
海豚调度系列之:任务类型——SPARK节点
一、SPARK节点
Spark 任务类型用于执行 Spark 应用。对于 Spark 节点,worker 支持两个不同类型的 spark 命令提交任务:
- (1) spark submit 方式提交任务。
- (2) spark sql 方式提交任务。
二、创建任务
- 点击项目管理 -> 项目名称 -> 工作流定义,点击”创建工作流”按钮,进入 DAG 编辑页面:
- 拖动工具栏的 任务节点到画板中。
三、任务参数
- 程序类型:支持 Java、Scala、Python 和 SQL 四种语言。
- 主函数的 Class:Spark 程序的入口 Main class 的全路径。
- 主程序包:执行 Spark 程序的 jar 包(通过资源中心上传)。
- SQL脚本:Spark sql 运行的 .sql 文件中的 SQL 语句。
- 部署方式:(1) spark submit 支持 cluster、client 和 local 三种模式。 (2) spark sql 支持 client 和 local 两种模式。
- 命名空间(集群):若选择命名空间(集群),则以原生的方式提交至所选择 K8S 集群执行,未选择则提交至 Yarn 集群执行(默认)。
- 任务名称(可选):Spark 程序的名称。
- Driver 核心数:用于设置 Driver 内核数,可根据实际生产环境设置对应的核心数。
- Driver 内存数:用于设置 Driver 内存数,可根据实际生产环境设置对应的内存数。
- Executor 数量:用于设置 Executor 的数量,可根据实际生产环境设置对应的内存数。
- Executor 内存数:用于设置 Executor 内存数,可根据实际生产环境设置对应的内存数。
- Yarn 队列:用于设置 Yarn 队列,默认使用 default 队列。
- 主程序参数:设置 Spark 程序的输入参数,支持自定义参数变量的替换。
- 选项参数:设置Spark命令的选项参数,例如–jars、–files、–archives、–conf。
- 资源:如果其他参数中引用了资源文件,需要在资源中选择指定。
- 自定义参数:是 Spark 局部的用户自定义参数,会替换脚本中以 ${变量} 的内容。
四、任务样例
1.spark submit
执行 WordCount 程序
本案例为大数据生态中常见的入门案例,常应用于 MapReduce、Flink、Spark 等计算框架。主要为统计输入的文本中,相同的单词的数量有多少。
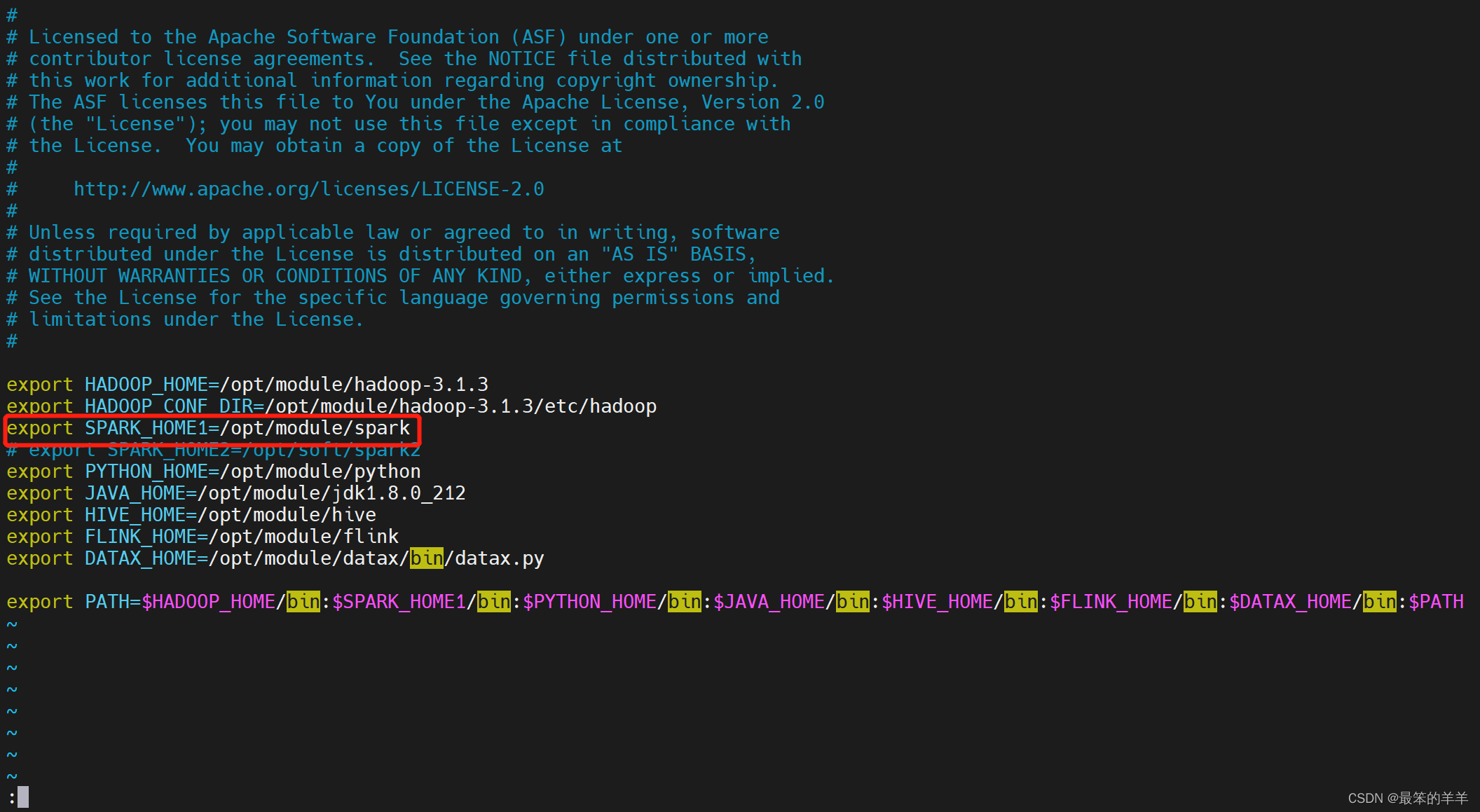
在 DolphinScheduler 中配置 Spark 环境
若生产环境中要是使用到 Spark 任务类型,则需要先配置好所需的环境。配置文件如下:bin/env/dolphinscheduler_env.sh。
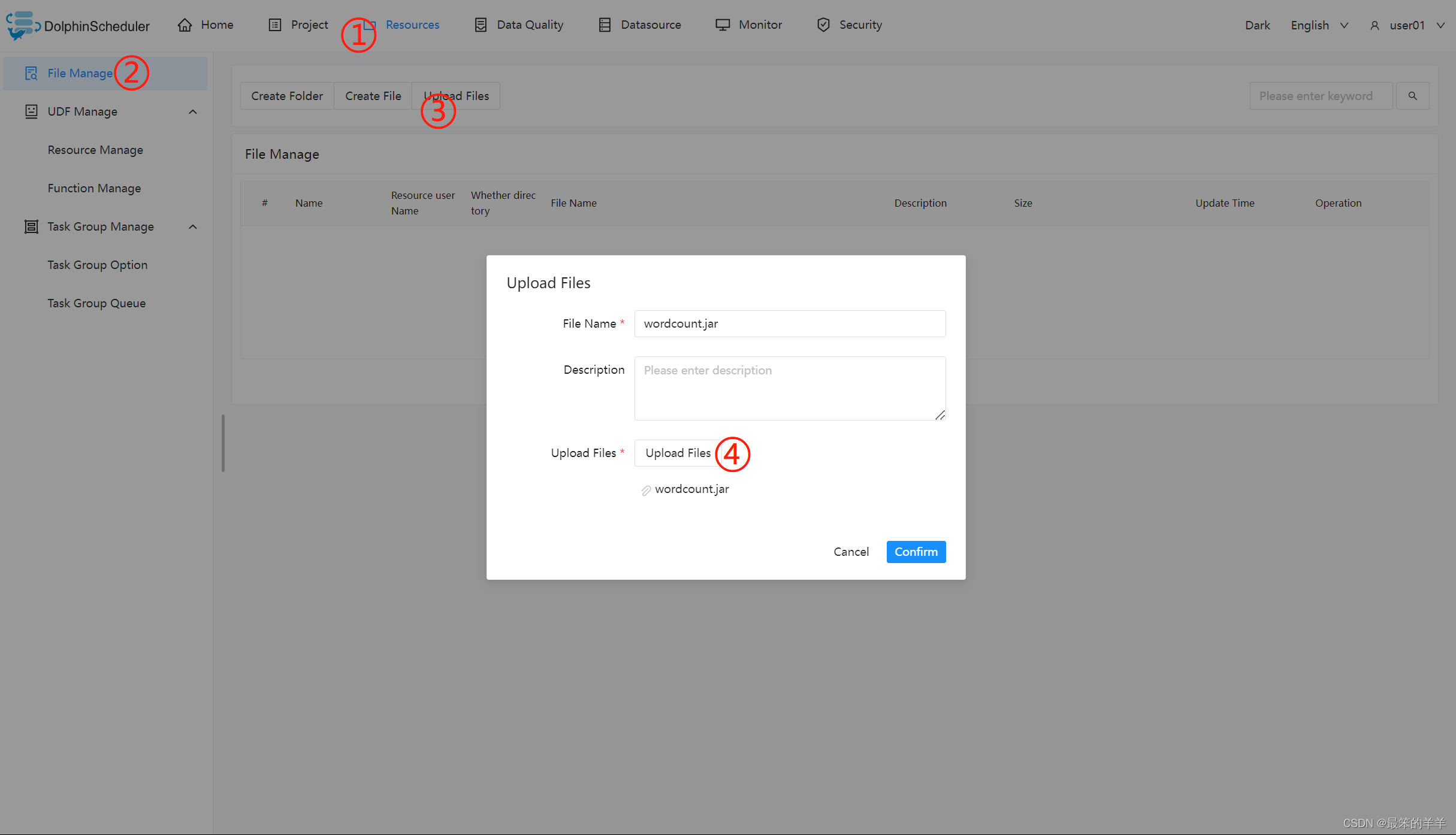
上传主程序包
在使用 Spark 任务节点时,需要利用资源中心上传执行程序的 jar 包。
当配置完成资源中心之后,直接使用拖拽的方式,即可上传所需目标文件。
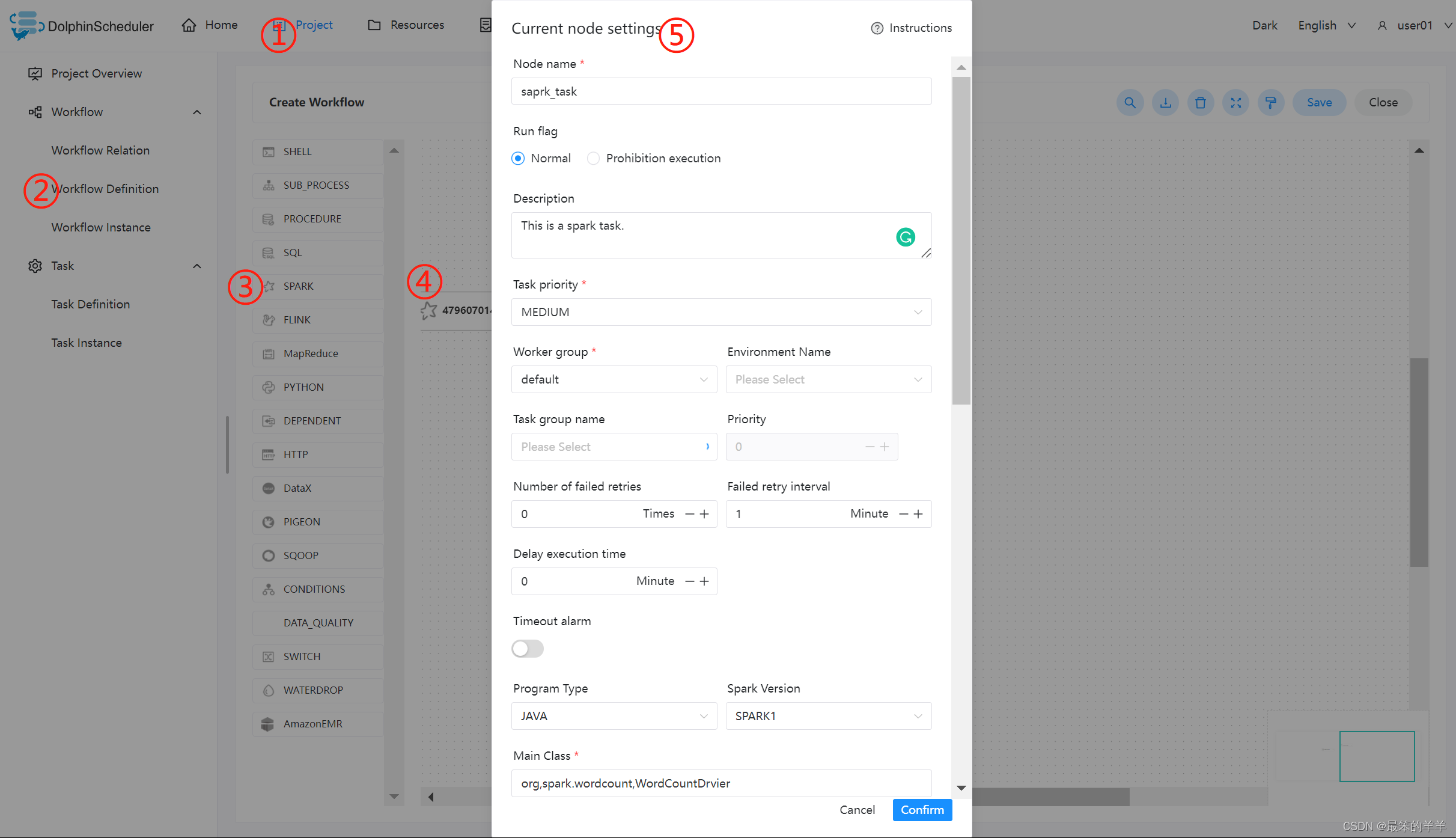
配置 Spark 节点
根据上述参数说明,配置所需的内容即可。
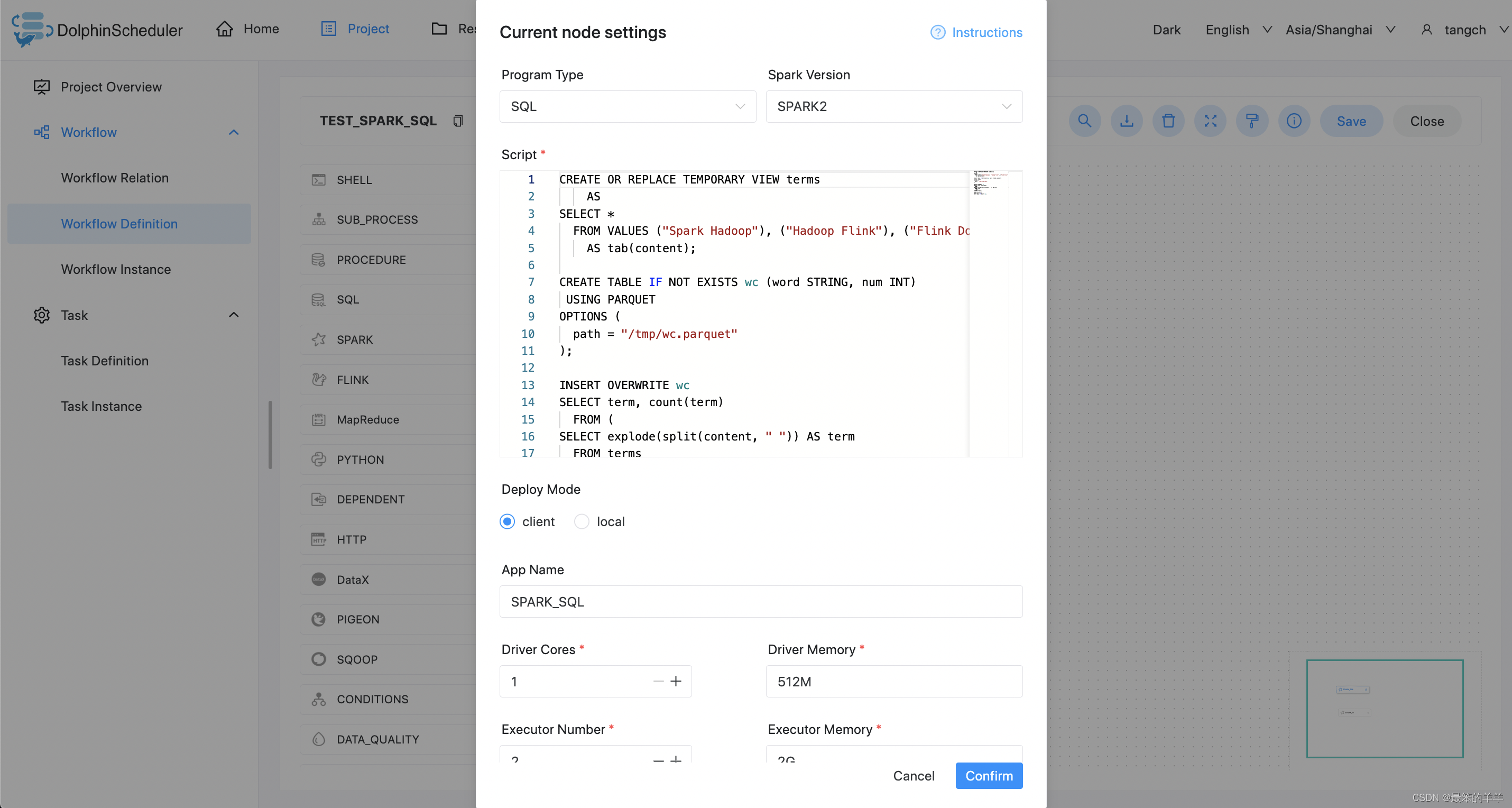
2.spark sql
执行 DDL 和 DML 语句
本案例为创建一个视图表 terms 并写入三行数据和一个格式为 parquet 的表 wc 并判断该表是否存在。程序类型为 SQL。将视图表 terms 的数据插入到格式为 parquet 的表 wc。
五、注意事项:
注意:
- JAVA 和 Scala 只用于标识,使用 Spark 任务时没有区别。如果应用程序是由 Python 开发的,那么可以忽略表单中的参数Main Class。参数SQL脚本仅适用于 SQL 类型,在 JAVA、Scala 和 Python 中可以忽略。
- SQL 目前不支持 cluster 模式。
本文转载自: https://blog.csdn.net/zhengzaifeidelushang/article/details/136685109
版权归原作者 最笨的羊羊 所有, 如有侵权,请联系我们删除。
版权归原作者 最笨的羊羊 所有, 如有侵权,请联系我们删除。