
讲师:骆撷冬 Hologres PD
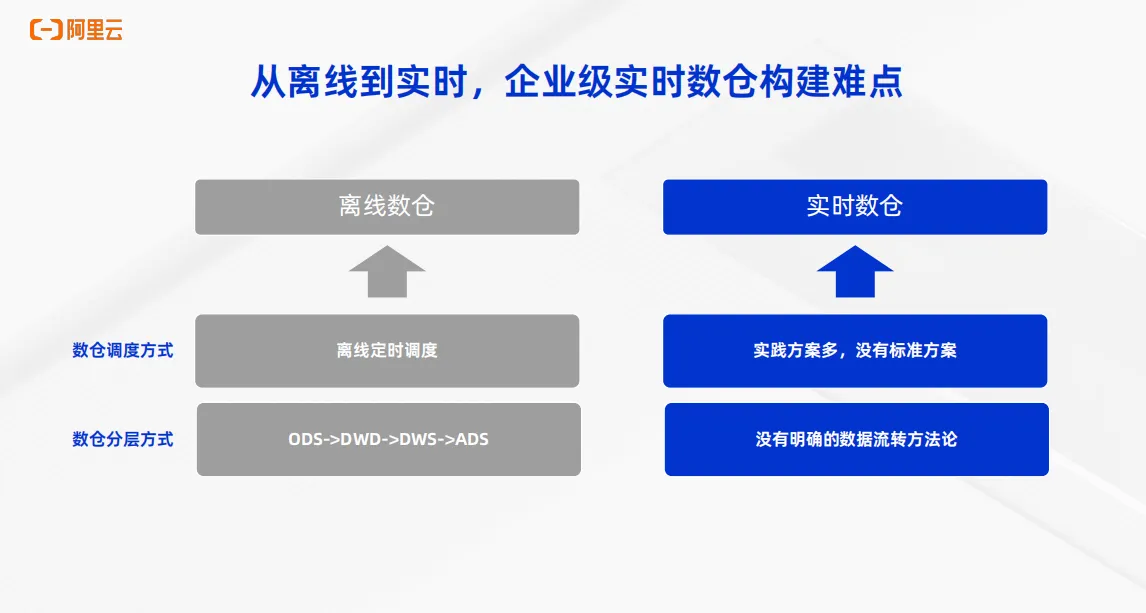
随着业务发展,业务对于时效性的要求在逐渐提升。各种场景都需要实时,例如春晚实时直播大屏、双11 GMV实时大屏、实时个性化推荐等等多种场景,都对数据的时效性有着非常高的要求。随着实时需求的发展,大数据技术也开始发展出实时数仓的概念。相比于传统的离线数仓,有着明确的方法论,即通过离线的定时调度来实现调度方式,通过ODS、DWD、DWS、ADS这类明确的数仓分层方式来完成离线数仓的搭建,实时入仓在业内并没有一个明确的方法论,实践方案多,没有标准的方案。
当前,业内提出了 Streaming Warehouse的概念,本质上希望能够解决数据实时流动的问题,从而解决数据实时分层的问题,这也是企业级实时数仓的本质。

一、传统实时数仓分层方案
1、Flink+Kafka分层方案
传统的实时数仓分层分为多种方案,包括以下几个。
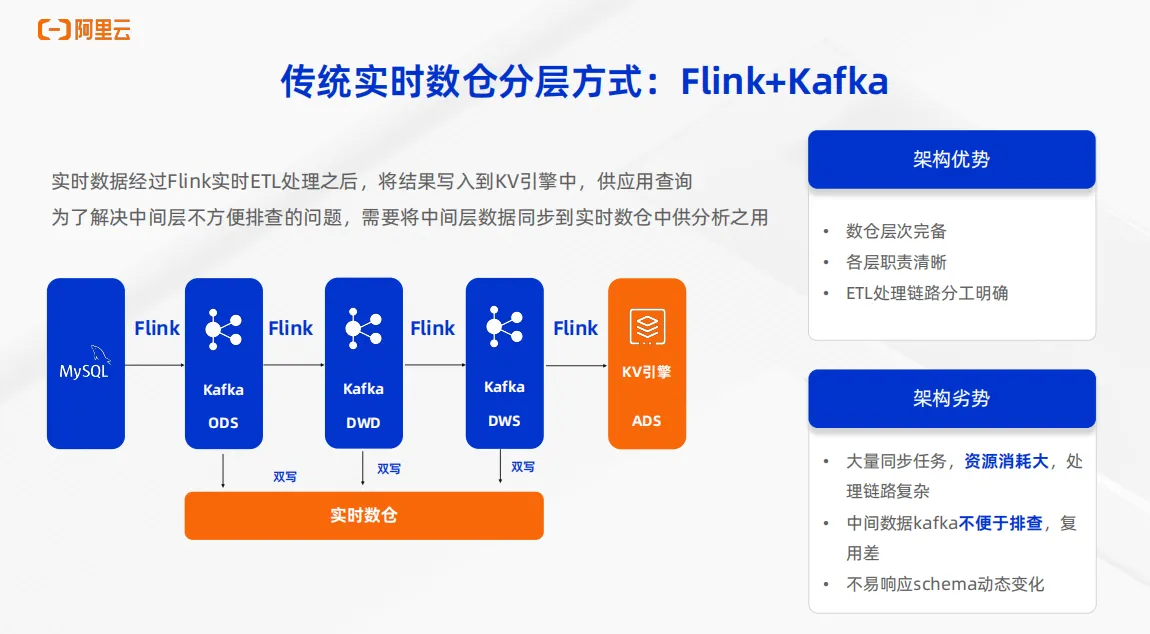
首先是基于 Flink 加Kafka的实时数仓分层方案。实时数据经过 Flink 实时处理,实时加工以后,将最终将结果写到 key value 引擎中供应用来查询。在期间通过 Flink 和Kafka的反复交互来实现数据从 ODS 到 DWD 到 DWS 层的多层数仓构建。业务如果需要查询中间层,还需要把中间层的数据实时写到实时数仓中来供业务使用,这样的架构优势在于首先数仓层次完备,各层的职级清晰,整个 ETL 处理链路也分工明确。但是这样的架构显然有着明确的劣势,就是有着大量的数据同步任务,资源消耗非常大,处理链路非常复杂。第二个明显的劣势在于中间层的 Kafka 的数据无法直接排查,复用性差,如果需要中间数据可读,还需要把数据双写到数仓中。第三个劣势在于无法做到快速响应 schema 的动态变化,比如 MySQL 原表又发生了加列改数据类型等等情况,整个数据链路都需要做改动。这是第一个传统数仓分层的方案。
2、定时调度分层方案

这种方案通过 Flink 把数据源的数据实时写到实时数仓中,形成 DWD 层,再通过数仓或者周边工具的高频调度能力,以分钟级为例来构建 DWS 和 ADS 层,实现分钟级的数据增量更新,最终供下游使用。这样的架构优势在于成本相比于 Flink 加 Kafka 更低,并且方案也偏向于成熟,但是有一个明确的劣势,在于它增加了整个数仓数据处理链路的延时,整个实时数仓退化成了近实时数仓,并且调度层级越多,延时会越大。
3、物化视图分层方案

该方案Flink同样负责将原表数据实时写入实时数仓中来形成 DWD 层,再通过实时数仓的物化视图来加工形成 DWS 或者是 ADS 层,最终为下游做服务。这样的架构优势在于整个数仓处理加工的链路功能都是系统内置的,并且物化视图的结果能够提供一些高 QPS 的点查和简单查询能力。但是这样的架构也有一些明显不足,首先业内在实时物化视图方面的能力往往不成熟,对于算子各方面的支持也有限。其次,很多系统提供的基本上都是一些批模式的物化,这种物化方式的时效性比较差,通常无法满足实时数仓对于时效性的需求。
二、实时数仓Hologres+Flink分层方案
那么有没有一种方案能够非常完美解决上述传统实施数仓分层所面临的问题呢?今天为大家带来的内容通过 Flink 加 Hologres 来解决实时数仓分层的问题。

1、Hologres介绍
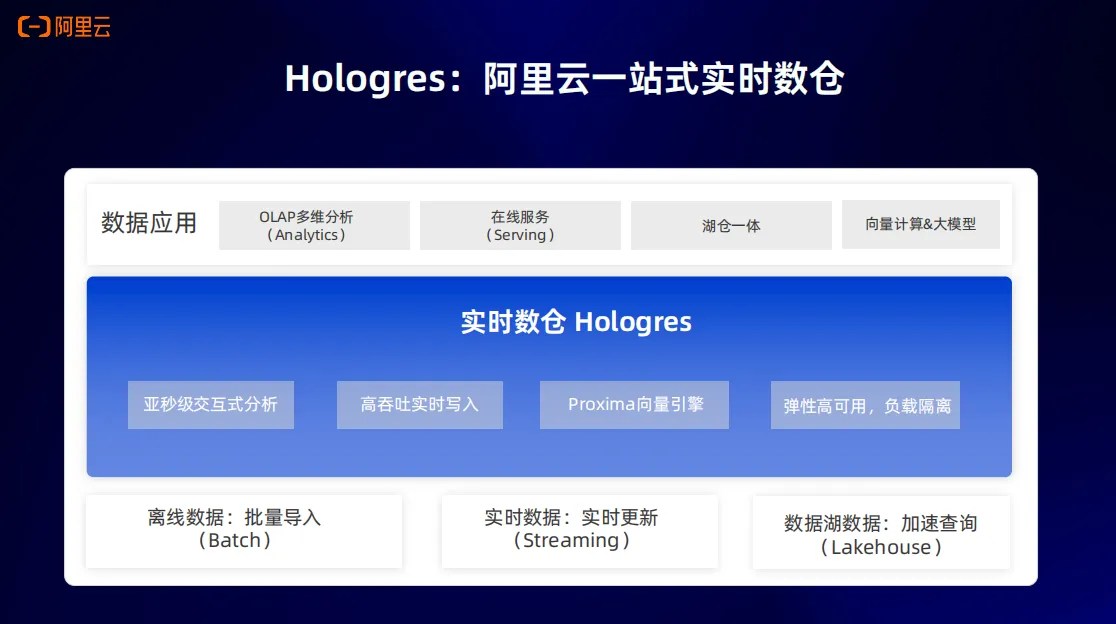
Hologres 提供统一、实时、弹性、易用的一站式实时数仓引擎,分析性能打破TPC-H世界记录,一份数据可同时支持多维分析(OLAP)、即席分析(Ad Hoc)、点查(Servering)、向量计算等多种场景,替换各类OLAP 引擎(ClickHouse/Doris/Greenplum/Presto/Impala等)、KV 数据库(HBase/Redis等)。传统实时数仓可以解决亚秒级交互式分析的能力,在此基础上,Hologres还支持行列共存的表存储格式,可以实现高吞吐的数据实时写入与更新。同时 Hologres 还支持一系列高可用架构来实现业务的弹性、高可用以及负载隔离。
2、Flink+Hologres的Streaming Warehouse方案
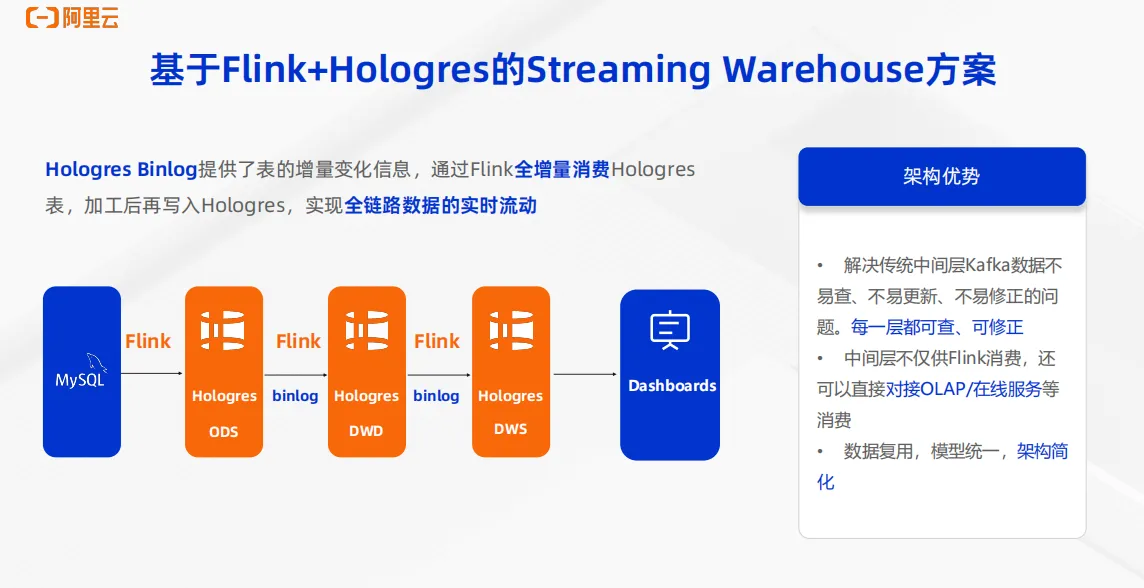
这里展示整个方案的架构,数据从MySQL 或者其他数据源通过 Flink 实时写入到 Hologres 中,形成 ODS 层。Hologres 支持Binlog,可以提供表的增量变化信息,以此成为 Flink 的源表,通过 Flink 来全增量消费 Hologres源表并加工后再写入 Hologres 中,形成 DWD 层。DWD层再次生成 Binlog 供 Flink 消费。再次写入 Hologres 中,形成聚合层DWS,以此最终为下游提供服务。这样一个架构的优势显而易见,首先可以解决传统中间层 Kafka 数据不易查、不易更新、不易修正问题。 Hologres是一款实时数据仓库,数据写入即可查,所以不管是结果聚合层的 DWS 层,还是中间层 ODS、DWD 层,每一层都实时可查,可实时更新。第二点优势在于中间层不仅可以供 Flink 消费,还可以供下游直接提供服务,比如业务直接查询 ODS 层或 DWD 层做 OLAP 分析,甚至是做在线服务等等场景都可以直接实现。第三个主要优势在于整个链路的数据都是复用的,模型统一,架构简化,一份存储,一个引擎。
3、Flink与Hologres深度集成
为什么 Hologres可以和 Flink 有效结合,形成强大的 Streaming Warehouse 方案呢?这个就得益于 Hologres和 Flink 多年从阿里巴巴集团内部到阿里云上服务众多云上客户的过程中,面向企业级用户场景不断深度集成各类能力。
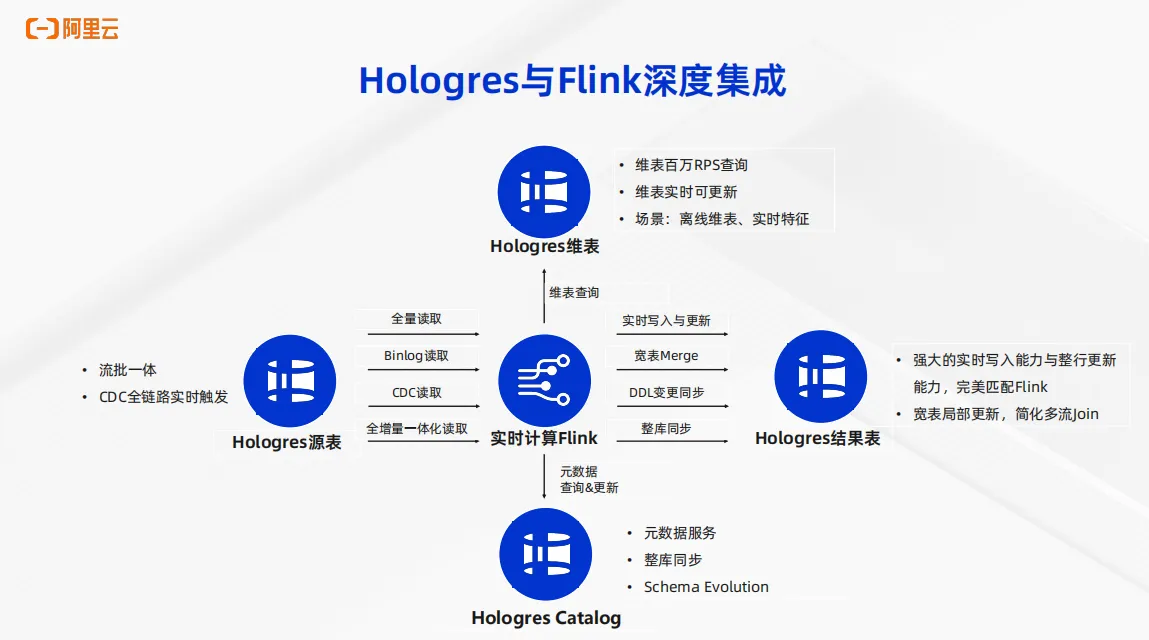
主要分四个方面,第一, Hologres可以作为 Flink 的源表。刚刚提到Hologres支持生成Binlog。类似于传统数据库的Binlog,Hologres通过生成Binlog供 Flink 消费,以此可以实现多种高级能力,包括Binlog 读取、 CDC 读取以及全增量一体化读取。其次, Hologres 可以作为 Flink 的维表。 Hologres 支持行存或者行列共存的模式,以此可以供 Flink 进行维表关联。Flink的维表关联对Hologres而言本质上就是对于维表的点查, Hologres 的高性能点查能力可以提供对于百万 RPS 的维表关联性能。第三方面是Hologres可以作为 Flink 的结果表,Hologres支持强大的实时数据写入能力与整行更新能力,完美匹配 Flink 对于结果表的要求。同时Hologres还支持对于宽表的高性能的局部更新能力,可以极大程度的简化 Flink 多流 join 的场景。第四点,整个链路可以通过 Flink 创建 Hologres Catalog 来完成。 Flink 支持Hologres Catalog 来实现统一的元数据服务,以此可以支撑整库同步能力,以及 Schema Evolution能力,包括数据类型变更、加列等等场景。通过以上四个方面的深度集成,从而实现 Flink 加Hologres搭建 Streaming Warehouse 这样成熟的解决方案。
三、Hologres+Flink企业级实时数仓核心能力
刚刚所说的解决方案,对于Hologres来说依托于Hologres的三大核心能力:Binlog、行列共存和资源隔离。接下来一一解读。

1、Hologres Binlog
首先, Binlog 可以助力整个实时数仓全链路的数据实时流动。 Hologres Binlog 类似于传统数据库,比如 MySQL 的 Binlog,可以用来记录单表数据修改的日志,包括insert、delete以及update前后的信息,共 4 种数据事件类型,提供表的增量变化信息。Binlog有多种场景的应用。首先最重要的是用于本文所说的解决方案,在数仓分层间进行数据的实时加工。可以通过 Flink 全增量消费 Hologres 表,加工之后再次写入Hologres,来实现整个全链路数据的实时流动。还有其他一些场景,比如可以进行多实例之间的数据同步,可以进行数据的行列转换以及数据的变化监测。Hologres的 Binlog 表会包含如右图所示的这些字段,用来全面记录用户的表数据变更的信息。通过 Flink 加Hologres的 Binlog 就可以实现有状态的全链路的事件实时驱动开发。

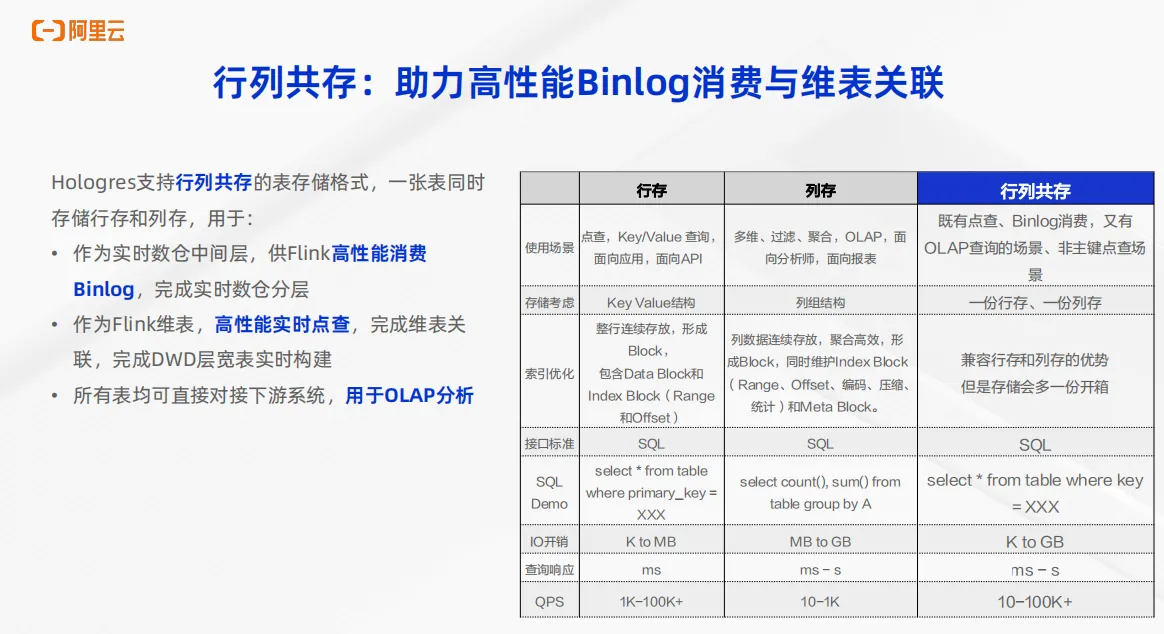
2、Hologres 行列共存
第二点核心能力是Hologres的行列共存能力。行列共存可以助力高性能的 Binlog 消费以及高性能的维表关联。Hologres支持行列共存的表存储格式,也就是一张表可以同时存储一份行存数据和一份列存数据,对于下游只感知到一张表,这样可以用于多个场景。比如作为实时数仓的中间层, ODS 层或 DWD 层可以生成 Binlog,供 Flink 进行高性能的 Binlog 消费,来完成实时数仓的分层。第二点是可以作为 Flink 的维表来实现高性能的实时点查,以此来完成高性能的维表关联,完成 DWD 层宽表的实时构建。第三点典型应用场景是所有的表,如果存储成了行列共存,不仅可以完成上述两种场景, Binlog 消费以及实时点查,还都可以同时用于对接下游业务系统用于 OLAP 分析。右边的表展示了Hologres的三种表存储格式,包括行存、列存和行列共存,分别可以面向不同的场景。
3、Hologres 资源隔离
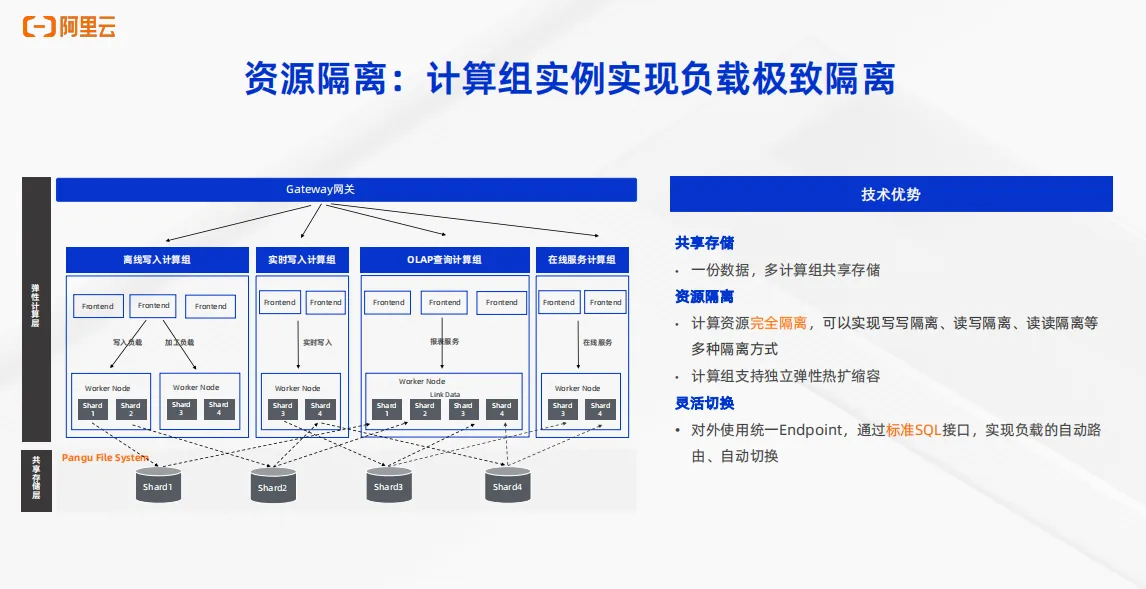
第三点重要的能力是 Hologres 的资源隔离能力。在企业级实时数仓的场景,对于资源和稳定性的要求是非常高的。Hologres 推出了计算组(Warehouse)实例这样一个可以实现极致的负载隔离架构,架构图如左图所示。首先是计算存储分离,在存储层只有一份存储,在计算层通过把一个实例分隔成不同的计算组,可以用通过一个计算组来实现离线写入,通过一个计算组来做实时写入,通过一个计算组来做 OLAP 查询,通过第四个计算组来做在线服务。整个架构共享一份存储,对于不同的计算组之间计算资源完全隔离,可以实现写写隔离、读写隔离、读读隔离等多种隔离方式。并且每一个计算组可以支持独立的弹性热扩缩容。对于业务层的应用使用统一的 Endpoint 为下游提供服务。通过标准的 SQL 接口就可以实现负载的自动路由自动切换,以此来实现极致的负载隔离。针对于 Flink 加Hologres 搭建实时入仓的场景而言,就可以实现写入Hologres 使用一份计算组,消费Binlog再使用另外一个计算组。对于业务的 OLAP 查询场景,在线服务场景也可以分别使用不同的计算组来承载,以此实现极致的负载隔离。
四、某电商平台 Streaming Warehouse 实践。
下面介绍基于 Flink Catalog 的 Streaming Warehouse 实践。
1、业务背景及架构介绍
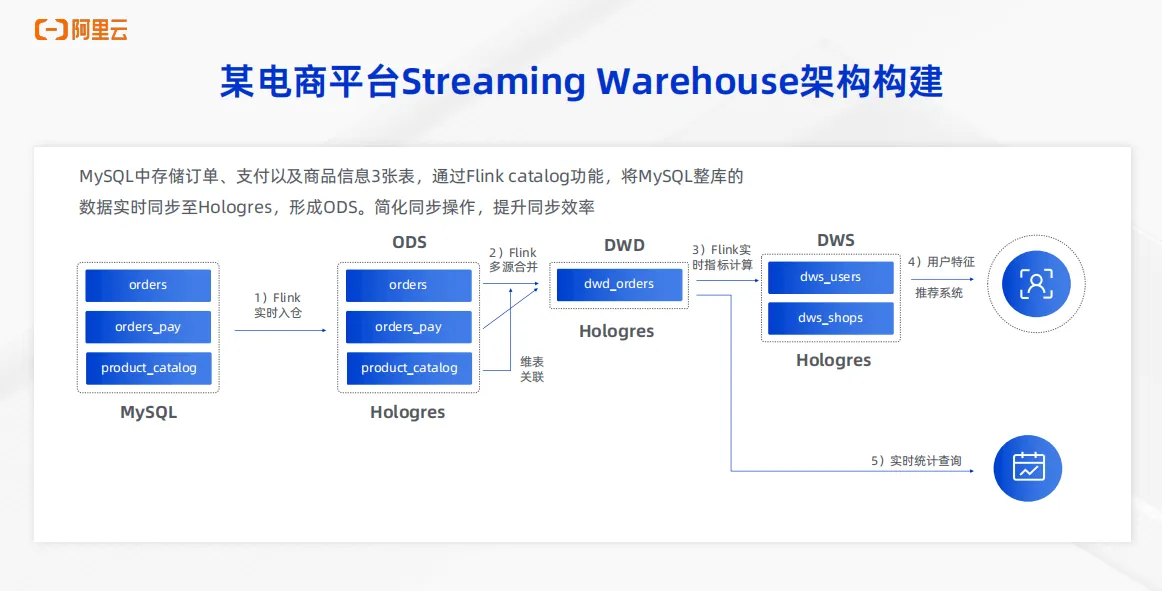
先介绍一个典型的电商场景,一个某典型的电商平台的 Streaming Warehouse 的构建。该电商平台的数据源存储在 MySQL 中,包括 orders 订单表, orders pay 支付表以及 product catalog 商品信息三张表。首先可以通过 Flink 的 catalog 功能将 MySQL 的数据整库实时同步到 Hologres 中形成 ODS 层。第二步可以通过 Flink 的多流 join 以及维表关联能力把 ODS 层的三张表实时打宽,形成 DWD 层,写入到Hologres 中。第三步,通过 Flink 的实施指标计算实时聚合能力,把 orders 表中的不同维度进行实时聚合,形成 DWS 层,写入到 Hologres 中,DWS 可以直接为下游用户特征推荐系统提供服务。第五步,业务还有一些实时的统计信息查询的需求,这一部分的需求可以通过 DWD 层的Hologres 表来承载,
2、ODS实时同步
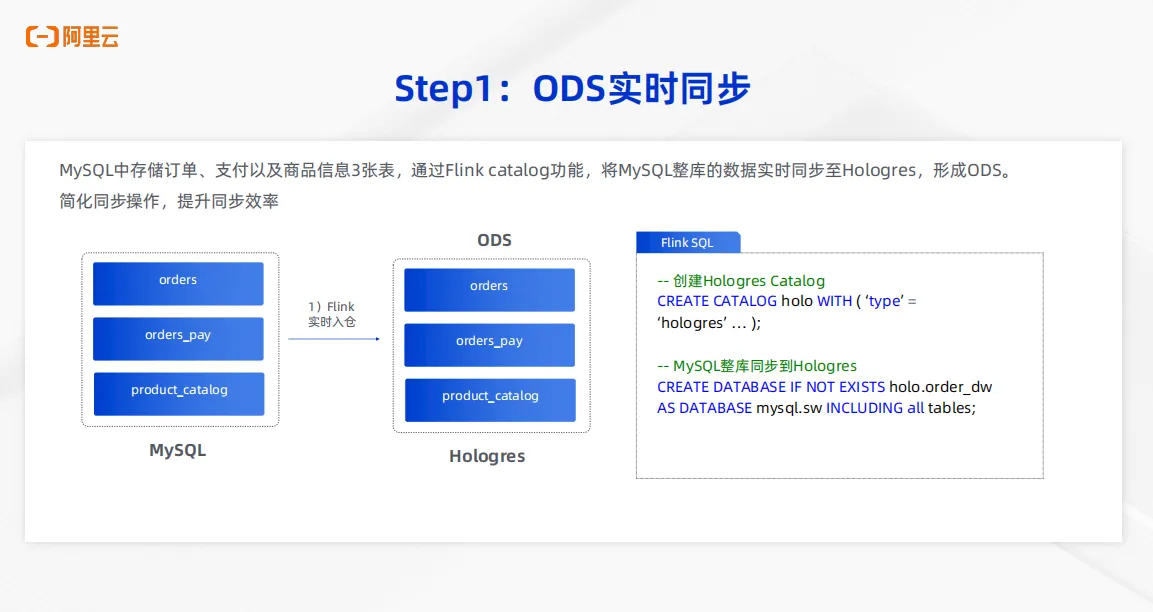
首先第一步是 ODS 层的实时同步能力。业务将 MySQL 中存储订单、支付和商品信息三张表,通过 Flink 的 Catalog 功能可以直接将 MySQL 整库实时同步到Hologres中,形成 ODS 层。我们可以看到在右边的SQL中,只需要通过在 Flink 中创建Hologres Catalog,通过 Create DATABASE 语句即可将 MySQL 整库同步到Hologres中,整个操作步骤非常简化,数据同步效率显著提升。
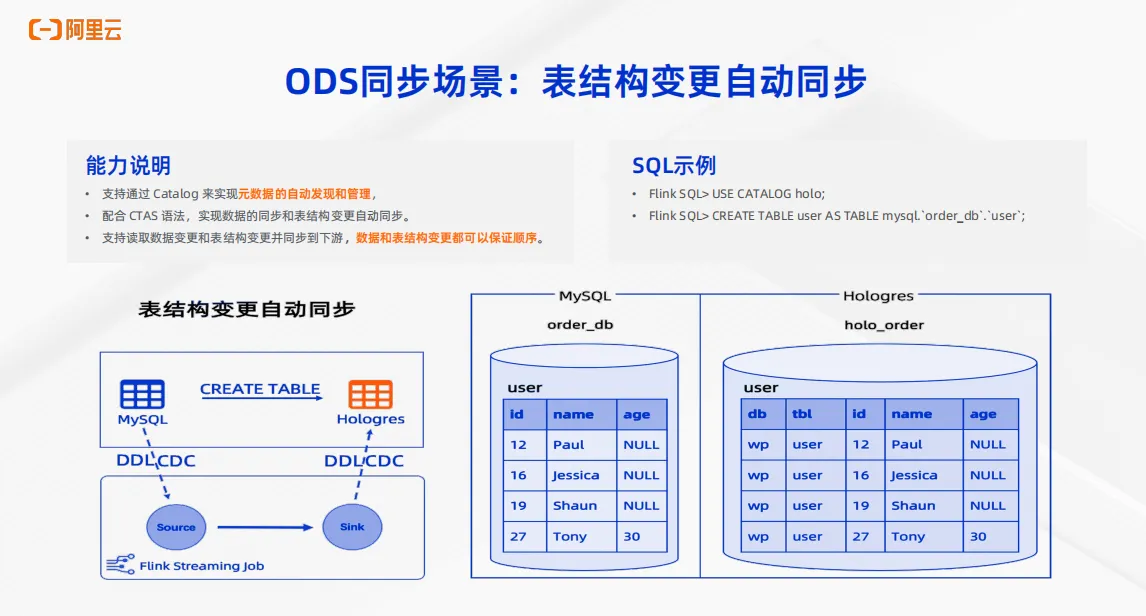
在 ODS 同步的场景中,有很多功能是Hologres加 Flink 共建的,非常易用。首先,对于表结构变更,我们可以支持自动同步。通过 Flink Catalog 既可以实现元数据的自动发现和管理,再配合 create table as 语法就可以实现数据的同步和表结构自动变更。同时支持读取数据的更新以及表结构的变更,并且实时同步到下游的Hologres表中。
第二个典型的同步场景是整库同步。
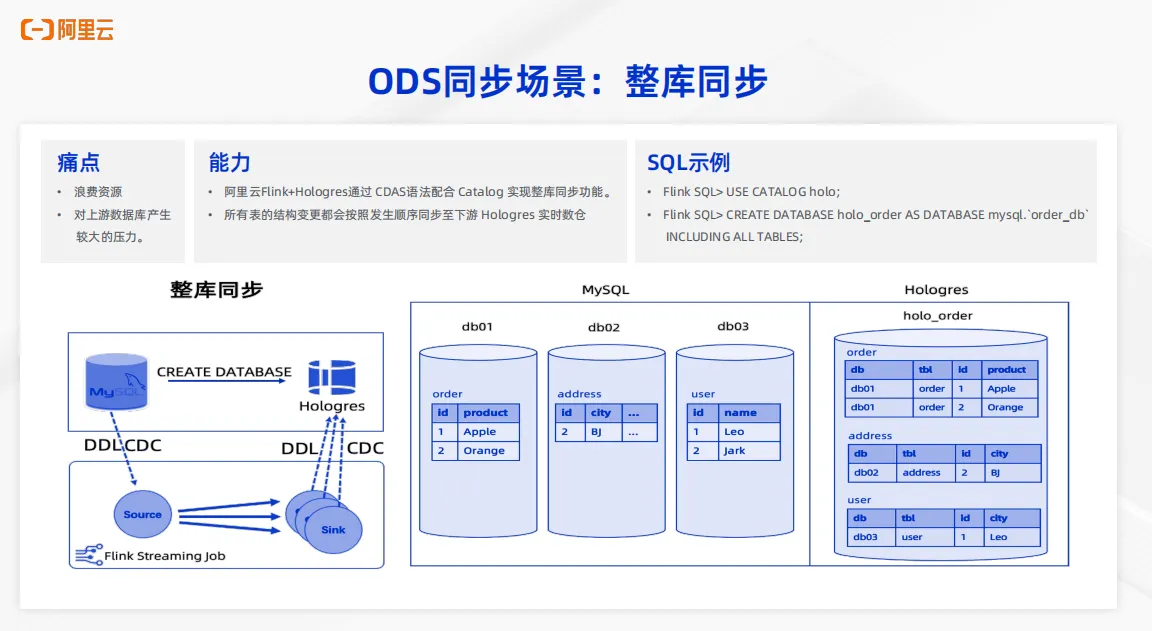
对于业界的整库同步能力而言,在以前会有明显的痛点,一是整库同步需要浪费很多资源,二是会对于上游的数据库产生比较大的压力。Hologres加 Flink 可以通过 create database as 语法配合 Catalog 来实现整库同步功能,整个过程无需用户手写DDL语句,无需提前建表,就可以快速实现。
第三个典型场景是分库分表合并同步。

传统数据库通常为了解决数据量大、并发需求高的难题时,会选择进行分库分表操作。对于实时数仓 Hologres而言,我们只需要把数据存储到同一张表中,依托于Hologres的强大的 MPP 架构就可以实现对于下游的在线分析,在线查询。阿里云 Flink 加上Hologres实现了对于源表分库分表合并同步的特性,只需要通过 create table as 语法以及对于源表的正则表达,就可以将源表数据库的分库分表高效的合并同步到下游的Hologres数仓中。
3、DWD实时同步
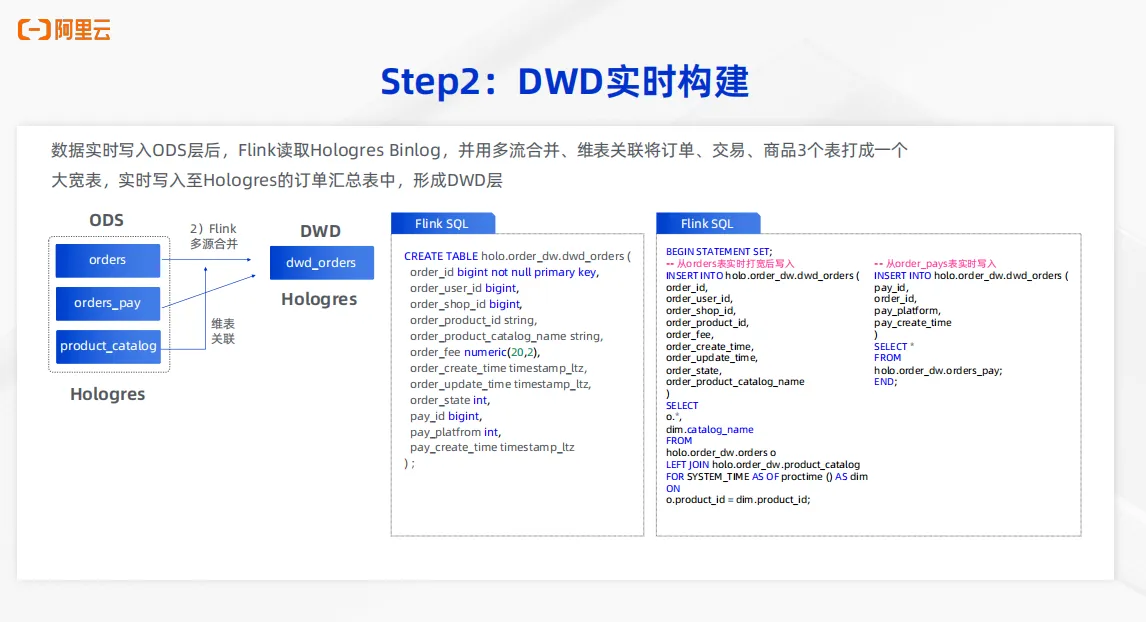
当实时数据实时写入 ODS 层之后,在 Hologres 的 ODS 表中先生成 Binlog。 Flink 来读取 Hologres ODS层表的Binlog,并且采用多流合并、维表关联等方式把订单交易商品三张表打成一个大宽表,并且实时写入到Hologres的 DWD 层,形成订单汇总表。具体SQL通过 create table 语句形成 DWD 层表的创建,通过 Flink SQL 中两个 insert 语句可以实现多流合并和维表关联。第一个 insert 语句可以实现对于 orders 表的实时打宽,通过和商品表的维表关联形成实时打宽的能力。第二个 insert 语句则是对于 orders 表,将其中交易相关的信息写入到表中。对于这样的 insert 语句中,最重要的就是每一个 insert 语句都是对于 DWD orders 这张表的局部更新。通过两个局部更新语句,最终将 Hologres 的 DWD orders 表实时打宽来形成订单汇总表的构建。
在刚刚说的 DWD底层实时打宽的能力中,很重要的一步是多流合并。
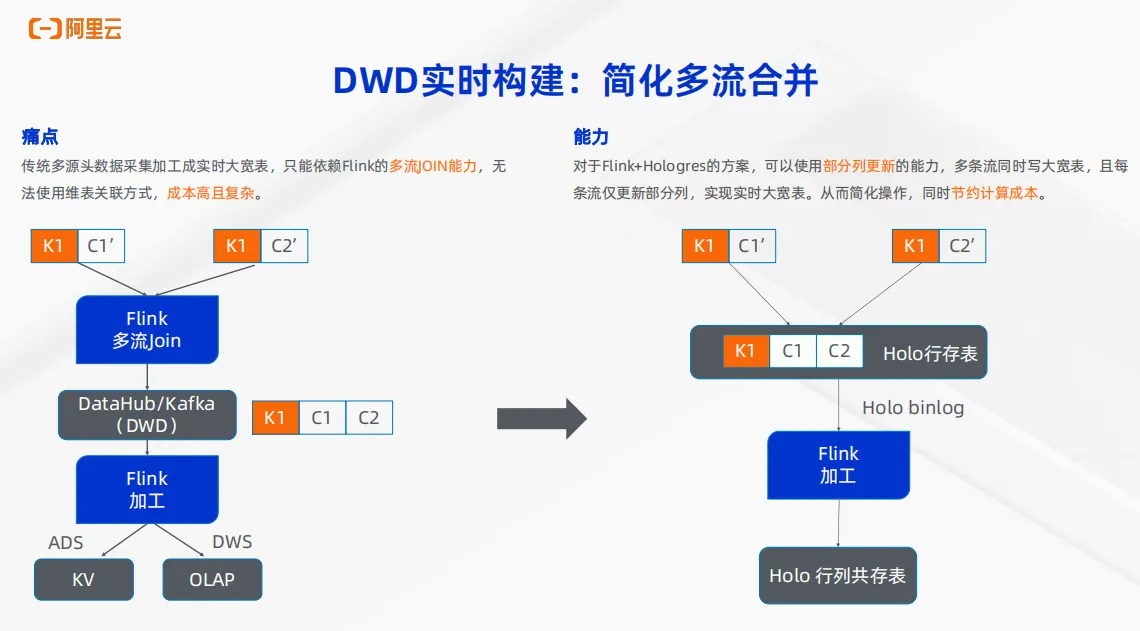
对于传统的多流合并的能力,通过 Flink 加 Kafka 来实现多流join能力无法使用维表关联的方式,成本非常高,非常复杂。需要使用 Flink 的多流 join 把结果写到 Kafka 或者 Datahub 中,再通过 Flink 加工一层形成 ADS 或 DWS 层供下游服务。但是对于 Flink 加 Hologres的方案可以依托于Hologres的强大的局部更新,也就是部分列更新的能力,把多张流同时写入到 Hologres 的宽表中。同时在这个过程中实现维表关联,每条流只更新Hologres宽表的部分列,形成实时宽表。从而来简化操作,同时节约计算成本。
对于 DWD 层实时构建,Hologres为什么能做到这样高的性能的实时写入与更新呢?这依托于 Hologres 的一个高级功能——Fixed Plan。
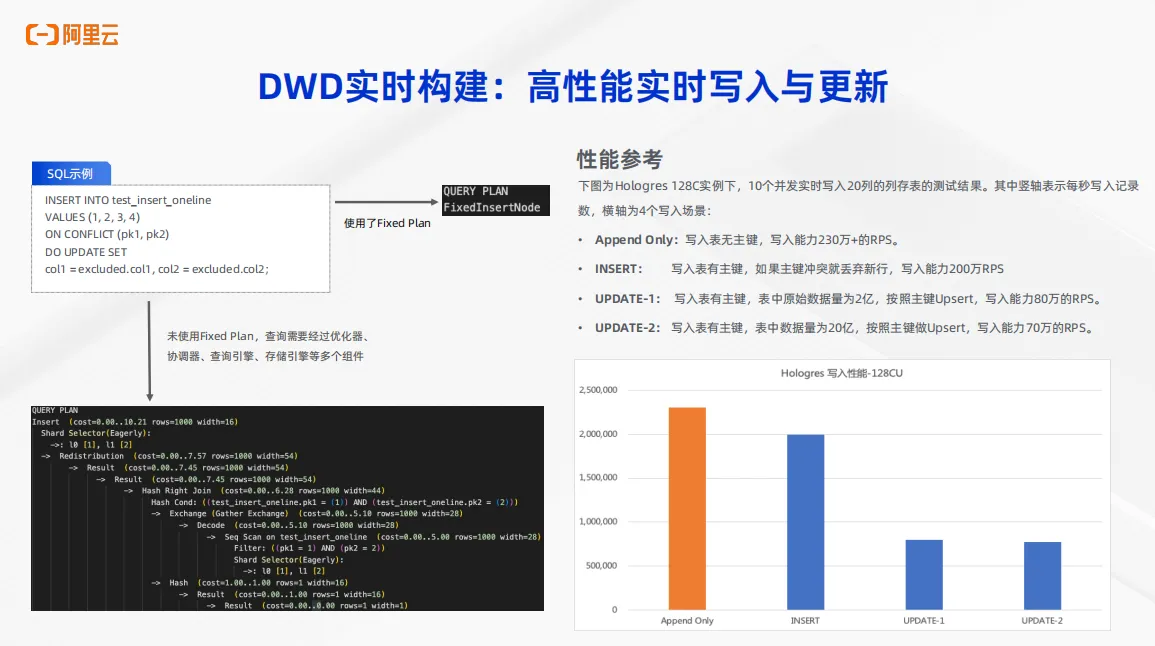
传统的 OLAP 引擎针对于一条 SQL 需要经过优化器生成执行计划,然后经过协调器,经过查询引擎、存储引擎等多个组件最终完成 SQL 的执行。但是如果使用 fixed plan,则可以绕过刚刚所说的优化器、协调器等多个组件,直接使用固定的 plan 来实现数据的高性能实时写入与更新。这个功能有测试结果作为参考,如右图。可以看到针对 append only 写入无主键表的场景、针对 insert 写入有主键表的场景、针对于两种数据更新场景,几乎都可以达到近百万甚至是 200 万的RPS。依托于 fixed plan 功能,我们可以实现对于数据的高性能实时写入与更新,从而完成 DWD 层的实时构建。
4、DWS实时聚合
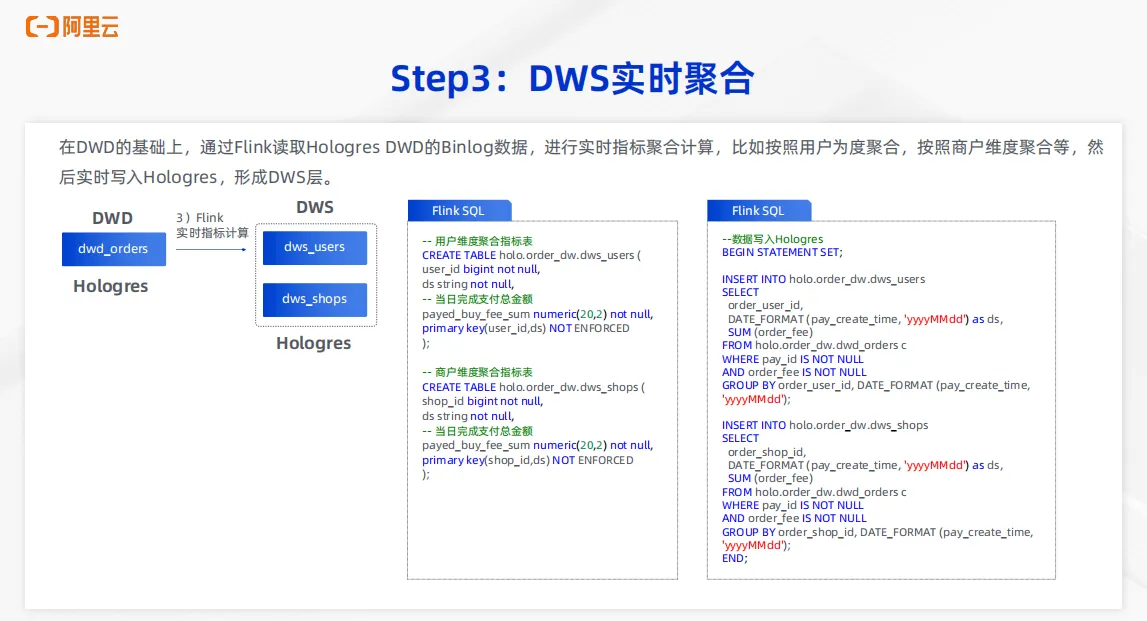
构建完成 DWD 层后再次生成Hologres Binlog,通过 Flink 来读取 Hologres 的 DWD 层的 Binlog 数据来进行实时指标的聚合计算。可以形成用户维度的聚合表,也可以形成商户维度的聚合表等等,取决于业务需求。最终把每一个维度的聚合表分别写入到 Hologres 的 DWS 层的表中,形成实时聚合表。整个 SQL 如图所示。首先可以在通过 Flink SQL 完成两个聚合表的创建,再通过 Flink SQL 执行写入,在写入过程中完成聚合计算,即可以完成整个 DWS 层的构件。
5、构建数据应用
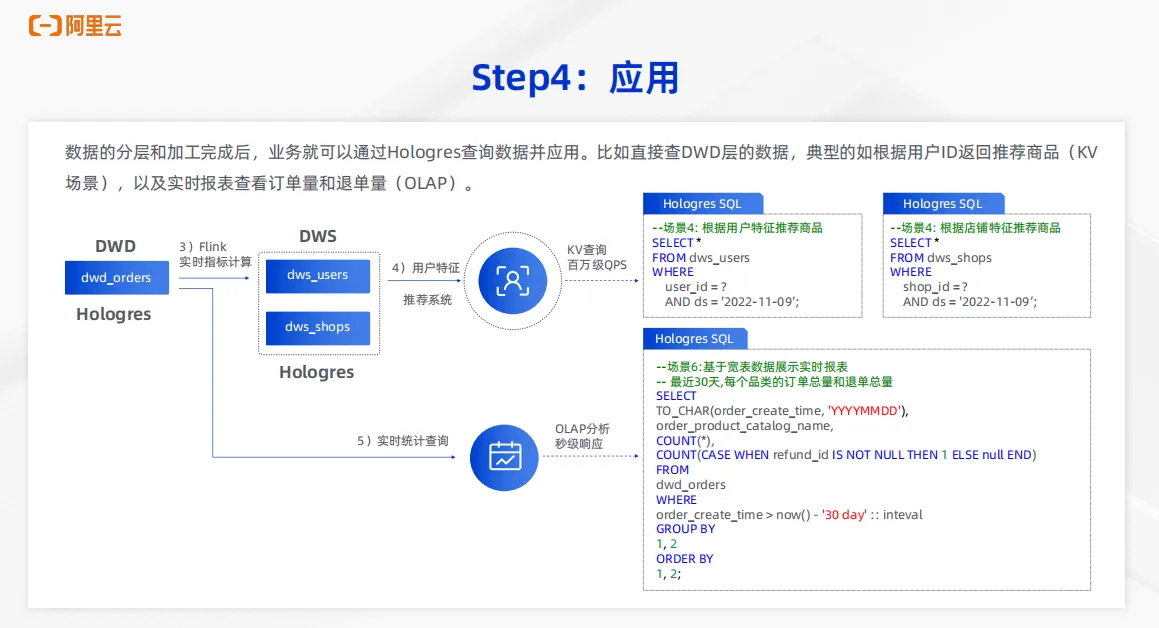
当整个数据的分层和加工完成后,业务就可以通过 Hologres 来查询数据,并且应用到业务层。比如业务可以直接查询 DWD 层的数据,如图下面场景 6 的SQL,对于宽表数据来展示实时报表,统计最近 30 天每个品类的订单总量、退单总量等等信息,可以通过直接查询 DWD 层的明细宽表来实现。同样对于下游会有一些在线服务的场景,比如根据用户特征来推荐商品,本质上就是对于 DWS users 表的点查,比如根据商铺特征推荐商品,这样的场景可以直接查询 DWS 层的 Hologres 表来提供百万级的 QPS 查询。
五、客户案例
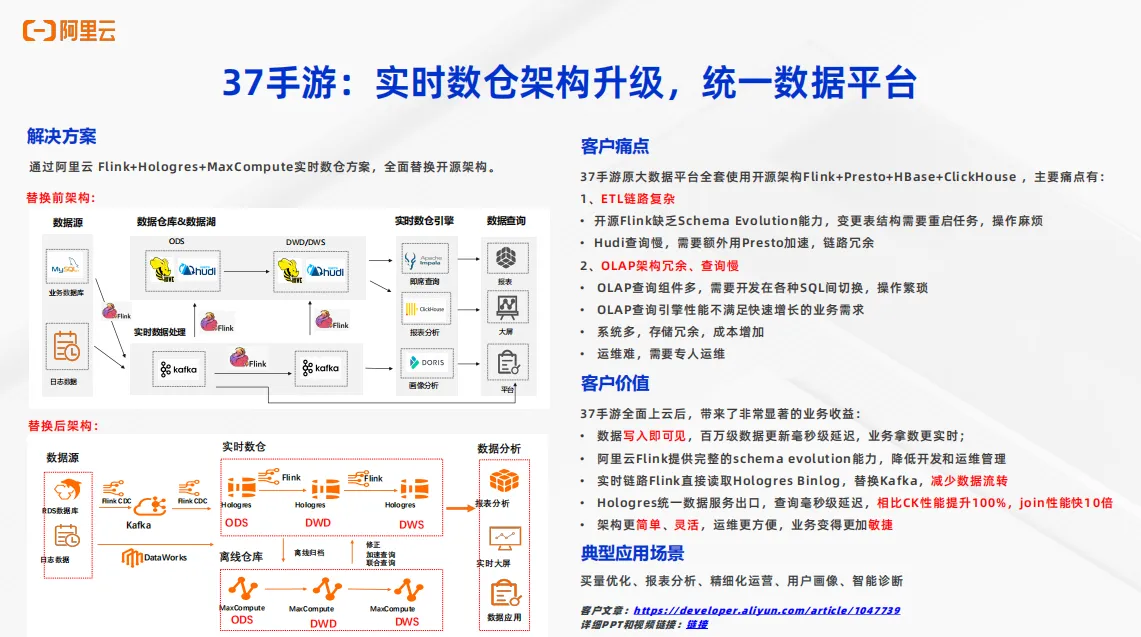
37手游是使用 Flink 加 Hologres 搭建实时数仓的典型客户。通过 Flink 加 Hologres 完成了整个实时数仓的架构升级,实现统一数据平台。在使用 Flink 加 Hologres 之前,客户的架构如左上图所示。针对于实时业务,通过 Flink 把数据源的数据经过Flink 加 Kafka 的实时数仓搭建方式来形成实时数仓分层。其次,将实时数据通过 Flink 写入到数据仓库和数据湖中来形成离线数仓的搭建。当实时数仓和离线数仓搭建完成后,针对于下游的不同业务需求,使用不同的开源引擎进行服务。对于即席查询的需求,通过 Impala 来对接报表。对于交互式分析大屏而言,使用 Clickhouse 来完成报表分析。对于一些实时分析、实时查询的需求,通过 Doris 来做画像分析,可以看到这样的一套架构非常复杂且割裂。主要痛点包括两个方面, 一是ETL 链路非常复杂,开源 Flink 缺少schema evolution 能力。当上游数据源的表结构发生变更,每次变更都需要重启 Flink 任务,运维操作非常复杂。其次,对于数据湖而言, Hudi的查询性能有待提升。客户还需要额外使用 Presto 来做湖仓加速,整个链路非常冗余。第二方面是 OLAP 架构冗余,查询慢。可以看出整个架构中的 OLAP 查询组件非常多,往往需要开发在不同的 SQL 之间切换,整个操作非常繁琐。并且开源的 OLAP 查询引擎性能很难满足业务日益增长的业务需求。第三方面,整个架构系统非常多,不同的系统会带来不同的存储,整个存储方面是冗余的,成本会显著增加。其次整个架构非常复杂,运维非常困难。
那么使用 Hologres 加 Flink 加 MaxCompute 构建出了实时离线一体化的数仓架构之后,客户的问题得到了解决。替换后的架构如左下图所示,可以看到对于实时数仓使用的就是刚刚所介绍的 Flink 加 Hologres 形成实时数仓分层。对于离线数仓而言,通过 DataWorks加MaxCompute完成离线数仓分层。对于实时数仓和离线数仓之间,可以通过Hologres向 MaxCompute 写入数据来实现离线数据归档,也可以通过 MaxCompute 向Hologres来完成实时数据的修正。Hologres也可以直接对接 MaxCompute 来实现离线数仓加速查询和联邦查询。Hologres 作为统一数仓出口,来为下游的数据分析提供服务。
这样的架构带来了明显的业务收益。首先第一点,整个数据处理链路是写入即可见的,百万级的数据更新可以实现毫秒级的延时,业务的时效性得到了显著提升。第二,阿里云的 Flink加Hologres可以提供完整的 schema evolution 能力。上游数据发生了表结构的变更,不需要重启 Flink 作业,可以显著降低开发和运维管理难度。第三,实时链路中 Flink 直接读取 Hologres Binlog,以此来替换Kafka,减少数据的流转。第四, Hologres 作为统一数据服务出口来提供服务,查询毫秒级延时。相比于 Clickhouse 性能提升超过100%,在教育场景性能快了 10 倍,整个架构更加简化,更加灵活,运维也更加简单,业务变得更加敏捷。37 手游将整个架构应用于很多业务场景,包括但不限于买量优化、报表分析、精细化运营、用户画像分析、智能诊断等等多种场景。
以上就是今天所有的分享,希望大家能够通过Hologres+Flink构建易用、统一的企业级实时数仓。
版权归原作者 阿里云大数据AI技术 所有, 如有侵权,请联系我们删除。