
1. 下载数据集
下载后数据如下:
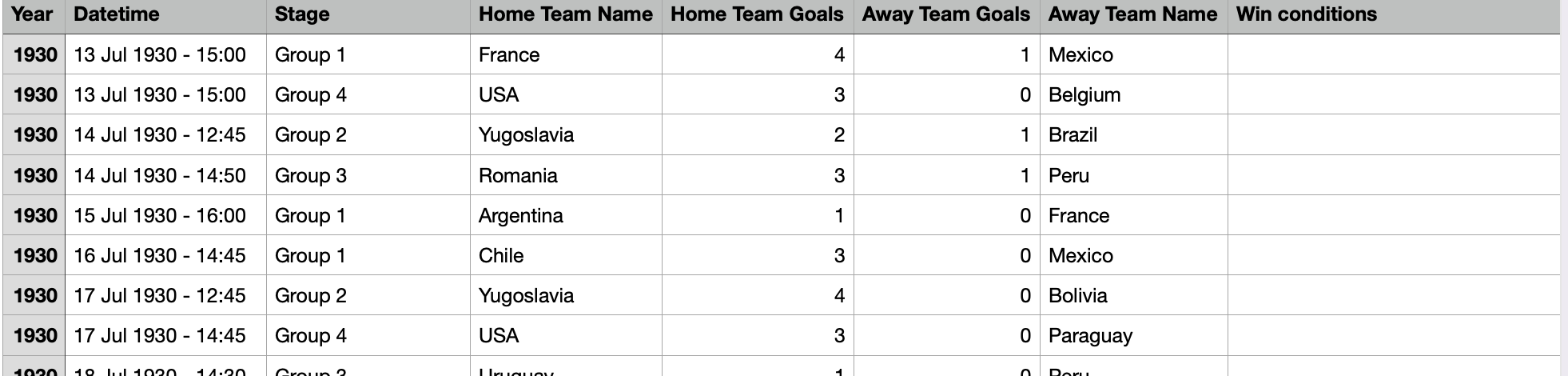
FIFA World Cup | Kaggle
2. 数据预处理
reprocess_dataset() 方法是数据进行预处理。预处理过的数据如下:
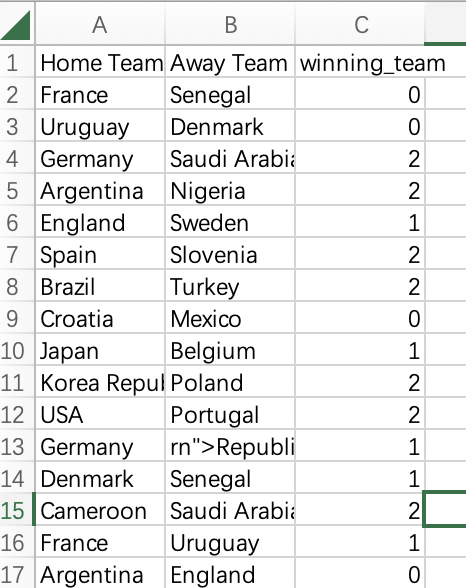
save_dataset() 方法是对预处理过的数据,进行向量化。
完整代码如下:
import pandas as pd
import numpy as np
from sklearn.feature_extraction import DictVectorizer
import joblib
root_path = "models"
def reprocess_dataset():
#load data
results = pd.read_csv('datasets/WorldCupMatches.csv', encoding='gbk')
#Adding goal difference and establishing who is the winner
winner = []
for i in range (len(results['Home Team Name'])):
if results ['Home Team Goals'][i] > results['Away Team Goals'][i]:
winner.append(results['Home Team Name'][i])
elif results['Home Team Goals'][i] < results ['Away Team Goals'][i]:
winner.append(results['Away Team Name'][i])
else:
winner.append('Draw')
results['winning_team'] = winner
#adding goal difference column
results['goal_difference'] = np.absolute(results['Home Team Goals'] - results['Away Team Goals'])
# narrowing to team patcipating in the world cup, totally there are 32 football teams in 2022
worldcup_teams = ['Qatar','Germany','Denmark', 'Brazil','France','Belgium', 'Serbia',
'Spain','Croatia', 'Switzerland', 'England','Netherlands', 'Argentina',' Iran',
'Korea Republic','Saudi Arabia', 'Japan', 'Uruguay','Ecuador','Canada',
'Senegal', 'Poland', 'Portugal','Tunisia', 'Morocco','Cameroon','USA',
'Mexico','Wales','Australia','Costa Rica', 'Ghana']
df_teams_home = results[results['Home Team Name'].isin(worldcup_teams)]
df_teams_away = results[results['Away Team Name'].isin(worldcup_teams)]
df_teams = pd.concat((df_teams_home, df_teams_away))
df_teams.drop_duplicates()
df_teams.count()
#dropping columns that wll not affect matchoutcomes
df_teams_new =df_teams[[ 'Home Team Name','Away Team Name','winning_team']]
print(df_teams_new.head() )
#Building the model
#the prediction label: The winning_team column will show "2" if the home team has won, "1" if it was a tie, and "0" if the away team has won.
df_teams_new = df_teams_new.reset_index(drop=True)
df_teams_new.loc[df_teams_new.winning_team == df_teams_new['Home Team Name'],'winning_team']=2
df_teams_new.loc[df_teams_new.winning_team == 'Draw', 'winning_team']=1
df_teams_new.loc[df_teams_new.winning_team == df_teams_new['Away Team Name'], 'winning_team']=0
print(df_teams_new.count() )
df_teams_new.to_csv('datasets/raw_train_data.csv', encoding='gbk', index =False)
def save_dataset():
df_teams_new = pd.read_csv('datasets/raw_train_data.csv', encoding='gbk')
feature = df_teams_new[[ 'Home Team Name','Away Team Name']]
vec = DictVectorizer(sparse=False)
print(feature.to_dict(orient='records'))
X =vec.fit_transform(feature.to_dict(orient='records'))
X = X.astype('int')
print("===")
print(vec.get_feature_names())
print(vec.feature_names_)
y = df_teams_new[[ 'winning_team']]
y =y.astype('int')
print(X.shape)
print(y.shape)
joblib.dump(vec, root_path+"/vec.joblib")
np.savez('datasets/train_data', x= X, y = y)
if __name__ == '__main__':
reprocess_dataset()
save_dataset();
3. 模型训练与选择
用不同的传统机器学习方法进行训练,训练后的模型比较
ModelTraining AccuracyTest AccuracyLogistic Regression67.40%61.60%SVM67.30%62.70%Naive Bayes65.50%63.80%Random Forest90.80%65.50%XGB75.30%62.00%
可以看到随机森林模型在测试集上准确率最高,所以我们可以用它来做预测。
下面是完整训练代码:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import matplotlib.ticker as ticker
import matplotlib.ticker as plticker
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn import svm
import sklearn as sklearn
from sklearn.feature_extraction import DictVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.ensemble import RandomForestClassifier
import joblib
from sklearn.metrics import classification_report
from xgboost import XGBClassifier
from sklearn.metrics import confusion_matrix
root_path = "models"
def get_dataset():
train_data = np.load('datasets/train_data.npz')
return train_data
def train_by_LogisticRegression(train_data):
X = train_data['x']
y = train_data['y']
# Separate train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30, random_state=42)
logreg = LogisticRegression()
logreg.fit(X_train, y_train)
joblib.dump(logreg, root_path+'/LogisticRegression_model.joblib')
score = logreg.score(X_train, y_train)
score2 = logreg.score(X_test, y_test)
print("LogisticRegression Training set accuracy: ", '%.3f'%(score))
print("LogisticRegression Test set accuracy: ", '%.3f'%(score2))
def train_by_svm(train_data):
X = train_data['x']
y = train_data['y']
# Separate train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30, random_state=42)
model = svm.SVC(kernel='linear', verbose=True, probability=True)
model.fit(X_train, y_train)
joblib.dump(model, root_path+'/svm_model.joblib')
score = model.score(X_train, y_train)
score2 = model.score(X_test, y_test)
print("SVM Training set accuracy: ", '%.3f' % (score))
print("SVM Test set accuracy: ", '%.3f' % (score2))
def train_by_naive_bayes(train_data):
X = train_data['x']
y = train_data['y']
# Separate train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30, random_state=42)
model = MultinomialNB()
model.fit(X_train, y_train)
joblib.dump(model, root_path+'/naive_bayes_model.joblib')
score = model.score(X_train, y_train)
score2 = model.score(X_test, y_test)
print("naive_bayes Training set accuracy: ", '%.3f' % (score))
print("naive_bayes Test set accuracy: ", '%.3f' % (score2))
def train_by_random_forest(train_data):
X = train_data['x']
y = train_data['y']
# Separate train and test sets
X_train = X
y_train = y
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30, random_state=42)
model = RandomForestClassifier(criterion='gini', max_features='sqrt')
model.fit(X_train, y_train)
joblib.dump(model, root_path+'/random_forest_model.joblib')
score = model.score(X_train, y_train)
score2 = model.score(X_test, y_test)
print("random forest Training set accuracy: ", '%.3f' % (score))
print("random forest Test set accuracy: ", '%.3f' % (score2))
def train_by_xgb(train_data):
X = train_data['x']
y = train_data['y']
# Separate train and test sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30, random_state=42)
model = XGBClassifier(use_label_encoder=False)
model.fit(X_train, y_train)
joblib.dump(model, root_path+'/xgb_model.joblib')
score = model.score(X_train, y_train)
score2 = model.score(X_test, y_test)
print("xgb Training set accuracy: ", '%.3f' % (score))
print("xgb Test set accuracy: ", '%.3f' % (score2))
y_pred = model.predict(X_test)
report = classification_report(y_test, y_pred, output_dict=True)
# show_confusion_matrix(y_test, y_pred)
print(report)
def show_confusion_matrix(y_true, y_pred, pic_name = "confusion_matrix"):
confusion = confusion_matrix(y_true=y_true, y_pred=y_pred)
print(confusion)
sns.heatmap(confusion, annot=True, cmap= 'Blues', xticklabels=['0','1','2'], yticklabels=['0','1','2'], fmt = '.20g')
plt.xlabel('Predicted class')
plt.ylabel('Actual Class')
plt.title(pic_name)
# plt.savefig('pic/' + pic_name)
plt.show()
if __name__ == '__main__':
train_data = get_dataset()
train_by_LogisticRegression(train_data)
train_by_svm(train_data)
train_by_naive_bayes(train_data)
train_by_random_forest(train_data)
train_by_xgb(train_data)
4. 预测
执行下面预测代码,结果是Ecuador胜于Qatar, 英国队胜于伊朗队。
[2]
[[0.05 0.22033333 0.72966667]]
Probability of Ecuador winning: 0.730
Probability of Draw: 0.220
Probability of Qatar winning: 0.050
[2]
[[0.02342857 0.21770455 0.75886688]]
Probability of England winning: 0.759
Probability of Draw: 0.218
Probability of Iran winning: 0.023
完整代码
import joblib
worldcup_teams = ['Qatar','Germany','Denmark', 'Brazil','France','Belgium', 'Serbia',
'Spain','Croatia', 'Switzerland', 'England','Netherlands', 'Argentina',' Iran',
'Korea Republic','Saudi Arabia', 'Japan', 'Uruguay','Ecuador','Canada',
'Senegal', 'Poland', 'Portugal','Tunisia', 'Morocco','Cameroon','USA',
'Mexico','Wales','Australia','Costa Rica', 'Ghana']
root_path = "models"
def verify_team_name(team_name):
for worldcup_team in worldcup_teams:
if team_name==worldcup_team:
return True
return False
def predict(model_dir =root_path+'/LogisticRegression_model.joblib', team_a='France', team_b = 'Mexico'):
if not verify_team_name(team_a):
print(team_a, ' is not correct')
return
if not verify_team_name(team_b) :
print(team_b, ' is not correct')
return
logreg = joblib.load(model_dir)
input_x = [{'Home Team Name': team_a, 'Away Team Name': team_b}]
vec = joblib.load(root_path+"/vec.joblib")
input_x = vec.transform(input_x)
result = logreg.predict(input_x)
print(result)
result1 = logreg.predict_proba(input_x)
print(result1)
print('Probability of ',team_a , ' winning:', '%.3f'%result1[0][2])
print('Probability of Draw:', '%.3f' % result1[0][1])
print('Probability of ', team_b, ' winning:', '%.3f' % result1[0][0])
if __name__ == '__main__':
team_a = 'Ecuador'
team_b = 'Qatar'
predict('models/random_forest_model.joblib', team_a, team_b)
team_a = 'England'
team_b = ' Iran'
predict('models/random_forest_model.joblib', team_a, team_b)
5. 个人总结
特征少的可怜,如果可以加一些球员的信息和状态的特征会更好,数据也相对太少,如果可以把欧洲杯,亚洲杯,非洲杯和美洲杯的每届数据加入进来就好了。数据有点旧(1930年后所有数据),这也是没办法,因为没有其它数据了。
如果预测的是比分,是不是也可以用分类做呢?比如最多可以踢入4个球每个队,当然像西班牙队可以踢进去7个球太罕见了,我们可以忽略不计,哈哈。那就是25个类别。效果会不会好呢?有待检验。
6. 2018后新的数据
YearHome Team NameAway Team Namewinning_team2018FranceCroatia22018BelgiumEngland22018CroatiaEngland22018FranceBelgium22018RussiaCroatia12018SwedenEngland02018BrazilBelgium02018UruguayFrance02018ColombiaEngland12018SwedenSwitzerland22018BelgiumJapan22018BrazilMexico22018CroatiaDenmark12018SpainRussia12018UruguayPortugal22018FranceArgentina22018EnglandBelgium02018ParaguayTunisia02018SenegalColombia02018JapanPoland02018SwitzerlandCosta Rica12018SerbiaBrazil02018MexicoSweden02018Korea RepublicGermany22018IcelandCroatia02018NigeriaArgentina02018DenmarkFrance12018AustraliaPeru02018IR IranPortugal12018SpainMorocco12018Saudi ArabiaEgypt22018UruguayRussia22018PolandColombia02018JapanSenegal12018EnglandPanama22018GermanySweden22018Korea RepublicMexico02018BelgiumTunisia22018SerbiaSwitzerland02018NigeriaIceland22018BrazilCosta Rica22018ArgentinaCroatia02018FrancePeru22018DenmarkAustralia12018IR IranSpain02018UruguaySaudi Arabia22018PortugalMorocco22018RussiaEgypt22018PolandSenegal02018ColombiaJapan02018TunisiaEngland02018BelgiumPanama22018SwedenKorea Republic22018BrazilSwitzerland12018GermanyMexico02018Costa RicaSerbia02018CroatiaNigeria22018PeruDenmark02018ArgentinaIceland12018FranceAustralia22018PortugalSpain12018MoroccoIR Iran02018EgyptUruguay02018RussiaSaudi Arabia22022QatarEcuador02022EnglandIran22022SenegalNetherlands02022USAWales12022ArgentinaSaudi Arabia02022DenmarkTunisia12022MexicoPoland12022FranceAustralia22022MoroccoCroatia12022GermanyJapan02022SpainCosta Rica22022BelgiumCanada22022SwitzerlandCameroon22022UruguayKorea Republic12022PortugalGhana22022BrazilSerbia22022WalesIran02022QatarSenegal02022NetherlandsEcuador12022EnglandUSA12022TunisiaAustralia02022PolandSaudi Arabia22022FranceDenmark22022ArgentinaMexico22022JapanCosta Rica02022BelgiumMorocco02022CroatiaCanada22022SpainGermany1
版权归原作者 茫茫人海一粒沙 所有, 如有侵权,请联系我们删除。