
14.Selenium 经典动态渲染工具的使用
Selenium-Python中文文档 https://selenium-python-zh.readthedocs.io/en/latest/
Selenium
是一个自动化测试工具,利用它我们可以驱动浏览器执行特定的动作,如点击、下拉等等操作,对于一些 JavaScript 渲染的页面来说,此种抓取方式非常有效,下面我们来看下 Selenium 的安装过程。
1.查看chrome浏览器版本

2.ChromeDriver 安装
ChromeDriver 版本选择:选择跟chrome浏览器一样的版本或者接近的版本
- 官方下载:https://sites.google.com/a/chromium.org/chromedriver 官网需要魔法上网,还要登录
- 其他下载1:https://chromedriver.storage.googleapis.com/index.html
- 其他下载2: https://googlechromelabs.github.io/chrome-for-testing/#stable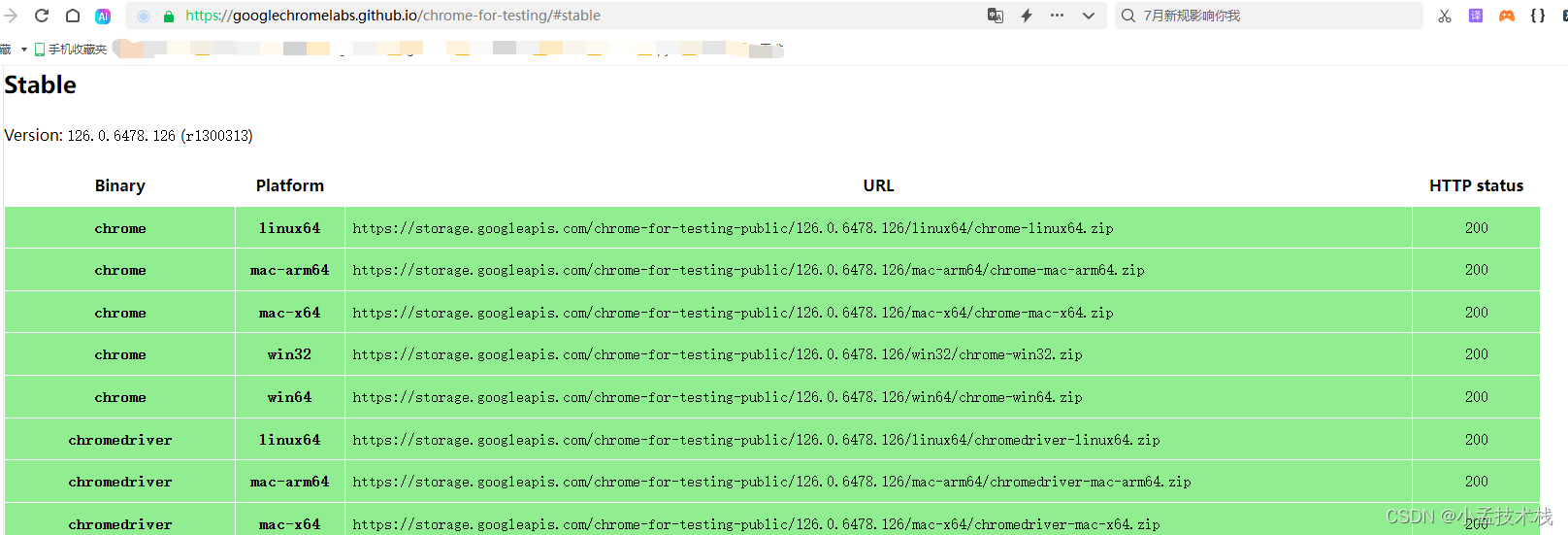
可以看这篇文章 chromedriver下载与安装方法
3.Selenium 安装
执行如下命令即可:
pip3 install selenium
导入一下 Selenium 包,如果没有报错,则证明安装成功
from selenium import webdriver
Selenium 支持非常多的浏览器,如
Chrome
、
Firefox
、
Edge
等
from selenium import webdriver
browser = webdriver.Chrome()
browser = webdriver.Firefox()
browser = webdriver.Edge()
browser = webdriver.Safari()
4.验证安装
from selenium import webdriver
from time import sleep
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')input()
加入
input()
是为了让程序暂停,等待用户输入任意字符后才继续执行下一步操作。这样做是为了防止程序执行完毕后自动关闭浏览器窗口,让用户有足够的时间观察程序的执行结果或手动进行后续操作。
如果运行完毕之后弹出来了一个 Chrome 浏览器并加载了百度页面,出现
chrome正受到自动测试软件的控制
,那就证明没问题了。
5.基本用法
- 使用 Selenium 进行自动化测试的一般流程包括:
启动浏览器
:使用 webdriver.Chrome() 或其他浏览器类型的初始化函数启动浏览器。
导航到页面
:调用 driver.get(url) 方法访问指定的网址。
查找元素
:使用 find_element_by_* 系列方法定位页面元素,如 find_element_by_id、find_element_by_xpath 等。
执行操作
:对定位到的元素执行点击、输入等操作,如 **element.click()、element.send_keys(“some keys”)**。
关闭浏览器
:测试完成后,调用 driver.quit() 关闭浏览器。
- selenium如何选取元素
序号方法描述1find_element_by_id()通过ID定位元素2find_element_by_name()通过name定位元素3find_element_by_class_name()通过类样式名称定位元素4find_element_by_tag_name()通过标签名称定位元素5find_element_by_link_text()通过链接定位元素(a标签)6find_element_by_css_selector()通过CSS定位元素7find_element_by_xpath()通过xpath语法来获取元素5.1启动浏览器
from selenium import webdriver
browser = webdriver.Chrome()input()//

5.2导航到页面
我们以淘宝为例
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')print(browser.page_source)input()

运行后发现,此时弹出了 Chrome 浏览器并且自动访问了淘宝,然后控制台输出了淘宝页面的源代码
5.3查找元素
5.3.1单个元素 find_element
比如,想要从淘宝页面中提取搜索框这个节点,首先要观察它的源代码,如图所示。
可以发现,它的 id 是
q
,name 也是
q
。此外,还有许多其他属性,此时我们就可以用多种方式获取它了。比如,find_element_by_name 是根据 name 值获取,find_element_by_id 是根据 id 获取。另外,还有根据 XPath、CSS 选择器等获取的方式。
find_element获取满足条件的第一个元素find_elements获取满足条件的所有元素
下面我们用代码实现一下:
from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
input_first = browser.find_element(By.ID,'q')
input_second = browser.find_element(By.NAME,'q')
input_third = browser.find_element(By.CSS_SELECTOR,'#q')
input_four = browser.find_element(By.XPATH,'//*[@id="q"]')print(input_first)print(input_second)print(input_third)print(input_four)input()
上面我们使用 4 种方式获取输入框,分别是根据 ID、NAME、CSS 选择器、XPath 获取,它们返回的结果完全一致。
运行结果如下:
<selenium.webdriver.remote.webelement.WebElement (session="322747cbc97f25d32d7e199fe73cf3ab", element="f.4D2DE1B1A752F3ABC3158D83A25383C1.d.832E76F3B106DFD76922F559D8DEE26C.e.2")><selenium.webdriver.remote.webelement.WebElement (session="322747cbc97f25d32d7e199fe73cf3ab", element="f.4D2DE1B1A752F3ABC3158D83A25383C1.d.832E76F3B106DFD76922F559D8DEE26C.e.2")><selenium.webdriver.remote.webelement.WebElement (session="322747cbc97f25d32d7e199fe73cf3ab", element="f.4D2DE1B1A752F3ABC3158D83A25383C1.d.832E76F3B106DFD76922F559D8DEE26C.e.2")><selenium.webdriver.remote.webelement.WebElement (session="322747cbc97f25d32d7e199fe73cf3ab", element="f.4D2DE1B1A752F3ABC3158D83A25383C1.d.832E76F3B106DFD76922F559D8DEE26C.e.2")>
我们来看一下这个 By 类的源码
from selenium.webdriver.common.by import By

8种选择方式,对应上面 element_by_XXXX 8种 描述,find_element_by_id(id) 就等价于 find_element(By.ID, id)

不过,selenium 高版本 看样子是不支持 find_element_by_XXX 这种方式了,建议使用 find_element(By.ID, id) 这种方式
5.3.2多个元素 find_elements

from selenium import webdriver
from selenium.webdriver.common.by import By
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')
lis = browser.find_elements(By.CSS_SELECTOR,'.service-bd li')for li in lis:print(li.text)input()
运行结果如下:
<selenium.webdriver.remote.webelement.WebElement (session="534ac2aa5a88454893b18103508d1059", element="f.1EE12A838B8B70DCD9CA4EB62C5951F0.d.57598506BAF39D291C85857AE242A0FD.e.69")><selenium.webdriver.remote.webelement.WebElement (session="534ac2aa5a88454893b18103508d1059", element="f.1EE12A838B8B70DCD9CA4EB62C5951F0.d.57598506BAF39D291C85857AE242A0FD.e.70")><selenium.webdriver.remote.webelement.WebElement (session="534ac2aa5a88454893b18103508d1059", element="f.1EE12A838B8B70DCD9CA4EB62C5951F0.d.57598506BAF39D291C85857AE242A0FD.e.71")><selenium.webdriver.remote.webelement.WebElement (session="534ac2aa5a88454893b18103508d1059", element="f.1EE12A838B8B70DCD9CA4EB62C5951F0.d.57598506BAF39D291C85857AE242A0FD.e.72")><selenium.webdriver.remote.webelement.WebElement (session="534ac2aa5a88454893b18103508d1059", element="f.1EE12A838B8B70DCD9CA4EB62C5951F0.d.57598506BAF39D291C85857AE242A0FD.e.73")><selenium.webdriver.remote.webelement.WebElement (session="534ac2aa5a88454893b18103508d1059", element="f.1EE12A838B8B70DCD9CA4EB62C5951F0.d.57598506BAF39D291C85857AE242A0FD.e.74")><selenium.webdriver.remote.webelement.WebElement (session="534ac2aa5a88454893b18103508d1059", element="f.1EE12A838B8B70DCD9CA4EB62C5951F0.d.57598506BAF39D291C85857AE242A0FD.e.75")><selenium.webdriver.remote.webelement.WebElement (session="534ac2aa5a88454893b18103508d1059", element="f.1EE12A838B8B70DCD9CA4EB62C5951F0.d.57598506BAF39D291C85857AE242A0FD.e.76")><selenium.webdriver.remote.webelement.WebElement (session="534ac2aa5a88454893b18103508d1059", element="f.1EE12A838B8B70DCD9CA4EB62C5951F0.d.57598506BAF39D291C85857AE242A0FD.e.77")><selenium.webdriver.remote.webelement.WebElement (session="534ac2aa5a88454893b18103508d1059", element="f.1EE12A838B8B70DCD9CA4EB62C5951F0.d.57598506BAF39D291C85857AE242A0FD.e.78")><selenium.webdriver.remote.webelement.WebElement (session="534ac2aa5a88454893b18103508d1059", element="f.1EE12A838B8B70DCD9CA4EB62C5951F0.d.57598506BAF39D291C85857AE242A0FD.e.79")>
5.4 执行操作
**在淘宝搜索框自动输入
华为手机
两个字,清除输入,再次输入
iphone
,点击搜索,跳转到登录界面,输入
登录信息
,点击登录按钮,这一系列操作**
代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
browser = webdriver.Chrome()
browser.get('https://www.taobao.com')input= browser.find_element(By.ID,'q')#选择搜索输入框input.send_keys('华为手机')#输入华为手机
time.sleep(1)input.clear()#清除输入的内容input.send_keys('iPhone')#输入iPhone
button = browser.find_element(By.CLASS_NAME,'btn-search')#选择搜索按钮
button.click()#点击搜索按钮
input1 = browser.find_element(By.ID,'fm-login-id')#选择登录用户名输入框
input1.send_keys('176xxxxxxx9')#输入登录用户名
input2 = browser.find_element(By.ID,'fm-login-password')#选择登录密码输入框
input2.send_keys('123456')#输入登录用户密码
button1 = browser.find_element(By.CLASS_NAME,'password-login')#选择登录按钮
button1.click()#点击登录按钮input()
通过上面的方法,我们完成了一些常见节点的操作,更多的操作可以参见官方文档的交互动作介绍 http://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.remote.webelement
5.5 动作链ActionChains
使用xpath定位到元素后,页面有些内容需要鼠标操作才能显示,例如双击、悬浮或拖拽的操作。可以使用selenium提供的ActionChains类进行鼠标操作
ActionChains的执行原理,当你调用ActionChains的方法时,不会立即执行,而是会将所有的操作按顺序放在一个队列里,当你调用perform()方法时,队列中的时间会依次执行
ActionChains类提供的鼠标操作,分为两种动作,一个是鼠标的动作,另一个是执行、清除动作
ActionChains的动作:
动作方法动作描述click(on_element=None)单击鼠标左键
click_and_hold(on_element=None)点击鼠标左键,不松开
context_click(on_element=None)点击鼠标右键
double_click(on_element=None)双击鼠标左键
drag_and_drop(source, target)拖拽到某个元素然后松开
drag_and_drop_by_offset(source, xoffset, yoffset)拖拽到某个坐标然后松开
key_down(value, element=None)按下某个键盘上的键
key_up(value, element=None)松开某个键
move_by_offset(xoffset, yoffset)鼠标从当前位置移动到某个坐标
move_to_element(to_element)鼠标移动到某个元素
move_to_element_with_offset(to_element, xoffset, yoffset)移动到距某个元素(左上角坐标)多少距离的位置
release(on_element=None)在某个元素位置松开鼠标左键
send_keys(*keys_to_send)发送某个键到当前焦点的元素
send_keys_to_element(element, *keys_to_send)发送某个键到指定元素
执行、清除动作:
动作方法动作描述pause动作之间可以暂停perform执行动作reset_action清除动作
示例:
from selenium import webdriver
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://www.csdn.net/")
item = driver.find_element(By.XPATH,'//*[@id="floor-nav_557"]')#实例化ActionChains,调用鼠标操作,执行鼠标操作#移动到item元素,停留1s,执行
ActionChains(driver).move_to_element(item).pause(4).perform()

其他一些用法可以看这篇文章:
ActionChains用法
5.6 执行 JavaScript
execute_script
对于某些操作,Selenium API 并没有提供。比如,下拉进度条,它可以直接模拟运行 JavaScript,此时使用 execute_script 方法即可实现,代码如下:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.bilibili.com/')
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
browser.execute_script('alert("To bilibili")')input()
这里就利用 execute_script 方法将进度条下拉到最底部,然后弹出 alert 提示框。
所以说有了这个方法,基本上 API 没有提供的所有功能都可以用执行 JavaScript 的方式来实现了。

5.7 WebElement属性和方法
- WebElement属性
当我们使用WebDriver的find方法定位到元素后,会返回一个WebElement对象,该对象用来描述Web页面上的一个元素.WebElement的常用属性和方法见下表
属性属性描述id标识size宽高rect宽高和坐标tag_name标签名称text文本内容
- WebElement方法
方法方法描述send_keys()输入内容clear()清空内容click()单击get_attribute()获得属性值is_selected()是否被选中is_enabled()是否可用is_displayed()是否显示value_of_css_property()css属性值
具体可以看这篇文章【Selenium核心技术篇】selenium WebElement属性和方法
5.8 切换 Frame
我们知道网页中有一种节点叫作
iframe
,也就是子 Frame,相当于页面的子页面,它的结构和外部网页的结构完全一致。Selenium 打开页面后,它默认是在父级 Frame 里面操作,而此时如果页面中还有子 Frame,它是不能获取到子 Frame 里面的节点的。这时就需要使用 switch_to.frame 方法来切换 Frame

嵌套iframe样式
<iframeid="one"><iframeid="two"></iframe></iframe>
如何切换样例
# 1、id定位,通过iframe的 id ="one" 定位并切入 第一个iframe
driver.switch_to.frame(driver.find_element(By.ID,'one'))# 2、id定位,通过iframe的 id ="two" 定位并切入 第二个iframe
driver.switch_to.frame(driver.find_element(By.ID,'two'))# 3、切换到当前定位 id="two"的iframe 的父级id="one"的iframe
driver.switch_to.parent_frame()# 从当前的iframe中切出
driver.switch_to.default_content()
实战:
#导入模块from time import sleep
from selenium import webdriver
from selenium.webdriver.common.by import By
#实例化浏览器对象
driver=webdriver.Chrome()# 浏览器访问qq邮箱地址
driver.get("https://mail.qq.com/")# 1、class name定位,通过iframe的 class name ="QQMailSdkTool_login_loginBox_qq_iframe" 定位并切入 第一个iframe
driver.switch_to.frame(driver.find_element(By.CLASS_NAME,'QQMailSdkTool_login_loginBox_qq_iframe'))# 2、id定位,通过iframe的 id ="ptlogin_iframe" 定位并切入 第二个iframe
driver.switch_to.frame(driver.find_element(By.ID,'ptlogin_iframe'))# 3、id定位,点击切换为账号密码登录
driver.find_element(By.ID,'switcher_plogin').click()# 4、id定位,邮箱账号输入框,输入邮箱账号[email protected]
driver.find_element(By.ID,'u').send_keys("[email protected]")
sleep(5)# 从当前的iframe中切出
driver.switch_to.default_content()# 根据超链接使用link_text方法定位"基本版"并点击
driver.find_element(By.PARTIAL_LINK_TEXT,"基本版").click()input()
效果图:


5.9 浏览器窗口操作(切换,前进,后退)
- 窗口切换
import time
from selenium import webdriver
#1.打开京东官网
browser = webdriver.Chrome()
browser.get('https://www.jd.com/')print(browser.window_handles)#2.新打开一个浏览器窗口,打开淘宝官网
browser.execute_script('window.open()')
browser.switch_to.window(browser.window_handles[1])
browser.get('https://www.taobao.com')print(browser.window_handles)#3.新打开一个浏览器窗口,打开拼多多官网
browser.execute_script('window.open()')
browser.switch_to.window(browser.window_handles[2])
browser.get('https://www.pinduoduo.com/')print(browser.window_handles)#4.休眠3秒,切换到第一个窗口,也就是京东官网
time.sleep(3)
browser.switch_to.window(browser.window_handles[0])input()
运行结果:
#京东['D6D4DF09BC5DC02586AFE328CD9325D8']#京东,淘宝['D6D4DF09BC5DC02586AFE328CD9325D8', 'C0C35009783F322052AFE911854BA439']#京东,淘宝,拼多多['D6D4DF09BC5DC02586AFE328CD9325D8', 'C0C35009783F322052AFE911854BA439', 'A00B01BC4E9FD4420270E82FC7D03F1C']
这里首先访问了京东官网,然后调用了
execute_script
方法,这里传入
window.open
这个 JavaScript 语句新开启一个选项卡。接下来,我们想切换到该选项卡。这里调用
window_handles
属性获取当前开启的所有选项卡,返回的是选项卡的代号列表。要想切换选项卡,只需要调用
switch_to.window
方法即可,其中参数是选项卡的代号(
列表下标
)。这里我们将第二个选项卡代号传入,即跳转到第二个选项卡,接下来在第二个选项卡下打开一个新页面,然后切换回第一个选项卡重新调用 switch_to.window 方法,再执行其他操作即可。
- 前进,后退
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.jd.com/')
time.sleep(2)
browser.get('https://www.taobao.com/')
time.sleep(2)
browser.get('https://www.pinduoduo.com/')
time.sleep(2)
browser.back()
time.sleep(2)
browser.back()
time.sleep(2)
browser.forward()
time.sleep(2)
browser.forward()input()
上面代码执行逻辑顺序:
- 打开京东–》休眠2秒
- 打开淘宝–》休眠2秒
- 打开拼多多–》休眠2秒
- 后退到淘宝–》休眠2秒
- 后退到京东–》休眠2秒
- 前进到淘宝–》休眠2秒
- 前进到拼多多
5.10 Cookies
使用 Selenium,还可以方便地对 Cookies 进行操作,例如获取、添加、删除 Cookies 等
from selenium import webdriver
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.zhihu.com/explore')
print(browser.get_cookies())
browser.add_cookie({'name':'xxx', 'domain':'xxx', 'value':'germey'})
print(browser.get_cookies())
browser.delete_all_cookies()
print(browser.get_cookies())
运行结果:
5.11 延时等待
在 Selenium 中,get 方法会在网页框架加载结束后结束执行,此时如果获取 page_source,可能并不是浏览器完全加载完成的页面,如果某些页面有额外的 Ajax 请求,我们在网页源代码中也不一定能成功获取到。所以,这里需要延时等待一定时间,确保节点已经加载出来。
这里等待方式有两种:一种是隐式等待,一种是显式等待。
- 隐式等待(implicitly_wait 方法)
当查找节点而节点并没有立即出现的时候,隐式等待将等待一段时间再查找 DOM,默认的时间是 0。
from selenium import webdriver
browser = webdriver.Chrome()
browser.implicitly_wait(10)
browser.get('https://xxxxxx/')input= browser.find_element_by_class_name('xxxxxx')print(input)
- 显式等待(WebDriverWait 对象)
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
browser = webdriver.Chrome()
browser.get('https://www.taobao.com/')# 这里首先引入 WebDriverWait 这个对象,指定最长等待时间,然后调用它的 until 方法,传入等待条件 expected_conditions
wait = WebDriverWait(browser,10)# 在 10 秒内如果 ID 为 q 的节点(即搜索框)成功加载出来,就返回该节点;如果超过 10 秒还没有加载出来,就抛出异常input= wait.until(EC.presence_of_element_located((By.ID,'q')))# 如果 10 秒内它是可点击的,也就是成功加载出来了,就返回这个按钮节点;如果超过 10 秒还不可点击,也就是没有加载出来,就抛出异常
button = wait.until(EC.element_to_be_clickable((By.CSS_SELECTOR,'.btn-search')))print(input, button)
更多等待条件的参数及用法介绍可以参考官方文档:http://selenium-python.readthedocs.io/api.html#module-selenium.webdriver.support.expected_conditions。
5.12 CDP解决反屏蔽
现在很多网站都加上了对 Selenium 的检测,来防止一些爬虫的恶意爬取。即如果检测到有人在使用 Selenium 打开浏览器,那就直接屏蔽。
在大多数情况下,检测的基本原理是检测当前浏览器窗口下的 window.navigator 对象是否包含 webdriver 这个属性。因为在正常使用浏览器的情况下,这个属性是 undefined,然而一旦我们使用了 Selenium,Selenium 会给 window.navigator 设置 webdriver 属性。很多网站就通过 JavaScript 判断如果 webdriver 属性存在,那就直接屏蔽。
在 Selenium 中,我们可以使用
CDP
(即 Chrome Devtools-Protocol,Chrome 开发工具协议)来解决这个问题,通过它我们可以实现在每个页面刚加载的时候执行 JavaScript 代码,执行的 CDP 方法叫作 Page.addScriptToEvaluateOnNewDocument,然后传入上文的 JavaScript 代码即可,这样我们就可以在每次页面加载之前将 webdriver 属性置空了。另外,我们还可以加入几个选项来隐藏 WebDriver 提示条和自动化扩展信息,代码实现如下:
from selenium import webdriver
from selenium.webdriver import ChromeOptions
option = ChromeOptions()
option.add_experimental_option('excludeSwitches',['enable-automation'])
option.add_experimental_option('useAutomationExtension',False)
browser = webdriver.Chrome(options=option)
browser.execute_cdp_cmd('Page.addScriptToEvaluateOnNewDocument',{'source':'Object.defineProperty(navigator, "webdriver", {get: () => undefined})'})
browser.get('https://antispider1.scrape.center/')
5.13 无头模式
我们可以观察到,上面的案例在运行的时候,总会弹出一个浏览器窗口,虽然有助于观察页面爬取状况,但在有时候窗口弹来弹去也会形成一些干扰。
Chrome 浏览器从 60 版本已经支持了无头模式,即 Headless。无头模式在运行的时候不会再弹出浏览器窗口,减少了干扰,而且它减少了一些资源的加载,如图片等,所以也在一定程度上节省了资源加载时间和网络带宽。
我们可以借助于 ChromeOptions 来开启 Chrome Headless 模式,代码实现如下:
from selenium import webdriver
from selenium.webdriver import ChromeOptions
option = ChromeOptions()
option.add_argument('--headless')
browser = webdriver.Chrome(options=option)
browser.set_window_size(1366,768)
browser.get('https://www.baidu.com')print(browser.get_screenshot_as_file('preview.png'))
这里我们通过 ChromeOptions 的 add_argument 方法添加了一个参数 --headless,开启了无头模式。在无头模式下,我们最好设置一下窗口的大小,接着打开页面,最后我们调用 get_screenshot_as_file 方法输出了页面的截图。
运行代码之后,我们发现 Chrome 窗口就不会再弹出来了,代码依然正常运行,最后输出的页面如图所示。

版权归原作者 小孟技术栈 所有, 如有侵权,请联系我们删除。