
目录
一、背景
挠头怎么写这篇博文,这问题其实挺偶然机会发现,甚至一度触及到了知识盲点(滑稽狗头),其实吧,就是为了清理平台底层关联不到元数据信息的垃圾文件,大家都懂滴,垃圾不清理,存储迟早要炸,
然而发现某表的文件路径指向不太得劲儿,带有
location 和 path
两种属性,而且两个属性指向的文件路径,撇撇~~,居然
两个不一样的路径
,这就有好玩了,路径既然不一样,那数据是否会错乱呢?研究研究准备复现。
二、环境及测试场景
①、环境
组件版本备注hive2.1.0已测试spark2.3.2已测试spark3.1.2
待测试
②、测试场景
场景测试状态备注普通表已测试分区表
待测试
估计和普通表没啥两样删表
待测试
会删哪个路径(hive和spark是否有差异)?create table like
待测试
location和path属性是否会被同时继承?
三、复现历程
问题是如何复现!!!同时带这俩属性的表是怎么创建出来的,神马神操作……
一个头两个大,脑袋要爆炸
①、场景探索
此处吐槽一番,绝逼是开发在偷懒,为了快速建表,图省事,不考虑可能会出现的大坑
方式引擎操作结果手动创建hivecreate table ……未复现手动创建sparkcreate table ……未复现SparkSQLhivecreate table ……未复现SparkSQLsparkcreate table ……未复现SparkCoresparkspark.sql(“create table ……”)未复现SparkCorespark
df.saveAsTable()
复现
- 复现code - 测试代码,仅供参考,谁用谁入坑
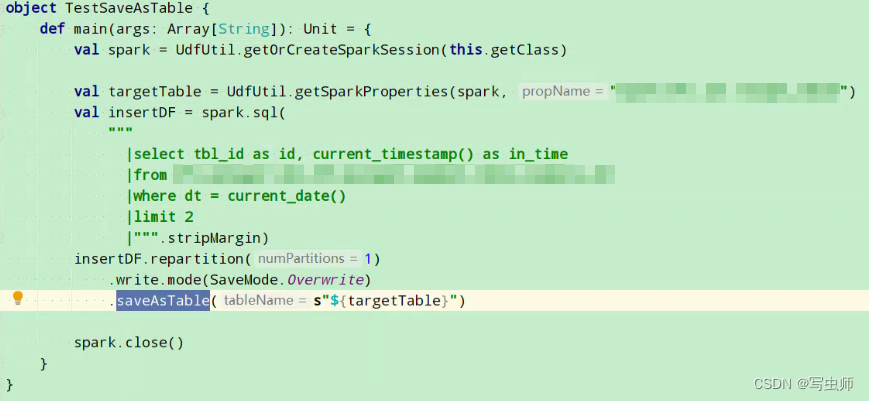
- 初始化表 并且 写入第一批数据 测试任务执行时间:
2022-05-20 19:26:51 ~ 2022-05-20 19:27:46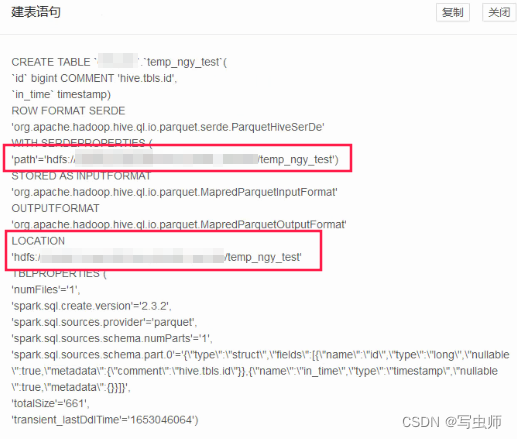
- 记录时间戳 先记录再说,排查问题,时间戳很重要,方便比对 表hdfs目录创建时间戳:
2022-05-20 19:27:44 第一批文件名:
第一批文件名:part-00000-87fc30fc-90b1-4a1c-a7cc-adb42f8009af-c000.snappy.parquet第一批文件修改时间:2022-05-20 19:27:44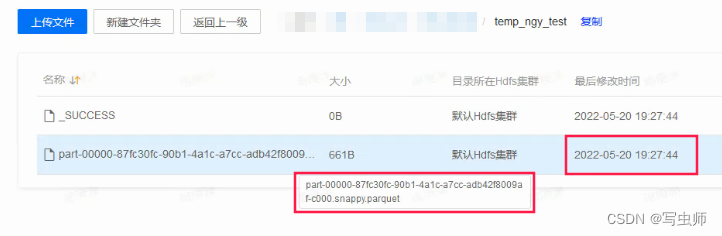
- 现象: 这个时候的表和正常的表没啥两样,只是比普通的表多了
path属性,和location指向相同,数据的读写都还在同一路径下,没啥影响 - 问题:但是
location和path不一致的情况怎么产生,产生后会有什么隐患?准备测试用例
②、测试用例(写数据)
经观察,历史存量的异常表都是
表名称
和
location
一致,
表名称
和
path
不一致
能产生这种情况的,那就是
rename to
操作了
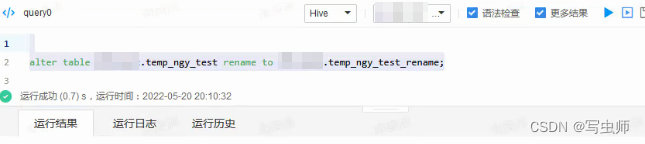
1. rename表(hive引擎)
rename运行时间:
2022-05-20 20:10:32
-- hive引擎altertable xx.temp_ngy_test renameto xx.temp_ngy_test_rename;
2. 观察rename后表结构
异常的表结构出现了,
表名称
和
location
一致,
表名称
和
path
不一致
- 问题:这个时候的表,
数据是往哪个路径写,查询时候又是加载哪个路径下的数据?
3. 记录下rename后的目录状态
- 旧路径:
temp_ngy_test目录已经不存在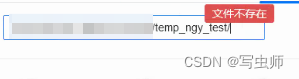
- 新路径:
temp_ngy_test_rename目录被创建 并且继承第一批写入的旧数据文件和时间戳

4. jar包 insertInto写入第二批数据
- 测试code:仅修改
saveAsTable→insertInto测试任务执行时间:2022-05-20 20:45:10 ~ 2022-05-20 20:46:13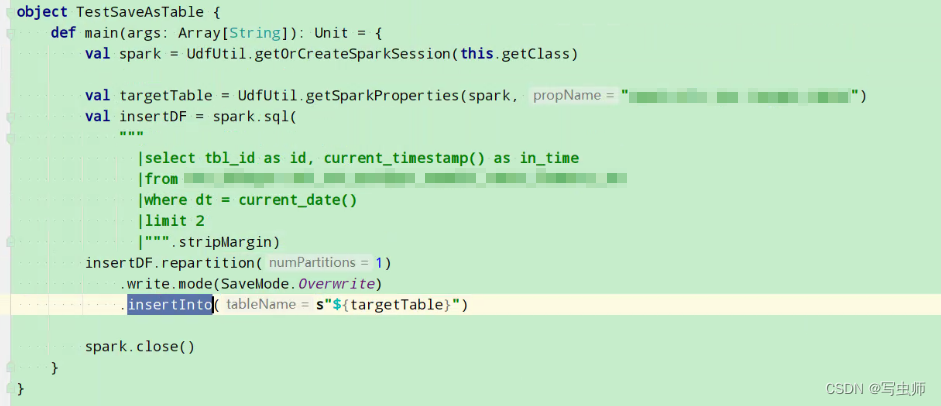
- 重点:旧路径
temp_ngy_test被重新创建出来,并且写入新数据 第二批文件名:
第二批文件名:part-00000-eed210c3-9106-4d18-8ee0-3abcdb5dae99-c000.snappy.parquet第二批文件修改时间:2022-05-20 20:45:58
③、测试用例(读数据)
注意观察数据的时间戳,和上文两次数据生成的时间作比对
1. hive引擎读新路径(location)的旧数据

2. spark引擎读旧路径(path)的新数据
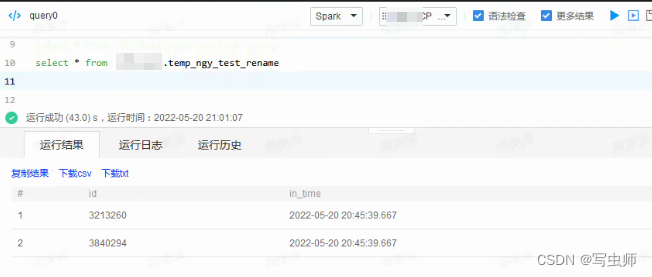
四、隐患
这就很明显了,表如果同时存在location和path两个属性
hive引擎走location
:rename之后的新路径
spark引擎走path
:rename之前的旧路径
①、隐患:数据写入和查询混乱
重点:rename之后,hive引擎写新路径(location),spark引擎继续写旧路径(path),如果用户中间切换过引擎,数据将会错位,导致新路径和旧路径中都有新增加的数据,对于下游查询造成问题。
②、隐患:数据管理和治理困难
如果表在管理过程中,出现误操作、误删等动作,数据将不是很好修复,对于排查问题也将造成一定的困难
五、修正方案
①、方案:简单粗暴,不管何种状态,手动重建
②、方案:表已创建未rename
也简单,如果必须要rename,用
spark引擎
进行操作
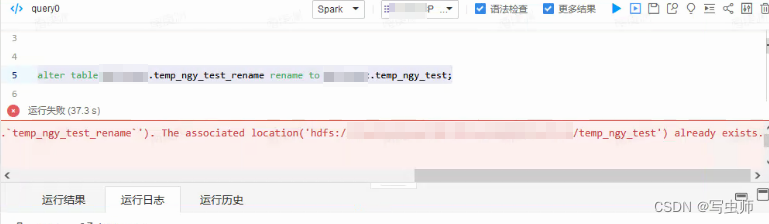
③、无法执行的方案:表已创建,hive引擎也rename了
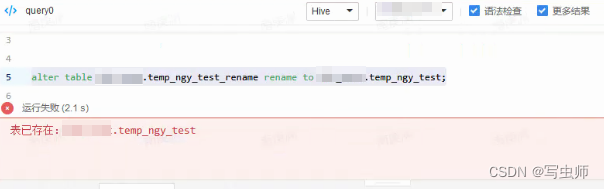
之前自以为是的想了个方案,步骤如下:
- 先hive引擎rename回旧表名,这样location和path路径就一致了
- 再spark引擎rename成新表名,这样location和path一致情况下,还不影响下游查询数据
当暗自窃喜自己很机智的时候,啪啪打脸
自求多福吧,hive引擎直接报错
旧表名已存在
不死心,spark引擎总可以吧,然而,GG思密达,我跪了,报错
旧目录已存在
假设性思考
方案③虽然不可行,但是请思考两个假设性问题:
- 假设此方案可执行,数据是否可以被最终目录继承,不丢失?
- 假设此方案可执行,表、目录、文件权限是否可以被继承,不丢失?
版权归原作者 写虫师 所有, 如有侵权,请联系我们删除。