
文章目录
一、collect_set()/collect_list():
在 Hive 中想实现按某字段分组,对另外字段进行合并,可通过collect_list()或者collect_set()实现。
- collect_set()函数与collect_list()函数:列转行专用函数,都是将分组中的某列转为一个数组返回。有时为了字段拼接效果,多和concat_ws()函数连用。
- collect_set()与collect_list()的区别:
collect_list()函数 - - 不去重
collect_set()函数 - - 去重
二、实际运用
1、创建测试表及插入数据 :
droptable test_1;createtable test_1(
id string,
cur_day string,rule string
)row format delimited fieldsterminatedby',';insertinto test_1 values('a','20230809','501'),('a','20230811','502'),('a','20230812','503'),('a','20230812','501'),('a','20230813','512'),('b','20230809','511'),('b','20230811','512'),('b','20230812','513'),('b','20230812','511'),('b','20230813','512'),('b','20230809','511'),('c','20230811','512'),('c','20230812','513'),('c','20230812','511'),('c','20230813','512');
把同一分组的不同行的数据聚合成一个行
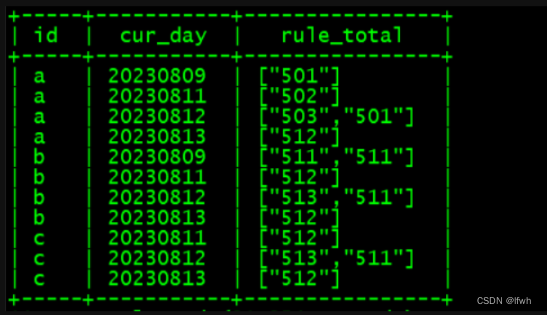
举例1:按照id,cur_day分组,取出每个id对应的所有rule(不去重)。
select id,cur_day,collect_list(rule)as rule_total from test_1 groupby id,cur_day orderby id,cur_day;
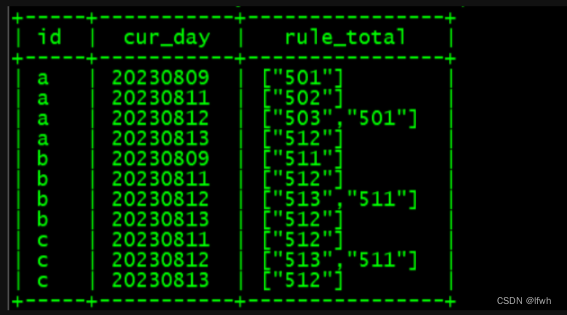
举例2:按照id,cur_day分组,取出每个id对应的所有rule(去重)。
select id,cur_day,collect_set(rule)as rule_total from test_1 groupby id,cur_day orderby id,cur_day;
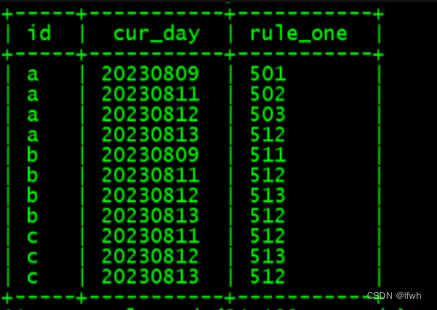
- 用下标可以随机取某一个
select id,cur_day,collect_list(rule)[0]as rule_one from test_1 groupby id,cur_day orderby id,cur_day;select id,cur_day,collect_set(rule)[0]as rule_one from test_1 groupby id,cur_day orderby id,cur_day;
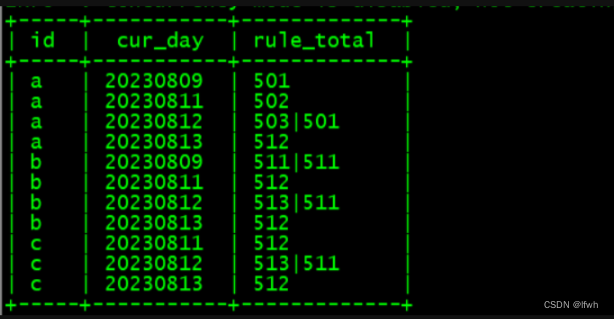
- 聚合后的中的值用‘|’分隔开
select id,cur_day,concat_ws('|',collect_list(rule))as rule_total from test_1 groupby id,cur_day orderby id,cur_day;select id,cur_day,concat_ws('|',collect_set(rule))as rule_total from test_1 groupby id,cur_day orderby id,cur_day;
- 例子
- spark-sql : COLLECT_LIST里边字段起别名.(as等其他方式都用过,都报错. 最后用子查询来解决)
SELECT fenceCode,
COLLECT_LIST(STRUCT(vehicleNo, plateColor, enterTime, levaeTime, trans))AS actInfos
FROM(SELECT fence_code AS fenceCode,
veh_no AS vehicleNo,
veh_color AS plateColor,
enter_time AS enterTime,
out_time AS levaeTime,
trans
FROM mid.ct_fence_into_out_dt where dt =20230911) subquery
GROUPBY fenceCode;
总结
如果此篇文章有帮助到您, 希望打大佬们能
关注、
点赞、
收藏、
评论支持一波,非常感谢大家!
如果有不对的地方请指正!!!
参考1
本文转载自: https://blog.csdn.net/weixin_42326851/article/details/134597900
版权归原作者 lfwh 所有, 如有侵权,请联系我们删除。
版权归原作者 lfwh 所有, 如有侵权,请联系我们删除。