
1.Hadoop 生态圈组件介绍

一、简介
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。Hadoop的框架最核心的设计就是:HDFS和MapReduce。HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
二、HDFS
Hadoop Distributed File System,简称HDFS,是个分布式文件系统,是hadoop的一个核心部分。HDFS有这高容错性(fault-tolerent)的特点,并且设计用来部署在低廉价的(low-cost)的硬件上,提供了高吞吐量(high-throughout)来访问应用程序的数据,适合那些有着超大数据集(largedata set)的应用程序。HDFS开始是为开源的apache项目nutch的基础结构而创建的。
三、MapReduce
Mapreduce是一个编程模型,一个处理和生成超大数据集算法模型的实现,简单概括就是“数据分解、并行计算、结果合并“。Mapreduce最大的优点是它简单的编程模型,程序猿只需根据该模型框架设计map和reduce函数,剩下的任务,如:分布式存储、节点任务调度、节点通讯、容错处理和故障处理都由mapreudce框架来完成,程序的设计有很高的扩展性。
2.Hadoop的核心组件。
- 核心组件有:Hdfs、Yarn、MapReduce;
- 广义上指一个生态圈,泛指大数据技术相关的开源组件或产品,如hdfs、yarn、hbase、hive、spark、pig、zookeeper、kafka、flume、phoenix、sqoop。
3..、分门别类介绍其中详细组件为了方便理解以下按照功能进行了分类,并且把较为流行的排在了前面介绍,列表如下:
文件系统
HDFS,目前大量采用的分布式文件系统,是整个大数据应用场景的基础通用文件存储组件S3, Simple Storage Service简单存储服务,更好的可扩展性,内置的持久性,以及较低的价格
资源调度
YARN,分布式资源调度,可以接收计算的任务把它分配到集群各节点处理,相当于大数据操作系统,通用性好,生态支持好;Mesos,同YARN类似,偏向于资源的抽象和管理
计算框架
Spark序列,有流计算、图计算、机器学习;
Flink,支持计算数据不断变化,即增量计算;
Storm,专注于流式计算,功能强大;
Mapreduce, 分布式计算基本计算框架,编程难度高,执行效率低
数据库
Hbase,一种NoSQL列簇数据库,支持数十亿行数百万列大型数据储存和访问,尤其是写数据的性能非常好,数据读取实时性较好,提供一套API,不支持SQL操作,数据存储采用HDFS;Cassandra,对大型表格和 Dynamo支持得最好;Redis,运行异常快,还可应用于分布式缓存场景
SQL支持
Spark SQL,由Shark、Hive发展而来的,以SQL方式访问数据源(如hdfs、hbase、S3、redis甚至关系统数据库等,下同);
Phoenix,一套专注于SQL方式访问hbase的JDBC驱动,支持绝大部分SQL语法,支持二级索引,支持事务,低延时;
Hive,通过HQL(类似SQL)来统计分析生成查询结果,通过解析HQL生成可以Mapreduce上执行的任务,典型的应用场景是与hbase集成;
其它:impala、pig等,都实现了类似的功能,解决了直接写map/reduce分析数据的复杂性,降低了数据分析工作者或开发人员使用大数据的门槛
其它工具
分布式协作zookeeper,可以理解为一个小型高性能的数据库,为生态圈中与很多组件提供发布订阅的功能,还可以监测节点是否失效(心跳检测),如HBase、Kafka中利用zookeeper存放了主从节点信息;
Kafka, 是一种分布式的,基于发布/订阅的消息系统,类似于消息对列的功能,可以接收生产者(如webservice、文件、hdfs、hbase等)的数据,本身可以缓存起来,然后可以发送给消费者(同上),起到缓冲和适配的作;
Flume,分布式的海量日志采集、聚合和传输的系统,主要作用是数据的收集和传输,也支持非常多的输入输出数据源;
Sqoop,主要用于在Hadoop(Hive)与传统的数据库(mysql、postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle ,Postgres等)中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中
2.介绍mapreduce概述
mapreduce是hadoop的计算框架,它与hdfs关系紧密。可以说它的计算思想是基于分布式文件而设计的。
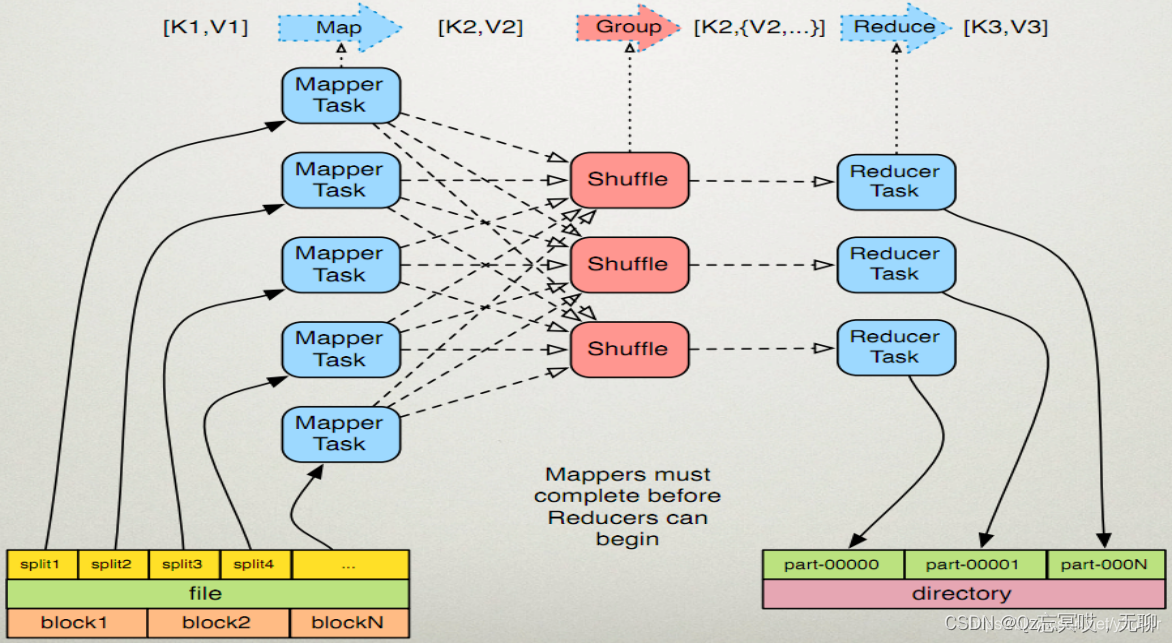
1.2 MapReduce优缺点
1.2.1 优点
1)MapReduce 易于编程
它简单的实现一些接口,就可以完成一个分布式程序,这个分布式程序可以分布到大量廉价的PC机器上运行。也就是说你写一个分布式程序,跟写一个简单的串行程序是一模一样的。就是因为这个特点使得MapReduce编程变得非常流行。
2)良好的扩展性
当你的计算资源不能得到满足的时候,你可以通过简单的增加机器来扩展它的计算能力。
3)高容错性
MapReduce设计的初衷就是使程序能够部署在廉价的PC机器上,这就要求它具有很高的容错性。比如其中一台机器挂了,它可以把上面的计算任务转移到另外一个节点上运行,不至于这个任务运行失败,而且这个过程不需要人工参与,而完全是由Hadoop内部完成的。
4)适合PB级以上海量数据的离线处理
可以实现上千台服务器集群并发工作,提供数据处理能力。
1.2.2 缺点
1)不擅长实时计算
MapReduce无法像MySQL一样,在毫秒或者秒级内返回结果。
2)不擅长流式计算
流式计算的输入数据是动态的,而MapReduce的输入数据集是静态的,不能动态变化。这是因为MapReduce自身的设计特点决定了数据源必须是静态的。
3)不擅长DAG(有向无环图)
计算多个应用程序存在依赖关系,后一个应用程序的输入为前一个的输出。在这种情况下,MapReduce并不是不能做,而是使用后,每个MapReduce作业的输出结果都会写入到磁盘,会造成大量的磁盘IO,导致性能非常的低下。
3.介绍spark技术特点和概述
1. Spark 框架概述
整个Spark框架模块包含:Spark Core、Spark SQL、 Spark Streaming、Spark GraphX、Spark MLlib,而后四项的能力都是建立在核心引擎之上。
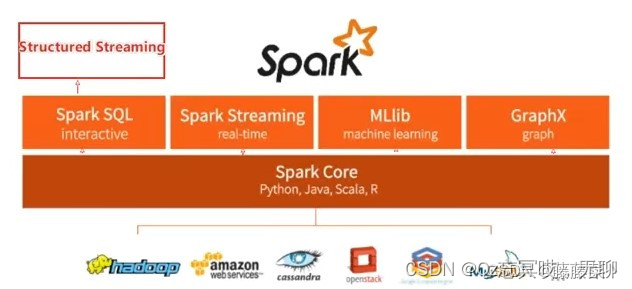
Spark Core: Spark的核心,Spark核心功能均由Spark Core模块提供,是Spark运行的基础。SparkCore以RDD为数据抽象,提供Python、Java、Scala、R语言的API,可以编程进行海量离线数据批处理计算。
SparkSQL: 基于SparkCore之上,提供结构化数据的处理模块。可以以SparkSQL为基础,进行数据的流式计算。
SparkStreaming:以SparkCore为基础,提供数据的流式计算功能。
MLlib:以SparkCore为基础,进行机器学习计算,内置了大量的机器学习库和API算法等。方便用户以分布式计算的模式进行机器学习计算。
GraphX: 以SparkCore为基础,进行图计算,提供了大量的图计算API,方便用于以分布式计算模式进行图计算。
2.spark的特点
一、速度快
由于Apache Spark支持内存计算,并且通过DAG(有向无环图)执行引擎支持无环数据流,所以官方宣称其在内存中的运算速度要比Hadoop的MapReduce快100倍,在硬盘中要快10倍
Spark处理数据与MapReduce处理数据相比,有如下两个不同点:
Spark处理数据时,可以将中间处理结果数据存储到内存中
Spark Job调度以DAG方式,并且每个任务Task执行以线程方式,并不是像MapReduce以进程方式执行
二、易于使用
Spark的版本已经更新到了Spark3.1.2(截止日期2021.06.01),支持了包括Java、Scala、Python、R和SQL语言在内的多种语言。为了兼容Spark2.x企业级应用场景,Spark仍然持续更新Spark2版本
三、通用性强
在Spark的基础上,Spark还提供了包括Spark SQL、Spark Streaming、MLib及GraphX在内的多个工具库,我们可以在一个应用中无缝的使用这些工具库

四、运行方式
Spark支持多种运行方式,包括在Hadoop和Mesos上,也支持Standalone的独立运行模式,同时也可以运行在云Kubernets(Spark2.3开始支持)上对于数据源而言,Spark支持从HDFS、HBase、Cassandra及Kafka等多种途径获取和数据
4.对比mapreduce和spark的区别
- MapReduce框架局限性
1)仅支持Map和Reduce两种操作
2)处理效率低效。
a)Map中间结果写磁盘,Reduce写HDFS,多个MR之间通过HDFS交换数据; 任务调度和启动开销大;
b)无法充分利用内存
c)Map端和Reduce端均需要排序
3)不适合迭代计算(如机器学习、图计算等),交互式处理(数据挖掘) 和流式处理(点击日志分析)
- MapReduce编程不够灵活
1)尝试scala函数式编程语言
- 主要用于hue或者支持hive sql 的表/视图创建、清空、删除,数据的查询,表结构的设置与查看。
Spark
- 高效,快3-5倍
一般来说,Spark比MapReduce运行速度快的原因主要有以下几点:
- task启动时间比较快,Spark是fork出线程;而MR是启动一个新的进程;
- 更快的shuffles,Spark只有在shuffle的时候才会将数据放在磁盘,而MR却不是。
- 更快的工作流:典型的MR工作流是由很多MR作业组成的,他们之间的数据交互需要把数据持久化到磁盘才可以;而Spark支持DAG以及pipelining,在没有遇到shuffle完全可以不把数据缓存到磁盘。
- 缓存:虽然目前HDFS也支持缓存,但是一般来说,Spark的缓存功能更加高效,特别是在SparkSQL中,我们可以将数据以列式的形式储存在内存中
1)内存计算引擎,提供Cache机制来支持需要反复迭代计算或者多次数据共享,减少数据读取的IO开销
3)使用多线程池模型来减少task启动开稍,shuffle过程中避免 不必要的sort操作以及减少磁盘IO操作
- 易用
1)提供了丰富的API,支持Java,Scala,Python和R四种语言
2)代码量比MapReduce少2~5倍
- 与Hadoop集成 读写HDFS/Hbase 与YARN集成
5.结构化数据与非结构化数据
结构化数据
结构化的数据一般是指可以使用关系型数据库表示和存储,可以用二维表来逻辑表达实现的数据。例如:需要多少个属性,每个属性什么类型,每个属性的取值范围等等,类似下图所示,提前定义好了一个二维矩阵的元数据,包含有列名称、列的类型、列的约束等:
可见,虽然结构化数据的存储和排列是很有规律的,这对查询和修改等操作很有帮助。但是,它的扩展性不好(比如,业务需要增加一个字段,此时就需要将已存储入库的所有数据全部更新一遍,效率极低)。对于结构化数据来讲通常是先有结构再有数据,而对于半结构化数据来说则是先有数据再有结构。
**非结构化数据
**非结构化数据就是没有固定结构的数据。包括所有格式的办公文档、Word、PPT、文本、图片、各类报表、图像和音频/视频信息等等。对非结构化的数据,一般以二进制的形式直接整体进行存储。
6.Linux简单操作命令实训练习
主要对用户进行删除添加设置密码等操作
**1. **文件与目录操作
命令
格式
含义
pwd
pwd
显示当前所在目录。
ls
ls [选项] [文件|目录]
显示指定目录中的文件或子目录信息。
cd
cd <路径>
切换当前用户所在的工作目录。
mkdir
mkdir [选项] 目录
创建目录。
rm
rm [选项] <文件>
删除文件或目录。
cp
cp [选项] <文件> <目标文件>
复制文件或目录。
mv
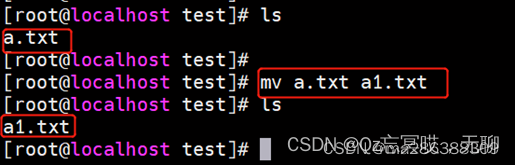
mv [选项] <文件> <目标文件>
移动文件或对其改名。
cat
cat [选项] [文件]
查看文件内容。
tar
tar [选项] [档案名] [文件或目录]
为文件和目录创建档案。
**2. **用户操作
命令
格式
含义
useradd
useradd用户名
创建新用户。
passwd
passwd用户名
设置或修改指定用户的口令。
chown
chown [选项]
将文件或目录的拥有者改为指定的用户或组。
chmod
chmod [-R] 模式 文件或目录
修改文件或目录的访问权限。
模式为文件或目录的权限表示,有三种表示方法:
(1)数字表示
(2)字符赋值
(3)字符加减权限
su
su [-] 用户名
将当前操作员的身份切换到指定用户。
sudo
sudo命令
让普通用户执行需要特殊权限的命令。
**3. **文本操作
命令
格式
含义
vi
vi [文件名]
Linux的常用文本编辑器,有三个工作模式:
(1)命令模式
启动 vi,便进入命令模式。常用的命令:
i切换到输入模式。
x 删除当前光标所在处的字符。
: 切换到末行模式。
(2)输入模式
编辑文件内容,按 Esc 键返回命令模式。
(3)末行模式
保存、查找或者替换等,需进入末行模式。常用命令:
Set nu:每一行显示行号
r 文件名:读取指定的文件。
w文件名:将编辑内容保存到指定的文件内。
q:退出vi
wq:保存文件并退出vi
q!:强制退出vi,不管是否保存文档内容。
**4. **系统操作
命令
格式
含义
clear
Clear
清除屏幕。
hostname
hostname [选项]
显示和设置系统的主机名称。
hostnamectl
格式1:hostnamectl
格式2:hostnamectl set-hostname <host-name>
格式1:显示当前主机的名称和系统版本。
格式2:永久设置当前主机的名称。
ip
格式1:ip link <选项> dev <设备名>
格式2:ip address <选项> dev <设备名>
格式1:对网络设备(网卡)进行操作,选项add、delete、show、set分别对应增加、删除、查看和设置网络设备。
格式2:对网卡的网络协议地址(IPv4/IPv6)进行操作,选项add、change、del、show分别对应增加、修改、删除、查看IP地址。
systemctl
systemctl <选项> service_name
管理系统中的服务
修改文件名练习
版权归原作者 Qz忘冥哎,无聊 所有, 如有侵权,请联系我们删除。