
在k8s上 Prometheus(普罗米修斯) 监控,需要部署各种组件,比如Prometheus、Alertmanager、Grafana。同时各个组件的配置文件也是需要到处各个配置,Prometheus配置监控服务时,你还要知道各个监控服务的地址,地址换了还需要更新, 实在是麻烦。而今天的主角 Prometheus Operator 使用自定义资源的方式来简化Prometheus、Alertmanager配置, 实现自动化部署、自动化服务发现、轻松配置配置等功能。下面我们来一起看看吧。
Operator
Operator
是由CoreOS公司开发的,用来扩展 Kubernetes API,特定的应用程序控制器,它用来创建、配置和管理复杂的有状态应用,如数据库、缓存和监控系统。
Operator
基于 Kubernetes 的资源和控制器概念之上构建,但同时又包含了应用程序特定的一些专业知识,比如创建一个数据库的
Operator
,则必须对创建的数据库的各种运维方式非常了解,创建
Operator
的关键是
CRD
(自定义资源)的设计。
CRD是对 Kubernetes API 的扩展,Kubernetes 中的每个资源都是一个 API 对象的集合,例如我们在YAML文件里定义的那些
spec都是对 Kubernetes 中的资源对象的定义,所有的自定义资源可以跟 Kubernetes 中内建的资源一样使用 kubectl 操作。
Operator
是将运维人员对软件操作的知识给代码化,同时利用 Kubernetes 强大的抽象来管理大规模的软件应用。目前
CoreOS
官方提供了几种
Operator
的实现,其中就包括我们今天的主角:
Prometheus Operator
,
Operator
的核心实现就是基于 Kubernetes 的以下两个概念:
- 资源:对象的状态定义
- 控制器:观测、分析和行动,以调节资源的分布
当然我们如果有对应的需求也完全可以自己去实现一个
Operator
,接下来我们就来给大家详细介绍下
Prometheus-Operator
的使用方法。
介绍
Prometheus Operator 提供Kubernetes 原生部署和管理Prometheus和相关的监控组件。该项目的是简化和自动化配置Prometheus的监控Kubernetes集群。
Prometheus Operator 包括但不限于以下功能:
- Kubernetes自定义资源:使用Kubernetes自定义资源来部署和管理Prometheus、Alertmanager和相关组件。
- 简化的部署配置:从本地Kubernetes资源配置Prometheus的基本功能,如版本、持久性、保留策略和副本。
- Prometheus Target 配置:根据熟悉的Kubernetes标签查询自动生成监控目标配置;无需学习Prometheus专用的配置语言。
Prometheus Operator vs. kube-prometheus vs. community helm chart
- Prometheus Operator:使用Kubernetes自定义资源简化Prometheus、Alertmanager和相关监视组件的部署和配置。
- kube-prometheus:kube-prometheus提供了基于Prometheus和Prometheus Operator的完整集群监视堆栈的示例配置。这包括部署多个Prometheus和Alertmanager实例、用于收集节点指标的node_exporter等指标exporte、将Prometheus链接到各种指标端点的临时目标配置,以及用于通知集群中潜在问题的示例警报规则。
- helm chart:这prometheus-community/helm-charts 提供了一个类似于Prometheus Operator的功能集。该helm chart由Prometheus 社区维护。
Prometheus Operator CRD介绍
Prometheus Operator 的目标是尽可能容易地在Kubernetes上运行Prometheus,同时保留Kubernetes本地配置选项。
本指南将向您展示如何部署Prometheus操作符、设置Prometheus实例以及为一个示例应用程序配置度量收集。
Prometheus Operator 要求使用 Kubernetes 版本 v1.16.x 及以上.
Prometheus Operator 在Kubernetes中引入了自定义资源,以声明Prometheus和Alertmanager集群以及Prometheus配置的理想状态。prometheus-operator的使用,基本是如何操作下述的CRD对象。:
Prometheus: 对prometheus-server的部署ServiceMonitor: 对service监控对象的抽象;它声明性地指定了应该如何监控Kubernetes services 组。Operator 根据API服务器中对象的当前状态自动生成Prometheus scrape配置(scrape_configs)。PodMonitor: 对pod监控对象的抽象;它声明性地指定了应该如何监控一组pod。Operator 根据API服务器中对象的当前状态自动生成Prometheus scrape配置。PrometheusRule: 对prometheus报警规则的抽象;其定义了一组期望的Prometheus 警报和/或记录规则。Operator 生成一个Prometheus实例可以使用的规则文件。- **
Alertmanager**:它定义了所需的Alertmanager部署。 - **
AlertmanagerConfig**: 它以声明方式指定Alertmanager配置的子部分,允许将警报路由到自定义接收器,并设置禁止规则。 - **
ThanosRuler**: 它定义了所需的Thanos 规则部署 - **
Probe**: 它以声明方式指定应该如何监视入侵组或静态目标组。操作员根据定义自动生成普罗米修斯刮削配置。
这
Prometheus
资源声明性地描述了Prometheus部署的期望状态,而
ServiceMonitor
和
PodMonitor
资源描述了Prometheus监控的
targets
。
Prometheus Operator 架构图

上图是
Prometheus-Operator
官方提供的架构图,其中
Operator
是最核心的部分,作为一个控制器,他会去创建
Prometheus
、
ServiceMonitor
、
AlertManager
以及
PrometheusRule
4个
CRD
资源对象,然后会一直监控并维持这4个资源对象的状态。
其中创建的
prometheus
这种资源对象就是作为
Prometheus Server
存在,而
ServiceMonitor
就是
exporter
的各种抽象,
exporter
前面我们已经学习了,是用来提供专门提供
metrics
数据接口的工具,
Prometheus
就是通过
ServiceMonitor
提供的
metrics
数据接口去 pull 数据的,当然
alertmanager
这种资源对象就是对应的
AlertManager
的抽象,而
PrometheusRule
是用来被
Prometheus
实例使用的报警规则文件。
这样我们要在集群中监控什么数据,就变成了直接去操作 Kubernetes 集群的资源对象了,是不是方便很多了。上图中的 Service 和 ServiceMonitor 都是 Kubernetes 的资源,一个 ServiceMonitor 可以通过 labelSelector 的方式去匹配一类 Service,Prometheus 也可以通过 labelSelector 去匹配多个ServiceMonitor。
开始使用
我们使用 kube-prometheus 来部署 Prometheus Operator,因为他不仅提供了 Prometheus Operator 还提供 Alertmanager、Grafana,node_exporter等组件
获得kube-prometheus项目
从GitHub克隆kube-prometheus
git clone https://github.com/prometheus-operator/kube-prometheus.git
或者下载当前主分支的zip文件并提取其内容:
github . com/Prometheus-operator/kube-Prometheus/archive/main . zip
一旦你下载完成,你就可以进入项目的根目录。
部署 kube-prometheus
# Create the namespace and CRDs, and then wait for them to be availble before creating the remaining resources
kubectl create -f manifests/setup
# Wait until the "servicemonitors" CRD is created. The message "No resources found" means success in this context.
until kubectl get servicemonitors --all-namespaces ; do date; sleep 1; echo ""; done
kubectl create -f manifests/
我们首先创建namespace和CustomResourceDefinitions,以避免在部署监控组件时出现竞争情况。或者,可以用一个命令应用两个文件夹中的资源
kubectl create -f manifests/setup -f manifests
,但是可能需要多次运行该命令才能成功创建所有组件。
查看CRD类型:
[root@a1 ~]# kubectl get crd |grep coreos
alertmanagerconfigs.monitoring.coreos.com 2022-08-11T01:37:54Z
alertmanagers.monitoring.coreos.com 2022-08-11T01:37:54Z
podmonitors.monitoring.coreos.com 2022-08-11T01:37:54Z
probes.monitoring.coreos.com 2022-08-11T01:37:54Z
prometheuses.monitoring.coreos.com 2022-08-11T01:37:54Z
prometheusrules.monitoring.coreos.com 2022-08-11T01:37:54Z
servicemonitors.monitoring.coreos.com 2022-08-11T01:37:54Z
thanosrulers.monitoring.coreos.com 2022-08-11T01:37:54Z
查看特定CRD类型下的实例:
[root@a1 ~]# kubectl get prometheuses -n monitoring
NAME VERSION REPLICAS AGE
k8s 2.32.1 2 97d
[root@a1 ~]# kubectl get servicemonitors -n monitoring
NAME AGE
alertmanager-main 97d
blackbox-exporter 97d
coredns 97d
example-app 92d
grafana 97d
kube-apiserver 97d
kube-controller-manager 97d
kube-scheduler 97d
kube-state-metrics 97d
kubelet 97d
node-exporter 97d
prometheus-adapter 97d
prometheus-k8s 97d
prometheus-operator 97d
查看创建的 Service:
kubectl get svc -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanager-main ClusterIP 10.110.204.224 <none> 9093/TCP 23h
alertmanager-operated ClusterIP None <none> 9093/TCP,6783/TCP 23h
grafana ClusterIP 10.98.191.31 <none> 3000/TCP 23h
kube-state-metrics ClusterIP None <none> 8443/TCP,9443/TCP 23h
node-exporter ClusterIP None <none> 9100/TCP 23h
prometheus-adapter ClusterIP 10.107.201.172 <none> 443/TCP 23h
prometheus-k8s ClusterIP 10.107.105.53 <none> 9090/TCP 23h
prometheus-operated ClusterIP None <none> 9090/TCP 23h
prometheus-operator ClusterIP None <none> 8080/TCP 23h
可以看到上面针对 grafana 和 prometheus 都创建了一个类型为 ClusterIP 的 Service,当然如果我们想要在外网访问这两个服务的话可以通过创建对应的 Ingress 对象或者使用 NodePort 类型的 Service。
访问Prometheus
可以使用以下工具快速访问Prometheus、Alertmanager和Grafana仪表板
kubectl port-forward
通过以下命令运行快速入门后。
kubectl --namespace monitoring port-forward svc/prometheus-k8s 9090
在浏览器打开Prometheus localhost:9090 .
查看 警报
http://localhost:9090/alerts
和 规则
http://localhost:9090/rules
带有预配置规则和警报的页面!
这个普罗米修斯应该监控你的Kubernetes集群,并确保在它出现问题时提醒你。
对于您自己的应用程序,我们建议运行一个或多个其他实例。
访问Alertmanager
kubectl --namespace monitoring port-forward svc/alertmanager-main 9093
访问Grafana
kubectl --namespace monitoring port-forward svc/grafana 3000
打开Grafana 本地主机:3000在您的浏览器中。
您可以使用用户名登录
admin
和密码
admin
.
移除kube-prometheus
如果您已经完成了kube-prometheus和prometheus Operator 的实验,您可以通过运行以下命令来简单地拆除部署:
kubectl delete --ignore-not-found=true -f manifests/ -f manifests/setup
配置
安装完成后,我们就可以通过去访问上面的两个服务了,比如查看 prometheus 的 service-discovery页面:

我们可以看到大部分的配置都是正常的,只有两三个没有管理到对应的监控目标,比如 kube-controller-manager 和 kube-scheduler 这两个系统组件,这就和 ServiceMonitor 的定义有关系了,我们先来查看下 kube-scheduler 组件对应的 ServiceMonitor 资源的定义:(prometheus-serviceMonitorKubeScheduler.yaml)
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
labels:
k8s-app: kube-scheduler
name: kube-scheduler
namespace: monitoring
spec:
endpoints:
- bearerTokenFile: /var/run/secrets/kubernetes.io/serviceaccount/token
interval: 30s
port: https-metrics
scheme: https
tlsConfig:
insecureSkipVerify: true
jobLabel: app.kubernetes.io/name
namespaceSelector:
matchNames:
- kube-system
selector:
matchLabels:
app.kubernetes.io/name: kube-scheduler
上面是一个典型的 ServiceMonitor 资源文件的声明方式,上面我们通过
selector.matchLabels
在 kube-system 这个命名空间下面匹配具有
app.kubernetes.io/name=kube-scheduler
这样的 Service,但是我们系统中根本就没有对应的 Service,所以我们需要手动创建一个 Service:(prometheus-kubeSchedulerService.yaml)
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-scheduler
labels:
app.kubernetes.io/name: kube-controller-manager
spec:
selector:
component: kube-controller-manager
ports:
- name: https-metrics
port: 10257
targetPort: 10257
protocol: TCP
其中最重要的是上面 labels 和 selector 部分,labels 区域的配置必须和我们上面的 ServiceMonitor 对象中的 selector 保持一致,
selector
下面配置的是
component=kube-scheduler
,为什么会是这个 label 标签呢,我们可以去 describe 下 kube-scheduelr 这个 Pod:
$ kubectl describe pod kube-scheduler-master -n kube-system
Name: kube-scheduler-master
Namespace: kube-system
Node: master/10.151.30.57
Start Time: Sun, 05 Aug 2018 18:13:32 +0800
Labels: component=kube-scheduler
tier=control-plane
......
创建完成后,隔一小会儿后去 prometheus 查看 targets 下面 kube-scheduler 的状态:

我们可以看到现在已经发现了 target,但是抓取数据结果出错了,这个错误是因为我们集群是使用 kubeadm 搭建的,其中 kube-scheduler 默认是绑定在
127.0.0.1
上面的,而上面我们这个地方是想通过节点的 IP 去访问,所以访问被拒绝了,我们只要把 kube-scheduler 绑定的地址更改成
0.0.0.0
即可满足要求,由于 kube-scheduler 是以静态 Pod 的形式运行在集群中的,所以我们只需要更改静态 Pod 目录下面对应的 YAML 文件即可:
$ ls /etc/kubernetes/manifests/
etcd.yaml kube-apiserver.yaml kube-controller-manager.yaml kube-scheduler.yaml
将 kube-scheduler.yaml 文件中
-command
的
--address
地址更改成
0.0.0.0
:
修改完成后我们将该文件从当前文件夹中移除,隔一会儿再移回该目录,就可以自动更新了,然后再去看 prometheus 中 kube-scheduler 这个 target 是否已经正常了:

大家可以按照上面的方法尝试去修复下 kube-controller-manager 组件的监控。
入门监控实例
部署示例应用程序
首先,让我们部署一个简单的示例应用程序,它有3个副本,监听并公开端口上的指标
8080
.
apiVersion: apps/v1
kind: Deployment
metadata:
name: example-app
spec:
replicas: 3
selector:
matchLabels:
app: example-app
template:
metadata:
labels:
app: example-app
spec:
containers:
- name: example-app
image: fabxc/instrumented_app
ports:
- name: web
containerPort: 8080
我们用一个
Service
来绑定这些pod。并且暴露 8080 。
kind: Service
apiVersion: v1
metadata:
name: example-app
labels:
app: example-app
spec:
selector:
app: example-app
ports:
- name: web
port: 8080
最后,我们创建一个ServiceMonitor对象来根据label自动发现需要监控的服务(example-app),它选择
app: example-app
标签。
ServiceMonitor
对象也有一个
team
标签(在这种情况下
team: frontend
)来确定哪个团队负责监控 pod或者service。
apiVersion: monitoring.coreos.com/v1
kind: ServiceMonitor
metadata:
name: example-app
labels:
team: frontend
spec:
selector:
matchLabels:
app: example-app
endpoints:
- port: web
部署 Prometheus
如果您的集群使用的是RBAC授权方式,您必须先为Prometheus服务帐户创建RBAC规则。
应用以下清单来创建服务帐户和所需的
ClusterRole/ClusterRoleBinding
:
apiVersion: v1
kind: ServiceAccount
metadata:
name: prometheus
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus
rules:
- apiGroups: [""]
resources:
- nodes
- nodes/metrics
- services
- endpoints
- pods
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources:
- configmaps
verbs: ["get"]
- apiGroups:
- networking.k8s.io
resources:
- ingresses
verbs: ["get", "list", "watch"]
- nonResourceURLs: ["/metrics"]
verbs: ["get"]
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: prometheus
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus
subjects:
- kind: ServiceAccount
name: prometheus
namespace: default
Prometheus 自定义资源(CRD)定义了底层具体状态集的特征(副本数量、资源请求/限制等)以及应包含哪些服务监视器
spec.serviceMonitorSelector
字段。
我们已经使用
team: frontend
标签,这里我们定义Prometheus对象应该选择所有带有
team: frontend
标签。这使得
frontend
团队能够创建新的服务监视器和服务,而不必重新配置Prometheus对象。
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
name: prometheus
spec:
namespaceSelector:{}
serviceAccountName: prometheus
serviceMonitorNamespaceSelector: {}
serviceMonitorSelector:
matchLabels:
team: frontend
resources:
requests:
memory: 400Mi
enableAdminAPI: false
要验证实例已启动并正在运行,运行:
kubectl get -n default prometheus prometheus -w
默认情况下,Prometheus将只从当前命名空间中选取ServiceMonitors。若要从其他命名空间中选择ServiceMonitors,可以更新
spec.serviceMonitorNamespaceSelector
Prometheus resource 资源领域。
选择所有的namespace
namespaceSelector:
any: true
选择指定的 namespace
namespaceSelector:
matchNames:
- prod
使用 PodMonitors
我们可以使用PodMonitor来代替ServiceMonitor。在实践中
spec.selector
标签告诉Prometheus应该选择的pod。
apiVersion: monitoring.coreos.com/v1
kind: PodMonitor
metadata:
name: example-app
labels:
team: frontend
spec:
selector:
matchLabels:
app: example-app
namespaceSelector: {}
podMetricsEndpoints:
- port: web
interval: 15s
path: /metrics
类似地,Prometheus对象定义了用
spec.podMonitorSelector
字段。
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
name: prometheus
spec:
serviceAccountName: prometheus
podMonitorSelector:
matchLabels:
team: frontend
resources:
requests:
memory: 400Mi
enableAdminAPI: false
访问 Prometheus service
要访问Prometheus接口,您必须向外部公开服务。为了简单起见,我们使用一个
NodePort
服务。
当然也可以使用Ingress
apiVersion: v1
kind: Service
metadata:
name: prometheus
spec:
type: NodePort
ports:
- name: web
nodePort: 30900
port: 9090
protocol: TCP
targetPort: web
selector:
prometheus: prometheus
一旦创建了服务,Prometheus web服务器就可以在端口上的节点IP地址下使用了
30900
。web界面中的Targets页面应该显示已经成功发现了示例应用程序的实例。

Prometheus Admin API
Prometheus Admin API允许访问删除特定时间范围内的series (数据),清理tombstones,捕捉快照等。关于admin API的更多信息可以在Prometheus 官方文档默认情况下,此API访问是禁用的,可以使用此bool标志进行切换。以下示例公开了管理API:
警告:启用管理API会启用变异端点、删除数据、关闭Prometheus等等。启用此功能时应小心谨慎,建议用户通过代理添加额外的身份验证/授权,以确保只有获得授权的客户端才能执行这些操作。
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
name: prometheus
spec:
serviceAccountName: prometheus
serviceMonitorSelector:
matchLabels:
team: frontend
resources:
requests:
memory: 400Mi
enableAdminAPI: true
Alerting
在Prometheus中定义AlertRule(告警规则 PrometheusRule),Prometheus会周期性的对告警规则进行计算,如果满足告警触发条件就会向Alertmanager发送告警信息。Alertmanager 再经过分组、抑制以及静默发送到 对应的receiver
Prometheus Operator引入了一个
Alertmanager
资源,该资源允许用户以声明方式描述Alertmanager集群。要成功部署Alertmanager集群,理解Prometheus和Alertmanager之间的契约非常重要。Alertmanager用于:
- 对从Prometheus收到的警报进行重复数据去重。
- 静音提示。
- 将分组通知路由和发送到各种集成(PagerDuty、OpsGenie、mail、chat等)。
Prometheus Operator还引入了一个
AlertmanagerConfig
资源,它允许用户以声明方式描述Alertmanager配置。
Prometheus的配置还包括“rule files”,其中包含警报规则 alerting rules。当一个警报规则触发时,它会触发该警报全部Alertmanager实例,打开每个规则评估间隔。Alertmanager实例相互交流哪些通知已经发出。有关此系统设计的更多信息,请参见高可用性页面。
部署 Alertmanager
首先,创建一个包含三个副本的Alertmanager集群:
apiVersion: monitoring.coreos.com/v1
kind: Alertmanager
metadata:
name: example
spec:
replicas: 3
等待所有报警管理器盒准备就绪:
kubectl get pods -l alertmanager=example -w
管理 Alertmanager configuration
默认情况下,Alertmanager实例将以最小的配置启动,这并不是真正有用的,因为它没有报警配置,所以在接收警报时不会发送任何通知。
你需要用下面几种选择来提供警报管理器配置:
- 您可以使用存储在Kubernetes secret中的本地Alertmanager配置文件。
- 你可以用
spec.alertmanagerConfiguration在定义主Alertmanager配置的同一命名空间中引用AlertmanagerConfig对象。
- 你可以用
- 你可以定义
spec.alertmanagerConfigSelector和spec.alertmanagerConfigNamespaceSelector告诉operator 应该选择哪些AlertmanagerConfigs对象并将其与主Alertmanager配置合并。
- 你可以定义
1. 使用 Kubernetes Secret
以下本机Alertmanager配置向外部的webhook服务发送通知:
route:
group_by: ['job']
group_wait: 30s
group_interval: 5m
repeat_interval: 12h
receiver: 'webhook'
receivers:
- name: 'webhook'
webhook_configs:
- url: 'http://example.com/'
将上述配置保存在一个名为
alertmanager.yaml
并从中创建一个
Secret
:
kubectl create secret generic alertmanager-example --from-file=alertmanager.yaml
Prometheus operator要求
Secret
的命名要像
alertmanager-{ALERTMANAGER_NAME}
。在前面的示例中,Alertmanager的名称是
example
,所以Secret名必须是
alertmanager-example
。
Secret
中保存配置数据的密钥的名称必须是
alertmanager.yaml
.
注意:如果要使用不同的
Secret名称,可以用
spec.configSecretAlertmanager资源中的字段。
Alertmanager配置可能会引用磁盘上的自定义模板或
Secret
文件。这些可以和
alertmanager.yaml
配置文件。例如,假设我们有以下
Secret
:
apiVersion: v1
kind: Secret
metadata:
name: alertmanager-example
data:
alertmanager.yaml: {BASE64_CONFIG}
template_1.tmpl: {BASE64_TEMPLATE_1}
template_2.tmpl: {BASE64_TEMPLATE_2}
Alertmanager容器也可以访问模板比如
/etc/alertmanager/config
目录。Alertmanager配置可以像这样引用它们:
templates:
- '/etc/alertmanager/config/*.tmpl'
2. 使用AlertmanagerConfig Resources
以下示例配置创建了一个向webhook服务发送通知的AlertmanagerConfig资源。
apiVersion: monitoring.coreos.com/v1alpha1
kind: AlertmanagerConfig
metadata:
name: config-example
labels:
alertmanagerConfig: example
spec:
route:
groupBy: ['job']
groupWait: 30s
groupInterval: 5m
repeatInterval: 12h
receiver: 'webhook'
receivers:
- name: 'webhook'
webhookConfigs:
- url: 'http://example.com/'
在群集中创建AlertmanagerConfig资源:
curl -sL https://raw.githubusercontent.com/prometheus-operator/prometheus-operator/main/example/user-guides/alerting/alertmanager-config-example.yaml | kubectl create -f -
这
spec.alertmanagerConfigSelector
需要更新Alertmanager资源中的字段,以便operator选择AlertmanagerConfig资源。在前面的示例中,标签
alertmanagerConfig: example
所以Alertmanager对象应该像这样更新:
apiVersion: monitoring.coreos.com/v1
kind: Alertmanager
metadata:
name: example
spec:
replicas: 3
alertmanagerConfigSelector:
matchLabels:
alertmanagerConfig: example
3. 使用AlertmanagerConfig进行全局配置
下面的示例配置创建一个Alertmanager资源,该资源使用AlertmanagerConfig资源来代替
alertmanager-example
secret。
apiVersion: monitoring.coreos.com/v1
kind: Alertmanager
metadata:
name: example
namespace: default
spec:
replicas: 3
alertmanagerConfiguration:
name: config-example
名为
example-config
的AlertmanagerConfig资源在命名空间中
default
将是一个全局警报管理器配置。当operator 从中生成Alertmanager配置时,不会对路由和禁止规则强制使用名称空间标签。
暴露 Alertmanager service
要访问Alertmanager接口,必须向外部公开服务。为了简单起见,我们使用一个
NodePort
服务。
apiVersion: v1
kind: Service
metadata:
name: alertmanager-example
spec:
type: NodePort
ports:
- name: web
nodePort: 30903
port: 9093
protocol: TCP
targetPort: web
selector:
alertmanager: example
创建服务后,Alertmanager web服务器就可以在节点的IP地址端口下使用了
30903
.
与Prometheus整合
在Prometheus中配置Alertmanager
这个Alertmanager集群现在功能齐全且高度可用,但是没有针对它触发任何警报。
首先,创建一个Prometheus实例,它将向Alertmanger集群发送警报:
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
name: example
spec:
serviceAccountName: prometheus
replicas: 2
alerting:
alertmanagers:
- namespace: default
name: alertmanager-example
port: web
serviceMonitorSelector:
matchLabels:
team: frontend
ruleSelector:
matchLabels:
role: alert-rules
prometheus: example
这
Prometheus
资源发现
Service
之前创建的(注意
name
,
namespace
和
port
应该与Alertmanager服务的定义相匹配的字段)。
打开Prometheus web界面,转到“Status > Runtime & Build Information”页面,检查Prometheus是否发现了3个Alertmanager实例。

部署 Prometheus Rules
PrometheusRule
CRD允许定义警报和记录规则。operator 知道为给定的Prometheus 选择哪个PrometheusRule 对象
spec.ruleSelector
字段。
注意:默认情况下,
spec.ruleSelector为nil意味着操作符没有选择任何规则。
默认情况下,Prometheus resources 仅发现
PrometheusRule
同一命名空间中的资源。这可以用
ruleNamespaceSelector
字段:
- 要从所有名称空间中发现规则,传递一个空的
{}(ruleNamespaceSelector: {}). - 若要从匹配某个标签的所有命名空间中发现规则,请使用
matchLabels字段。
Prometheus 会自动发现
PrometheusRule
资源与
role=alert-rules
和
prometheus=example
来自所有命名空间的标签
team=frontend
标签:
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
name: example
spec:
serviceAccountName: prometheus
replicas: 2
alerting:
alertmanagers:
- namespace: default
name: alertmanager-example
port: web
serviceMonitorSelector:
matchLabels:
team: frontend
ruleSelector:
matchLabels:
role: alert-rules
prometheus: example
ruleNamespaceSelector:
matchLabels:
team: frontend
如果您想按名称选择单个命名空间,可以使用
kubernetes.io/metadata.name
标签,它会自动用NamespaceDefaultLabelName功能。
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
creationTimestamp: null
labels:
prometheus: example
role: alert-rules
name: prometheus-example-rules
spec:
groups:
- name: ./example.rules
rules:
- alert: ExampleAlert
expr: vector(1)
创建
PrometheusRule
对象。请注意,对象的标签与
spec.ruleSelector
Prometheus 配置的相对应
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
creationTimestamp: null
labels:
prometheus: example
role: alert-rules
name: prometheus-example-rules
spec:
groups:
- name: ./example.rules
rules:
- alert: ExampleAlert
expr: vector(1)
apiVersion: monitoring.coreos.com/v1
kind: PrometheusRule
metadata:
creationTimestamp: null
labels:
prometheus: k8s
role: alert-rules
name: prometheus-example-rules
spec:
groups:
- name: hostStatsAlert
rules:
- alert: hostCpuUsageAlert
expr: sum(avg without (cpu)(irate(node_cpu_seconds_total{mode!='idle'}[5m]))) by (instance) > 0.5
for: 1m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} CPU usgae high"
description: "{{ $labels.instance }} CPU usage above 85% (current value: {{ $value }})"
- alert: hostMemUsageAlert
expr: (node_memory_MemTotal_bytes - node_memory_MemAvailable_bytes)/node_memory_MemTotal_bytes > 0.5
for: 1m
labels:
severity: page
annotations:
summary: "Instance {{ $labels.instance }} MEM usgae high"
description: "{{ $labels.instance }} MEM usage above 85% (current value: {{ $value }})"
那些坑
Prometheus Operator 高可用设计
Prometheus 高可用
Prometheus Operator 暂不支持 高可通设计还在规划中,详情参考官方文档 https://prometheus-operator.dev/docs/operator/high-availability/
Alertmanager
通过Gossip协议实现高可用,部署完之后自动形成集群

Prometheus 高可用参考:【Prometheus】Prometheus 集群与高可用
Prometheus 支持远程读写
kubectl explain Prometheus.spec.remoteRead
tsdb 保留天数

默认情况下Prometheus Operator 的 tsdb(–storage.tsdb.retention.time) 只保留1天,这里我们需要要在自己的意愿把他变成
使用explain 查看Prometheus 资源结构
kubectl explain Prometheus.spec
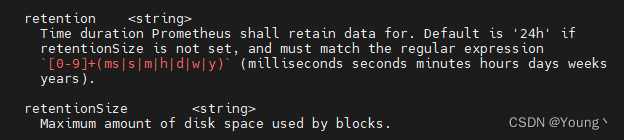
可以查看到有 retention 保留设置
kind: Prometheus
apiVersion: monitoring.coreos.com/v1
...
spec:
...
retention: 15d
结果
参考
查看Prometheus 资源结构
版权归原作者 Young丶 所有, 如有侵权,请联系我们删除。