
端口号说明
4040(计算):Spark 查看当前 Spark-shell 运行任务情况;
8080(资源):Standalone 模式下,Spark Master Web端口号;
7077:Spark Master 内部通信服务;
18080:Spark 历史服务器端口号;
8088:Hadoop YARN 任务运行情况查看端口号。
spark核心模块
spark SQL、spark Streaming、spark GraphX、spark MLlib
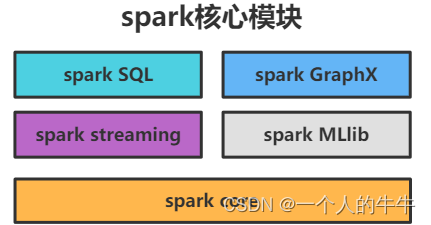
spark core
Spark Core 提供了 Spark 最基础与最核心的功能。
Spark 其他的功能都是在 Spark Core 的基础上进行扩展的。
spark SQL
Spark SQL 是 Spark 用来操作结构化数据的组件。
通过 Spark SQL,用户可以使用 SQL 或HQL(hive)来查询数据。
spark streaming
Spark Streaming 是 Spark 平台上针对实时数据进行流式计算的组件。
spark streaming提供了丰富的处理数据流的 API。
MLlib
MLlib 是 Spark 提供的一个机器学习算法库。
GraphX
GraphX 是 Spark 面向图计算提供的框架与算法库。
spark核心组件
Spark的核心是一个计算引擎。
driver
driver是spark驱动器节点,用于执行 spark 任务中的 main 方法,负责实际代码的执行工作。
简单理解,driver 就是驱使整个应用运行起来的程序。
主要负责:
(1)将用户程序转化为作业(job);
(2)在 Executor 之间调度任务(task) ;
(3)跟踪 Executor 的执行情况;
(4)通过 UI 展示查询运行情况。
executor
executor是集群中Worker的一个 JVM 进程,负责在 Spark 作业中运行具体任务,任务之间相互独立。
Spark应用启动,Executor节点同时启动,且存在于Spark应用的生命周期。
如果有Executor节点发生了故障或崩溃,spark会将出错节点上的任务调度到其他 Executor节点上继续运行。
Executor核心功能:
(1)负责运行组成 Spark 应用的任务,并将结果返回给驱动器;
(2)为用户程序中要求缓存的 RDD 提供内存式存储;
(3)RDD直接缓存在Executor进程内,任务可以在运行时充分利用缓存数据加速运算。
Master&Worker
Master 和 Worker:这里的 Master 是一个进 程,主要负责资源的调度和分配,进行集群监控等;Worker也是进程,一个Worker运行在集群中的一台服务器上,Master分配资源Worker对数据进行并行的处理和计算。
ApplicationMaster
ApplicationMaster用于向资源调度器申请执行任务的资源容器Container,运行用户自己的程序任务 job,监控整个任务的执行,跟踪整个任务的状态,处理任务失败等异常情况。
运行架构
Driver:负责管理整个集群中的作业任务调度。
Executor:负责实际执行任务。

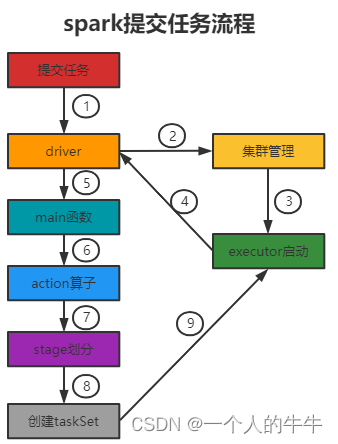
提交任务流程
一般会有两种部署执行的方式:Client 和 Cluster
两种模式主要区别在于:Driver程序的运行节点位置。Client模式将用于监控和调度的Driver模块在客户端执行。Cluster模式将用于监控和调度的Driver模块在Yarn集群中执行。
Yarn Client
(1)Driver在任务提交的本地机器上运行;
(2)Driver和ResourceManager通讯,申请启动ApplicationMaster;
(3)ResourceManager分配Container,在合适的NodeManager上启动ApplicationMaster;
(4)ApplicationMaster负责向ResourceManager申请Executor内存;
(5)ResourceManager分配container;
(6)ApplicationMaster在指定的NodeManager上启动Executor进程;
(7)Executor向Driver反向注册;
(8)Executor全部注册完成后Driver开始执行;
(9)执行main函数,执行Action算子(Action算子触发一个 Job),根据宽依赖划分stage,每个 stage生成对应的TaskSet,将 task 分发到各个 Executor 上执行。
Yarn Cluster
(1)Driver任务提交;
(2)Driver和ResourceManager通讯,申请启动ApplicationMaster;
(3)ResourceManager分配Container,在合适的NodeManager上启动ApplicationMaster,这个ApplicationMaster就是Driver;
(4)ApplicationMaster负责向ResourceManager申请Executor内存;
(5)ResourceManager分配container;
(6)ApplicationMaster在指定的NodeManager上启动Executor进程;
(7)Executor向Driver反向注册;
(8)Executor全部注册完成后Driver开始执行;
(9)执行main函数,执行Action算子(Action算子触发一个 Job),根据宽依赖划分stage,每个 stage生成对应的TaskSet,将 task 分发到各个 Executor 上执行。
本文仅仅是学习笔记的记录!!!
版权归原作者 一个人的牛牛 所有, 如有侵权,请联系我们删除。