
第二章:Scala基础
一.map()方法
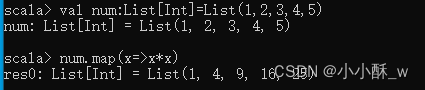
map()方法可通过一个函数重新计算列表中的所有元素,并且返回一个包含相同数目元素的新列表。例如,定义一个Int类型列表,列表中的元素为 1~5,使用 map()方法对列表中的元素进行平方计算。
二.foreach()方法
foreach()方法和 map()方法类似,但是foreach()方法没有返回值,只用于对参数的失进行输出。
三.filter()方法
使用 filter()方法可以移除传入函数的返回值为 false 的元素。
四.flatten()方法
flatten()方法可以将嵌套的结构展开,即 flatten()方法可以将一个二維的列表展开成一个一维的列表。定义一个二维列表list,通过 flatten()方法可以将 list 展开为一维列表。
五.flatMap()方法
flatMap()方法结合了 map()方法和 flatten()方法的功能,接收一个可以处理嵌套列表的函数,再对返回结果进行连接。

六.groupBy()方法
groupBy ()方法可对集合中的元素进行分组操作,返回的结果是一个映射。对 1~10根据奇偶性进行分组,因此 groupBy ()方法传入的参数是一个计算偶数的函数,得到的结果是一个映射,包含两个键值对,键为 false 对应的值为奇数列表,键为true对应的值为偶数列表。

第三章:Spark编程基础——RDD方法
一.map()方法转换数据
map()方法是一种基础的RDD转换操作,可以对RDD中的每一个数据元素通过某种函数进行转换并返回新的RDD。map()方法是转换操作,不会立即进行计算。
转换操作是创建RDD的第二种方法,通过转换已有RDD生成新的RDD。因为RDD是一个不可变的集合,所以如果对RDD数据进行了某种转换,那么会生成一个新的RDD。

二.SortBy()方法进行排序
sortBy()方法用于对标准RDD进行排序,有3个可输入参数,说明如下。
第1个参数是一个函数f:(T) => K,左边是要被排序对象中的每一个元素,右边返回的值是元素中要进行排序的值。
第2个参数是ascending,决定排序后RDD中的元素是升序的还是降序的,默认是true,即升序排序,如果需要降序排序那么需要将参数的值设置为false。
第3个参数是numPartitions,决定排序后的RDD的分区个数,默认排序后的分区个数和排序之前的分区个数相等,即this.partitions.size。
第一个参数是必须输入的,而后面的两个参数可以不输入。

三.collect()方法查询数据
collect()方法是一种行动操作,可以将RDD中所有元素转换成数组并返回到Driver端,适用于返回处理后的少量数据。
因为需要从集群各个节点收集数据到本地,经过网络传输,并且加载到Driver内存中,所以如果数据量比较大,会给网络传输造成很大的压力。
因此,数据量较大时,尽量不使用collect()方法,否则可能导致Driver端出现内存溢出问题。

四.flatMap()方法转换数据
flatMap()方法将函数参数应用于RDD之中的每一个元素,将返回的迭代器(如数组、列表等)中的所有元素构成新的RDD。
使用flatMap()方法时先进行map(映射)再进行flat(扁平化)操作,数据会先经过跟map一样的操作,为每一条输入返回一个迭代器(可迭代的数据类型),然后将所得到的不同级别的迭代器中的元素全部当成同级别的元素,返回一个元素级别全部相同的RDD。
这个转换操作通常用来切分单词。

五.take()方法查询某几个值
take(N)方法用于获取RDD的前N个元素,返回数据为数组。
take()与collect()方法的原理相似,collect()方法用于获取全部数据,take()方法获取指定个数的数据。
六.union()方法合并多个RDD
union()方法是一种转换操作,用于将两个RDD合并成一个,不进行去重操作,而且两个RDD中每个元素中的值的个数、数据类型需要保持一致。
使用union()方法合并两个RDD。
七.filter()方法进行过滤
filter()方法是一种转换操作,用于过滤RDD中的元素。
filter()方法需要一个参数,这个参数是一个用于过滤的函数,该函数的返回值为Boolean类型。
filter()方法将返回值为true的元素保留,将返回值为false的元素过滤掉,最后返回一个存储符合过滤条件的所有元素的新RDD。

八.distinct()方法进行去重
distinct()方法是一种转换操作,用于RDD的数据去重,去除两个完全相同的元素,没有参数。

九.intersection()方法
intersection()方法用于求出两个RDD的共同元素,即找出两个RDD的交集,参数是另一个RDD,先后顺序与结果无关。
十.subtract()方法
subtract()方法用于将前一个RDD中在后一个RDD出现的元素删除,可以认为是求补集的操作,返回值为前一个RDD去除与后一个RDD相同元素后的剩余值所组成的新的RDD。两个RDD的顺序会影响结果。
创建两个RDD,分别为rdd1和rdd2,包含相同元素和不同元素,通过subtract()方法求rdd1和rdd2彼此的补集。
十一.cartesian()方法
cartesian()方法可将两个集合的元素两两组合成一组,即求笛卡儿积。
第四章:Spark编程进阶
用本地模式将开发环境(IDEA)的代码文件打jar包到我们的集群环境下运行。
一.用IDEA自带的打包方式
点击 File ==> Project Structure ==> Artifacts ==> 点击加号 ==> 选择JAR ==> 选择From modules with dependencies。
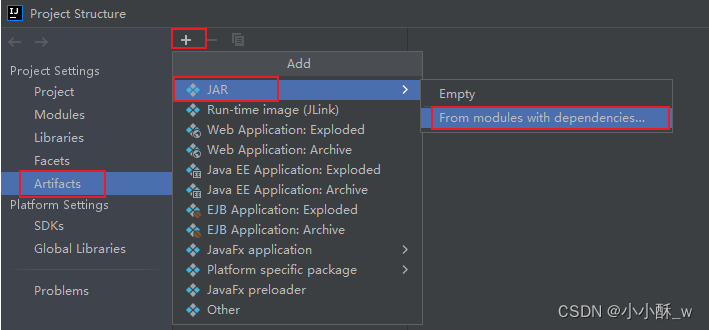
1.先选择你要打包的模块和启动类,然后选择extract to the target JAR ,点击OK。
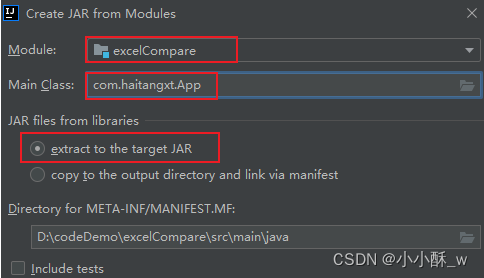
2.确认要生成的 jar 名称(默认是项目或模块名),确认 jar 包的输出的目录,确认最终输出的 jar 里包含的依赖,点击 Apply 和 OK。
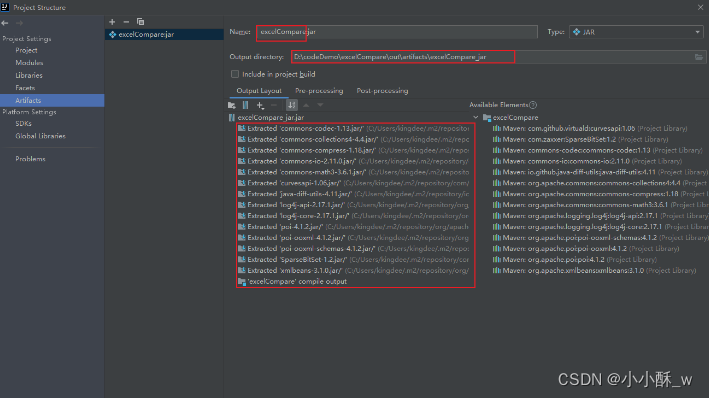
3 . 点击 Build ==> Build Artifacts。在弹出的窗体中选择word==>Build。

4.构建打包提示成功后就可以在输出目录里找到打好的 jar 包了。
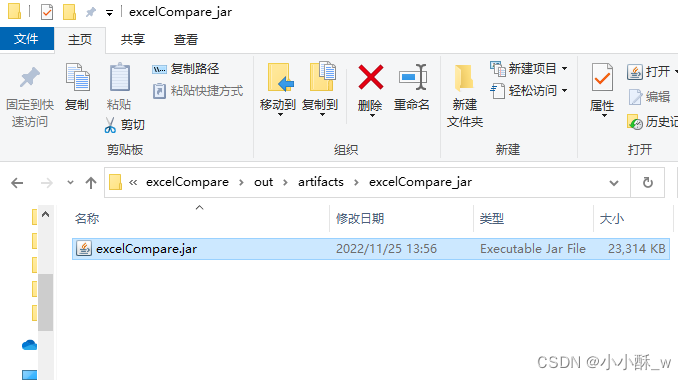
二. 用maven 项目中的插件来打包
1.首先创建我们的maven项目。

2.然后再配置我们的pom.xml文件 。



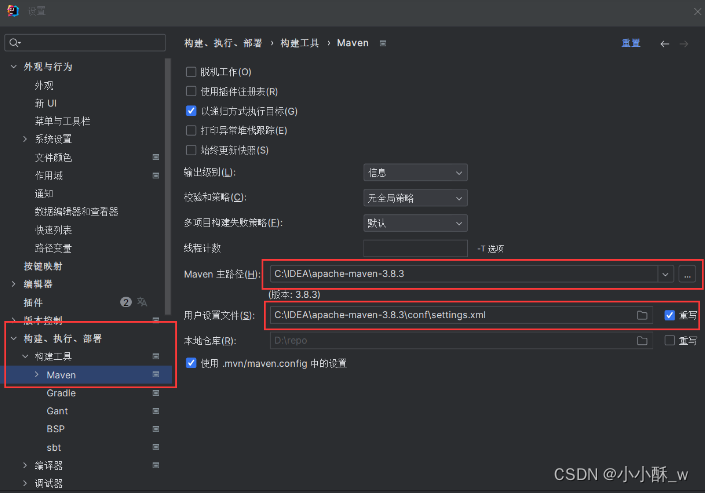
3.设置中将我们的maven路径添加到我们的构建工具中。
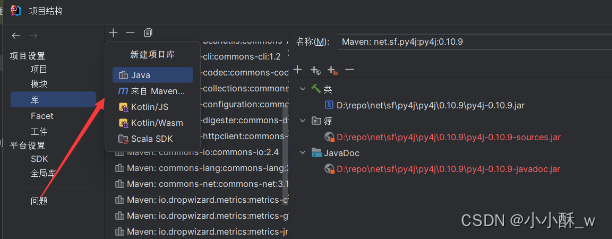
4.在我们的项目结构库中添加我们的spark与Scala,路径选择我们的Scala根目录,spark的jar目录。
第五章:Spark SQL——结构化数据文件处理
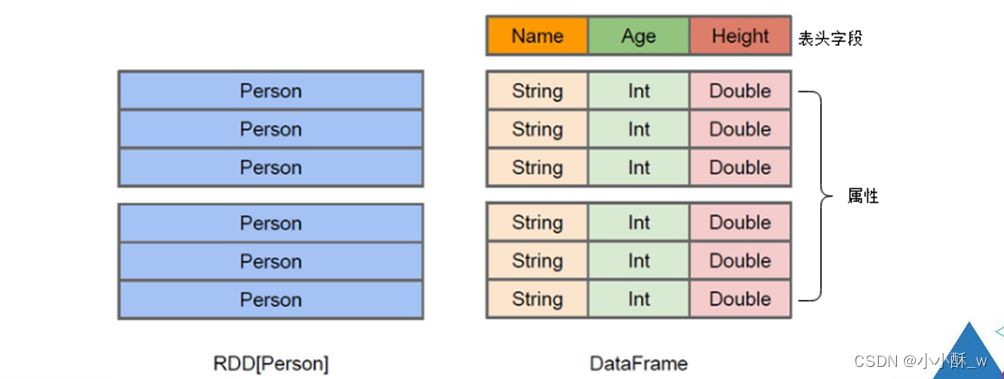
一.DataFrame简介
DataFrame可以看作是分布式的Row对象的集合,在二维表数据集的每一列都带有名称和类型,这就是Schema元信息,这使得Spark框架可获取更多数据结构信息,从而对在DataFrame背后的数据源以及作用于DataFrame之上数据变换进行针对性的优化,最终达到提升计算效率。
二.DataFrame的创建
数据准备

创建DataFrame的两种基本方式:
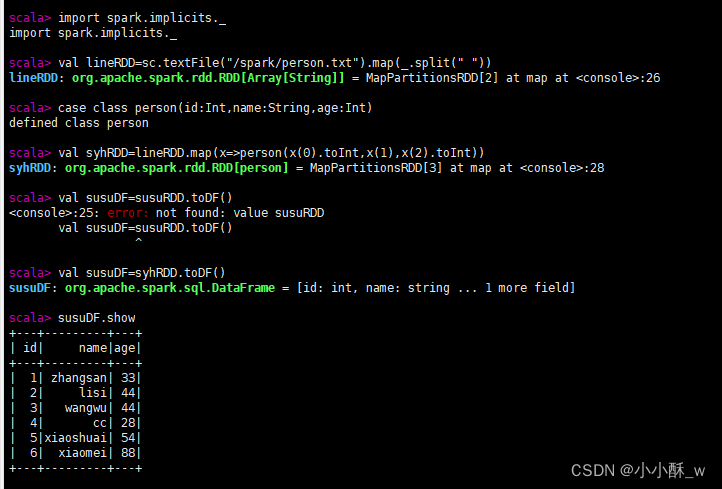
1.已存在的RDD调用toDF()方法转换得到DataFrame。
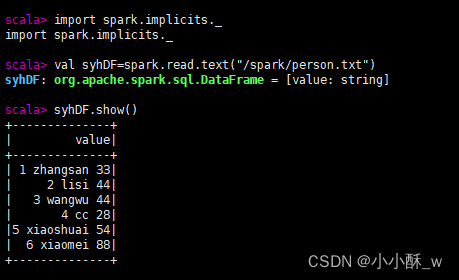
2.通过Spark读取数据源直接创建DataFrame。
三.DataFrame****的常用操作
1.select实现对列名进行重命名
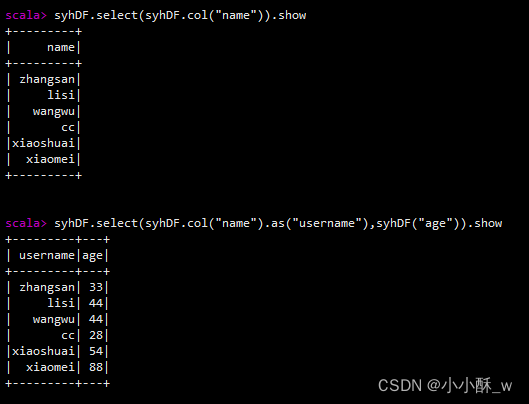
2.selectExpr()方法指定字段特殊处理



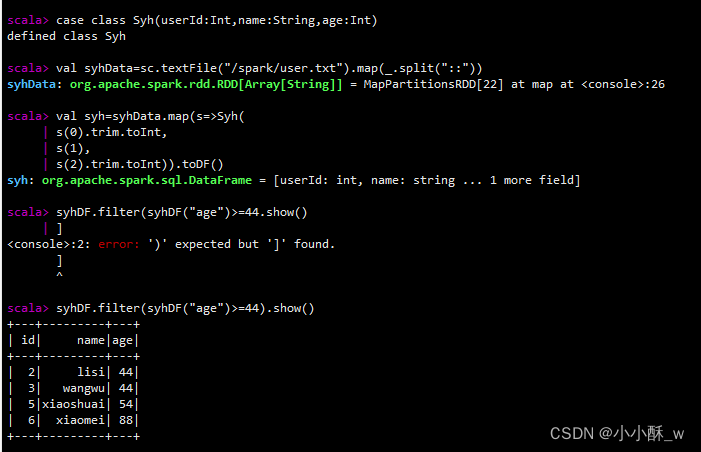
3.filter()/where条件查询
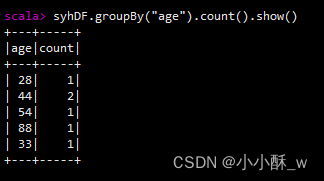
4.groupBy()对数据进行分组
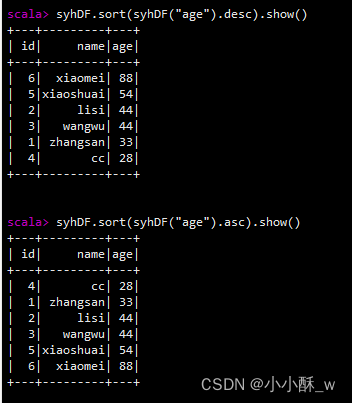
5.sort()/orderBy():对特定字段进行排序 desc:降序;asc:升序
版权归原作者 小小酥_w 所有, 如有侵权,请联系我们删除。