
摘要:该项目是一个基于Spark的综合实训项目,旨在实现对新浪新闻网数据的实时采集和分析。项目包括数据采集(使用Python和Scrapy框架将新浪新闻数据存入MongoDB)、数据转存(使用Scala将数据从MongoDB实时导入HDFS)、数据分析与存储(使用Spark Streaming对HDFS上的数据进行实时统计并存储到MySQL)、以及数据可视化(使用Python绘制并上传分析结果到Web端)。报告详细描述了每个步骤的功能设计、实现步骤、源码实现和运行截图。
关键词:Scrapy数据采集 实时分析 ** Spark Scala HDFS Spark Streaming** MongoDB MySQL 数据可视化
(篇幅受限)详细内容可下载文档查看!!!
目录:
1.1概述(5分)
1.1.1 训练要点(1分)
回顾并熟练使用python进行数据采集;
掌握scala的使用,将数据从mongo采集到hdfs;
熟练掌握使用spark streaming实现对hdfs目录监测并完成数据分析与处理;
熟练spark的使用,将分析结果存储到mysql;
训练数据据的可视化,将mysql的数据取出并完成可视化。
1.1.2 需求说明(2分)
本实训充许同学们采集各类题材数据,包括并不限于:商品、音乐、新闻、房产、书籍、招聘;
本实训要实现的功能是通过同学采集某类题材数据,实时采集题材数据到mongodb, 再从mongodb将所有同学采集的同题材数据采集hdfs,然后实现该类数据的实时流分析,对分析结果进行存储,然后对mysq中数据实时可视化。
1.1.3 实现步骤(2分)
数据采集:使用scrapy框架实现新闻题材网站的数据采集,存入mongo数据库
数据转存:scala实时采集题材数据从mongo到hdfs
数据分析:启动Spark Streaming监控hdfs目录,分析统计数据
数据存储:使用spark将统计结果转存到mysql中
数据可视:使用python将mysql的结果数据每隔几秒显示出来并更新到web上
1.2 总体设计(20分)
1.2.1总体流程(10分)
【业务流程图】(5分)
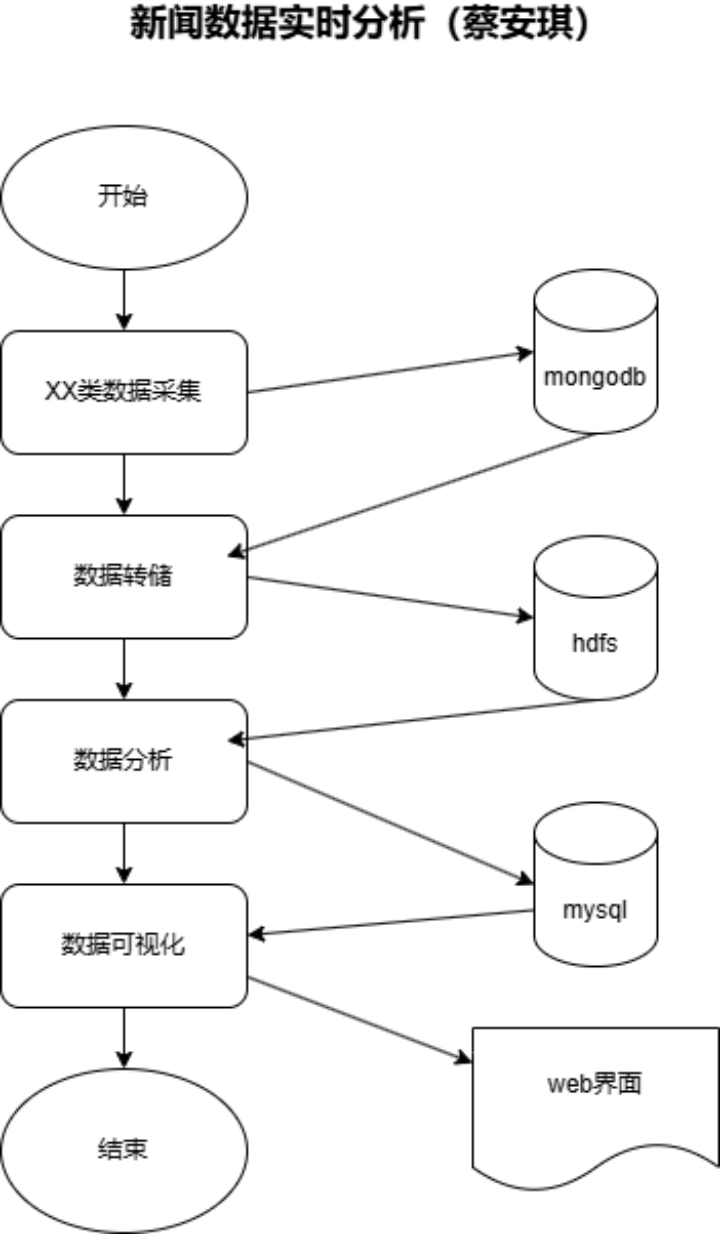
【数据流图】(5分)
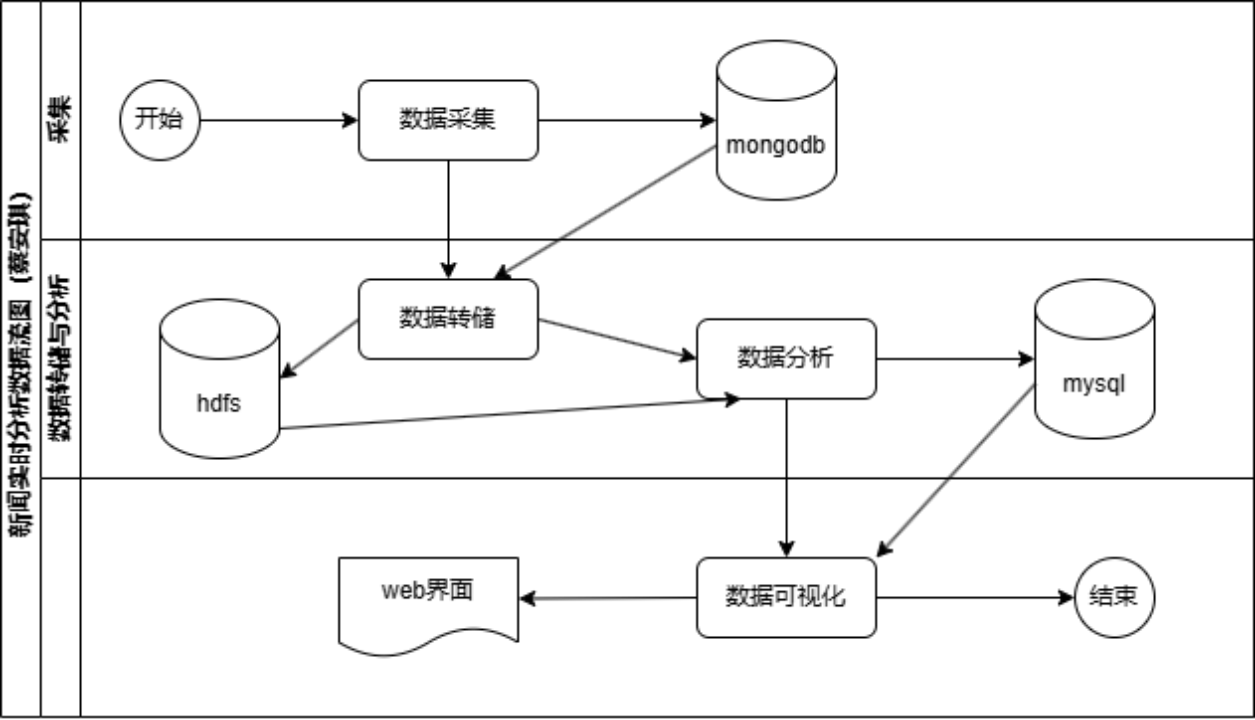
1.2.2 系统功能结构(5分)
【模块组织结构图】(5分)

**1.2.3 **运行环境(5)
- 操作系统和软件依赖(2分)
子系统
操作系统
依赖软件
备注
数据采集
macOS
PyCharm ,python3.9,Chrome
数据存储(mongodb->hdfs)
Linux,Window
Vmware,IDEA,Mongodb,Hadoop3.1, scala2.12,jdk1.8
数据分析与存储(spark streaming)
Linux,Window
Vmware,IDEA,Mysql5.7,Hadoop3.1,scala2.12,jdk1.8
数据可视化
macOS
Pycharm,Mysql,web,python3.9
- 网络拓朴图(3分)
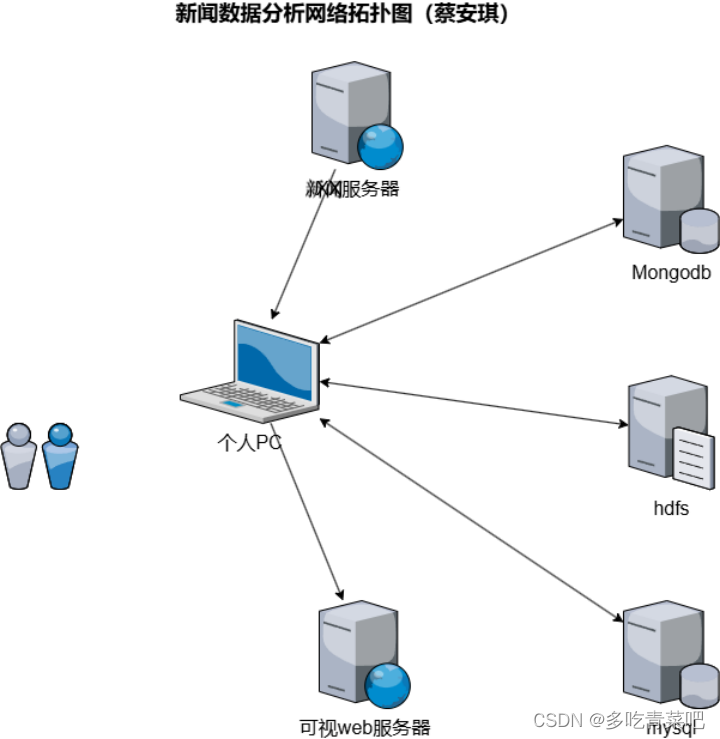
1.3 详细设计(70分)
1.3.1 库表设计(10分)

1.3.2 数据采集(10分)
功能说明:使用python采集数据到MongoDB
采集内容:新闻数据,包括新闻标题,新闻关键词,发布媒体等数据
采集过程:利用Pycharm从新浪网采集新闻数据到mongodb库中
框架:使用scrapy框架
功能设计:将新浪网的新闻数据,包括新闻标题,新闻关键词,发布媒体等数据采集到mongodb远程数据库中。
以下是scrapy框架:
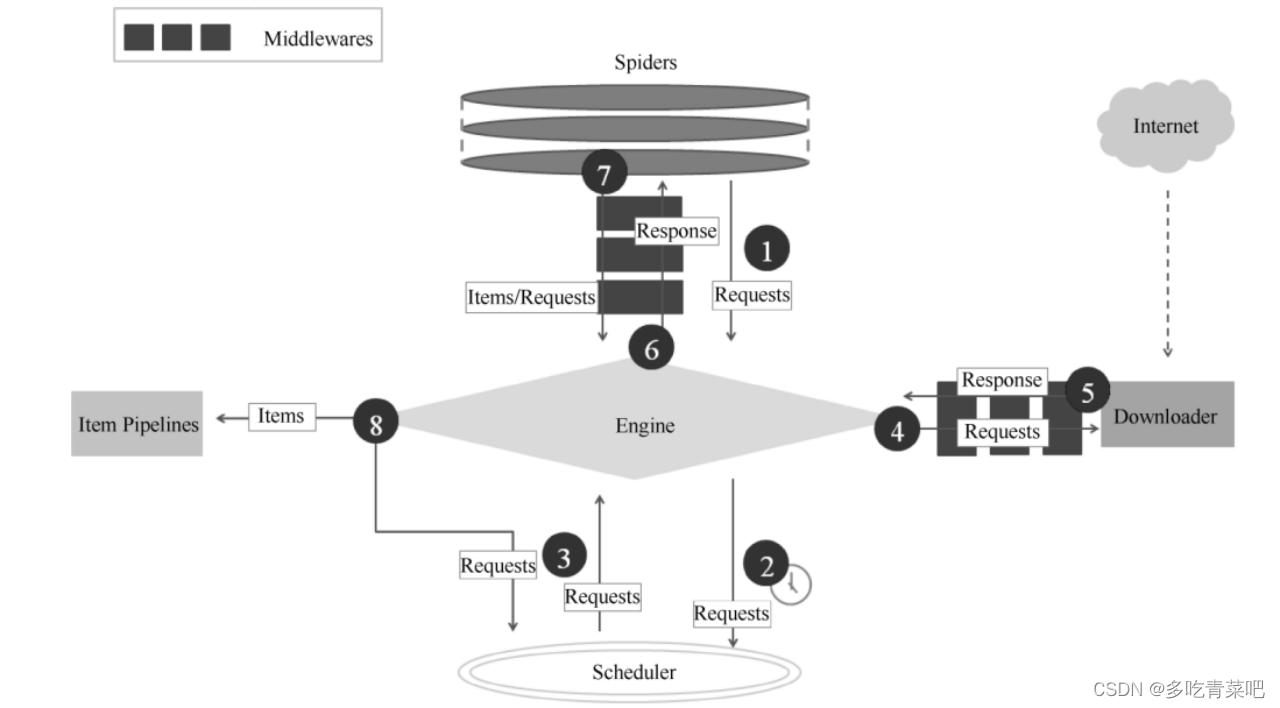
新闻数据的采集流程如下:
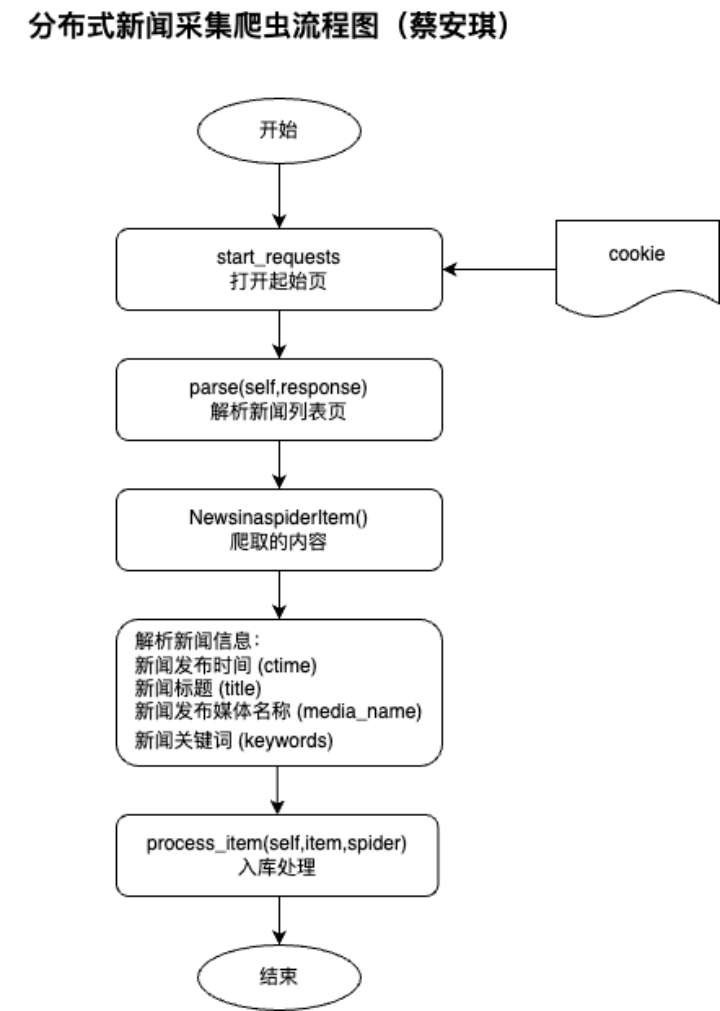
源码实现:
1、scrapy脚本:
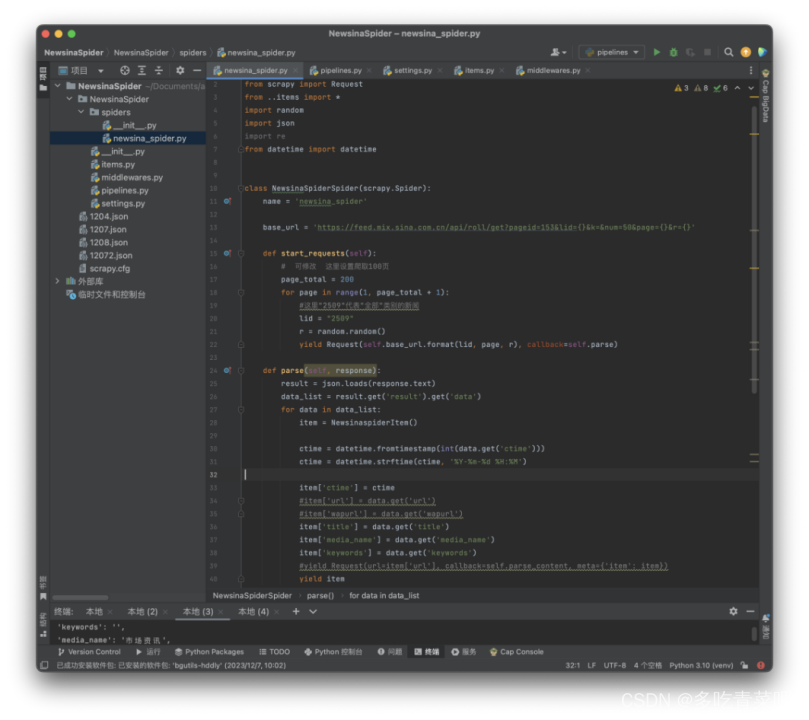
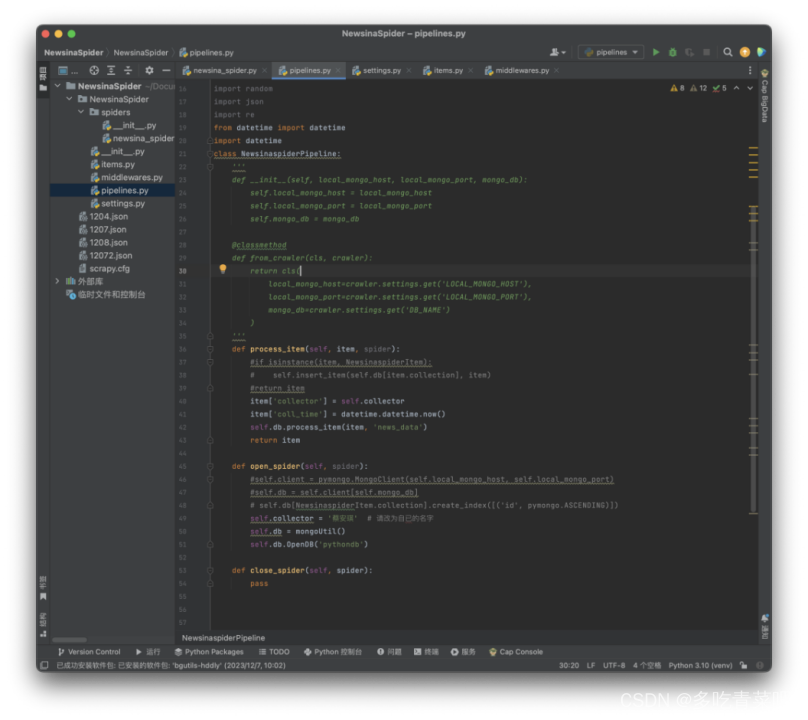
2、pipline脚本
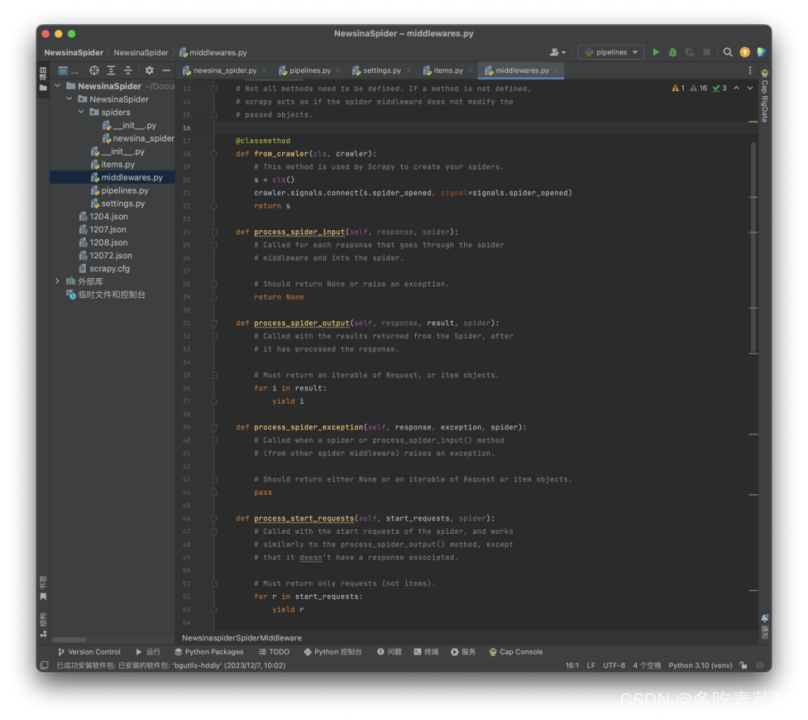
3、 midlleware脚本
4、item脚本
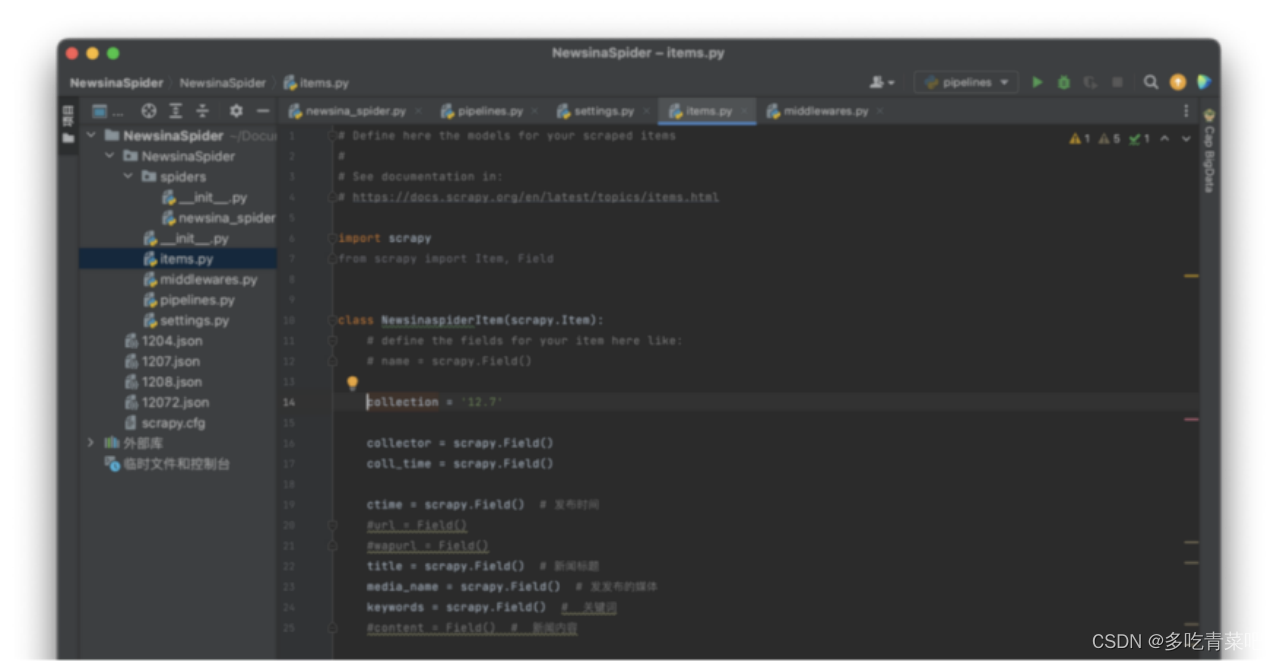
运行截图:
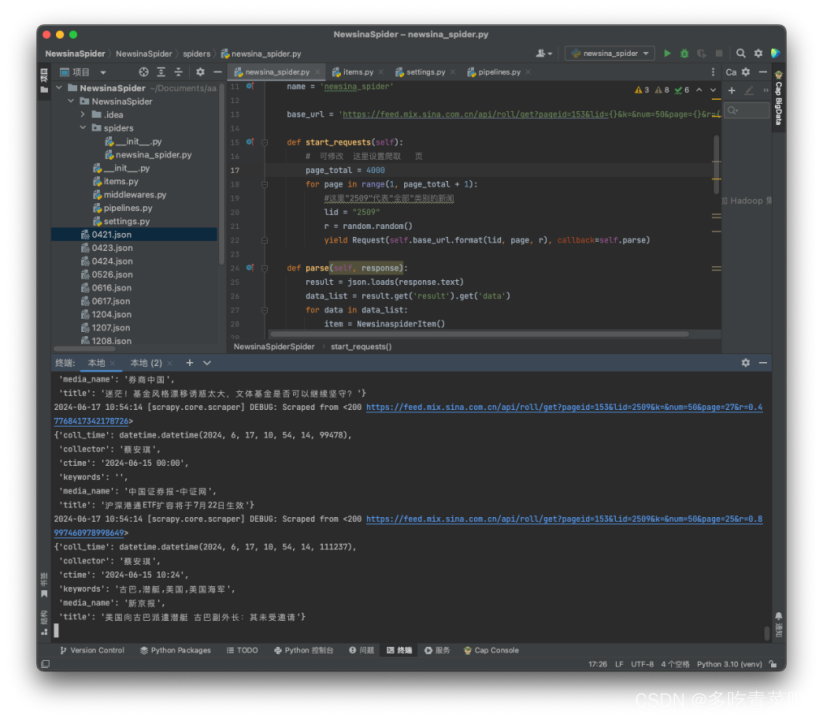
1.3.3 数据存储(mongodb->hdfs)(10分)
功能说明:使用scala将mongdb数据拉取到hdfs,而且这个过程时实时的不断进行的。
功能设计:连接mongdb数据库,从pythondb数据库的表news_data的表中筛选出满足collector为“蔡安琪”条件的数据,然后遍历数据,将数据导入Hdfs文件系统中。
流程图如下:
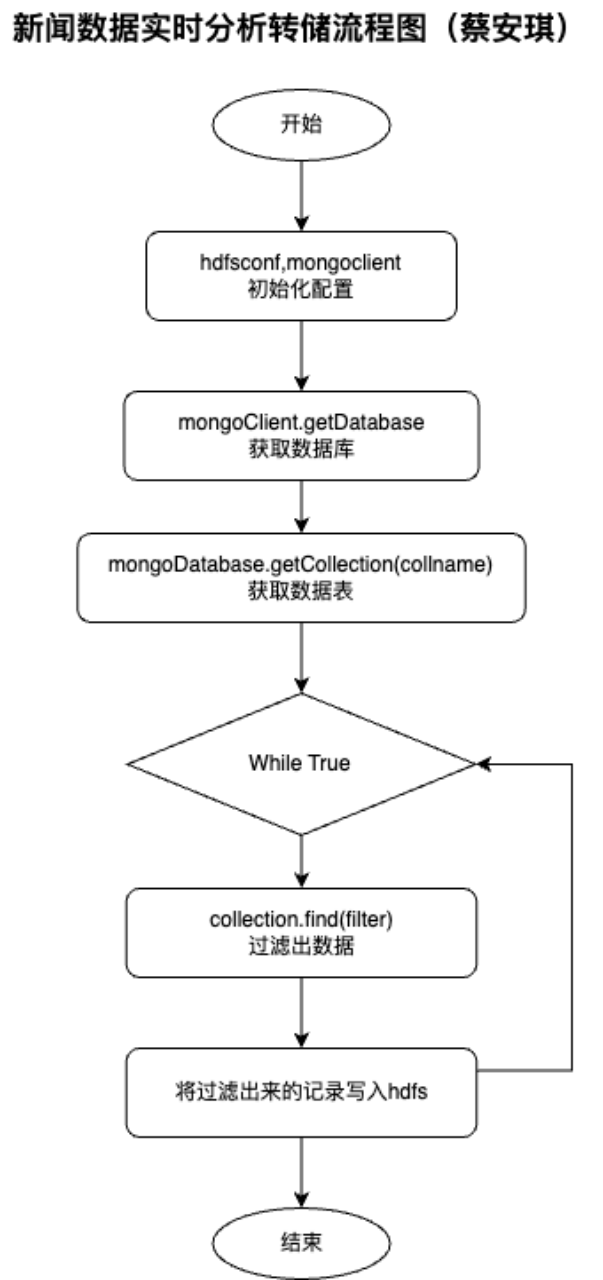
源码实现:

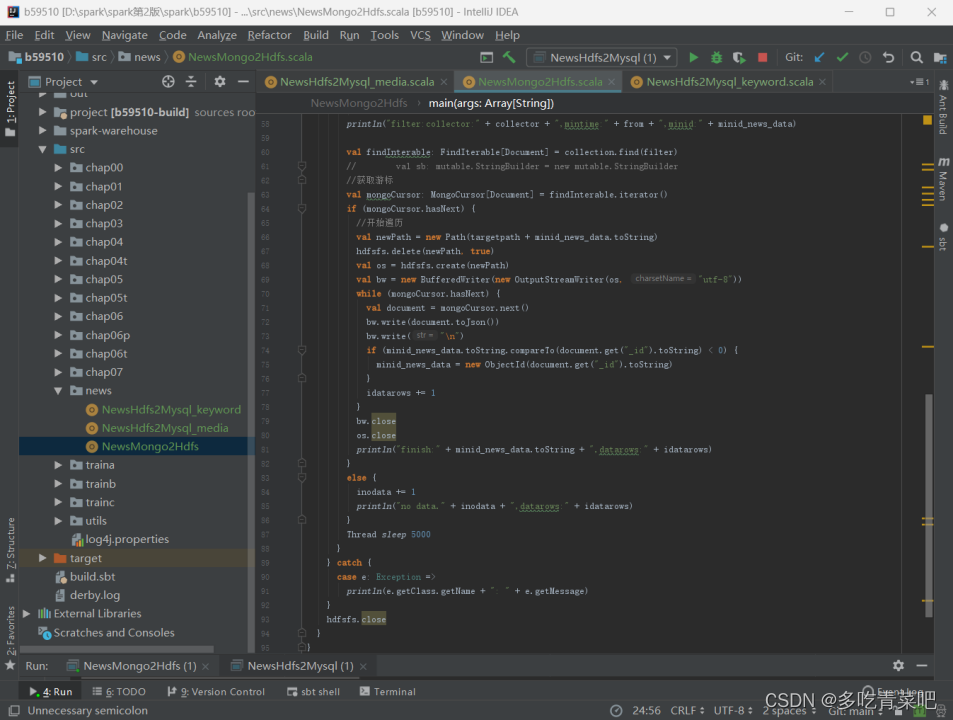
运行截图:
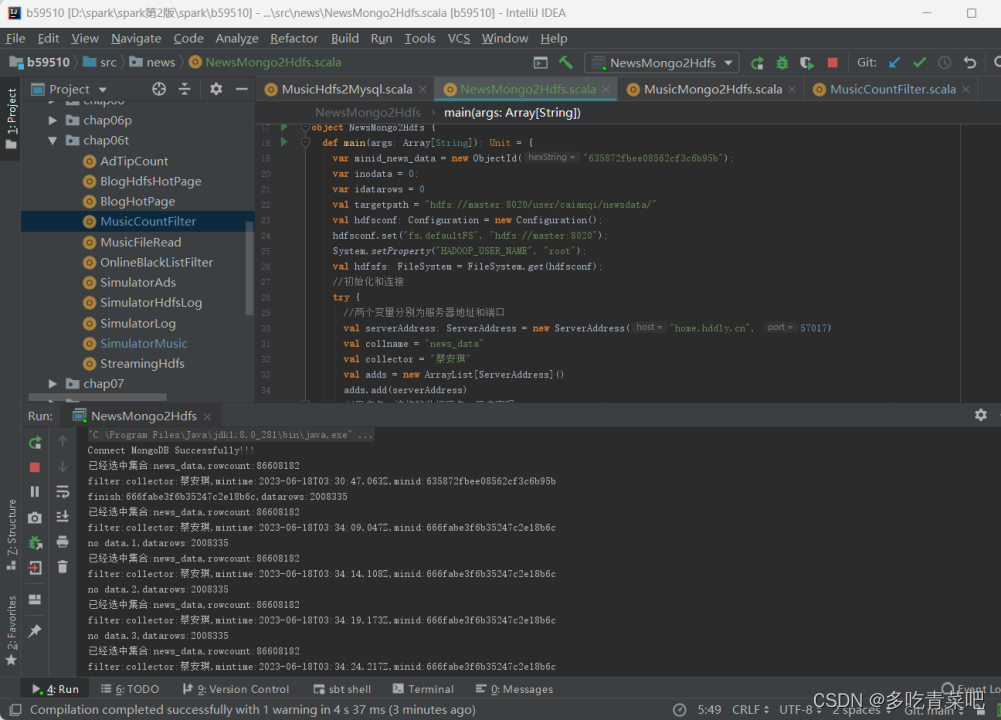
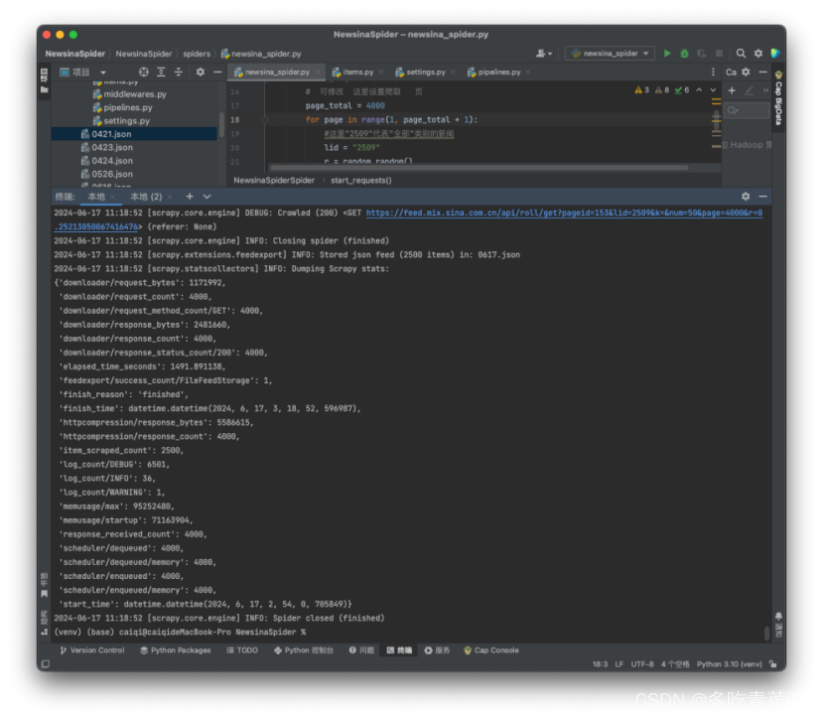
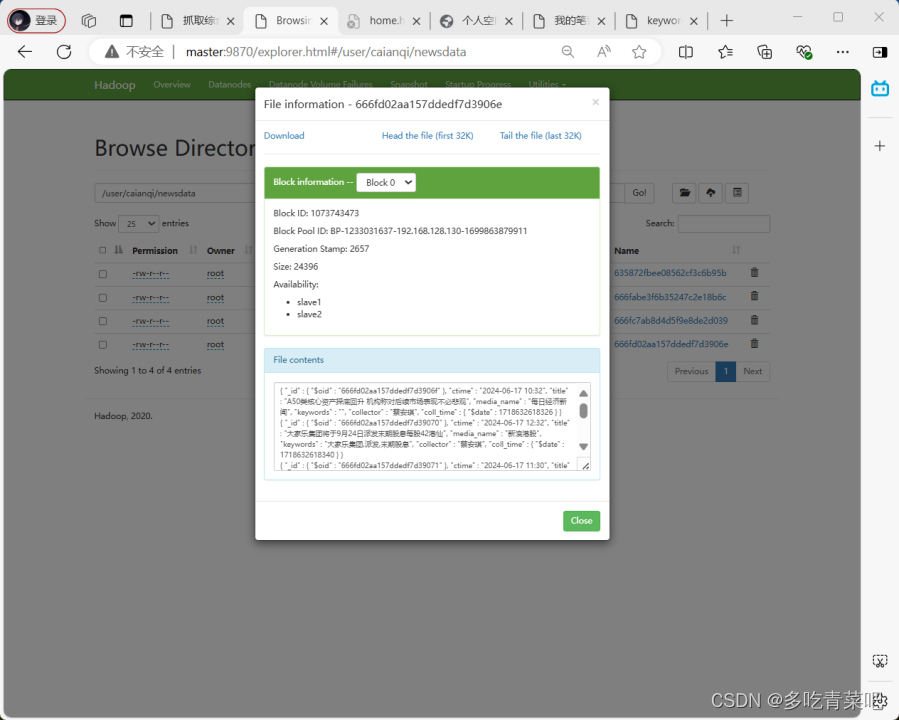
在hadoop集群上运行结果截图:
1.3.4 数据分析与存储(spark streaming)(30分)
功能说明:使用spark streaming分析数据,实时监控 hdfs上从mongdo转储过来的数据,进行实时分析,按发布媒体名称、关键词进行实时统计,将统计结果存入mysql。
功能设计:
1、首先进行初始化sc,ssc:
2、ssc.textFileStream(streamingpath)监控hdfs目录,得到 DStream: lines;
3、对DStream:lines进行map转换,转换keyvalue 的DStream:ItemPairs;
4、进行窗口转换操作ItemPairs.reduceByKeyAndWindow生成htmlCount;
5、对htmlCount进行htmlCount.transform操作,得到发布媒体名称、关键词统计实时分析结果hottestHtml;
6、将分析结果hottestHtml的数据存入mysql;
流程图:

源码实现:
- 统计关键词Top15:
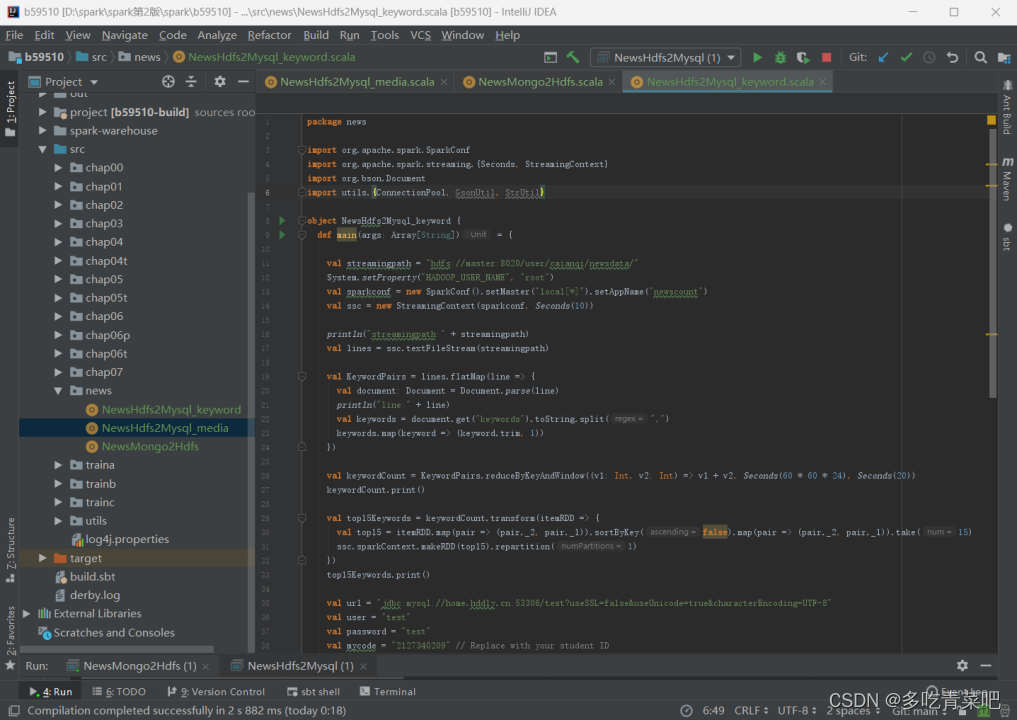
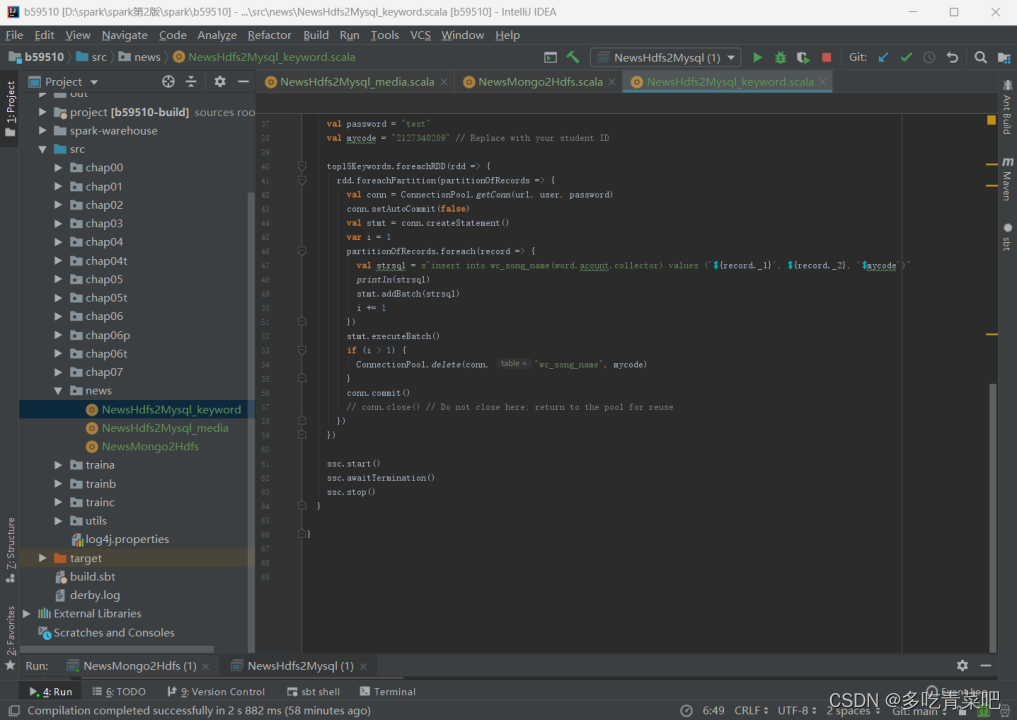
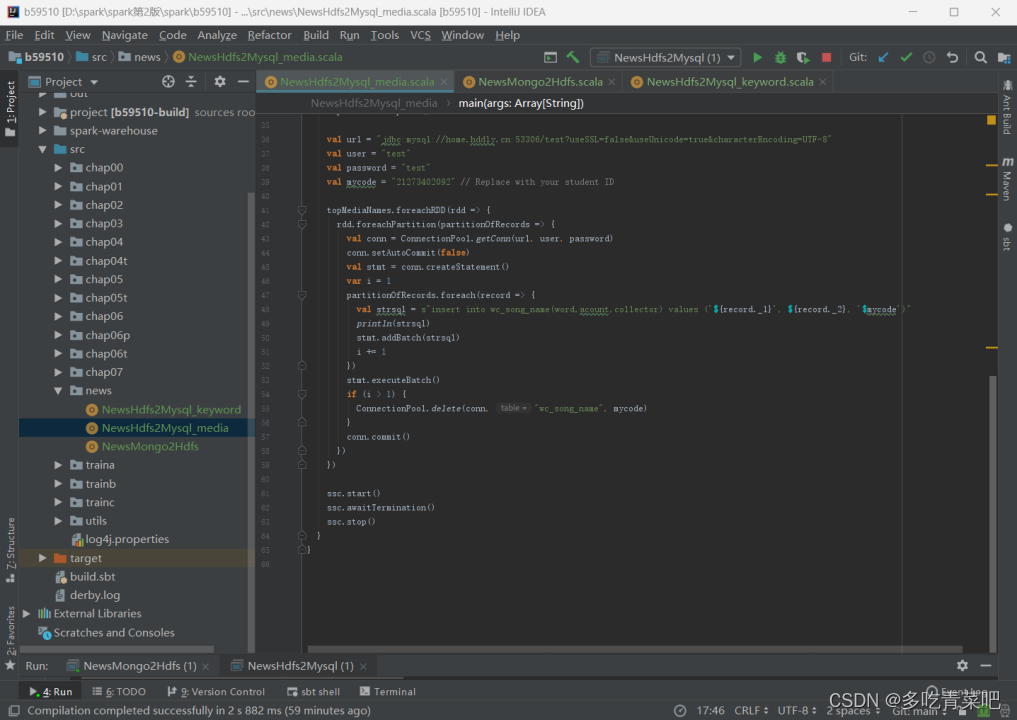
2.统计发布媒体Top15:

运行截图:
1、统计关键词Top15:
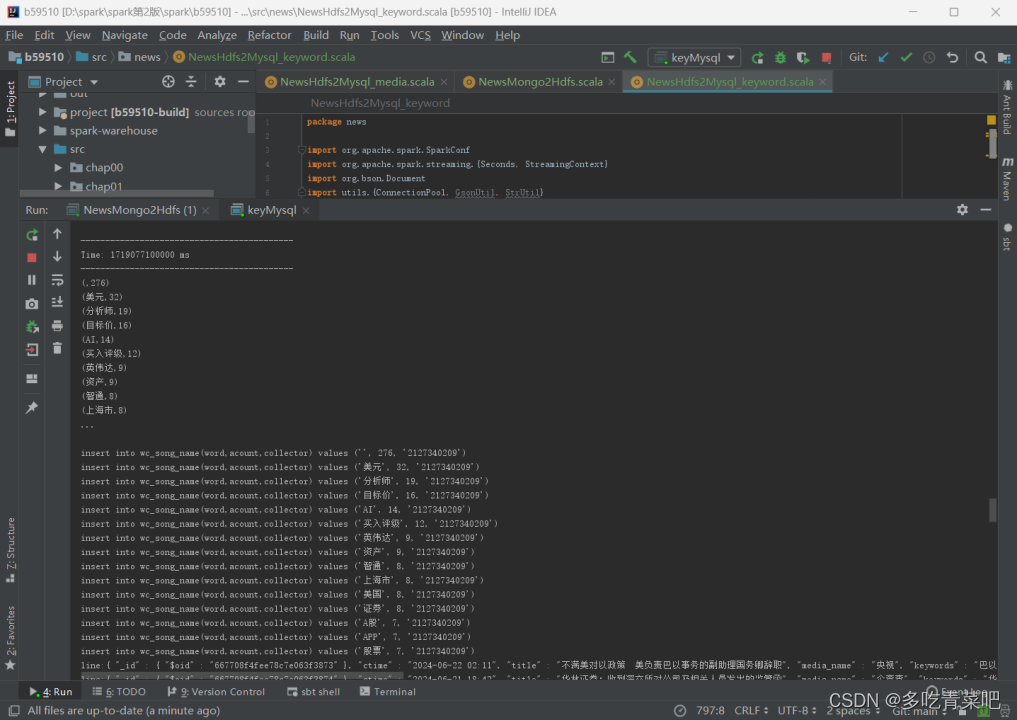
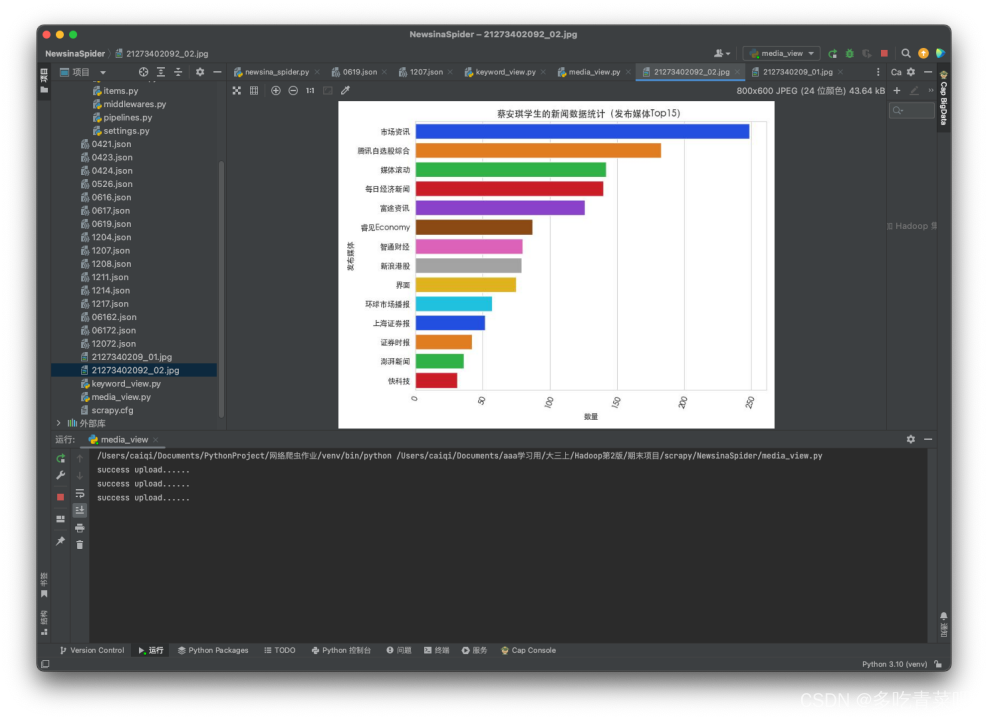
2、统计发布媒体Top15:
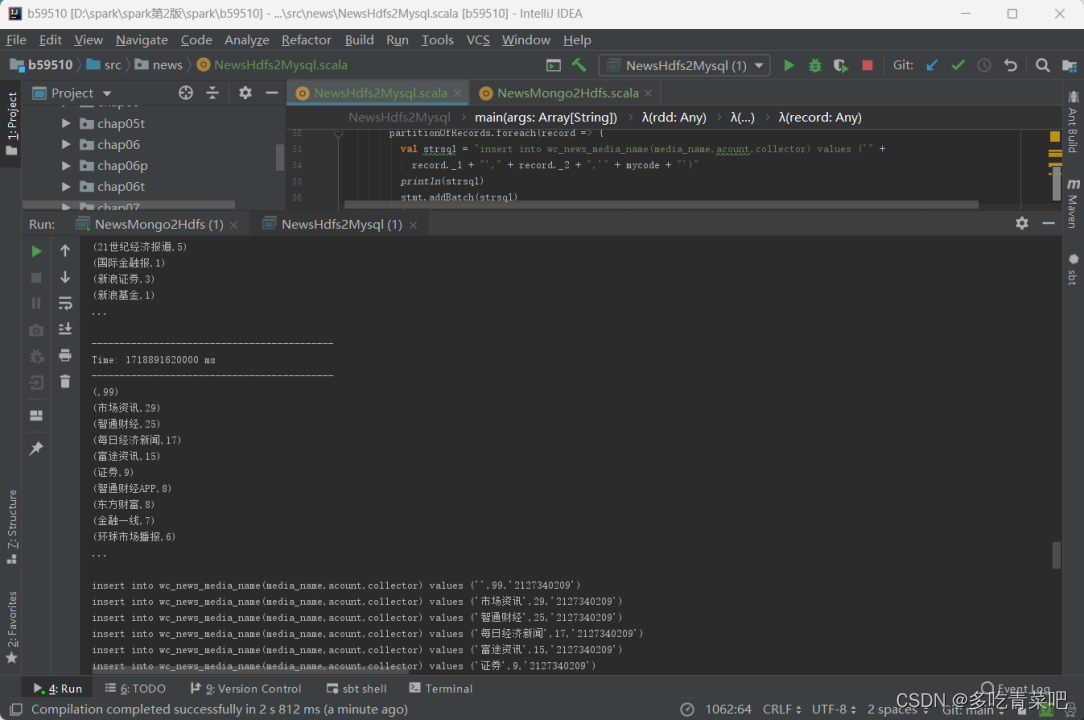
1.3.5 数据可视(10分)
功能说明:使用python语言绘制可视化图片,并上传到web端
功能设计:使用python语言的barplot()根据存储在mysql的分析结果绘制直方图图片,并将这些图片上传到指定的web网页。
流程图:
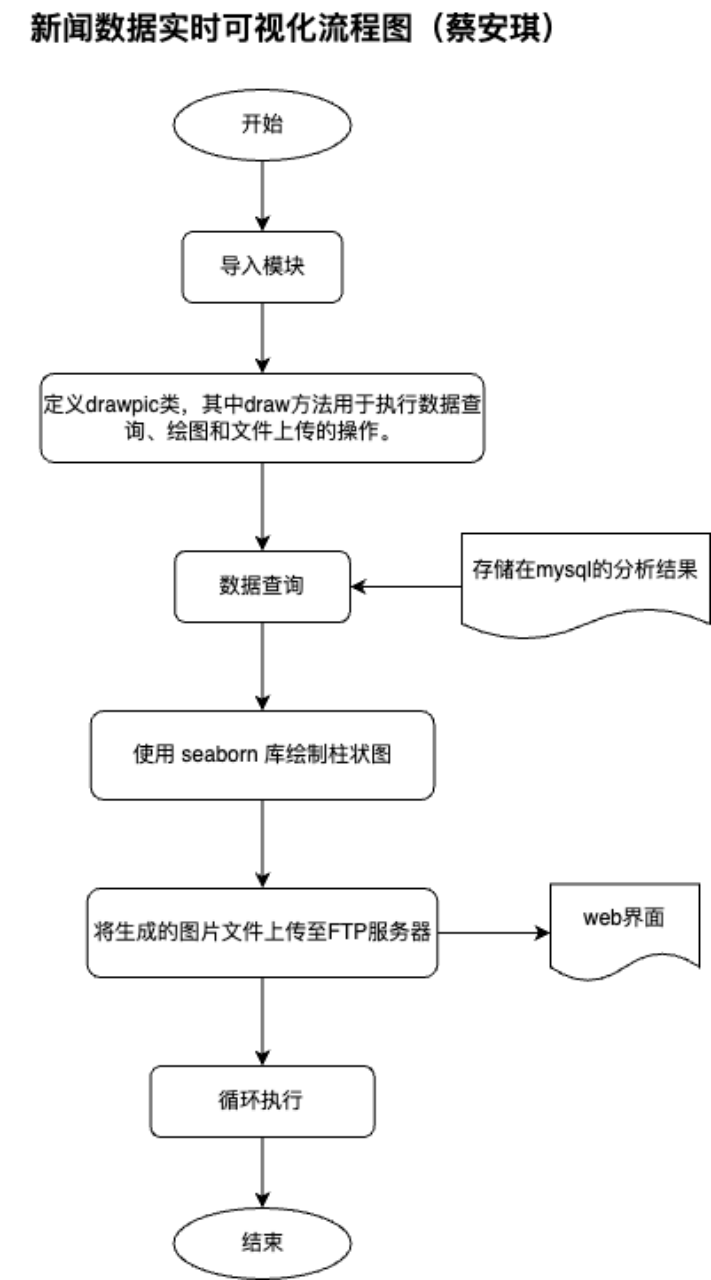
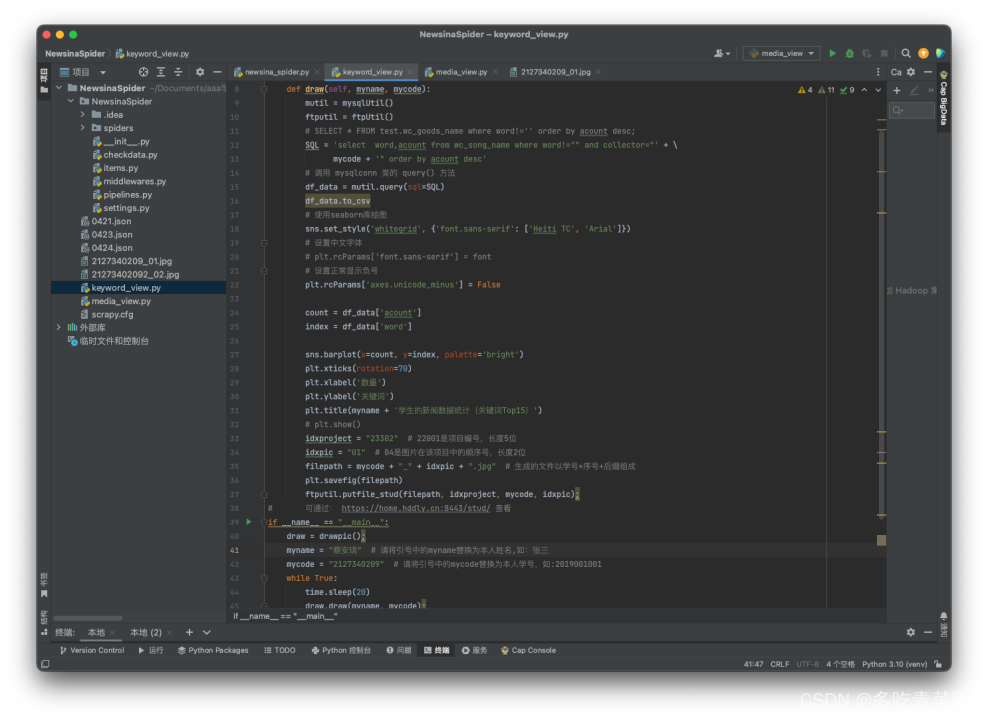
源码实现:
1、关键词Top15:
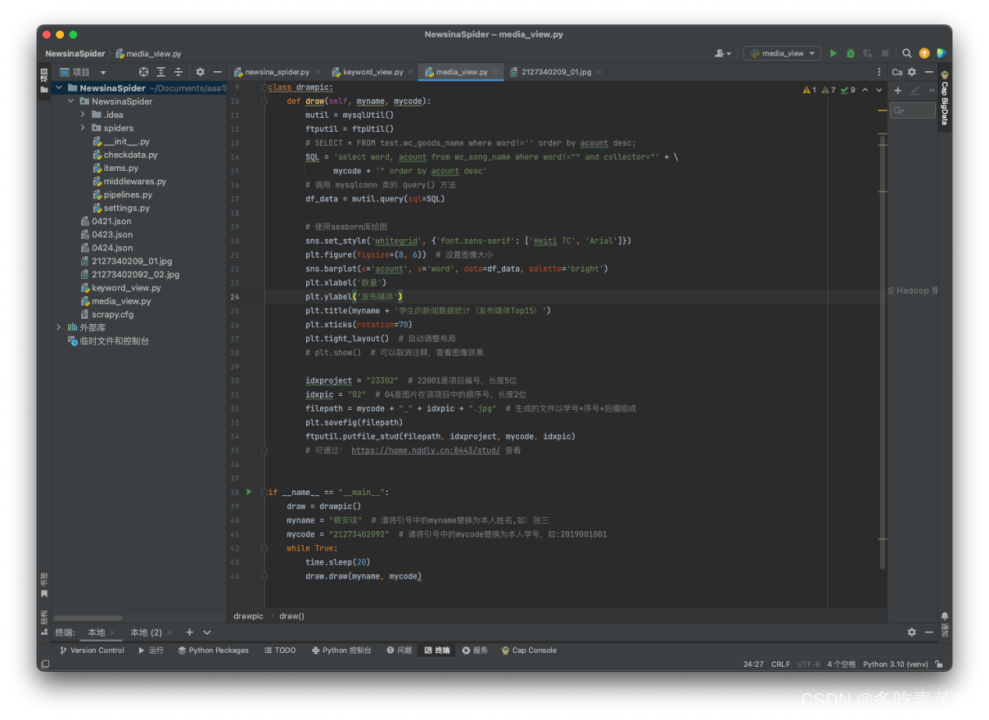
2、发布媒体Top15:
运行截图:
1、关键词Top15:
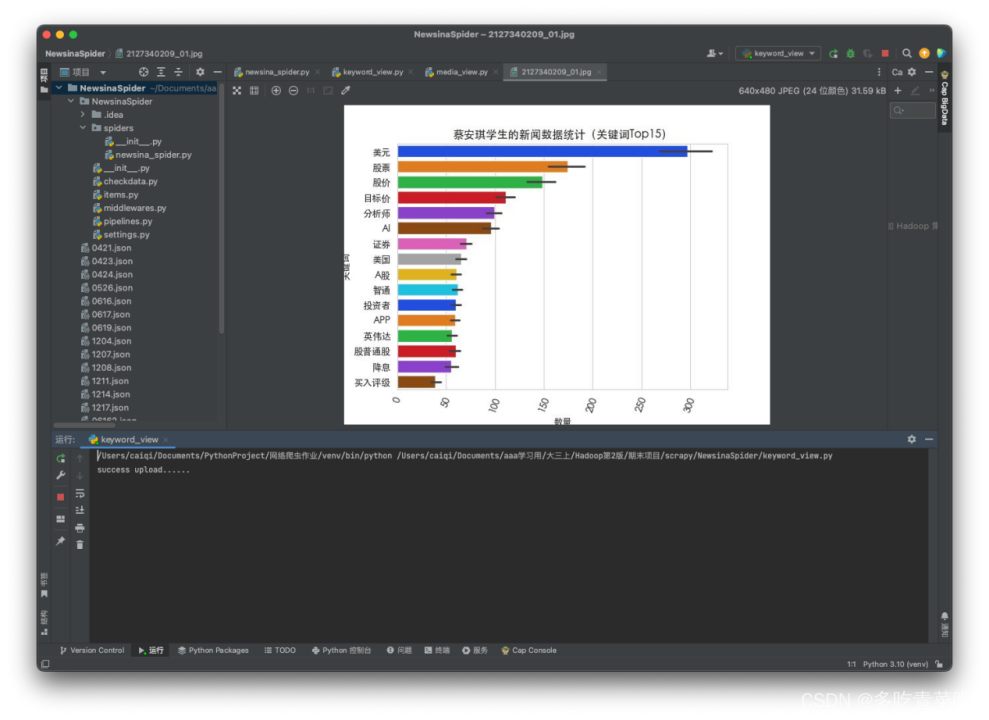
2、发布媒体Top15:
1.4 项目小结(5分)
本项目是一个综合性的数据处理实训,总结了本学期Spark快速大数据处理实训课的相关内容。旨在通过对新浪新闻数据的实时采集与分析,展示如何使用Spark及相关技术(Scrapy、Scala、MongoDB、HDFS、MySQL)完成一个实际的数据处理任务。项目的主要目的是通过使用Python进行数据采集,利用Scala将数据从MongoDB导入HDFS,以及使用Spark Streaming进行实时数据分析和处理。
项目从数据采集的步骤开始,使用Scrapy框架从新浪新闻网站抓取数据,并将这些数据存入MongoDB。然后,通过Scala实时地将这些数据从MongoDB转存到HDFS。在这一过程中,使用了Hadoop的分布式文件系统来存储大量数据,并为Spark Streaming准备数据源。
Spark Streaming在这一项目中发挥了关键作用,它用于实时监控HDFS中的新闻数据,并对其进行统计分析。通过Spark Streaming的窗口操作,能够按发布媒体名称和关键词实时统计数据,并将这些统计结果存储到MySQL数据库中。
最后,项目通过Python脚本对存储在MySQL中的分析结果进行可视化处理,生成直方图,并将这些图片上传到一个Web页面,以便直观地查看分析结果。
整个项目展示了从数据采集到数据分析,再到数据存储和可视化的完整流程。通过这个项目,我不仅掌握了Spark Streaming的实战应用,还提升了数据处理和可视化的能力。
总的来说,这个项目它不仅锻炼了我的编程技能,还让我在实际操作中理解了大数据处理和分析的复杂性,以及如何通过断点分析来解决实际问题。
版权归原作者 多吃青菜吧 所有, 如有侵权,请联系我们删除。