
一. Prometheus 监控集群概述
Prometheus三大组件:
Server 主要负责数据采集和存储,提供PromQL查询语言的支持。
Alertmanager 警告管理器,用来进行报警。
Push Gateway 支持临时性Job主动推送指标的中间网关。
1.1 Prometheus组件架构图
Prometheus是由SoundCloud开发的开源监控报警系统和时序列数据库(TSDB)。Prometheus使用Go语言开发,是Google BorgMon监控系统的开源版本。Prometheus的主要特点如下:
多维度数据模型。
灵活的查询语言。
不依赖分布式存储,单个服务器节点是自主的。
通过基于HTTP的pull方式采集时序数据。
可以通过中间网关进行时序列数据推送。
通过服务发现或者静态配置来发现目标服务对象。
支持多种图形和Dashboard的展示,例如Grafana。
Prometheus根据配置的任务(job)以周期性pull的方式获取指定目标(target)上的指标(metric):
Prometheus Server:主服务,接受外部http请求,根据配置完成数据采集,服务发现以及数据存储。
prometheus targets:静态收集的目标服务数。
service discovery:动态发现服务。
Push Gateway:为应对部分push场景提供的插件,监控数据先推送到Push Gateway上,然后再由Prometheus Server端采集pull。由于存在时间较短,可能在Prometheus来pull之前,jobs就消失了。(若Prometheus Server在采集间隔期间,Push Gateway上的数据没有变化,Prometheus Server将采集到2次相同的数据,仅时间戳不同)。
Exporters(探针):是Prometheus的一类数据采集组件的总称。它负责从目标处搜集数据,并将其转化为Prometheus支持的格式。与传统的数据采集组件不同的是,它并不向中央服务器发送数据,而是等待中央服务器主动前来抓取。抓取什么样的数据,就需要什么类型的exporter,比如说抓取mysql状态的数据,就需要mysqld_exporter。
Alertmanager:Prometheus server主要负责根据基于PromQL的告警规则分析数据,如果满足PromQL定义的规则,则会产生一条告警,并发送告警信息到Alertmanager,Alertmanager则是根据配置处理告警信息并发送。常见的接收方式有:电子邮件,webhook等。Alertmanager三种处理告警信息的方式:分组,抑制,静默。

Prometheus Daemon负责定时去目标上抓取metrics(指标)数据,每个抓取目标需要暴露一个http服务的接口给它定时抓取。Prometheus支持通过配置文件、文本文件、Zookeeper、Consul、DNS SRV Lookup等方式指定抓取目标。Prometheus采用PULL的方式进行监控,即服务器可以直接通过目标PULL数据或者间接地通过中间网关来Push数据。
Prometheus在本地存储抓取的所有数据,并通过一定规则进行清理和整理数据,并把得到的结果存储到新的时间序列中。
Prometheus通过PromQL和其他API可视化地展示收集的数据。Prometheus支持很多方式的图表可视化,例如Grafana、自带的Promdash以及自身提供的模版引擎等等。Prometheus还提供HTTP API的查询方式,自定义所需要的输出。
PushGateway支持Client主动推送metrics到PushGateway,而Prometheus只是定时去Gateway上抓取数据。
Alertmanager是独立于Prometheus的一个组件,可以支持Prometheus的查询语句,提供十分灵活的报警方式。
其工作流程大致如下:
Prometheus 服务器定期从配置好的 jobs 或者 exporters 中获取度量数据;或者接收来自推送网关发送过来的度量数据。
Prometheus 服务器在本地存储收集到的度量数据,并对这些数据进行聚合。
运行已定义好的 alert.rules,记录新的时间序列或者向告警管理器推送警报。
告警管理器根据配置文件,对接收到的警报进行处理,并通过email等途径发出告警。
Grafana等图形工具获取到监控数据,并以图形化的方式进行展示。
1.2 Grafana简介
Grafana是一个开源的度量分析与可视化套件,经常被用作基础设施的时间序列数据和应用程序分析的可视化。
Grafana支持许多不同的数据源,每个数据源都有一个特定的查询编辑器,该编辑器定制的特性和功能是公开的特定数据来源。
官方支持以下数据源:Graphite,InfluxDB,OpenTSDB,Prometheus,Elasticsearch,CloudWatch和KairosDB。
每个数据源的查询语言和能力都是不同的,可以把来自多个数据源的数据组合到一个仪表板,但每一个面板被绑定到一个特定的数据源,它就属于一个特定的组织。
1.3 Exporter详解
随着Prometheus的流行,很多系统都已经自带了用于Prometheus监控的接口,例如etcd、Kubernetes、coreDNS等,所以这些系统可以直接被Prometheus所监控。但是有很多应用目前还没有提供用于Prometheus监控的接口,针对这这类应用Prometheus提出了Exporter的解决方案。
Exporter是一个采集被监控系统的监控数据,通过Prometheus监控规范对外提供数据的组件。简单来说,为了采集被监控系统的监控样本数据,需要安装一个程序,该程序对外暴露了一个用于获取当前监控样本数据的HTTP访问地址,这样的一个程序称为Exporter,Exporter的实例称为一个Target。Prometheus通过轮询的方式定时从Target中获取监控数据样本,并且存储在数据库当中。
从广义的层面上讲,任何遵循Prometheus数据格式 ,可对其提供监控指标的程序都可以称为Exporter。Prometheus官方和社区提供了非常丰富的Exporter,例如Node Exporter、HAProxy Exporter、MySQL Exporter、Redis Exporter和Rabbitmq Exporter等等。
这些Exporter主要通过被监控对象提供的监控相关的接口获取监控数据,通过例如以下几种方式获取到被监控对象的监控指标:
HTTP/HTTPs:例如Rabbitmq Exporter通过HTTPs接口获取监控数据。
TCP:例如Redis Exporter通过Redis提供的系统监控相关命令获取监控指标,MySQL Server Exporter通过MySQL开放的监控相关的表获取监控指标
本地文件:例如Node Exporter通过读取整个proc文件系统下的文件,得到整个系统的当前状态。
标准协议:例如IPMI Exporter通过IPMI协议获取硬件相关信息,并将这些信息的格式进行转化,输出为Prometheus能够识别的监控数据格式,从而扩大Prometheus的数据采集能力。
所有的Exporter程序都需要按照Prometheus的规范返回监控的样本数据。
1.3.1 Exporter运行方式
- 独立运行
以待会后面会使用的node_exporter为例,由于操作系统本身并不直接支持Prometheus,因此,只能通过一个独立运行的程序,从操作系统提供的相关接口将系统的状态参数转换为可供Prometheus读取的监控指标。
除了操作系统外,如Mysql、kafka、Redis等介质,都是通过这种方式实现的。这类Exporter承担了一个中间代理的角色。
- 应用集成
由于Prometheus项目的火热,目前有部分开源产品直接在代码层面使用Prometheus的Client Library,提供了在监控上的直接支持,如kubernetes、ETCD等产品。
这类产品自身提供对应的metrics接口,Prometheus可通过接口直接获取相关的系统指标数据。这种方式打破了监控的界限,应用程序本身做为一个Exporter提供功能。
1.3.2 常用的Exporter
下面表格是一些较常使用到的Exporter,内容覆盖了数据库、主机、HTTP、云平台等多个层面。
类型
监控介质
Exporter
数据库
Mysql
MySQL server exporter
Elasticsearch
Elasticsearch exporter
Mongodb
MongoDB exporter
Redis
Redis exporter
PostgreSQL
PostgreSQL exporter
硬件/操作系统
主机/Linux
Node exporter
GPU
NVIDIA GPU exporter
Windows
Windows exporter
IPMI
IPMI exporter
网络设备
SNMP exporter
消息队列
RabbitMQ
RabbitMQ exporter
Kafka
Kafka exporter
RocketMQ
RocketMQ exporter
HTTP
Apache
Apache exporter
HAProxy
HAProxy exporter
Nginx
Nginx exporter
云平台
阿里云
Alibaba Cloudmonitor exporter
AWS
AWS CloudWatch exporter
Azure
Azure Monitor exporter
华为云
Huawei Cloudeye exporter
腾讯云
TencentCloud monitor exporter
其他
探针检测
Blackbox exporter
容器
cArdviso
SSH
SSH exporter
除以上这些外,还有很多其他用途的Exporter,有兴趣的朋友可以自行查看官网:https://prometheus.io/docs/instrumenting/exporters/。
1.4 Prometheus命令参数详解
- Prometheus启动参数配置及释义
参数名称
含义
备注
--version
显示应用的版本信息
配置文件参数
--config.file="prometheus.yml"
Prometheus配置文件路径
WEB服务参数
--web.listen-address="0.0.0.0:9090"
UI、API、遥测(telemetry)监听地址
--web.read-timeout=5m
读取请求和关闭空闲连接的最大超时时间
默认值:5m
--web.max-connections=512
最大同时连接数
默认值:512
--web.external-url=
可从外部访问普罗米修斯的URL
如果Prometheus存在反向代理时使用,用于生成相对或者绝对链接,返回到Prometheus本身,如果URL存在路径部分,它将用于给Prometheus服务的所有HTTP端点加前缀,如果省略,将自动派生相关的URL组件。
--web.route-prefix=
Web端点的内部路由
默认路径:--web.external-url
--web.user-assets=
静态资产目录的路径
在 /user 路径下生效可用
--web.enable-lifecycle
通过HTTP请求启用关闭(shutdown)和重载(reload)
--web.enable-admin-api
启用管理员行为API端点
--web.console.templates="consoles"
总线模板目录路径
在 /consoles 路径下生效可用
--web.console.libraries="console_libraries"
总线库文件目录路径
--web.page-title="Prometheus Time Series Collection and Processing Server"
Prometheus实例的文档标题
--web.cors.origin=".*"
CORS来源的正则Regex,是完全锚定的
例如:'https?://(domain1|domain2).com'
数据存储参数
--storage.tsdb.path="data/"
指标存储的根路径
--storage.tsdb.retention=STORAGE.TSDB.RETENTION
[DEPRECATED]样例存储时间
此标签已经丢弃,用"storage.tsdb.retention.time"替代
--storage.tsdb.retention.time=STORAGE.TSDB.RETENTION.TIME
存储时长,如果此参数设置了,会覆盖"storage.tsdb.retention"参数;如果设置了"storage.tsdb.retention" 或者"storage.tsdb.retention.size"参数,存储时间默认是15d(天),单位:y, w, d, h, m, s, ms
--storage.tsdb.retention.size=STORAGE.TSDB.RETENTION.SIZE
[EXPERIMENTAL]试验性的。存储为块的最大字节数,需要使用一个单位,支持:B, KB, MB, GB,TB, PB, EB
此标签处于试验中,未来版本会改变
--storage.tsdb.no-lockfile
不在data目录下创建锁文件
--storage.tsdb.allow-overlapping-blocks
[EXPERIMENTAL]试验性的。允许重叠块,可以支持垂直压缩和垂直查询合并。
--storage.tsdb.wal-compression
压缩tsdb的WAL
WAL(Write-ahead logging, 预写日志),WAL被分割成默认大小为128M的文件段(segment),之前版本默认大小是256M,文件段以数字命名,长度为8位的整形。WAL的写入单位是页(page),每页的大小为32KB,所以每个段大小必须是页的大小的整数倍。如果WAL一次性写入的页数超过一个段的空闲页数,就会创建一个新的文件段来保存这些页,从而确保一次性写入的页不会跨段存储。
--storage.remote.flush-deadline=
关闭或者配置重载时刷新示例的等待时长
--storage.remote.read-sample-limit=5e7
在单个查询中通过远程读取接口返回的最大样本总数。0表示无限制。对于流式响应类型,将忽略此限制。
--storage.remote.read-concurrent-limit=10
最大并发远程读取调用数。0表示无限制。
--storage.remote.read-max-bytes-in-frame=1048576
在封送处理之前,用于流式传输远程读取响应类型的单个帧中的最大字节数。请注意,客户机可能对帧大小也有限制。
默认情况下,protobuf建议使用1MB。
告警规则相关参数
--rules.alert.for-outage-tolerance=1h
允许prometheus中断以恢复“for”警报状态的最长时间。
--rules.alert.for-grace-period=10m
警报和恢复的“for”状态之间的最短持续时间。这仅对配置的“for”时间大于宽限期的警报进行维护。
--rules.alert.resend-delay=1m
向Alertmanager重新发送警报之前等待的最短时间。
告警管理中心相关参数
--alertmanager.notification-queue-capacity=10000
挂起的Alertmanager通知的队列容量。
默认值:10000
--alertmanager.timeout=10s
发送告警到Alertmanager的超时时间
默认值:10s
数据查询参数
--query.lookback-delta=5m
通过表达式解析和联合检索指标的最大反馈时间
默认值:5m
--query.timeout=2m
查询中止前可能需要的最长时间。
默认值:2m
这两项是对用户执行prometheus查询适合的优化设置,防止太多用户同时查询,也防止单个用户执行过大的查询而一直不退出。
--query.max-concurrency=20
并发(concurrently)执行查询的最大值
--query.max-samples=50000000
单个查询可以加载到内存中的最大样本数。注意,如果查询试图将更多的样本加载到内存中,则会失败,因此这也限制了查询可以返回的样本数。
数量级:5千万
日志信息参数
--log.level=info
仅记录给定的日志级别及以上的信息
可选参数值:[debug, info, warn, error],其中之一
--log.format=logfmt
日志信息输出格式
可选参数值:[logfmt, json],其中之一
二. 集群环境
2.1 Linux Centos环境准备
虚拟机:Virtualbox
系统:Centos-7
安装包
grafana-enterprise-9.3.6.linux-amd64.tar.gz
prometheus-2.37.6.linux-amd64.tar.gz
node_exporter-1.5.0.linux-amd64.tar.gz
mysqld_exporter-0.14.0.linux-amd64.tar.gz
promenthues和exporter的下载地址:https://prometheus.io/download/
主机时间与系统时间同步
主机信息:
IP地址(NAT)
主机名
大小
安装服务
角色
192.168.4.39
monitor-1
20G
Prometheus、Grafana、node_exporter、
mysqld_exporter
服务端、被监控端
192.168.4.81
monitor-2
20G
node_exporter
被监控端
2.2 修改主机hostname
- 本例中Linux操作系统为 centos 7,可使用自带的hostnamectl修改hostname
hostname monitor-1 #临时生效
hostnamectl set-hostname montior-1 #永久生效
hostname monitor-2
hostnamectl set-hostname monitor-2
# hostname立即生效
bash
- 在2台主机的host文件追加主机映射关系
vim /etc/hosts
192.168.0.17 monitor-1
192.168.0.18 monitor-2
- 关闭selinux
setenforce 0
sed -i 's/enforcing/disabled/' /etc/selinux/config
三. 服务端安装Prometheus
3.1 解压安装prometheus
- 下载安装长期支持稳定版本的prometheus
官网下载地址:https://prometheus.io/download/

wget https://github.com/prometheus/prometheus/releases/download/v2.37.6/prometheus-2.37.6.linux-amd64.tar.gz
tar xf prometheus-2.37.6.linux-amd64.tar.gz
mv prometheus-2.37.6.linux-amd64 /usr/local/prometheus
# 为了便于管理,执行以下步骤
mkdir /usr/local/prometheus/{data,conf,bin}
cd /usr/local/prometheus/
mv prometheus promtool ./bin/
mv prometheus.yml ./conf/
chown -R root:root /usr/local/prometheus/
- 配置环境变量
vim /etc/profile
PATH=/usr/local/prometheus/bin:$PATH:$HOME/bin
# 环境变量生效
source /etc/profile
# 查看版本
prometheus --version
prometheus, version 2.37.6 (branch: HEAD, revision: 8ade24a23af6be0f35414d6e8ce09598446c29a2)
build user: root@5f96027a7c3e
build date: 20230220-09:36:40
go version: go1.19.6
platform: linux/amd64

3.2 配置Prometheus系统服务
- 系统服务文件配置时设置prometheus启动参数
vim /lib/systemd/system/prometheus.service
[Unit]
Description=Prometheus
Documentation=https://prometheus.io/docs/introduction/overview/
After=network.target
[Service]
Type=simple
User=root
ExecStart=/usr/local/prometheus/bin/prometheus --config.file=/usr/local/prometheus/conf/prometheus.yml --web.enable-lifecycle --storage.tsdb.path=/usr/local/prometheus/data --storage.tsdb.retention.time=30d --log.level=info --log.format=logfmt
Restart=on-failure
[Install]
WantedBy=multi-user.target
# Prometheus启动参数说明:
--config.file # 指明prometheus的配置文件路径
--web.enable-lifecycle # 指明prometheus配置更改后可以进行热加载
--storage.tsdb.path # 指明监控数据存储路径
--storage.tsdb.retention.time # 指明样例数据保留时间
--log.level=info # 记录给定的日志级别及以上信息(生产环境建议 warn 级别)
--log.format=logfmt # 日志消息输出格式
# 说明:
prometheus在2.0之后默认的热加载配置没有开启, 配置修改后需要重启prometheus server才能生效, 对于生产环境的监控是不可行的, 所以需要开启prometheus server配置的热加载功能。
在启动prometheus时加上参数“web.enable-lifecycle”,可以启用配置的热加载;配置修改后热重载命令:curl -X POST http://localhost:9090/-/reload
- 重新加载systemd系统,查看服务是否启动
systemctl daemon-reload
systemctl start prometheus
systemctl enable prometheus

- 开放防火墙端口
# 添加端口
firewall-cmd --zone=public --add-port=9090/tcp --permanent
# 重新载入
firewall-cmd --reload
3.3 修改Prometheus的配置文件
- 编辑 prometheus.yml 配置文件
# 全局配置(如果有内部单独设定,会覆盖这个参数)
global:
scrape_interval: 1m # 表示抓取一次数据的间隔时间,默认1m。
evaluation_interval: 1m # 表示进行告警规则检测的间隔时间,默认1m。
scrape_timeout: 30s # 每次数据拉取超时时间,默认10s。
# 告警插件定义。这里会设定alertmanager这个报警插件。
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# 指定加载的告警规则文件。按照设定参数进行扫描加载,用于自定义报警规则,其报警媒介和route路由由alertmanager插件实现。
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# 收集数据配置列表,在配置字段内可以配置拉取数据的对象(Targets)、job以及实例采集配置。又分为静态配置和服务发现。
scrape_configs:
- job_name: "prometheus" # 定义唯一的job的名称:'prometheus'
honor_labels: true # 标签冲突,true为以抓取的数据为准并忽略服务器中的,false为通过重命名来解决冲突。
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"] # 这是prometheus本机的一个监控节点
其大致分为四部分:
global:全局配置。
alerting:告警管理器(Alertmanager)的配置,目前还没有安装Alertmanager。
rule_files:告警规规则文件,可以使用通配符。
scrape_configs:指定prometheus要监控的目标。一个 job_name 就是一个目标,其 targets 就是采集信息的IP和端口。这里默认监控了Prometheus自己,可以通过修改这里来修改Prometheus的监控端口。
Prometheus的每个 exporter 都会是一个目标,它们可以上报不同的监控信息,比如机器状态、或者mysql性能等等,不同语言sdk也会是一个目标,它们会上报自定义的业务监控信息。
- job_name: 'aliyun'
static_configs:
- targets: ['server01:9100','IP:9100','nginxserver:9100','web006:9100','redis:9100','logserver:9100','redis1:9100']
targets可以并列写入多个节点,用逗号隔开,机器名+端口号,端口号主要是exporters的端口,在这里9100其实是node_exporter的默认端口。配置完成后,prometheus就可以通过配置文件识别监控的节点,持续开始采集数据,prometheus基础配置也就搭建好了。
scrape_configs 主要用于配置拉取数据节点,每一个拉取配置主要包含以下参数:
job_name:任务名称
honor_labels: 用于解决拉取数据标签有冲突,当设置为 true, 以拉取数据为准,否则以服务配置为准
params:数据拉取访问时带的请求参数
scrape_interval: 拉取时间间隔
scrape_timeout: 拉取超时时间
metrics_path: 拉取节点的 metric 路径
scheme: 拉取数据访问协议
sample_limit: 存储的数据标签个数限制,如果超过限制,该数据将被忽略,不入存储;默认值为0,表示没有限制
relabel_configs: 拉取数据重置标签配置
metric_relabel_configs:metric 重置标签配置
- prometheus配置语法校验
建议每次修改prometheus配置之后,都进行语法校验,以免导致prometheus server无法启动。
promtool check config prometheus.yml
Checking prometheus.yml
SUCCESS: prometheus.yml is valid prometheus config file syntax
- 热重载prometheus配置
curl -X POST http://localhost:9090/-/reload
3.4 通过浏览器访问Prometheus监听页面
- 运行后,在浏览器访问机器IP:端口就可以查看Prometheus的界面了,这里的机器IP是运行Prometheus服务的主机,端口是上面配置文件中配置的监控自己的端口。打开后界面如下:http://192.168.4.39:9090
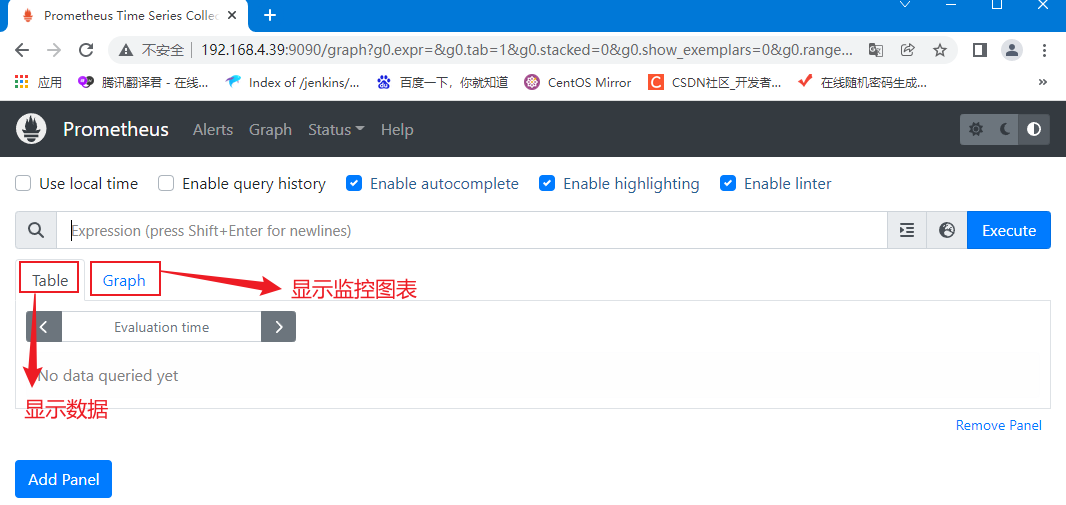
界面非常简单(所以还需要安装Grafana),上面标签栏中:
Alerts 是告警管理器,还没安装;
Graph 是查看监控项的图表,也是访问后的默认页面;
Status 中可以查看一些配置、监控目标、告警规则等。
- 在Graph页面,由于默认已经监控了Prometheus自己,所以可以直接查看一些监控数据。比如在输入框输入 promhttp_metric_handler_requests_total,点击 Execute,下面的小标签中切换到Graph就能看到“/metrics”访问次数的折线图。
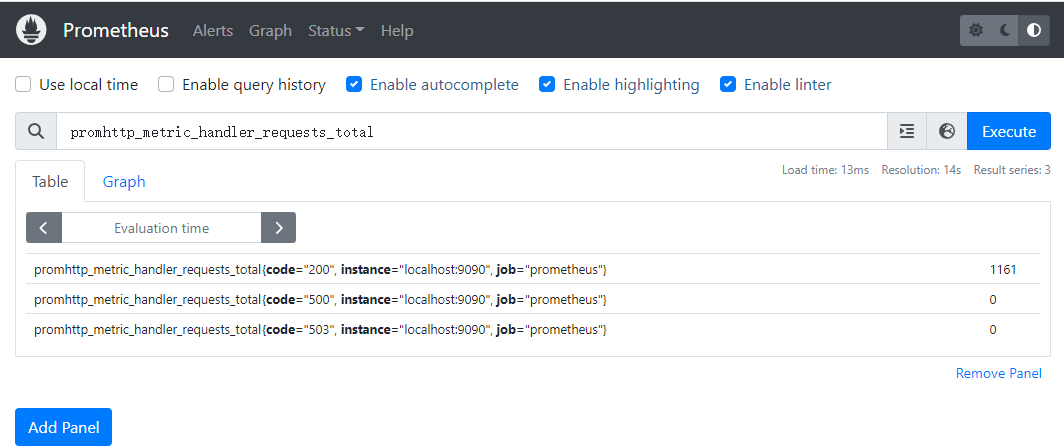
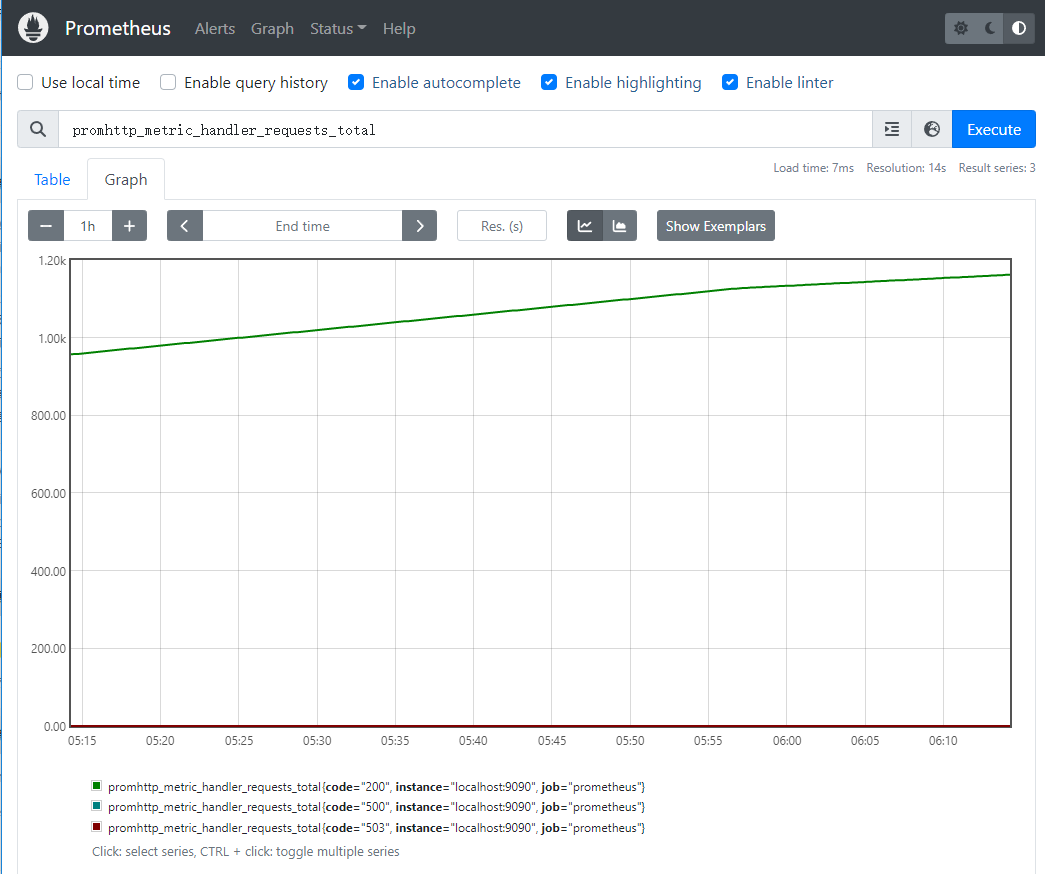
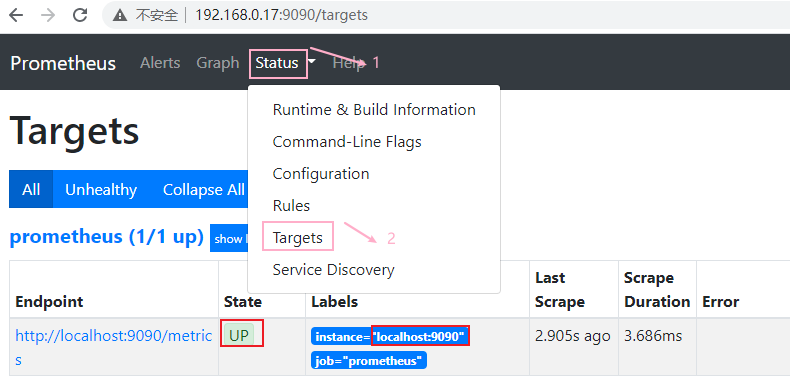
- 通过下面的步骤可以查看到prometheus自己的监控状态
四. 二进制安装node-exporter采集系统数据
Linux 环境下系统级采集数据,监控当前机器自身的状态,包括硬盘、CPU、流量等;Prometheus已经有了很多现成的常用exporter,所以可以直接用其中的node_exporter。
注意:node_exporter跟nodejs没有任何关系,在Prometheus看来,一台机器或者说一个节点就是一个node,所以该exporter是在上报当前节点的状态。
4.1 被监控端安装node_exporter
- 可以到下载页面选择对应的二进制安装包,在被监控节点安装node_exporter
wget https://github.com/prometheus/node_exporter/releases/download/v1.5.0/node_exporter-1.5.0.linux-amd64.tar.gz
tar xf node_exporter-1.5.0.linux-amd64.tar.gz
mkdir /usr/local/exporter
mv node_exporter-1.5.0.linux-amd64 /usr/local/exporter/node_exporter
chown -R root.root /usr/local/exporter/node_exporter/
- 配置node_exporter启动服务
vim /lib/systemd/system/node_exporter.service
[Unit]
Description=node_exporter
Documentation=https://prometheus.io/
After=network.target
[Service]
Type=simple
User=root
ExecStart=/usr/local/exporter/node_exporter/node_exporter
Restart=on-failure
[Install]
WantedBy=multi-user.target
# 启动服务
systemctl daemon-reload
systemctl start node_exporter
systemctl enable node_exporter
- 开放防火墙端口
# 添加
firewall-cmd --zone=public --add-port=9100/tcp --permanent
# 重新载入
firewall-cmd --reload
- 验证安装完成之后的数据,访问:http://IP:9100/metrics
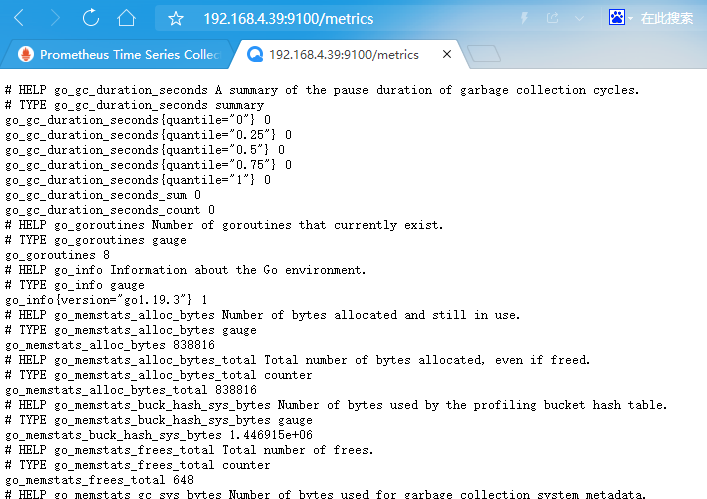

4.2 在prometheus配置node_exporter
为了更好的展示,将被监控端的node_exporter配置到prometheus server中,后面并通过grafana进行展示。
- 将node_exporter加入 prometheus.yml 配置文件中
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: "prometheus"
honor_labels: true
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
- job_name: "node_exporter" # 取一个job名称代表被监控的机器,此名称后面可在Grafana与Prometheus上查看管理。
honor_labels: true
static_configs:
- targets: ['192.168.4.39:9100','192.168.4.81:9100'] # 多节点的情况下使用逗号 , 号分隔。
- 重启Prometheus服务
# 检查配置文件
promtool check config prometheus.yml
systemctl restart prometheus
# 为了不影响正在运行的Prometheus服务,建议使用下面命令热重载服务
curl -X POST http://localhost:9090/-/reload
- 验证Prometheus数据采集
在标签栏的Status-->Targets中可以看到多了一个状态node_exporter (2/2 up);
如果新加的target的State是UP的话,就说明监听成功了。
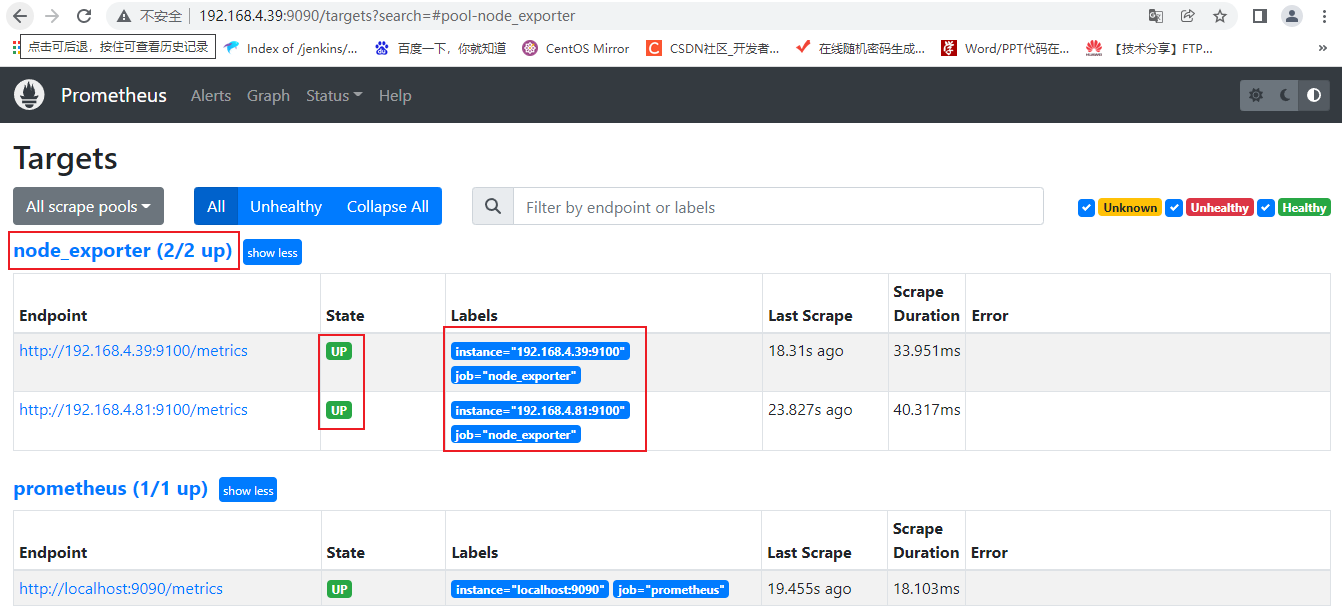
此时在Graph中,输入框输入node可以发现有很多node开头的监控项,都是和机器状态有关的,执行后可以看到2个被监控端的node_exporter数据采集的结果。


以上 node_exporter 已安装完毕,并且数据采集已更新至Prometheus。
五. 服务端安装配置可视化页面:Grafana
因为Prometheus的界面看起来比较简单,所以还需要Grafana这个监控展示框架。
5.1 安装Grafana
- 去官网下载安装Grafana
wget https://dl.grafana.com/enterprise/release/grafana-enterprise-9.3.6.linux-amd64.tar.gz
tar -zxvf grafana-enterprise-9.3.6.linux-amd64.tar.gz
mv grafana-9.3.6/ /usr/local/grafana
Grafana默认运端口为3000,可以通过配置文件进行修改;
可复制conf/defaults.ini文件为custom.ini,然后在这个配置文件里自定义修改配置项。
- 设置系统服务
# 配置环境变量
vim /etc/profile
export GRAFANA_HOME=/usr/local/grafana
export PATH=$GRAFANA_HOME/bin:$PATH
source /etc/profile
# 增加grafana系统服务
vim /etc/systemd/system/grafana-server.service
[Unit]
Description=grafana-server
After=network.target
[Service]
Type=notify
User=root
ExecStart=/usr/local/grafana/bin/grafana-server -homepath /usr/local/grafana/
Restart=on-failure
[Install]
WantedBy=multi-user.target
# 启动服务
systemctl daemon-reload
systemctl start grafana-server
systemctl enable grafana-server
- 开放防火墙
# 添加
firewall-cmd --zone=public --add-port=3000/tcp --permanent
# 重新载入
firewall-cmd --reload
5.2 接入prometheus数据源
管理员的账号/密码默认是admin/admin,首次登录后强制修改密码。
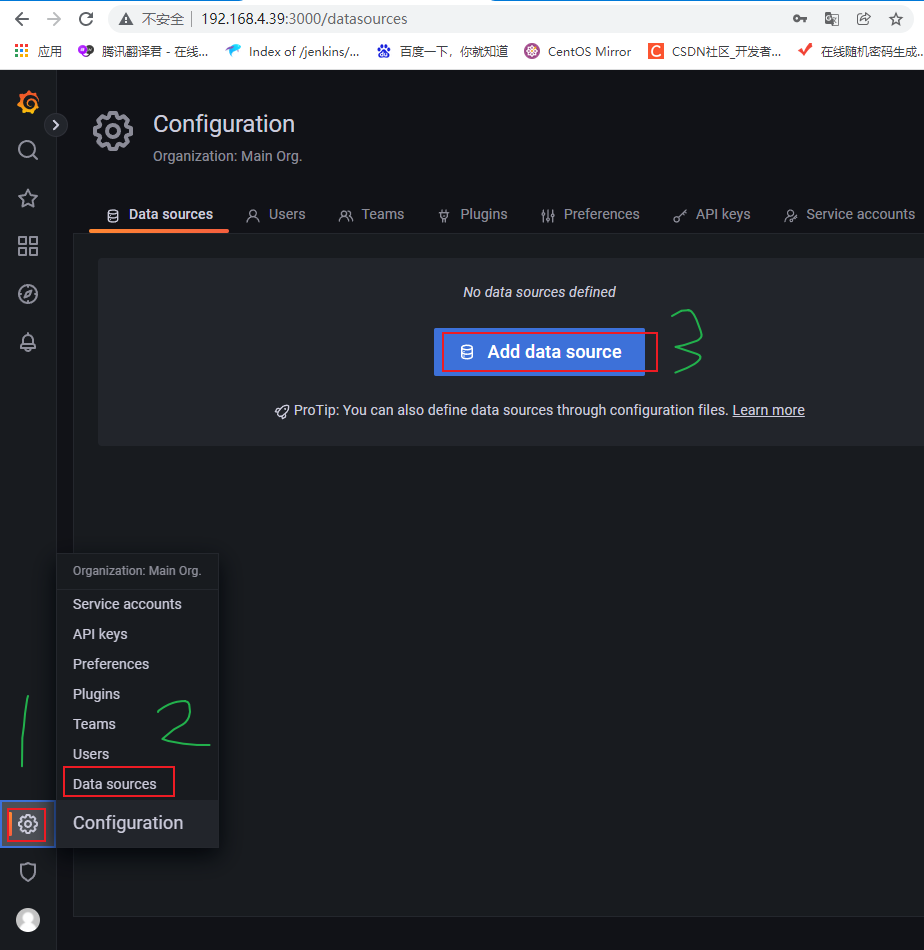
- 进入grafana后,左边选择设置图标中的Data Source,选择添加Prometheus的数据源。
- URL填写Prometheus Server的ip:端口,如果没修改且在本机运行的话,可默认为localhost:9090。
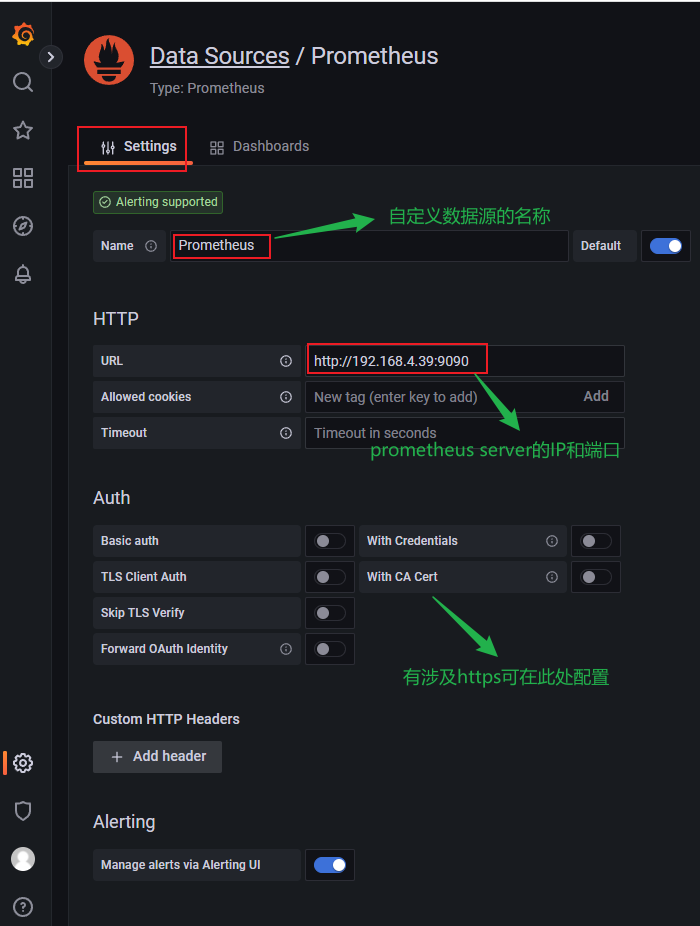
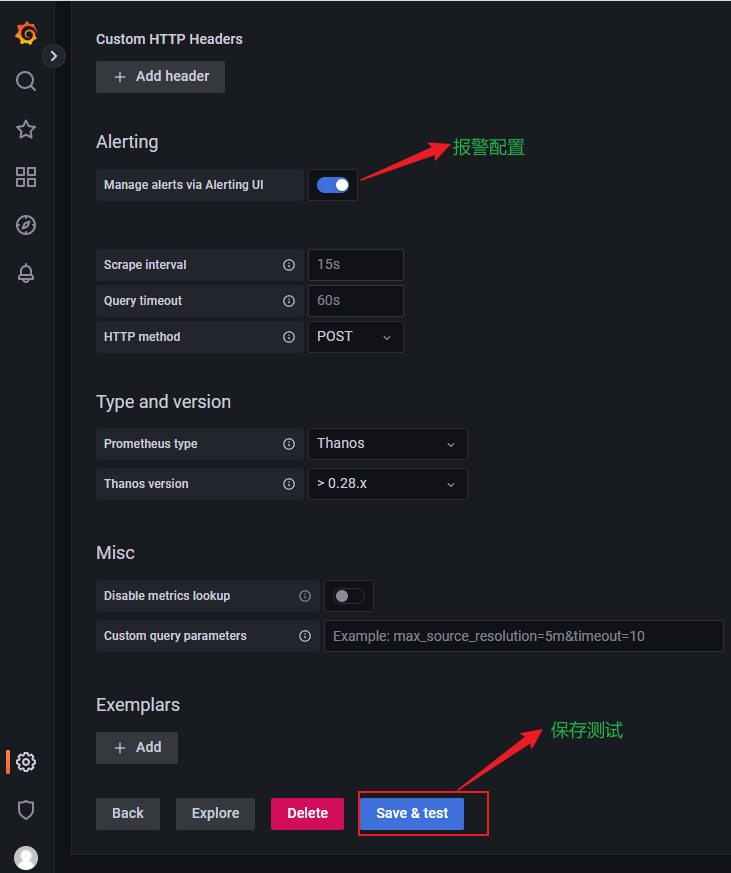
测试并保存,如果此处测试没有问题则返回working,如果有问题,则排查防火墙限制和Prometheus的UI地址。
- 查看已添加的数据源,可以点击进入修改或删除。

以上Grafana 已安装完成,并已配置接入prometheus 数据源。
六. node_exporter采集与Grafana显示
配置Grafana与Prometheus数据源模板,系统级采集数据使用node_exporter。
6.1 查看Grafana自带的Prometheus监控面板
- 此时在grafana自带的dashboard,也就是监控面板,查看Prometheus的数据展示。
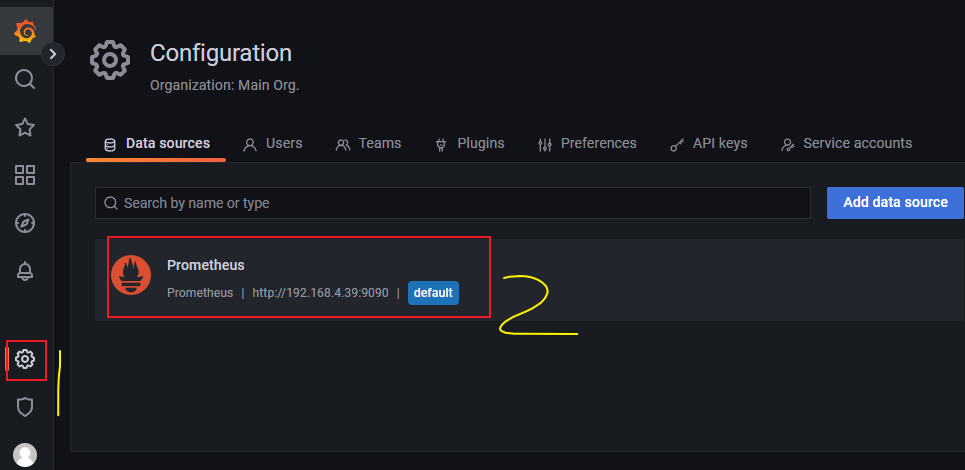
- 有3个监控面板可以直接点击进去查看效果
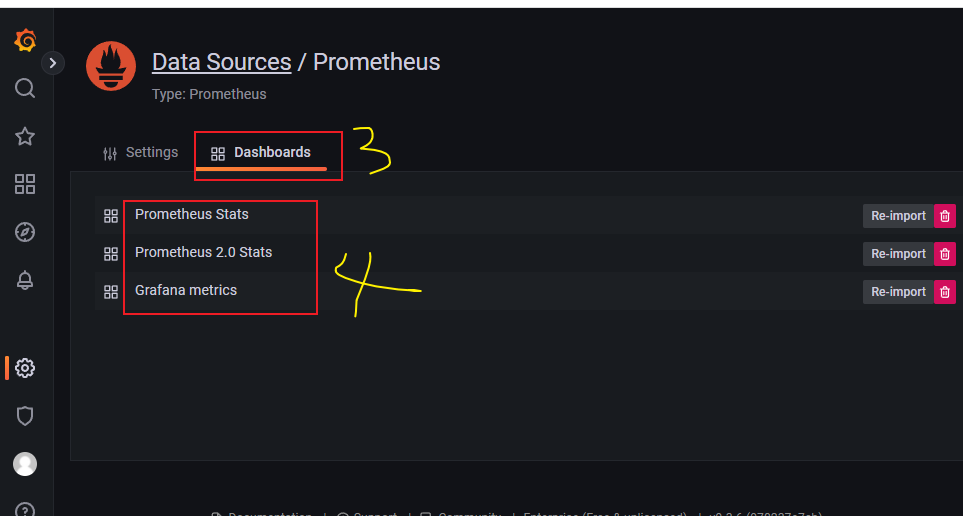

6.2 导入下载的监控面板
- 在Grafana的官方面板页面可以看到很多别人配置好的面板,面板中的每个图都是可以编辑的,也可以设置告警。可以在左边根据自己的要求搜索出喜欢的面板样式,一般选择评分高、下载多的。

- 进入到心仪面板的详情页面,比如这个node_exporter模板。
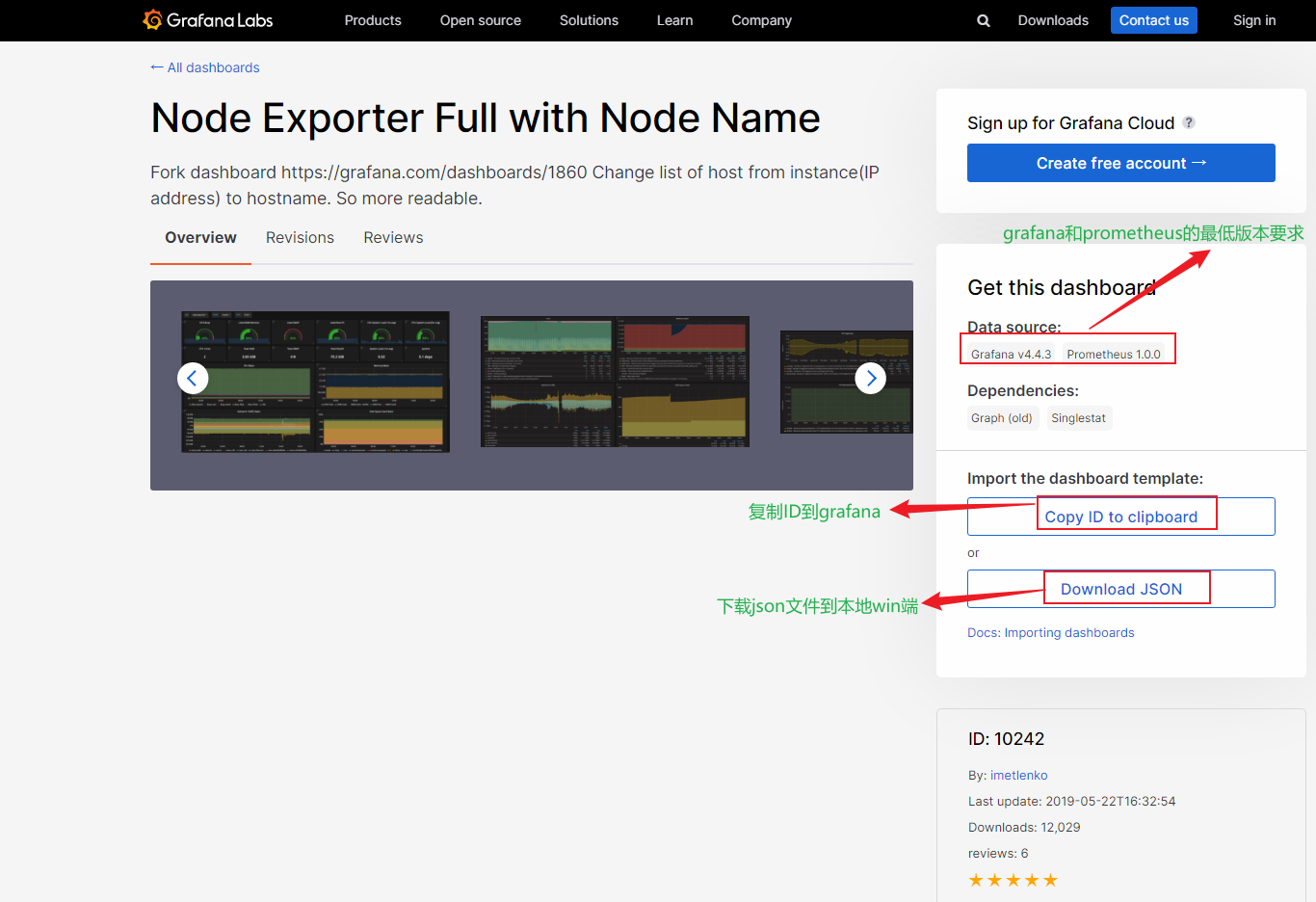
- 前面配置运行了node_exporter,为了更好的展现这个监控数据,点击图标中的Import,配置导入模板。
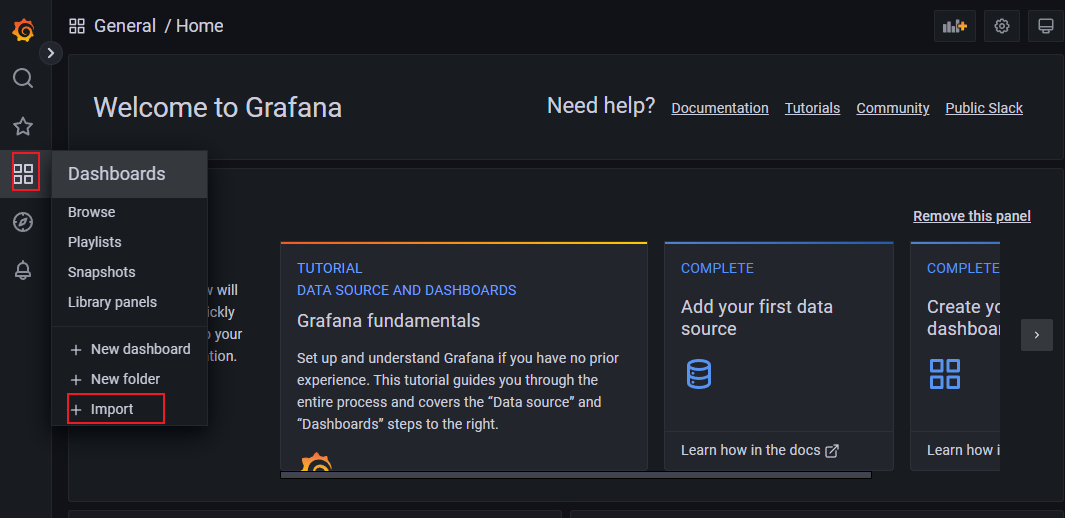
- 复制面板ID,然后在Import界面输入ID,导入下载好的json文件,并配置Prometheus数据源。
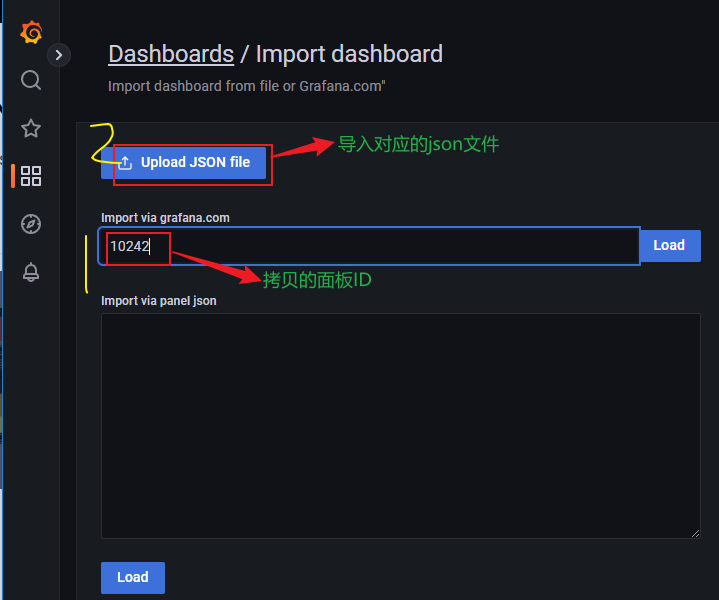
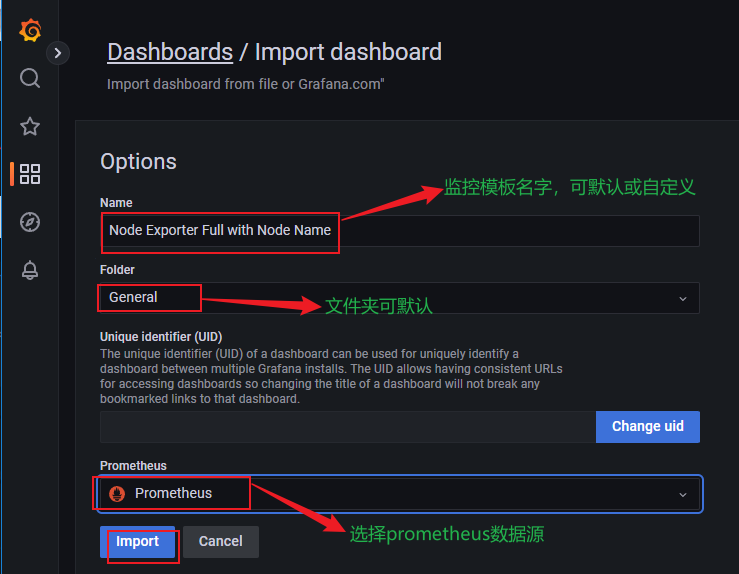
配置后即可看到系统主机节点监控信息,包括系统运行时间, 内存和CPU的配置, CPU、内存、磁盘、网络流量等信息, 以及磁盘IO、CPU温度等信息。
- 模板导入完成之后,会出现下图,表示Node_exporter的采集数据已通过prometheus数据源在grafana展示成功。
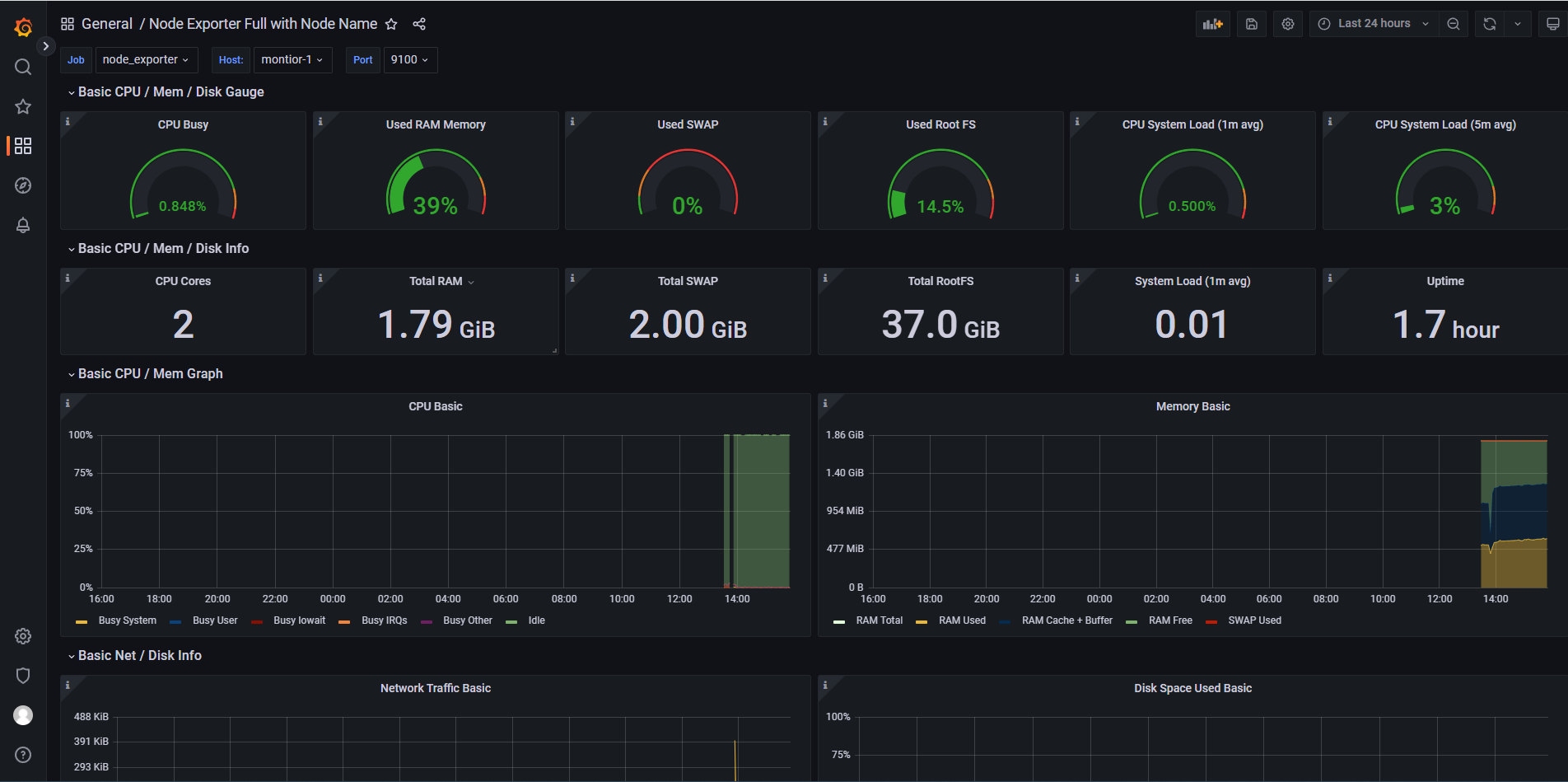
- 刚才添加的模板可在此处查看。
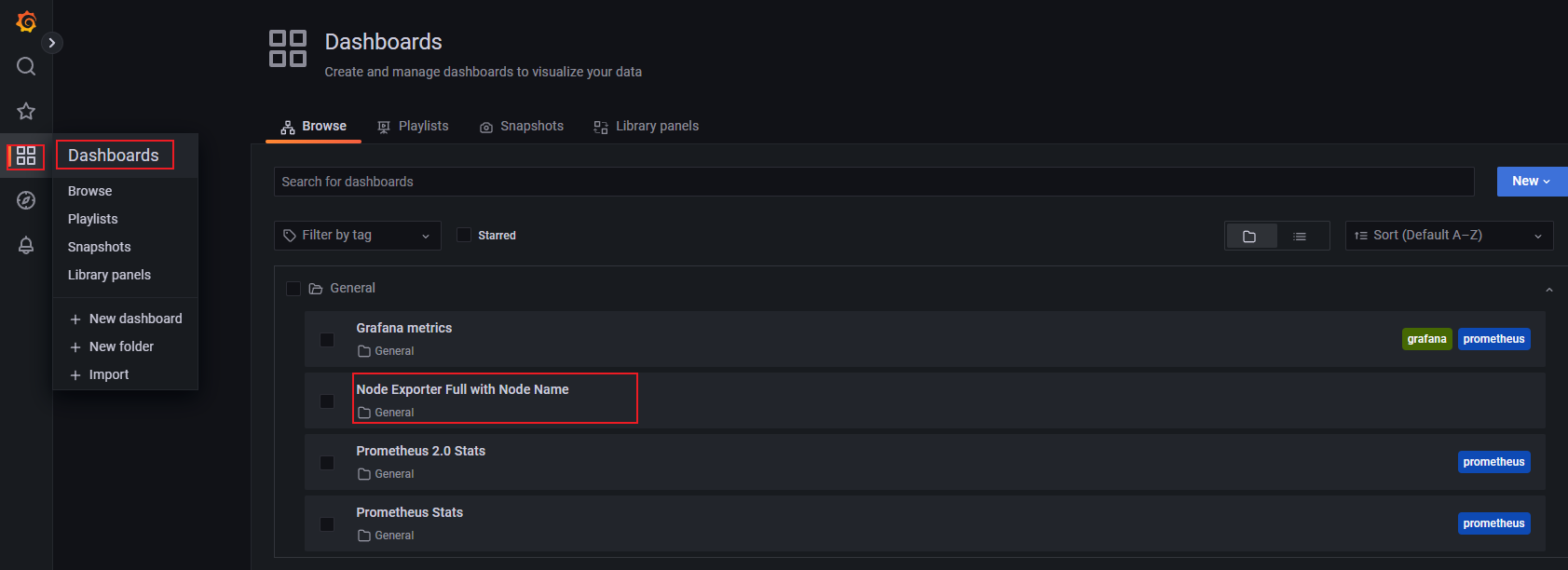
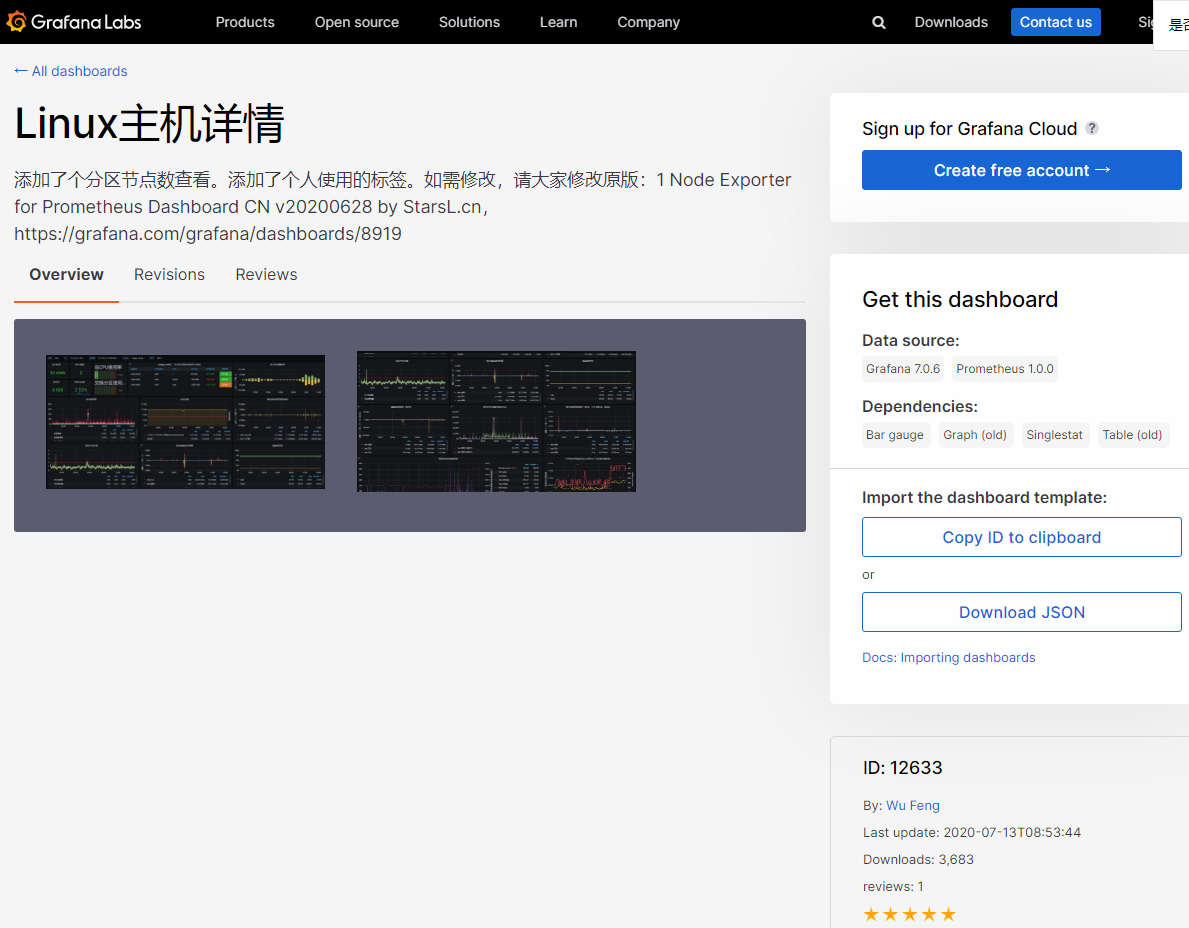
- 大家还可以根据自己要求去选择不同的监控模板,或者编辑模板。例如,下面导入了一个node_exporter中文监控模板。

七. 二进制安装Mysqld_exporer
如果需要利用Prometheus监控MySQL只需选择相应的Exporter即可,选择mysqld_exporter来采集MySQL的监控数据。
因为提前在192.168.4.39安装了mysql服务,正好可以在这台主机上测试mysql的监控测试。
7.1 被监控端安装mysqld_exporter
- 可以到下载页面选择对应的二进制安装包,在被监控节点安装mysqld_exporter
tar xf mysqld_exporter-0.14.0.linux-amd64.tar.gz
mv mysqld_exporter-0.14.0.linux-amd64 /usr/local/exporter/mysqld_exporter
chown -R root.root /usr/local/exporter/mysqld_exporter/
- 在mysql服务建立指定监控用户
mysql> grant select,replication client, process on *.* to 'mysql_monitor'@'%' identified by 'abc123';
Query OK, 0 rows affected, 1 warning (0.03 sec)
mysql> flush privileges;
Query OK, 0 rows affected (0.00 sec)
- 编辑mysql的配置文件
vim /usr/local/exporter/mysqld_exporter/mysqld_exporter.cnf
[client]
host = 192.168.4.39
port = 3306
user = mysql_monitor
password = abc123
- 配置mysqld_exporter启动服务
vim /usr/lib/systemd/system/mysqld_exporter.service
[Unit]
Description=Prometheus MySQL daemon
Documentation=https://prometheus.io
After=network.target
[Service]
Type=simple
User=root
ExecStart=/usr/local/exporter/mysqld_exporter/mysqld_exporter --config.my-cnf=/usr/local/exporter/mysqld_exporter/mysqld_exporter.cnf --web.listen-address=:9104
Restart=on-failure
[Install]
WantedBy=multi-user.target
# 启动服务
systemctl daemon-reload
systemctl start mysqld_exporter
systemctl enable mysqld_exporter
- 开放端口
# 添加
firewall-cmd --zone=public --add-port=9104/tcp --permanent
# 重新载入
firewall-cmd --reload
7.2 在prometheus中接入mysqld_exporter
- 在prometheus.yml文件末尾处中配置mysqld_exporter
vim /usr/local/prometheus/conf/prometheus.yml
scrape_configs:
- job_name: "prometheus"
honor_labels: true
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
- job_name: "node_exporter"
honor_labels: true
static_configs:
- targets: ['192.168.4.39:9100','192.168.4.81:9100']
- job_name: "mysqld_exporter"
honor_labels: true
static_configs:
- targets: ['192.168.4.39:9104']
- 重启prometheus
# 检查配置文件
promtool check config prometheus.yml
# 热重载服务
curl -X POST http://localhost:9090/-/reload
- 在标签栏的Status-->Targets中可以看到多了一个状态mysqld_exporter (1/1 up);如果新加的target的State是UP的话,就说明监听成功了。

7.3 在grafana中导入mysqld_exporter的dashboard并展示
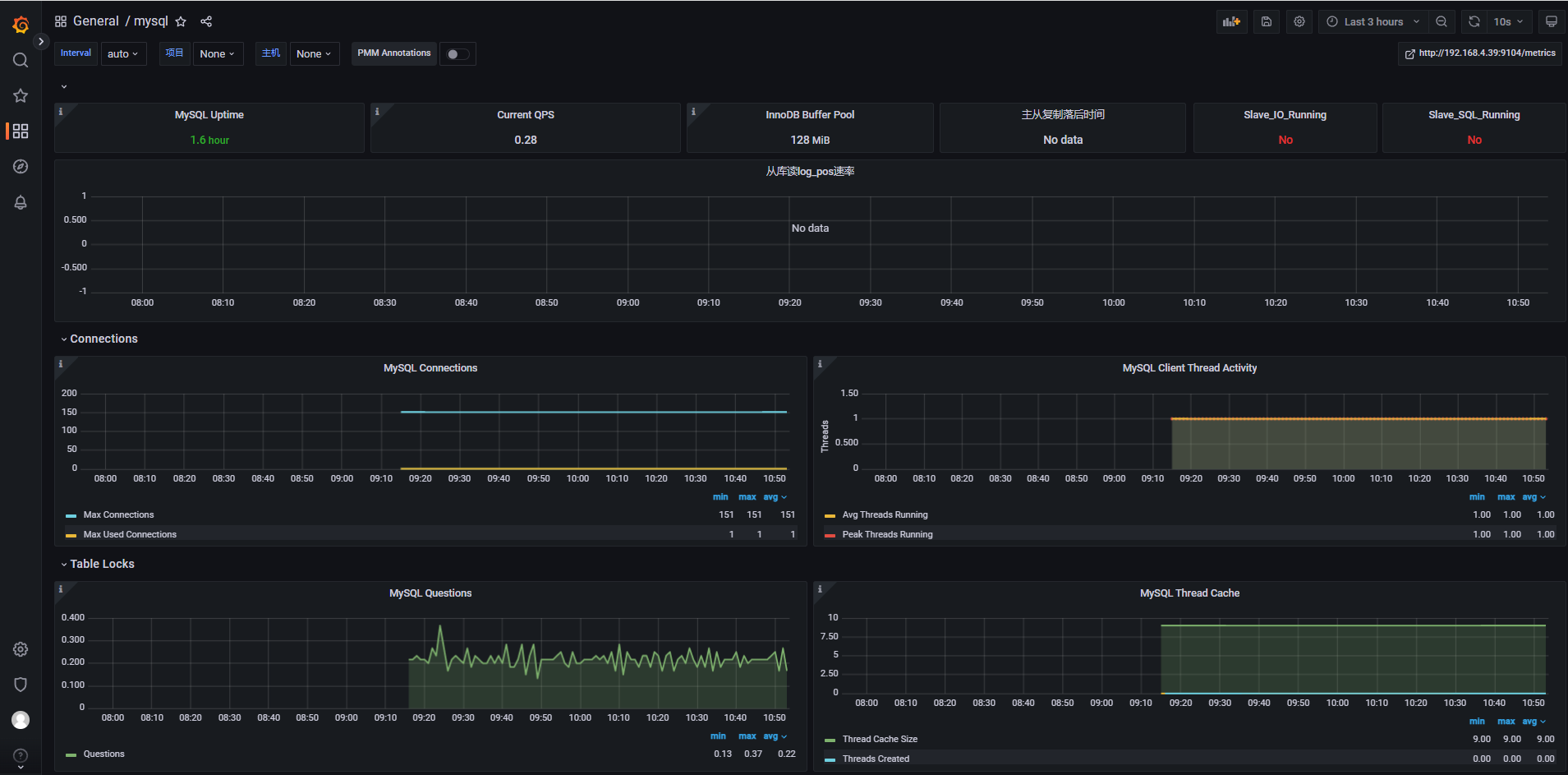
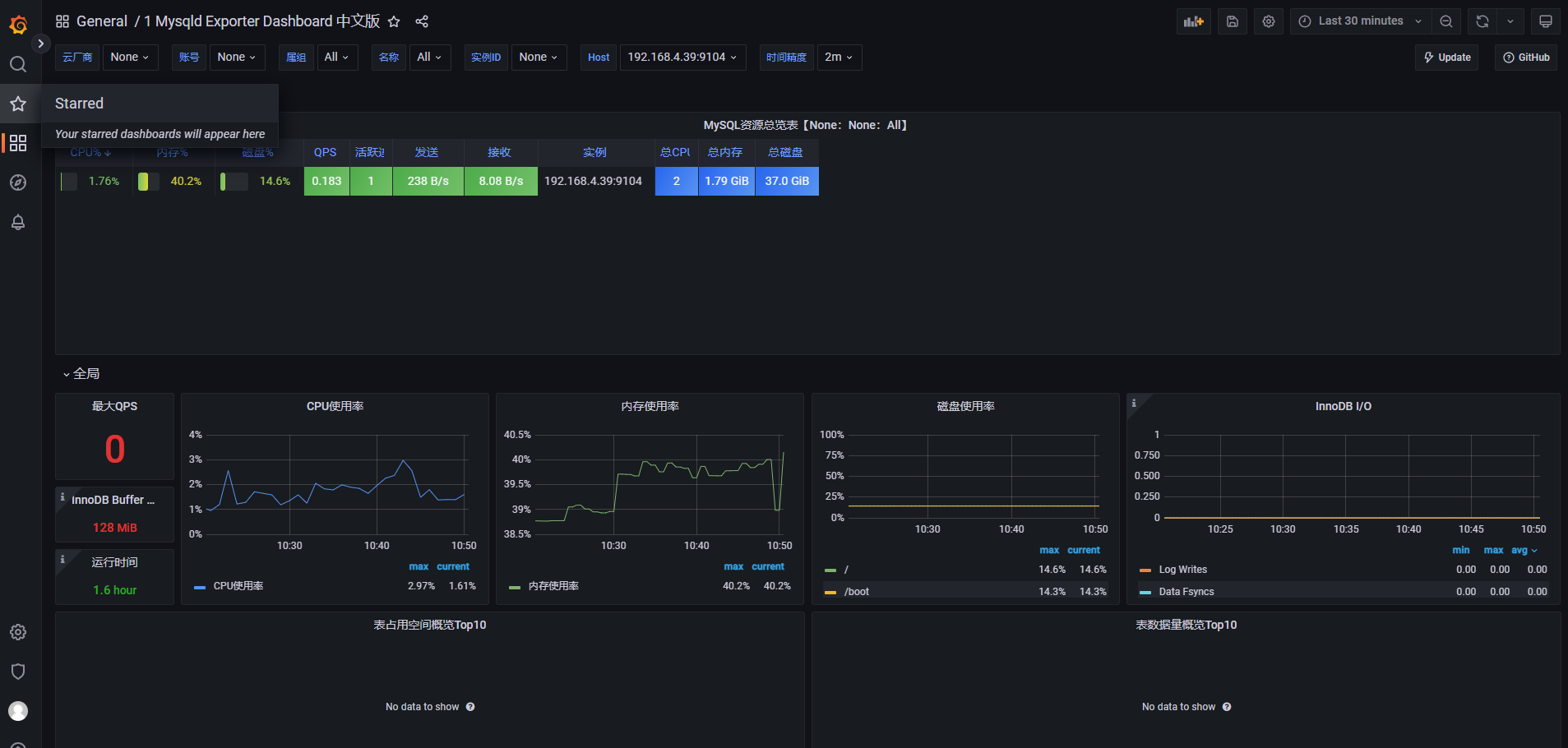
- 在Grafana的官方面板页面搜索出喜欢的mysqld_exporter面板样式。
①. 例如导入这个关系型数据库的各种信息数据的mysqld_exporter监控面板。
②. 也可以导入Mysqld Exporter Dashboard 中文版。
- 导入两个模板查看数据展示效果
八. 容器部署cAdvisor,收集容器节点信息
如果需要利用Prometheus监控docker容器,只需选择相应的Exporter即可,选择cAdvisor来采集容器节点的监控数据。
cadvisor(容器顾问)不仅可以搜集⼀台机器上所有运行的容器信息,还提供基础查询界⾯和http接口,方便其他组件如Prometheus进行数据抓取,cAdvisor可以对节点机器上的容器进行实时监控和性能数据采集,包括容器的CPU使用情况、内存使用情况、网络吞吐量及文件系统使用情况。
在192.168.0.7安装了docker服务,正好可以在这台主机上测试容器节点监控。
8.1 被监控端安装cAdvisor
- 在被监控节点安装cadvisor容器,
# 替换镜像为阿里云镜像
docker pull registry.cn-hangzhou.aliyuncs.com/liangxiaohui/cadvisor-amd64:v0.45.0
# docker容器部署
docker run -it -d --restart always --volume=/:/rootfs:ro --volume=/var/run:/var/run:ro --volume=/sys:/sys:ro --volume=/var/lib/containerd/:/var/lib/containerd:ro --volume=/dev/disk/:/dev/disk:ro --publish=8080:8080 --detach=true --name=cadvisor -h=cadvisor --privileged --device=/dev/kmsg registry.cn-hangzhou.aliyuncs.com/liangxiaohui/cadvisor-amd64:v0.45.0
- 部署后浏览器访问IP:8080

- 开放端口
# 添加
firewall-cmd --zone=public --add-port=8080/tcp --permanent
# 重新载入
firewall-cmd --reload
8.2 在prometheus中接入cAdvisor
- 在prometheus.yml文件末尾处中配置cAdvisor
vim /usr/local/prometheus/conf/prometheus.yml
scrape_configs:
- job_name: "prometheus"
honor_labels: true
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ["localhost:9090"]
- job_name: "node_exporter"
honor_labels: true
static_configs:
- targets: ['192.168.4.39:9100','192.168.4.81:9100']
- job_name: "mysqld_exporter"
honor_labels: true
static_configs:
- targets: ['192.168.4.39:9104']
- job_name: "docker"
honor_labels: true
static_configs:
- targets: ['192.168.4.39:8080']
- 重启prometheus
# 检查配置文件
promtool check config prometheus.yml
# 热重载服务
curl -X POST http://localhost:9090/-/reload
- 在标签栏的Status-->Targets中可以看到多了一个状态docker (1/1 up);如果新加的target的State是UP的话,就说明监听成功了。
8.3 在grafana中导入容器的dashboard并展示
略(参考上面mysql和node即可)
版权归原作者 一二三,开花 所有, 如有侵权,请联系我们删除。