
- 👏作者简介:大家好,我是爱敲代码的小黄,独角兽企业的Java开发工程师,CSDN博客专家,Java领域新星创作者
- 📝个人公众号:爱敲代码的小黄(回复 “技术书籍” 可获千本电子书籍)
- 📕系列专栏:Java设计模式、数据结构和算法、Kafka从入门到成神、Kafka从成神到升仙
- 📧如果文章知识点有错误的地方,请指正!和大家一起学习,一起进步👀
- 🔥如果感觉博主的文章还不错的话,请👍三连支持👍一下博主哦
- 🍂博主正在努力完成2022计划中:以梦为马,扬帆起航,2022追梦人

文章目录
往期推荐
Kafka从成神到成仙系列
- 【Kafka从成神到升仙系列 一】Kafka源码环境搭建
- 【Kafka从成神到升仙系列 二】生产者如何将消息放入到内存缓冲区
一、引言
初学一个技术,怎么了解该技术的源码至关重要。
对我而言,最佳的阅读源码的方式,那就是:不求甚解,观其大略
你如果进到庐山里头,二话不说,蹲下头来,弯下腰,就对着某棵树某棵小草猛研究而不是说先把庐山的整体脉络研究清楚了,那么你的学习方法肯定效率巨低而且特别痛苦。
最重要的还是慢慢地打击你的积极性,说我的学习怎么那么不 happy 啊,怎么那么没劲那,因为你的学习方法错了,大体读明白,先拿来用,用着用着,很多道理你就明白了。
先从整体上把关源码,再去扣一些细节问题。
举个简单的例子:
如果你刚接触 HashMap,你刚有兴趣去看其源码,在看 HashMap 的时候,有一个知识:当链表长度达到 8 之后,就变为了红黑树,小于 6 就变成了链表,当然,还和当前的长度有关。
这个时候,如果你去深究红黑树、为什么是 8 不是别的,又去查 泊松分布,最终会慢慢的搞死自己。
所以,正确的做法,我们先把这一部分给略过去,知道这个概念即可,等后面我们把整个庐山看完之后,再回过头抠细节。
当然,本章我们讲述 Kafka中的生产者怎么获取的元数据
二、Kafka为何不用 Netty
上篇文章我们讲述到,我们的 producer 会将消息发送至
RecordAccumulator
中,然后启动
Sender
线程
我们大概率可以猜测到,我们的
Sender
线程是和我们的
Broker
进行通信的,提到通信,不得不说一下
Netty
大家都知道,
Netty
是一个优秀的
I/O
框架,但
Kafka
在通信方面并没有采用
Netty
,让人比较难以理解
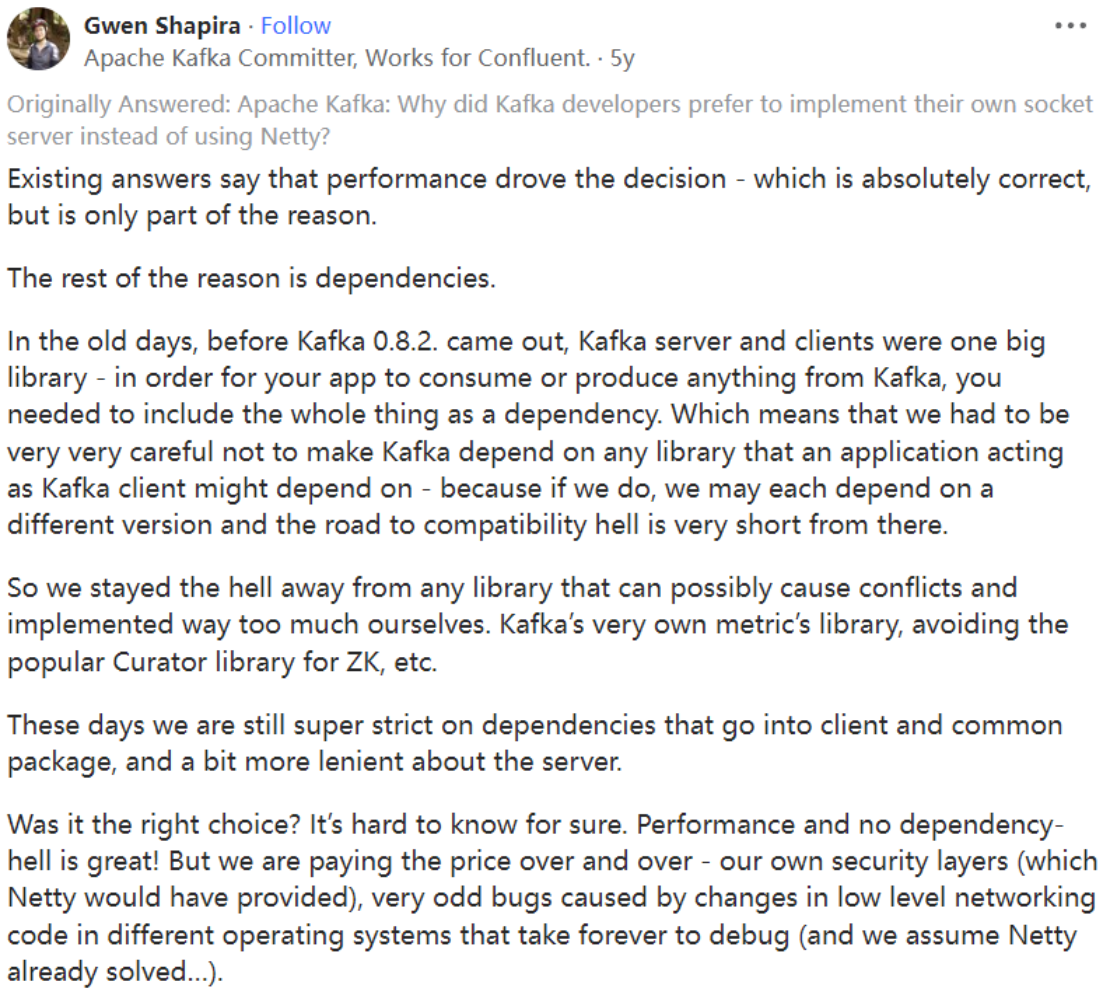
当然,博主也查到了关于
kafka
开发者的回答:
一共两个原因:
1、由于性能问题,kafka 的通信过程并不需要 netty 那么庞大的通信体系
2、kafka客户端原始时期,需要让用户将整个东西作为依赖项包含其内,如果引入了 netty,那么每个人依赖的版本号不同,将会产生巨大的兼容问题
3、kafka的安全层和一些另外的问题,需要 kafka 自己来解决,而这些烦恼的问题,netty 中已经解决了
博主感觉,极大概率由于历史原因,现在就算换成 netty,一些代码也不容易重构,更何况现在 kafka 自研的 I/O 通信模型反响还可以,所以 kafka 一直都没使用 netty 的想法。
三、元数据是什么
如果我们的
Sender
线程想要连接
Broker
,最大的一个环节就是获取
Broker
的元数据
而元数据的获取,是通过
Sender
线程来获取的
Sender 线程是一个不断轮询的线程,类似我们之前提到的 EventLoop 线程
我们首先解释一下 元数据(Metadata ) 是个什么东西:
// 这个类被 client 线程和后台 sender 所共享,它只保存了所有 topic 的部分数据,当我们请求一个它上面没有的 topic meta 时,它会通过发送 metadata update 来更新 meta 信息,// 如果 topic meta 过期策略是允许的,那么任何 topic 过期的话都会被从集合中移除,// 但是 consumer 是不允许 topic 过期的因为它明确地知道它需要管理哪些 topicpublicfinalclassMetadata{privatestaticfinalLogger log =LoggerFactory.getLogger(Metadata.class);publicstaticfinallongTOPIC_EXPIRY_MS=5*60*1000;privatestaticfinallongTOPIC_EXPIRY_NEEDS_UPDATE=-1L;privatefinallong refreshBackoffMs;// metadata 更新失败时,为避免频繁更新 meta,最小的间隔时间,默认 100msprivatefinallong metadataExpireMs;// metadata 的过期时间, 默认 60,000msprivateint version;// 每更新成功1次,version自增1,主要是用于判断 metadata 是否更新privatelong lastRefreshMs;// 最近一次更新时的时间(包含更新失败的情况)privatelong lastSuccessfulRefreshMs;// 最近一次成功更新的时间(如果每次都成功的话,与前面的值相等, 否则,lastSuccessulRefreshMs < lastRefreshMs)privateCluster cluster;// 集群中一些 topic 的信息privateboolean needUpdate;// 是都需要更新 metadata/* Topics with expiry time */privatefinalMap<String,Long> topics;// topic 与其过期时间的对应关系privatefinalList<Listener> listeners;// 事件监控者privatefinalClusterResourceListeners clusterResourceListeners;//当接收到 metadata 更新时, ClusterResourceListeners的列表privateboolean needMetadataForAllTopics;// 是否强制更新所有的 metadataprivatefinalboolean topicExpiryEnabled;// 默认为 true, Producer 会定时移除过期的 topic,consumer 则不会移除}
如果你感觉参数有点多,难以看懂,就记住一个
cluster
和
needUpdate
就好了,其他的不太重要
我们进一步看下
cluster
的参数:主要是 broker、topic、partition 的一些对应信息
publicfinalclassCluster{// 从命名直接就看出了各个变量的用途privatefinalboolean isBootstrapConfigured;privatefinalList<Node> nodes;// node 列表privatefinalSet<String> unauthorizedTopics;// 未认证的 topic 列表privatefinalSet<String> internalTopics;// 内置的 topic 列表privatefinalMap<TopicPartition,PartitionInfo> partitionsByTopicPartition;// partition 的详细信息privatefinalMap<String,List<PartitionInfo>> partitionsByTopic;// topic 与 partition 的对应关系privatefinalMap<String,List<PartitionInfo>> availablePartitionsByTopic;// 可用(leader 不为 null)的 topic 与 partition 的对应关系privatefinalMap<Integer,List<PartitionInfo>> partitionsByNode;// node 与 partition 的对应关系privatefinalMap<Integer,Node> nodesById;// node 与 id 的对应关系privatefinalClusterResource clusterResource;}// org.apache.kafka.common.PartitionInfo// topic-partition: 包含 topic、partition、leader、replicas、isrpublicclassPartitionInfo{privatefinalString topic;privatefinalint partition;privatefinalNode leader;privatefinalNode[] replicas;privatefinalNode[] inSyncReplicas;}
四、元数据的请求及获取
1、Producer 元数据获取
我们这块的元数据已经了解的差不多了,我们来看看元数据是怎么请求及获取的
当我们第一次发送
Kafka
消息时,会有一个
waitOnMetadata(record.topic(), this.maxBlockTimeMs)
方法
/**
* 第一次发送消息时,这里会判断当前是否拿到了元数据
* 如果没有拿到元数据信息,这里会堵塞循环并唤醒 Sender 线程,让其帮忙更新元数据
*/long waitedOnMetadataMs =waitOnMetadata(record.topic(),this.maxBlockTimeMs);// 等待元数据的更新privatelongwaitOnMetadata(String topic,long maxWaitMs)throwsInterruptedException{// 判断是否有元数据,没有的话,则一直循环堵塞while(metadata.fetch().partitionsForTopic(topic)==null){int version = metadata.requestUpdate();// 唤醒我们的 Sender 线程,让其更新元数据
sender.wakeup();
metadata.awaitUpdate(version, remainingWaitMs);}return time.milliseconds()- begin;}
这里如同我们的注释所说,会唤醒我们的
Sender
线程,让其帮忙更新我们的
Metadata
2、Sender 获取元数据
2.1 第一次 poll 调用
当
Sender
线程收到唤醒时,第一轮直接调用
this.client.poll(pollTimeout, now)
方法,如下:
voidrun(long now){// 获取元数据中的 Cluster 信息Cluster cluster = metadata.fetch();this.client.poll(pollTimeout, now);}publicList<ClientResponse>poll(long timeout,long now){// 判断是否需要更新 metadata,如果需要就更新long metadataTimeout = metadataUpdater.maybeUpdate(now);try{this.selector.poll(Utils.min(timeout, metadataTimeout, requestTimeoutMs));}}
我们看一下
metadataUpdater.maybeUpdate
做了什么
@OverridepubliclongmaybeUpdate(long now){// 根据当前更新的时间判断是否需要更新long timeToNextMetadataUpdate = metadata.timeToNextUpdate(now);long timeToNextReconnectAttempt =Math.max(this.lastNoNodeAvailableMs + metadata.refreshBackoff()- now,0);long waitForMetadataFetch =this.metadataFetchInProgress ?Integer.MAX_VALUE:0;long metadataTimeout =Math.max(Math.max(timeToNextMetadataUpdate, timeToNextReconnectAttempt),
waitForMetadataFetch);if(metadataTimeout ==0){// 选择一个当前链接建立最少的nodeNode node =leastLoadedNode(now);// 更新元数据maybeUpdate(now, node);}return metadataTimeout;}// 判断当前是否可以发送请求,可以的话将 metadata 请求加入到发送列表中privatevoidmaybeUpdate(long now,Node node){String nodeConnectionId = node.idString();// 通道是否已经准备完毕 if(canSendRequest(nodeConnectionId)){this.metadataFetchInProgress =true;MetadataRequest metadataRequest;if(metadata.needMetadataForAllTopics())
metadataRequest =MetadataRequest.allTopics();else
metadataRequest =newMetadataRequest(newArrayList<>(metadata.topics()));ClientRequest clientRequest =request(now, nodeConnectionId, metadataRequest);doSend(clientRequest, now);}elseif(connectionStates.canConnect(nodeConnectionId, now)){// 初始化链接initiateConnect(node, now);}else{this.lastNoNodeAvailableMs = now;}}}// 主要做的初始化与Broker 的连接privatevoidinitiateConnect(Node node,long now){String nodeConnectionId = node.idString();try{this.connectionStates.connecting(nodeConnectionId, now);
selector.connect(nodeConnectionId,newInetSocketAddress(node.host(), node.port()),this.socketSendBuffer,this.socketReceiveBuffer);}}
这里会进入一个
selector.connect
方法,在这个里面进行与
Broker
的连接
publicvoidconnect(String id,InetSocketAddress address,int sendBufferSize,int receiveBufferSize)throwsIOException{// 经典的 NIO 的实现(之前netty中聊过) SocketChannel socketChannel =SocketChannel.open();
socketChannel.configureBlocking(false);Socket socket = socketChannel.socket();
socket.setKeepAlive(true);// 发送的bufferif(sendBufferSize !=Selectable.USE_DEFAULT_BUFFER_SIZE)
socket.setSendBufferSize(sendBufferSize);// 接受的bufferif(receiveBufferSize !=Selectable.USE_DEFAULT_BUFFER_SIZE)
socket.setReceiveBufferSize(receiveBufferSize);// 设置TCP的状态
socket.setTcpNoDelay(true);boolean connected;try{// 直接连接服务端(这也是netty讲过的)
connected = socketChannel.connect(address);}catch(UnresolvedAddressException e){
socketChannel.close();thrownewIOException("Can't resolve address: "+ address, e);}// 注册接受事件(这个事件只能客户端注册)SelectionKey key = socketChannel.register(nioSelector,SelectionKey.OP_CONNECT);}
2.2 第二次 poll 调用
这个时候已经与我们的
Broker
建立了连接,我们下一步要找在哪里发送的请求,也就是
write
方法。
当我们第二次调用
poll
方法时, 再次到达
maybeUpdate
方法时,这个时候我们会走
canSendRequest(nodeConnectionId)
分支
// 由于上述我们已经建立了连接,这里已经可以发送了if(canSendRequest(nodeConnectionId)){this.metadataFetchInProgress =true;MetadataRequest metadataRequest;if(metadata.needMetadataForAllTopics())
metadataRequest =MetadataRequest.allTopics();else
metadataRequest =newMetadataRequest(newArrayList<>(metadata.topics()));ClientRequest clientRequest =request(now, nodeConnectionId, metadataRequest);doSend(clientRequest, now);}
**一开始博主以为这里的
doSend
已经完成了发送,实际上并没有,大家一定要注意这一点**
privatevoiddoSend(ClientRequest request,long now){
request.setSendTimeMs(now);this.inFlightRequests.add(request);
selector.send(request.request());}publicvoidsend(Send send){KafkaChannel channel =channelOrFail(send.destination());this.send = send;this.transportLayer.addInterestOps(SelectionKey.OP_WRITE);}
这里的
doSend
主要将我们本次请求放在
inFlight
这个组件里面(
inFlight:主要控制当前发送的请求量
)
另外,这里注册了一个
SelectionKey.OP_WRITE
事件,这个我们之前
Netty
大结局时讲过,有兴趣的可以去看一下
这里简单说一下,注册了
SelectionKey.OP_WRITE
事件,当内核的缓存区有空闲时,会触发该事件。
当注册完事件后,我们会调用
this.selector.poll(Utils.min(timeout, metadataTimeout, requestTimeoutMs))
方法,正式将我们的请求发送至
Broker
这里当前所有准备好的
key
拿出来,执行
pollSelectionKeys
去执行每一个
key
publicvoidpoll(long timeout)throwsIOException{/* check ready keys */long startSelect = time.nanoseconds();// 执行 nioSelector.selectNow() 方法,得到所有触发的 keyint readyKeys =select(timeout);long endSelect = time.nanoseconds();
currentTimeNanos = endSelect;this.sensors.selectTime.record(endSelect - startSelect, time.milliseconds());if(readyKeys >0||!immediatelyConnectedKeys.isEmpty()){pollSelectionKeys(this.nioSelector.selectedKeys(),false);pollSelectionKeys(immediatelyConnectedKeys,true);}}
循环去遍历每一个
key
,由于我们前面注册了
OP_WRITE
,这里一定有一个写的
key
,通过
channel.write()
方法写入到内核并发送至服务端
privatevoidpollSelectionKeys(Iterable<SelectionKey> selectionKeys,boolean isImmediatelyConnected){Iterator<SelectionKey> iterator = selectionKeys.iterator();while(iterator.hasNext()){SelectionKey key = iterator.next();
iterator.remove();KafkaChannel channel =channel(key);try{if(channel.ready()&& key.isWritable()){Send send = channel.write();if(send !=null){this.completedSends.add(send);this.sensors.recordBytesSent(channel.id(), send.size());}}}
2.3 第三次 poll 调用
当我们第三次调用
poll
时,这个时候我们发送的请求的响应回来了
// 处理响应long updatedNow =this.time.milliseconds();List<ClientResponse> responses =newArrayList<>();// 处理 inFlight 组件handleCompletedSends(responses, updatedNow);// 处理 metadatahandleCompletedReceives(responses, updatedNow);// 处理断开的连接handleDisconnections(responses, updatedNow);// 记录任何新完成的连接handleConnections();// 处理超时的连接handleTimedOutRequests(responses, updatedNow);
其他的我们暂时不研究,主要看
handleCompletedReceives
对于元数据的处理
privatevoidhandleCompletedReceives(List<ClientResponse> responses,long now){for(NetworkReceive receive :this.selector.completedReceives()){String source = receive.source();ClientRequest req = inFlightRequests.completeNext(source);Struct body =parseResponse(receive.payload(), req.request().header());if(!metadataUpdater.maybeHandleCompletedReceive(req, now, body))
responses.add(newClientResponse(req, now,false, body));}}// 如果当前的是 metadata 响应,则更新其元数据publicbooleanmaybeHandleCompletedReceive(ClientRequest req,long now,Struct body){short apiKey = req.request().header().apiKey();if(apiKey ==ApiKeys.METADATA.id && req.isInitiatedByNetworkClient()){handleResponse(req.request().header(), body, now);returntrue;}returnfalse;}// 拿到当前响应里面的各种信息,进行封装保存privatevoidhandleResponse(RequestHeader header,Struct body,long now){this.metadataFetchInProgress =false;MetadataResponse response =newMetadataResponse(body);Cluster cluster = response.cluster();// check if any topics metadata failed to get updatedMap<String,Errors> errors = response.errors();if(cluster.nodes().size()>0){this.metadata.update(cluster, now);}else{this.metadata.failedUpdate(now);}}
这里可以给大家看一下题主拉取的元数据的信息
{"brokers":[{"node_id":"2","host":"12.23.14.13","port":"9192","rack":"null"},{"node_id":"1","host":"12.23.14.14","port":"9192","rack":"null"}],"controller_id":"2","topic_metadata":[{"topic_error_code":"0","topic":"activity_test","is_internal":"false","partition_metadata":[{"partition_error_code":"0","partition_id":"1","leader":"1","replicas":["1","2"],"isr":["1","2"]},{"partition_error_code":"0","partition_id":"0","leader":"2","replicas":["2","1"],"isr":["2","1"]}]}]}
到这里,我们的元数据正式拿到并封装到我们的
Metadata
中
然后我们的
Prodecer
就可以拿到
Metadata
的信息,进行后续业务逻辑
3、验证
我们口说无凭,利用代码来验证下真正的流程逻辑

我们在每一个流程里面都加了相应的日志代码,如果我们的验证是没有问题的,那么输出的日志也应该按照我们预想的一样
启动我们的程序:

我们可以明显的看到,程序的逻辑符合预计的执行
Producer堵塞,唤醒Sender线程让其更新MetadataSender第一次调用poll方法,初始化与Broker的连接Sender第二次调用poll方法,向Selector注册写事件并将请求发送到BrokerSender第三次调用poll方法,处理元数据的响应信息Producer不阻塞,Sender已更新完元数据信息,继续执行其业务逻辑
五、总结
本章主要讲解了:
kafka为什么不用Netty的原因Metadata是什么Metadata的请求和获取 -Producer的堵塞与唤醒- 初始化Broker的连接- 注册写事件并发送请求至Broker- 接受响应处理响应的Metadata信息
下一章我们将会更新
Sender
如何拉取
RecordAccumulator
的数据并将其发送至
Broker
喜欢
kafka
的可以点个关注吆,后续会继续更新其源码文章。
我是爱敲代码的小黄,我们下次再见。
版权归原作者 爱敲代码的小黄 所有, 如有侵权,请联系我们删除。