
首先需要安装selenium:
第一种:可以自己下载selenium tar.gz包,下载到python目录下:解压到当前文件夹
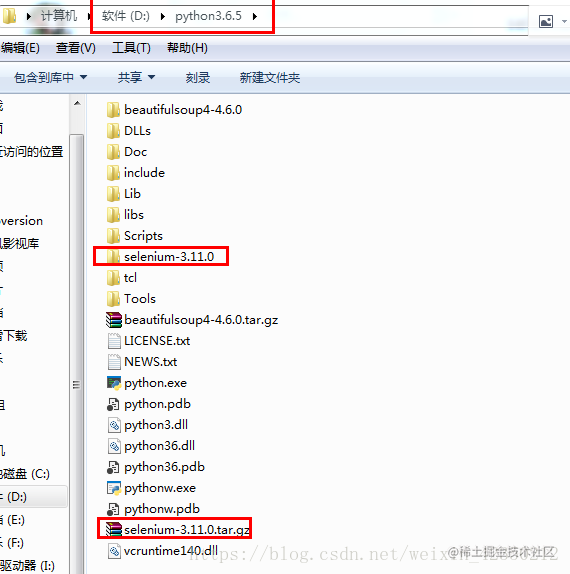
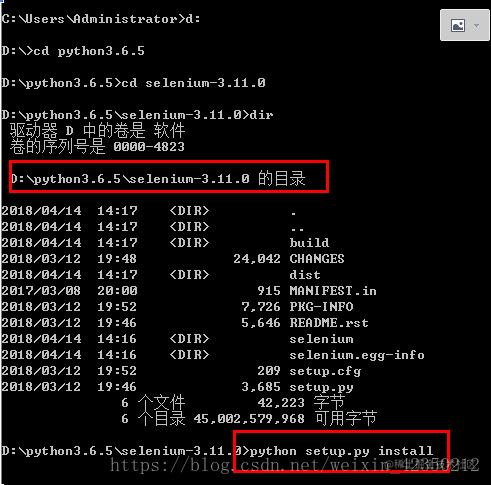
在cmd命令行:进入到解压包中,进行安装。安装完成之后,如果是eclipse中,请 clean project之后,
pydev才能识别新安装的包
第二种: 可以直接使用在命令窗口: pip install selenium进行安装
==================================
使用selenium模拟浏览器登录时,需要下载对应浏览器的内核:
chorme内核的下载地址:注意根据自己浏览器版本进行对应下载:
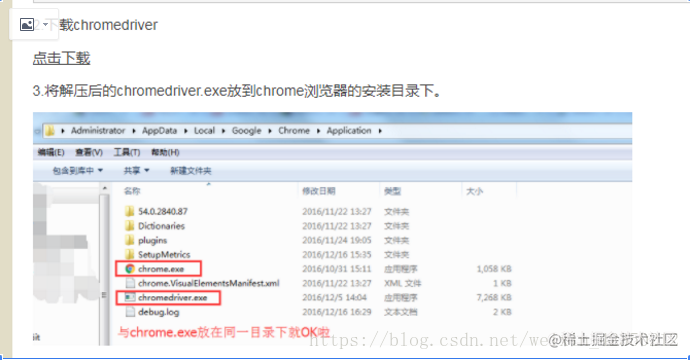
点击下载
将chromedriver,放在chorme.exe启动的相同位置
python代码:
-- coding:utf-8 --
from selenium import webdriver
import os
#引入chromedriver.exe
chromedriver="C:/Program Files (x86)/Google/Chrome/Application/chromedriver.exe"
os.environ["webdriver.chrome.driver"] = chromedriver
browser = webdriver.Chrome(chromedriver)
#设置浏览器需要打开的url
url = "www.baidu.com/"
browser.get(url)
#在百度搜索框中输入关键字"python"
browser.find_element_by_id("kw").send_keys("python")
#单击搜索按钮
browser.find_element_by_id("su").click()
#关闭浏览器
#browser.quit()
=================以上是使用selenium进行模拟浏览器登录,需要打开浏览器,其实可以增加无头参数,不启动浏览器进行爬取操作。
版权归原作者 恶霸程序员388 所有, 如有侵权,请联系我们删除。