
实验目的
(1)通过实验掌握Spark的基本编程方法;
(2)熟悉RDD到DataFrame的转化方法;
(3)熟悉利用Spark管理来自不同数据源的数据。
实验内容
1.Spark基本操作
请参照给出的数据score.txt,该数据集包含了某大学计算机系的成绩,数据格式如下所示:
Tom,DataBase,80
Tom,Algorithm,50
Tom,DataStructure,60
Jim,DataBase,90
Jim,Algorithm,60
Jim,DataStructure,80
……
请根据给定的实验数据,在spark-shell中通过编程来计算以下内容:
代码实现:
#注意,首先将score.txt文件上传到hdfs的根目录下,然后将hadoop01和9000替换为自己的就OK了
val scores = sc.textFile("hdfs://hadoop01:9000/score.txt")
//人数
val totalStudents = scores.map(line => line.split(",")(0)).distinct().count()
// (2) 计算该系共开设了多少门课程
val totalCourses = scores.map(line => line.split(",")(1)).distinct().count()
// (3) 计算 Tom 同学的总成绩平均分
val tomScores = scores.filter(_.startsWith("Tom")).map(_.split(",")(2).toInt)
val tomAvgScore = tomScores.sum() / tomScores.count()
// (4) 计算每名同学的选修课程门数
val courseCounts = scores.map(line => (line.split(",")(0), 1)).reduceByKey(_ + _)
// (5) 计算该系 DataBase 课程共有多少人选修
val dbStudents = scores.filter(_.split(",")(1) == "DataBase").map(_.split(",")(0)).distinct().count()
// 输出结果
println(s"该系总共有 ${totalStudents} 位学生")
println(s"该系共开设了 ${totalCourses} 门课程")
println(s"Tom 同学的总成绩平均分为 ${tomAvgScore} 分")
println("每位同学选修的课程门数如下:")
courseCounts.collect().foreach { case (student, count) =>
println(s"${student} 选修了 ${count} 门课程")
}
println(s"该系 DataBase 课程共有 ${dbStudents} 人选修")
实验过程:
################################LOG########################################
scala> val scores = sc.textFile("hdfs://hadoop01:9000/score.txt")
2024-03-20 15:32:06,949 INFO memory.MemoryStore: Block broadcast_1 stored as values in memory (estimated size 389.1 KiB, free 365.5 MiB)
2024-03-20 15:32:06,978 INFO memory.MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 40.2 KiB, free 365.5 MiB)
2024-03-20 15:32:06,980 INFO storage.BlockManagerInfo: Added broadcast_1_piece0 in memory on hadoop01:38796 (size: 40.2 KiB, free: 366.2 MiB)
2024-03-20 15:32:06,982 INFO spark.SparkContext: Created broadcast 1 from textFile at <console>:23
scores: org.apache.spark.rdd.RDD[String] = hdfs://hadoop01:9000/score.txt MapPartitionsRDD[4] at textFile at <console>:23
scala> val totalStudents = scores.map(line => line.split(",")(0)).distinct().count()
2024-03-20 15:32:14,939 INFO mapred.FileInputFormat: Total input files to process : 1
2024-03-20 15:32:15,160 INFO spark.SparkContext: Starting job: count at <console>:23
2024-03-20 15:32:15,628 INFO scheduler.DAGScheduler: Registering RDD 6 (distinct at <console>:23) as input to shuffle 0
......
2024-03-20 15:33:15,396 INFO scheduler.TaskSetManager: Starting task 0.0 in stage 7.0 (TID 14) (hadoop01, executor driver, partition 0, NODE_LOCAL, 7181 bytes)
2024-03-20 15:33:15,396 INFO scheduler.TaskSetManager: Starting task 1.0 in stage 7.0 (TID 15) (hadoop01, executor driver, partition 1, NODE_LOCAL, 7181 bytes)
2024-03-20 15:33:15,397 INFO executor.Executor: Running task 1.0 in stage 7.0 (TID 15)
2024-03-20 15:33:15,397 INFO executor.Executor: Running task 0.0 in stage 7.0 (TID 14)
2024-03-20 15:33:15,399 INFO storage.ShuffleBlockFetcherIterator: Getting 2 (580.0 B) non-empty blocks including 2 (580.0 B) local and 0 (0.0 B) host-local and 0 (0.0 B) push-merged-local and 0 (0.0 B) remote blocks
2024-03-20 15:33:15,399 INFO storage.ShuffleBlockFetcherIterator: Started 0 remote fetches in 0 ms
2024-03-20 15:33:15,399 INFO storage.ShuffleBlockFetcherIterator: Getting 2 (580.0 B) non-empty blocks including 2 (580.0 B) local and 0 (0.0 B) host-local and 0 (0.0 B) push-merged-local and 0 (0.0 B) remote blocks
2024-03-20 15:33:15,399 INFO storage.ShuffleBlockFetcherIterator: Started 0 remote fetches in 0 ms
2024-03-20 15:33:15,406 INFO executor.Executor: Finished task 0.0 in stage 7.0 (TID 14). 1747 bytes result sent to driver
2024-03-20 15:33:15,406 INFO executor.Executor: Finished task 1.0 in stage 7.0 (TID 15). 1747 bytes result sent to driver
2024-03-20 15:33:15,407 INFO scheduler.TaskSetManager: Finished task 1.0 in stage 7.0 (TID 15) in 11 ms on hadoop01 (executor driver) (1/2)
2024-03-20 15:33:15,407 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 7.0 (TID 14) in 11 ms on hadoop01 (executor driver) (2/2)
2024-03-20 15:33:15,407 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 7.0, whose tasks have all completed, from pool
2024-03-20 15:33:15,408 INFO scheduler.DAGScheduler: ResultStage 7 (count at <console>:23) finished in 0.019 s
2024-03-20 15:33:15,408 INFO scheduler.DAGScheduler: Job 4 is finished. Cancelling potential speculative or zombie tasks for this job
2024-03-20 15:33:15,408 INFO scheduler.TaskSchedulerImpl: Killing all running tasks in stage 7: Stage finished
2024-03-20 15:33:15,409 INFO scheduler.DAGScheduler: Job 4 finished: count at <console>:23, took 0.057629 s
dbStudents: Long = 125
scala> println(s"该系总共有 ${totalStudents} 位学生")
该系总共有 265 位学生
scala> println(s"该系共开设了 ${totalCourses} 门课程")
该系共开设了 8 门课程
scala> println(s"Tom 同学的总成绩平均分为 ${tomAvgScore} 分")
2024-03-20 15:33:26,537 INFO storage.BlockManagerInfo: Removed broadcast_8_piece0 on hadoop01:38796 in memory (size: 4.1 KiB, free: 366.2 MiB)
2024-03-20 15:33:26,547 INFO storage.BlockManagerInfo: Removed broadcast_9_piece0 on hadoop01:38796 in memory (size: 3.4 KiB, free: 366.2 MiB)
2024-03-20 15:33:26,558 INFO storage.BlockManagerInfo: Removed broadcast_5_piece0 on hadoop01:38796 in memory (size: 3.4 KiB, free: 366.2 MiB)
2024-03-20 15:33:26,569 INFO storage.BlockManagerInfo: Removed broadcast_4_piece0 on hadoop01:38796 in memory (size: 4.0 KiB, free: 366.2 MiB)
2024-03-20 15:33:26,578 INFO storage.BlockManagerInfo: Removed broadcast_6_piece0 on hadoop01:38796 in memory (size: 3.5 KiB, free: 366.2 MiB)
2024-03-20 15:33:26,584 INFO storage.BlockManagerInfo: Removed broadcast_7_piece0 on hadoop01:38796 in memory (size: 3.1 KiB, free: 366.2 MiB)
Tom 同学的总成绩平均分为 30.8 分
scala> println("每位同学选修的课程门数如下:")
每位同学选修的课程门数如下:
scala> courseCounts.collect().foreach { case (student, count) =>
| println(s"${student} 选修了 ${count} 门课程")
| }
2024-03-20 15:33:27,023 INFO spark.SparkContext: Starting job: collect at <console>:24
2024-03-20 15:33:27,024 INFO scheduler.DAGScheduler: Registering RDD 16 (map at <console>:23) as input to shuffle 3
2024-03-20 15:33:27,024 INFO scheduler.DAGScheduler: Got job 5 (collect at <console>:24) with 2 output partitions
2024-03-20 15:33:27,024 INFO scheduler.DAGScheduler: Final stage: ResultStage 9 (collect at <console>:24)
2024-03-20 15:33:27,024 INFO scheduler.DAGScheduler: Parents of final stage: List(ShuffleMapStage 8)
2024-03-20 15:33:27,024 INFO scheduler.DAGScheduler: Missing parents: List(ShuffleMapStage 8)
....
2024-03-20 15:33:27,092 INFO storage.ShuffleBlockFetcherIterator: Started 0 remote fetches in 0 ms
2024-03-20 15:33:27,104 INFO executor.Executor: Finished task 0.0 in stage 9.0 (TID 18). 4478 bytes result sent to driver
2024-03-20 15:33:27,105 INFO executor.Executor: Finished task 1.0 in stage 9.0 (TID 19). 4470 bytes result sent to driver
2024-03-20 15:33:27,107 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 9.0 (TID 18) in 21 ms on hadoop01 (executor driver) (1/2)
2024-03-20 15:33:27,108 INFO scheduler.TaskSetManager: Finished task 1.0 in stage 9.0 (TID 19) in 21 ms on hadoop01 (executor driver) (2/2)
2024-03-20 15:33:27,108 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 9.0, whose tasks have all completed, from pool
2024-03-20 15:33:27,108 INFO scheduler.DAGScheduler: ResultStage 9 (collect at <console>:24) finished in 0.028 s
2024-03-20 15:33:27,108 INFO scheduler.DAGScheduler: Job 5 is finished. Cancelling potential speculative or zombie tasks for this job
2024-03-20 15:33:27,108 INFO scheduler.TaskSchedulerImpl: Killing all running tasks in stage 9: Stage finished
2024-03-20 15:33:27,109 INFO scheduler.DAGScheduler: Job 5 finished: collect at <console>:24, took 0.085496 s
Bartholomew 选修了 5 门课程
Lennon 选修了 4 门课程
Joshua 选修了 4 门课程
Tom 选修了 5 门课程
Vic 选修了 3 门课程
Eli 选修了 5 门课程
Alva 选修了 5 门课程
Brady 选修了 5 门课程
Derrick 选修了 6 门课程
Willie 选修了 4 门课程
Bennett 选修了 6 门课程
Boyce 选修了 2 门课程
Elton 选修了 5 门课程
Sidney 选修了 5 门课程
Jay 选修了 6 门课程
Meredith 选修了 4 门课程
Harold 选修了 4 门课程
Jim 选修了 4 门课程
Adonis 选修了 5 门课程
Max 选修了 3 门课程
Abel 选修了 4 门课程
Barton 选修了 1 门课程
Peter 选修了 4 门课程
Matthew 选修了 2 门课程
Alexander 选修了 4 门课程
Donald 选修了 4 门课程
Raymondt 选修了 6 门课程
Devin 选修了 4 门课程
Kerwin 选修了 3 门课程
Borg 选修了 4 门课程
Roy 选修了 6 门课程
Harry 选修了 4 门课程
Abbott 选修了 3 门课程
Miles 选修了 6 门课程
Baron 选修了 6 门课程
Francis 选修了 4 门课程
Lewis 选修了 4 门课程
Aries 选修了 2 门课程
Glenn 选修了 6 门课程
Cleveland 选修了 4 门课程
Mick 选修了 4 门课程
Will 选修了 3 门课程
Henry 选修了 2 门课程
Jesse 选修了 7 门课程
Alvin 选修了 5 门课程
Ivan 选修了 4 门课程
Monroe 选修了 3 门课程
Hobart 选修了 4 门课程
Leo 选修了 5 门课程
Louis 选修了 6 门课程
Randolph 选修了 3 门课程
Sid 选修了 3 门课程
Blair 选修了 4 门课程
Abraham 选修了 3 门课程
Lucien 选修了 5 门课程
Benedict 选修了 6 门课程
Montague 选修了 3 门课程
Giles 选修了 7 门课程
Kerr 选修了 4 门课程
Berg 选修了 4 门课程
Simon 选修了 2 门课程
Lou 选修了 2 门课程
Ronald 选修了 3 门课程
Pete 选修了 3 门课程
Harlan 选修了 6 门课程
Arlen 选修了 4 门课程
Maxwell 选修了 4 门课程
Kennedy 选修了 4 门课程
Bernard 选修了 2 门课程
Spencer 选修了 5 门课程
Andy 选修了 3 门课程
Jeremy 选修了 6 门课程
Alan 选修了 5 门课程
Bruno 选修了 5 门课程
Jerry 选修了 3 门课程
Donahue 选修了 5 门课程
Barry 选修了 5 门课程
Kent 选修了 4 门课程
Frank 选修了 3 门课程
Noah 选修了 4 门课程
Mike 选修了 3 门课程
Tony 选修了 3 门课程
Webb 选修了 7 门课程
Ken 选修了 3 门课程
Philip 选修了 2 门课程
Robin 选修了 4 门课程
Amos 选修了 5 门课程
Chapman 选修了 4 门课程
Valentine 选修了 8 门课程
Angelo 选修了 2 门课程
Boyd 选修了 3 门课程
Chad 选修了 6 门课程
Benjamin 选修了 4 门课程
Allen 选修了 4 门课程
Evan 选修了 3 门课程
Albert 选修了 3 门课程
Alfred 选修了 2 门课程
Newman 选修了 2 门课程
Winston 选修了 4 门课程
Rory 选修了 4 门课程
Dean 选修了 7 门课程
Claude 选修了 2 门课程
Booth 选修了 6 门课程
Channing 选修了 4 门课程
Ward 选修了 4 门课程
Chester 选修了 6 门课程
Webster 选修了 2 门课程
Marshall 选修了 4 门课程
Cliff 选修了 5 门课程
Emmanuel 选修了 3 门课程
Jerome 选修了 3 门课程
Upton 选修了 5 门课程
Corey 选修了 4 门课程
Perry 选修了 5 门课程
Herbert 选修了 3 门课程
Maurice 选修了 2 门课程
Drew 选修了 5 门课程
Brandon 选修了 5 门课程
Adolph 选修了 4 门课程
Levi 选修了 2 门课程
Bing 选修了 6 门课程
Antonio 选修了 3 门课程
Stan 选修了 3 门课程
Les 选修了 6 门课程
Charles 选修了 3 门课程
Clement 选修了 5 门课程
Blithe 选修了 3 门课程
Brian 选修了 6 门课程
Matt 选修了 4 门课程
Archibald 选修了 5 门课程
Horace 选修了 5 门课程
Sebastian 选修了 6 门课程
Verne 选修了 3 门课程
Ford 选修了 3 门课程
Enoch 选修了 3 门课程
Kim 选修了 4 门课程
Conrad 选修了 2 门课程
Marvin 选修了 3 门课程
Michael 选修了 5 门课程
Ernest 选修了 5 门课程
Marsh 选修了 4 门课程
Duke 选修了 4 门课程
Armand 选修了 3 门课程
Lester 选修了 4 门课程
Broderick 选修了 3 门课程
Hayden 选修了 3 门课程
Bertram 选修了 3 门课程
Bart 选修了 5 门课程
Duncann 选修了 5 门课程
Colby 选修了 4 门课程
Bowen 选修了 5 门课程
Elmer 选修了 4 门课程
Elvis 选修了 2 门课程
Adair 选修了 3 门课程
Roderick 选修了 4 门课程
Walter 选修了 4 门课程
Jonathan 选修了 4 门课程
Jo 选修了 5 门课程
Rod 选修了 4 门课程
Scott 选修了 3 门课程
Elliot 选修了 3 门课程
Alvis 选修了 6 门课程
Joseph 选修了 3 门课程
Geoffrey 选修了 4 门课程
Todd 选修了 3 门课程
Wordsworth 选修了 4 门课程
Wright 选修了 4 门课程
Adam 选修了 3 门课程
Sandy 选修了 1 门课程
Ben 选修了 4 门课程
Clyde 选修了 7 门课程
Mark 选修了 7 门课程
Dempsey 选修了 4 门课程
Rock 选修了 6 门课程
Ellis 选修了 4 门课程
Edward 选修了 4 门课程
Eugene 选修了 1 门课程
Samuel 选修了 4 门课程
Gerald 选修了 4 门课程
Luthers 选修了 5 门课程
Virgil 选修了 5 门课程
Bradley 选修了 2 门课程
Dick 选修了 3 门课程
Bevis 选修了 4 门课程
Merlin 选修了 5 门课程
Armstrong 选修了 2 门课程
Ron 选修了 6 门课程
Archer 选修了 5 门课程
Nick 选修了 5 门课程
Hogan 选修了 4 门课程
Len 选修了 5 门课程
Benson 选修了 4 门课程
Colbert 选修了 4 门课程
John 选修了 6 门课程
Saxon 选修了 7 门课程
Marico 选修了 6 门课程
Kevin 选修了 4 门课程
Uriah 选修了 1 门课程
Aldrich 选修了 3 门课程
Jeffrey 选修了 4 门课程
Brook 选修了 4 门课程
Nicholas 选修了 5 门课程
Elijah 选修了 4 门课程
Bill 选修了 2 门课程
Greg 选修了 4 门课程
Payne 选修了 6 门课程
Colin 选修了 5 门课程
Gordon 选修了 4 门课程
Tracy 选修了 3 门课程
Alston 选修了 4 门课程
George 选修了 4 门课程
Griffith 选修了 4 门课程
Andrew 选修了 4 门课程
Egbert 选修了 4 门课程
Bishop 选修了 2 门课程
Beck 选修了 4 门课程
Gilbert 选修了 3 门课程
Phil 选修了 3 门课程
Antony 选修了 5 门课程
Nelson 选修了 5 门课程
Christ 选修了 2 门课程
Bruce 选修了 3 门课程
Rodney 选修了 3 门课程
Boris 选修了 6 门课程
Marlon 选修了 4 门课程
Don 选修了 2 门课程
Aaron 选修了 4 门课程
Sean 选修了 6 门课程
Truman 选修了 3 门课程
Solomon 选修了 5 门课程
Blake 选修了 4 门课程
Christopher 选修了 4 门课程
Clare 选修了 4 门课程
Milo 选修了 2 门课程
Victor 选修了 2 门课程
Nigel 选修了 3 门课程
Jonas 选修了 4 门课程
Jason 选修了 4 门课程
Hilary 选修了 4 门课程
Woodrow 选修了 3 门课程
William 选修了 6 门课程
Dennis 选修了 4 门课程
Jeff 选修了 4 门课程
Dominic 选修了 4 门课程
Merle 选修了 3 门课程
Elroy 选修了 5 门课程
Harvey 选修了 7 门课程
Clark 选修了 6 门课程
Herman 选修了 3 门课程
Bert 选修了 3 门课程
Alger 选修了 5 门课程
Hiram 选修了 6 门课程
Leonard 选修了 2 门课程
Kenneth 选修了 3 门课程
Leopold 选修了 7 门课程
Eric 选修了 4 门课程
Basil 选修了 4 门课程
Martin 选修了 3 门课程
Clarence 选修了 7 门课程
Bernie 选修了 3 门课程
Vincent 选修了 5 门课程
Christian 选修了 2 门课程
Winfred 选修了 3 门课程
Lionel 选修了 4 门课程
Bob 选修了 3 门课程
scala> println(s"该系 DataBase 课程共有 ${dbStudents} 人选修")
该系 DataBase 课程共有 125 人选修
################################LOG########################################
** **学生填写代码以及给出最终结果
(1) 该系总共有多少学生;
val scores = sc.textFile("hdfs://hadoop01:9000/score.txt")
val totalStudents = scores.map(line => line.split(",")(0)).distinct().count()

答案为:265 人
(2) 该系共开设来多少门课程;
val totalCourses = scores.map(line => line.split(",")(1)).distinct().count()
答案为:8门
(3) Tom同学的总成绩平均分是多少;
val tomScores = scores.filter(.startsWith("Tom")).map(.split(",")(2).toInt)
val tomAvgScore = tomScores.sum() / tomScores.count()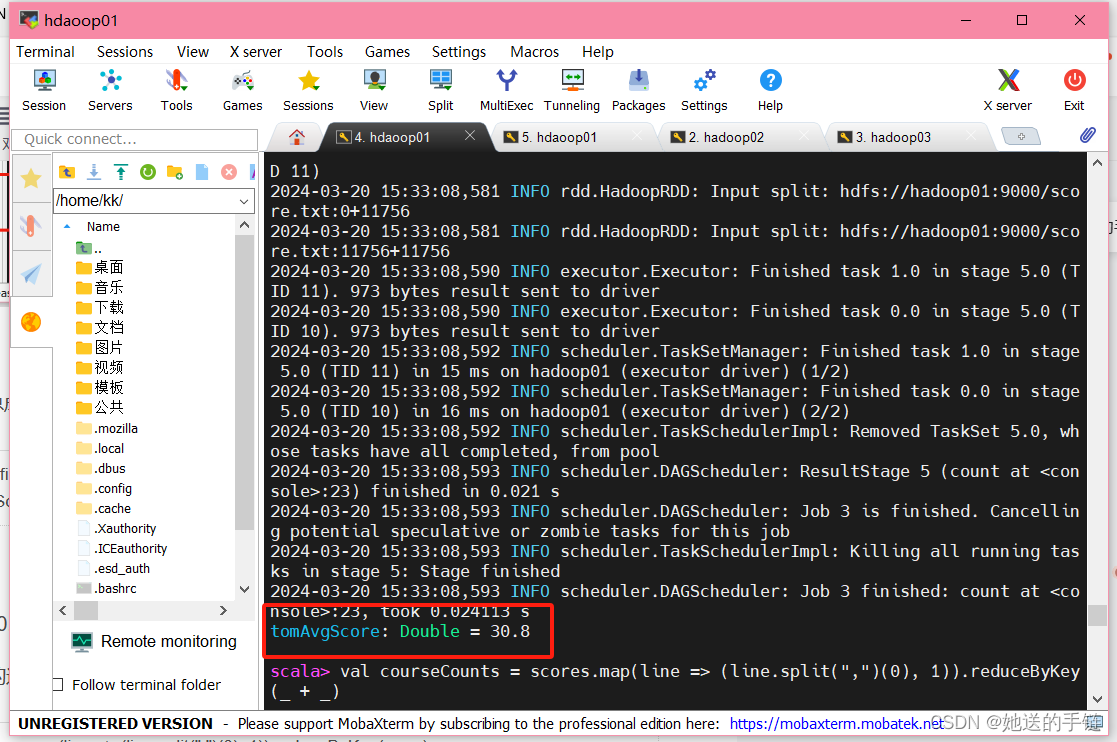
Tom同学的平均分为 30.8分
(4) 求每名同学的选修的课程门数;
val courseCounts = scores.map(line => (line.split(",")(0), 1)).reduceByKey(_ + _)
太多了就不显示了,总共265行

答案共:265行
(5) 该系DataBase课程共有多少人选修;
val dbStudents = scores.filter(.split(",")(1) == "DataBase").map(.split(",")(0)).distinct().count()
答案为:125 人
2.spark编程统计客户总消费金额
实验目标:
(1) 掌握数据读取和存储的方法
(2) 掌握RDD的基本操作
实验说明:
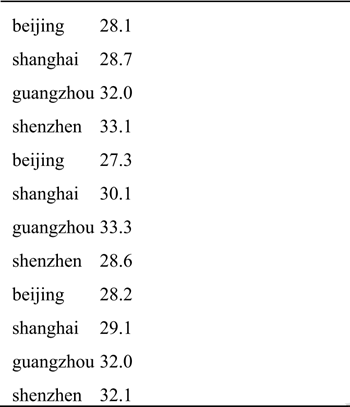
现有一份某电商2020年12月份的订单数据文件onlin_retail.csv,记录了每位顾客每笔订单的购物情况,包含三个数据字段,字段说明如下表所示。现需要统计每位客户的总消费金额,并筛选出消费金额在前50名的客户。

实现思路及步骤:
(1) 读取数据并创建RDD
(2) 通过map()方法分割数据,选择客户编号和订单价格字段组成键值对数据
(3) 使用reduceByKey()方法计算每位客户的总消费金额
(4) 使用sortBy()方法对每位客户的总消费金额进行降序排序,取出前50条数
实验过程:
- 读取数据并创建 RDD: 从 HDFS 中读取名为
online_retail.txt的订单数据文件,过滤掉首行(即列名)。 - 通过 map() 方法分割数据: 对每一行数据执行
split(",")操作,将数据切分为字段,并选取顾客编号(第一个字段)和订单价格(第二个字段)作为键值对的键和值。 - 使用 reduceByKey() 方法计算总消费金额: 将相同顾客编号的订单价格进行累加,得到每位顾客的总消费金额。
- 使用 sortBy() 方法对总消费金额进行降序排序: 将每位顾客的总消费金额进行降序排序,并取出前50名顾客。
- 打印结果: 将前50名顾客的顾客编号和总消费金额打印出来。
实现代码(学生填写):
// (1) 读取数据并创建RDD
val lines = sc.textFile("hdfs://hadoop01:9000/online_retail.txt").filter(!_.startsWith("Customer ID"))
// (2) 通过map()方法分割数据,选择顾客编号和订单价格字段组成键值对数据
val customerSpending = lines.map(line => {
val fields = line.split(",")
(fields(0), fields(1).toDouble)
})
// (3) 使用reduceByKey()方法计算每位顾客的总消费金额
val totalSpendingPerCustomer = customerSpending.reduceByKey(_ + _)
// (4) 使用sortBy()方法对每位顾客的总消费金额进行降序排序,取出前50条数据
val top50Customers = totalSpendingPerCustomer.sortBy(_._2, ascending = false).take(50)
// 打印结果
top50Customers.foreach(customer => println(s"顾客ID: ${customer._1} - 总消费金额: ${customer._2}"))
实验记录:
scala> val lines = sc.textFile("hdfs://hadoop01:9000/online_retail.txt").filter(!_.startsWith("Customer ID"))
2024-03-25 15:32:11,083 INFO memory.MemoryStore: Block broadcast_2 stored as values in memory (estimated size 389.1 KiB, free 365.5 MiB)
2024-03-25 15:32:11,122 INFO memory.MemoryStore: Block broadcast_2_piece0 stored as bytes in memory (estimated size 40.2 KiB, free 365.5 MiB)
2024-03-25 15:32:11,126 INFO storage.BlockManagerInfo: Added broadcast_2_piece0 in memory on hadoop01:40652 (size: 40.2 KiB, free: 366.2 MiB)
2024-03-25 15:32:11,128 INFO spark.SparkContext: Created broadcast 2 from textFile at <console>:23
lines: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[9] at filter at <console>:23
scala> val customerSpending = lines.map(line => {
| val fields = line.split(",")
| (fields(0), fields(1).toDouble)
| })
customerSpending: org.apache.spark.rdd.RDD[(String, Double)] = MapPartitionsRDD[10] at map at <console>:23
scala> val totalSpendingPerCustomer = customerSpending.reduceByKey(_ + _)
2024-03-25 15:32:22,505 INFO mapred.FileInputFormat: Total input files to process : 1
totalSpendingPerCustomer: org.apache.spark.rdd.RDD[(String, Double)] = ShuffledRDD[11] at reduceByKey at <console>:23
scala> val top50Customers = totalSpendingPerCustomer.sortBy(_._2, ascending = false).take(50)
2024-03-25 15:32:26,850 INFO spark.SparkContext: Starting job: sortBy at <console>:23
2024-03-25 15:32:26,856 INFO scheduler.DAGScheduler: Registering RDD 10 (map at <console>:23) as input to shuffle 1
2024-03-25 15:32:26,857 INFO scheduler.DAGScheduler: Got job 1 (sortBy at <console>:23) with 2 output partitions
......
2024-03-25 15:32:27,852 INFO executor.Executor: Finished task 0.0 in stage 6.0 (TID 8). 3276 bytes result sent to driver
2024-03-25 15:32:27,854 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 6.0 (TID 8) in 69 ms on hadoop01 (executor driver) (1/1)
2024-03-25 15:32:27,854 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 6.0, whose tasks have all completed, from pool
2024-03-25 15:32:27,855 INFO scheduler.DAGScheduler: ResultStage 6 (take at <console>:23) finished in 0.090 s
2024-03-25 15:32:27,856 INFO scheduler.DAGScheduler: Job 2 is finished. Cancelling potential speculative or zombie tasks for this job
2024-03-25 15:32:27,856 INFO scheduler.TaskSchedulerImpl: Killing all running tasks in stage 6: Stage finished
2024-03-25 15:32:27,856 INFO scheduler.DAGScheduler: Job 2 finished: take at <console>:23, took 0.211368 s
top50Customers: Array[(String, Double)] = Array(("",174463.66000000347), (12748,1618.1500000000015), (14911,1573.1600000000014), (17850,1176.2299999999982), (17841,1073.1299999999997), (14606,828.5199999999996), (16607,726.3199999999999), (14527,666.1399999999996), (17340,613.5099999999999), (15311,582.7899999999997), (15044,545.4599999999998), (13174,519.7500000000001), (14667,506.5499999999998), (15727,456.44999999999993), (17961,414.82000000000005), (14030,413.75), (18116,410.97999999999973), (15039,404.6699999999998), (16873,401.4299999999999), (18118,389.7099999999998), (15574,386.2499999999999), (14180,382.24999999999994), (16713,377.51999999999987), (18055,377.3799999999999), (14505,373.29999999999956), (15498,369.66999999999996), (15808,366.299999999999...
scala> top50Customers.foreach(customer => println(s"顾客ID: ${customer._1} - 总消费金额: ${customer._2}"))
2024-03-25 15:32:32,608 INFO storage.BlockManagerInfo: Removed broadcast_4_piece0 on hadoop01:40652 in memory (size: 4.0 KiB, free: 366.2 MiB)
顾客ID: - 总消费金额: 174463.66000000347
顾客ID: 12748 - 总消费金额: 1618.1500000000015
顾客ID: 14911 - 总消费金额: 1573.1600000000014
顾客ID: 17850 - 总消费金额: 1176.2299999999982
顾客ID: 17841 - 总消费金额: 1073.1299999999997
顾客ID: 14606 - 总消费金额: 828.5199999999996
顾客ID: 16607 - 总消费金额: 726.3199999999999
顾客ID: 14527 - 总消费金额: 666.1399999999996
顾客ID: 17340 - 总消费金额: 613.5099999999999
顾客ID: 15311 - 总消费金额: 582.7899999999997
顾客ID: 15044 - 总消费金额: 545.4599999999998
顾客ID: 13174 - 总消费金额: 519.7500000000001
顾客ID: 14667 - 总消费金额: 506.5499999999998
顾客ID: 15727 - 总消费金额: 456.44999999999993
顾客ID: 17961 - 总消费金额: 414.82000000000005
顾客ID: 14030 - 总消费金额: 413.75
顾客ID: 18116 - 总消费金额: 410.97999999999973
顾客ID: 15039 - 总消费金额: 404.6699999999998
顾客ID: 16873 - 总消费金额: 401.4299999999999
顾客ID: 18118 - 总消费金额: 389.7099999999998
顾客ID: 15574 - 总消费金额: 386.2499999999999
顾客ID: 14180 - 总消费金额: 382.24999999999994
顾客ID: 16713 - 总消费金额: 377.51999999999987
顾客ID: 18055 - 总消费金额: 377.3799999999999
顾客ID: 14505 - 总消费金额: 373.29999999999956
顾客ID: 15498 - 总消费金额: 369.66999999999996
顾客ID: 15808 - 总消费金额: 366.2999999999998
顾客ID: 15570 - 总消费金额: 363.50999999999993
顾客ID: 12567 - 总消费金额: 360.3999999999999
顾客ID: 17341 - 总消费金额: 343.92999999999995
顾客ID: 16003 - 总消费金额: 339.14
顾客ID: 15159 - 总消费金额: 338.5599999999999
顾客ID: 12471 - 总消费金额: 337.2599999999997
顾客ID: 15640 - 总消费金额: 335.16999999999996
顾客ID: 12647 - 总消费金额: 328.49999999999994
顾客ID: 15514 - 总消费金额: 326.68
顾客ID: 17377 - 总消费金额: 320.38999999999993
顾客ID: 16782 - 总消费金额: 310.3399999999999
顾客ID: 15998 - 总消费金额: 307.53999999999985
顾客ID: 17827 - 总消费金额: 305.8199999999997
顾客ID: 14415 - 总消费金额: 305.21999999999974
顾客ID: 14573 - 总消费金额: 304.6999999999999
顾客ID: 13564 - 总消费金额: 300.01
顾客ID: 17591 - 总消费金额: 297.5499999999999
顾客ID: 13145 - 总消费金额: 295.0
顾客ID: 15061 - 总消费金额: 293.1500000000001
顾客ID: 14083 - 总消费金额: 287.68999999999994
顾客ID: 16274 - 总消费金额: 286.5999999999998
顾客ID: 14723 - 总消费金额: 279.93
顾客ID: 14733 - 总消费金额: 279.06
实验结果:

3.spark编程统计各城市的平均气温
实验目标:
(1) 掌握RDD创建方法
(2) 掌握map,groupby,mapvalues,reduce方法的使用
实验说明:
现有一份各城市的温度数据文件avgTemperature.txt,数据如下表所示,记录了某段时间范围内各城市每天的温度,文件中每一行数据分别表示城市名和温度,现要求用spark编程计算出各城市的平均气温。
实现思路及步骤:
(1) 通过textFile()方法读取数据创建RDD
(2) 使用map()方法将数据输入数据按制表符进行分割,并转化成(城市,温度)的形式
(3) 使用groupBy()方法按城市分组,得到每个城市对应的所欲温度。
(4) 使用mapValues()和reduce()方法计算各城市的平均气温
实验过程:
- 通过textFile()方法读取数据创建RDD: 使用 SparkContext 的
textFile()方法从 HDFS 中的avgTemperature.txt文件读取数据,并创建一个包含文件中每一行的 RDD。 - 使用map()方法将数据按制表符进行分割,并转化成(城市,温度)的形式: 对 RDD 中的每一行数据执行
map()操作,将每行数据按制表符进行分割,并将城市名和温度值组成键值对。 - 使用groupBy()方法按城市分组,得到每个城市对应的所有温度: 使用
groupBy()方法将键值对按城市分组,得到每个城市对应的所有温度的 Iterable。 - 使用mapValues()和reduce()方法计算各城市的平均气温: 对每个城市的温度集合使用
mapValues()方法计算平均气温,然后使用reduce()方法对温度进行求和,并除以温度的数量,得到平均值。 - 打印结果: 使用
foreach()方法遍历每个城市的平均气温,并将结果打印出来,格式为 "城市:平均气温"。
实现代码(学生填写):
// (1) 通过textFile()方法读取数据创建RDD
val lines = sc.textFile("hdfs://hadoop01:9000/avgTemperature.txt")
// (2) 使用map()方法将数据按制表符进行分割,并转化成(城市,温度)的形式
val cityTemperatures = lines.map(line => {
val fields = line.split("\t")
(fields(0), fields(1).toDouble)
})
// (3) 使用groupBy()方法按城市分组,得到每个城市对应的所有温度
val cityTemperatureGroups = cityTemperatures.groupByKey()
// (4) 使用mapValues()和reduce()方法计算各城市的平均气温
val averageTemperatures = cityTemperatureGroups.mapValues(temperatures => temperatures.reduce(_ + _) / temperatures.size)
// 打印结果
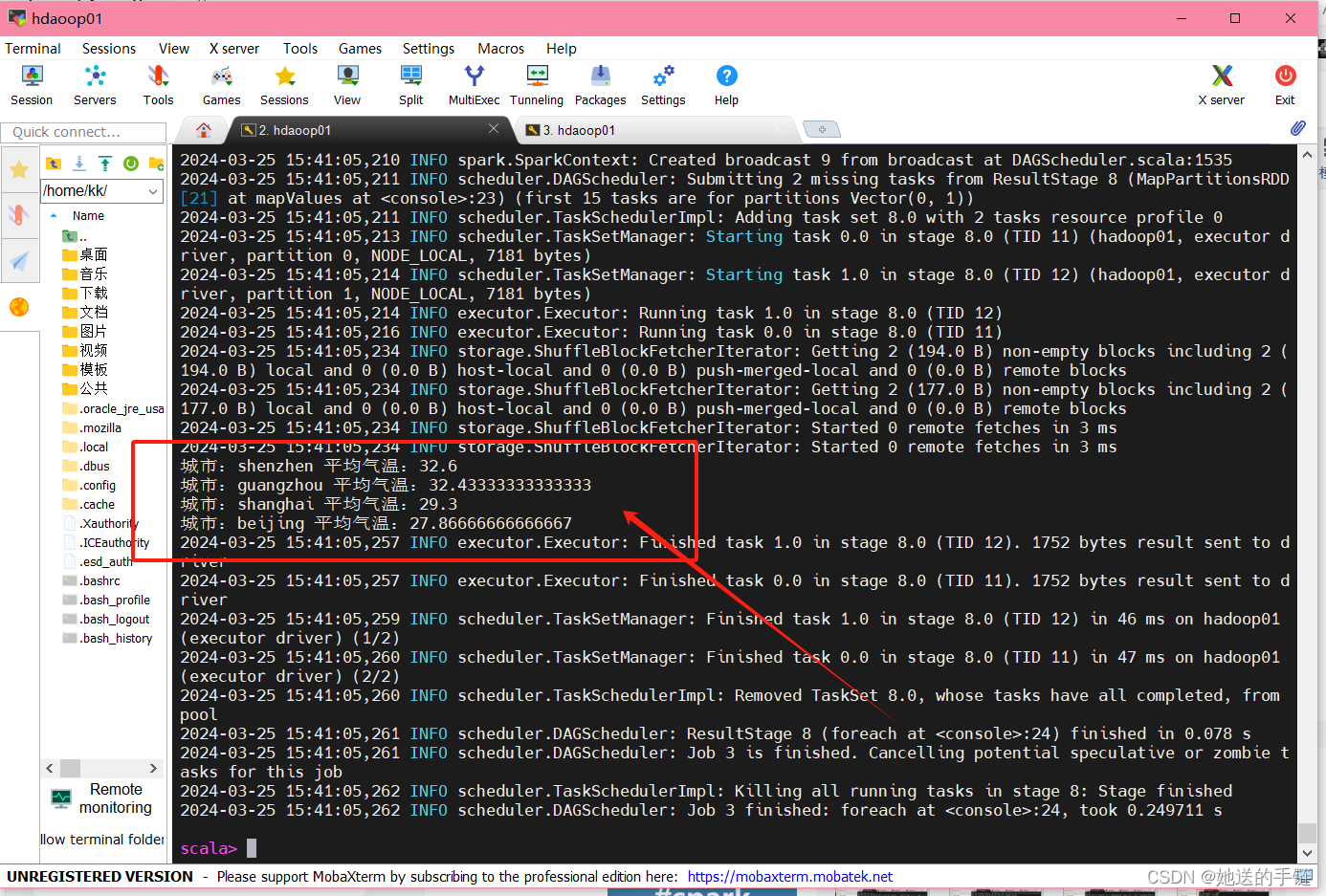
averageTemperatures.foreach(city => println(s"城市:${city._1} 平均气温:${city._2}"))
实验记录:
scala> val lines = sc.textFile("hdfs://hadoop01:9000/avgTemperature.txt")
2024-03-25 15:40:46,632 INFO memory.MemoryStore: Block broadcast_7 stored as values in memory (estimated size 389.1 KiB, free 365.1 MiB)
2024-03-25 15:40:46,671 INFO memory.MemoryStore: Block broadcast_7_piece0 stored as bytes in memory (estimated size 40.2 KiB, free 365.0 MiB)
2024-03-25 15:40:46,673 INFO storage.BlockManagerInfo: Added broadcast_7_piece0 in memory on hadoop01:40652 (size: 40.2 KiB, free: 366.2 MiB)
2024-03-25 15:40:46,675 INFO spark.SparkContext: Created broadcast 7 from textFile at <console>:23
lines: org.apache.spark.rdd.RDD[String] = hdfs://hadoop01:9000/avgTemperature.txt MapPartitionsRDD[18] at textFile at <console>:23
scala> val cityTemperatures = lines.map(line => {
| val fields = line.split("\t")
| (fields(0), fields(1).toDouble)
| })
cityTemperatures: org.apache.spark.rdd.RDD[(String, Double)] = MapPartitionsRDD[19] at map at <console>:23
scala> val cityTemperatureGroups = cityTemperatures.groupByKey()
2024-03-25 15:40:55,462 INFO mapred.FileInputFormat: Total input files to process : 1
cityTemperatureGroups: org.apache.spark.rdd.RDD[(String, Iterable[Double])] = ShuffledRDD[20] at groupByKey at <console>:23
scala> val averageTemperatures = cityTemperatureGroups.mapValues(temperatures => temperatures.reduce(_ + _) / temperatures.size)
averageTemperatures: org.apache.spark.rdd.RDD[(String, Double)] = MapPartitionsRDD[21] at mapValues at <console>:23
scala> averageTemperatures.foreach(city => println(s"城市:${city._1} 平均气温:${city._2}"))
2024-03-25 15:41:05,012 INFO spark.SparkContext: Starting job: foreach at <console>:24
2024-03-25 15:41:05,017 INFO scheduler.DAGScheduler: Registering RDD 19 (map at <console>:23) as input to shuffle 3
2024-03-25 15:41:05,018 INFO scheduler.DAGScheduler: Got job 3 (foreach at <console>:24) with 2 output partitions
2024-03-25 15:41:05,018 INFO scheduler.DAGScheduler: Final stage: ResultStage 8 (foreach at <console>:24)
2024-03-25 15:41:05,019 INFO scheduler.DAGScheduler: Parents of final stage: List(ShuffleMapStage 7)
....
2024-03-25 15:41:05,234 INFO storage.ShuffleBlockFetcherIterator: Getting 2 (177.0 B) non-empty blocks including 2 (177.0 B) local and 0 (0.0 B) host-local and 0 (0.0 B) push-merged-local and 0 (0.0 B) remote blocks
2024-03-25 15:41:05,234 INFO storage.ShuffleBlockFetcherIterator: Started 0 remote fetches in 3 ms
2024-03-25 15:41:05,234 INFO storage.ShuffleBlockFetcherIterator: Started 0 remote fetches in 3 ms
城市:shenzhen 平均气温:32.6
城市:guangzhou 平均气温:32.43333333333333
城市:shanghai 平均气温:29.3
城市:beijing 平均气温:27.86666666666667
实验结果:
版权归原作者 她送的手链 所有, 如有侵权,请联系我们删除。