
HDFS文件存储格式
丰富的存储格式
行式存储
优点: 写入是一次性完成的,消耗的时间比列式存储少,并且能够保证数据的完整性
缺点: 数据读取过程中会产生冗余数据,如果只有少量数据,此影响可以忽略,数量较大可能会影响到数据的处理效率。
行式存储适合插入不适合查询
列式存储
优点:在读取过程中不会产生冗余数据,这对数据完整性要求不高的大数据领域极其重要。
缺点: 写入效率、保证数据的完整性上都不如行式存储
列式存储适合查询不适合插入
Text File
文本格式是Hadoop生态系统内部和外部的最常见的格式,通常按照行存储,以回车换行符区分不同的行数据
优点:易读性好。至少是人能读懂的
缺点:
解析开销一般比二进制格式的开销大
,特别是XML和JSON
最大的特点:
不支持块级别压缩,
因此在进行压缩是会带来较高的读取成本
注意:Text File 不仅仅是指的是TXT文件,还包括CSV、JSON、XML等
Sequence File
- Sequence FIle,每条数据记录都是以
Key、Value键值对进行序列化存储(二进制格式) 序列化文件与文本文件相比更加紧凑,且支持record、block块级压缩。压缩的同时支持文件切分- 通常把Sequence File
作为中间数据存储格式,例如:将大量小文件合并放入到Sequence File文件中。
record
record 就是一个kv键值对,其中数据保存在value中,可以选择是否针对value进行压缩
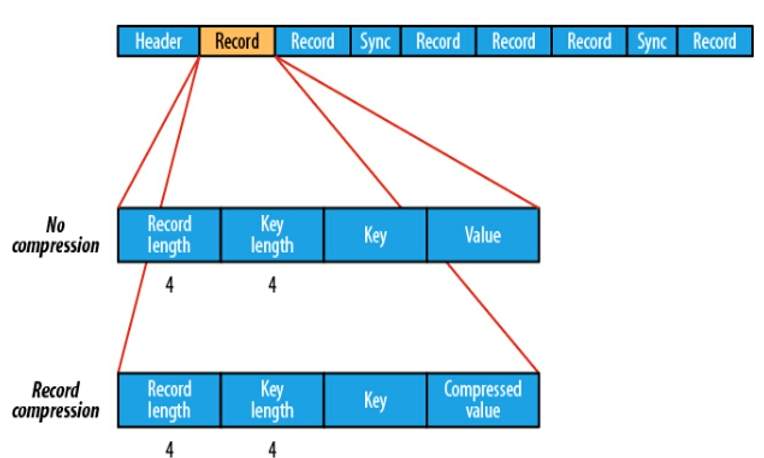
block
block就是多个record的集合,block级别的压缩性能更好
Avro File
- Avro是
与语言无关的序列化系统,由hadoop 之父进行开发 - Avro是
基于行的存储格式,他在每个文件中都包括Json格式的schema定义,从而提高了互操作性并允许schema的变法(删除列、添加行)。除了支持可切分以外,还支持快压缩。 - Avro是一种
自描述格式,他将数据的schema直接编码存储在文件中,可以用来存储复杂结构的数据。 - Avro直接将一行数据序列化在一个block中
适合于大量频繁写入宽表数据(字段多、列多)的场景,其序列化、反序列化很快
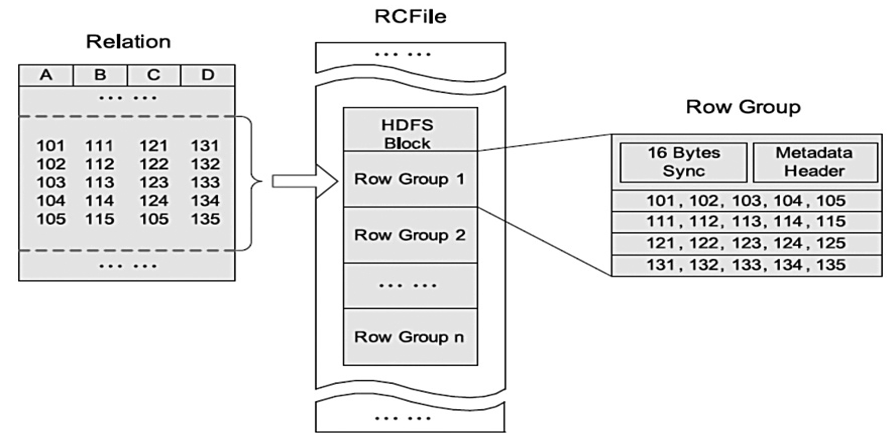
RC File
- Hive Record Columnar File(记录列文件),这中类型的文件首先将数据按行划分为行组,然会在行组内部将数据存储在列中。很适合在数仓中执行分析,且支持压缩、切分。
- 不支持schema拓展,如果要添加新的列,则必须重写文件,这会降低操作效率。
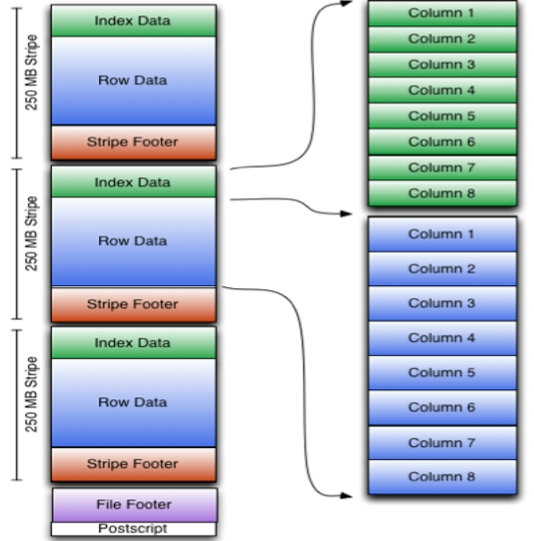
ORC File
- ORC File提供了比RC File更有效的文件格式。他在内部将数据划分为默认大小为250MB的Stripe,每个条
带均包括索引、数据和页脚,索引存储每列的最大值和最小值以及列中每一行的位置 - 他并不是一个单纯的列存储格式,仍然是首先根据Stripe分割整个表,在每一个Stripe内进行案列存储
- ORC
有多种文件压缩方式,并且有着很高的压缩比,文件时可切分的。 - ORC 文件是以
二进制方式存储的,所以是不可以直接读取的。
Parquet File
- Parquet File是面向分析性业务的列式存储方式。
- Parquet File 是以二进制方式存储的,所以是不可以直接读取的,文件中包括该文件的数据和元数据,因此Parquet格式文件是自解析的
- 支持块压缩
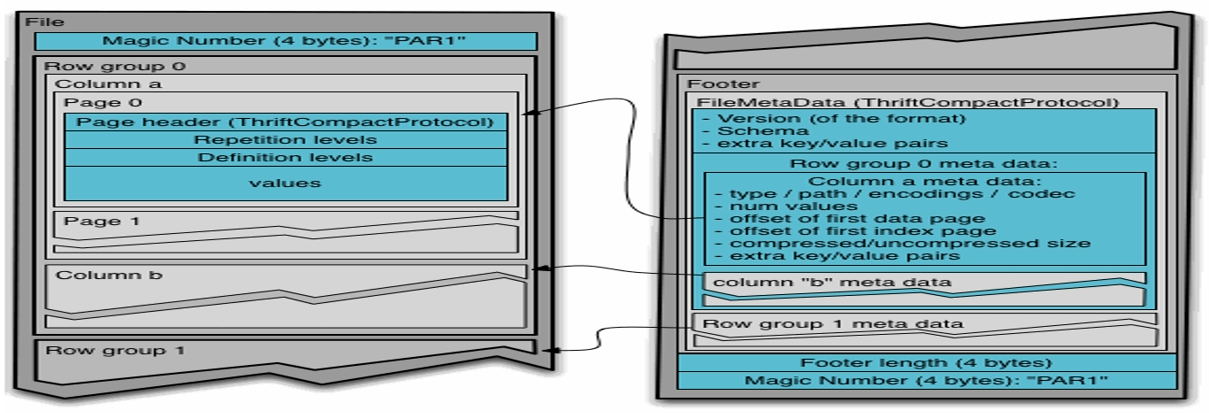
Parquet File 文件结构
- Parquet File 的存储模型主要由
行组、列块、页组成。 - 在水平方向上将数据划分为行组,默认行组大小与HDFS Block块大小对齐,Parquet保证一个行组会被一个Mapper处理。
- 行组中的每一列保存在每一个列块中,一个列块具有相同的数据类型,不同的列块可以使用不同的压缩方式。
- Parquet 是也是存储方式,每一个列块包含多个页,一个页是最小的编码的单位,同一块列的不同页可以使用不同的编码方式。
- 文件的首部都是该文件的Magic Code,用于校验它是否是一个Parquet文件
总结
- 选择文件存储格式不能够只追求某一项指标性能
- 更流行的是混合存储格式:兼容行式和列式
- 大数据中 ORC、Parquet、Avro使用的比较多
新一代的存储格式 : Arrow
- Arrow 是一个跨语言平台,是一种
列式内存数据结构,主要用于构建数据系统 -
- Arrow 促进了许多组件之间的通信
- 极大缩减了通信时候序列化、反序列化所浪费的时间
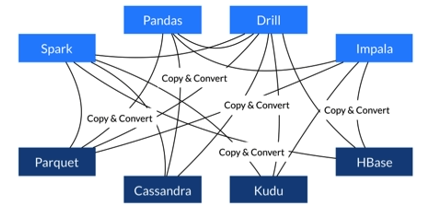
不适用Arrow:
使用Arrow:
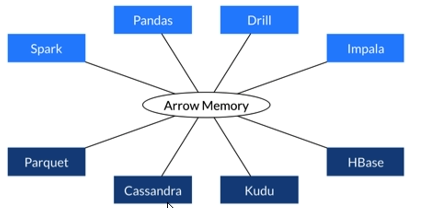
在内存中直接查找,大大提升了效率
Arrow如何提升数据移动性能
- 利用Arrow 作为内存中数据表示的两个过程可以将数据从一种方法重定向到另一个方法,而无需序列化或者反序列化。
- 无需进行反序列化,可以直接从启用了Arrow的数据存储系统中接收Arrow数据
- Arrow设置针对嵌套结构化数据的分析性能进行了优化
文件压缩格式
压缩算法优劣势指标
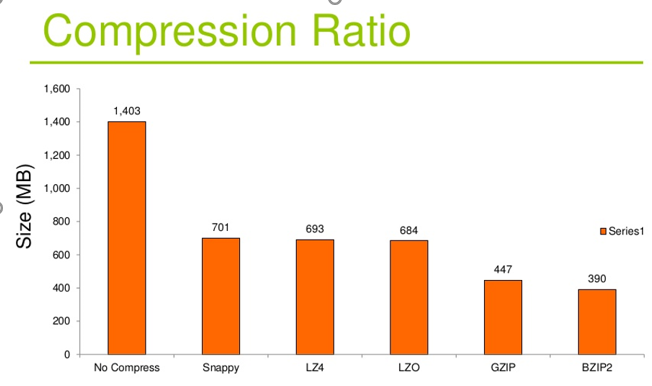
- 压缩比原先占100份的空间的东西经压缩后变成了20份空间,那么压缩比就是5,显然压缩比越高越好
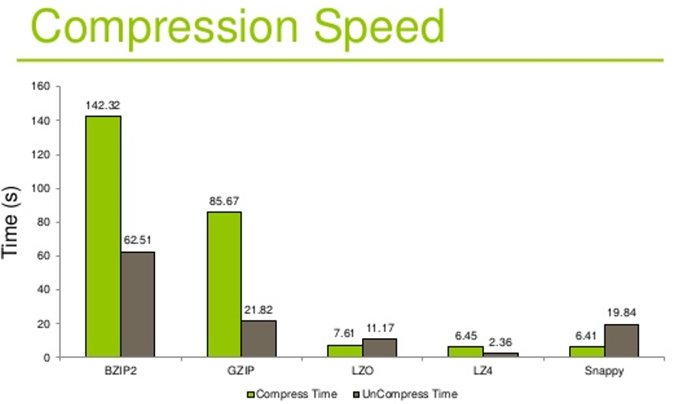
- 压缩/解压缩吞吐量(时间)- 每秒能压缩或解压缩多少MB的数据,吞吐量也是越高越好
- 压缩算法实现是否简单、开源
- 是否为无损压缩、回复效果是否够好
- 压缩后的文件是否支持split(切分)
Hadoop支持的压缩算法
Hadoop对文件压缩均实现org.apache.hadoop.io.compress.CompressionCodec接口,所有的实现类都在org.apache.hadoop.io.compress包下。
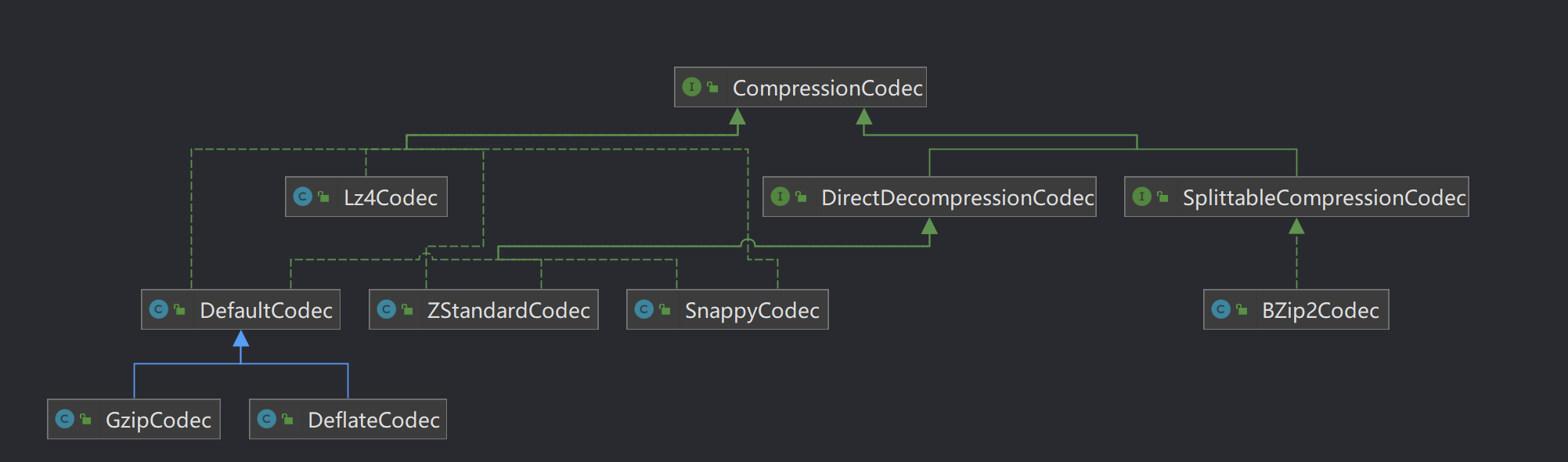
Hadoop支持的压缩对比
压缩格式工具算法文件扩展名是否可切分对应的编码解码器DEFLATE无DEFLATE.deflate否org.apache.hadoop.io.compress.DefaultCodecGzipgzipgzip.gz否org.apache.hadoop.io.compress.GzipCodecbzip2bzip2bzip2.bz2是org.apache.hadoop.io.compress.BZip2CodecLZOlzopLZO.lzo是(切分点索引)com.hadoop.compression.lzo.LzopCodecLZ4无LZ4.lz4否org.apache.hadoop.io.compress.Lz4CodecSnappy无Snappy.snappy否org.apache.hadoop.io.compress.SnappyCodec
压缩比:
压缩、解压时间
注意
压缩的合理使用可以提高HDFS的内存效率
压缩解压意味着CPU、内存需要参与编码解码
选择压缩算法时不能够一味的追求某一指标的极致,要综合考虑性价比比较高的
文件的压缩解压程序或者工序需要对数据进行处理,大数据相关处理软件都支持直接设置
HDFS 异构存储和存储策略
HDFS异构存储类型
冷、热、暖、冻数据
热数据:新传入的数据被大量地使用,这样的数据被标记成热数据。
暖数据:热数据随着时间的推移,访问次数在慢慢下滑,这时候就是一个暖数据
冷数据:暖数据的使用频率再次降低就是冷数据
冻数据:使用频率非常低,基本不使用甚至不用,则成为冻数据。
在Hadoop2.5及其以上就开始支持存储策略,在该策略下,不仅可以在默认的传统的磁盘上存储HDFS数据,还可以在SSD上存储数据
什么是异构存储
异构存储是Hadoop2.6.0版本以后出现的新特征,可以根据哥哥存储介质读写特征不同进行选择。
例如冷热数据的存储,对冷数据采用容量大但读写性能不高的存储介质如机器硬盘,热数据采用SSD进行存储
在读写效率上性能较大,异构特性允许我们对不同文件选择不同的存储介质进行保存,以实现机器性能的最大化
HDFS定义的四种异构存储类型
RAM_DISK(内存)
SSD(固态硬盘)
DISK(机器硬盘) 默认使用
ARCHIVE(高密度存储介质,存储档案历史数据)
那么如何让HDFS知道集群中的数据存储目录是哪种类型的介质?
配置属性时主动声明,HDFS没有自动检测的能力
参数配置
dfs:datanode.data.dir=[SSD]file:///grid/dn/ssd0
如果目录前没有嗲上[SSD] [DISK] [ARCHIVE] [RAM_DISK]这四种类型中的任意一个,则默认为DISK
由于在本地我并没有生命该磁盘的类型,进行查看:

显然是DISK
HDFS 块存储类型选择策略
块存储指的是对HDFS文件的数据块副本存储
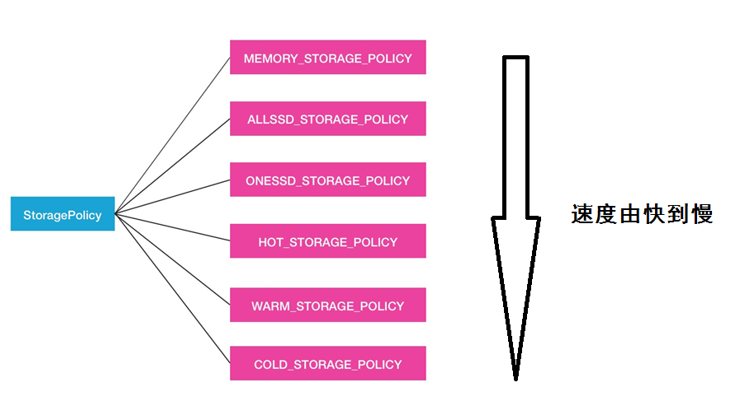
对于数据的存储介质,HDFS的BlockStoragePolicySuite类内部定义了6中策略
Hot(默认策略)、 COLD、 WARM、 ALL_SSD 、 ONE_SSD、 LAZY_PERSIST策略
Hot:用于存储和计算,流行且仍用于处理的数据将保留在此策略中。所有的副本都保存在DISK中
COLD:仅适用于计算量有限的存储。不再使用的数据或需要归档的数据从热数据移动到冷数据。所有的副本都存储在APCHIVE中
WARM:部分热和部分冷,热时,其某些副本存储在DISK中,其余副本存储在ARCHIVE中
ALL_SSD: 所有副本都存储在SSD中
One_SSD:用于将副本之一存储在SSD中,其余副本存储在DISK中
Lazy_Persist: 用于在内存中写入具有单个副本的块,首先将副本写入到RAM_DISK,然后将其延迟保存在DISK中
速度快慢:
相关命令
列出所有的策略:
hdfs storagepolicies -listPolicies
测试结果:

设置存储策略
hdfs storagepolicies -setStoragePolicy -path <path> -ploicy <policy>
取消存储策略
hdfs storagepolicies -unsetStoragePolicy -path <path>
在执行unset之后,将应用当前目录最近的祖先存储策略,如果没有任何祖先的策略,则采用默认的存储策略
获取存储策略
hdfs storagepolicies -getStoragePolicy -path <path>
相关实验: 冷热温数据异构存储
进行规划:
规划目录用途/data/hot热阶段数据/data/warm温阶段数据/data/cold冷阶段数据
配置DateNode存储目录,指定存储介质类型(hdfs-site.xml)
进入到hadoop的目录下的etc/hadoop下
编写hist-site.xml
<property><name>dfs.datanode.data.dir</name><value>[DISK]file://${hadoop.tmp.dir}/dfs/data,[ARCHIVE]file://${hadoop.tmp.dir}/dfs/data/archive</value></property>
保存后将文件分发到其他文件
rsync -av /opt/module/hadoop-3.3.1/etc/hadoop/ root@hadoop134:/opt/module/hadoop-3.3.1/etc/hadoop/
通过rsync将其进行分发
通过浏览器UI查看是否已经识别成功
一共三个节点,我们随便找到一个节点,查看其状态:

显然已经识别成功。
创建文件夹
hadoop fs -mkdir -p /data/hot
hadoop fs -mkdir -p /data/warm
hadoop fs -mkdir -p /data/cold
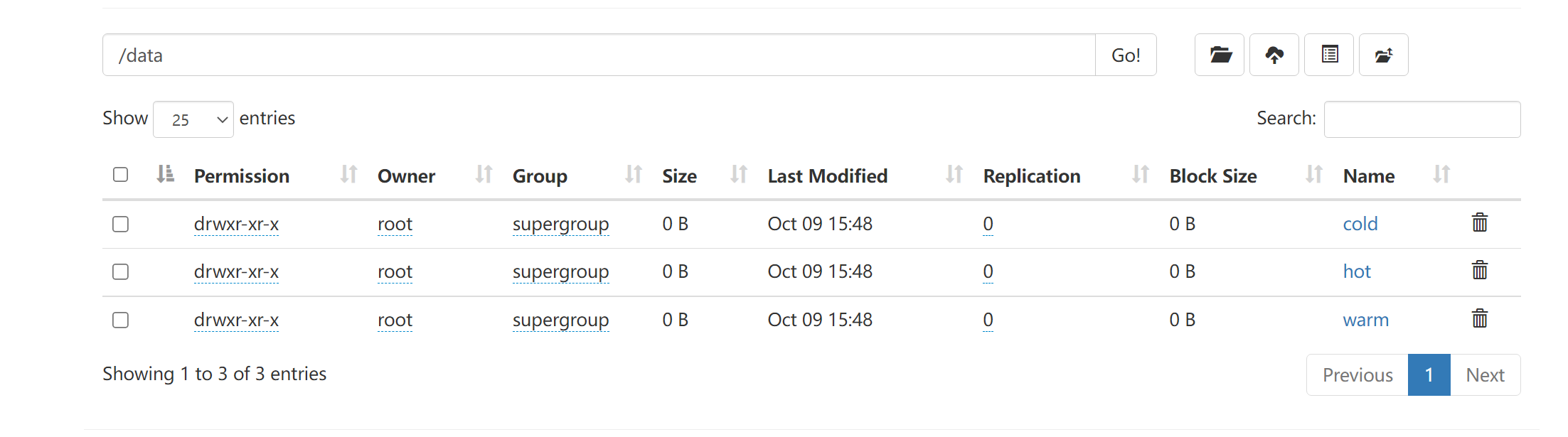
创建成功
设置三个目录的存储策略
hdfs storagepolicies -setStoragePolicy -path /data/hot -policy HOT
hdfs storagepolicies -setStoragePolicy -path /data/warm -policy WARM
hdfs storagepolicies -setStoragePolicy -path /data/cold -policy COLD

进行检验:
检查各个文件的策略:
hdfs storagepolicies -getStoragePolicy -path /data/hot
hdfs storagepolicies -getStoragePolicy -path /data/warm
hdfs storagepolicies -getStoragePolicy -path /data/cold

上传文件进行测试
这里将hello.txt文件上传到hdfs文件系统中
hadoop fs -put /root/hello.txt /data/hot
hadoop fs -put /root/hello.txt /data/warm
hadoop fs -put /root/hello.txt /data/cold
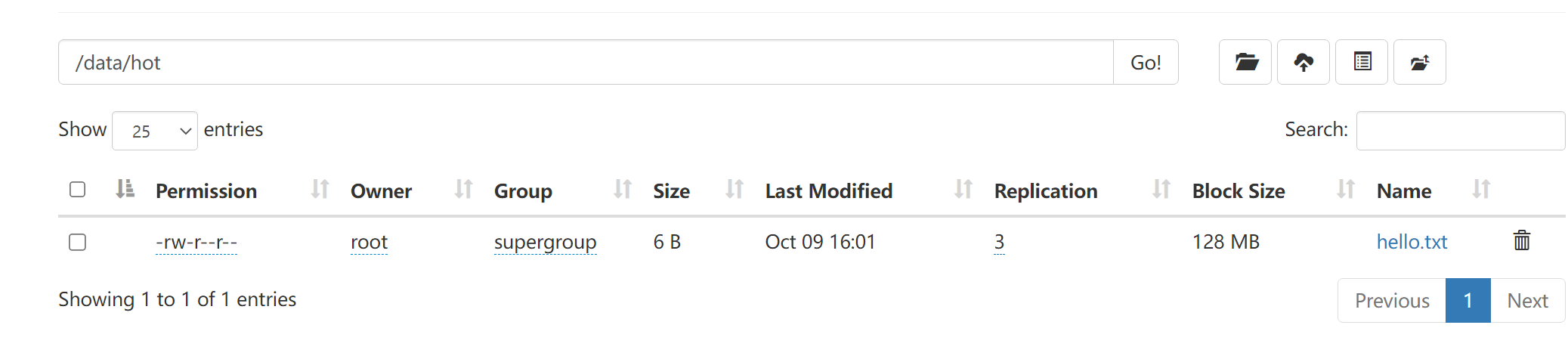
通过检查发现全部上传成功。
查看不同文件存储策略文件的block的位置
指令:
hdfs fsck /data/hot/hello.txt -files -blocks -locations
查看hot下文件的存储位置
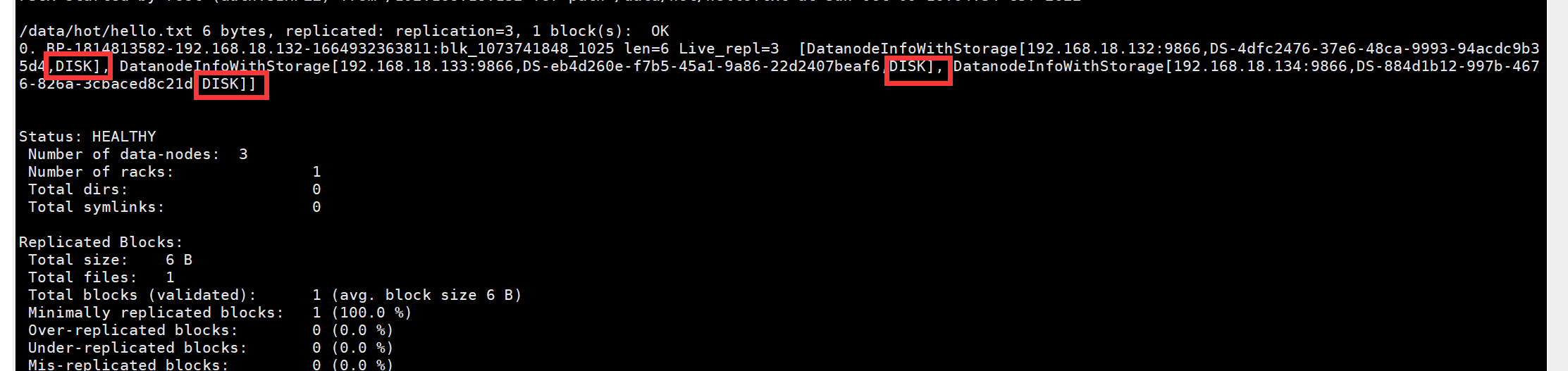
可见hot策略下,三个备份文件都存储在DISK(机器硬盘)下
hdfs fsck /data/warm/hello.txt -files -blocks -locations

可见WARM策略下部分存在DISK上,部分存在ARCHIVE中
hdfs fsck /data/cold/hello.txt -files -blocks -locations

在CLOD策略下,全部存储在ARCHIVE中
LAZY PERSIST策略介绍
- HDFS支持把数据写入有DataNodde管理的堆外内存
- DataNode异步的将内存中数据刷新到磁盘,从而减少代价较高的的磁盘IO操作,这种写入称为Lazy Persist写入
- 该特性在2.6.0开始被支持
执行流程
- 对目标文件目录设置StoragePolicy为LAZY_PERSIST的内存存储策略
- 客户端进程向NameNode发起创建/写文件请求
- 客户端请求到具体的DataNode后DataNode会把这些数据块写入到RAM内存中,同时启动异步线程服务将内存数据持久化写入到磁盘上
- 内存的异步持久化存储是指数据不是马上罗盘,而是懒惰的、延时的进行处理。
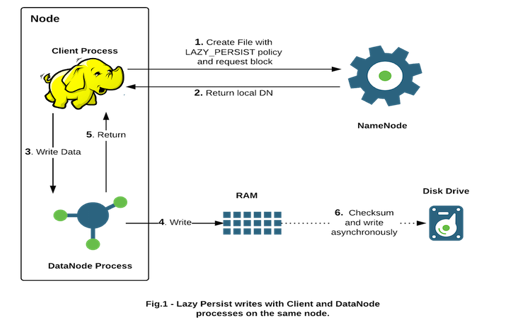
LAZY_PERSIST设置使用
虚拟内存的配置
使用的时
tmpfs
,tmpfs一种基于内存的文件系统。最好的RAM文件系统。
mount -t tmpfs -o size=200m tmpfs /mnt/tmpfs/
通过指令查看是否挂在成功:
df -h
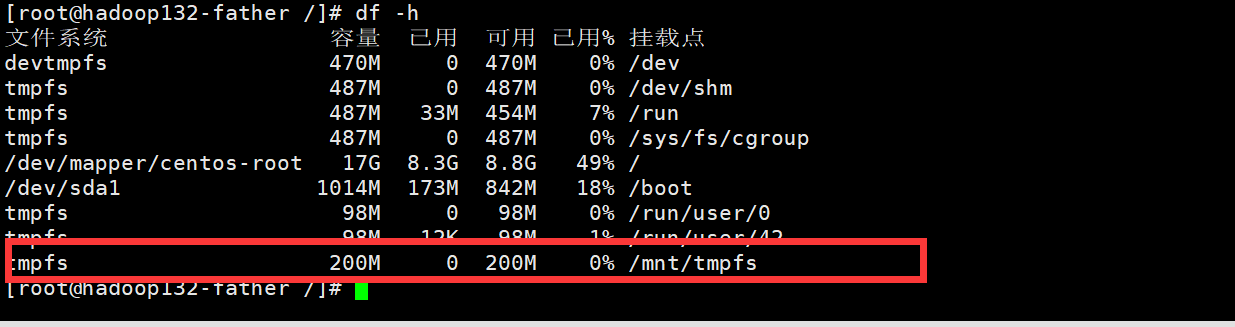
显然挂载成功
内存存储截至设置
将机器中已经完成好的虚拟内存盘配置到dfs.datanode.data.dir中,其次还需要带上
RAM_DISK
标签
配置文件如下:
<property><name>dfs.datanode.data.dir</name><value>[DISK]file://${hadoop.tmp.dir}/dfs/data,[ARCHIVE]file://${hadoop.tmp.dir}/dfs/data/archive,[RAM_DISK]/mnt/tmpfs</value></property>
随后通过rsync进行分发
然后重启hadoop 或者hdfs
查看是否能够识别:
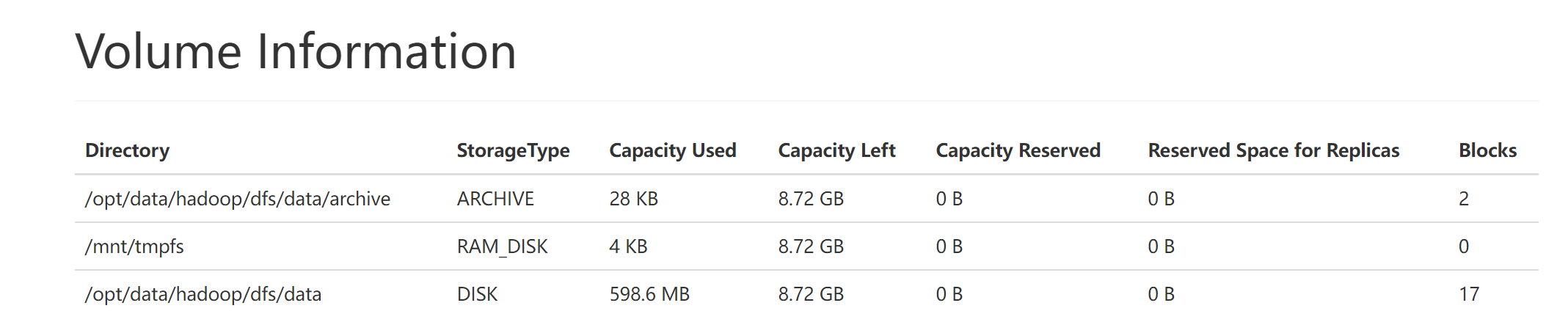
显然识别成功
参数设置优化
dfs.storage.policy.enabled
是否开启异构存储,默认为true,所以可以不进行设置
dfs.datanode.max.locked.memory
用于在数据节点上的内存中缓存块副本的内存量。默认情况下此参数设置为0,这将禁用内存中缓存。内存之国小会导致内存中的总的可存储的数据块变小,但如果超过DataNode能承受的最大内存大小的话,部分内存块会被直接移出
<!-- 用于在数据节点上的内存中缓存块副本的内存量(以字节为单位)。默认情况下,此参数设置为0,这将禁用 内存中缓存。内存值过小会导致内存中的总的可存储的数据块变少,但如果超过 DataNode 能承受的最大内存大小的话,部分内存块会被直接移出 。byte 类型 --><property><name>dfs.datanode.max.locked.memory</name><value>65536</value></property>
在目录上设置存储策略
先创建文件夹
hadoop fs -mkdir -p /data/lazy
设置策略
hdfs storagepolicies -setStoragePolicy -path /data/lazy -policy LAZY_PERSIST
查看策略是否设置成功:
hdfs storagepolicies -getStoragePolicy -path /data/lazy

显然设置成功
版权归原作者 不知落叶何时落 所有, 如有侵权,请联系我们删除。