
一、主机名、本地源
主机名修改命令:
hostnamectl set-hostname [主机名]
立即生效:
bash
本地源修改:
先进入一个文件,命令:
cd /etc/yum.repos.d/
然后输入命令(ls)就可以查看到文件夹下有一个.repo文件
如果需要改动直接替换就好
可以直接进入配置文件
cd /etc/yum.repos.d/****.repo
修改完本地源之后,要修改host文件
vim /etc/hosts
要把多台主机对应的IP地址和主机名写入
后期作了映射之后,如想在master上访问slave1,就不用去访问对应的IP了,直接访问slave1(主机名)就可以了
因为集群里面多台主机是要相互通讯的,所以我们要把防火墙关闭
systemctl stop firewalld
如果关闭了以后想去确认一下,就可以输入命令
systemctl status firewalld
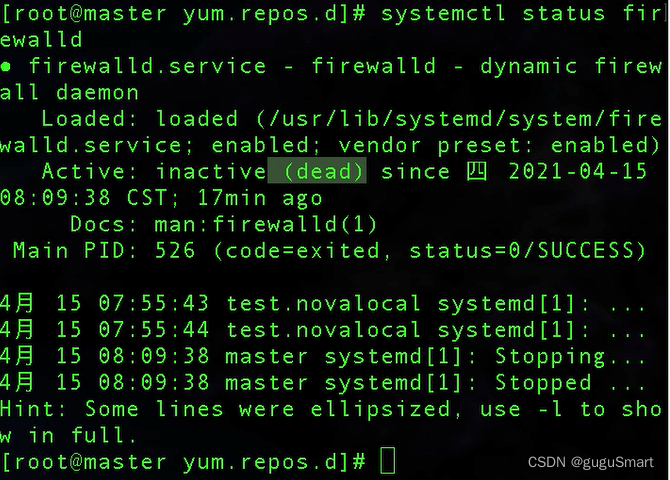
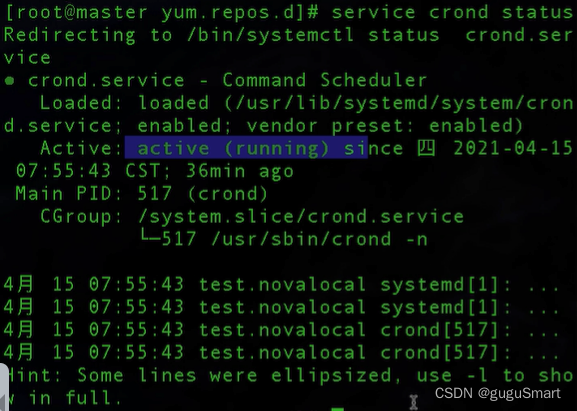
这时候就可以直接看到防火墙的状态是关闭(dead)状态了
二、时间同步
选择时区
tzselect
然后根据提示一步步选择就行
选择完毕后会出现提示,需要将一串代码写入到环境变量中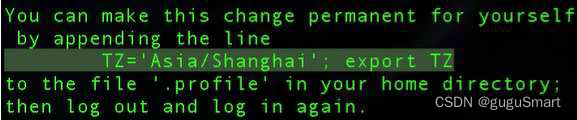
echo "[提示的代码]" >> /etc/profile && source /etc/profile
注意,要在所有主机中都输入这个命令
之后要对ntp时间协议进行操作
第一步是安装ntp包
yum install -y ntp
安装完成后可输入以下命令查看是否成功安装
rpm -qa | grep ntp
ntp包的下载需要在所有主机中都进行一次
接着要做相应的配置
要把master作为时钟源,以此为中心,把slave去同步master的时间
时钟源有相应的配置文件,直接在master中进行修改
vim /etc/ntp.conf
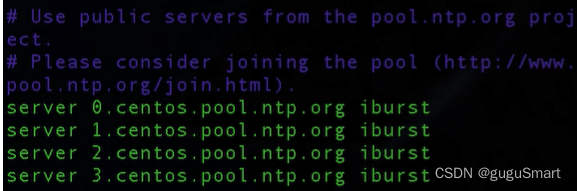
找到这一段信息,把原有的时钟源注释掉,并加入本机的时钟源,并嵌入10层时间服务器层级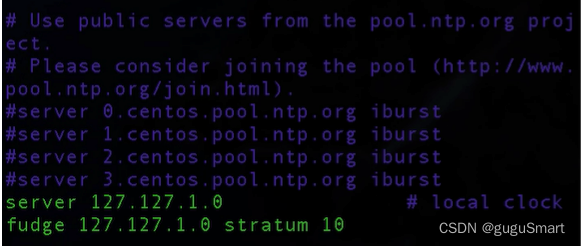
做完这些后,输入 :wq 保存并退出
在master上配置好后,要进行重启服务
/bin/systemctl restart ntpd.service
之后要在slave主机上进行时间同步
ntpdate master(即时间源主机名)
三、定时任务
此操作可以控制slave主机每隔一段时间去同步时间
要先看这个服务是否开启
service crond status
之后可以查看crondtab的具体命令
crontab -h
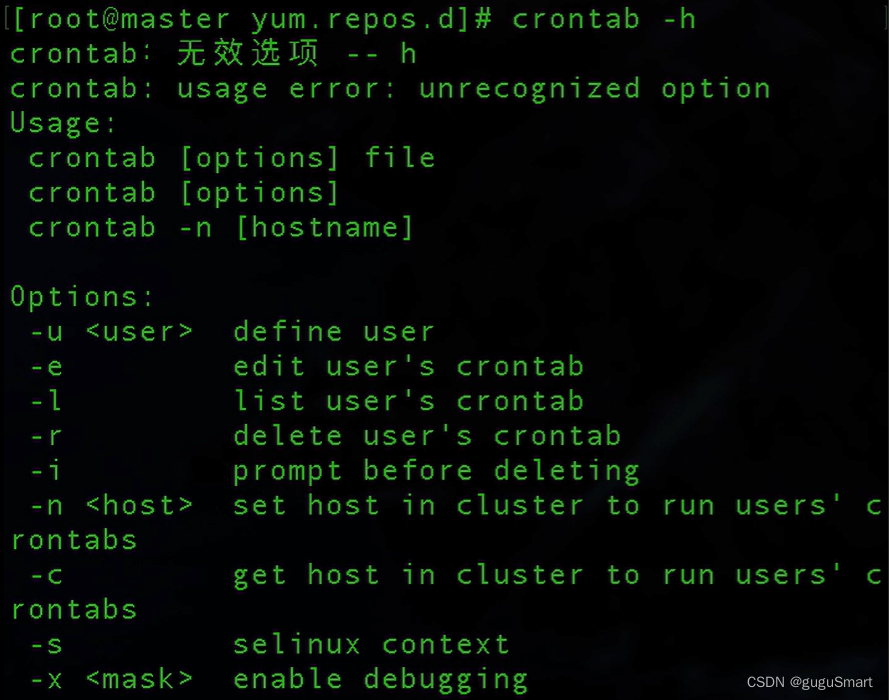 -e:写入定时任务
-e:写入定时任务
-l:列出任务,可查看当前的任务
接下来演示新建定时任务
首先,在slave主机中输入代码进入编辑
crontab -e
然后,在编辑状态下,输入接下来的指令
*/30 10-17 * * * /usr/sbin/ntpdate master
 这里解释一下,“*/30”表示每30分钟,因此第一个表示分钟;“10-17”表示一天内的时间,即10点到17点;“ * ”则分别代表“日 月 周”
这里解释一下,“*/30”表示每30分钟,因此第一个表示分钟;“10-17”表示一天内的时间,即10点到17点;“ * ”则分别代表“日 月 周”
代表意义分钟小时日月周命令数字范围0590231311120~7/
其中,“周”中的0和7都代表星期日
特殊符号意义代表能接受任意时刻,表示分割时间段-代表一个时间范围/n代表每间隔n个单位
创建完任务后输入 :wq 保存并退出
推出后可以输入命令查看任务
crontab -l
四、ssh服务
要使用ssh服务,首先得生成一个密钥
ssh-keygen
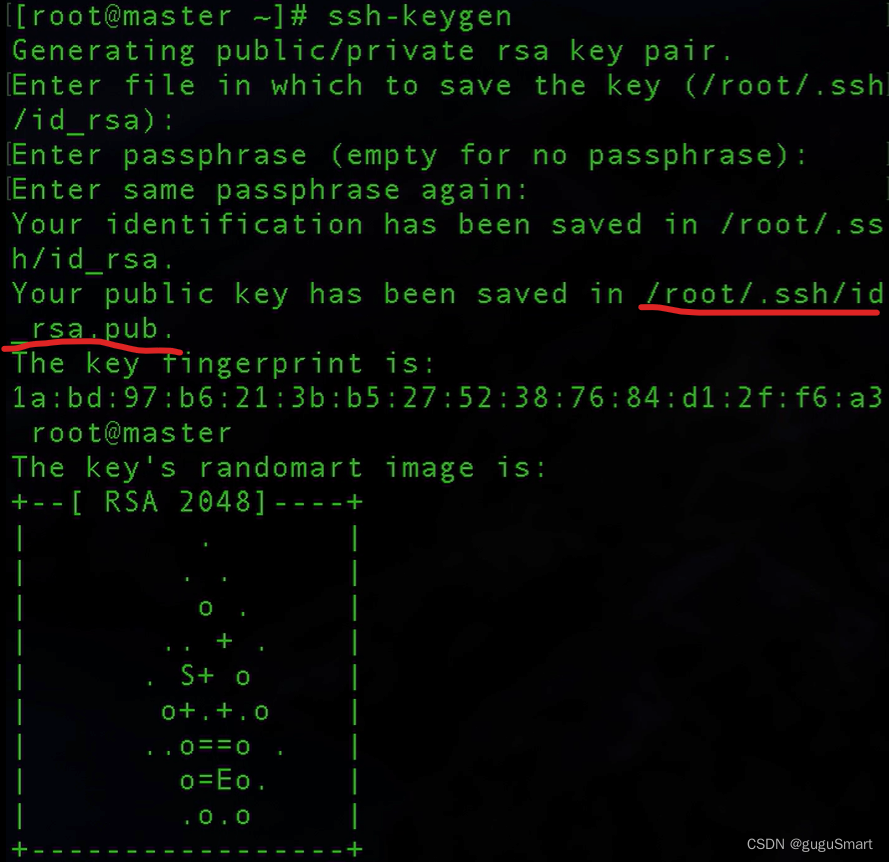 此密钥文件在目录 /root/.ssh/ 下,密钥也在上图中给出,很明显就是id_rsa.pub
此密钥文件在目录 /root/.ssh/ 下,密钥也在上图中给出,很明显就是id_rsa.pub
然后要把密钥文件复制到slave主机中
cat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
我们可以去验证一下,首先查看一下rsa密钥文件
cat id_rsa.pub
然后再去查看authorized_keys文件
cat authorized_keys
 可以看到两个文件中的内容是相同的,就是把id_rsa.pub文件中的内容放入了authorized_keys文件中。
可以看到两个文件中的内容是相同的,就是把id_rsa.pub文件中的内容放入了authorized_keys文件中。
之后,我们要把authorized_keys这个授权文件放到slave主机中进行相关的信任授权。
用scp命令将授权文件放到slave主机上的相同目录下
scp ~/.ssh/authorized_keys root@slave1:~/.ssh/
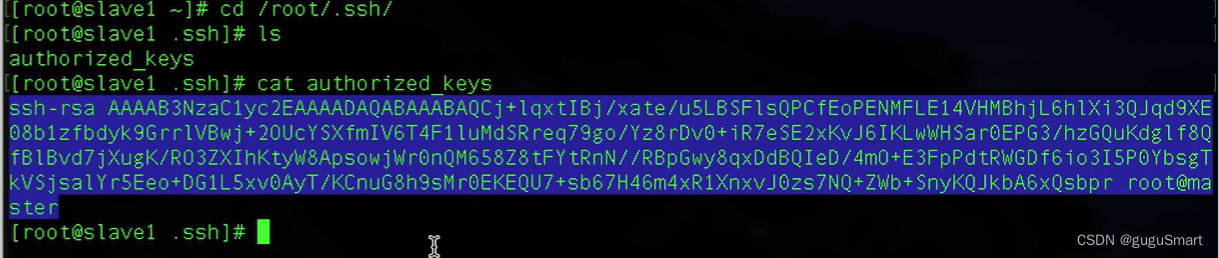 该操作需要将authorized_keys复制到每一台slave主机
该操作需要将authorized_keys复制到每一台slave主机
完成这个操作以后,我们就可以直接在master主机上连接到slave主机了
ssh slave1
如果想要退出,就可以输入 “exit” 退出。
五、安装JDK
首先返回至原始目录。
第一步,创建工作环境
mkdir /usr/java
第二步,进入目录
cd /usr/java/
第三步,将对应的下载包下载下来
第四步,解压下载包
可以直接解压到当前目录,也可以通过“-C”这个命令解压到指定目录
第五步,将对应的环境变量写进来
vim /etc/profile

然后将以上内容写入
export JAVA_HOME=/usr/java/jdk1.8.0_171
export CLASSPATH=$JAVA_HOME/lib/
export PATH=$PATH:$JAVA_HOME/bin
export PATH JAVA_HOME CLASSPATH
第六步,保存退出后,我们还要将以上环境变量进行生效。
source /etc/profile
生效后,我们可以通过以下命令查看一下
java -version
同样, 使用scp命令将其复制到slave主机中。
scp -r /usr/java root@slave1:/usr/
复制完成后,我们还是要在slave主机中修改profile文件,生效并验证。
六、安装Zookeeper
还是回到原始目录
最开始还是创建工作目录并进入
mkdir -p /usr/zookeeper && cd /usr/zookeeper
然后下载Zookeeper安装包
然后解压
完成后也是进入profile文件修改环境变量
vim /etc/profile
#Zookeeper
export ZOOKEEPER_HOME=/usr/zookeeper/zookeeper-3.4.10
PATH=$PATH:$ZOOKEEPER_HOME/bin
保存退出后进行生效
source /etc/profile
此操作要在slave主机上也进行一遍!!
接下来进行配置文件的修改
进入到zookeeper的配置文件中
cd zookeeper-3.4.10
cd conf/
配置文件就是zoo_sample.cfg
首先对它进行复制、重命名
cp zoo_sample.cfg zoo.cfg
然后就可以进入修改了
vim zoo.cfg
配置文件中已经有大量信息了,我们只需要修改它的数据路径以及日志路径就可以了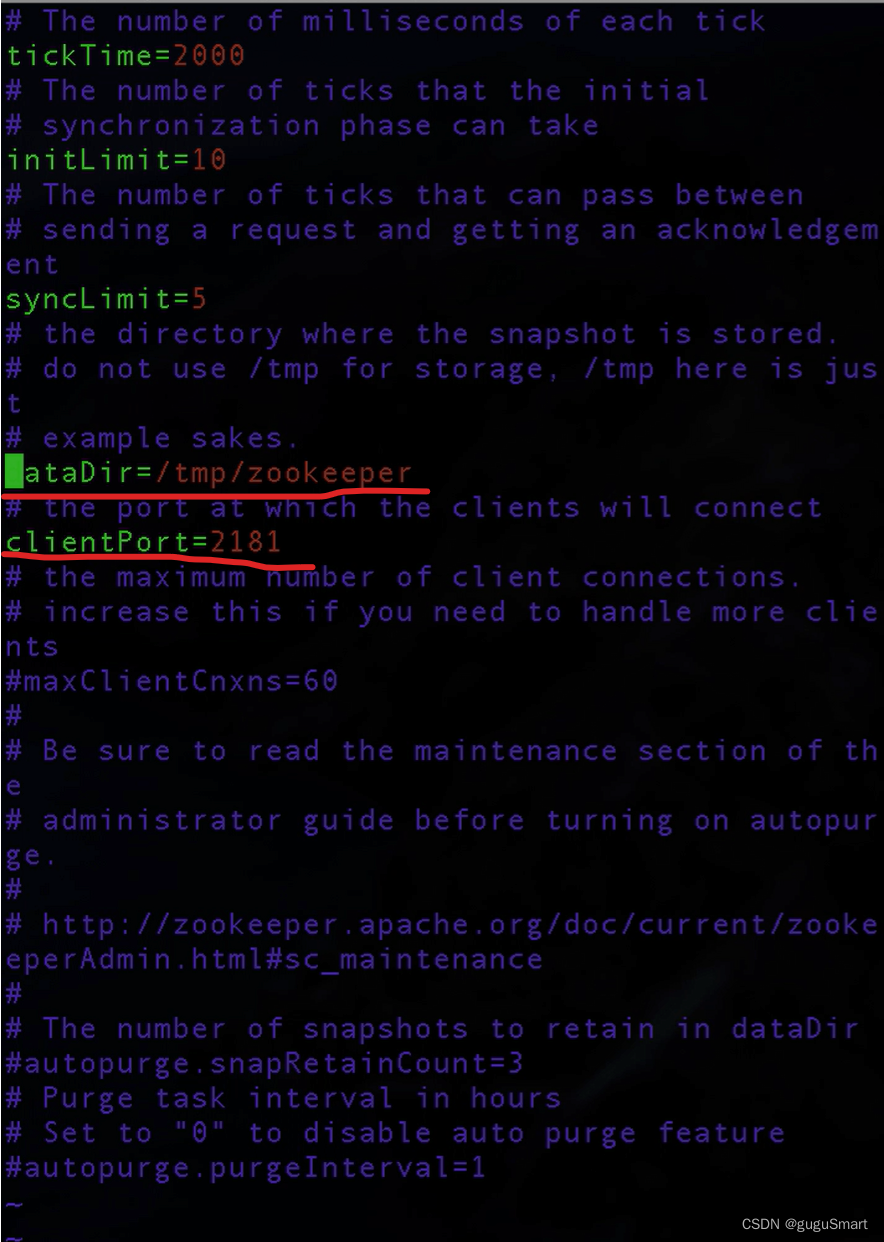
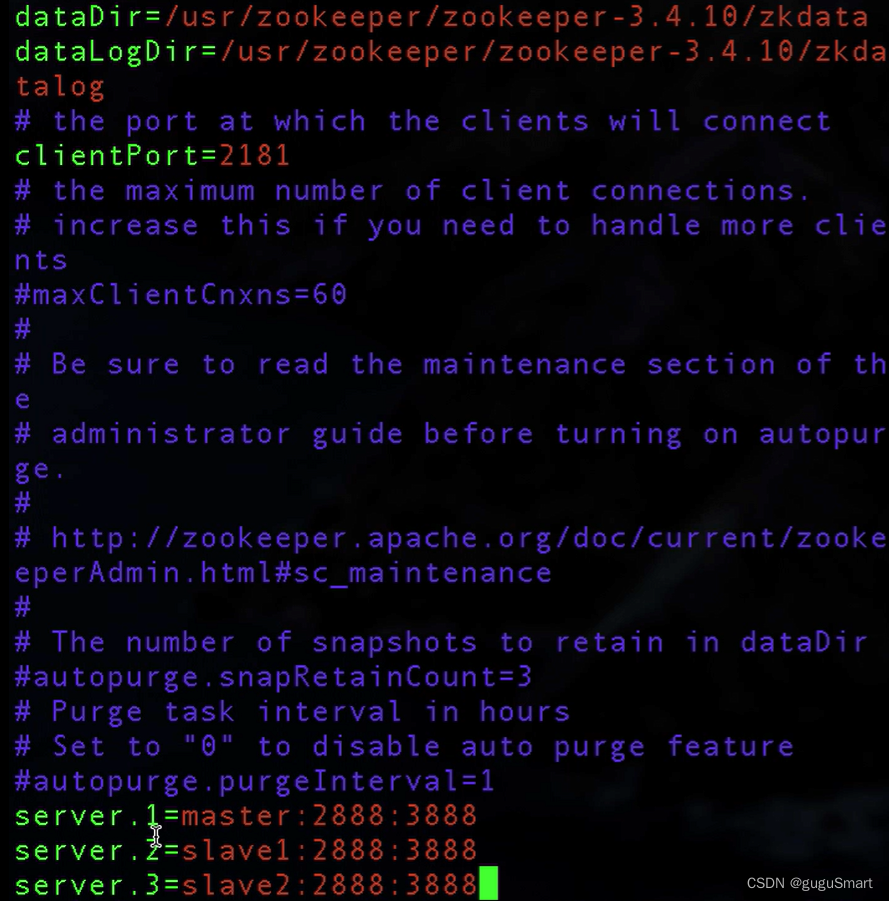
dataDir=/usr/zookeeper/zookeeper-3.4.10/zkdata
dataLogDir=/usr/zookeeper/zookeeper-3.4.10/zkdatalog
并要在最后加上三个集群节点
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
然后就是进入并创建数据及其日志的目录了
cd /usr/zookeeper/zookeeper-3.4.10 && mkdir zkdata zkdatalog
还是使用scp命令复制到slave主机上
scp -r /usr/zookeeper root@slave1:/usr/
之前在创建节点的时候有一个对应的序号,因此我们还需要创建一个myid将这些序号写进去
进入zkdata路径
vim myid
直接编辑myid,写入对应的序号。
这些操作在slave主机上也要进行
slave2主机:
cd /usr/zookeeper/zookeeper-3.4.10/zkdata
echo 2 >> myid
slave3主机:
cd /usr/zookeeper/zookeeper-3.4.10/zkdata
echo 3 >> myid
写好了以后就是要开启服务了
zkServer.sh start
注意,要在所有主机上都开启!
然后我们可以查看一下服务的状态
zkServer.sh status
总结
短短27分半的课竟然有那么大的信息量,有一说一,听得稀里糊涂、莫名其妙,要问我为什么要这样做吧,也不能说出啥所以然来。刚还是还是死记硬背吧,应该都是基础知识和固定的目录,背下来就完事儿了……
期待实操……
版权归原作者 guguSmart 所有, 如有侵权,请联系我们删除。