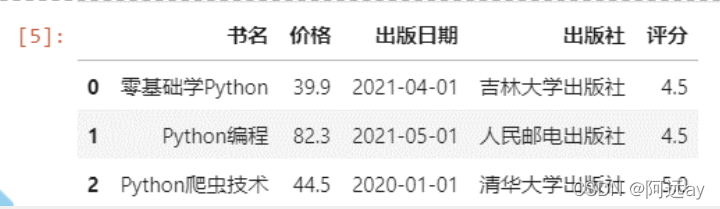
df = pd.DataFrame({'书名':['零基础学Python','Python编程','Python爬虫技术'],'评分':[4.5,4.5,5],'价格':[39.90,82.30,44.50],'出版日期':['2021-04-01','2021-05-01','2020-01-01'],'出版社':['吉林大学出版社','人民邮电出版社','清华大学出版社']})
df.to_csv('图书.csv',index=False)#写入csv文件,不使用行标签
df2=pd.read_csv('图书.csv',engine='python')#读取csv文件,文件名为中文,设置engine='python'
df2
③读写.txt文件
.txt文本文件是一种由若干行字符构成的计算机文件,它是一种典型的顺序文件。
使用pandas读写.txt文件里的数据,可以使用read_csv()方法,也可以使用read_table()方法。
read_csv和read_table方法基本用法是一致的,区别在关于sep分隔符。由于csv是逗号分隔值,默认读入以","分割的数据,而read_table默认是‘\t’(也就是tab)切割数据集。但由于txt文件分隔数据时不一定使用的是逗号,因此往往要额外指定分隔符。
写.txt文件也可以使用to_csv()方法完成。
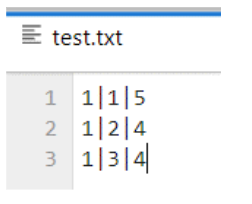
import pandas as pd
df = pd.read_csv('test.txt',sep='|',header=None)
df
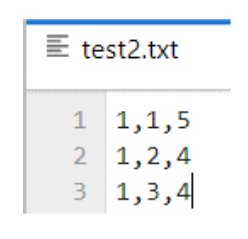
df.to_csv('test2.txt',header=False,index=False)

④读写json文件
JSON即JavaScript Object Notation(JavaScript对象表示法),是一种轻量级的数据交换格式。
JSON是基于纯文本的数据格式,它可以传输String、Number、Boolean类型的数据。
JSON文件的扩展名为.json
JSON分为JSON对象和JSON数组两种数据结构。
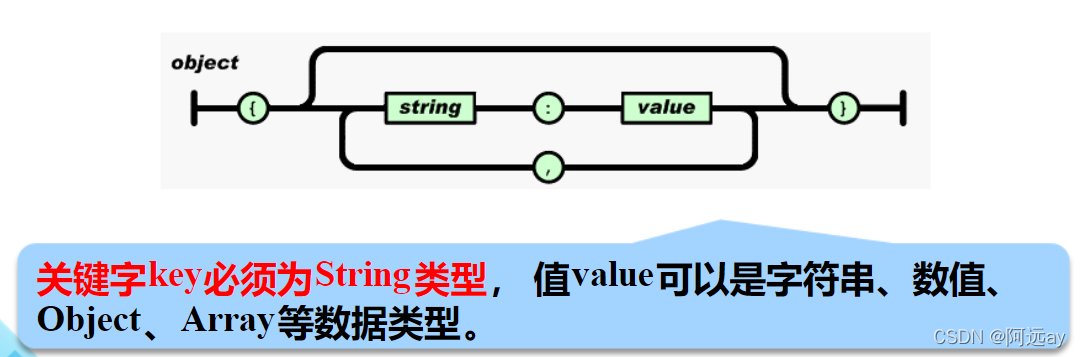
(1)JSON对象
JSON对象以"{“开始,以”}“结束。中间部分由0个或多个以”,"分隔的key:value对构成,注意关键字和值之间以“:”分隔。
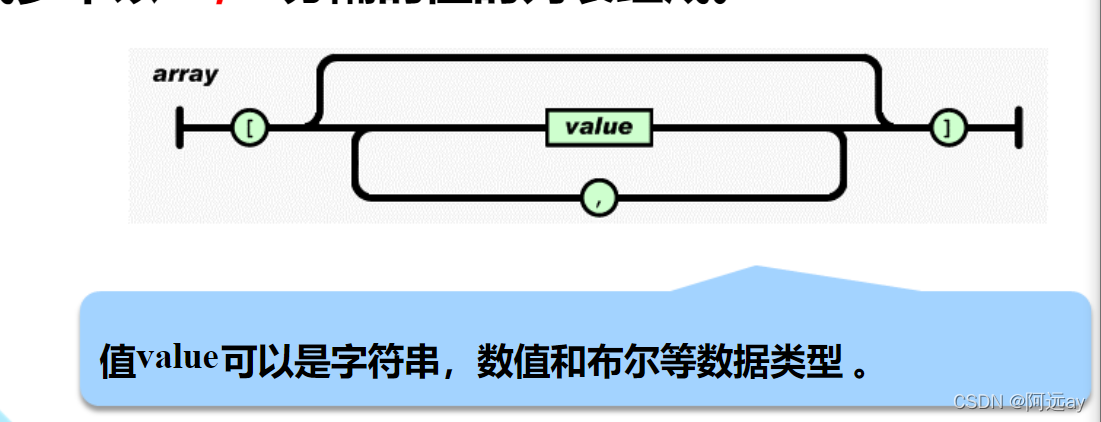
(2)JSON数组
JSON数字以"[" 开始,以"]“结束。中间部分由0或多个以”,"分隔的值的列表组成。
读取json文件:read_json()方法
写入json文件:to_json()方法
import pandas as pd
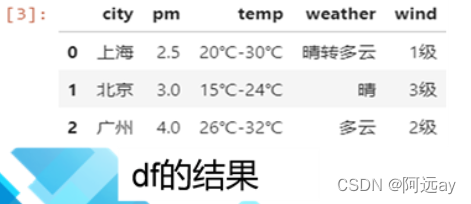
df = pd.read_json('weather.json',encoding='utf_8')#为正确读入中文,设置encoding='utf_8'
df
#写入json文件,force_ascii=False可正确写入中文#orient='recods'设置格式为[{column->value},...,{column->value}]
df.to_json('weather2.json',force_ascii=False,orient='recods')

⑤读写MySQL文件
(1)read_sql()方法
读取MySQL数据库文件,可以用read_sql()方法。其返回值是一个DataFrame对象,常用的就是前两个参数:sql为可执行的sql语句,con为数据库的连接。代码如下所示:
import pandas as pd
df = pd.read_sql(sql,con,index_col=None,coerce_float=True,params=None,parse_dates=None,columns=None,chunksize=None)
为了读取MySQL数据库,树妖使用pymysql库来进行数据连接。为了生成engine类型,还需要sqlalchemy库调用其create_engine()方法。
安装如下:
pip install pymysql
pip install sqlalchemy
import pandas as pd
import pymysql
import sqlalchemy
engine=sqlalchemy.create_engine('mysql+pymysql://root:admin@localhost:3306/mydb?charset=utf8')#第4行代码创建连接数据库的engine,root:admin表示为默认的root用户,密码为root用户的连接密码,3306为默认的端口号,mydb为要连接的数据库的名称,charset指定字符集为utf8
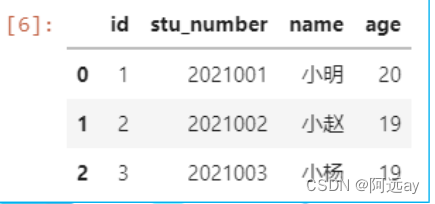
df=pd.read_sql('select * from student',con=engine)#通过pandas调用read_sql()方法,第一个参数为sql查询语句,student为表名,查询student表的所有数据,返回值保存为DataFrame对象df。
df
(2)to_sql()方法
写入MySQL:to_sql()方法
df.to_sql(name,con,schema=None,if_exists='fail',index=True,index_label=None,chunksize=None,dtype=None,method=None)

import pandas as pd
import pymysql
import sqlalchemy
engine=sqlalchemy.create_engine('mysql+pymysql://root:admin@localhost:3306/mydb?charset=utf8')
df=pd.read_sql('select * from student',con=engine)
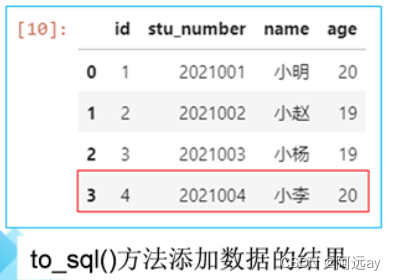
df.loc[3]=[4,'2021004','阿远',20]#给df对象添加一行数据
df[3:4].to_sql('student',con=engine,if_exists='append',index=False)#将这行数据添加到student表,if_exists='append'表示追加到表后面,index=False表示不适用df对象的行标签(索引)。
df2 = pd.read_sql('select * from student',con=engine)#重新连接数据库,完成对student表的查询,结果保存到DataFrame对象df2。
df2
二、数据合并
①堆叠合并数据
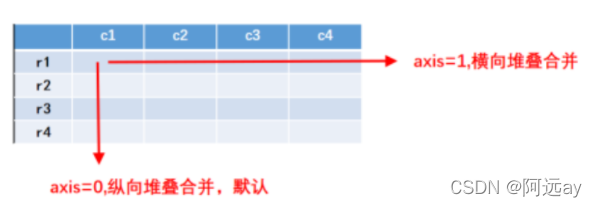
堆叠合并可以沿着指定的行/列将多个DataFrame或者Series对象合并到一起。按照合并的方向,可以分为横向堆叠合并,纵向堆叠合并和交叉堆叠合并。
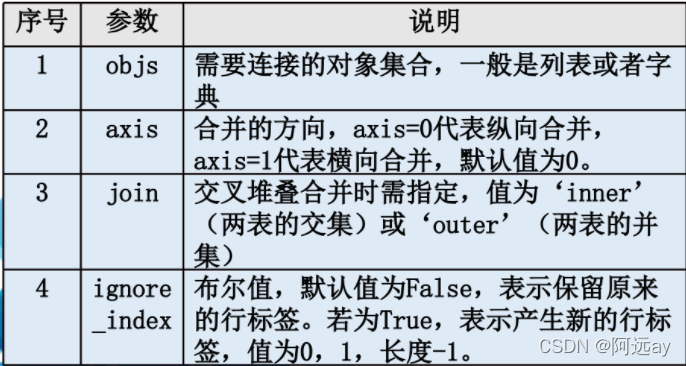
堆叠合并操作可以通过pandas库的concat()方法完成,返回值为合并后的DataFrame或Series对象。
concat()方法参数如下:
(1)横向堆叠合并
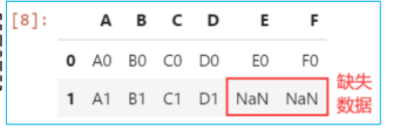
横向堆叠合并操作是将不同的表按行标签进行横向拼接,在concat()方法中设置参数axis=1。如果表的行标签不同时,缺失的数据用NaN填充。
import pandas as pd
df1 = pd.DataFrame({'A':['A0','A1'],'B':['B0','B1']})
df2 = pd.DataFrame({'C':['C0','C1'],'D':['D0','D1']})
cont = pd.concat([df1,df2],axis=1)
cont

df3 = pd.DataFrame({'E':['E0'],'F':['F0']})
cont = pd.concat([cont,df3],axis=1)
cont
(2)纵向堆叠合并
纵向堆叠合并操作是将不同的表按列标签进行纵向拼接,在concat方法中,默认是纵向拼接,即参数axis=0。纵向堆叠合并是按列对齐,如果表的列标签不同时,缺失的数据用NaN填充。
import pandas as pd
df1 = pd.DataFrame({'A':['A0','A1'],'B':['B0','B1']})
df2 = pd.DataFrame({'A':['A2','A3'],'B':['B2','B3']})
cont = pd.concat([df1,df2])
cont

注:纵向拼接默认是保留原来的行标签。如果要重新编号,则需要设置参数ignore_index=True。
cont = pd.concat([df1,df2],ignore_index=True)
cont

df3 = pd.DataFrame({'B':['B4'],'C':['C4']})
result = pd.concat(([concat,df3],ignore_index=True)
result

- df1,df2和df3被纵向拼接,而且重新产生行标签。
- 纵向合并时按列标签对齐,缺失的数据用NaN填充。
(3)交叉堆叠合并
交叉堆叠合并操作是按行/列标签对齐,进行两表的交集或并集的合并操作,通过在concat()方法中设置join参数来实现。
如果join=‘inner’,合并后得到的两表的交集;如果join='outer’合并后得到两表的并集,缺失的数据用NaN填充。
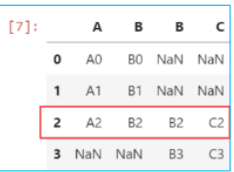
import pandas as pd
df1 = pd.DataFrame({'A':['A0','A1','A2'],'B':['B0','B1','B2']})
df2 = pd.DataFrame({'B':['B2','B3'],'C':['C2','C3']},index=[2,3])
cont = pd.concat([df1,df2],axis=1,join='inner')#按横向合并得到df1和df2的交集
cont
cont = pd.concat([df1,df2],axis=1,join='outer')#按横向合并得到df1和df2的并集
cont
cont = pd.concat([df1,df2],join='inner')#按纵向合并得到df1和df2的交集
cont
cont = pd.concat([df1,df2],join='outer')#按纵向合并得到df1和df2的并集
cont



(4)案例实现
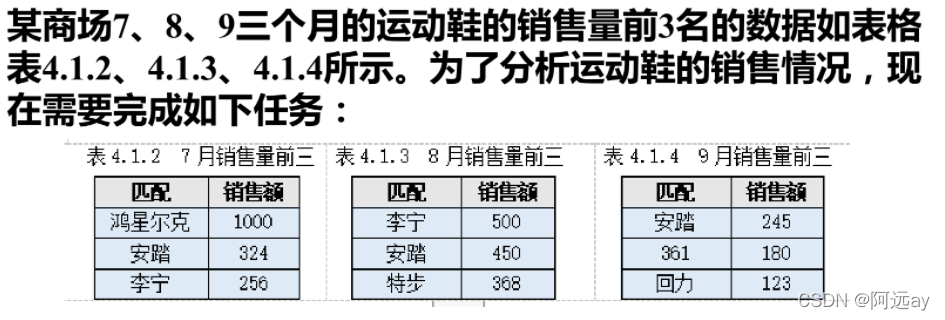
①把该商场7、8、9三个月运动鞋的销售量前3名的数据汇总到一张表。
②统计该商场7、8、9三个月运动鞋的销售量前3名中都出现的运动鞋品牌。
import pandas as pd
df1 = pd.DataFrame({'匹配':['鸿星尔克','安踏','李宁'],'7月销售额':[1000,324,256]},index=[1,2,3])
df2 = pd.DataFrame({'匹配':['李宁','安踏','特步'],'8月销售额':[500,450,368]},index=[3,2,4])
df3 = pd.DataFrame({'匹配':['安踏','361','回力'],'9月销售额':[245,180,123]},index=[2,5,6])
cont = pd.concat([df1,df2,df3],join="outer")
cont
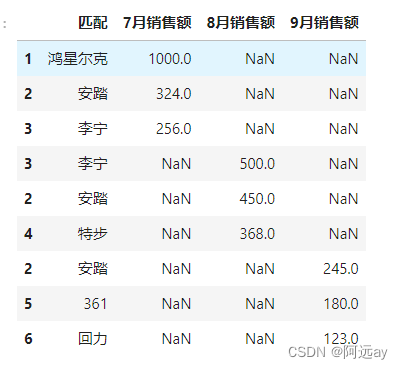
result = pd.concat([df1,df2,df3],axis=1,join="inner")
result

②主键合并
主键合并操作是通过1个或多个键值(键值是指数据表中值可唯一标识一行数据的列标签,类似于关系型数据库中表的主键)将两个数据表进行横向连接。根据合并方式的不同,主键合并可以分为左连接、右连接、内连接和外连接。
主键合并可以通过pandas库的merge()方法完成,该方法只能实现两个表的拼接。merge()方法的主要参数如表4.2.1所示:

(1)左连接
左连接是指在对两张表进行主键合并操作时,按左表的主键值进行合并,保持左表的主键值的顺序,如果左表的主键值在右表不存在,用NaN填充。
左连接通过设定merge()方法的参数how=‘left’来实现。
import pandas as pd
df1 = pd.DataFrame({'id':[1,2,3,4],'gender':['男','男','男','女']},columns=['id','gender'])
df2 = pd.DataFrame({'id':[4,2,5],'payment':[100,200,50]},columns=['id','payment'])
cont = pd.merge(df1,df2,how='left',on='id')
cont
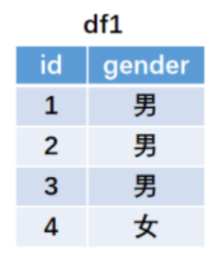
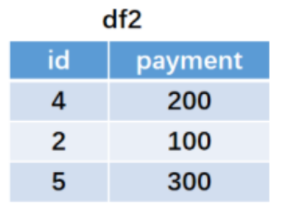

左连接以左边表格的所有键值为基准进行连接。因为右表中id=5不在左表中.故不会进行连接。
右表中的payment列在合并时,和左表中的id=1和id=3没有匹配值,所以左连接合并以后用缺失值NaN填充。
(2)右连接
右连接是在对左右表进行主键合并操作时,按右表的主键值进行合并,保持右表的主键值的顺序,如果右表的主键值在左表不存在,用NaN填充。右连接通过设定merge()方法的参数how=‘right’来实现。
在这里插入代码片

右连接以右边表格的所有键值为基准进行连接。因为左表中id=1和id=3不在右表中,故不会进行连接。
左表中的gender列在合并时,和右表中的id=5没有匹配值,所以右连接合并以后用缺失值NaN填充。
(3)内连接
内连接是在对左右表进行主键合并操作时,以左右表的主键值的交集进行合并,并保持左表的主键值的顺序。右连接通过设定merge()方法的参数how=‘inner’来实现。
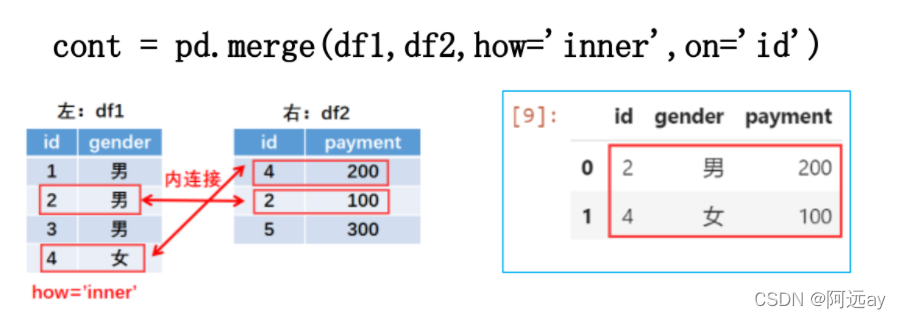
df1和df2的主键id值的交集={2,4},所以内连接时将左右表的键值id=2和id=4为基准进行连接,而id=1,3,5则不进行连接。
合并结果以左表的键值顺序输出。
(4)外连接
外连接是在对左右表进行主键合并操作时,以左右表的主键值的并集进行合并,按字典顺序对主键值重新排序。外连接通过设定merge()方法的参数how=‘outer’来实现。

df1和df2的主键id值的并集={1,2,3,4,5},所以外连接时将左右表的全部键值进行连接。左表中的gender列在合并时,和右表中的id=5没有匹配值,所以外连接后用缺失值NaN填充。右表的apyment列在合并时,和左表中的id=1和id=3没有匹配值,所以外连接后都用缺失值NaN填充。
合并结果按字典顺序对主键值重新排序。
③重叠合并
数据处理的过程中偶尔会出现同样一份数据存储在两张表中。分别查看这两张表的数据,会发现每张表的数据都不完整,都存在数据缺失的情况。但是,如果将其中一个表的数据补充进另外一个表中,生成的这张表则是相对完整的数据。用一张表的数据来填充另一张表的缺失数据的方法就叫重叠合并。
重叠合并数据的功能通过pandas库中提供的combine_first()方法完成,语法格式如下:
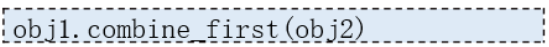

import pandas as pd
import numpy as np
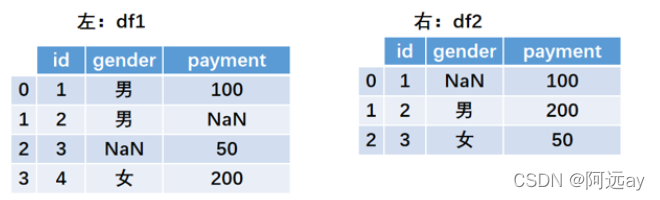
df1 = pd.DataFrame({'id':[1,2,3,4],'gender':['男','男',np.nan,'女'],'payment':[100,np.nan,50,200]})
df2 = pd.DataFrame({'id':[4,2,5],'gender':[np.nan,'男','女'],'payment':[100,200,50]})
result = df1.combine_first(df2)
result

版权归原作者 阿远ay 所有, 如有侵权,请联系我们删除。