
一:概述
并行程序的执行速度在很大程度上取决于程序的资源需求与硬件的资源限制。在几乎所有并行编程模型中,管理并行代码与硬件资源约束之间的相互影响对于实现高性能非常重要的。这是一种实用的技能,需要对硬件体系结构有深刻理解,并需要在(为高性能设计的)并行编程模型中不断练习。
到目前为止,我们已经了解了GPU架构的各个方面及其对性能的影响。在前面的CUDA编程04 - GPU计算架构和线程调度中,我们了解了GPU的计算架构以及相关的性能考量因素,例如控制分叉(control divergence)和占用率(occupancy)。在CUDA编程05 - GPU内存架构和数据局部性中,我们了解了GPU的片上存储器架构和使用共享内存来提高程序性能。在本文中,我们将简要介绍片外内存(DRAM)架构,并讨论相关的性能考量因素,如内存合并和内存访问延迟隐藏。然后,我们将讨论一种重要的优化类型—线程粗粒度化(thread granularity coarsening),最后,我们总结一个常见的性能优化清单,并将该清单将作为优化的指南。
在不同的应用中,不同的体系结构约束可能占主导地位并成为限制性能的主要因素,这些主要的限制因素通常被称为瓶颈。通过将一种资源的使用转换为另一种资源的使用,通常可以显著提高应用程序在特定CUDA设备上的性能。如果在应该策略之前,资源限制是主要的限制因素,并且应用该策略之后不会对并行程序性能产生负面影响,那么该策略就很有效。如果不理解瓶颈在哪里,性能调优就只能是猜测,看似合理的策略也可能不会增强性能。
二:内存合并(memory burst access)
CUDA内核性能最重要的因素之一是访问全局内存,而全局内存的带宽有限,可能成为瓶颈。CUDA应用程序广泛利用数据并行性。自然地,CUDA应用程序倾向于在短时间内处理大量来自全局内存的数据。在前面CUDA编程05 - GPU内存架构和数据局部性文章中,我们研究了利用共享内存的分块技术,以减少每个线程块中的线程从全局内存访问的数据总量。在本章中,我们将进一步讨论内存合并技术,以有效地在全局内存和共享内存或寄存器之间移动数据。内存合并技术通常与分块技术结合使用,以使CUDA设备通过有效利用全局内存带宽来达到其性能潜力。
CUDA设备的全局内存是通过DRAM实现的。数据位存储在小电容的DRAM单元中,其中微小电荷的存在或缺失区分了1和0值。从DRAM单元读取数据需要小电容使用其微小电荷驱动一条高电容线路,连接到传感器并触发传感器的检测机制,以确定电容器中是否存在足够的电荷以符合“1”的标准。这个过程在现代DRAM芯片中需要几十纳秒(详见“为什么DRAM如此慢?”)。这与现代计算设备的亚纳秒时钟周期时间形成鲜明对比。由于这个过程相对于所需的数据访问速度非常慢(每字节亚纳秒访问),现代DRAM设计采用并行性来提高数据访问速率,通常称为内存访问吞吐量。
每次访问DRAM位置时,会访问包括请求位置在内的一系列连续位置。每个DRAM芯片中提供了许多传感器,它们都是并行工作的。每个传感器感知这些连续位置中一个比特的内容。一旦被传感器检测到,来自所有这些连续位置的数据可以以高速传输到处理器。这些被访问和传输的连续位置称为DRAM-burst。如果应用程序集中使用这些 busrt 中的数据,DRAM可以以比真正随机访问位置时更高的速率提供数据。
认识到现代DRAM的 burst 组织,当前的CUDA设备采用一种技术,使程序员能够通过将线程的内存访问组织成有利的模式来实现高全局内存访问效率。这项技术利用了这样一个事实:在任何给定时刻,warp中的线程执行相同的指令。当warp中的所有线程执行加载指令时,硬件会检测它们是否访问连续的全局内存位置。换句话说,当warp中的所有线程访问连续的全局内存位置时,达到了最有利的访问模式。在这种情况下,硬件将所有这些访问合并或聚合为对连续DRAM位置的集中访问。例如,对于warp的给定加载指令,如果线程0访问全局内存位置X,线程1访问位置X + 1,线程2访问位置X + 2,依此类推,所有这些访问将在访问DRAM时被聚合或合并为对连续位置的单个请求。这样的聚合访问允许DRAM以busrt方式访问数据。
为了理解如何有效利用合并硬件,我们需要回顾访问 C 语言多维数组元素时内存地址的形成。回想 CUDA编程03 - 多维数据并行(在此复制为下图6.1以便于参考),C 和 CUDA 中的多维数组元素按照行主序约定放置在线性寻址的内存空间中。回想一下,行主序一词(row-major)指的是数据的放置方式保持了行的结构:同一行中的所有相邻元素被放置在地址空间中的连续位置。在图 6.1 中,行 0 的四个元素首先按其在行中的出现顺序放置。接着放置行 1 的元素,然后是行 2 的元素,最后是行 3 的元素。应该清楚的是,尽管 M0,0 和 M1,0 在二维矩阵中看似连续,但它们在线性寻址的内存中相隔四个位置。

假设图6.1中的多维数组是用于矩阵乘法的第二个输入矩阵。在这种情况下,分配给连续输出元素的warp中的连续线程将遍历该输入矩阵的连续列。图6.2的左上部分显示了此计算的代码,右上部分显示了访问模式的逻辑视图:连续线程遍历连续列。通过检查代码可以看出,对M的访问可以合并。数组M的索引为k*Width+col。变量k和Width在warp中的所有线程中具有相同的值。变量col定义为blockIdx.x*blockDim.x+threadIdx.x,这意味着连续线程(具有连续的threadIdx.x值)将具有连续的col值,因此将访问M的连续元素。
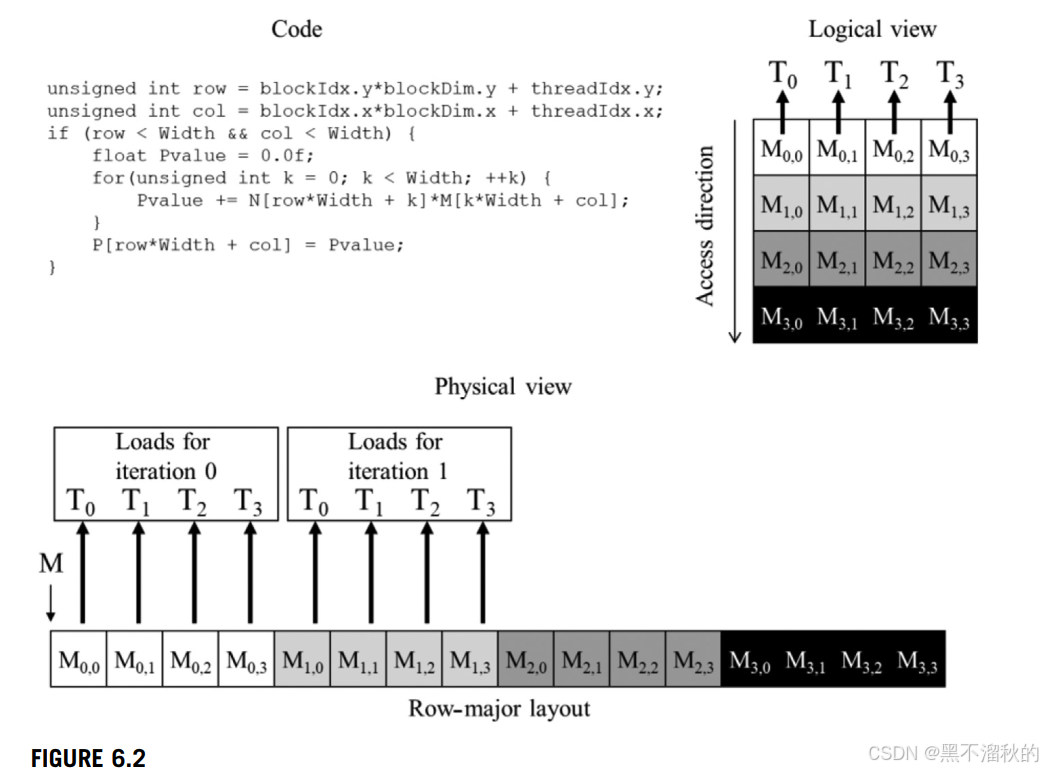
图6.2的底部显示了访问模式的物理视图。在迭代0中,连续的线程将访问内存中相邻的行0中的连续元素,如图6.2中的“迭代0的加载”所示。在迭代1中,连续的线程将访问内存中相邻的行1中的连续元素,如图6.2中的“迭代1的加载”所示。这个过程对所有行继续进行。正如我们所看到的,线程在此过程中形成的内存访问模式是一个可以合并的有利模式。实际上,在我们迄今为止实现的所有核函数中,我们的内存访问自然地进行了合并。
现在假设矩阵是以列优先顺序存储的,而不是行优先顺序。这可能有各种原因。例如,我们可能在乘以一个以行优先顺序存储的矩阵的转置。在线性代数中,我们常常需要使用矩阵的原始形式和转置形式。最好避免创建和存储这两种形式。一种常见的做法是以一种形式创建矩阵,比如原始形式。当需要转置形式时,可以通过交换行和列索引的角色来访问原始形式的元素。在C语言中,这相当于将转置矩阵视为原始矩阵的列优先布局。
图6.3说明了当矩阵以列优先顺序存储时,连续线程如何遍历连续列。图6.3的左上部分显示了代码,右上部分显示了内存访问的逻辑视图。程序仍然试图让每个线程访问矩阵M的一列。通过检查代码,可以看出对M的访问不利于合并。数组M的索引为col*Width+k。与之前一样,col被定义为blockIdx.x*blockDim.x+threadIdx.x,这意味着连续线程(具有连续的threadIdx.x值)将具有连续的col值。然而,在M的索引中,col乘以Width,这意味着连续线程将访问相隔Width的M元素。因此,这些访问不利于合并。
在图6.3的底部部分,我们可以看到内存访问的物理视图与图6.2中的视图截然不同。在迭代0中,连续线程将逻辑上访问第0行的连续元素,但由于列优先布局,这些元素在内存中并不相邻。这些加载在图6.3中被标记为“迭代0的加载”。同样,在迭代1中,连续线程将访问第1行的连续元素,这些元素在内存中也不相邻。对于一个现实的矩阵,通常每个维度中有数百甚至数千个元素。M相邻
标签:
CUDA
本文转载自: https://blog.csdn.net/zg260/article/details/141113654
版权归原作者 黑不溜秋的 所有, 如有侵权,请联系我们删除。
版权归原作者 黑不溜秋的 所有, 如有侵权,请联系我们删除。